Command Palette
Search for a command to run...
Ein Team Des MIT Hat Drahtlose Bildverarbeitungssysteme Verbessert, Indem Es Generative KI Einsetzte, Um Vollständig Verdeckte Objekte Mit Hoher Genauigkeit Zu Rekonstruieren Und Dabei Eine Spitzengenauigkeit Von 851 TP3T Zu erreichen.

In der Computer Vision und intelligenten Sensorik stellt die Rekonstruktion vollständig verdeckter Objekte seit jeher eine große Herausforderung dar. Man denke an gestapelte Pakete in einem Logistiklager, komplexe Anlagen in einer Produktionslinie oder Anwendungen in der Augmented Reality, die verborgene Objekte erkennen müssen; herkömmliche optische Sensoren wie Kameras oder LiDAR sind hier oft unzureichend. Sie basieren auf der Reflexion von sichtbarem Licht oder Laserstrahlen, doch diese Signale werden durch Hindernisse blockiert, wodurch die Objekte unsichtbar werden.
In den letzten Jahren hat die Entwicklung der Millimeterwellen-Technologie (mmWave) eine neue Lösung für dieses Problem geboten.Millimeterwellensignale können gängige Hindernisse wie Kartons und Stoffe durchdringen und sind gleichzeitig sicher und schonend für den menschlichen Körper.Dies birgt ein enormes Potenzial in Bereichen wie Industrie, Logistik, Robotik und Augmented Reality. DennochMillimeterwellensignale weisen spiegelnde Reflexionseigenschaften, ein hohes Rauschen und eine geringe räumliche Auflösung auf, was ihre direkte Verwendung für eine vollständige 3D-Rekonstruktion erschwert.Um dieses Problem zu lösen, bietet sich die Anwendung bestehender, auf Bildverarbeitung basierender Formvervollständigungsmodelle auf die Millimeterwellenrekonstruktion an. Diese Strategie liefert jedoch häufig keine zuverlässigen Rekonstruktionsergebnisse, da diese Modelle ursprünglich für hochauflösende, großflächige Sensoren im sichtbaren Lichtbereich entwickelt wurden und die besonderen physikalischen Eigenschaften der Millimeterwellenreflexion nicht berücksichtigen.
Als Reaktion auf dieses Problem,Forscher des MIT haben eine neuartige Methode namens Wave-Former vorgeschlagen, die die Lücke zwischen drahtloser Sensorik und modernen Formvervollständigungstechniken schließt, indem sie die physikalischen Eigenschaften von Millimeterwellen in den Lernprozess einbettet und so eine hochpräzise 3D-Formrekonstruktion von vollständig verdeckten, unterschiedlichsten Alltagsgegenständen ermöglicht.Dieses Verfahren löst nicht nur die Probleme von hohem Signalrauschen und starker Verdeckung, sondern ermöglicht durch ein innovatives Trainingsframework für die physikalische Wahrnehmung auch eine hochpräzise Rekonstruktion in realen Umgebungen auf Basis synthetischer Trainingsdaten. Im direkten Vergleich mit modernsten Basisverfahren verbessert Wave-Former die Trefferquote von 541 TP3T auf 721 TP3T bei gleichbleibend hoher Genauigkeit von 851 TP3T.
Die zugehörigen Forschungsergebnisse mit dem Titel „Wave-Former: Through-Occlusion 3D Reconstruction via Wireless Shape Completion“ wurden als Preprint auf arXiv veröffentlicht.
Forschungshighlights:
* In diesem Beitrag wird erstmals ein Millimeterwellen-3D-Formvervollständigungsframework für verschiedene Objekte vorgestellt, das es ermöglicht, das Modell vollständig mit synthetischen Daten zu trainieren und gleichzeitig eine 3D-Rekonstruktion an realen Daten zu erreichen.
* Diese Methode verbessert die Trefferquote von 54% auf 72% im realen MITO-Datensatz und übertrifft damit bestehende Millimeterwellen-Rekonstruktionsmethoden.
* Bei Anwendung auf Millimeterwellen-Teilpunktwolken übertrifft es das native visuelle Vervollständigungsmodell, verbessert den Recall um 121 TP3T und erreicht eine Spitzengenauigkeit von 851 TP3T.
Papieradresse:
https://arxiv.org/abs/2511.14152
Folgen Sie unserem offiziellen WeChat-Konto und antworten Sie im Hintergrund mit „Millimeterwelle“, um das vollständige PDF zu erhalten.
Der 3D-Objektdatensatz bietet eine reichhaltige Stichprobe.
Zum Trainieren und Validieren von Wave-Former nutzte das Forschungsteam drei öffentlich verfügbare 3D-Objektdatensätze –
* OmniObject3D:Es enthält eine große Menge an vielfältigen Punktwolkendaten von Alltagsgegenständen, die Kategorien wie Möbel, Werkzeuge und Spielzeug abdecken.
* Toys4K-3D:Mit dem Fokus auf Spielzeug und kleinen Gegenständen erweitert es die Vielfalt der Formen und Materialeigenschaften.
* Objaverse Thingiverse-Teilmenge:Es bietet eine Open-Source-Plattform zur Erstellung von 3D-Modellen zur Generierung synthetischer Trainingsdaten.
Diese drei Datensätze enthalten insgesamt über 25.000 3D-Punktwolken.Es bietet eine umfangreiche Sammlung von Trainingsbeispielen für Wave-Former.
Für die Evaluierung in der Praxis verwendete das Forschungsteam den MITO-Datensatz, der 61 Objekte aus dem YCB-Datensatz enthält.Diese Objekte decken eine Vielzahl von Anwendungsbereichen ab, darunter Küchenutensilien, Werkzeuge, Lebensmittel und Spielzeug. Sie bestehen aus Materialien wie Holz, Metall, Pappe und Kunststoff und sind in einer Vielzahl komplexer Formen erhältlich.Dies umfasst scharfe Kanten, ebene und gekrümmte Oberflächen. An jedem Objekt wurden Millimeterwellenmessungen sowohl unter sichtbaren als auch unter vollständig verdeckten Bedingungen durchgeführt, wodurch die Generalisierungsfähigkeit des Modells gründlich geprüft werden konnte.
Hinweis: Der YCB-Datensatz, kurz für YCB Object and Model Set, ist ein klassischer und weit verbreiteter Standarddatensatz in den Bereichen Robotik und Computer Vision.
Erwähnenswert ist, dass das Training von Wave-Former vollständig auf synthetischen Daten basiert. Durch das auf physikalischer Wahrnehmung basierende Trainingsframework kann das Modell die Eigenschaften von Millimeterwellensignalen erlernen und somit in realen Messungen gute Ergebnisse erzielen. Dadurch werden die Trainingsschwierigkeiten vermieden, die durch die Knappheit realer Millimeterwellendaten entstehen.
Wave-Former: Trainiert mit synthetischen Daten, erreicht er die 3D-Rekonstruktion realer Daten.
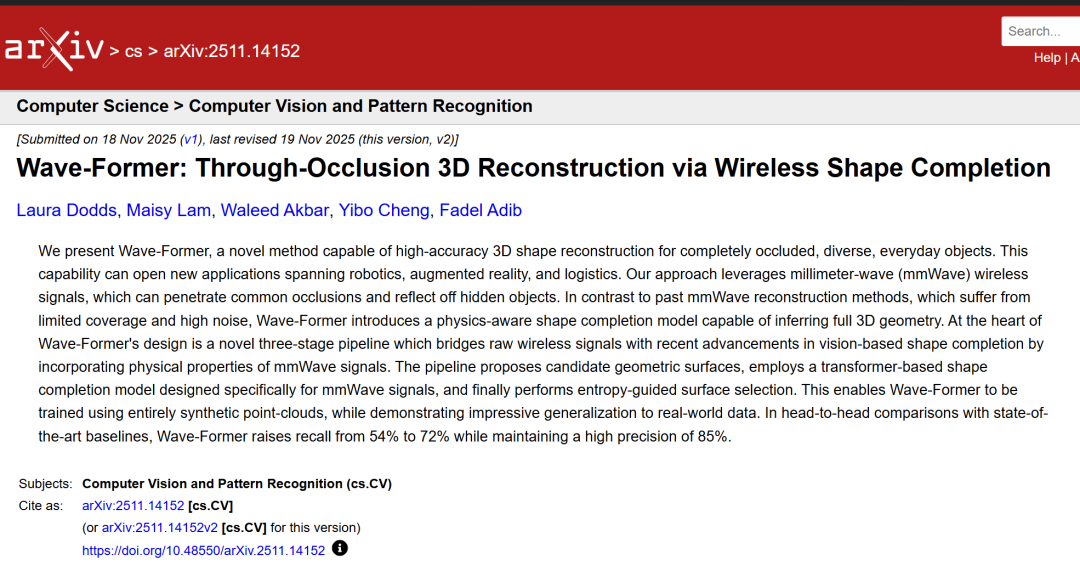
Das Kerndesign von Wave-Former besteht aus zwei Teilen: einem Trainingsprozess zur physikalischen Wahrnehmung und einem Prozess zur Schlussfolgerung aus der realen Welt.Diese Konstruktion berücksichtigt umfassend die Eigenschaften von Millimeterwellensignalen: spiegelnde Reflexion, hohes Rauschen, geringe räumliche Auflösung und ungleichmäßige Sichtbarkeit. Der Gesamtprozess ist in der folgenden Abbildung dargestellt:
Physikbasierte Trainingspipeline
Der physikbasierte Trainingsprozess von Wave-Former integriert physikalische Eigenschaften in das Training durch induktive Verzerrung der Spiegelreflexionswahrnehmung, reflexionsabhängige Sichtbarkeitsmuster und einen gemeinsamen Optimierungs- und Vervollständigungsrahmen, wodurch das Modell vollständig mit synthetischen Daten trainiert werden kann.
Die erste ist die induktive Verzerrung der Wahrnehmung spiegelnder Reflexionen.Bestehende visuelle Ergänzungsmodelle kodieren im Wesentlichen eine induktive Verzerrung, die mit sichtbarem Licht übereinstimmt. Diese Verzerrung ist jedoch mit Millimeterwellensignalen inkompatibel, da ihre „kameraähnlichen“ Teilbeobachtungen diffuse Reflexion und eine große Abdeckung voraussetzen. Um dieses Problem zu lösen, haben Forscher die induktive Verzerrung durch physikalisch konsistente Teilbeobachtungen neu definiert, um die spiegelnde Reflexion von Millimeterwellensignalen zu simulieren.
Die zweite ist die Sichtbarkeit, die von Reflexionen abhängt.Im Gegensatz zu optischen Sensoren weist die Sichtbarkeit im Millimeterwellenbereich eine starke Anisotropie auf. Das bedeutet, dass die messbare Reflexion vom Einfallswinkel und der Intensität der vom Objekt reflektierten Strahlung abhängt. Daher können selbst zwei Objekte mit identischer Geometrie aufgrund der Materialeigenschaften eine deutlich unterschiedliche Sichtbarkeit aufweisen.
Um dieses Verhalten zu modellieren,Die Forscher führten ein von der Reflexion abhängiges Sichtbarkeitsmuster ein.Die Dämpfungsflächenpunkte werden durch physikalische Gegebenheiten und Materialbeschränkungen bestimmt. Dies ersetzt die übliche Annahme einer isotropen Abdeckung und ermöglicht es dem Netzwerk zu erkennen, dass die Sichtbarkeit im Millimeterwellenbereich naturgemäß ungleichmäßig und winkelabhängig ist.
Der dritte Aspekt ist die kombinierte Rauschunterdrückung und Vervollständigung.Bestehende bildbasierte Modelle zur Formvervollständigung sind für die typischen Rausch- und Auflösungseigenschaften von Kameras oder LiDAR-Sensoren ausgelegt und gehen daher davon aus, dass die eingegebene partielle Punktwolke direkt mit den rekonstruierten Punkten zusammengefügt werden kann. Millimeterwellensignale weisen jedoch ein deutlich höheres Rauschen und eine geringere Auflösung auf, sodass bestehende Zusammenfügungsverfahren erhebliche Verzerrungen im endgültigen Rekonstruktionsergebnis verursachen.
Um dieses Problem zu lösen,Forscher haben eine gemeinsame Optimierungs- und Vervollständigungsmethode vorgeschlagen.Während des Trainings wird Rauschen eingeführt, um die Eigenschaften realer Millimeterwellensignale zu simulieren. Anschließend wird die Verlustfunktion so neu definiert, dass das Modell eine vollständige 3D-Form ausgeben kann (ohne die Eingabe zusammenzusetzen). Dadurch werden unzuverlässige Punkte neu interpretiert, anstatt sie einfach beizubehalten.
Das gesamte Trainingsframework basiert auf der Transformer-Encoder-Decoder-Architektur (PoinTr-Backbone), kombiniert mit einem physikalisch konsistenten Beobachtungsmodell und einem Entrauschungs- und Vervollständigungsziel.Dadurch kann das Modell mit vollständig synthetischen Daten trainiert werden und eine hochpräzise Rekonstruktion realer Millimeterwellensignale erreichen.
Inferenzprozess in der realen Welt
Der Realwelt-Inferenzprozess von Wave-Former nutzt eine dreistufige Pipeline, um vollständige 3D-Objekte aus realen Millimeterwellensignalen zu rekonstruieren.
Millimeterwellen-Oberflächenkandidatengenerierung (Phase eins)
Zunächst wandelten die Forscher die Rohdaten der Millimeterwellenmessungen in eine Reihe von Kandidaten-Teiloberflächen um und erfassten dabei präzise die in den Reflexionen enthaltenen geometrischen Informationen. Üblicherweise basiert die Schätzung von Millimeterwellen-Teilpunktwolken auf der Schwellenwertbildung des dreidimensionalen Leistungsbildes im Millimeterwellenbereich; dies führt jedoch zu einer großen Anzahl fehlerhafter Punkte. Die Forscher nutzten daher aktuelle Fortschritte in der Millimeterwellen-Bildgebung, um die Rohreflexionen in einen geometrisch konsistenten Teiloberflächenraum zu transformieren.
Physikalische Wahrnehmung, Formvervollständigung (Phase zwei)
Das trainierte Modell wird auf jede Kandidatenoberfläche angewendet, um eine Reihe physikalisch konsistenter vollständiger Kandidatenrekonstruktionen zu erzeugen.
Auswahl von Oberflächen mittels Entropiemessung (Phase 3)
Bei hohem Rauschen oder schwacher Reflexion werden die Kontinuität und Planarität der Punktwolke mittels lokaler Entropie gemessen, und die Kandidatenrekonstruktion mit der niedrigsten Entropie wird ausgewählt, um die endgültige hochauflösende 3D-Punktwolke zu erhalten.
Dieses Verfahren ermöglicht es Wave-Former, komplexe Verdeckungen, geringe Abdeckung und hohes Rauschen in realen Szenarien zu bewältigen und eine umfassende 3D-Rekonstruktion durchzuführen.
Wave-Former stellt eine deutliche Verbesserung gegenüber den bisherigen State-of-the-Art-Millimeterwellen-3D-Rekonstruktionsverfahren dar.
Zur Leistungsbewertung verglichen die Forscher Wave-Former mit vier hochmodernen Millimeterwellen-Rekonstruktionsverfahren:
* Rückprojektion: Eine klassische und weitverbreitete Millimeterwellen-Bildgebungsmethode, eine Volumenrekonstruktionsmethode, die auf grundlegenden Prinzipien basiert.
* mmNorm: Eine kürzlich vorgeschlagene, hochmoderne Millimeterwellen-3D-Rekonstruktionsmethode, die ebenfalls auf Grundprinzipien basiert, rekonstruiert die Objektoberfläche durch Schätzung von Oberflächennormalenvektoren.
* RMap: Eine hochmoderne, lernbasierte Millimeterwellen-Rekonstruktionsmethode, die ursprünglich für das Szenenverständnis entwickelt wurde.
* RMap (feinabgestimmte Version): RMap wurde anhand der gleichen Trainingsdaten wie Wave-Former für die Objektrekonstruktion feinabgestimmt.
Qualitative Leistung
Zunächst verglichen die Forscher Wave-Former anhand von Messungen aus der Praxis qualitativ mit vier Vergleichsmethoden. Die Abbildung unten zeigt isometrische Ansichten der realen RGB-Daten (nach der Segmentierung) und der Punktwolke mehrerer vollständig verdeckter Objekte sowie die Rekonstruktionsergebnisse der einzelnen Methoden.
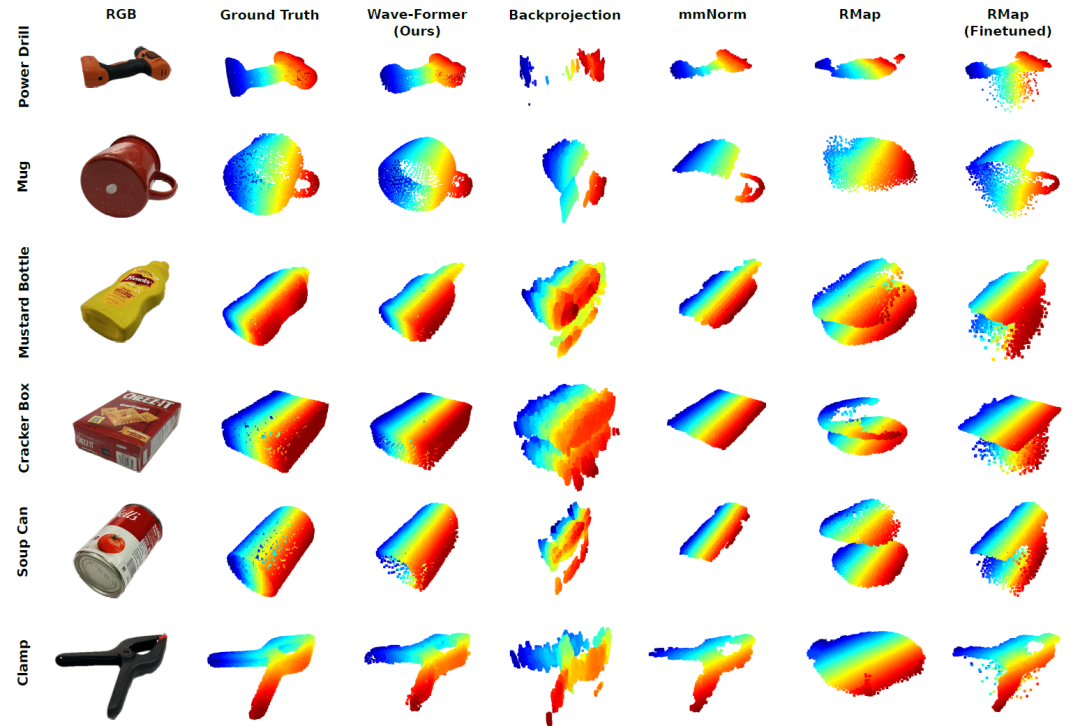
Visueller Vergleich von Millimeterwellen-3D-Rekonstruktionen vollständig verdeckter Objekte in der realen Welt
Offensichtlich,Wave-Former kann die vollständige Form eines Objekts stabil rekonstruieren, selbst komplexe Geometrien wie Bohrer oder Vorrichtungen.Im Gegensatz dazu weisen herkömmliche Methoden eine geringe Genauigkeit, eine begrenzte Abdeckung und ein hohes Rauschen auf und sind in manchen Fällen kaum in der Lage, die Geometrie von Objekten zu unterscheiden. Diese Ergebnisse belegen den signifikanten Fortschritt von Wave-Former gegenüber bisherigen hochmodernen Millimeterwellen-3D-Rekonstruktionsverfahren.
Quantitative Ergebnisse
Die folgende Tabelle zeigt die Leistung von Wave-Former im Vergleich zu allen Basislinien hinsichtlich mittlerer Chamfer-Distanz, F-Score, Präzision und Trefferquote:
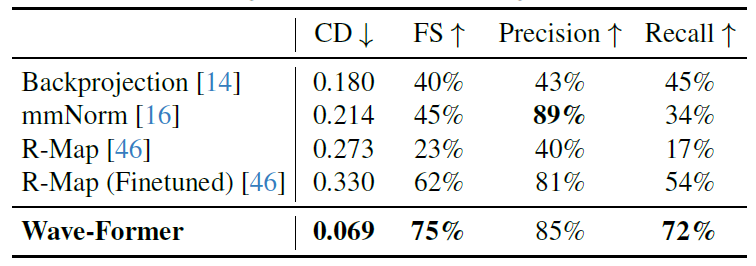
Es ist erwähnenswert, dassDie Trefferquote von Wave-Former wurde deutlich verbessert, von 54% in der besten Basisversion RMap (feinabgestimmte Version) auf 72%, während gleichzeitig eine hohe Genauigkeit von 85% beibehalten wurde.Darüber hinaus weist Wave-Former mit 0,069 den geringsten Chamfer-Abstand auf, verglichen mit dem optimalen Basiswert von 0,18. Dies belegt eindrucksvoll den Wert der vorgeschlagenen Methode für die hochpräzise 3D-Rekonstruktion vollständig verdeckter Objekte.
Im Vergleich zur visuellen Formvervollständigung
Die Forscher untersuchten außerdem, ob moderne native visuelle Formvervollständigungsmodelle eine hochpräzise 3D-Rekonstruktion im Millimeterwellenbereich ermöglichen können. Die folgende Tabelle vergleicht die Leistung von Wave-Former mit vier weiteren hochmodernen Modellen:
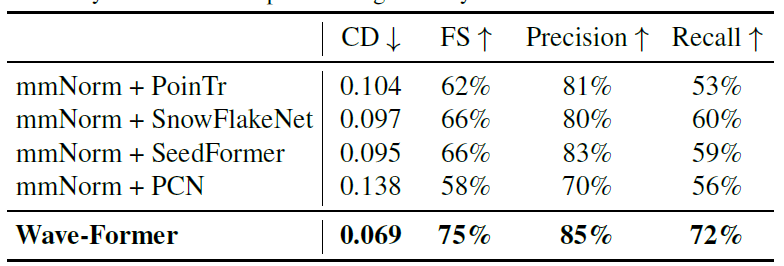
Wave-Former übertraf andere Modelle in allen Metriken und verbesserte die Trefferquote von 60% auf 72% bei gleichzeitig höchster Präzision von 85%.Dies verdeutlicht die Bedeutung der Einbeziehung physikalischer Eigenschaften in Formvervollständigungsmodelle.
Ablationsexperiment
Abschließend analysierten die Forscher auch den Beitrag jeder einzelnen Designkomponente des Wave-Formers zur Gesamtleistung. Die folgende Tabelle zeigt den durchschnittlichen Fasenabstand (CD), den CD-Wert des 75. Perzentils und die prozentuale Verbesserung des Wave-Formers im Vergleich zu drei verschiedenen Teilimplementierungsschemata:

Wenn die durch spiegelnde Reflexion wahrgenommene induktive Verzerrung und die reflexionsabhängige Sichtbarkeit (Modell A) entfernt werden, verschlechtert sich die Leistung erheblich: Der durchschnittliche Abstand der Fasen erhöht sich um 521 TP3T, und das 75. Perzentil erhöht sich um 671 TP3T.
Wird das gemeinsame Rekonstruktions- und Fertigstellungsmodul (Modell B) weiter entfernt, erhöht sich der durchschnittliche Fasenabstand um 10%.
Wird das entropiebewusste Oberflächenauswahlmodul (Modell C) wieder entfernt, erhöht sich der 75. Perzentilwert der CD um 19%.
Zusammenfassend zeigen diese Ergebnisse deutlich den Beitrag jeder einzelnen Komponente des Wave-Formers zur Gesamtleistung.
Technologische Erweiterung: Von der „Rekonstruktion von Objekten“ zur „Rekonstruktion des Raumes“
Wenn Wave-Former bewiesen hat, dass es mit Hilfe von generativer KI und Millimeterwellensignalen möglich ist, eine hochpräzise 3D-Rekonstruktion von „vollständig verdeckten Objekten“ zu erreichen,Eine weitere, parallel durchgeführte Studie des MIT-Teams geht noch einen Schritt weiter und dehnt diese Fähigkeit von einem einzelnen Objekt auf den gesamten Raum aus.
In dieser Studie konzentrieren sich die Forscher nicht mehr ausschließlich auf die Form der versteckten Objekte.Stattdessen nutzt es die Mehrwege-Reflexionen von Millimeterwellen, die vom menschlichen Körper bei Bewegungen in Innenräumen erzeugt werden, um die gesamte Innenraumumgebung zu rekonstruieren.Herkömmliche Methoden verwerfen solche komplexen Reflexionen typischerweise als Rauschen, doch diese Studie ergab, dass diese sogenannten „Geistersignale“ tatsächlich wichtige Hinweise auf die räumliche Struktur enthalten: Wenn das Signal mehrfach zwischen dem menschlichen Körper und Wänden und Möbeln reflektiert wird, kodieren die Veränderungen seines Weges selbst die geometrischen Informationen der Umgebung.
Das Problem besteht darin, dass diese Signale stark chaotisch sind und eine begrenzte Auflösung aufweisen, wodurch eine direkte Analyse mit herkömmlichen physikalischen Modellen nahezu unmöglich ist. Um dem entgegenzuwirken, setzte das Forschungsteam generative KI ein, um diese qualitativ minderwertigen und spärlichen anfänglichen Rekonstruktionsergebnisse zu verstehen und zu vervollständigen. Dadurch kann das Modell die statistischen Muster der Mehrwegeausbreitungsreflexionen erlernen und schrittweise die vollständige räumliche Anordnung ableiten.
Umfangreiche Experimente zeigen, dass RISE im Vergleich zu bestehenden Verfahren zur Layoutrekonstruktion den Fasenabstand um 601 TP3T (bis auf 16 cm) reduziert und erstmals eine millimeterwellenbasierte Zielerkennung mit einem IoU von 581 TP3T ermöglicht. Diese Ergebnisse belegen, dass RISE mit einem einzigen statischen Radar eine neue Grundlage für die geometrische Wahrnehmung und das datenschutzkonforme Verständnis von Innenraumszenen schafft.
Titel des Papers: RISE: Single Static Radar-based Indoor Scene Understanding
Link zum Artikel:https://arxiv.org/abs/2511.14019
Aus einer umfassenderen Perspektive zeigen diese beiden Studien gemeinsam einen klaren technologischen Weg auf: KI dient nicht mehr nur der Verbesserung der Sensorgenauigkeit, sondern beginnt, Informationslücken selbst zu kompensieren. Ob Wave-Former verdeckte Objekte ergänzt oder RISE Innenräume erfasst – im Kern nutzen sie generative Modelle, um unvollständige oder sogar stark verzerrte Eingaben in eine strukturell vollständige und physikalisch plausible dreidimensionale Welt zu transformieren. Zukünftige Wahrnehmungssysteme hängen somit möglicherweise nicht mehr davon ab, „wie viel sichtbar ist“, sondern vielmehr davon, „wie viel erschlossen werden kann“. Im Zuge dieser Entwicklung werden Bereiche wie Robotik, Smart Homes und sogar Augmented Reality voraussichtlich eine völlig neue Fähigkeit erlangen: die Rekonstruktion der Realität aus dem Unsichtbaren.
Quellen:
1.https://arxiv.org/abs/2511.14152
2.https://news.mit.edu/2026/generative-ai-improves-wireless-vision-system-sees-through-obstructions-0319
3.https://arxiv.org/abs/2511.14019








