Command Palette
Search for a command to run...
Neueste Erkenntnisse Der Tsinghua-Universität Und Der Universität Chicago in Nature! Künstliche Intelligenz Ermöglicht Es Wissenschaftlern, Ihre Karrieren Um 1,37 Jahre Zu Beschleunigen Und Den Umfang Der Wissenschaftlichen Forschung Um 4,631 TP3T Zu reduzieren.

Die rasante Entwicklung künstlicher Intelligenz (KI) verändert die Grundlagen wissenschaftlicher Forschung grundlegend. Von AlphaFolds präziser Vorhersage von Proteinstrukturen und dem dafür verliehenen Nobelpreis über ChatGPT, das autonome Labore für Hochdurchsatzexperimente steuert, bis hin zu großen Sprachmodellen, die das wissenschaftliche Schreiben und die Ergebnisextraktion erleichtern, demonstriert KI ihr enormes Potenzial, die Produktivität wissenschaftlicher Forschung zu steigern und die Sichtbarkeit von Forschungsergebnissen in vielfältiger Weise zu erhöhen.
Während KI-Werkzeuge den Fortschritt einzelner Wissenschaftler vorantreiben, regen sie gleichzeitig zu einer tiefgreifenden Reflexion über ihre Auswirkungen auf die Gesamtentwicklung der Wissenschaft an, wobei der Kernpunkt der potenzielle Konflikt zwischen individuellen und kollektiven Interessen ist:Unterstützt KI lediglich die individuelle akademische Entwicklung von Wissenschaftlern oder kann sie gleichzeitig vielfältige Forschung und langfristigen Fortschritt im wissenschaftlichen Bereich vorantreiben?Während bestehende Forschungsergebnisse darauf hindeuten, dass KI einzelnen Wissenschaftlern erhebliche Vorteile bringen kann, birgt sie aufgrund der KI-Ausbildungslücke auch das Risiko, Ungleichheiten zu verschärfen. Zudem verändert die Entwicklung von Zitationsmustern die Forschungslandschaft im Stillen. Allerdings fehlen weiterhin groß angelegte empirische Messungen der Auswirkungen von KI auf die Wissenschaft, und ihre detaillierten und dynamischen Effekte auf das Forschungsökosystem müssen noch genauer untersucht werden.
Kürzlich,Ein Forschungsteam der Tsinghua-Universität und der Universität Chicago veröffentlichte seine neuesten Forschungsergebnisse in Nature unter dem Titel „Werkzeuge der künstlichen Intelligenz erweitern den Einfluss von Wissenschaftlern, aber schränken den Fokus der Wissenschaft ein“.Die Analyse von Daten aus 41,3 Millionen naturwissenschaftlichen Publikationen und von 5,37 Millionen Wissenschaftlern im Zeitraum von 1980 bis 2025 hat ein überraschendes Paradoxon im Hinblick auf KI in der Wissenschaft offenbart: KI wirkt als „Superbeschleuniger“ für die individuelle Forschung, aber als „unsichtbares Schrumpfungsinstrument“ für die kollektive Wissenschaft. Diese Studie zeichnet sich nicht nur durch einen umfangreichen Datensatz aus, sondern verwendet auch einen hochentwickelten Analyseansatz.Dies liefert beispiellose systematische Belege für das Verständnis der Branche hinsichtlich der grundlegenden Auswirkungen von KI auf die Wissenschaft.
Papieradresse:
Folgen Sie unserem offiziellen WeChat-Account und antworten Sie im Hintergrund mit „AI Tools“, um das vollständige PDF zu erhalten.
Weitere Artikel zu den Grenzen der KI:
https://hyper.ai/papers
Forschungsansatz: Konstruktion einer vollständigen Kausalkette vom Individuum zum Kollektiv.
Das übergeordnete Studiendesign ist äußerst klar. Es beschränkt sich nicht auf eine einfache Beschreibung des Phänomens, sondern konstruiert eine vollständige analytische Kette von der Identifizierung bis zur Erforschung des Mechanismus.
Ausgangspunkt: Genaue Identifizierung (Was)
Der erste und wichtigste Schritt der Forschung bestand darin, aus der Fülle an Literatur jene Arbeiten herauszufiltern, die „KI als Werkzeug nutzen“, anstatt „KI selbst zu untersuchen“. Das Forschungsteam schloss bewusst Arbeiten aus den Bereichen Informatik und Mathematik aus.Der Schwerpunkt liegt auf sechs naturwissenschaftlichen Disziplinen, darunter Biologie, Medizin und Chemie.Die Forschung sollte sich auf die „Spillover-Effekte“ von KI auf wissenschaftliche Produktionsmethoden konzentrieren.
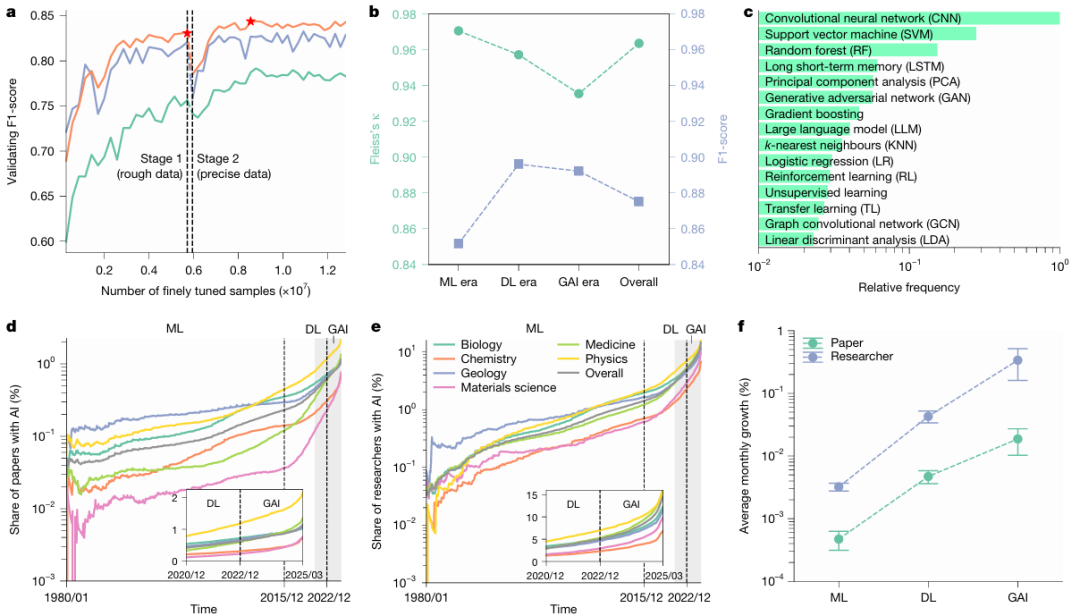
A: Im Rahmen des zweistufigen Feinabstimmens des vortrainierten BERT-Modells verbesserte sich die Leistung der KI bei der wissenschaftlichen Artikelerkennung kontinuierlich: In der ersten Stufe wurden relativ grobe Trainingsdaten verwendet, in der zweiten Stufe wurde auf Basis dieser Daten eine präzisere Unterscheidungsfähigkeit entwickelt. Die Forscher trainierten unabhängig voneinander zwei Modelle, jeweils basierend auf den Titeln (grün) und Abstracts (lila), und integrierten diese anschließend in ein Ensemble-Modell (orange). Das Modell mit der besten Leistung in beiden Stufen wurde dynamisch ausgewählt (roter Stern), um alle relevanten Artikel zu identifizieren.
b: Die Genauigkeit der Erkennungsergebnisse wurde von menschlichen Experten bewertet. Für Stichproben aus drei Entwicklungsstadien der KI wurde ein hoher Konsens unter den Experten erzielt (κ ≥ 0,93). Das Modell zeigte bei der Validierung anhand von Experten-annotierten Daten eine hohe Genauigkeit mit einem F1-Score von mindestens 0,85.
c: Relative Anwendungshäufigkeit der 15 wichtigsten KI-Methoden in jeder Disziplin während des ausgewählten KI-Entwicklungszeitraums.
d, e: Zunahme KI-gestützter Publikationen (d, n = 41.298.433) und der Anzahl von Forschern, die KI einsetzen (e, n = 5.377.346), in den ausgewählten wissenschaftlichen Disziplinen von 1980 bis 2025, unterteilt in die drei Phasen Maschinelles Lernen (ML), Deep Learning (DL) und Generative KI (GAI). Die vertikale Achse ist logarithmisch.
f: Die durchschnittliche monatliche Wachstumsrate der Anzahl von KI-Publikationen und -Forschenden in allen ausgewählten Disziplinen während der Zeiträume ML, DL und GAI (n = 543 monatliche Beobachtungen). Die Fehlerbalken stellen 99%-Konfidenzintervalle (KI) um den Mittelwert dar.
Individuelle Ebene: Quantifizierung der individuellen Auswirkungen
Auf der Grundlage einer präzisen Identifizierung beantwortete die Studie zunächst die Frage: „Welchen Nutzen ergeben sich für einzelne Wissenschaftler?“Durch die Verfolgung der jährlichen Veröffentlichungen, Zitationen und Karriereübergänge der Forscher (vom Nachwuchswissenschaftler zum Projektleiter) gelangte das Forschungsteam zu einer Reihe verblüffender Daten:3,02-mal mehr veröffentlichte Artikel, 4,84-mal mehr Zitationen und 1,37 Jahre längerer Karrierevorsprung.
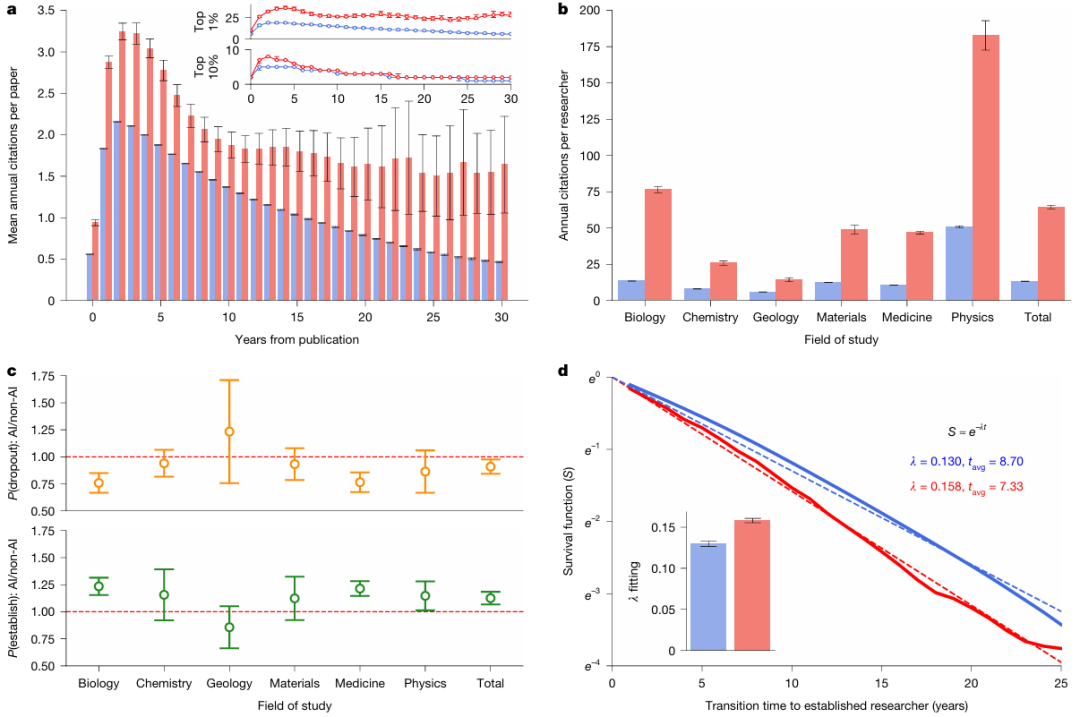
a: Durchschnittliche jährliche Zitationen nach Veröffentlichung für KI-Artikel (rot) und Nicht-KI-Artikel (blau) (der Ausschnitt zeigt die obersten 11 TP3T- bzw. die obersten 101 TP3T-Quantile; n = 27.405.011), was darauf hindeutet, dass KI-Artikel im Allgemeinen mehr Zitationen erhalten.
b: Vergleich der durchschnittlichen jährlichen Zitationen zwischen Forschern, die KI einsetzten, und solchen, die dies nicht taten (P < 0,001, n = 5.377.346), wobei Forscher, die KI einsetzten, im Durchschnitt 4,84-mal mehr Zitationen erhielten als diejenigen, die dies nicht taten.
c: Unter Nachwuchswissenschaftlern wurde die Wahrscheinlichkeit von Rollenwechseln zwischen Forschern, die KI einsetzten, und solchen, die dies nicht taten, verglichen (alle Beobachtungen beziehen sich auf n = 46 Jahre). Nachwuchswissenschaftler, die KI einsetzten, entwickelten sich mit höherer Wahrscheinlichkeit zu erfahrenen Forschern und verließen die Wissenschaft seltener als ihre Kollegen, die keine KI einsetzten.
d: Überlebensfunktion für den Übergang von Nachwuchswissenschaftlern zu erfahrenen Forschern (P < 0,001, n = 2.282.029). Diese Überlebensfunktion lässt sich gut durch eine Exponentialverteilung beschreiben, was darauf hindeutet, dass Nachwuchswissenschaftler, die KI einsetzen, diesen Übergang früher vollziehen. In allen Abbildungen stellen die Fehlerbalken das 99%-Konfidenzintervall (KI) dar; der Ausschnitt in a ist auf die 1%- und 10%-Quantile zentriert, während die übrigen Abbildungen auf den Mittelwert zentriert sind. Alle statistischen Tests wurden mit zweiseitigen t-Tests durchgeführt.
Kollektive Ebene: Strukturwandel aufdecken
In der Folge verlagerte sich der Forschungsschwerpunkt vom Individuum auf das Makroökosystem und warf eine grundlegendere Frage auf: „Welche Veränderungen ergeben sich in der Wissenschaft insgesamt, wenn alle von KI profitieren?“ Zu diesem Zweck führte das Forschungsteam zwei innovative Indikatoren ein: den Wissensumfang, der die Breite der abgedeckten Forschungsthemen misst, und die Folgeinteraktionsdichte, die die Interaktionsdichte zwischen Folgestudien erfasst. Die Forschenden betrachteten Folgeergebnisse, die dieselbe Originalstudie zitierten, als Ganzes und berechneten die gegenseitige Zitationsdichte dieser Ergebnisse. Die Ergebnisse zeigten, dass die Folgeinteraktionen in der KI-Forschung um etwa 221 TP3T abnahmen.
Attribution: Erforschung der zugrunde liegenden Mechanismen (Warum)
Schließlich beschränkte sich die Forschung nicht auf die Phänomene.Stattdessen geht es der Frage nach, welcher Mechanismus diesem „Expansions-Kontraktions“-Paradoxon zugrunde liegt.Durch den Ausschluss von Faktoren wie Popularität, anfänglicher Wirkung und Förderprioritäten wies das Forschungsteam auf den grundlegendsten Grund hin: die Datenverfügbarkeit. Künstliche Intelligenz (KI) konzentriert sich naturgemäß auf etablierte Bereiche mit reichlich Daten und einfacher Modellierung, was zu einer Konzentration der kollektiven Aufmerksamkeit und einem schrumpfenden Spielraum für weitere Forschung führt.
Diese vollständige logische Kette vom „Was“ zum „Warum“ macht die Forschungsergebnisse äußerst überzeugend.
Forschungshighlights: Drei wichtige Innovationen zur Lösung der Kernprobleme
KI-gestützte Methoden zur Papiererkennung, die über die Stichwortübereinstimmung hinausgehen:
Die traditionelle Forschung nutzt häufig Schlüsselwörter (wie „Neuronales Netzwerk“), um KI-Publikationen zu sichten, was jedoch sehr anfällig für Verzerrungen ist. Diese Studie verwendet ein zweistufiges, feinabgestimmtes BERT-Modell, das separat anhand von Titel und Abstract der Publikation trainiert wird und die Ergebnisse anschließend integriert, um eine abschließende Bewertung zu treffen.Diese Methode erreichte nach einer Blindprüfung durch Experten einen F1-Wert von bis zu 0,875.Damit wurde eine solide und verlässliche Datengrundlage für die gesamte Studie geschaffen.
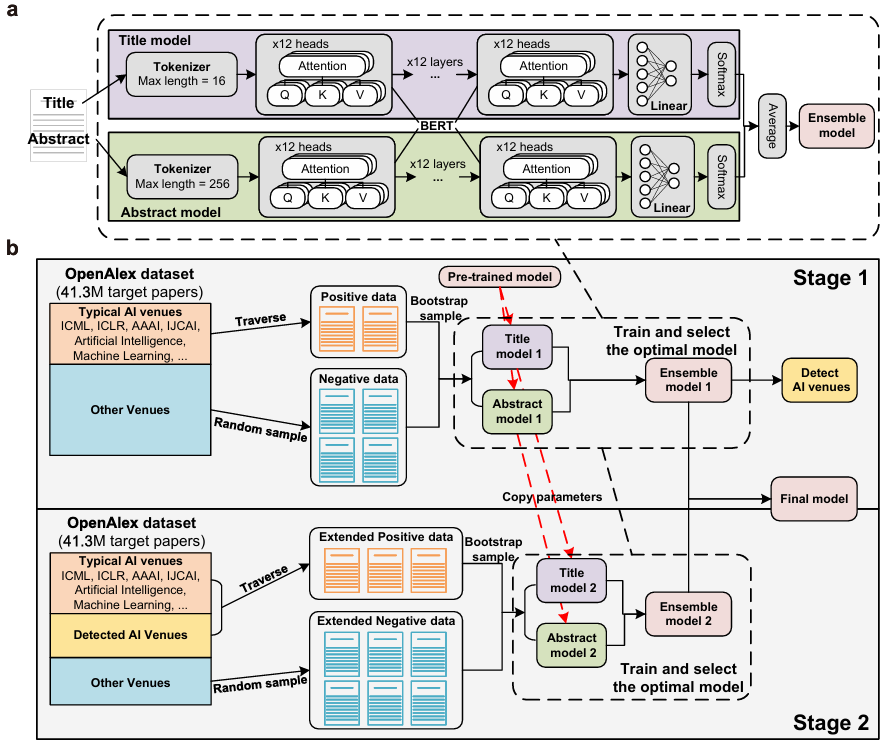
a: Ein schematisches Diagramm des eingesetzten Sprachmodells, das aus einem Tokenizer, dem BERT-Kernmodell und linearen Schichten besteht.
b: Schematische Darstellung des zweistufigen Modell-Feinabstimmungsprozesses, in dem die Forscher für jede Stufe spezifische Methoden zur Konstruktion positiver und negativer Beispieldaten entwickelten.
Ein bahnbrechender quantitativer Indikator für „Wissensbreite“:
Wie messen wir den „Explorationsumfang“ eines Forschungsfeldes? Das Forschungsteam nutzte SPECTER 2.0, ein speziell für wissenschaftliche Literatur entwickeltes Einbettungsmodell.Jedes Dokument wird einem 768-dimensionalen semantischen Vektorraum zugeordnet.Die „Wissensbreite“ einer Aufsatzsammlung wird als der maximale Durchmesser definiert, den sie in diesem Raum einnimmt. Dieser Ansatz, der das abstrakte Konzept der „Wissensdiversität“ in eine präzise berechenbare geometrische Distanz umwandelt, ist eine bedeutende Innovation in der Wissenschaftsmetrik.
Aufdeckung des akademischen Interaktionsmusters der „einsamen Überfüllung“:
Forschungen haben ergeben, dass nachfolgende Studien, die dieselbe KI-Veröffentlichung zitieren, sich bis zum 221.13.2020 seltener gegenseitig zitieren. Dies zeichnet das Bild einer eher „sternförmigen“ als einer „vernetzten“ Forschungslandschaft: Zahlreiche Studien konzentrieren sich wie Planeten auf wenige herausragende KI-Errungenschaften, weisen aber kaum Querverbindungen zueinander auf. Dieser Zustand isolierter Forschungsgruppen ist ein besorgniserregendes Zeichen dafür, dass wissenschaftliche Kreativität gehemmt wird.
Wie können wir den Vektorraum nutzen, um die Breite der Wissenschaft zu "messen"?
Wenn man das gesamte Dokument als ein imposantes Gebäude betrachtet, dann ist seine Kerntechnologie zweifellos das SPECTER 2.0-Einbettungsmodell und der damit verbundene Wissensumfang.
Stellen Sie sich das gesamte wissenschaftliche Wissenssystem als ein riesiges Universum vor. SPECTER 2.0 hat die Aufgabe, ein präzises Koordinatensystem für dieses Universum zu etablieren. Durch die Analyse von Millionen wissenschaftlicher Artikel und ihrer Zitationsbeziehungen transformiert es jeden Artikel in einen 768-dimensionalen Koordinatenpunkt (d. h. einen Vektor). In diesem hochdimensionalen Raum liegen die Koordinatenpunkte von Artikeln mit ähnlichen Themen nahe beieinander; Artikel mit sehr unterschiedlichen Themen weisen hingegen große Unterschiede auf.
Wie lässt sich mit diesem Koordinatensystem das „Territorium“ eines Forschungsfeldes messen? Der Ansatz des Forschungsteams ist sehr raffiniert:
Probenahme: Aus einem bestimmten Fachgebiet (z. B. KI-gestützte biologische Forschung) wird nach dem Zufallsprinzip eine Reihe von Artikeln ausgewählt.
Position: Mithilfe von SPECTER 2.0 wurden alle diese Dokumente in ein 768-dimensionales Wissensuniversum projiziert, woraus eine Menge von Koordinatenpunkten resultierte.
Finde die Mitte: Berechnen Sie den geometrischen Mittelpunkt (Schwerpunkt) aller dieser Punkte.
Messen Sie den Durchmesser: Der Abstand vom am weitesten vom Zentrum entfernten Punkt wird als die „Breite des Wissens“ dieser Aufsatzsammlung definiert.
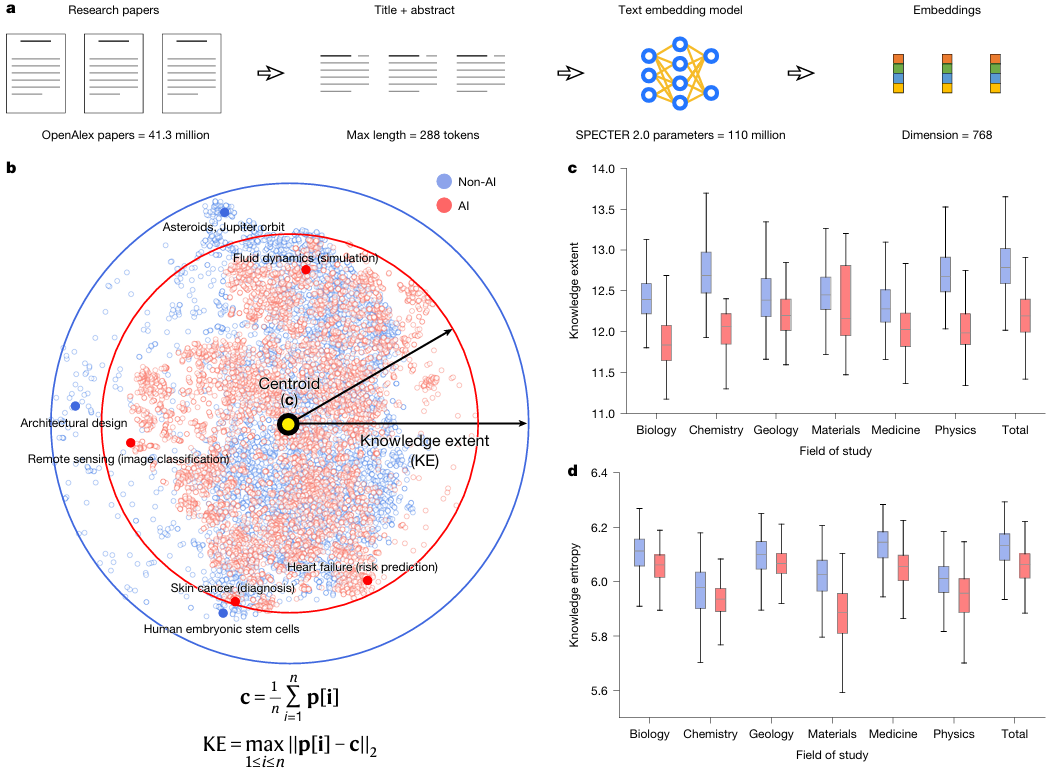
a: Forscher verwendeten ein vortrainiertes Text-Embedding-Modell, um Forschungsarbeiten in einen 768-dimensionalen Vektorraum einzubetten und die Breite des Wissens in den Arbeiten innerhalb dieses Raums zu messen.
b: Zur besseren Visualisierung nutzten die Forscher den t-SNE-Algorithmus (t-distributed Random Neighborhood Embedding), um die hochdimensionalen Einbettungen von 10.000 zufällig ausgewählten Publikationen (davon die Hälfte KI-Publikationen) in einen zweidimensionalen Raum zu komprimieren. Wie die durchgezogenen Pfeile und Kreise zeigen, weisen die KI-Publikationen (deren Wissensbreite im ursprünglichen Raum ohne Dimensionsreduktion berechnet wurde) eine geringere Wissensbreite über die gesamten Naturwissenschaften hinweg auf. Darüber hinaus zeigen die KI-Publikationen eine stärkere Clusterbildung im Wissensraum, was auf eine fokussiertere Auseinandersetzung mit spezifischen Fragestellungen hindeutet.
c: Vergleich der Wissensbreite von KI- und Nicht-KI-Publikationen in verschiedenen Disziplinen (P < 0,001, n = 1.000 Stichproben pro Disziplin). Die Ergebnisse zeigen, dass sich die KI-Forschung auf einen engeren Wissensbereich konzentriert.
d: Vergleich der Wissensentropie zwischen KI- und Nicht-KI-Publikationen verschiedener Disziplinen (P < 0,001, n = 1.000 Stichproben pro Disziplin). KI-Forschung weist eine geringere Wissensentropie auf. In den Abbildungen c und d sind die Boxplots um den Median zentriert. Die obere und untere Grenze der Boxen repräsentieren das erste bzw. dritte Quartil (Q1 und Q3), die Whisker das 1,5-fache des Interquartilsabstands. Alle statistischen Tests wurden mit dem Median-Test durchgeführt.
Mithilfe dieser Methode konnte das Forschungsteam die Größe des Forschungsfelds der KI-Forschung und der Nicht-KI-Forschung vergleichen. Die Ergebnisse zeigen deutlich, dass die mittlere Wissensbreite der KI-Forschung um 4,631 TP3T geringer ist als die der Nicht-KI-Forschung. Dies bedeutet, dass sich Wissenschaftler, angetrieben durch die KI, einhellig auf ein kleineres, konzentrierteres Wissensgebiet konzentrieren.
Darüber hinaus analysierte die Studie die Zitationsverteilung und stellte fest, dass die KI-Forschung einen stärkeren „Matthäus-Effekt“ aufweist:Die 22,21 besten KI-Veröffentlichungen (TP3T) erhielten 801 TP3T an Zitationen, und ihre Zitationsungleichheit (Gini-Koeffizient 0,754) war deutlich höher als die der Nicht-KI-Forschung (0,690).
Abschluss
Zusammenfassend:Diese technische Lösung beantwortet nicht nur die Frage, ob die Wissenschaft enger geworden ist, sondern gibt Forschern auch genauer Auskunft darüber, „wie viel enger“, „in welcher Dimension sie enger geworden ist“ und „welche Art von Struktur sich nach der Verengung gebildet hat“.Dies ist keine vage Sorge mehr, sondern eine Realität, die sich präzise mit Daten darstellen lässt.
Der Wert dieser Studie liegt nicht in der Ablehnung von KI, sondern in der strengsten Aufdeckung der versteckten Kosten, die Forschern durch den Einsatz von KI entstehen können. Sie erinnert Forscher daran, dass wahre wissenschaftliche Intelligenz nicht bloß ein „Werkzeug“ zur Effizienzsteigerung sein sollte, sondern vielmehr ein „Partner“ zur Erweiterung der Grenzen menschlicher Kognition.








