Command Palette
Search for a command to run...
Ausgewählt Für ICML 2025! Die Harvard Medical School Und Andere Haben Das Weltweit Erste Klinische Mindmap-Modell Im HIE-Bereich Eingeführt, Mit Einer Leistungssteigerung Von 15% Bei Aufgaben Zur Vorhersage Neurokognitiver Ergebnisse

Während die Technologie der künstlichen Intelligenz sprunghafte Fortschritte macht, verändern groß angelegte Vision-Language-Modelle (LVLMs) die kognitiven Grenzen zahlreicher Bereiche mit erstaunlicher Geschwindigkeit.Im Bereich der natürlichen Bild- und VideoanalyseDieser Modelltyp stützt sich auf eine fortschrittliche neuronale Netzwerkarchitektur, umfangreiche gekennzeichnete Datensätze und leistungsstarke Computerunterstützung und kann anspruchsvolle Aufgaben wie Objekterkennung und Szenenanalyse präzise erledigen.Im Bereich der natürlichen SprachverarbeitungDurch das Lernen aus Textkorpora auf TB-Ebene hat LVLMs professionelle Leistung bei Aufgaben wie maschineller Übersetzung, Textzusammenfassung und Stimmungsanalyse erreicht. Die generierten wissenschaftlichen Abstracts können sogar die Kernaussagen der medizinischen Literatur präzise extrahieren.
Mit dem Vordringen der Technologie in den medizinischen Bereich stößt die Implementierung von LVLMs jedoch auf erheblichen Widerstand. Obwohl der Bedarf an intelligenter Hilfsdiagnose in klinischen Szenarien äußerst dringend ist, befindet sich die medizinische Anwendung solcher Modelle noch in der ersten Erkundungsphase.Der zentrale Engpass ergibt sich aus den einzigartigen Eigenschaften medizinischer Daten:Aufgrund zahlreicher Einschränkungen, wie etwa Bestimmungen zum Schutz der Privatsphäre von Patienten, Inseleffekten bei medizinischen Daten und Mechanismen zur ethischen Überprüfung, beträgt der Umfang öffentlich verfügbarer medizinischer Datensätze hoher Qualität nur ein Zehntausendstel des Umfangs im allgemeinen Bereich.Die meisten vorhandenen medizinischen Datensätze verwenden grundlegende visuelle Frage- und Antwortarchitekturen und konzentrieren sich auf primäre Mustererkennungsaufgaben wie „Welche anatomische Struktur ist das?“——Beispielsweise enthält ein öffentlicher Datensatz 200.000 Röntgenanmerkungen, aber der Anmerkungsinhalt von 90% bleibt auf der Ebene der Organlokalisierung und kann keine zentralen klinischen Anforderungen wie die Einstufung des Schweregrads von Läsionen und die Bewertung des Prognoserisikos berühren.
Diese Diskrepanz zwischen Datenangebot und tatsächlichem Bedarf führt dazu, dass das Modell zwar bei MRT-Bildern einer neonatalen hypoxisch-ischämischen Enzephalopathie (HIE) abnorme Signale in den Basalganglien erkennen kann, jedoch nicht in der Lage ist, mehrdimensionale Informationen wie das Gestationsalter und die perinatale Krankengeschichte zu integrieren, um eine Prognose der neurologischen Entwicklung zu erstellen.
Um dieses Dilemma zu lösen, sammelte ein interdisziplinäres Team des Boston Children's Hospital, der Harvard Medical School, der New York University und des MIT-IBM Watson Laboratory zehn Jahre lang MRT-Bilder und Experteninterpretationen von 133 Personen mit hypoxisch-ischämischer Enzephalopathie (HIE).Konstruierte einen Benchmark-Datensatz für medizinisches Denken auf professionellem Niveau,Ziel ist es, die Denkleistung von LVLMs in medizinischen Berufsfeldern genau zu bewerten.Das Forschungsteam schlug außerdem ein klinisches Mindmap-Modell (CGoT) vor.Die Möglichkeit, den Diagnoseprozess durch klinisch wissensbasierte Mind-Mapping-Eingabeaufforderungen zu simulieren, ermöglicht die Einbeziehung domänenspezifischen klinischen Wissens als visuelle und textuelle Eingaben, wodurch die Vorhersagekraft von LVLMs erheblich verbessert wird.
Die entsprechenden Forschungsergebnisse mit dem Titel „Visual and Domain Knowledge for Professional-level Graph-of-Thought Medical Reasoning“ wurden erfolgreich für ICML 2025 ausgewählt.
Forschungshighlights:
* Erstellen Sie einen neuen HIE-Benchmark-Test für das medizinische Denken, der erstmals klinische visuelle Wahrnehmung mit professionellem medizinischem Wissen kombiniert, den klinischen Entscheidungsprozess simuliert und die professionelle Leistung von LVLMs im medizinischen Denken genau bewertet.
* Umfassender Vergleich fortgeschrittener allgemeiner und medizinischer LVLMs, um ihre Einschränkungen im Hinblick auf medizinisches Fachwissen aufzuzeigen und Hinweise zur Modellverbesserung zu geben.
* Das CGoT-Modell wurde vorgeschlagen, das medizinisches Fachwissen mit LVLMs integriert, den klinischen Entscheidungsprozess nachahmt und die medizinische Entscheidungsunterstützung effektiv verbessert.

Papieradresse:
https://openreview.net/forum?id=tnyxtaSve5
Weitere Artikel zu den Grenzen der KI:
https://go.hyper.ai/owxf6
Das Open-Source-Projekt „awesome-ai4s“ vereint mehr als 100 AI4S-Papierinterpretationen und stellt umfangreiche Datensätze und Tools bereit:
https://github.com/hyperai/awesome-ai4s
HIE-Reasoning: Aufbau multimodaler Datensätze und Erstellung eines professionellen Reasoning-Aufgabensystems
In Bezug auf die Datenkonstruktion konzentriert sich diese Studie auf die hypoxisch-ischämische Enzephalopathie (HIE), eine schwere Neugeborenenerkrankung.Über einen Zeitraum von 10 Jahren wurden hochwertige MRT-Bilder von 133 HIE-Kindern im Alter von 0–14 Tagen gesammelt.Erhalten Sie gleichzeitig klinisch validierte Interpretationsberichte von multidisziplinären Experten (darunter ein leitender Neuroradiologe mit 30 Jahren Erfahrung), um einen Kerndatensatz für die Längsschnittverfolgung zu bilden.
Wie in der folgenden Abbildung dargestellt, haben die Forscher sechs Aufgaben für LVLMs definiert, um professionelles klinisches Denken durchzuführen:
* Aufgabe 1: Läsionsgradierung.Die Aufgabe quantifiziert Hirnschäden, indem sie den Prozentsatz des von HIE-Läsionen betroffenen Hirnvolumens schätzt und die Schwere der Läsionen beurteilt.
* Aufgabe 2: Läsionsanatomie.Diese Aufgabe identifiziert den spezifischen Bereich des Gehirns, der von der Läsion betroffen ist.
* Mission 3: Läsion an seltenen Orten.Mit dieser Aufgabe werden durch HIE verursachte Läsionen identifiziert und die betroffenen Bereiche als häufig oder selten klassifiziert. Auf diese Weise lässt sich leichter feststellen, ob der Patient zusätzliche Aufmerksamkeit benötigt.
* Aufgabe 4: MRI-Verletzungswert.Die Aufgabe gibt einen Gesamtverletzungswert aus der MRT aus und bietet ein standardisiertes Maß für die Schwere der Verletzung, um die Behandlung zu steuern und das Ergebnis vorherzusagen.
* Aufgabe 5: Neurokognitives Ergebnis nach 2 Jahren.Die Aufgabe sagt die neurokognitiven Ergebnisse der Patienten zwei Jahre später voraus und hilft Klinikern, langfristige Auswirkungen vorherzusehen und geeignete Interventionen zu planen.
* Aufgabe 6: Zusammenfassung der MRT-Interpretation.Die Aufgabe basiert auf einer von Radiologen empfohlenen MRT-Zusammenfassungsvorlage für Neugeborene und kann eine umfassende MRT-Interpretation für den Patienten erstellen.
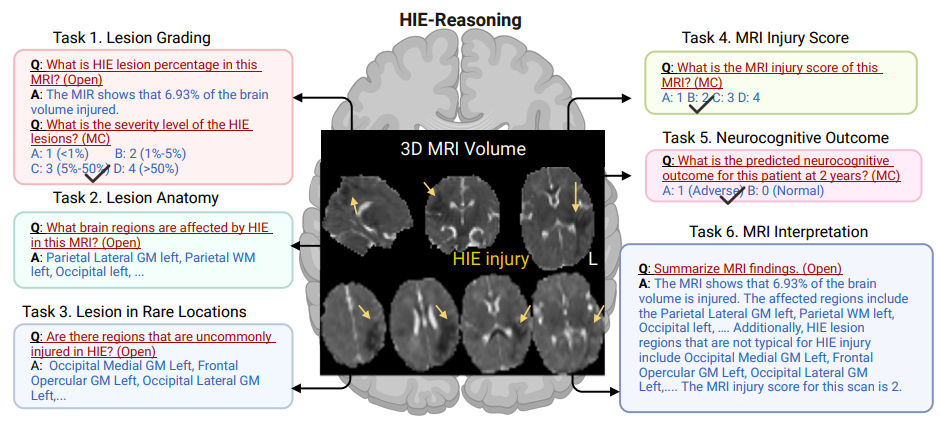
Finale,Die Forscher erstellten den weltweit ersten öffentlichen HIE-Datensatz, HIE-Reasoning, der 749 Frage-Antwort-Paare und 133 MRT-Interpretationszusammenfassungen enthält.Im Gegensatz zu traditionellen medizinischen Datensätzen wie VQAmed und OmiMed-VQA, die sich auf grundlegende Fragen wie die Erkennung bildgebender Verfahren und die Positionierung von Organen konzentrieren,Dieser Datensatz wandelt den tiefgreifenden Denkprozess klinischer Experten erstmals in ein berechenbares Bewertungssystem um.Die innovative Datenstruktur basiert auf einer dreischichtigen Architektur: Originalbilder und Aufgabendateien auf Patientenebene, fallübergreifende Vorlagen für Metawissensschlussfolgerungen und individuelle Läsionswahrscheinlichkeitskarten. Dadurch bleibt nicht nur die Integrität der medizinischen Daten gewahrt, sondern das Modell erhält auch expliziten Wissensinput, einschließlich pathologischer Mechanismen.
Obwohl die Stichprobengröße nur 133 Fälle betrug, wurde durch eine 17-jährige (2001-2018) multizentrische retrospektive Erhebung, kombiniert mit der geringen Inzidenz von HIE in Tertiärkrankenhäusern von 1-5‰,Dieser Datensatz ist der erste HIE-spezifische Benchmark, der bildgebende, klinische und prognostische multimodale Informationen integriert.Seine Kennzeichnungsgenauigkeit und klinische Tiefe reichen aus, um die Skalenbeschränkungen auszugleichen, und stellen einen unverzichtbaren Maßstab für LVLMs dar, um den Engpass der „grundlegenden Identifizierung“ zu überwinden und in die tiefen Gewässer der Diagnose- und Behandlungsentscheidung vorzudringen.
CGoT-Modell: Angetrieben von einer klinischen Denkkarte, die einen neuen Rahmen für interpretierbares hierarchisches medizinisches Denken schafft
Um den Engpass bei der Interpretierbarkeit herkömmlicher groß angelegter visueller Sprachmodelle (LVLMs) in der medizinischen Argumentation (siehe Abbildung A unten) zu überwinden, schlug das Forschungsteam das Clinical Goal Map Model (CGoT) vor, wie in Abbildung BC unten dargestellt. Durch die Integration klinischen Wissens zur Steuerung des Sprachmodells bei der Simulation des ärztlichen Diagnoseprozesses kann die Zuverlässigkeit der Vorhersage neurokognitiver Ergebnisse deutlich verbessert werden.Dieses Modell verwendet auf innovative Weise eine strukturierte „Reasoning Mind Map“., indem die Diagnoseschritte medizinischer Experten in eine hierarchische Argumentationskette umgewandelt werden, um komplexe Aufgaben durch schrittweise Ansammlung von Wissen zu lösen.
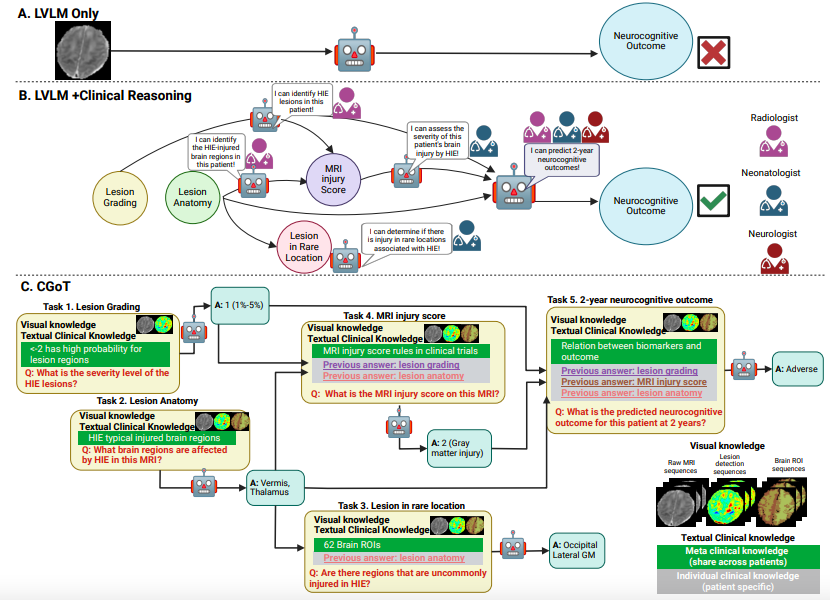
Das Textwissen ist in metaklinisches Wissen (einschließlich allgemeinmedizinischem Hintergrund wie anatomischen Karten des Gehirns, Läsionsverteilungsmustern, Assoziationen zu MRT-Biomarkern und Prognosen usw.) und individuelles klinisches Wissen (patientenspezifische diagnostische Hinweise, die dynamisch aus den Ergebnissen früherer Aufgaben generiert werden) unterteilt. Die beiden Wissensarten werden strukturiert und in einer zeitnahen technischen Weise eingegeben, um LVLM dabei zu unterstützen, schrittweise gemäß der logischen Kette „klinische Richtlinien – bildgebende Merkmale – individuelle Krankengeschichte“ Ableitungen vorzunehmen.
Das gesamte Framework transformiert implizite medizinische Diagnoselogik in berechenbaren Modell-Input, indem es strukturierte Eingabeaufforderungen klinischer Graphen mit modalübergreifendem Wissen integriert. Dadurch bleiben nicht nur die modalübergreifenden Verarbeitungsfähigkeiten von LVLMs erhalten, sondern durch die Verankerung klinischen Wissens wird auch die Zufälligkeit des Denkprozesses vermieden.
Die Leistungsbewertung des klinischen Denkens von CGoT erzielt bahnbrechende Verbesserungen bei Schlüsselaufgaben
Um die Wirksamkeit des HIE-Reasoning-Benchmarks und des CGoT-Modells zu überprüfen, entwickelte das Forschungsteam ein mehrdimensionales experimentelles System.
Erste,Die Forscher führten Zero-Shot-Evaluierungen an sechs groß angelegten visuellen Sprachmodellen durch.Drei Typen allgemeiner LVLMs (Gemini1.5-Flash, GPT4o-Mini, GPT4o) und drei Typen medizinischer LVLMs (MiniGPT4-Med, LLava-Med, Med-Flamingo) wurden als Basismodelle ausgewählt. Sechs wichtige klinische Aufgaben, darunter Läsionsgradierung, anatomische Lokalisierung und Prognosevorhersage, wurden anhand aufgabenspezifischer Indikatoren wie Genauigkeit, MAE, F1-Score und ROUGE-L bewertet. Die zweijährige neurokognitive Ergebnisvorhersage nutzte die durchschnittliche Genauigkeit zwischen den Kategorien, um die Label-Verteilungsverzerrung auszugleichen.
Die experimentellen Ergebnisse verdeutlichen die erheblichen Einschränkungen herkömmlicher LVLMs: Bei der direkten Eingabe von MRT-Schnitten und Aufgabenbeschreibungen schneiden alle Basismodelle bei professionellen medizinischen Denkaufgaben schlecht ab. Einige Modelle reagieren halluzinogen oder verweigern aufgrund mangelnder klinischer Kenntnisse konservativ die Antwort. Beispielsweise generiert Med-Flamingo bei anatomischen Positionierungsaufgaben bedeutungslose, repetitive Inhalte, und die GPT4o-Reihe kann aufgrund ihrer Ausrichtungsstrategie Probleme mit hoher Unsicherheit nicht bewältigen.
Im krassen Gegensatz dazu, wie in der folgenden Tabelle gezeigt,Das CGoT-Modell erzielt bahnbrechende Verbesserungen bei Schlüsselaufgaben durch die Integration klinischer Mindmaps und modalübergreifenden Wissens——Insbesondere im Hinblick auf den klinischen Kernbedarf der Vorhersage einer Zweijahresprognose ist die Leistung im Vergleich zum Basismodell um mehr als 15% verbessert, und auch die Genauigkeit und Konsistenz von Aufgaben wie der Läsionsklassifizierung und der Verletzungsbewertung sind deutlich besser als bei der Kontrollgruppe.
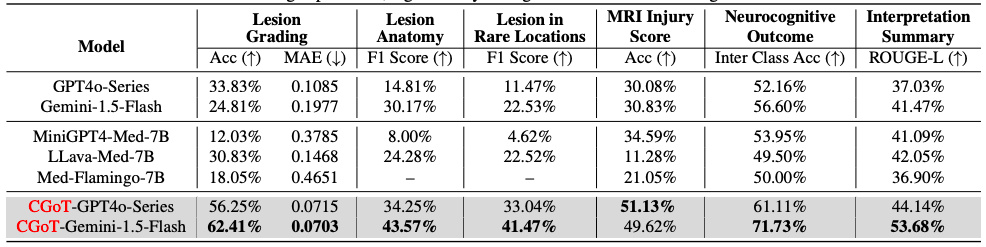
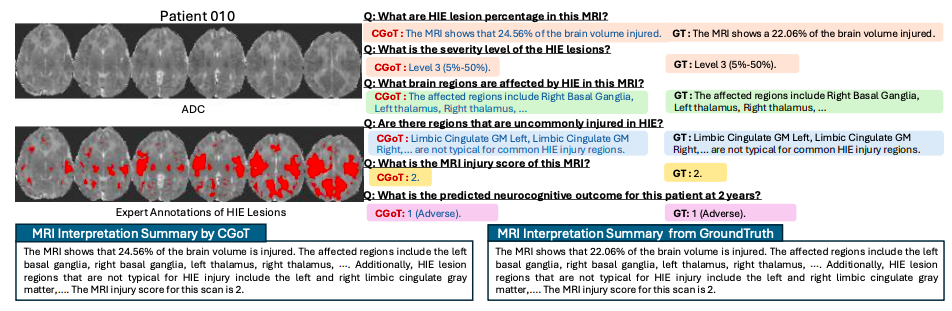
Gleichzeitig zeigen Robustheitsexperimente, dass selbst bei ±1-Stufenfehlern in den Zwischenaufgabenergebnissen von 10%-30% die Modellleistung nur allmählich abnimmt. Dies belegt die Fähigkeit des Modells, sich an das in der klinischen Praxis übliche Datenrauschen anzupassen. Zusammengenommen deuten diese Ergebnisse darauf hin, dassDurch die Simulation des hierarchischen Denkprozesses der klinischen Diagnose durchbricht CGoT nicht nur die Wissensblindstellen traditioneller Modelle, sondern erstellt auch ein zuverlässiges Entscheidungsunterstützungssystem, das realen Diagnose- und Behandlungsszenarien nahe kommt.
Der Doppelradantrieb medizinischer LVLMs: innovative Praktiken und Trends in Wissenschaft und Wirtschaft
Weltweit erleben die Forschung und Anwendung großer Vision-Language-Modelle (LVLMs) im medizinischen Bereich einen Paradigmenwechsel, und innovative Verfahren in der Wissenschaft und der Geschäftswelt treiben gemeinsam Durchbrüche in diesem Bereich voran.
Auf akademischer Forschungsebene hat das Shanghai Artificial Intelligence Laboratory zusammen mit der University of Washington, der Monash University, der East China Normal University und anderen Forschungseinrichtungen den GMAI-MMBench-Benchmark-Test veröffentlicht.Es integriert 284 Datensätze zu klinischen Aufgaben und deckt 38 medizinische Bildgebungsverfahren und 18 zentrale klinische Anforderungen ab (wie etwa Tumordiagnose, Neurobildgebungsanalyse usw.).Der Benchmark verwendet ein Vokabelbaum-Klassifizierungssystem, um Fälle genau nach Abteilung, Modalität und Aufgabentyp zu klassifizieren und so einen standardisierten Rahmen für die Bewertung der klinischen Argumentationsfähigkeit von LVLMs bereitzustellen.
* Klicken Sie hier, um den vollständigen Bericht anzuzeigen: Shanghai AI Lab und andere haben den multimodalen medizinischen Benchmark GMAI-MMBench veröffentlicht, der 284 Datensätze enthält und 18 klinische Aufgaben abdeckt.
Darüber hinaus führt Med-R1, das gemeinsam von der Emory University, der University of Southern California, der University of Tokyo und der Johns Hopkins University entwickelt wurde, auf innovative Weise die gruppenrelative Richtlinienoptimierung (GRPO) ein, um die Einschränkungen traditioneller Methoden der überwachten Feinabstimmung (SFT) zu beheben.Stabile Richtlinienaktualisierungen durch Regelbelohnungen und Gruppenvergleiche ohne komplexe Wertmodelle.Open-Source-LVLMs wie MedDr, das von der Hong Kong University of Science and Technology eingeführt wurde, haben bei bestimmten Aufgaben (wie etwa der Läsionsgradierung) eine Leistung erreicht, die kommerziellen Modellen nahekommt, und zeigen damit das Potenzial des Open-Source-Ökosystems im Bereich der medizinischen KI.
Die Wirtschaft beschleunigt die klinische Transformation von LVLMs, wobei die Implementierung von Technologie im Mittelpunkt steht. Beispielsweise hat die Microsoft Azure Medical Cloud Platform durch die Integration von KI-Tools und klinischen Daten eine umfassende Integration der medizinischen Bildanalyse, der Automatisierung elektronischer Patientenakten und anderer Funktionen erreicht. Das intelligente Radiologiesystem, das sie in Zusammenarbeit mit vielen Krankenhäusern entwickelt hat, istMöglichkeit, durch LVLMs schnell abnormale Bereiche in MRT-Bildern zu identifizieren und strukturierte Berichte zu erstellen.Unterstützen Sie Ärzte bei der Einstufung von Läsionen und der anatomischen Positionierung.
Google hat das Open-Source-Medizinmodell MedGemma auf den Markt gebracht. Es basiert auf der Gemma3-Architektur und ist speziell für den Medizin- und Gesundheitsbereich konzipiert. Ziel ist es, medizinische Anwendungen zu verbessern und die Effizienz medizinischer Diagnose und Behandlung durch die nahtlose Kombination der Analyse medizinischer Bilder und Textdaten zu steigern.
* Klicken Sie hier für einen ausführlichen Bericht: Google veröffentlicht MedGemma, basierend auf Gemma 3, spezialisiert auf medizinisches Text- und Bildverständnis
Zusammengenommen zeigen diese Praktiken zwei Haupttrends in der Entwicklung medizinischer LVLMs:Erstens die tiefe Integration von klinischem Wissen und Modellarchitektur.Beispielsweise das Aufgabensystem, das durch Expertenannotationen im in diesem Artikel beschriebenen HIE-Reasoning-Benchmark erstellt wurde, und die durch das CGoT-Modell eingeführte klinische Denkkarte;Der zweite Punkt ist Innovation in der interdisziplinären Zusammenarbeit und Datenverwaltung.GMAI-MMBench beispielsweise integriert globale Datensätze durch einheitliche Annotationsformate und ethische Compliance-Prozesse und bietet so ein Modell zur Lösung des medizinischen Datenmangels. Durch die weitere Anwendung von Technologien wie föderiertem Lernen und der Generierung synthetischer Daten dürften Wissenschaft und Wirtschaft künftig Durchbrüche in komplexeren klinischen Szenarien (wie multimodaler Prognosevorhersage und chirurgischer Navigation in Echtzeit) erzielen und so die Transformation der KI vom Hilfsmittel zum intelligenten Entscheidungspartner vorantreiben.
Referenzartikel:
1.https://blog.csdn.net/Python_cocola/article/details/146590017
2.https://mp.weixin.qq.com/s/0SGHeV8OcXu8kFk68f-7Ww








