Command Palette
Search for a command to run...
Ein Lokal Ausführbares Modell Zur Erkennung Von Datenschutzverletzungen: Privacy Filter Erzielt Eine Hochwertige Filterung Personenbezogener Daten Zu Geringen Kosten; Echte Open Source! Umfasst Den Strukturierten Fußballdatensatz Von Transfermarkt Mit Über 80.000 Spielen.

Privacy Filter ist ein von OpenAI entwickeltes Open-Source-Modell zur bidirektionalen Klassifizierung mit Labeln, das für die Bereinigung großer Datenmengen eingesetzt wird. Es dient der effizienten Erkennung und Maskierung personenbezogener Daten (PII) in Texten. Das Modell basiert auf einer kleinen, vortrainierten Architektur, ähnlich wie gpt-oss, und verzichtet auf die traditionelle Wort-für-Wort-Generierung. Stattdessen dekodiert es direkt zusammenhängende Segmente der Eingabesequenz durch eine einzige Vorwärtsausbreitung in Kombination mit dem eingeschränkten Viterbi-Algorithmus.
Aktuell ist auf der HyperAI-Website [der entsprechende Bereich/die entsprechende Funktion] verfügbar.DatenschutzfiltermodellKomm und probier es aus!
Online-Nutzung:https://go.hyper.ai/Py1l3
Ein kurzer Überblick über die Aktualisierungen der offiziellen Website von hyper.ai vom 25. bis 30. April:
* Hochwertige öffentliche Datensätze: 5
* Eine Auswahl hochwertiger Tutorials: 5
* Analyse von Community-Artikeln: 1 Artikel
* Beliebte Enzyklopädieeinträge: 5
Besuchen Sie die offizielle Website:hyper.ai
Ausgewählte öffentliche Datensätze
1. Transfermarkt Fußballdatensatz
Transfermarkt Football ist ein strukturierter Datensatz zum Fußballtransfermarkt, der auf der Transfermark-Website basiert und für Sportanalysen und Datenmodellierung entwickelt wurde. Der Datensatz umfasst über 80.000 Fußballspiele, 400 Vereine und mehr als 37.000 Spieler und erfasst Marktwertveränderungen, Einsätze und Transferaktivitäten der Spieler.
Online-Nutzung:https://go.hyper.ai/lF661
2. Yoga-Training: Klassifizierung von Yoga-Haltungen und Trainingsdatensatz
Yoga Training ist ein Datensatz zur Klassifizierung von Yoga-Positionen, der primär für Bildklassifizierung, Positionserkennung, ressourcenschonendes Deep-Learning-Training und Transfer-Learning-Experimente verwendet wird. Dieser Datensatz enthält 1.771 Beispielbilder von Yoga-Positionen unterschiedlicher Schwierigkeitsgrade und Positionskategorien.
Online-Nutzung:https://go.hyper.ai/hVdM8
3. Datensatz zu Maisblattkrankheiten
Der Datensatz „Maisblattkrankheiten“ enthält Bilder von Maisblättern, die speziell für die Zielerkennung in der Präzisionslandwirtschaft entwickelt wurden. Er umfasst 4.027 Bilder von Maisblättern in vier Kategorien: gesunde Blätter sowie drei häufige Krankheiten wie Rost, Graufleckenkrankheit und Welke.
Online-Nutzung:https://go.hyper.ai/UbRRp
4. Datensatz zu Apfelblattkrankheiten
Der Datensatz „Apple Leaf Diseases“ ist ein hochwertiger Bilddatensatz für Apfelblätter, der speziell für die Zielerkennung in der Präzisionslandwirtschaft entwickelt wurde. Er enthält 3.444 Bilder von Apfelblättern aus vier Kategorien: gesunde Blätter und drei häufige Krankheiten: Schwarzfäule, Zedernrost und Schorf.
Online-Nutzung:https://go.hyper.ai/LDafw
5. Datensatz zur Erkennung unerwünschter Arzneimittelwirkungen
Die Datenbank „Drug Adverse Event Detection“ ist ein Textdatensatz, der reale Szenarien mit Mehrfachverschreibungen simuliert. Ziel ist die Untersuchung des Risikos von Arzneimittelnebenwirkungen durch die gleichzeitige Anwendung mehrerer Medikamente. Die Datenbank findet breite Anwendung in der Erkennung von Arzneimittelnebenwirkungen, der Extraktion medizinischer Informationen, der klinischen Textanalyse und dem Training medizinischer KI-Modelle.
Online-Nutzung:https://go.hyper.ai/AlL32
Ausgewählte öffentliche Tutorials
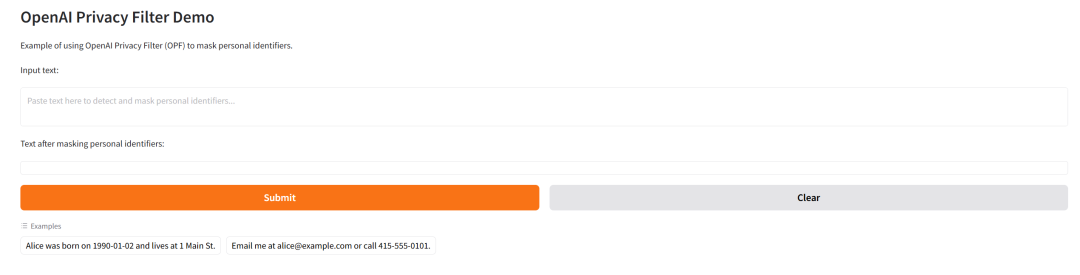
1. Sichtschutzfiltermodell
Der OpenAI Privacy Filter ist ein bidirektionales Token-Klassifizierungsmodell, das von OpenAI im April 2026 veröffentlicht wurde und dazu dient, personenbezogene Daten (PII) in Texten zu erkennen und zu maskieren. Das Modell verwendet eine ähnliche Architektur wie gpt-oss, ist jedoch deutlich kleiner. Laut der offiziellen Modellbeschreibung verfügt es über ca. 1,5 Milliarden Parameter, davon ca. 50 Millionen aktive Parameter, unterstützt maximal 128.000 Token-Kontexte und gibt die Grenzen von Datenschutzfragmenten mithilfe von 33 BIOES-Token-Level-Labels aus.
Online ausführen:https://go.hyper.ai/Py1l3
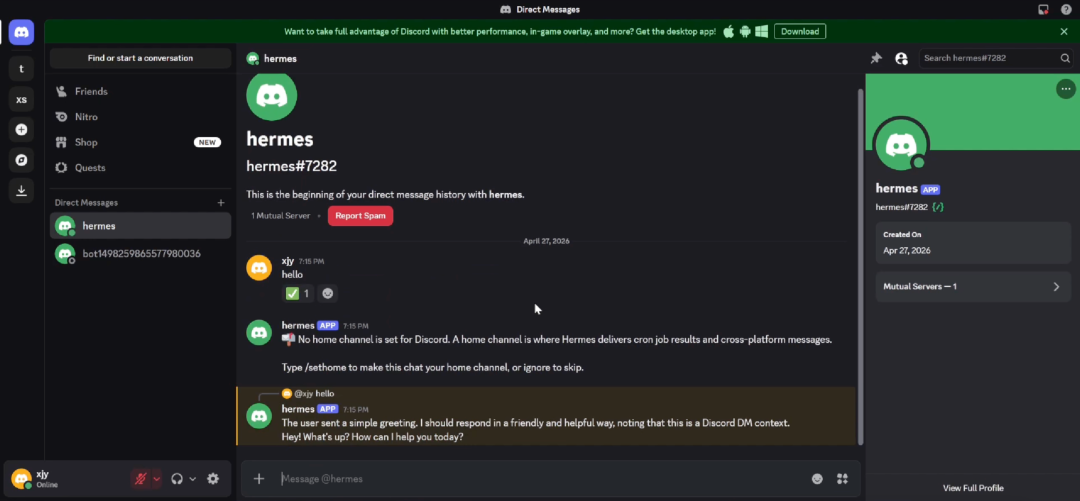
2. Hermes-Bedienungsanleitung
Hermes Agent ist ein Open-Source-KI-Agent, der sich selbst weiterentwickelt und 2026 vom Nous Research-Team entwickelt wurde. Ein Kernmerkmal dieses Projekts ist sein integrierter Lernprozess: Er generiert automatisch Fähigkeiten aus der Aufgabenerfahrung, verbessert sich kontinuierlich während der Nutzung, speichert Wissen proaktiv in seinem Speichersystem und kann vergangene Konversationen durchsuchen, um schrittweise ein tiefes Verständnis des Nutzers aufzubauen. Diese Website bietet Anleitungen zur Ausführung von Hermes auf GPU und CPU.
GPU-Version online ausführen:https://go.hyper.ai/nnyFT
Online-CPU-Version:https://go.hyper.ai/kdo9i
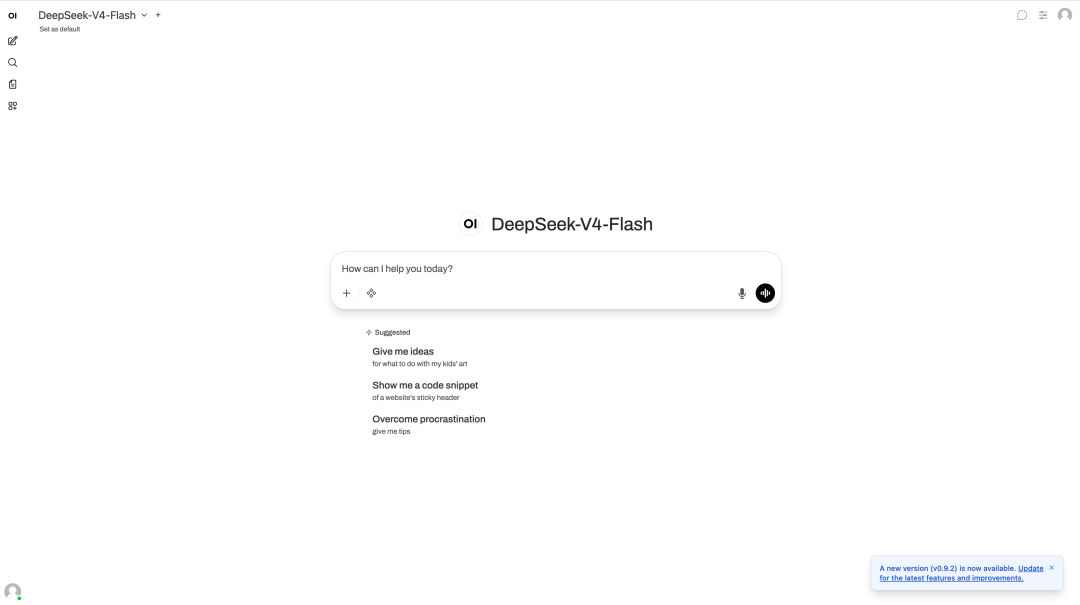
3. Bereitstellung von DeepSeek-V4-Flash mit einem Klick
DeepSeek V4 ist die neueste Generation großer Sprachmodelle des DeepSeek-Teams und umfasst zwei Versionen: DeepSeek-V4-Pro (1,6 Billionen Parameter) und DeepSeek-V4-Flash (285 Milliarden Parameter). DeepSeek V4 verwendet einen brandneuen, hocheffizienten Aufmerksamkeitsmechanismus für lange Kontexte, der Kontextlängen von bis zu einer Million Token nativ unterstützt und speziell für die Verarbeitung extrem langer Texte konzipiert wurde.
Online ausführen:https://go.hyper.ai/sFyxU
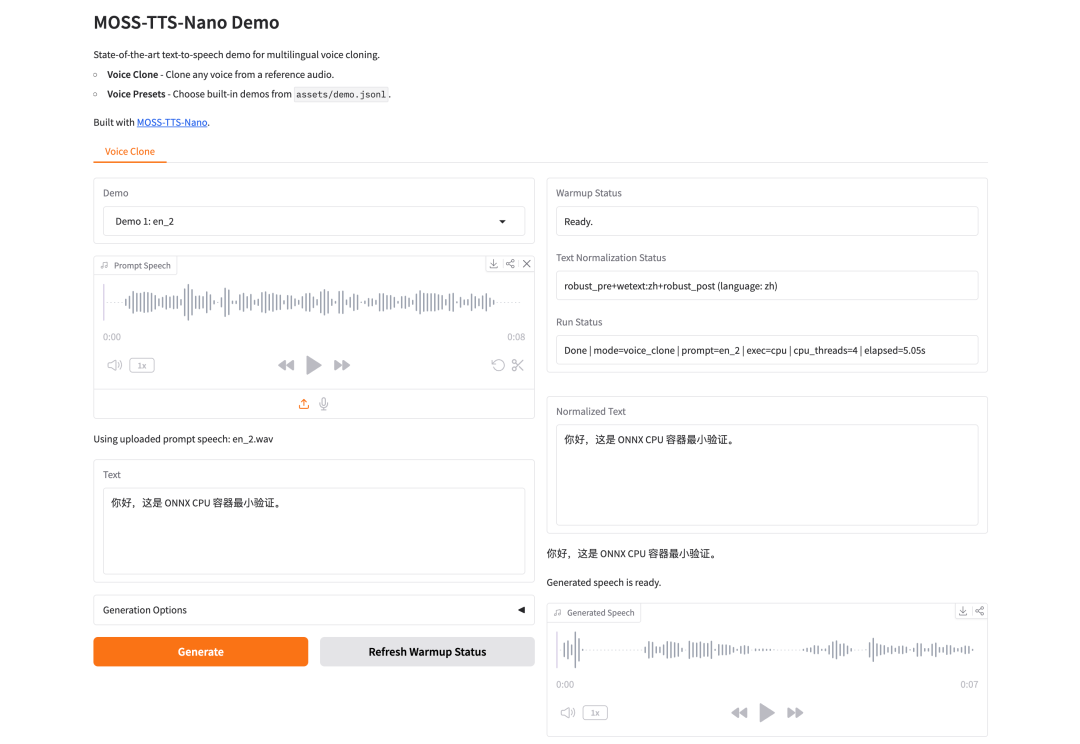
4. MOSS-TTS-Nano mit Free-CPU bereitstellen
MOSS-TTS-Nano ist ein mehrsprachiges Text-zu-Sprache-Modell mit 0,1 Milliarden Parametern, das vom OpenMOSS-Team im April 2026 veröffentlicht wurde. Es unterstützt die Sprachgenerierung und das Klonen von Sprache in einer CPU-Umgebung. Das Modell ist so konzipiert, dass es ein ausgewogenes Verhältnis zwischen Natürlichkeit der Text-zu-Sprache-Generierung, sprachübergreifender Nutzbarkeit und referenzaudiobasierter Klangfarbenübertragung bietet. Dadurch eignet es sich für eine Vielzahl gängiger Aufgaben, vom einfachen Vorlesen bis zum Klonen von Sprache.
Online ausführen:https://go.hyper.ai/CwMEH
Interpretation von Gemeinschaftsartikeln
1. Einem britischen Forschungsteam ist es mithilfe von gestapeltem Ensemble-Lernen gelungen, den seismischen Index von 251 Delta-Scuti-Sternen hochpräzise vorherzusagen.
Ein Forschungsteam der Universität Warwick in Großbritannien hat ein gestaffeltes Ensemble-Lernverfahren entwickelt, um wichtige asteroseismische Parameter von Delta-Scuti-Sternen direkt aus TESS-Lichtkurven vorherzusagen. Diese Methode erzielte bemerkenswerte Ergebnisse an einer Stichprobe von 643 Sternen: Der Bestimmtheitskoeffizient (R²) lag für alle Zielparameter über 0,77, und sie zeigte eine gute Generalisierungsfähigkeit bei 60 Sternen, die nicht im Training verwendet wurden. Die Vorhersageergebnisse stimmten weitgehend mit traditionellen asteroseismischen Analysen überein.
Den vollständigen Bericht ansehen:https://go.hyper.ai/mNGlM
Beliebte Enzyklopädieartikel
1. Fähigkeiten
2. Hypernetzwerke
3. Sigmoidfunktion
4. Reziproke Rangfusion
5. Multiagentenarchitektur
Hier sind Hunderte von KI-bezogenen Begriffen zusammengestellt, die Ihnen helfen sollen, „künstliche Intelligenz“ zu verstehen:
Das Obige ist der gesamte Inhalt der Auswahl des Herausgebers dieser Woche. Wenn Sie über Ressourcen verfügen, die Sie auf der offiziellen Website von hyper.ai veröffentlichen möchten, können Sie uns auch gerne eine Nachricht hinterlassen oder einen Artikel einreichen!
Bis nächste Woche!
Über HyperAI
HyperAI (hyper.ai) ist eine führende Community für künstliche Intelligenz und Hochleistungsrechnen in China.Wir haben uns zum Ziel gesetzt, die Infrastruktur im Bereich der Datenwissenschaft in China zu werden und inländischen Entwicklern umfangreiche und qualitativ hochwertige öffentliche Ressourcen bereitzustellen. Bisher haben wir:
* Bietet inländische beschleunigte Download-Knoten für mehr als 2100 öffentliche Datensätze
* Enthält über 700 klassische und beliebte Online-Tutorials
* Analyse von über 300 AI4Science-Fallstudien
* Unterstützt die Suche nach über 700 verwandten Begriffen
* Hosting der ersten vollständigen chinesischen Apache TVM-Dokumentation in China
Besuchen Sie die offizielle Website, um Ihre Lernreise zu beginnen:








