Command Palette
Search for a command to run...
Ein Interdisziplinäres Team Der Carnegie Institution Konnte Mithilfe Eines Random-Forest-Modells Auf Basis Von 406 Proben Erfolgreich Spuren Von Leben Erfassen, Die 3,3 Milliarden Jahre zurückreichen.

Die Entschlüsselung der organischen Moleküle, die tief unter der Erdoberfläche in uralten Gesteinsschichten verborgen liegen, ist entscheidend für das Verständnis der Erdgeschichte und die Erforschung der Evolution des Lebens. Diese potenziellen Zeugen lebender Aktivitäten können nicht nur die Geheimnisse der Entstehung des Lebens auf der Erde lüften und insbesondere den Ursprung der Photosynthese sowie den Zusammenhang mit der atmosphärischen Oxidation klären, sondern auch Lücken in der Chronologie der Lebensentwicklung schließen und wichtige Hinweise zum Verständnis der Entstehung früher Ökosysteme der Erde liefern. Im Gegensatz zu großen Organismen, die sichtbare Fossilien bilden, sind diese „Zeugen“ jedoch durch geologische Erosion längst spurlos verschwunden.Daher ist die Identifizierung von Lebensspuren aus stark zersetzten organischen Überresten zu einer großen Herausforderung in den Bereichen Paläontologie und Geowissenschaften geworden.
Lange Zeit stützten sich Wissenschaftler hauptsächlich auf die paläontologische Fossilienmorphologie und Isotopenanalyse, um das frühe Leben zu erforschen. Diese Methoden sind jedoch oft durch den Erhaltungszustand der Proben eingeschränkt: So lassen sich beispielsweise eindeutige Spuren komplexer Moleküle wie Lipide und Porphyrine erst bis vor etwa 1,6 Milliarden Jahren zurückverfolgen – weitaus früher als der durch andere Belege nahegelegte Ursprung des Lebens. Darüber hinaus ist der Ursprung organischer Moleküle in archaischen Gesteinen unklar, und die Grenze zwischen biogenem und abiotischem Ursprung ist schwer zu bestimmen. All dies hat dazu geführt, dass viele wichtige Entdeckungen im spekulativen Stadium verblieben sind.
Um diese Pattsituation zu lösenUnter der Leitung des Earth and Planetary Laboratory der Carnegie Institution for Science und in Zusammenarbeit mit einem interdisziplinären Team aus zahlreichen Universitäten und Forschungseinrichtungen weltweit wurde eine Lösung auf Basis der „Technologiekonvergenz“ vorgeschlagen.Zunächst verwendeten sie Pyrolyse-Gaschromatographie-Massenspektrometrie (Py-GC-MS) zur Analyse und setzten dann überwachte maschinelle Lernverfahren ein, um die analysierten Daten zu klassifizieren und zu unterscheiden und so uralte Spuren des Lebens in den chaotischen Molekülfragmenten zu erfassen.
Experimente zeigen, dass das Modell, das diese Technologien integriert, bessere Ergebnisse liefert als erwartet. Es kann moderne organische Substanz und organische Substanz aus Meteoriten/Fossilien mit einer Auflösung von 1001 TP3T präzise unterscheiden und fossiles Pflanzengewebe mit einer Genauigkeit von 971 TP3T differenzieren. Noch wichtiger ist, dass das Modell bei Anwendung auf unbekannte Proben erfolgreich Hinweise auf biogene Molekülverbindungen in paläoarchaischen und neoarchaischen Gesteinen aus der Zeit vor 3,33 Milliarden bzw. 2,52 Milliarden Jahren identifizieren konnte. Dies bietet neue methodische Unterstützung für die Erforschung älterer und weniger gut erhaltener Lebensspuren.
Die zugehörige Studie mit dem Titel „Organische geochemische Hinweise auf Leben in archaischen Gesteinen, identifiziert durch Pyrolyse-GC-MS und überwachtes maschinelles Lernen“ wurde in den Proceedings of the National Academy of Sciences (PNAS) veröffentlicht.
Forschungshighlights:
* Der vorgeschlagene Technologiefusionsansatz überwindet traditionelle Beschränkungen und bewältigt die zentrale Herausforderung der Unterscheidung von Molekülen nach dem Abbau durch die Kombination von Pyrolyse-Gaschromatographie-Massenspektrometrie mit maschinellem Lernen.
* Die Forschungsstichprobe deckt ein breites Spektrum ab, von modernem Leben bis zu Gesteinen aus Milliarden von Jahren, von terrestrischen Organismen bis zu extraterrestrischen Meteoriten, und bietet so einen umfassenden Vergleich für das Modelltraining.
* Experimente zeigen, dass diese Methode sowohl wissenschaftlich fundiert als auch zukunftsweisend ist, da sie nicht nur die Existenz von Lebensspuren in archaischen Gesteinen bestätigt, sondern auch eine neue Methode zur Erforschung anderer unbekannter Lebensspuren bietet.

Papieradresse:
https://www.pnas.org/doi/10.1073/pnas.2514534122
Folgen Sie unserem offiziellen WeChat-Account und antworten Sie im Hintergrund mit "Pyrolyse-Gaschromatographie", um das vollständige PDF zu erhalten.
Datensatz: 406 Stichproben, die ein breites Spektrum abdecken und einen umfassenden Vergleich für das Modell ermöglichen.
Das Forschungsteam analysierte insgesamt 406 natürliche und synthetische Proben mit einer Vielzahl organischer Moleküle aus alten und modernen, biologischen und abiotischen Quellen, die einen Zeitraum von etwa 3,8 Milliarden Jahren (Archaikum) bis vor 10 Millionen Jahren (Neogen) umfassen. Zu den Probentypen gehörten Sedimentgesteine (141 Stück), Fossilien (65 Proben), moderne Organismen (123), Meteoriten (42, davon 39 kohlige Chondrite) und im Labor synthetisierte organische Moleküle (35 Gruppen). Dies bildet eine reichhaltige und vielfältige Datengrundlage für die Analyse mittels maschinellen Lernens.
Von diesen 406 Proben wurden 272 anhand phylogenetischer Verwandtschaftsverhältnisse und physiologischer Merkmale klar in 9 Kategorien unterteilt und für das überwachte maschinelle Lernen (Training: 75%; Test: 25%) verwendet, wie in der folgenden Abbildung dargestellt:
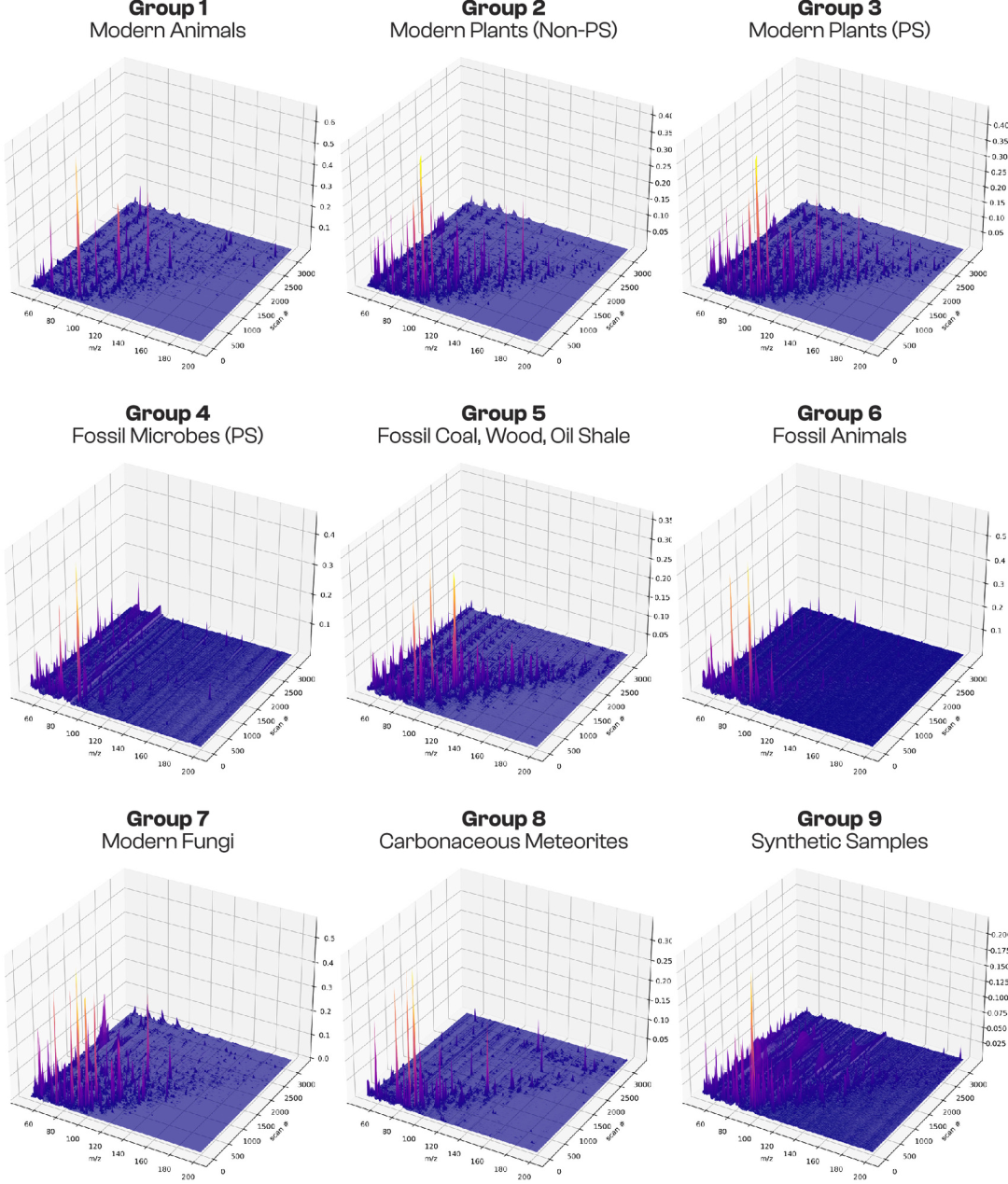
* Moderne Tiere:Organische molekulare Eigenschaften moderner nicht-photosynthetischer heterotropher Organismen wurden aus einer Vielzahl kürzlich verstorbener Wirbelloser und Wirbeltiere gewonnen. Die Stichprobengröße betrug 21.
* Moderne Pflanzen (nicht-photosynthetische Gewebe):Diese Studie umfasste nicht-photosynthetische Gewebe und Sekrete aus Pflanzenwurzeln, Samen, Blüten, Früchten und Pflanzensaft und repräsentiert somit die molekularen Unterschiede zwischen verschiedenen funktionellen Pflanzengeweben. Die Stichprobengröße betrug 40.
* Moderne Pflanzen (photosynthetisches Gewebe):Die Studie konzentrierte sich hauptsächlich auf Blätter und andere photosynthetische Gewebe und dient als moderne Referenz für die Eigenschaften photosynthetischer Biomoleküle. Die Stichprobengröße betrug 36.
* Sedimentgesteine, die Fossilien von photosynthetischen Cyanobakterien/Algen enthalten:Organische Rückstände, angereichert durch Säurebehandlung mit Salzsäure (HCl) und Fluorwasserstoffsäure (HF) in Schiefer oder Feuerstein, liefern in diesen Gesteinen verlässliche morphologische Hinweise auf Cyanobakterien- oder Algenfossilien und dienen somit als molekularer Nachweis urzeitlicher photosynthetischer Mikroorganismen. Die Stichprobengröße betrug 24.
* Versteinertes Holz, Kohle und Ölschiefer:Die Proben stammen hauptsächlich aus dem Phanerozoikum (vor weniger als 541 Millionen Jahren), umfassen aber auch komplexe, kohlenwasserstoffreiche Sedimente aus dem Proterozoikum, wie Schungit und Anthraxolith, die die molekularen Erhaltungsmerkmale urzeitlicher höherer Pflanzen und Kohlenwasserstoffe repräsentieren. Insgesamt wurden 49 Proben untersucht.
* Tierfossilien:Alle Proben stammen aus dem Phanerozoikum und umfassen verkohlte Überreste von Fisch- und Trilobitenfossilien sowie Schalenbindungsproteine aus den Gehäusen miozäner Gastropoden, die organische Molekülreste urzeitlicher Tiere darstellen. Insgesamt handelt es sich um neun Proben.
* Moderne Pilze:Sie umfasst verschiedene holzabbauende Pilze und Hefen und schließt Lücken in den molekularen Daten von nicht-pflanzlichen und nicht-tierischen Gruppen innerhalb der Eukaryoten. Die Stichprobengröße beträgt 16.
* Meteorit:Bei den Proben handelte es sich hauptsächlich um kohlenstoffhaltige Chondriten (insgesamt 39), die einer chemischen Auflösung und Anreicherung organischer Molekülverbindungen unterlagen und somit als eindeutiger Referenzwert für nicht-biologische organische Quellen dienten. Insgesamt wurden 42 Proben gesammelt.
* Im Labor synthetisierte Proben:In der Studie wurden Komplexe organischer Moleküle verwendet, die durch Laborsyntheseverfahren wie die Maillard-Reaktion und die Formose-Reaktion gewonnen wurden, um die molekularen Eigenschaften abiotisch entstandener organischer Substanzen zu simulieren. Die Stichprobengröße betrug 35.
außerdem,Das Forschungsteam erstellte außerdem zwei zusätzliche Hilfsklassen für spezifische Modelle des maschinellen Lernens.Zur Unterscheidung zwischen photosynthetischen und nicht-photosynthetischen Organismen wurden insgesamt drei Proben verwendet. Zwei moderne Cyanobakterienproben dienten der Ergänzung der Daten zu photosynthetischen Prokaryoten. Eine moderne halophile Bakterienprobe (Halobacter) diente der Ergänzung der Daten zu nicht-photosynthetischen Archaeen.
Die verbleibenden 131 Proben bestanden hauptsächlich aus säurelöslichen, angereicherten Rückständen aus archaischen oder proterozoischen Sedimentgesteinen mit hohem Gehalt an organischer Substanz. Ursprung und physiologische Eigenschaften der organischen Moleküle in diesen Proben sind unbekannt oder umstritten. Dies bietet jedoch ein neues Testfeld für die Klassifizierung und die Überprüfung der Anwendung von maschinellem Lernen in diesem Experiment.
Forschungsmethoden und -modelle: Tiefe Integration von py-GC-MS und maschinellem Lernen
Dieses Experiment lässt sich in vier Hauptschritte zusammenfassen:
* Im ersten Schritt wurden 406 verschiedene kohlenstoffhaltige Proben aus verschiedenen modernen und alten, biologischen und abiotischen Quellen gesammelt;
* Im zweiten Schritt werden kohlenstoffhaltige Makromoleküle aus Meteoriten und alten Sedimentgesteinen extrahiert;
* Im dritten Schritt wird jede Probe mittels Pyrolyse-Gaschromatographie gekoppelt mit Elektronenstoßionisations-Massenspektrometrie analysiert;
* Schritt 4: Verwenden Sie die Daten aus der experimentellen Stichprobenanalyse (maschinelles Lernverfahren), um ein überwachtes Random-Forest-Modell zu trainieren.
Der wichtigste Aspekt dieser Methode ist die "technische Integration" von py-GC-MS-Analysetechniken mit Methoden des maschinellen Lernens.
Zunächst einmal die Analysetechnik.In diesem Experiment verwendete das Forschungsteam eine CDS 6150-Thermosonde, gekoppelt mit einem Agilent 8860-Gaschromatographen und einem Agilent 5999-Quadrupol-Massenspektrometer. Die chromatographische Trennung erfolgte mit einer Agilent 30 M 5%-Phenyl-PDMS-Säule. Die Pyrolyseprodukte wurden zur Analyse sofort mit Helium auf die gaschromatographische Säule geleitet. Die genauen Verfahrensschritte sind wie folgt:
* Pyrolyse:Die Forscher füllten Proben (10-100 μg) in vorgeheizte (3 Stunden lang an der Luft bei 550 °C verbrannte) Quarzröhrchen, führten diese dann in eine Wärmesondenspule zur Blitzpyrolyse ein, erhitzten sie mit einer Rate von 500 °C/s auf 610 °C und hielten sie 10 Sekunden lang auf dieser Temperatur.
* Chromatographie:Die Anfangstemperatur betrug 50 °C und wurde 1 Minute lang gehalten, dann mit einer Rate von 5 °C/min auf 300 °C erhöht und 15 Minuten lang gehalten. Als Trägergas wurde Helium höchster Reinheit (UHP 5.5) verwendet.
* Massenspektrometrie:Es arbeitet im Elektronenionisationsmodus (EI) mit einer Ionisationsenergie von 70 eV bei 250℃, mit einem Scanbereich von m/z 45-700, einer Scangeschwindigkeit von 0,80 s/Dekade und einer Verzögerung zwischen den Scans von 0,20 s.
Um Störungen durch flüchtige niedermolekulare Verbindungen (wie CO₂ und H₂O) zu vermeiden, wurden in den ersten zwei Minuten des Experiments keine MS-Daten erfasst. Zudem mussten Signale aus den Elutionsbereichen häufiger Verunreinigungen im Chromatogramm (wie Palmitinsäure und Stearinsäure) ausgeschlossen werden. Jede Probe wurde in eine zweidimensionale Matrix (3240 Elutionszeitintervalle × 150 m/z-Werte) umgewandelt, und die Signalintensität von 489240 Elementen wurde als Funktion von Masse und Retentionszeit aufgezeichnet. Nach Standardisierung und Glättung wurden schließlich 8149 effektive Merkmale beibehalten.
Zweitens wurde eine Modellauswahl durchgeführt. In diesem Experiment wurde die Random-Forest-Methode angewendet.Dies ist eine Ensemble-Klassifikationsmethode mit hoher Genauigkeit, geringem Rechenaufwand und guter Interpretierbarkeit. Sie reduziert das Risiko von Überanpassung durch die Konstruktion mehrerer Dekorrelations-Entscheidungsbäume. Das Modell basiert auf dem von Leo Breiman in „Random Forests“ beschriebenen Random-Forest-Modell.
Die Forscher nutzten zwei Validierungsstrategien für das trainierte Machine-Learning-Modell. Zunächst wurde eine geschichtete Zufallsstichprobe mit einem Trainingsdatensatz von 751 TP3T und einem Testdatensatz von 251 TP3T verwendet, um sicherzustellen, dass der Anteil jeder Klasse in beiden Gruppen konstant war. Anschließend wurde die Generalisierungsfähigkeit des Modells durch zehnfache 10-fache Kreuzvalidierung evaluiert und die durchschnittliche Genauigkeit berechnet, um zufällige Fehler zu reduzieren.
Im Rahmen des Experiments wurden vier Modelle getestet, um zwischen modernen biogenen Quellen (Pflanzen und Tiere) und abiotischen Quellen (Meteoriten + synthetische Proben), alten biogenen Quellen (Sedimentgesteine bekannter biogener Herkunft) und abiotischen Quellen, alten biogenen Quellen (ausgenommen versteinertes Holz und Kohle) und abiotischen Quellen sowie photosynthetischen und nicht-photosynthetischen Proben zu unterscheiden.
Experimentelle Ergebnisse: Ein multimodelliger, multidimensionaler Ansatz bestätigt die Machbarkeit der Technologieintegration.
In den ersten Tests verwendeten die Forscher ein Random-Forest-Modell, um 36 paarweise Kombinationen von Proben mit 9 bekannten Attributen zu klassifizieren, wobei sie von einer relativ ausgewogenen Stichprobengröße ausgingen.Von den 36 Tests wiesen 25 eine Genauigkeit von ≥ 90% sowohl im Trainings- als auch im Testdatensatz auf, wobei 19 davon eine Genauigkeit von ≥ 95% erreichten.Alle Ergebnisse sind in der folgenden Tabelle aufgeführt:
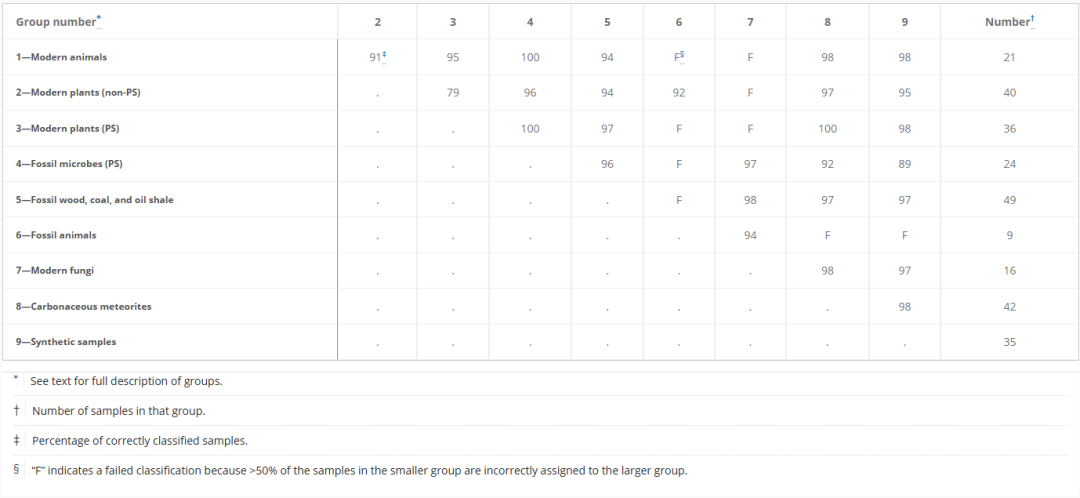
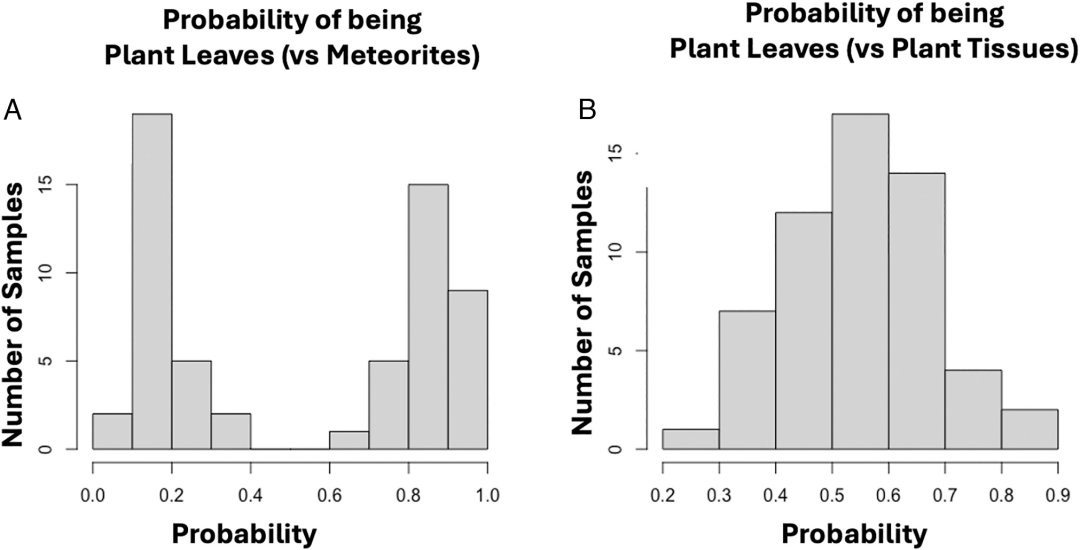
Um die Methode weiter zu veranschaulichen, präsentiert die Arbeit mehrere Fallstudien, die die Unterschiede in Effizienz und Ineffizienz in verschiedenen Fällen aufzeigen. Zum Beispiel in den Gruppen 3 und 8, nämlich modernen Pflanzen (photosynthetisches Gewebe) und Meteoriten,Mit dieser Methode konnten Pflanzen von Meteoriten mit einer Genauigkeit von 100% unterschieden werden.Alle Proben wiesen Klassenwahrscheinlichkeiten > 0,6 oder < 0,4 auf, was auf signifikante Unterschiede in den molekularen Eigenschaften hinweist. Siehe Abbildung A unten:
Darüber hinaus ist die Identifizierung biogener und abiotischer Proben ein zentrales Ziel der paläontologischen und astrobiologischen Forschung. Zu diesem Zweck entwickelte und verglich das Forschungsteam drei verschiedene Random-Forest-Modelle, um deren Fähigkeit zu überprüfen, biogene und abiotische Quellen für verschiedene Probenkombinationen zu unterscheiden.
Im Modell # 1 testete das Forschungsteam insbesondere die Fähigkeit, zwischen modernen Pflanzen und Tieren sowie abiotischen Quellen (Meteoriten und synthetischen Proben) in den Gruppen 1, 2, 3 und 8, 9 mit jeweils 97 bzw. 77 Proben zu unterscheiden.Die Gesamtgenauigkeitsrate erreichte 981 TP3T.Der AUC-Wert beträgt 0,977 im Trainingsdatensatz und 1,000 im Testdatensatz; die Genauigkeit der 10-fachen Kreuzvalidierung beträgt 98,3%.
Das Modell # 2 wurde primär zur Validierung der Fähigkeit eingesetzt, zwischen alten biologischen Proben und abiotischen, organisch reichen Proben zu unterscheiden. Die Kontrollproben stammten aus den Gruppen 4 und 5 sowie 8 und 9 und umfassten 87 bzw. 77 Proben.Von den 87 biogenen, alten organischen Proben wurden 83 korrekt klassifiziert, was einer Genauigkeitsrate von 95,1 TP3T entspricht.Darüber hinaus wiesen 70 dieser Proben (80%) eine hohe Wahrscheinlichkeit für die Klassifizierung ihres biologischen Ursprungs auf (>0,6). 69 der nicht-biologischen Proben wurden korrekt klassifiziert, was einer Genauigkeit von 90% entspricht; der AUC-Wert betrug 0,924 im Trainingsdatensatz und 0,926 im Testdatensatz; die Genauigkeit der 10-fachen Kreuzvalidierung lag bei 92,7%.
Bei der Anwendung des Modells # 2 auf 109 alte Sedimentgesteine unbekannter biogener Herkunft wurde festgestellt, dass 68 Proben (61%) eine Wahrscheinlichkeit für eine Klassifizierung als biogener Ursprung von > 0,50 und 32 Proben eine Wahrscheinlichkeit für eine Klassifizierung als biogener Ursprung von > 0,60 aufwiesen.
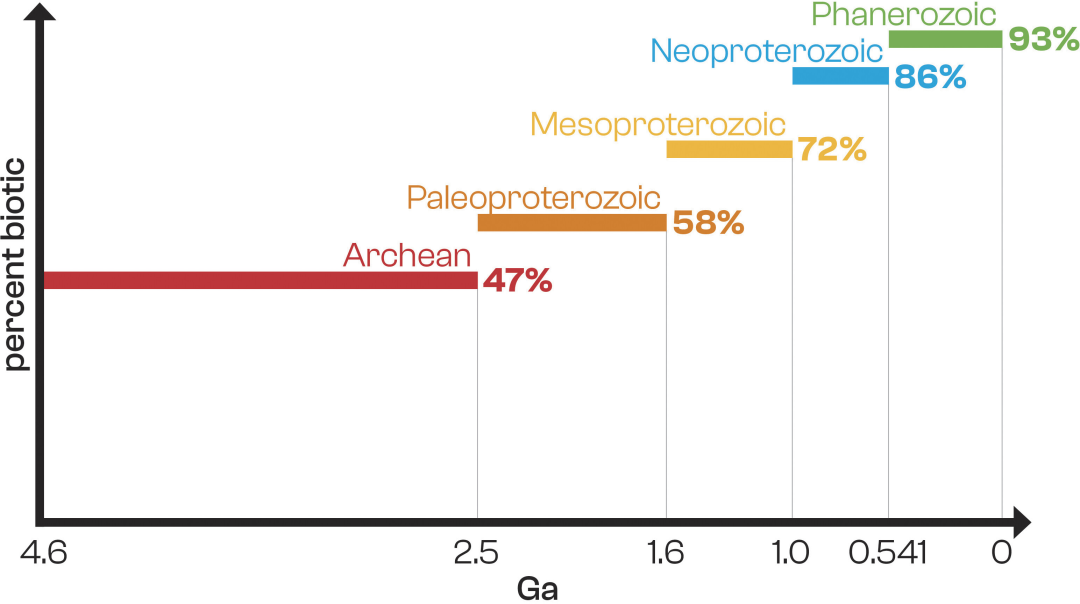
Die Ergebnisse zeigten zudem einen abnehmenden Trend im Anteil biogener Proben mit zunehmendem geologischen Alter. Von den 82 phanerozoischen Proben waren 76 (93%) biogenen Ursprungs, 43 (73%) stammten aus dem Proterozoikum und nur 21 (47%) aus dem Archaikum (45 Proben). Dies deutet auf einen signifikanten Rückgang des prozentualen Anteils biogener Proben mit zunehmendem Alter hin, was möglicherweise auf biomolekularen Abbau oder abiotischen organischen Eintrag in die Proben zurückzuführen ist. (Siehe Abbildung unten.)
Das Modell # 3 dient primär der Überprüfung der Fähigkeit, zwischen biogenen und abiotischen Quellen aus der Antike zu unterscheiden. Die biogenen Proben stammen aus 89 Schiefer- und Feuersteinproben, darunter die vierte Probengruppe, während die abiotischen Proben weiterhin die 77 Proben der achten und neunten Gruppe umfassen.Alle biologischen Proben wurden korrekt klassifiziert. Bei 80%-Proben besteht eine hohe Wahrscheinlichkeit für die Klassifizierung als biologische Ursache (>0,60), und die Genauigkeit der Proben mit nicht-biologischer Ursache beträgt 77%; der AUC-Wert beträgt 0,873 für den Trainingsdatensatz und 0,863 für den Testdatensatz; die Genauigkeit der 10-fachen Kreuzvalidierung beträgt 91,6%.
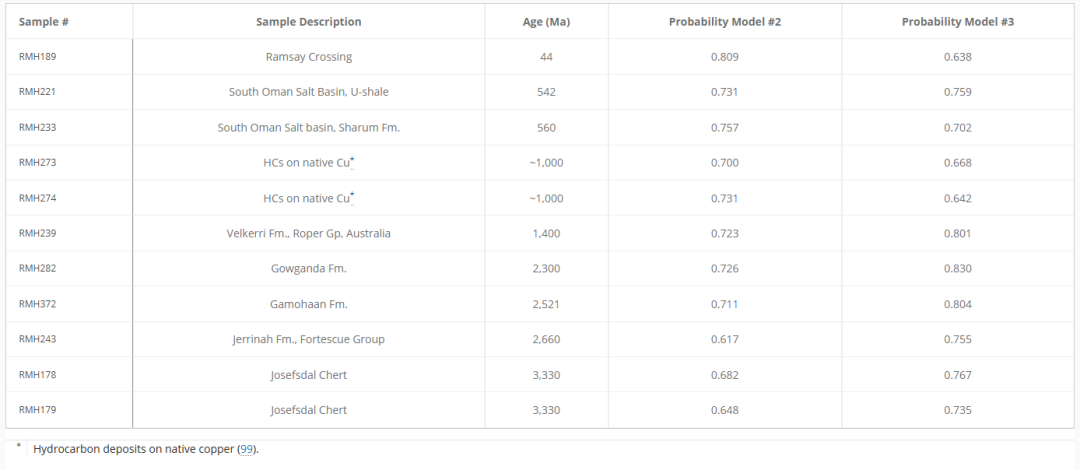
Des Weiteren wird durch die Kombination von Modell # 2 und Modell # 3Forscher haben elf antike Proben als biologischen Ursprungs identifiziert, wobei es sich bei der ältesten um den Josefsdal-Feuerstein aus dem Barberton Greenstone Belt in Südafrika handelt, der 3,33 Milliarden Jahre alt ist.Wie in der folgenden Tabelle gezeigt:
Die technologische Integration hat sich zu einem wichtigen Mittel zur Erforschung der Ursprünge des Lebens entwickelt.
In den letzten Jahren haben internationale Forschungsteams zahlreiche innovative Untersuchungen durchgeführt, um zentrale Herausforderungen wie die Identifizierung von Spuren frühen Lebens und die Suche nach extraterrestrischer organischer Materie anzugehen. Diese Studien konzentrieren sich auch auf die Analyse komplexer Molekülgemische und nutzen algorithmische Modelle, um biologische Eigenschaften zu erforschen, die mit traditionellen Analysemethoden schwer zu erfassen sind. Dadurch wird eine solide Grundlage für die Realisierbarkeit technologischer Integrationswege und die Erforschung des Ursprungs des Lebens auf der Erde geschaffen.
Beispielsweise wurden in Zusammenarbeit mit anderen Institutionen auch die oben genannten Methoden angewendet, um die Ergebnisse des Earth and Planetary Laboratory der Carnegie Institution for Science zu ermitteln. Mit diesen Methoden lässt sich der biologische Ursprung organischer Substanz in planetaren Proben bestimmen sowie Spuren frühen Lebens auf der Erde identifizieren.Diese Methode kombiniert Pyrolyse-Gaschromatographie-Massenspektrometrie-Messungen von terrestrischen und extraterrestrischen kohlenstoffhaltigen Materialien mit Klassifizierungsmethoden des maschinellen Lernens.Es erreichte eine Genauigkeit von 90% bei der Unterscheidung zwischen Proben nicht-biologischen Ursprungs und biologischen Proben (einschließlich stark degradierter biologischer Proben) und spiegelt die Notwendigkeit der biomolekularen Selektionsfunktion Darwins genau wider.
Titel der Veröffentlichung: Eine robuste, agnostische molekulare Biosignatur basierend auf maschinellem Lernen
Papieradresse:https://www.pnas.org/doi/10.1073/pnas.2307149120
Die Integration von Py-GC-MS und maschinellem Lernen überwindet nicht nur die Grenzen traditioneller Methoden in der Erforschung des frühen Lebens, sondern etabliert auch ein neues Paradigma an der Schnittstelle von Paläontologie und künstlicher Intelligenz. Wie die zuvor genannten Experimente und weitere Studien zeigen, bietet dieser technologieintegrierte Ansatz jedoch noch Optimierungspotenzial und liefert wichtige Anhaltspunkte für weiterführende, vertiefende Forschung. Es ist zu erwarten, dass die Menschheit dank kontinuierlicher technologischer Fortschritte in Zukunft ein intuitiveres und umfassenderes Verständnis der Ursprünge des Lebens erlangen und sogar nach Spuren außerirdischen Lebens suchen kann.








