Command Palette
Search for a command to run...
2,5.000 Fragen! HLE Hat Einen Durchbruch Beim Aufbau Eines Präzisen Bewertungssystems Für Große Sprachmodelle erzielt. Jan-Nano, Ein Leichtes Großes Sprachmodell Mit 4 Milliarden Parametern, Ist Für Tiefgreifende Forschungsaufgaben konzipiert.

In den letzten Jahren haben große Sprachmodelle (LLMs) bahnbrechende Fortschritte erzielt und sind nun in der Lage, vielfältige Aufgaben wie die Beantwortung von Fragen und die Erstellung von Inhalten zu bewältigen, was ihre Leistungsfähigkeit unter Beweis stellt. Benchmarks sind wichtige Instrumente zur Bewertung der Entwicklungsfähigkeit von LLMs und von entscheidender Bedeutung für deren Verbesserung und Erweiterung. Die aktuell gängigen Benchmarks weisen jedoch Mängel im Schwierigkeitsgrad auf, da hochmoderne LLMs in vielen bestehenden Bewertungen ähnliche und hohe Werte erzielt haben. Dies schränkt die Genauigkeit der LLM-Leistungsmessung ein und erschwert die Verbesserung der Leistungsfähigkeit großer Modelle.
Auf dieser Grundlage haben das Center for AI Safety und Scale AI gemeinsam den multimodalen Benchmark-Datensatz für menschliche Probleme „Humanity's Last Exam“ (HLE) veröffentlicht.Ziel ist es, das ultimative Siegel zu bauen, das die Grenzen des menschlichen Wissens abdecktGeschlossenAuswertenSystem.Dieser Datensatz besteht aus 2.500 Fragen aus Dutzenden von Themenbereichen und soll einen genauen und effektiven Messstandard für LLM-Fähigkeiten bieten, die Lücke zwischen aktuellen LLM-Fähigkeiten und professionellen Akademikern verdeutlichen und eine schnellere Verbesserung der LLM-Fähigkeiten in den Grenzbereichen des Wissens besser erreichen.
Derzeit wurde auf der offiziellen Website des HyperAI Super Neural Network der „HLE Human Problem Reasoning Benchmark Dataset“ veröffentlicht. Kommen Sie vorbei und probieren Sie ihn aus ~
Datensatz-Download:
Vom 14. bis 18. Juli gibt es Updates auf der offiziellen Website von hyper.ai:
* Hochwertige öffentliche Datensätze: 10
* Hochwertige Tutorial-Auswahl: 5
* Empfohlene Artikel dieser Woche: 5
* Interpretation von Community-Artikeln: 5 Artikel
* Beliebte Enzyklopädieeinträge: 5
* Top-Konferenzen mit Deadline im Juli: 4
Besuchen Sie die offizielle Website:hyper.ai
Ausgewählte öffentliche Datensätze
1. GSM8K-Datensatz zum mathematischen Denken
GSM8K ist ein 2022 von OpenAI veröffentlichter Datensatz zum mathematischen Denken, der die Leistung von Machine-Learning-Modellen beim Verstehen und Lösen komplexer mathematischer Probleme verbessern soll. Der Datensatz enthält 8,5.000 hochwertige, sprachübergreifende Textaufgaben aus dem Grundschulbereich, die Algebra, Arithmetik, Geometrie und weitere Bereiche abdecken. Die Aufgaben sind in 2–8 Schritten zu lösen. Die Lösung besteht hauptsächlich aus einer Reihe einfacher Berechnungen mit grundlegenden Rechenoperationen (Addition, Subtraktion, Multiplikation und Division), um das endgültige Ergebnis zu erhalten.
Direkte Verwendung:https://go.hyper.ai/ZqNLt
2. Pflanzenkrankheiten Pflanzenkrankheitsdatensatz
Crops Disease ist ein Bilddatensatz zu landwirtschaftlichen Pflanzenkrankheiten, der die Entwicklung von Computer-Vision-Modellen zur automatischen Erkennung und Klassifizierung von Krankheiten verschiedener Nutzpflanzen unterstützen soll. Der Datensatz enthält rund 1.300 Bilder von Pflanzenkrankheiten, die häufige Krankheiten verschiedener Nutzpflanzen (wie Mais, Tomaten, Kartoffeln usw.) abdecken. Jedes Bild ist mit einer spezifischen Krankheitskategorie versehen.
Direkte Verwendung:https://go.hyper.ai/GEDTA

3. OpenScience Multi-Domain-Synthetische Datensätze
OpenScience ist ein multidomänenbasierter synthetischer Datensatz, der 2023 von NVIDIA veröffentlicht wurde. Ziel ist es, die Genauigkeit fortgeschrittener Benchmarks wie GPQA-Diamond und MMLU-Pro durch überwachtes Feintuning oder bestärkendes Lernen zu verbessern. Der Datensatz enthält sechs Millionen Multiple-Choice-Frage-Antwort-Paare mit detaillierten Argumentationslinien und deckt verschiedene wissenschaftliche Bereiche wie MINT, Recht, Wirtschaft und Geisteswissenschaften ab.
Direkte Verwendung:https://go.hyper.ai/YvAo7
4. Skywork-OR1-RL-Datensatz zur Problembegründung in der mathematischen Programmierung
Skywork-OR1-RL ist ein Datensatz zum mathematischen Programmieren, der zum Trainieren des mathematischen Programmier-Reasoning-Modells Skywork-OR1 (Open Reasoner 1) entwickelt wurde. Der Datensatz enthält 105.000 mathematische Probleme und 14.000 Programmierprobleme, die überprüfbar, anspruchsvoll und vielfältig sind.
Direkte Verwendung:https://go.hyper.ai/mxoAv
5. Bilddatensatz zur Vogelklassifizierung
Bird Species ist ein Datensatz zur Klassifizierung von Vogelbildern, der sich für das Training von Computer-Vision-Modellen zur Identifizierung und Klassifizierung von Vogelarten eignet. Der Datensatz enthält sieben verschiedene Arten mit jeweils 1.200 Bildern. Die Bilder jeder Art zeigen das Federmuster, die Farbe und den Körperbau des jeweiligen Vogels. Einige Bilder sind absichtlich unscharf, geneigt oder zeigen zwei Vögel verschiedener Arten. Dies erhöht die Komplexität der realen Welt und macht das Modell robuster für eine genaue Klassifizierung in natürlichen Umgebungen.
Direkte Verwendung:https://go.hyper.ai/X2X2M

6. NextCoder-Code-Bearbeitungsdatensatz
NextCoder ist ein synthetischer Datensatz zur Bearbeitung von Dialogcodierungen, der 2025 von Microsoft veröffentlicht wurde. Er dient der Feinabstimmung großer Sprachmodelle, um deren Leistung bei Codereparatur, Refactoring und Optimierung zu verbessern. Er eignet sich hervorragend für das Training von KI-Programmierassistenten und die Verbesserung des Codelesens und der mehrstufigen Interaktion. Der Datensatz enthält etwa 381.000 einstufige Anweisungsbeispiele (NextCoderDataset) und 57.000 mehrstufige Dialogbeispiele (Konversationsversion) und deckt acht Sprachen wie Python und Java ab.
Direkte Verwendung:https://go.hyper.ai/e4MIs
7. Psych-101-Datensatz zur Beantwortung von Wissensfragen in der Psychologie
Psych-101 ist ein Datensatz zur Beantwortung psychologischer Wissensfragen. Er soll die Entwicklung natürlicher Sprachverarbeitungsmodelle für psychologische Wissensfragen und die Förderung psychologiebezogener KI-Forschung unterstützen, insbesondere in der Psychologieausbildung, der Sentimentanalyse und im Bereich der psychischen Gesundheit. Der Datensatz enthält Daten aus 160 psychologischen Experimenten mit 60.092 Teilnehmern und insgesamt 10.681.650 Auswahlmöglichkeiten.
Direkte Verwendung:https://go.hyper.ai/NUshw
8. Leukämie Leukämie-Bilddatensatz
Leukemia ist ein Datensatz mit Leukämiezellbildern, der zum Trainieren von Computervision-Modellen zur automatischen Erkennung und Klassifizierung von Leukämiezellen entwickelt wurde. Der Datensatz enthält 6.778 Zellbilder, darunter 3.389 normale Zellen und 3.389 Leukämiezellen.
Direkte Verwendung:https://go.hyper.ai/Lwxwj
9. Röntgenbilddatensatz zur Lungenentzündung im Brustkorb
„X-Ray Images for Chest Pneumonia“ ist ein Datensatz mit Röntgenaufnahmen des Brustkorbs, der zum Trainieren und Evaluieren von Computervision-Modellen entwickelt wurde, um automatisierten Diagnosesystemen die Erkennung von Atemwegserkrankungen wie Lungenentzündung zu ermöglichen. Der Datensatz enthält rund 5.800 Röntgenaufnahmen des Brustkorbs, unterteilt in zwei Kategorien: normal und Lungenentzündung (bakteriell und viral).
Direkte Verwendung:https://go.hyper.ai/Pgra4
10. Bodenfeuchtigkeit Bilddatensatz zur Bodenfeuchtigkeit
Soil Moisture ist ein messbasierter Datensatz zur Bodenfeuchtigkeit, der die Auswirkungen der Bodenfeuchtigkeit auf das Pflanzenwachstum untersucht, Bewässerungssysteme optimiert und die landwirtschaftliche Produktionseffizienz verbessert. Er findet auch wichtige Anwendung in Bereichen wie Klimawandel und Wasserressourcenmanagement. Der Datensatz enthält 200 Bodenoberflächenbilder aus dem Regenfeldbaugebiet Bondowoso in Indonesien.
Direkte Verwendung:https://go.hyper.ai/TtpgP

Ausgewählte öffentliche Tutorials
Diese Woche haben wir 4 Kategorien hochwertiger öffentlicher Tutorials zusammengefasst:
*KI für Wissenschafts-Tutorials: 2
*Tutorial zur Texterkennung: 1
*Multimodales Tutorial: 1
*Großes Modell-Tutorial: 1
Tutorial: KI für die Wissenschaft
1. RFdiffusion: ein Diffusionsprotein-Designmodell
RFdiffusion ist ein Framework zur Generierung von Proteinstrukturen: Es verwendet RoseTTAFold als Backbone-Netzwerk und führt das denoised diffusion probability model (DDPM) ein, um neue Proteinstrukturen von Grund auf zu entwerfen. Das Framework ermöglicht die Entwicklung von Proteinen mit komplexen Formen (wie α-Helices und β-Faltungen) und die präzise Vorhersage des katalytischen Gerüsts von Enzymen.
Online ausführen:https://go.hyper.ai/q7Ajs
2. Biomni: Der erste allgemeine biomedizinische Wirkstoff
Biomni ist ein universeller biomedizinischer KI-Agent, der komplexe Forschungsaufgaben in mehreren biomedizinischen Bereichen wie Genetik, Genomik, Mikrobiologie, Pharmakologie und klinischer Medizin autonom erledigen kann und damit eine neue Stufe in der Entwicklung KI-gestützter wissenschaftlicher Entdeckungen markiert.
Online ausführen:https://go.hyper.ai/aameS
Tutorial zur Texterkennung
1. OCRFlux-3B: Intelligentes Texterkennungs-Toolkit
OCRFlux-3B ist ein Toolkit, das auf einem multimodalen Großsprachenmodell basiert und PDFs und Bilder in sauberen, lesbaren Markdown-Text konvertiert. Das Tool bietet nicht nur Textkonvertierung auf Seitenebene, sondern unterstützt auch das Zusammenführen von Tabellen und Absätzen über mehrere Seiten hinweg und bietet so leistungsstarke Unterstützung bei der Verarbeitung komplexer Dokumentstrukturen.
Online ausführen:https://go.hyper.ai/BGqmR
Multimodales Tutorial
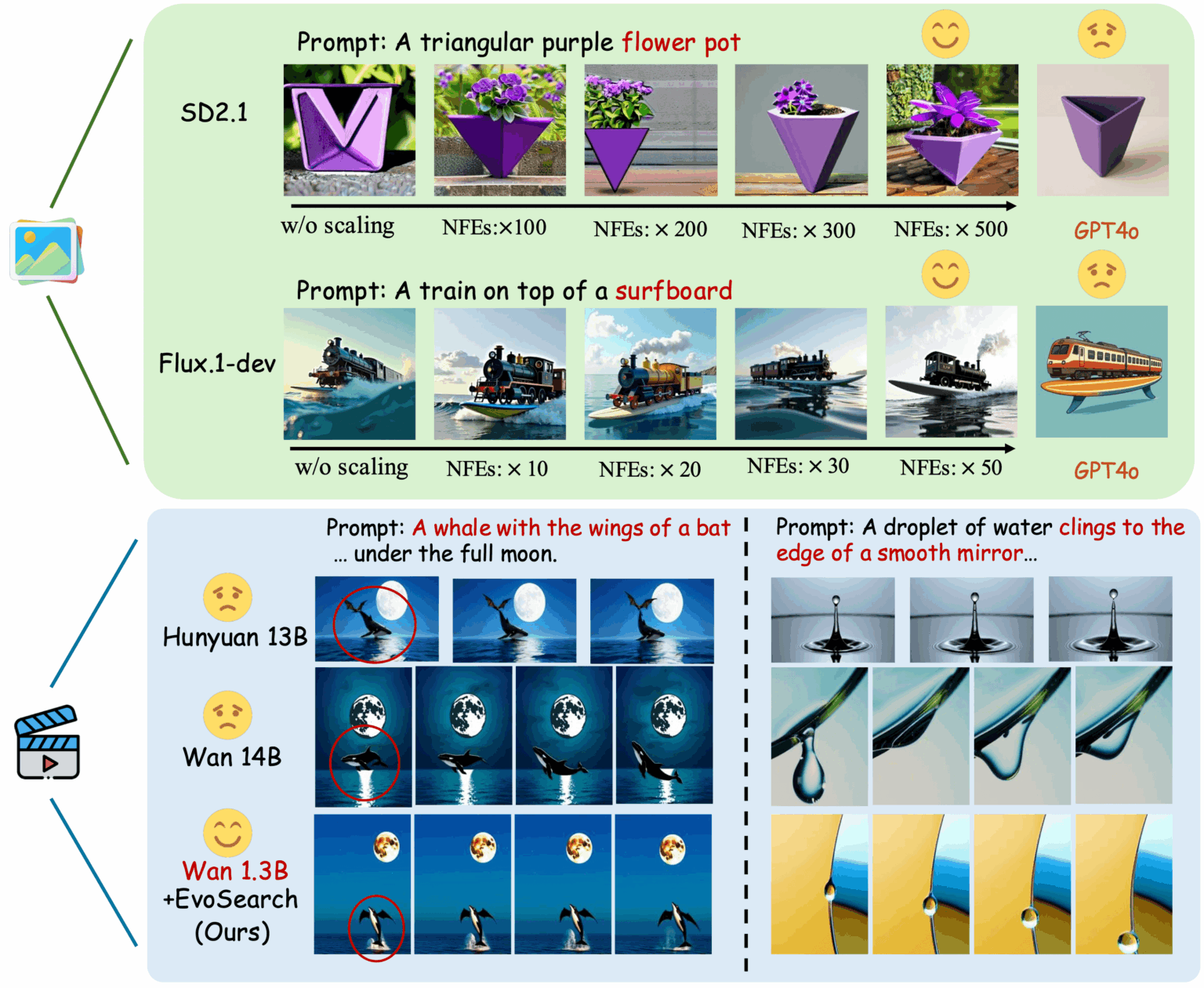
1. EvoSearch-Codes: Evolutionäres Algorithmus-Framework
EvoSearch-Codes ist eine evolutionäre Suchmethode, die von der Hong Kong University of Science and Technology und dem Kuaishou Keling-Team entwickelt wurde. Sie verbessert die Generierungsqualität des Modells deutlich, indem sie den Rechenaufwand während der Inferenz erhöht, die Bild- und Videogenerierung unterstützt und die fortschrittlichsten diffusions- und flussbasierten Modelle unterstützt. Das Modell kann bei einer Reihe von Aufgaben ohne Training oder Gradientenaktualisierungen signifikant optimale Ergebnisse erzielen und weist gute Skalierbarkeit, Robustheit und Generalisierung auf.
Online ausführen:https://go.hyper.ai/zjzrE
Tutorial für große Modelle
1. Jan-Nano: Ein kompaktes forschungsspezifisches Sprachmodell
Jan-Nano ist ein leichtes, großes Sprachmodell mit 4 Milliarden Parametern, das am 1. Juli 2025 vom Menlo Research-Team veröffentlicht wurde. Es ist für tiefgreifende Forschungsaufgaben konzipiert und für den Model Context Protocol (MCP)-Server optimiert, um eine effiziente Integration mit einer Vielzahl von Forschungstools und Datenquellen zu ermöglichen.
Online ausführen:https://go.hyper.ai/mC8gx
💡Wir haben außerdem eine Austauschgruppe für Tutorials zur stabilen Diffusion eingerichtet. Willkommen, Freunde, scannen Sie den QR-Code und kommentieren Sie [SD-Tutorial], um der Gruppe beizutreten, verschiedene technische Probleme zu besprechen und Anwendungsergebnisse auszutauschen~

Die Zeitungsempfehlung dieser Woche
1. Testzeitskalierung mit reflektierendem generativem Modell
Dieses Dokument stellt MetaStone-S1 vor, das erste reflektierende generative Modell, das durch ein selbstüberwachtes Prozessbelohnungsmodell (SPRM) das Leistungsniveau von OpenAI o3 erreicht. Durch die gemeinsame Nutzung des Backbone-Netzwerks und die Verwendung aufgabenspezifischer Köpfe für die nächste Token-Vorhersage bzw. die Prozessbewertung integriert SPRM das Richtlinienmodell und das Prozessbelohnungsmodell (PRM) erfolgreich in eine einheitliche Schnittstelle, ohne dass zusätzliche Prozessannotationen erforderlich sind. Dadurch werden die PRM-Parameter um mehr als 99% reduziert und eine effiziente Inferenz erreicht.
Link zum Artikel:https://go.hyper.ai/zFLhf
2. Open Vision Reasoner: Übertragung sprachlich-kognitiven Verhaltens auf visuelles Denken
Dieses Papier schlägt ein zweistufiges Paradigma basierend auf Qwen2.5-VL-7B vor: Zunächst wird die Sprache im Kaltstart feinabgestimmt, gefolgt von fast 1000 Schritten multimodalen Reinforcement Learnings (RL), das alle bisherigen Open-Source-Versuche übertrifft. Das finale Modell Open-Vision-Reasoner (OVR) erreicht Spitzenleistungen bei verschiedenen Reasoning-Benchmarks, darunter 95,31 TP3T bei MATH500, 51,81 TP3T bei MathVision und 54,61 TP3T bei MathVerse.
Link zum Artikel:https://go.hyper.ai/WucU8
3. Argumentation oder Auswendiglernen? Unzuverlässige Ergebnisse des bestärkenden Lernens aufgrund von Datenkontamination
Die Forscher stellten fest, dass Qwen2.5 zwar gute mathematische Ergebnisse liefert, durch das Vortraining auf einem umfangreichen Webkorpus jedoch anfällig für Datenkontaminationen in gängigen Benchmarks ist, was wiederum die Zuverlässigkeit der Ergebnisse dieser Benchmarks beeinträchtigt. Um dieses Problem zu lösen, führten die Forscher einen Generator ein, der vollständig synthetische Rechenaufgaben beliebiger Länge und Schwierigkeit generieren kann, was zu einem sauberen Datensatz namens RandomCalculation führt. Mithilfe dieser leckfreien Datensätze wird bewiesen, dass nur präzise Belohnungssignale die Leistung kontinuierlich verbessern können, während verrauschte oder fehlerhafte Signale dies nicht können.
Link zum Artikel:https://go.hyper.ai/WZp4V
4. NeuralOS: Auf dem Weg zur Simulation von Betriebssystemen mithilfe neuronaler generativer Modelle
Dieses Dokument stellt NeuralOS vor, ein neuronales Framework, das die grafische Benutzeroberfläche (GUI) eines Betriebssystems simuliert, indem es Bildschirmbilder als Reaktion auf Benutzereingaben wie Mausbewegungen, Klicks und Tastatureingaben direkt vorhersagt. NeuralOS kombiniert ein rekurrentes neuronales Netzwerk (RNN) zur Verfolgung des Computerzustands und einen diffusionsbasierten neuronalen Renderer zur Generierung von Bildschirmbildern. Es bietet einen Weg zur Entwicklung vollständig adaptiver, generativer neuronaler Schnittstellen für zukünftige Mensch-Computer-Interaktionssysteme.
Link zum Artikel:https://go.hyper.ai/hceCb
5. CLiFT: Komprimierte Lichtfeld-Token für recheneffizientes und adaptives neuronales Rendering
In diesem Artikel schlagen wir eine neuronale Rendering-Methode vor, die Szenen als „Compressed Light Field Tokens (CLiFTs)“ darstellt und so das detailreiche Erscheinungsbild und die Geometrie der Szene bewahrt. CLiFT erreicht durch die Verwendung komprimierter Token ein rechnerisch effizientes Rendering und ermöglicht gleichzeitig die Änderung der Tokenanzahl in einem einzelnen trainierten Netzwerk, um die Szene darzustellen oder neue Perspektiven zu rendern.
Link zum Artikel:https://go.hyper.ai/aqzHX
Weitere Artikel zu den Grenzen der KI:https://go.hyper.ai/iSYSZ
Interpretation von Gemeinschaftsartikeln
Ein gemeinsames Forschungsteam von Meta FAIR, der Universität Cambridge und dem MIT entwickelte den All-Atom-Diffusion-Transformer ADiT, der die Modellierungsbarrieren zwischen periodischen und nichtperiodischen Systemen durchbrach. Dank zweier wichtiger Innovationen – der einheitlichen latenten Darstellung aller Atome und der latenten Diffusion des Transformers – gelang ein Durchbruch bei der Erzeugung von Molekülen und Kristallen mit einem einzigen Modell.
Den vollständigen Bericht ansehen:https://go.hyper.ai/Dnw5r
Das Team der Stanford University und des Arc Institute in Palo Alto, Kalifornien, schlugen gemeinsam eine neue Methode zur Proteinsequenzierung vor: FAMPNN (Full-Atom MPNN). Diese Methode kann die Sequenzidentität und Seitenkettenstruktur jedes Aminosäurerests explizit modellieren. Das Modell nutzt eine Nachrichtenübermittlungsarchitektur auf Basis von Graph-Neural-Networks, kombiniert mit verbesserten MPNN- und GVP-Modulen für die Vollatomkodierung. Dadurch können Hauptketten- und Seitenketteninformationen von Proteinen gleichzeitig verarbeitet werden.
Den vollständigen Bericht ansehen:https://go.hyper.ai/x04Am
Die Stanford University hat in Zusammenarbeit mit Genentech, dem Arc Institute, der UCSF und anderen Institutionen den ersten allgemeinen biomedizinischen KI-Agenten namens Biomni entwickelt. Dieser kann autonom eine breite Palette von Forschungsaufgaben in verschiedenen biomedizinischen Teilbereichen durchführen und den ersten einheitlichen Umweltagenten erstellen. Dazu nutzt er die notwendigen Werkzeuge, Datenbanken und Lösungen aus Zehntausenden von Publikationen in 25 biomedizinischen Bereichen. System-Benchmarks zeigen, dass Biomni eine starke Generalisierung bei heterogenen biomedizinischen Aufgaben ohne aufgabenspezifisches Prompt-Tuning erreicht.
Den vollständigen Bericht ansehen:https://go.hyper.ai/VHpMD
Am 5. Juli ging der 7. Meet AI Compiler Technology Salon von HyperAI erfolgreich zu Ende. Dong Zhaohua, Senior Director von Muxi Integrated Circuit, erläuterte ausführlich die Anwendung von TVM auf Muxi-GPUs, stellte die technischen Merkmale seiner GPU-Produkte, TVM-Compiler-Anpassungslösungen, konkrete Anwendungsfälle und die Vision einer ökologischen Konstruktion vor und demonstrierte die technologischen Durchbrüche und das Anwendungspotenzial inländischer GPUs in den Bereichen Hochleistungsrechnen und KI.
Den vollständigen Bericht ansehen:https://go.hyper.ai/rxxX3
Das Forschungsteam von NVIDIA hat in Zusammenarbeit mit Mila vom Quebec Institute for Artificial Intelligence in Kanada La-Proteina entwickelt, eine Proteindesignmethode auf atomarer Ebene, die auf partiellem Latentfluss-Matching basiert. Sie befasst sich mit der zentralen Herausforderung der Dimensionsvariabilität expliziter Seitenkettendarstellungen während der Proteingenerierung und bringt neue Durchbrüche im Bereich des Proteindesigns.
Den vollständigen Bericht ansehen:https://go.hyper.ai/0Sw8R
Beliebte Enzyklopädieartikel
1. DALL-E
2. Reziproke Sortierfusion RRF
3. Pareto-Front
4. Umfangreiches Multitasking-Sprachverständnis (MMLU)
5. Kontrastives Lernen
Hier sind Hunderte von KI-bezogenen Begriffen zusammengestellt, die Ihnen helfen sollen, „künstliche Intelligenz“ zu verstehen:
Juli-Frist für den Gipfel
11. Juli 7:59:59 POPL 2026
15. Juli 7:59:59 SODA 2026
18. Juli 7:59:59 SIGMOD 2026
19. Juli 7:59:59 ICSE 2026
Zentrale Verfolgung der wichtigsten wissenschaftlichen KI-Konferenzen:https://go.hyper.ai/event
Das Obige ist der gesamte Inhalt der Auswahl des Herausgebers dieser Woche. Wenn Sie über Ressourcen verfügen, die Sie auf der offiziellen Website von hyper.ai veröffentlichen möchten, können Sie uns auch gerne eine Nachricht hinterlassen oder einen Artikel einreichen!
Bis nächste Woche!








