Command Palette
Search for a command to run...
Nachdem Innerhalb Von Drei Tagen 100 Millionen Datenpunkte Des Hubble-Weltraumteleskops Ausgewertet Wurden, Schlug Die Europäische Weltraumorganisation AnomalyMatch Vor Und Entdeckte Dabei Über Tausend Anomale Himmelsobjekte.

Aktuell treiben großflächige, mehrbandige Himmelsdurchmusterungen mit großem Sichtfeld und hoher Bildtiefe die Astronomie in ein beispielloses datenintensives Zeitalter. Mit der Inbetriebnahme von Weltraumteleskopen der nächsten Generation wie dem Euclid-Weltraumteleskop, dem Rubin-Observatorium und dem Roman-Weltraumteleskop wird das Universum systematisch in einem noch nie dagewesenen Umfang und mit noch nie dagewesener Präzision kartiert. Diese Beobachtungen werden voraussichtlich Milliarden von Himmelsbildern und spektroskopischen Daten liefern – eines ihrer zentralen wissenschaftlichen Potenziale…Das heißt, die seltenen Himmelskörper mit besonderem astrophysikalischem Wert systematisch zu entdecken und zu identifizieren.Beispiele hierfür sind starke Gravitationslinsen, verschmelzende Galaxien, Quallengalaxien und protoplanetare Scheiben mit Kantenorientierung.
Diese seltenen Himmelsobjekte, oft als „astrophysikalische Anomalien“ bezeichnet, spielen eine entscheidende Rolle bei der Überprüfung von Galaxienentwicklungsmodellen, Gravitationstheorien und kosmologischen Parametern. Ihre Entdeckung beruhte jedoch lange Zeit hauptsächlich auf zufälligen visuellen Beobachtungen durch Forscher oder manuellen Untersuchungen im Rahmen von Bürgerwissenschaftsprojekten.Diese Methoden sind nicht nur höchst subjektiv und ineffizient, sondern lassen sich auch nur schwer an die massiven Datenmengen anpassen, die in Kürze auftauchen werden.
gleichzeitig,Traditionelle überwachte maschinelle Lernverfahren stehen vor grundlegenden Herausforderungen aufgrund der extrem begrenzten Anzahl von gekennzeichneten Beispielen seltener Himmelsobjekte und des extremen Ungleichgewichts der Datenkategorien.Um diesen Engpass zu beheben, hat sich die Forschung zunehmend auf unüberwachte oder schwach überwachte Verfahren zur Anomalieerkennung verlagert. Diese Methoden definieren keine spezifischen Zielkategorien vor, sondern lernen mithilfe von Algorithmen die Gesamtstruktur oder Verteilung der Daten selbst und identifizieren so automatisch Ausreißer, die deutlich von der „normalen“ Gruppe abweichen. Beispielsweise haben Werkzeuge, die auf Algorithmen wie Isolation Forests und Local Anomaly Factors basieren, oder Techniken, die Repräsentationsräume durch selbstüberwachtes Lernen konstruieren und anschließend Ähnlichkeitssuchen durchführen, ihre Effektivität bei Aufgaben wie dem Screening nach starker Gravitationslinsenwirkung in großflächigen Himmelsdurchmusterungsdaten unter Beweis gestellt.
Rein unüberwachte Verfahren können jedoch eine große Anzahl von „Rauschen“-Anomalien erzeugen, die für astrophysikalische Zwecke irrelevant sind. Um diesen Nachteil auszugleichen,Ein Forschungsteam des Europäischen Weltraumastronomiezentrums (ESAC), einer Abteilung der Europäischen Weltraumorganisation (ESA), hat eine neue Methode namens AnomalyMatch vorgeschlagen und angewendet.Die Erkennung seltener Himmelsobjekte stellt ein extrem unausgewogenes, semi-überwachtes binäres Klassifizierungsproblem dar, das eng mit aktiven Lernschleifen verknüpft ist. Sie kann mit nur wenigen, weniger als zehn markierten Anomalien begonnen werden. Gleichzeitig nutzt sie den Wert großer Mengen ungelabelter Daten durch semi-überwachte Lernverfahren wie Pseudo-Labels und Konsistenzregularisierung. Darüber hinaus wird im gesamten Prozess ein Expertenverifizierungsmechanismus eingeführt, wodurch die Erkennungsleistung durch die umfassende Nutzung ungelabelter Daten und Expertenwissens schrittweise verbessert wird.
Die zugehörigen Forschungsergebnisse mit dem Titel „Identifizierung astrophysikalischer Anomalien in 99,6 Millionen Quellausschnitten aus dem Hubble-Archiv mithilfe von AnomalyMatch“ wurden in Astronomy & Astrophysics veröffentlicht.
Forschungshighlights:
* Mit AnomalyMatch wurde die erste systematische Suche nach anomalen Himmelsobjekten im gesamten Hubble Heritage Archive (ca. 100 Millionen Bildausschnitte) durchgeführt.
* Das System hat einen Katalog neu entdeckter astrophysikalischer Anomalien veröffentlicht, der die Stichprobenbibliothek seltener Phänomene erheblich erweitert. Darunter befinden sich 417 neue Galaxienverschmelzungen, 138 Kandidaten für Gravitationslinseneffekte, 18 Quallengalaxien und 2 Kollisionsringgalaxien.
* Die extrem hohe Verarbeitungseffizienz und Genauigkeit der Methode wurden erfolgreich verifiziert, wobei die vollständige Datenanalyse in nur 2 bis 3 Tagen abgeschlossen war. Dies demonstriert ihr transformatives Potenzial bei der Verarbeitung zukünftiger ultra-großflächiger Himmelsdurchmusterungsdaten des Euclidean Telescope und anderer Quellen.
Papieradresse:https://doi.org/10.1051/0004-6361/202555512
Folgen Sie unserem offiziellen WeChat-Konto und antworten Sie im Hintergrund mit „seltene Himmelskörper“, um das vollständige PDF zu erhalten.
Weitere Artikel zu den Grenzen der KI:
https://hyper.ai/papers
Erstellt auf einem standardisierten Datensatz von etwa 100 Millionen Hubble-Quellschnittkarten
Der in dieser Studie verwendete Datensatz stammt aus Quellenausschnitten, die von O'Ryan et al. erstellt wurden. Ziel dieser Arbeit war es ursprünglich, systematisch nach interagierenden und verschmelzenden Galaxien im Hubble Legacy Archive zu suchen und dabei nahezu alle ausgedehnten Quellen innerhalb des Archivs zu verarbeiten, um letztendlich einen großflächigen, standardisierten Bilddatensatz zu erstellen. Um Datenkonsistenz und -kompatibilität zu gewährleisten,Die Forscher wählten ausschließlich die Level-3-kalibrierten Mosaikbilder aus, die mit Hilfe des Weitfeldkanals der Advanced Camera for Surveys des Hubble-Weltraumteleskops unter dem F814W-Filter aufgenommen wurden.Dies bezieht sich auf Daten, die so weit aufbereitet wurden, dass sie direkt für wissenschaftliche Analysen verwendet werden können.
Dieser Screening-Prozess lieferte ungefähr zehntausend Beobachtungen, die ausgedehnte Quellen im Hubble-Quellenkatalog abdeckten, der von Whitmore et al. unter Verwendung der SourceExtractor-Software veröffentlicht wurde.Dies führte letztendlich zu einer Bildbibliothek mit rund 99,6 Millionen Einzelbildern von Pflanzenausschnitten.Jedes Segment hat eine feste Größe von 150 × 150 Pixeln, was einem Himmelsbereich von etwa 7,5 Quadratbogensekunden entspricht, und wird mithilfe der linearen Streckungs- und ZScaleInterval-Methoden von Astropy optimiert und im Graustufen-JPEG-Format gespeichert. Obwohl der Hubble-Quellenkatalog selbst MatchID zur Duplikatsbereinigung enthält, führten Orion et al. die Duplikatsbereinigung erst nach der Klassifizierung durch, um die Strukturinformationen interagierender Systeme oder verschmelzender Mehrkerngalaxien zu erhalten. Die Forscher verfolgten dieselbe Strategie, um sicherzustellen, dass der Trainingsdatensatz keine unterschiedlichen Segmente derselben Quelle enthielt.
Darüber hinaus können bei tiefen Beobachtungen bestimmter kompakter Sternfelder, wie der Andromeda-Galaxie, der Magellanschen Wolke oder Kugelsternhaufen, dichte Punktquellen durch Software zu einer einzigen „ausgedehnten Quelle“ verschmolzen werden, wodurch eine besondere Art von Bildartefakt entsteht.Forscher identifizierten solche Fälle im nachfolgenden aktiven Lernen und verwendeten annotationsgestützte Modelle, um sie als niedrig bewertete anomale Objekte zu klassifizieren.Um die Effizienz des Datenzugriffs zu verbessern, werden alle rund 99,6 Millionen Slices in Blöcken über etwa tausend HDF5-Dateien verteilt gespeichert.
Bei der Erstellung des Trainingsdatensatzes konzentrierten sich die Forscher zunächst auf protoplanetare Scheiben mit geraden Kanten. Daher enthielten die anfänglichen Trainingsdaten, wie in der Abbildung unten dargestellt, nur drei solcher anomalen Beispiele, 128 gekennzeichnete normale Beispiele und eine große Anzahl unbeschrifteter Bilder. Die normalen Beispiele wurden durch Zufallsstichproben aus der gesamten Datenbank und manuelle Überprüfung gewonnen und umfassten isolierte Galaxien, Sternfelder und häufige Artefakte.
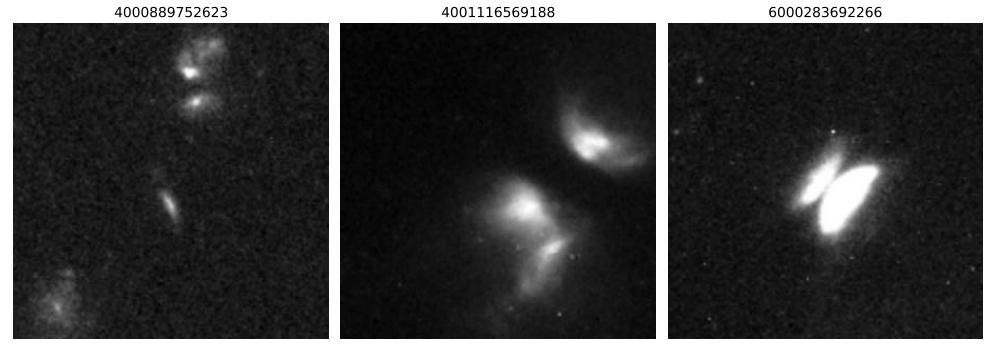
Mit der Einführung des aktiven Lernens jedochDie vom Modell ermittelten, vielversprechenden Kandidatenobjekte wurden rasch auf andere Himmelskörper mit besonderen Formen und Forschungswert ausgeweitet.Mithilfe dieser Daten erstellten und erweiterten die Forscher schrittweise einen allgemeineren Trainingsdatensatz, der schließlich 1400 beschriftete Bilder umfasste, von denen 375 anomal und 1025 normal waren. Die anomalen Bilder zeigten hauptsächlich verschmelzende Galaxien (178) und Gravitationslinsensysteme (63).

Trotz der zunehmenden Vielfalt und Größe des Trainingsdatensatzes gelang es den Forschern nicht, neue, an den Rändern ausgerichtete protoplanetare Scheiben in den F814W-Daten zu entdecken. Dies ist hauptsächlich auf zwei Gründe zurückzuführen: Erstens sind solche Objekte in diesem Beobachtungsband extrem selten; zweitens wurden die wenigen bekannten protoplanetaren Scheibenproben durch die schrittweise Einbeziehung anderer Anomalietypen in den Trainingsdatensatz Teil dieser Daten, wodurch die Wahrscheinlichkeit sank, dass sie als „unbekannte“ Anomalien eingestuft und erneut entdeckt wurden. Dieser Prozess spiegelt auch die tatsächliche Entwicklung dieser Methode von einem Werkzeug zur gezielten Suche hin zu einem allgemeinen Rahmenwerk zur Anomalieerkennung wider.
AnomalyMatch: Ein interaktives und effizientes Framework zur Anomalieerkennung, das halbüberwachtes und aktives Lernen kombiniert.
AnomalyMatch ist ein von Forschern entwickeltes Machine-Learning-Framework, das die Herausforderung der Erkennung seltener Himmelsobjekte in umfangreichen astronomischen Datensätzen bewältigt. Die Kerninnovation dieser Methode liegt in…Es definiert die Anomalieerkennung explizit als ein extrem unausgewogenes binäres Klassifizierungsproblem und kombiniert auf kreative Weise halbüberwachtes Lernen mit einer aktiven Lernschleife.Dies ermöglicht die effiziente Entdeckung potenzieller seltener Zielstrukturen in riesigen Mengen unmarkierter Daten, wobei lediglich eine sehr geringe Anzahl bekannter anomaler Proben benötigt wird.
Wie in der Abbildung unten dargestellt, basiert das Design dieses Modells auf fortschrittlichen, halbüberwachten Lernparadigmen wie FixMatch. Sein Kern nutzt gelabelte und ungelabelte Daten aus dem Benutzerdatensatz, um die EfficientNet-Architektur zu trainieren und so ein Gleichgewicht zwischen Recheneffizienz und Merkmalsextraktionsfähigkeit zu erzielen.Das Gesamtkonzept umfasst zwei kollaborative Lernkomponenten: Der überwachte Lernteil verwendet fokalen Verlust in Kombination mit einer dynamischen Gewichtungsstrategie.Es implementiert außerdem intelligentes Oversampling für seltene Anomaliekategorien, um Trainingsverzerrungen, die durch extreme Klassenungleichgewichte verursacht werden, wirksam zu mindern;Der unüberwachte Teil erzeugt Pseudo-Labels mit hoher Konfidenz durch schwach verbesserte Bilder.Darüber hinaus wird der stark verbesserten Version eine Konsistenzregularisierungsbeschränkung auferlegt, die das Modell dazu zwingt, robuste morphologische Repräsentationen in den Daten zu lernen, anstatt sich auf Oberflächenartefakte zu verlassen.
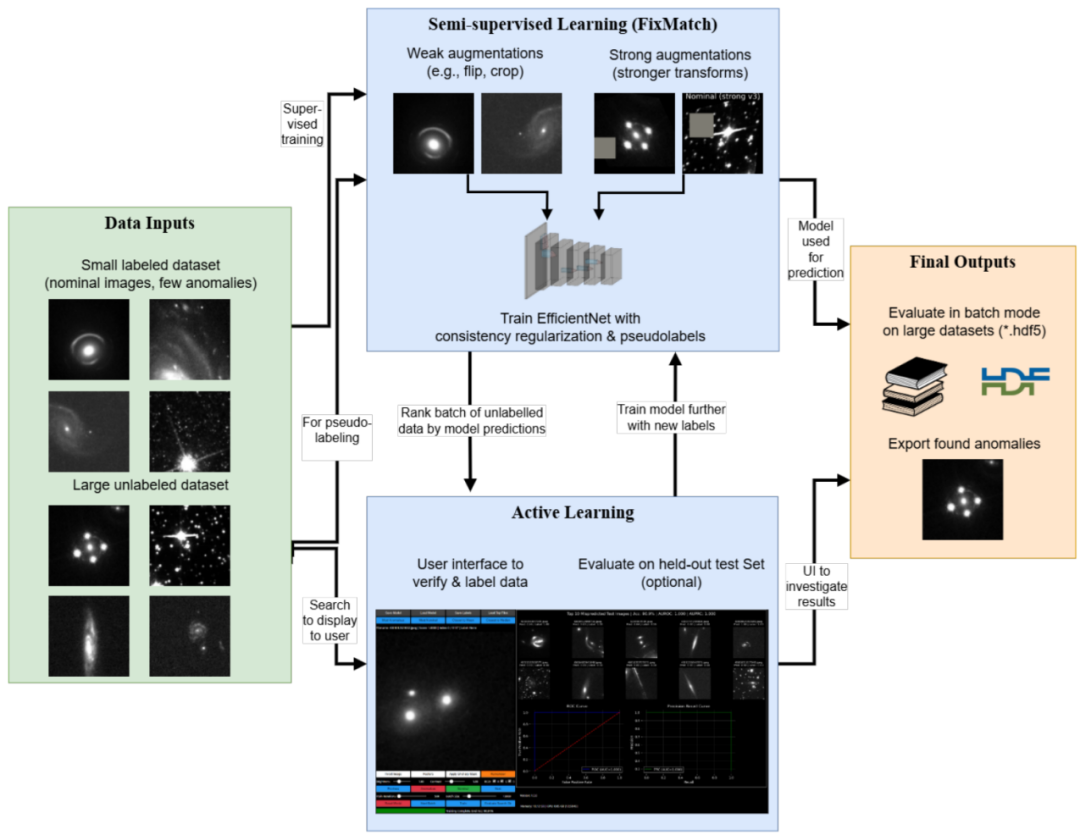
Hinsichtlich des Trainingsmechanismus wendet das Modell eine phasenweise Optimierungsstrategie an.In der Anfangsphase werden zunächst einige wenige gelabelte Beispiele für ein überwachtes Aufwärmtraining verwendet. Anschließend werden nach und nach ungelabelte Daten und deren Pseudolabels für ein halbüberwachtes Training eingeführt.Nach jeder Trainingsrunde analysiert das Modell den gesamten unbeschrifteten Datensatz und gibt für jede Stichprobe einen „Anomalie-Score“ aus. Dieser Score basiert auf der Vorhersagegenauigkeit des Modells in der jeweiligen Anomaliekategorie, und seine Zuverlässigkeit wird durch eine Kalibrierungsstrategie verbessert.
AnomalyMatch integriert nahtlos einen interaktiven Active-Learning-Workflow. Dieser Workflow präsentiert Domänenexperten über eine speziell für die astronomische Bildanalyse entwickelte Weboberfläche die Kandidatenbeispiele mit den höchsten Modellvorhersagewerten. Experten können Beispiele schnell klassifizieren, labeln oder ausschließen, und die Validierungsergebnisse fließen in Echtzeit in den Trainingskreislauf zurück. Die neu bestätigten Beispiele erweitern nicht nur den Label-Satz, sondern ihre Annotationsinformationen werden auch genutzt, um Klassengewichte und Pseudo-Label-Schwellenwerte dynamisch anzupassen. So entsteht ein sich selbst verstärkender geschlossener Kreislauf aus „Modellempfehlung – Expertenbestätigung – Modelliteration“.
Für das Hubble Heritage Archive, das etwa 100 Millionen Quellausschnitte enthält, führt das Modell eine vollständige Dateninferenz in nur etwa 2,5 Tagen durch und unterstützt die Wiederaufnahme an Haltepunkten sowie inkrementelle Aktualisierungen.In praktischen Anwendungen hat dieses Framework nicht nur zahlreiche neue, seltene Himmelsobjekte wie verschmelzende Galaxien, Gravitationslinsen und Quallengalaxien erfolgreich entdeckt, sondern auch mehrere einzigartige Systeme identifiziert, die bisher noch nicht in der Literatur beschrieben wurden. Seine hohe Effizienz und starke Generalisierungsfähigkeit belegen eindrucksvoll den zentralen Wert solcher hybrider intelligenter Frameworks für die Verarbeitung von Daten aus großflächigen Himmelsdurchmusterungen der nächsten Generation.
1.339 ungewöhnliche Himmelsobjekte wurden im Hubble Heritage Archiv entdeckt.
Nach Abschluss des Modelltrainings wurde dieses auf den gesamten Datensatz des Hubble Heritage Archive angewendet, um systematisch nach anomalen Himmelsobjekten zu suchen und diese zu klassifizieren.
Zunächst entfernten die Forscher sorgfältig Duplikate aus den 5.000 Kandidatenproben mit den höchsten Anomaliewerten im Modelloutput. Dazu glichen sie die Proben anhand ihrer Quell-IDs mit dem Hubble-Quellenkatalog ab, extrahierten deren Koordinaten und führten anschließend einen präzisen radialen Abgleich mit einem Radius von 10 Bogensekunden durch. Da die Wahrscheinlichkeit, dass zwei unabhängige anomale Objekte in einem so kleinen Winkelabstand gemeinsam auftreten, extrem gering ist, eliminiert diese Methode effektiv durch Datenfragmentierung verursachte Bildduplikate. Das Ergebnis nach diesem Schritt ist in der folgenden Abbildung dargestellt.Die Forscher erhielten 1.339 einzigartige anomale Kandidaten, was an sich schon intuitiv das Problem der hohen Wiederholungsrate im ursprünglichen Datensatz widerspiegelt.
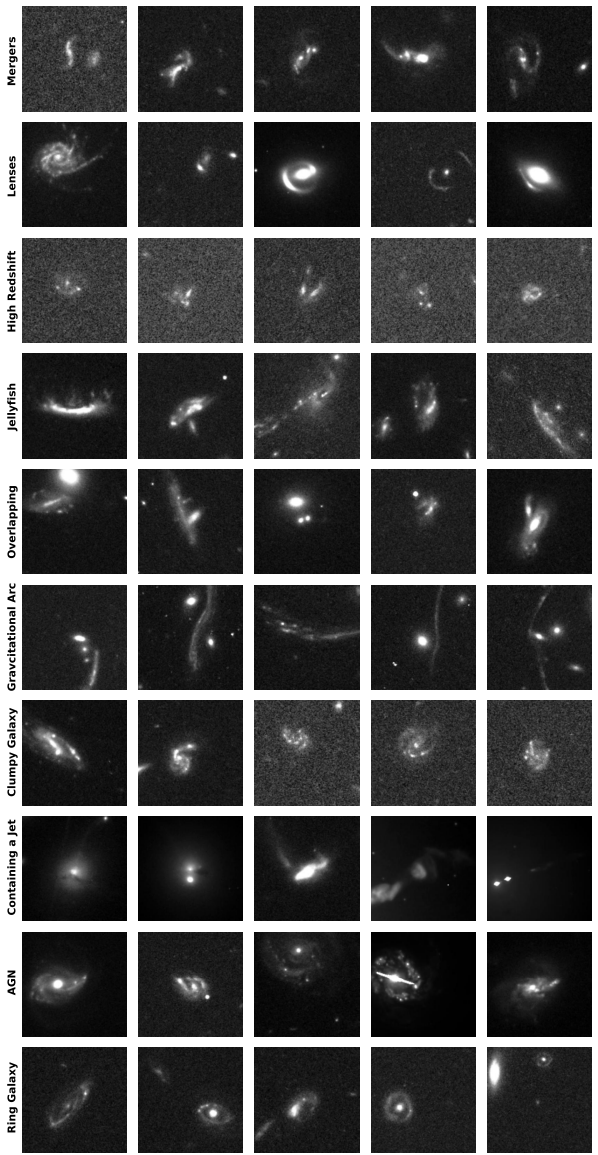
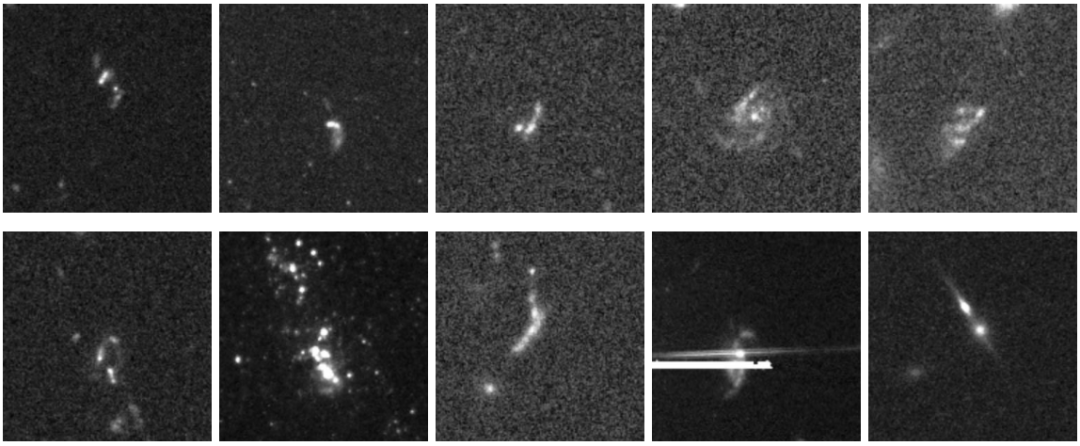
Anschließend untergliederten Fachexperten anhand morphologischer Analysen und Literaturrecherchen in Datenbanken wie SIMBAD und ESASky jede der 1339 einzigartigen Proben sorgfältig. Die Klassifizierungsergebnisse zeigten, dass…Verschmelzende oder interagierende Galaxien sind die am häufigsten entdeckte Kategorie; sie umfasst insgesamt 629 unabhängige Systeme, was etwa 501 TP3T der Gesamtzahl entspricht.
Dies liegt zum Teil daran, dass solche Himmelskörper relativ häufige Anomalien darstellen, zum Teil aber auch an ihren starken Gezeitenkräften, die ihnen eine einzigartige Morphologie verleihen, welche sich gut in Modellen darstellen lässt. Es ist zu beachten, dass die Forscher für ihre Darstellungen ein begrenztes Sichtfeld haben. Daher können manche stark gestörte Verschmelzungssysteme im Spätstadium als einzelne Objekte in den Bildern erscheinen, und ihre Verschmelzungseigenschaften müssen durch Anpassen des Sichtfelds oder durch Konsultation der Fachliteratur weiter bestätigt werden.
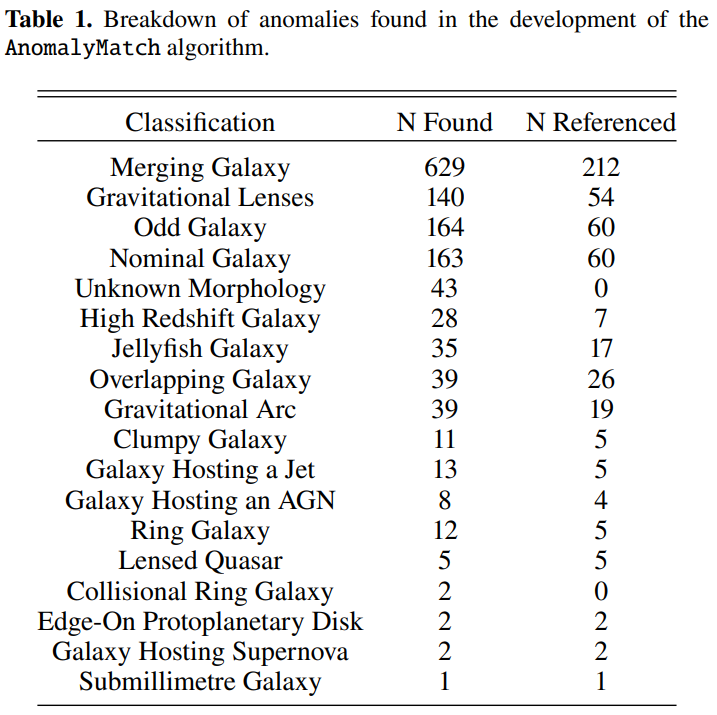
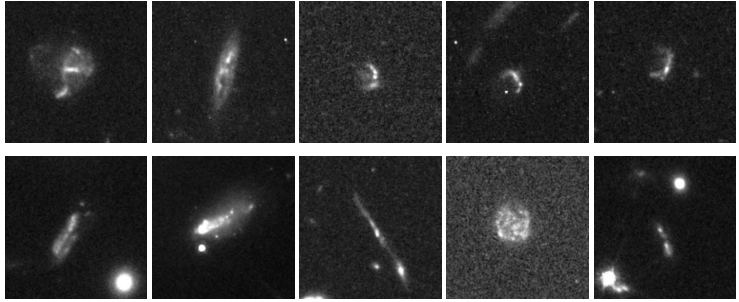
Gravitationslinsen und verwandte Phänomene bilden die zweite Hauptkategorie der entdeckten Anomalien. Forscher identifizierten eine beträchtliche Anzahl starker Kandidaten für Gravitationslinsen, darunter mehrere bekannte Linsensysteme und zahlreiche neue potenzielle Kandidaten. Darüber hinaus unterschieden sie 39 Gravitationsbögen, die typischerweise von Galaxienhaufen im Vordergrund erzeugt werden. Deren Ausdehnung übersteigt oft den Bereich einer einzelnen Tilde und erscheint in den Daten nur als Fragment eines riesigen Lichtbogens. Das Modell detektierte außerdem erfolgreich eine Gruppe von Galaxien mit hoher Rotverschiebung, die in den Bildern als dichte, leicht unregelmäßige Flecken mit niedrigem Signal-Rausch-Verhältnis erscheinen, was mit den Beobachtungseigenschaften solcher Objekte übereinstimmt.
In anderen Kategorien entdeckten die Forscher 35 Quallengalaxien, die strenge Kriterien erfüllten (alle in Galaxienhaufen gelegen und mit Bugstoßwellen und Ablösungsspuren an der Vorderkante versehen), 11 Klumpengalaxien und eine ähnliche Anzahl überlappender Galaxien. Bemerkenswerterweise zeigte das Modell ohne spezifisches Training eine bemerkenswerte Fähigkeit zur Generalisierung bei der Erkennung morphologischer Merkmale.Mehrere Quasarlinsen (charakterisiert durch Strukturen wie das „Einstein-Kreuz“) und 13 relativistische Jet-Wirtsgalaxien, die im optischen Bereich recht selten sind, wurden erfolgreich entdeckt.Dies beweist, dass AnomalyMatch erlerntes Wissen übertragen und anomale Subtypen erkennen kann, die im Trainingsdatensatz nicht vorkamen.
Zusätzlich zu den oben genannten, klar kategorisierten Mitgliedern enthält der endgültige Katalog auch drei allgemeine Kategorien: „Spezielle Galaxien“ bezieht sich auf Himmelsobjekte mit deutlich unregelmäßigen Formen, die keiner der bestehenden Unterkategorien entsprechen; „Normale Galaxien“ stellen falsch positive Ergebnisse (etwa 10%) dar, bei denen die Beurteilung des Modells fehlerhaft ist, wobei es sich hauptsächlich um isolierte Galaxien mit leichten strukturellen Störungen, dichten Sternfeldern oder Instrumentenartefakten handelt; und „Unbekannte Galaxien“ umfassen 43 ungewöhnliche Objekte, die derzeit auf der Grundlage des vorhandenen Wissens nicht klassifiziert werden können, was Raum für zukünftige Forschung lässt.
Künstliche Intelligenz verändert die moderne Astronomie.
Angesichts der Datenflut, die durch die nächste Generation groß angelegter Himmelsdurchmusterungen entstehen wird, durchläuft die globale astronomische Forschung einen tiefgreifenden Paradigmenwechsel.
In der akademischen Forschung liegt ein Schwerpunkt darauf, wie Maschinen die komplexen zeitlichen und Zustandsänderungen in astronomischen Daten intelligenter verstehen können. So hat beispielsweise ein Forschungsteam der Universität Toronto, des Imperial College London und des Harvard-Smithsonian Centre for Astrophysics eine neue Methode auf Basis von Hidden-Markov-Modellen im kontinuierlichen Raum entwickelt, um verschiedene physikalische Zustände astronomischer Quellen automatisch zu identifizieren und zu trennen.
Vereinfacht ausgedrückt modelliert diese Methode die Sternaktivität als eine Reihe verborgener, sich ständig verändernder Zustände.ICH Durch die Analyse der vom Teleskop erfassten Mehrband-Lichtänderungskurven ist es möglich, den physikalischen Zustand eines Himmelskörpers zu jedem Zeitpunkt intelligent abzuleiten.Das Forschungsteam wandte diesen Algorithmus auf einen aktiven Flare-Stern namens EV Lac an. Die KI konnte anhand der Röntgendaten erfolgreich zwischen verschiedenen Zuständen wie „ruhig“ und „Flare“ unterscheiden und die Merkmale der Eruptionsereignisse präzise quantifizieren.
Titel des Papiers:
Trennung von Zuständen in astronomischen Quellen mithilfe von Hidden-Markov-Modellen: eine Fallstudie zu Flares und Ruhephasen auf EV Lac
Link zum Artikel:https://doi.org/10.1093/mnras/stae2082
Gleichzeitig beteiligt sich die Wirtschaft in beispielloser Weise an dieser astronomischen Datenrevolution – nicht mehr nur als Technologieanbieter, sondern auch als Planer, Erbauer und Betreiber wissenschaftlicher Missionen. Ein Paradebeispiel hierfür ist Open Cosmos, ein führendes europäisches Raumfahrttechnologieunternehmen. Im Jahr 2024 ging das Unternehmen eine Partnerschaft mit dem Katalanischen Raumfahrtinstitut ein…Das Unternehmen entwarf und baute formell seine erste Satellitenplattform, die der astrophysikalischen Forschung gewidmet ist, „PhotSat“.Dieser kleine, aber leistungsstarke CubeSat wird zwei Teleskope tragen und soll alle zwei Tage den gesamten Himmel im sichtbaren und ultravioletten Bereich abtasten, um kontinuierlich die Veränderungen von Millionen der hellsten Sterne zu überwachen. Seine wissenschaftlichen Ziele sind klar definiert: Er soll wertvolle Daten für wichtige Forschungsbereiche wie die Suche nach Exoplaneten, die Charakterisierung von Sterneigenschaften und die Beobachtung von Supernova-Explosionen liefern.
Ob es sich nun um in Universitätslaboren entwickelte Hidden-Markov-Modelle handelt, die Einblicke in den tiefen Zustand von Daten ermöglichen, oder um astrophysikalische Satelliten kommerzieller Raumfahrtunternehmen, die sich der Erreichung spezifischer wissenschaftlicher Ziele verschrieben haben – ihr zentraler Antrieb ist die Bewältigung des exponentiellen Wachstums von Datenumfang und -komplexität. Es ist absehbar, dass mit der Inbetriebnahme von Einrichtungen der neuen Generation wie dem Rubin-Observatorium und dem Roman-Weltraumteleskop dieses duale Antriebsmodell aus „intelligenten Algorithmen und innovativen Plattformen“ an Bedeutung gewinnen und die Astronomie von einer hypothesengetriebenen in eine neue Ära führen wird, die sowohl von Daten als auch von Algorithmen bestimmt wird. Dies ermöglicht eine effizientere Entdeckung seltener und wertvoller kosmischer Geheimnisse im unermesslichen Universum.
Referenzlinks:
1.https://www.electronicsweekly.com/news/business/open-cosmos-to-develop-astrophysical-satellite-2024-10/








