Command Palette
Search for a command to run...
Das Team Von Zhiyuan, Der Peking-Universität Und Der Beijing University of Posts and Telecommunications Wurde Für Die NeurIPS 2025 Ausgewählt Und Hat Ein Multi-Stream-Control-Videogenerierungsframework Vorgeschlagen, Das Eine Präzise Audiovisuelle Synchronisation Auf Basis Von Audio-Demixing erreicht.

Im Vergleich zu Text besitzt Audio eine inhärente, kontinuierliche zeitliche Struktur und reichhaltige dynamische Informationen, was eine präzisere zeitliche Steuerung bei der Videogenerierung ermöglicht. Daher hat sich die audiobasierte Videogenerierung mit der Entwicklung von Videogenerierungsmodellen zunehmend zu einem wichtigen Forschungsgebiet im Bereich der multimodalen Generierung entwickelt. Aktuelle Forschungsarbeiten umfassen verschiedene Szenarien wie Sprecheranimationen, musikbasierte Videos und die audiovisuelle Synchronisation; die Erzielung einer stabilen und präzisen audiovisuellen Ausrichtung in komplexen Videoinhalten bleibt jedoch eine große Herausforderung.
Die Hauptbeschränkung bestehender Methoden liegt in der Art und Weise, wie Audiosignale modelliert werden. Die meisten Modelle betrachten das Eingangsaudio als ganzheitliche Bedingung im Generierungsprozess und vernachlässigen dabei die funktionalen Rollen verschiedener Audiokomponenten wie Sprache, Soundeffekte und Musik auf visueller Ebene. Dieser Ansatz reduziert die Modellierungskomplexität zwar bis zu einem gewissen Grad.Dies führt jedoch auch zu einer Verwischung der Grenzen zwischen Audio und Visual, wodurch es schwierig wird, gleichzeitig die Anforderungen an Lippensynchronisation, zeitliche Abstimmung der Ereignisse und die Kontrolle der gesamten visuellen Atmosphäre zu erfüllen.
Um dieses Problem zu beheben,Die Beijing Academy of Artificial Intelligence, die Peking University und die Beijing University of Posts and Telecommunications haben gemeinsam einen Rahmen für die audiovisuelle synchronisierte Videoerzeugung auf Basis von Audio-Demixing vorgeschlagen.Das Eingangsaudio wird in drei Audiospuren aufgeteilt: Sprache, Soundeffekte und Musik. Jede Spur steuert unterschiedliche Ebenen der visuellen Generierung. Dieses Framework erzielt durch ein Multi-Stream-Temporal-Control-Netzwerk sowie einen entsprechenden Datensatz und eine Trainingsstrategie eine präzisere audiovisuelle Korrespondenz auf zeitlicher und globaler Ebene. Experimentelle Daten belegen, dass diese Methode stabile Verbesserungen in Videoqualität, audiovisueller Ausrichtung und Lippensynchronisation erzielt und somit die Effektivität von Audio-Demixing und Multi-Stream-Control bei komplexen Videogenerierungsaufgaben bestätigt.
Die zugehörigen Forschungsergebnisse mit dem Titel „Audio-Sync Video Generation with Multi-Stream Temporal Control“ wurden für die NeurIPS 2025 ausgewählt.
Papieradresse:
https://arxiv.org/abs/2506.08003
Forschungshighlights:
* Wir erstellen den DEMIX-Datensatz, der aus fünf sich überschneidenden Teilmengen für die audio-synchronisierte Videogenerierung besteht, und schlagen eine mehrstufige Trainingsstrategie zum Erlernen audiovisueller Beziehungen vor.
* Schlägt ein MTV-Framework vor, das Audio in drei Spuren unterteilt: Sprache, Soundeffekte und Musik. Diese Spuren steuern verschiedene visuelle Elemente wie Lippenbewegungen, Ereigniszeitpunkt und die gesamte visuelle Atmosphäre und ermöglichen so eine präzisere semantische Steuerung.
* Entwurf eines Multi-Stream-Zeitsteuerungsnetzwerks (MST-ControlNet) zur gleichzeitigen Feinsynchronisation lokaler Zeitintervalle und globaler Stilanpassung innerhalb desselben Generierungsrahmens, das strukturell die differenzierte Steuerung verschiedener Audiokomponenten auf einer Zeitskala unterstützt.
Multifunktionale Stromerzeugungsfähigkeit
MTV verfügt über multifunktionale Generierungsmöglichkeiten, wie z. B. charakterzentrierte Erzählungen, Interaktionen zwischen mehreren Charakteren, geräuschausgelöste Ereignisse, durch Musik erzeugte Atmosphäre und Kamerabewegungen.
Der DEMIX-Datensatz führt entmischte Track-Annotationen ein, um ein phasenweises Training zu ermöglichen.
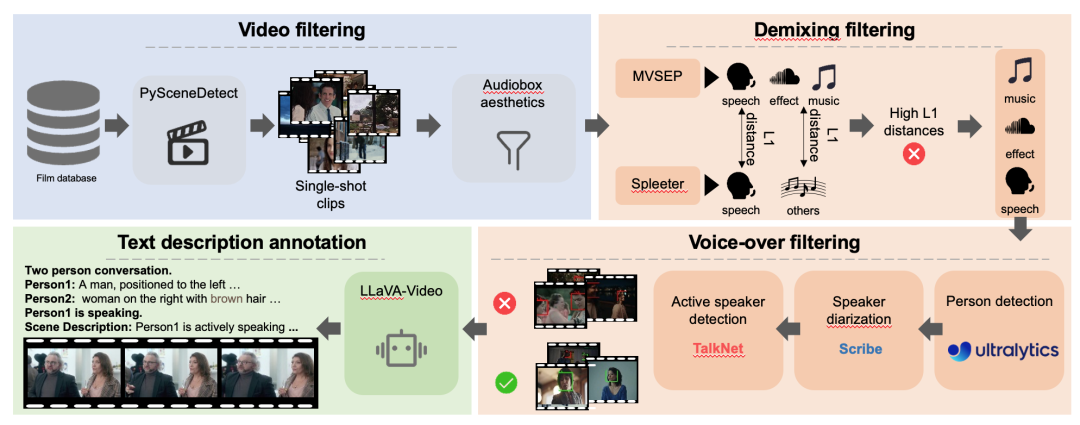
In dieser Arbeit wird zunächst der DEMIX-Datensatz durch einen detaillierten Filterprozess gewonnen. Die gefilterten DEMIX-Daten werden anschließend in fünf sich überschneidende Teilmengen strukturiert:Grundlegende Gesichtszüge, Effekte für Einzelpersonen, Effekte für mehrere Personen, Geräuscheffekte und Umgebungsatmosphäre. Basierend auf fünf sich überschneidenden Teilmengen.In diesem Beitrag wird eine mehrstufige Trainingsstrategie vorgestellt.Das Modell wird schrittweise skaliert. Zunächst wird es anhand eines grundlegenden Gesichtsdatensatzes trainiert, um Lippenbewegungen zu erlernen. Anschließend lernt es anhand eines Datensatzes mit einer einzelnen Person die menschliche Pose, das Erscheinungsbild der Szene und die Kamerabewegung. Danach wird es anhand eines Datensatzes mit mehreren Personen trainiert, um komplexe Szenen mit mehreren Sprechern zu verarbeiten. Im nächsten Schritt verlagert sich der Trainingsschwerpunkt auf das Timing von Ereignissen, und das Verständnis des Subjekts wird mithilfe eines Datensatzes mit Ereignisgeräuschen von Menschen auf Objekte erweitert. Schließlich wird das Modell anhand eines Datensatzes mit Umgebungsgeräuschen trainiert, um seine Darstellung visueller Emotionen zu verbessern.
Durch einen Multi-Stream-Timing-Steuerungsmechanismus werden eine präzise audiovisuelle Zuordnung und eine genaue Zeitausrichtung erreicht.
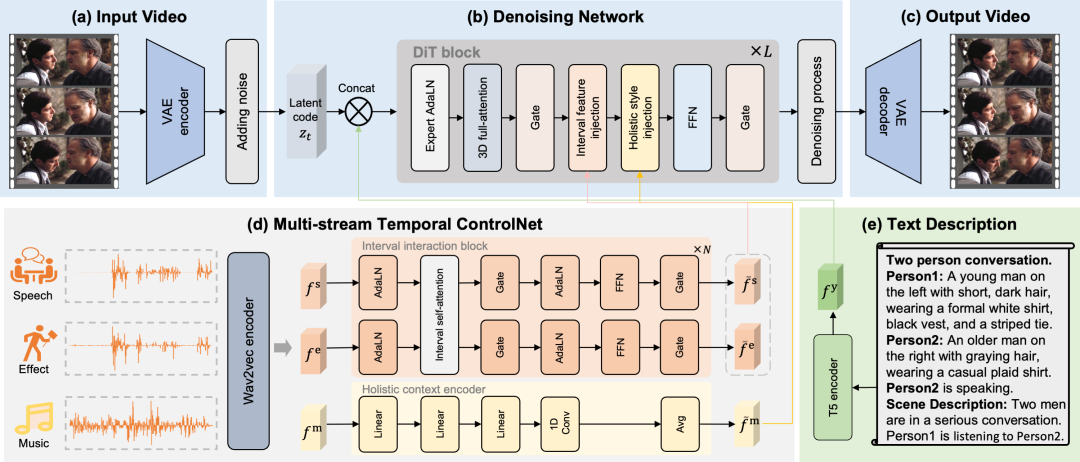
Dieser Artikel unterteilt Audio explizit in drei verschiedene Kontrollspuren: Sprache, Soundeffekte und Musik.Diese separaten Tonspuren ermöglichen es dem MTV-Framework, Lippenbewegungen, Ereigniszeitpunkte und visuelle Emotionen präzise zu steuern und so das Problem der mehrdeutigen Zuordnung zu lösen. Um das MTV-Framework für verschiedene Aufgaben nutzbar zu machen, wird in diesem Beitrag eine Vorlage zur Erstellung der Textbeschreibung entwickelt. Diese Vorlage beginnt mit einem Satz, der die Anzahl der Teilnehmer angibt, z. B. „Gespräch zwischen zwei Personen“. Anschließend werden die einzelnen Personen aufgelistet, beginnend mit einer eindeutigen Kennung (Person1, Person2) und einer kurzen Beschreibung ihres Aussehens. Nach der Auflistung der Teilnehmer identifiziert die Vorlage explizit die aktuell sprechende Person. Abschließend liefert ein Satz eine allgemeine Beschreibung der Szene. Um eine präzise zeitliche Ausrichtung zu erreichen, schlägt dieser Beitrag ein Multi-Stream-Zeitsteuerungsnetzwerk vor, das Lippenbewegungen, Ereigniszeitpunkte und visuelle Emotionen durch explizit getrennte Sprach-, Effekt- und Musikspuren steuert.
Intervallmerkmaleinfügung
Bezüglich Sprach- und SoundeffektfunktionenDiese Arbeit entwirft einen Intervallablauf, um Lippenbewegungen und Ereigniszeitpunkte präzise zu steuern.Die Merkmale jeder Audiospur werden durch das Intervallinteraktionsmodul extrahiert, und die Interaktion zwischen Sprache und Soundeffekten wird durch den Selbstaufmerksamkeitsmechanismus simuliert. Schließlich werden die interaktiven Sprach- und Soundeffektmerkmale mittels Kreuzaufmerksamkeit in jedes Zeitintervall eingefügt; dies wird als Intervallmerkmaleinfügungsmechanismus bezeichnet.
Globale Feature-Einspeisung
In Bezug auf musikalische Merkmale,Diese Arbeit entwirft einen Gesamtablauf zur Steuerung der visuellen Emotionen des gesamten Videosegments.Da musikalische Merkmale Ausdruck der Gesamtästhetik sind, wird zunächst die visuelle Gesamtwirkung der Musik mithilfe eines globalen Kontext-Encoders extrahiert. Anschließend wird Average Pooling angewendet, um die globalen Merkmale des gesamten Segments zu gewinnen. Schließlich werden diese globalen Merkmale als Einbettungen verwendet, und der latente Videocode wird mithilfe von AdaLN moduliert. Dies wird als Mechanismus zur globalen Merkmalseinspeisung bezeichnet.
Erzeugt präzise audio-synchronisierte Videos in Kinoqualität.
Indikatoren für eine umfassende Bewertung
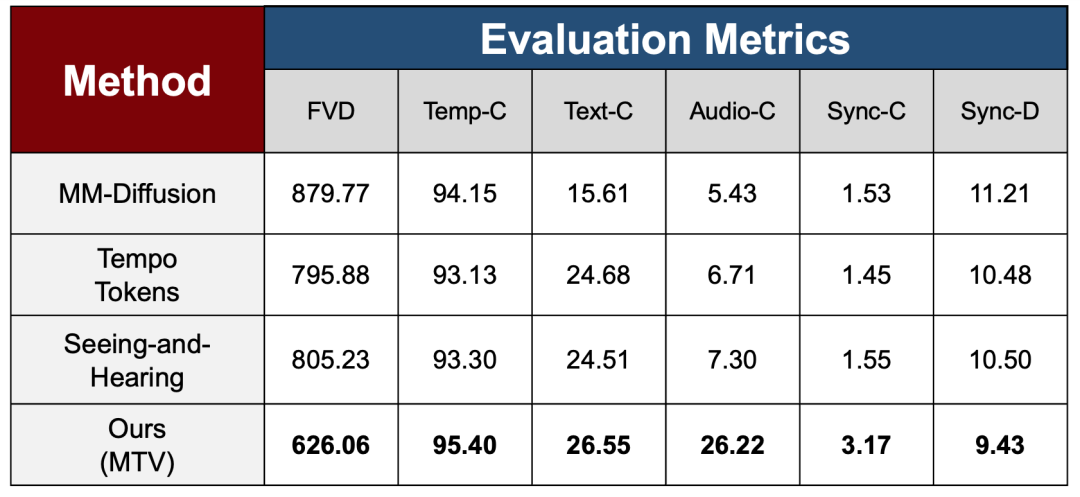
Um die Effektivität der mehrstufigen Trainingsstrategie in verschiedenen Lernphasen zu überprüfen, verwendet die Arbeit im experimentellen Teil eine Reihe umfassender Bewertungsmetriken, die Videoqualität, zeitliche Konsistenz und multimodale Ausrichtungsfähigkeit abdecken, um die Gesamtstabilität und Konsistenzleistung des Modells nach der schrittweisen Einführung komplexer Steuersignale systematisch zu bewerten und mit drei State-of-the-Art-Methoden zu vergleichen.
Hinsichtlich der Generierungsqualität und der zeitlichen Stabilität verwendet die Studie FVD, um die Verteilungsunterschiede zwischen generierten und realen Videos zu messen, und Temp-C, um die zeitliche Kontinuität zwischen benachbarten Frames zu bewerten. Die Ergebnisse zeigen, dass MTV bestehende Methoden bei FVD deutlich übertrifft. Dies deutet darauf hin, dass das Modell die Gesamtgenerierungsqualität nicht beeinträchtigt und gleichzeitig eine hohe zeitliche Stabilität bei Temp-C beibehält, selbst bei Einführung einer komplexeren Audiosteuerung.
Auf der Ebene der multimodalen Ausrichtung misst die Studie die Übereinstimmung zwischen Video und Text/Audio mithilfe der Metriken Text-C bzw. Audio-C. MTV zeigte eine signifikante Verbesserung in der Audio-C-Metrik, die die Vergleichsmethoden deutlich übertraf. Dies spiegelt die Wirksamkeit der Audio-Demixing- und Multi-Stream-Steuerungsmechanismen zur Verbesserung der audiovisuellen Korrespondenz wider.
Um die wichtigsten Probleme in sprachgesteuerten Szenarien anzugehen, werden in diesem Beitrag zwei Synchronisationsmetriken, Sync-C und Sync-D, eingeführt, um das Synchronisationsvertrauen bzw. die Fehlergröße zu bewerten und eine optimale Leistung zu erzielen.
Vergleichsergebnisse

Wie in der obigen Abbildung dargestellt, verglichen die Forscher das MTV-Framework mit den aktuellen Stand der Technik (SOTA). Aus visueller Sicht weisen bestehende Methoden im Allgemeinen eine unzureichende Stabilität bei der Verarbeitung komplexer Textbeschreibungen oder filmischer Szenen auf.
Selbst nach der Feinabstimmung von MM-Diffusion über 320.000 Schritte auf acht NVIDIA A100 GPUs mithilfe des offiziellen Codes gelingt es dem Verfahren beispielsweise nicht, visuell kohärente und narrativ strukturierte Bilder zu erzeugen. Der Gesamtstil wirkt eher fragmentiert. TempoTokens hingegen neigt dazu, in komplexen Szenen, insbesondere bei mehreren Personen oder in HDR-Szenarien, unnatürliche Gesichtsausdrücke und Bewegungen zu erzeugen, was den Realismus der Ergebnisse erheblich beeinträchtigt. Auch die audiovisuelle Synchronisation bereitet dem Verfahren von Xing et al. Schwierigkeiten, bestimmte Ereignissequenzen synchron zu gestalten, was zu Darstellungsfehlern bei den Gesten der Spielfiguren während des Gitarrenspiels führt (siehe Abbildung oben rechts).
Im Gegensatz dazu kann das MTV-Framework in verschiedenen Szenarien eine hohe visuelle Qualität und eine stabile audiovisuelle Synchronisation gewährleisten und präzise audio-synchronisierte Videos in Kinoqualität erzeugen.
Referenzlinks:
1.https://arxiv.org/abs/2506.08003








