Command Palette
Search for a command to run...
Team Der Purdue University Erreicht Dateneffiziente Taktile Darstellung Für Roboterlernen Durch Simulation Des Reaktiven Greifens Des Menschen

Auf dem Weg der Roboter zum autonomen Lernen ist die Berührung ein unverzichtbarer Bestandteil, da sie den Maschinen die Fähigkeit verleiht, Details der physischen Welt wahrzunehmen. Das Training herkömmlicher taktiler Wahrnehmungssysteme beruht jedoch häufig auf der Erfassung großer Datenmengen, was kostspielig und ineffizient ist. Da die Grenzen datenbasierter Ansätze deutlich werden,Die Frage, wie sich die Leistungsfähigkeit des taktilen Lernens durch eine effiziente Datendarstellung verbessern lässt, ist zu einem Schwerpunkt der aktuellen Robotikforschung geworden.
In den letzten Jahren sind innovative Technologien auf Basis von selbstüberwachtem Lernen, spärlicher Darstellung und modalübergreifender Wahrnehmung schnell entstanden und liefern neue Ideen für die Vereinfachung und Optimierung der taktilen Darstellung.

Durchbrüche in diesem Bereich werden es Robotern nicht nur ermöglichen, sich schnell an komplexe Aufgaben mit begrenzten Daten anzupassen, sondern auch ihre Fähigkeit zur Interaktion mit Menschen und der Umwelt deutlich verbessern.Bei diesem revolutionären Wandel öffnet die dateneffiziente taktile Darstellungstechnologie neue Türen für die Wahrnehmung und das Lernen von Robotern.
Am 18. Dezember fand beim vierten Online-Sharing-Event „Newcomers on the Frontier“ der Embodied Touch Community statt, das von HyperAI mitorganisiert wurde.Xu Zhengtong, ein Doktorand im dritten Jahr an der Purdue University, teilte die beiden wichtigsten wissenschaftlichen Forschungsergebnisse von LeTac-MPC und UniT sowie ihre technischen Forschungswege mit allen zum Thema „Dateneffiziente taktile Darstellung für Roboterlernen“.
HyperAI hat die ausführlichen Ausführungen von Dr. Xu Zhengtong zusammengestellt und zusammengefasst, ohne die ursprüngliche Absicht zu verletzen.
Differenzierbare Optimierung ist ein leistungsstarkes Werkzeug beim Roboterlernen
Die Optimierung ist ein sehr wichtiges und effizientes Werkzeug im Bereich der Robotik und hat viele hervorragende Ergebnisse bei der Trajektorienplanung und der Mensch-Computer-Interaktion gezeigt.Bevor wir über die Optimierung sprechen,Zunächst müssen wir ein Konzept einführen: Differenzierbare Optimierung.Um dieses Konzept zu erklären, beginnen wir mit der allgemeinen Formulierung von Optimierungsproblemen.
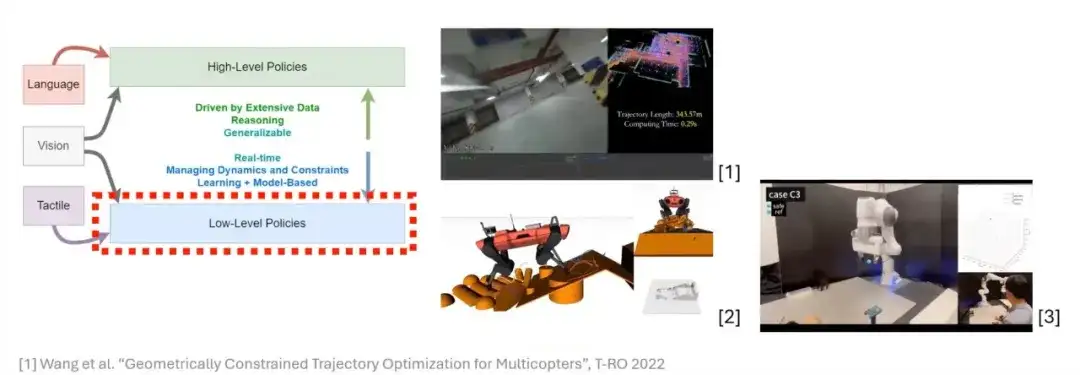
Die Kernidee der Optimierung besteht darin, eine Zielfunktion (Kostenfunktion) für bestimmte Anwendungsszenarien zu konstruieren.Diese Zielfunktionen beinhalten normalerweise viel Vorwissen und können einer Reihe von Einschränkungen unterliegen. Daher ist es bei der Formulierung von Optimierungsproblemen häufig erforderlich, diese Einschränkungen der Zielfunktion hinzuzufügen.
Nächste,Wir konzentrieren uns auf eine grundlegende Form der Optimierung – die Quadratische Programmierung (QP).Es handelt sich um eine der einfachsten Formen im Bereich der Optimierung und bietet dennoch vielfältige Anwendungsszenarien in der Praxis.

Auf dieser Grundlage führen wir den Begriff „differenzierbar“ ein. Das sogenannte Differenzieren bedeutet, dass in einem neuronalen Netzwerk die Ausgabe einer Schicht partielle Ableitungen ihrer internen Parameter berechnen kann.Die Bedeutung der Einführung der Differenzierbaren Quadratischen Programmierung (Differentiable QP) liegt darin, dassWenn wir einem neuronalen Netzwerk eine Optimierungsschicht hinzufügen möchten, müssen wir sicherstellen, dass die Schicht differenzierbar ist. Nur auf diese Weise können die Parameter der Optimierungsschicht während des Netzwerktrainings und der Inferenz auf natürliche Weise aktualisiert und durch Gradienteninformationen fließen. Wenn es uns also gelingt, das quadratische Programmierproblem differenzierbar zu machen, können wir es in das neuronale Netzwerk integrieren und zu einem Teil des Netzwerks machen.
Darüber hinaus basieren Optimierungsprobleme beim Roboterlernen häufig auf Vorwissen in bestimmten Szenarien, beispielsweise der Gestaltung von Zielfunktionen und Einschränkungen. Durch die Formulierung eines differenzierbaren Optimierungsproblems können wir dieses Vorwissen voll ausnutzen und effizient in die Modellentwicklung integrieren. In manchen Fällen ist es uns jedoch möglicherweise nicht möglich, das Problem modellbasiert zu beschreiben (d. h. wir können keine modellbasierte Darstellung erstellen). In diesem ZusammenhangSie können versuchen, datengesteuerte Methoden zu verwenden, damit das Modell die Regeln dieser Teile selbst lernt. Dies ist die Kernidee differenzierbarer Optimierungsprobleme.
Zusammenfassend lässt sich sagen, dass das quadratische Programmierproblem die Eigenschaft hat, differenzierbar zu sein, sodass wir es als Teil des neuronalen Netzwerks einführen können.Dieser Ansatz bietet nicht nur neue Tools für das Netzwerkdesign, sondern verleiht dem Modelldesign im Roboterlernen auch mehr Flexibilität und Möglichkeiten.
LeTac-MPC: Forschung zu reaktivem Greifen und Modellsteuerungsmethoden basierend auf taktilen Signalen
Wir schlagen ein Konzept namens „Reaktives Greifen“ vor.Durch die Beobachtung des menschlichen Greifvorgangs nach Objekten haben wir festgestellt, dass Menschen die Eigenschaften und Zustände von Objekten normalerweise über ihre Finger wahrnehmen und die Bewegungen ihrer Finger anhand der Rückmeldung anpassen. Zum Beispiel:
* Wenn wir ein Ei greifen, empfinden wir es als hart, aber zerbrechlich und wenden daher die entsprechende Kraft an, um Schäden zu vermeiden. Wenn der Rückkopplungsdruck der Finger zunimmt, schwächen wir unseren Griff.
* Da das Brot weich ist, wird beim Greifen eines Stücks Brot die Bewegung Ihrer Finger entsprechend angepasst, um ein Zusammendrücken und Verformen des Brots zu verhindern.
* Wenn Sie eine Milchflasche greifen und diese schütteln, verändert das Schütteln der Milch die Trägheit des Objekts. Die Finger spüren diese Veränderungen und passen ihre Greifbewegung dynamisch an, um zu verhindern, dass die Flasche aufgrund der Trägheit verrutscht.

Implementierung eines reaktiven Greifroboters
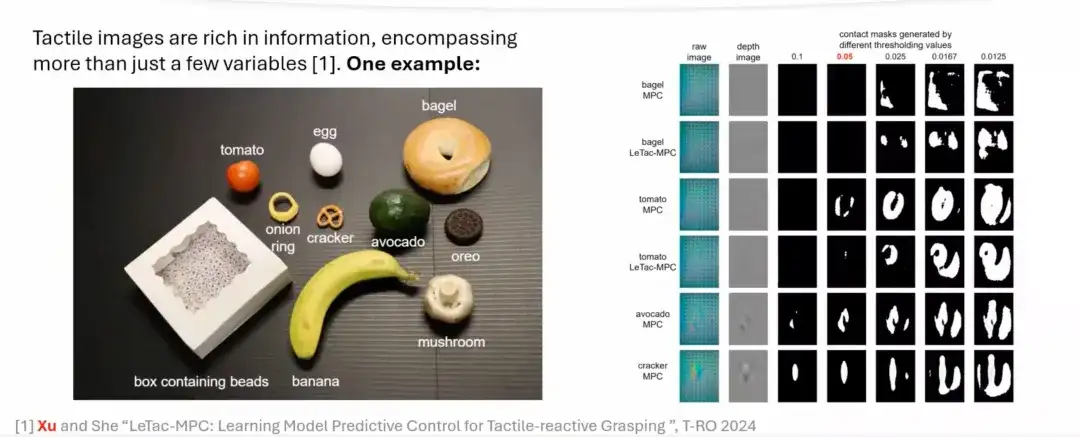
Ausgehend vom menschlichen Greifprozess untersuchen wir, wie dieser Prozess durch einen modellbasierten Ansatz simuliert werden kann.Mit visuellen Tastsensoren wie GelSight,Wir können Schlüsselmerkmale aus dem Originalbild extrahieren, durch einfache Verarbeitung ein Tiefenbild oder ein Differenzbild erzeugen und die Kontaktfläche durch eine Schwellenwertoperation berechnen. Die Kontaktfläche kann die Größe der ausgeübten Kraft widerspiegeln. Je größer die Kraft, desto größer die Kontaktfläche; Je geringer die Kraft, desto kleiner die Kontaktfläche.
Darüber hinaus kann durch die Verwendung der optischen Flusstechnologie zur Verfolgung der Bewegung von Markierungen eine weitere wichtige Größe ermittelt werden: die Verschiebung.Diese Größe hängt mit der Seitenkraft zusammen. Durch die Kombination dieser Signale können wir eine Steuerungsmethode auf der Grundlage eines Proportional-Differential-Reglers (PD) konstruieren, um ein taktil-reaktives Greifen zu erreichen.
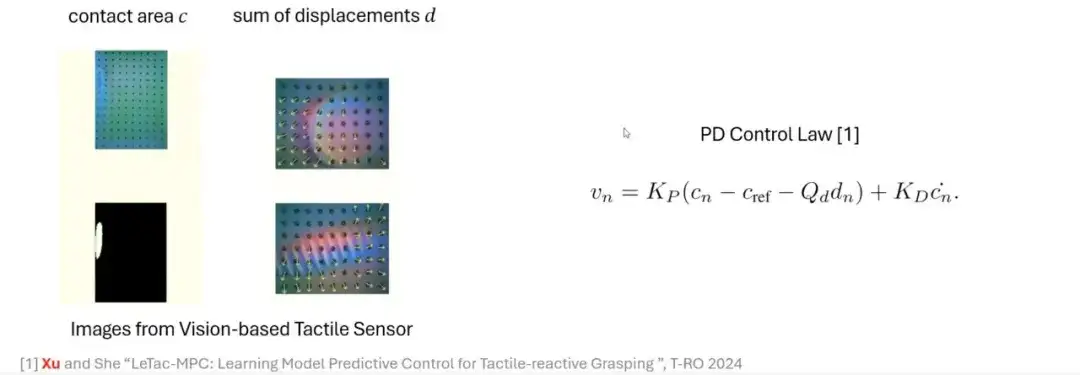
Vom PD-Regler zum MPC-Regler
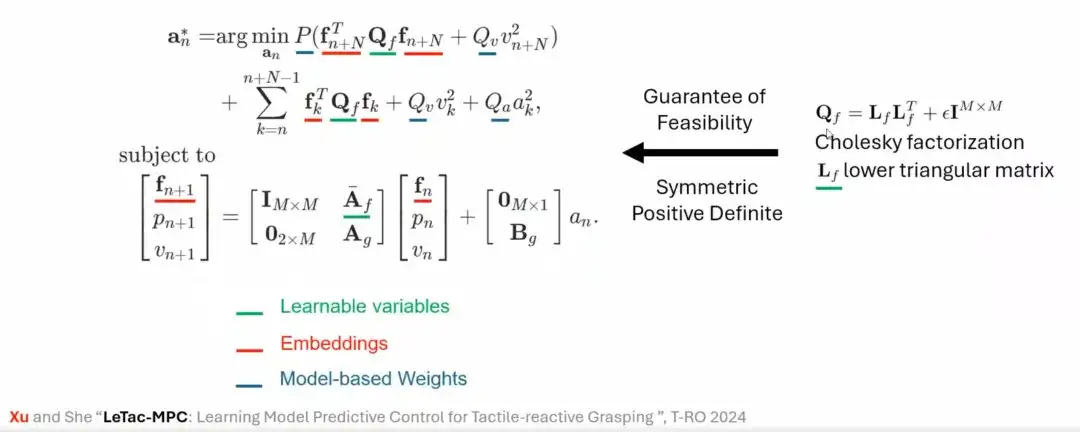
Zusätzlich zum PD-Regler haben wir auch eine Greifmethode basierend auf einem modellprädiktiven Regler (MPC) entwickelt. Das Steuerungsziel von MPC ähnelt dem des PD-Reglers, seine Eigenschaften basieren jedoch auf linearen Annahmen und dem Gripper-Modell. Beispielsweise werden zunächst die lineare Annahme und das Greiferbewegungsmodell mit einem Freiheitsgrad eingeführt, dann werden beide vereinheitlicht und modelliert und schließlich wird das MPC-basierte Steuergesetz erstellt.
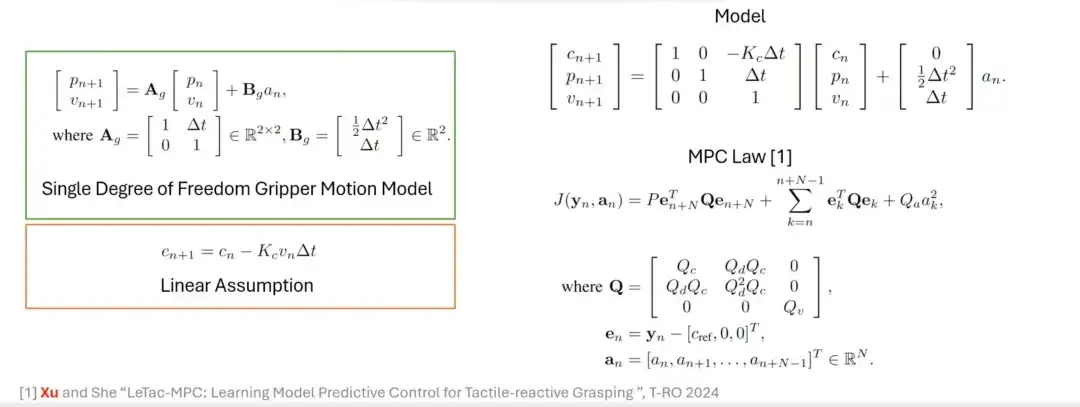
Anwendungen und Einschränkungen von MPC-Reglern
Das MPC-Reglermodell funktioniert in vielen Szenarien gut.Hier liste ich zwei Anwendungen auf.Die erste Anwendung ist,Beim Ziehen der Banane kann der Greifer die Kraft entsprechend der dynamischen Rückmeldung der Banane anpassen, um ein stabiles Greifen zu gewährleisten. Wenn die äußere Kraft entfernt wird (beispielsweise wenn eine Person die Banane loslässt), nähert sich der Controller allmählich einem stabilen Zustand.
Papieradresse:
https://ieeexplore.ieee.org/document/10684081
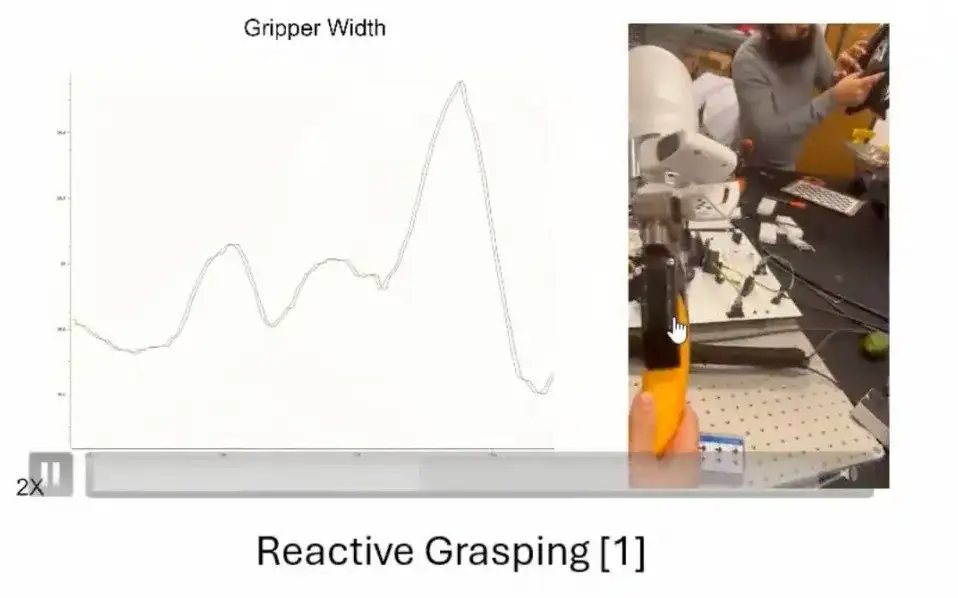
Die zweite Anwendung ist das von einem anderen Mitglied unserer Gruppe bei IROS vorgeschlagene Ergebnis.Das heißt, zur Realisierung komplexer Betriebsaufgaben wird ein Greifer mit mehreren Freiheitsgraden verwendet und der von uns vorgeschlagene MPC-Controller übernommen.
Papieradresse:
https://arxiv.org/abs/2408.00610

Allerdings unterliegen modellbasierte Regler gewissen Einschränkungen und lassen sich nur schwer auf die meisten Alltagsgegenstände im wirklichen Leben übertragen.Dies liegt vor allem an den vereinfachten Annahmen im Modellierungsprozess, die für einige reale Objekte oft nicht funktionieren. Wie in der folgenden Abbildung gezeigt, ist es bei weichen Objekten oder Objekten mit komplexen Formen schwierig, die Kontaktfläche durch einfaches Festlegen eines Schwellenwerts genau zu extrahieren. Bei härteren Objekten wie Avocados und Keksen sind die taktilen Signale (taktilen Bilder) jedoch stärker, sodass die Kontaktfläche genau erfasst werden kann.
Drei Hauptvorteile des LeTac-MPC-Controllers
Um dieses Problem zu lösen, verwenden wir mathematische Methoden (wie die Cholesky-Faktorisierung), um die Lösbarkeit des Optimierungsproblems sicherzustellen und so den Trainingsprozess des Controllers zu stabilisieren. Schließlich haben wir LeTac-MPC vorgeschlagen.
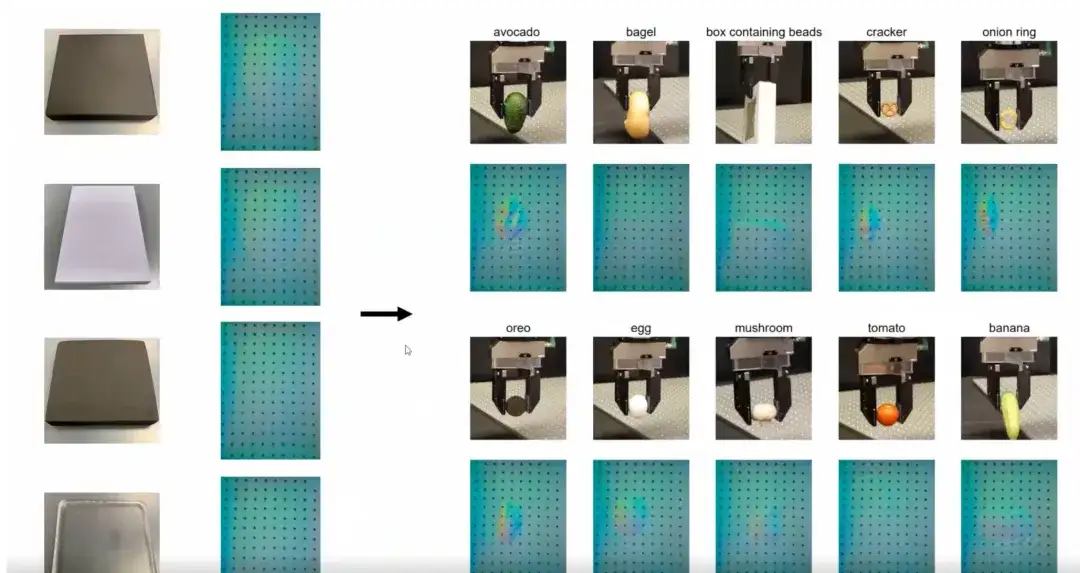
Die folgende Abbildung zeigt die intuitivsten Trainingsergebnisse. Wir haben mit einem Datensatz trainiert, der nur 4 Objekte mit unterschiedlicher Härte enthält. Diese Objekte haben unterschiedliche Steifigkeit. Trotz begrenzter Trainingsdaten trainieren wir Controller, die sich auf Alltagsgegenstände unterschiedlicher Größe, Form, Materialien und Beschaffenheit verallgemeinern lassen.Diese Generalisierungsfähigkeit auf Grundlage des Trainings mit kleinen Stichproben ist ein wesentlicher Vorteil des Controllers.
Zweitens trainieren wir den Controller, damit er robust gegenüber Störungen durch das gegriffene Objekt ist.Die Greifmethode und -stärke können in Echtzeit angepasst werden, sodass das gegriffene Objekt nicht aufgrund äußerer Störungen herunterfällt.
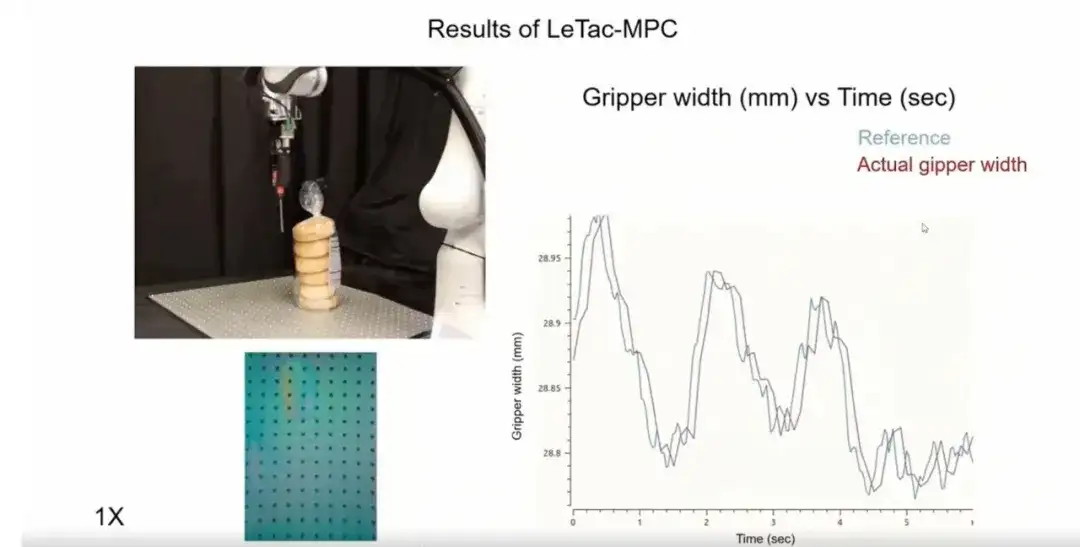
Drittens reagiert der von uns geschulte Controller sehr schnell.Wie in der folgenden Abbildung gezeigt, kann der Controller in Szenarien mit intensiver Bewegung oder Trägheitsänderungen (z. B. einer mit Schutt gefüllten Kiste) schnell auf die dynamischen Änderungen des Objekts reagieren.
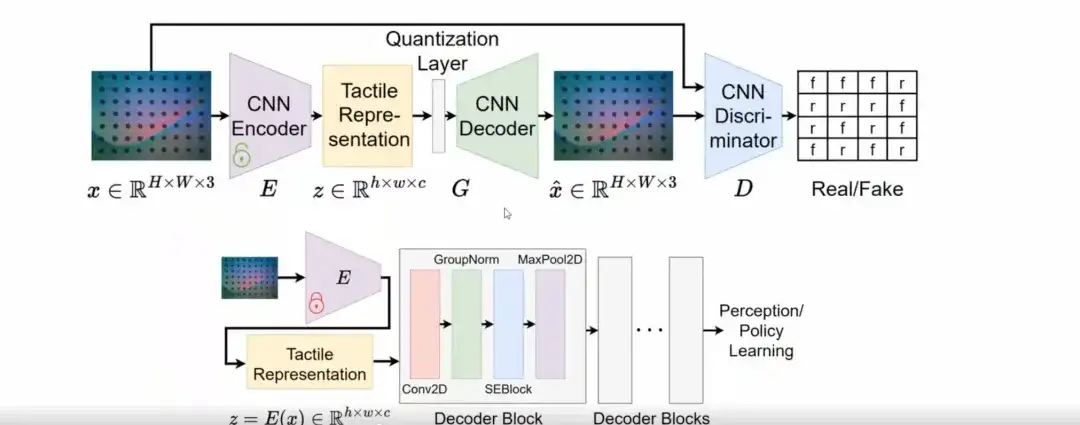
UniT: Einheitliche taktile Darstellung für Roboterlernen
In der obigen Untersuchung haben wir die Generalisierungsfähigkeit des Controllers erreicht. Können wir mithilfe eines einzigen einfachen Objekts eine einheitliche taktile Darstellung erlernen?
Wie in der Abbildung unten gezeigt, kann ein einzelnes einfaches Objekt ein geometrisch einfaches Objekt wie eine kleine Kugel oder ein Schraubenschlüssel (z. B. ein Inbusschlüssel) sein. Da die taktilen Bilder dieser Objekte relativ einfach sind, ist auch unsere Methode relativ einfach.

Konkret stellten wir fest, dass VQGAN, anstatt eine völlig neue Netzwerkstruktur zu entwerfen, taktile Darstellungen mit Generalisierungsfunktionen effektiv erlernen kann.
In der Trainingsphase übernehmen wir das VQGAN-Modell, um taktile Darstellungen zu erlernen. In der Inferenzphase wird der latente Raum von VQGAN durch eine einfache Faltungsschicht dekodiert, um eine Verbindung zu nachgelagerten Aufgaben wie Wahrnehmung oder Richtlinienlernen herzustellen.
Papieradresse:
https://arxiv.org/abs/2408.06481
Rekonstruktionsexperiment
Um die Wirksamkeit der Darstellung zu überprüfen, haben wir Rekonstruktionsexperimente mit Inbusschlüssel und kleiner Kugel durchgeführt.
Das erste ist das Inbusschlüssel-Experiment.Wie in der folgenden Abbildung gezeigt, können wir, obwohl die Trainingsdaten nur von Allen Key stammen, das Originalbild des unsichtbaren Objekts dennoch durch den latenten Raum rekonstruieren, was zeigt, dass der latente Raum die meisten nützlichen Informationen des Originalbilds enthält. Im Vergleich zu MAE stellen wir fest, dass es für MAE schwierig ist, das Originalbild genau zu rekonstruieren, was darauf hindeutet, dass es bei MAE während des Dekodierungsprozesses zu Informationsverlust kommen kann.

Das zweite ist das Small-Ball-Experiment.Wie in der folgenden Abbildung gezeigt, kann das Modell das ursprüngliche Signal komplexer Objekte bis zu einem gewissen Grad rekonstruieren, obwohl die Trainingsdaten nur von Small Ball stammen und der Rekonstruktionseffekt nicht so gut ist wie bei Inbusschlüssel.

Darüber hinaus erfasst der latente Raum nicht nur die taktilen geometrischen Informationen (wie Form und Kontaktkonfiguration), sondern enthält implizit auch die Bewegungsinformationen der Markierungen. Durch die Verfolgung der Markierungen des Originalbilds und des rekonstruierten Bilds haben wir beispielsweise festgestellt, dass ihre Leistung bei der Markierungsverfolgung sehr ähnlich ist.

Nachgelagerte Aufgaben und Benchmarks
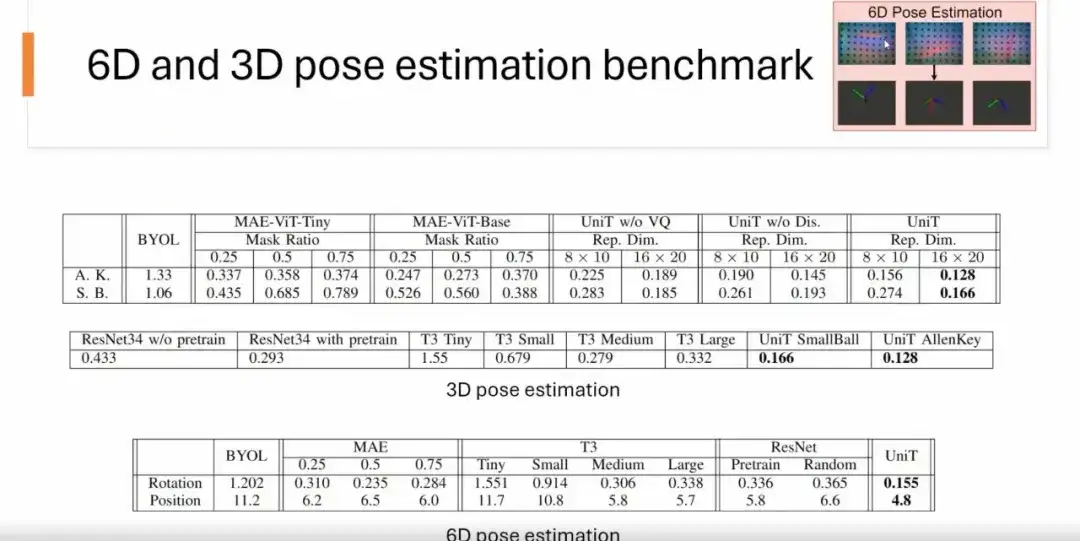
Wir haben die Darstellungsfähigkeiten der UniT-Methode anhand mehrerer Benchmarks getestet, darunter 6D-Pose-Schätzung, 3D-Pose-Schätzung und Klassifizierungs-Benchmarks.
Für die 6D-Pose-Schätzung,Wir geben ein taktiles Rohbild ein (z. B. ein taktiles Bild eines USB-Steckers), um seine Position und Drehung vorherzusagen. Die Ergebnisse zeigen, dass das UniT-Modell im Vergleich zu den Methoden MAE, BYOL, ResNet und T3 andere Methoden hinsichtlich der Genauigkeit übertrifft.
Zur 3D-Pose-Schätzung,Wir sagen nur die Rotationspose des Objekts voraus. Wie in der folgenden Abbildung gezeigt, ist die Leistung von UniT besser als bei anderen Methoden.
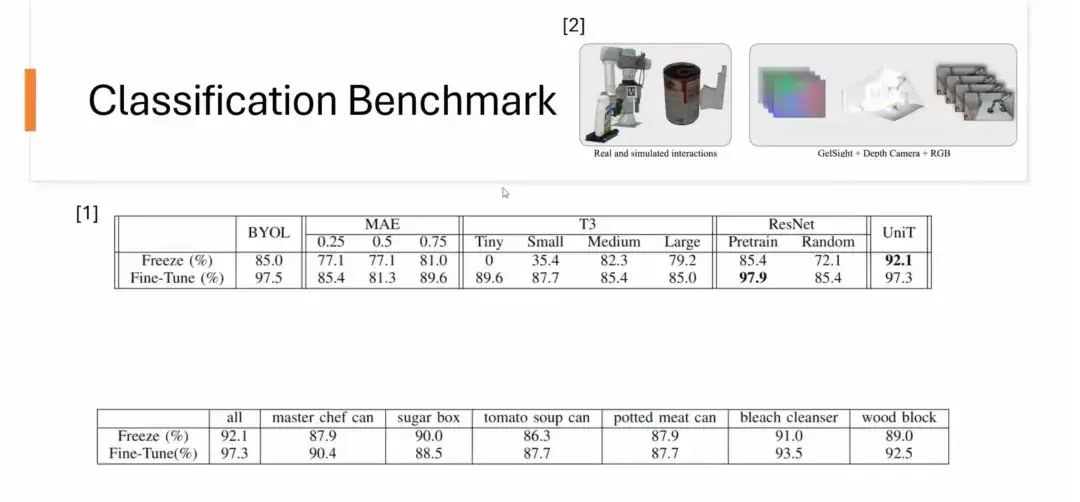
Zweitens haben wir auch einen Klassifizierungs-Benchmark durchgeführt.Der Datensatz stammt von YCBSight-Sim der CMU. Obwohl der Datensatz klein ist, zeigt UniT bei Klassifizierungsaufgaben eine gute Leistung. Insbesondere kann die taktile Darstellung eines einzelnen Objekts nach dem Erlernen dieser Methode auf natürliche Weise auf Klassifizierungsaufgaben anderer, nicht sichtbarer Objekte verallgemeinert werden. Beispielsweise kann eine Darstellung, die nur auf „Meisterkoch“ trainiert wurde, erfolgreich auf die Klassifizierung von 6 verschiedenen Objekten angewendet werden und liefert hervorragende Ergebnisse. Einige Darstellungen, die auf ein einzelnes Objekt trainiert wurden, sind sogar leistungsfähiger als solche, die auf eine große Anzahl von Objekten trainiert wurden.
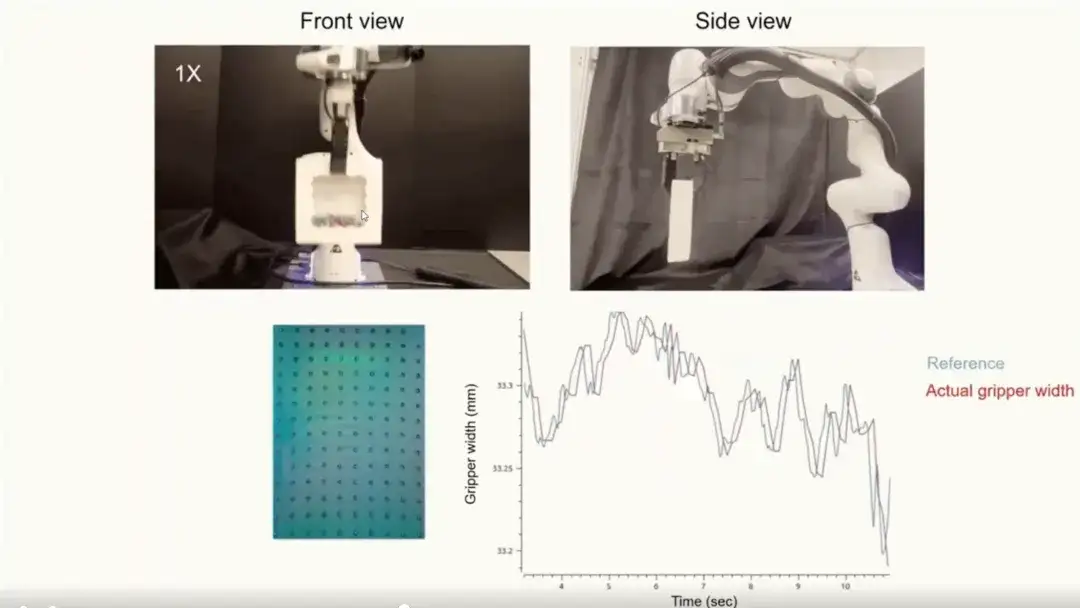
Strategie-Lernexperiment
Darüber hinaus haben wir die taktile Darstellung auf politische Lernexperimente angewendet.Überprüfen Sie die Leistung bei komplexen Aufgaben. Das Experiment verwendete Inbusschlüsseldaten für das Training und bewertete die folgenden drei Aufgaben:
* Einsetzen des Inbusschlüssels (siehe links): Präzise Einsetzaufgabe, die äußerst hohe Genauigkeit erfordert.
* Chips-Greifen (siehe Bild): Handhabung filigraner Greifaufgaben bei zerbrechlichen Objekten.
Hängende Hühnerbeine (siehe rechts): eine Aufgabe mit beiden Armen, die dynamisches Greifen und Kontrollieren über einen langen Zeitraum erfordert.

Wir haben drei verschiedene Methoden verglichen:Die drei Methoden sind: Vision-Only (basierend nur auf visuellen Signalen), Visual-Tactile from Scratch (gemeinsames Training von Sehen und Tastsinn) und Visual-Tactile mit UniT (unter Verwendung von taktilen Darstellungen, die von UniT zum Strategielernen extrahiert wurden). Wie in der folgenden Abbildung gezeigt, schneidet die Policy-Learning-Methode mit UniT-Darstellung bei allen Aufgaben am besten ab.

Auch in Zukunft wird HyperAI die Embodied-Touch-Community dabei unterstützen, weiterhin Online-Sharing-Aktivitäten durchzuführen und Experten und Wissenschaftler aus dem In- und Ausland einzuladen, um hochmoderne Ergebnisse und Erkenntnisse auszutauschen. Bleiben Sie dran!








