Command Palette
Search for a command to run...
Auf Basis Klinischer Daten Aus 11.647 Fällen Ist Es Einem Französischen Team Erstmals Gelungen, Mithilfe Von Maschinellem Lernen Das Doppelte Mortalitätsrisiko Bei Lebertransplantationen Aufgrund Von HCC Genau vorherzusagen.
Leberkrebs gilt aufgrund seiner heimtückischen Frühstadien und seines raschen Fortschreitens seit Langem als „König der Krebserkrankungen“. Das hepatozelluläre Karzinom (HCC) ist die häufigste Form von Leberkrebs und macht 701–901 aller primären Leberkarzinome aus. Patienten benötigen in der Regel im Frühstadium eine Lebertransplantation als radikale Behandlung, die für viele HCC-Patienten die letzte Hoffnung auf Leben darstellt.
Die extreme Knappheit an Spenderorganen macht diese Hoffnung auf Leben jedoch umso wertvoller. Erschwerend kommt hinzu, dass Kandidaten für eine Lebertransplantation bei hepatozellulärem Karzinom (HCC) ständig der doppelten Bedrohung durch Leberversagen und Tumorprogression ausgesetzt sind; diese beiden Faktoren sind eng miteinander verknüpft und beeinflussen sich gegenseitig, wodurch das Sterberisiko während der Wartezeit erheblich steigt. DaherDie genaue Einschätzung des Sterberisikos während der Wartezeit für Kandidaten für eine Lebertransplantation bei hepatozellulärem Karzinom ist nicht nur der Schlüssel zur Optimierung der Prioritätensetzung auf der Warteliste für Lebertransplantationen und zur fairen Zuteilung der knappen Spenderorgane, sondern auch eine zentrale Herausforderung, um jeden Patienten effizient zu retten und die hart erkämpfte Hoffnung auf Leben zu sichern.
Bisher wurden traditionelle Risikobewertungsmethoden wie Child-Pugh, Albumin-Bilirubin (ALBI) und MELD (Model for End-Stage Liver Disease) häufig zur Beurteilung des Lebererkrankungsrisikos eingesetzt. Angesichts der komplexen Situation von Patienten mit hepatozellulärem Karzinom (HCC) zeigten diese Methoden jedoch erhebliche Schwächen: Entweder konzentrierten sie sich auf die Beurteilung der Leberfunktion und des Zirrhosegrades oder ausschließlich auf die Vorhersage des Tumorwachstums und berücksichtigten somit nicht beide Risiken gleichzeitig. Auch die Entwicklung umfassender Scoring-Systeme wie HALT-HCC und des Mehta-Modells, die beide Risiken gleichzeitig einbeziehen können, …Aufgrund der Beschränkungen linearer Modelle, fester variabler Gewichte und statischer Messungen zu einem einzigen Zeitpunkt ist es unmöglich, die Wechselwirkungen zwischen Einflussfaktoren und die Risikoveränderungen im dynamischen Verlauf der Krankheit zu erfassen, was eine genaue individuelle Risikobewertung erschwert.
Als Antwort auf dieses klinische Problem,Ein Forschungsteam von Telecom Sud-Paris und der Universität Paris-Saclay in Frankreich hat ein Framework für maschinelles Lernen vorgeschlagen, das Ensemble Learning (EL) mit der Schapel Additive exPlanations (SHAP)-Analyse integriert.Diese Studie bietet einen neuen Ansatz zur Beurteilung des Mortalitätsrisikos bei Lebertransplantationskandidaten mit hepatozellulärem Karzinom (HCC). Basierend auf klinischen Daten von 11.647 Patienten wurden drei Ensemble-Modelle verglichen: Random Forest (RF), XGBoost und LightGBM. Durch die Einbettung von SHAP-Werten in den niedrigdimensionalen UMAP-Raum (Uniform Manifold Approximation and Projection) und die Kombination mit dem K-Medoids-Algorithmus für überwachtes Clustering konnte gezeigt werden, dass Leberfunktionsstörung und Tumorprogression die beiden Hauptrisikofaktoren für den Tod bei HCC-Patienten darstellen.
Diese Studie schließt insbesondere eine Lücke in bisherigen Modellen des maschinellen Lernens zur genauen Beurteilung von Kandidaten für eine Lebertransplantation bei hepatozellulärem Karzinom, insbesondere in Studien mit doppelten Risiken.Diese Studie ermöglicht eine präzise Vorhersage und klinische Interpretierbarkeit der Mortalität während der dreimonatigen Wartezeit für Kandidaten für eine Lebertransplantation bei HCC und bietet damit ein neues Instrument für die klinische Entscheidungsfindung und Risikostratifizierung bei Lebertransplantationen für HCC-Patienten.
Die Ergebnisse mit dem Titel „Erklärbare Mortalitätsvorhersage für Lebertransplantationskandidaten mit hepatozellulärem Karzinom: Ein überwachtes Clustering-Verfahren“ wurden in Health Data Science veröffentlicht.
Forschungshighlights:
* Diese Studie ist die erste umfassende Studie, die maschinelle Lernmodelle verwendet, um das Mortalitätsrisiko von HCC-Lebertransplantationskandidaten auf der Warteliste eingehend zu analysieren.
* Mithilfe von SHAP + UMAP + K-Medoiden wurden sieben klinisch erklärbare Risikogruppen stratifiziert, um die Kernfaktoren des dualen Risikos zu identifizieren.
* Der neuartige Risikoscore ELM-HCC, der auf der Grundlage des SHAP-Screenings von 8 Schlüsselvariablen erstellt wurde, weist eine deutlich höhere Vorhersagegenauigkeit auf als herkömmliche Scores.
* Diese Studie ist die erste, die wichtige dynamische Variablen (wie AFP_DIFF) in die Risikobewertung von Kandidaten für eine Lebertransplantation bei HCC einbezieht und ihre Rolle als wichtiger Prädiktor für die Mortalität während der Wartezeit für HCC-Patienten verdeutlicht.
Papieradresse:
https://spj.science.org/doi/10.34133/hds.0295
Folgen Sie unserem offiziellen WeChat-Account und antworten Sie im Hintergrund mit „Lebertransplantation“, um das vollständige PDF zu erhalten.
Weitere hochaktuelle KI-Veröffentlichungen ansehen:
Datensatz: Strategie für große Stichproben + Einführung dynamischer Variablen
Um Störfaktoren zu reduzieren,Die Studie nutzte eine Strategie mit großen Stichproben auf Basis öffentlich zugänglicher Datenbankdaten.
Die Studiendaten stammen insbesondere aus den Standard Transplant Analysis and Research (STAR)-Dateien des Organ Procurement and Transplantation Network (OPTN) und des United Network for Organ Sharing (UNOS) und umfassen erwachsene HCC-Patienten, die keine Mehrfachorgantransplantation erhielten und zwischen dem 27. Februar 2002 und dem 30. September 2023 registriert wurden.
Ziel dieser Studie war es, die Mortalität während der dreimonatigen Wartezeit auf eine Lebertransplantation bei Patienten mit hepatozellulärem Karzinom (HCC) vorherzusagen. Daher teilte das Forschungsteam die Studienpopulation für die Analyse in zwei Gruppen auf.Patienten, die länger als drei Monate auf der Warteliste stehen, werden als „auf der Warteliste“ bezeichnet; Patienten, die innerhalb von drei Monaten auf der Warteliste sterben oder deren Zustand sich verschlechtert und sie dadurch nicht mehr transplantiert werden können, werden als „Wartelistenmortalität“ bezeichnet.Finale,Die gesamte Studienkohorte umfasste 11.647 Patienten.Von diesen befanden sich 11.199 Patienten auf der Warteliste und 448 Patienten auf der Warteliste für Todesfälle. Die Daten umfassten klinische, laborchemische und krankheitsbezogene multidimensionale Variablen.
Um die dynamischen Merkmale des Gesundheitszustands der Patienten zu erfassen, berechnete das Forschungsteam in der Datenvorverarbeitungsphase die kontinuierliche Messdifferenz (DIFF) von sechs wichtigen Laborvariablen, die in die traditionelle Bewertung einbezogen werden, darunter Serum-Natrium, Kreatinin, Albumin, Bilirubin, Alpha-Fetoprotein (AFP) und die International Normalized Ratio (INR), um den dynamischen Verlauf der Veränderungen des Gesundheitszustands der Patienten zu erfassen.Dadurch erhöht sich die Gesamtzahl der Merkmale auf 31 (25 ursprüngliche statische Variablen + 6 neu hinzugefügte dynamische Variablen).
Zur Behandlung fehlender Werte wurden numerische Variablen (Fehlraten < 7%) durch den Klassenmittelwert ersetzt; bei kategorialen Variablen (Fehlraten < 0,1%) wurden die Datensätze, die fehlende Werte enthielten, direkt gelöscht.
Modellarchitektur: Durchgängig integrierter Prozess + Vergleich mehrerer Ensemble-Lernmodelle
Um die zuverlässige Genauigkeit und Interpretierbarkeit der Mortalitätsprognose während der dreimonatigen Wartezeit für Kandidaten für eine Lebertransplantation bei hepatozellulärem Karzinom zu gewährleisten,Das Forschungsteam entwickelte einen durchgängig integrierten Prozess, der Ensemble-Lernen, SHAP-Interpretierbarkeitsanalyse, UMAP-Dimensionsreduktion und K-Medoids-überwachtes Clustering kombiniert.Wie in der folgenden Abbildung dargestellt:
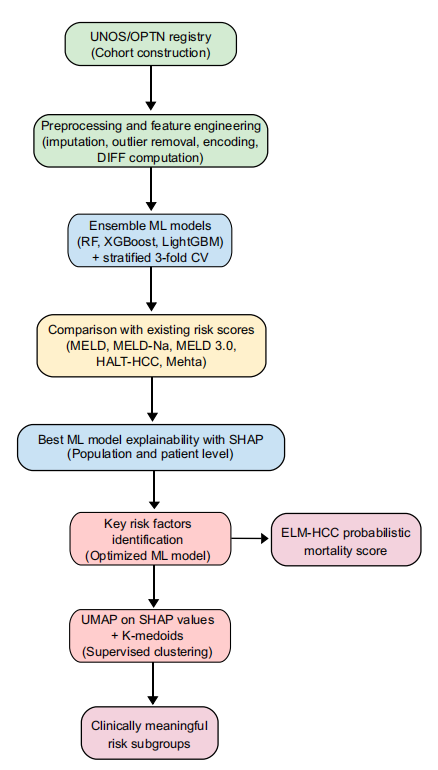
Erstens verwendet das Kernmodell ein Ensemble-Lernbaummodell.Diese Modelltypen eignen sich besonders gut für die Verarbeitung tabellarischer und heterogener Daten. Um die Leistungsfähigkeit dieser Modelle weiter zu vergleichen, wurden drei grundlegende Ensemble-Lernmodelle verwendet: Random Forest, XGBoost und LightGBM. Die Experimente wurden in zwei Trainingsszenarien durchgeführt: Im ersten Szenario wurden nur 25 statische Variablen verwendet, im zweiten 31 kombinierte statische und dynamische Variablen.
Zweitens dient die Interpretierbarkeit dazu, eine wissenschaftliche und nachvollziehbare Interpretation der vorhergesagten Ergebnisse zu ermöglichen und damit die Grundlage für klinische Entscheidungen zu verbessern.Zu diesem Zweck integrierte das Forschungsteam eine SHAP-Interpretierbarkeitsanalyse in das Rahmenwerk, um wichtige Risikofaktoren zu identifizieren und Modellvorhersagen aufzuzeigen.
Zur globalen Interpretation quantifiziert die Berechnung der SHAP-Werte den Beitrag jedes Merkmals zu den Vorhersageergebnissen des Modells, identifiziert zentrale Risikofaktoren für die Mortalitätsprognose und verdeutlicht die Korrelation zwischen Merkmalen und Mortalitätsrisiko. Zur lokalen Interpretation können SHAP-Übersichtsdiagramme und SHAP-Kraftdiagramme den spezifischen Einfluss einzelner Merkmalswerte auf die Vorhersageergebnisse sowie die Verteilung der Merkmalsbeiträge für jeden Patienten darstellen. Darüber hinaus liefert dieser Schritt einen SHAP-Wert-Merkmalssatz für die nachfolgende Clusteranalyse, der die Originaldaten ersetzt und die klinische Interpretierbarkeit des Clusterings verbessert.
Um schließlich eine präzisere Risikostratifizierung für Patienten zu erreichen, verlagerte sich der Fokus von der Vorhersage auf Bevölkerungsebene hin zur Analyse von Untergruppen.Der Forschungsprozess umfasste die Dimensionsreduktionsmethode UMAP und die überwachten Clustering-Methoden K-Medoids.Zunächst werden die vorhergesagten SHAP-Werte in den dimensionsreduzierten UMAP-Raum eingebettet. Anschließend wird der K-Medoids-Algorithmus verwendet, um die im dreidimensionalen UMAP-Raum eingebetteten SHAP-Werte zu clustern und so potenzielle Patientensubgruppen mit unterschiedlichen klinischen Merkmalen zu identifizieren. Dieses Verfahren wird als „überwachtes Clustering“ bezeichnet, da das Clustering auf den SHAP-Werten und nicht auf den Originaldaten basiert.
Die optimale Anzahl an Clustern wurde zunächst durch ein Screening mithilfe quantitativer Indikatoren wie dem Silhouette-Koeffizienten und dem Davies-Bouldin-Index und anschließend durch eine klinische Validierung der Clustercharakteristika mittels SHAP-Analyse ermittelt. Letztendlich wurde die optimale Anzahl an Clustern auf 7 festgelegt.
Experimentelle Ergebnisse: Das neue Modell wurde unter Verwendung von 8 traditionellen Bewertungsmethoden als Vergleich und des optimalen Merkmalsatzes trainiert.
Leistungsvergleich der Risikobewertung
Die Studie vergleicht die Leistungsfähigkeit des vorgeschlagenen Rahmens mit acht traditionellen Risikobewertungsmethoden, darunter ALBI, Child-Pugh, AFP, Hazard associated with LT for HCC (HALT-HCC), Mehta-Modell, MELD und seine beiden Varianten MELD-Na und MELD 3.0.
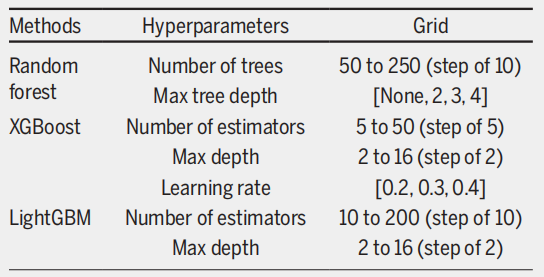
Aufgrund des starken Klassenungleichgewichts im Datensatz wurde die Mehrheitsgruppe (auf der Warteliste) verkleinert, um 30 Teilmengen ähnlicher Größe wie die Minderheitsgruppe (Todesfälle während der Wartezeit) zu generieren. Für jede balancierte Teilmenge wurde eine dreifache Kreuzvalidierung durchgeführt, um sicherzustellen, dass alle Beobachtungen desselben Patienten entweder dem Trainings- oder dem Testdatensatz zugeordnet wurden. Die optimalen Hyperparameter-Konfigurationen für die drei Ensemble-Modelle wurden anschließend mittels Gittersuche ermittelt, wie in der folgenden Abbildung dargestellt.
Die Ergebnisse zeigen, dassIn traditionellen Bewertungssystemen schneidet das Mehta-Modell mit einem AUROC von 0,782 am besten ab, gefolgt vom HALT-HCC mit einem AUROC von 0,763.Noch wichtiger ist jedoch, dass diese beiden Modelle ein ausgewogeneres Verhältnis von Sensitivität und Spezifität aufweisen. Obwohl MELD 3.0 die Basismodelle MELD und MELD-Na übertrifft, weist es ein Ungleichgewicht zwischen Sensitivität und Spezifität auf.
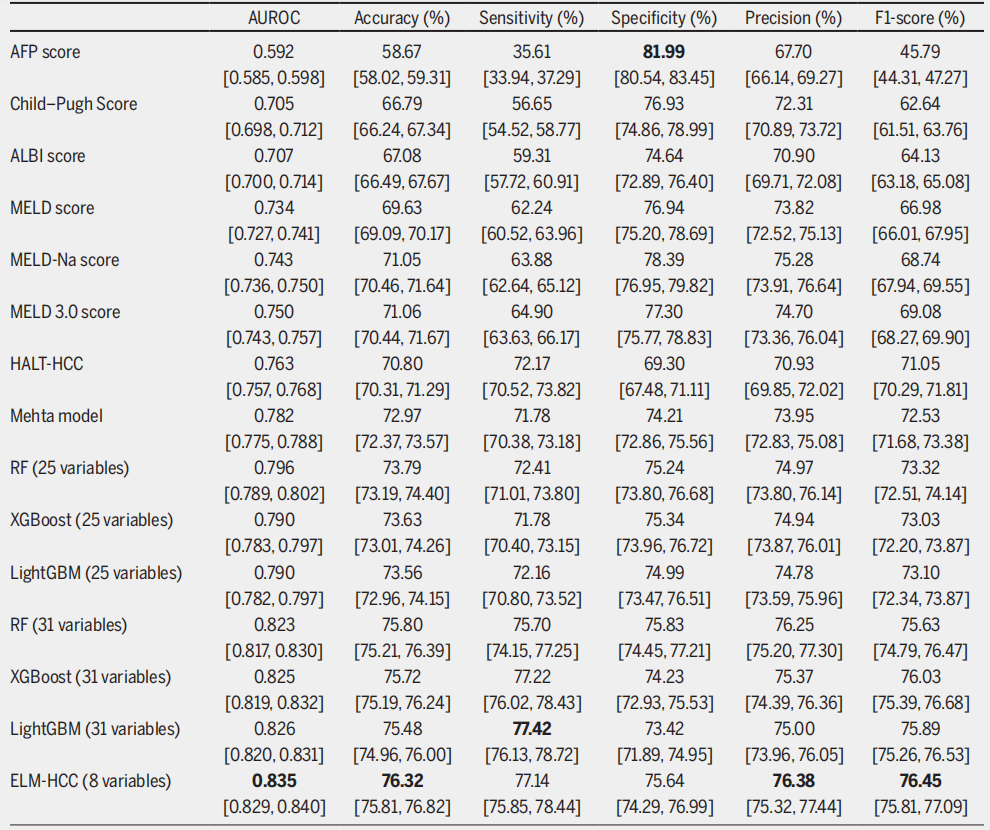
Als das Experiment auf ein Ensemble-Lernverfahren ausgeweitet wurde, übertraf die Genauigkeit aller mit 25 statischen Variablen trainierten Modelle die traditioneller Bewertungssysteme. RF erzielte mit einem AUROC von 0,796 die besten Ergebnisse; auch die Sensitivität (72,411 TP³T) und Spezifität (75,241 TP³T) waren gut ausbalanciert. Nach der Einführung von 31 kombinierten dynamischen und statischen Variablen erreichten alle Ensemble-Lernmodelle eine noch bessere Leistung.LightGBM erreichte einen AUROC-Wert von 0,826 und die höchste Sensitivität von 77,42% und ist damit das effektivste Modell zur Identifizierung von Hochrisikopatienten.
Analyse der Fähigkeit zur Identifizierung wichtiger Risikofaktoren
Nach dem Training der Modelle werden für die Leistungsbewertung nur die relevantesten Merkmale herangezogen. Zu diesem Zweck nutzte das Forschungsteam zwei Methoden zur Bewertung der Merkmalswichtigkeit – Gain Importance und SHAP Global Importance –, um die wichtigsten Merkmale für das leistungsstärkste LightGBM-Modell zu ermitteln.
Basierend auf dem LightGBM-Modell (dem leistungsstärksten Modell) erzielen die mit Hilfe der SHAP-Global-Importance ausgewählten acht wichtigsten Merkmale eine optimale Modellperformance.Mit einem AUROC-Wert von 0,835, einer Sensitivität von 77,141 TP3T und einer Spezifität von 75,641 TP3T übertraf es nicht nur die Ergebnisse des Gain-Importance-Screenings (AUROC-Wert von 0,812 mit 8 Merkmalen und maximal 0,828 mit 12 Merkmalen), sondern auch die Leistung von LightGBM mit allen 31 Variablen (AUROC-Wert von 0,826). Daher wurde es vom Forschungsteam als optimaler Merkmalsatz ausgewählt.
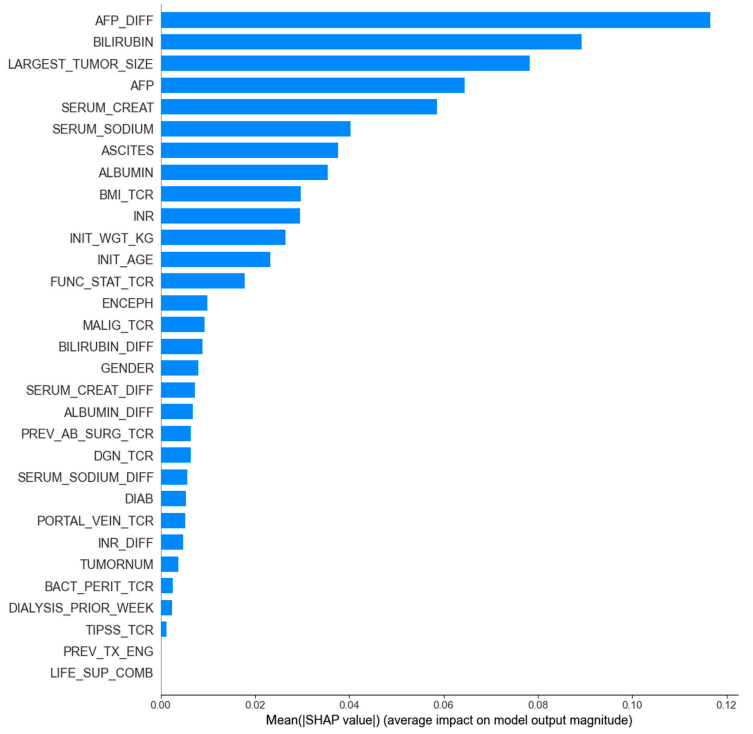
Letztendlich identifizierte und entwickelte die Studie einen probabilistischen Mortalitäts-Score für HCC-Patienten, genannt ELM-HCC, basierend auf dem mit dem optimalen Merkmalsatz trainierten LightGBM-Modell. Erwähnenswert ist, dass…LightGBM übertraf den AUROC-Wert beim vereinfachten Variablensatz im Vergleich zum vollständigen 31-Variablen-Satz, was zeigt, dass die ausgewählten 8 Variablen eine stärkere Vorhersagekraft besitzen.Gleichzeitig unterstreicht das Auftreten von AFP_DIFF in den wichtigsten relevanten Merkmalen die Bedeutung der Einbeziehung dynamischer Informationen.
Risikostratifizierung und Subgruppenanalyse
Die Studie identifizierte sieben Patientensubgruppen mit unterschiedlichen klinischen Merkmalen und Risikostufen anhand eines überwachten Clusterings unter Verwendung von SHAP-Werten. Abbildung B unten zeigt deutlich die stratifizierte Mortalitätsanalyse mit stufenweise ansteigenden Mortalitätswahrscheinlichkeiten von Cluster 1 bis Cluster 7.
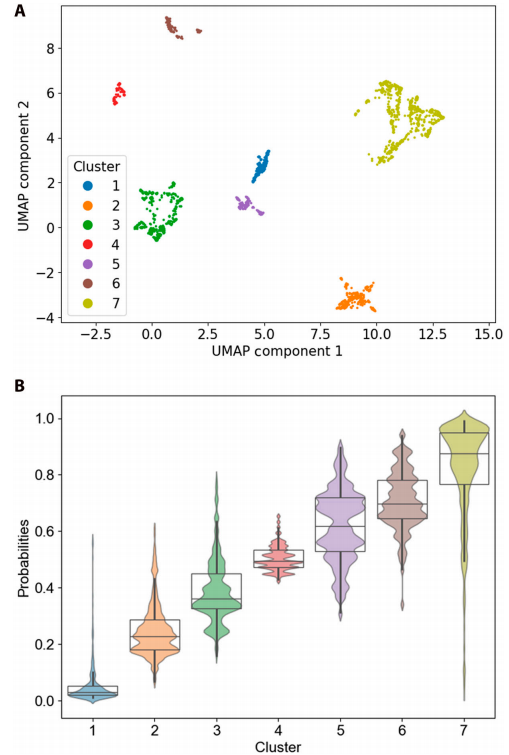
B stellt den Boxplot und den Populationsplot der Sterbewahrscheinlichkeiten für 7 gruppierte Beobachtungen dar.
Eine weiterführende Analyse mittels Kruskal-Wallis-Test ergab Unterschiede in den Variablen zwischen den verschiedenen Clustern. Wie die SHAP-Grafik zeigt, stieg die Sterbewahrscheinlichkeit von Cluster 1 bis Cluster 7 kontinuierlich an; beispielsweise erhöhte sich die Sterbewahrscheinlichkeit für einen repräsentativen Patienten von 0,03 auf 0,98.Dieser Trend stimmt mit den in den Boxplots beobachteten Rangfolgen überein und unterstreicht die Effektivität der Clustering-Methode.
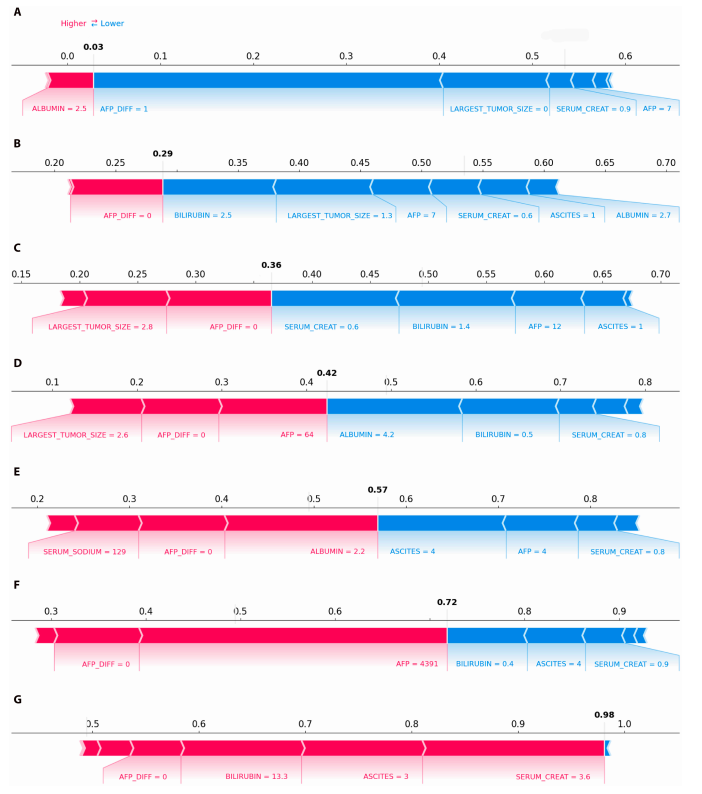
Darüber hinaus ergab die Subgruppenanalyse eindeutig zwei Hauptursachen für das hohe Mortalitätsrisiko: schweres Leberversagen (gekennzeichnet durch hohe Bilirubin- und Kreatininwerte sowie mäßigen Aszites, die alle positiven SHAP-Werten entsprechen und das Sterberisiko signifikant erhöhen) und aktives Tumorwachstum (gekennzeichnet durch hohe AFP-Werte).
Zusammenfassend lässt sich sagen, dass das in dieser Studie vorgestellte maschinelle Lernframework ELM-HCC, basierend auf LightGBM und der SHAP-Interpretierbarkeitsanalyse, eine deutlich bessere Leistung als herkömmliche Scoring-Systeme bei der Vorhersage des Sterberisikos während der dreimonatigen Wartezeit für Lebertransplantationskandidaten mit hepatozellulärem Karzinom (HCC) aufweist. Gleichzeitig identifiziert es durch überwachtes Clustering Patientensubgruppen mit unterschiedlichen Risikomerkmalen und bietet somit ein präziseres und besser interpretierbares Risikobewertungsinstrument für die klinische Entscheidungsfindung.
Innovative Methoden zur Risikobewertung von Lebertransplantationskandidaten; ein umfassender Ansatz schließt eine Forschungslücke.
Wie bereits erwähnt, entwickelt sich Leberkrebs zu einer globalen Herausforderung für die öffentliche Gesundheit. Angesichts der zunehmend schwerwiegenden Krankheitsverläufe und des steigenden medizinischen Bedarfs ist ein wissenschaftlich fundierter und sinnvoller Plan für die Wartelisten von Lebertransplantationskandidaten unerlässlich. Bereits 2002 wurde das MELD-Score-Modell (Model for End-Stage Liver Disease) zur Priorisierung von Lebertransplantationskandidaten eingesetzt. Trotz mehrerer Überarbeitungen kann die MELD-basierte Priorisierung jedoch noch immer nicht allen Kandidaten gerecht werden.
Maschinelles Lernen, mit seiner Fähigkeit, hochdimensionale und multimodale Daten zu verarbeiten, hat sich mittlerweile zur besten Lösung für die Vorhersage des Mortalitätsrisikos von Organtransplantationskandidaten entwickelt.
Maschinelle Lernmodelle wurden bereits zur Vorhersage der Sterblichkeitsrate nach Lebertransplantationen eingesetzt. Beispielsweise schlug ein gemeinsames Team des MIT, der UC San Francisco und der University of Texas OPOM vor, ein auf optimalen Entscheidungsbäumen (Optimal Classification Trees, OCTs) basierendes Modell zur Optimierung der Sterblichkeitsratenvorhersage.Auf Basis dieses Modells zur Leberallokation kann die Zahl der Todesfälle pro Jahr im Vergleich zum MELD-Modell um etwa 418 reduziert werden, was zu einer signifikanten Verringerung der Zahl der Todesfälle/Entfernungen in allen UNOS-Regionen und Schweregraden der Erkrankung führt.Darüber hinaus passte das Modell auch die Anzahl der Lebern an, die Patienten mit und ohne HCC zugeteilt wurden, was die Lebertransplantationszuteilung deutlich optimierte und die Sterblichkeit der Kandidaten verringerte.
Titel der Dissertation: Entwicklung und Validierung einer optimierten Mortalitätsprognose für Kandidaten auf der Warteliste für eine Lebertransplantation
Papieradresse:
https://www.sciencedirect.com/science/article/pii/S1600613522090335
Obwohl OPOM gute Ergebnisse lieferte, basiert dieses Modell auf einer gemischten Kohorte von Patienten mit und ohne hepatozellulärem Karzinom (HCC) und berücksichtigt nicht spezifisch die beiden Risiken von Leberversagen und Tumorprogression bei HCC-Patienten. ELM-HCC schließt diese Lücke zweifellos.
Diese Studie verbessert und erweitert nicht nur frühere Forschungsergebnisse, sondern schließt – wie die Autoren selbst betonen – vor allem eine Forschungslücke. Durch die erstmalige, interpretierbare und präzise Vorhersage der Mortalität während der dreimonatigen Wartezeit für Lebertransplantationskandidaten mit hepatozellulärem Karzinom (HCC) bietet sie einen neuen Ansatz für maschinelles Lernen in Kombination mit der Risikobewertung von Organtransplantationskandidaten.
Quellen:
1. Ein Forschungsteam von Telecom Sud-Paris und der Universität Paris-Saclay in Frankreich hat ein Framework für maschinelles Lernen vorgeschlagen, das Ensemble-Lernen mit der SHAP-Analyse (SHAple Additive exPlanations) integriert und damit eine neue Lösung zur Beurteilung des Mortalitätsrisikos von Kandidaten für eine Lebertransplantation bei hepatozellulärem Karzinom (HCC) bietet.
2.https://www.sciencedirect.com/science/article/pii/S1600613522090335








