Command Palette
Search for a command to run...
Metas Größter Datensatz Zur Videosegmentierung Ist Jetzt Online Und 50-mal Größer Als Ähnliche Datensätze. Es Hat 9.000 Sterne! Die Kuaishou Digital Human Demo Beginnt Mit Einem Klick!

Wie erweckt KI statische Porträts zum Leben und lässt ihre Lächeln, Blinzeln und sogar subtilen Gesichtsausdrücke lebendig werden? Vor Kurzem hat das Kuaishou-Team LivePortrait als Open Source freigegeben. Laden Sie einfach ein statisches Foto hoch und es kann in ein dynamisches Porträt mit ausdrucksstarken Elementen umgewandelt werden. Es hat auf GitHub bereits 9.000 Sterne erhalten.Dieses Tutorial ist jetzt auf HyperAI verfügbar. Kommen Sie und erleben Sie es jetzt!
LivePortrait Link zum Tutorial:
Vom 29. Juli bis 2. August gibt es Updates auf der offiziellen Website von hyper.ai:
* Hochwertige öffentliche Datensätze: 11
* Auswahl an hochwertigen Tutorials: 3
* Community-Artikelauswahl: 4 Artikel
* Beliebte Enzyklopädieeinträge: 5
* Top-Konferenzen mit Deadline im August: 4
Besuchen Sie die offizielle Website:hyper.ai
Ausgewählte öffentliche Datensätze
1. SA-V-Videosegmentierungsdatensatz
Der SA-V-Datensatz ist ein umfangreicher Datensatz zur Videosegmentierung, der 2024 von Meta zum Trainieren und Bewerten von Meta Segment Anything Model 2 erstellt wurde. Er enthält ungefähr 51.000 Videos aus der realen Welt und 643.000 räumlich-zeitliche Maskenanmerkungen und ist damit etwa 50-mal größer als andere ähnliche Datensätze.
Direkte Verwendung:https://go.hyper.ai/X4DGI
Um die effektive Entwicklung von KI-Systemen im Bereich der Biologie zu fördern, haben Forscher von FutureHouse Inc. den Language Agent Biology Benchmark Dataset LAB-Bench eingeführt, der zur Bewertung der Leistung von KI-Systemen in der tatsächlichen biologischen Forschung wie Literaturrecherche und -schlussfolgerung, Graphinterpretation sowie Verständnis und Verarbeitung von DNA- und Proteinsequenzen verwendet wird. Die Ergebnisse wurden der Spitzenkonferenz NeurlPS 2024 vorgelegt.
Direkte Verwendung:https://go.hyper.ai/UznkS
3. NuminaMath-CoT Mathematik-Wettbewerbsproblem-Datensatz
Der Datensatz enthält über 860.000 Frage-Lösungspaare aus Mathematikwettbewerben, von denen jedes die Chain of Thought (CoT)-Argumentationsvorlage verwendet. Zu den Quellen des Datensatzes zählen Mathematikübungen für chinesische Oberschulen sowie Wettbewerbsfragen der amerikanischen und internationalen Mathematikolympiade. Die Daten wurden hauptsächlich aus Online-Prüfungsbögen im PDF-Format und aus Mathematik-Diskussionsforen gesammelt.
Direkte Verwendung:https://go.hyper.ai/svElx
4. Taptap überprüft den Datensatz mit Spielebewertungen
Dieser Datensatz enthält gekennzeichnete Bewertungen von etwa 300 Spielen der mobilen Spiele-App TapTap mit insgesamt 4.888 Datenbeispielen, die für Aufgaben zur Stimmungsanalyse verwendet werden können. Darunter wurden Nutzerbewertungen mit weniger als 3 Sternen (maximal 5 Sterne) als 0 (unzufrieden) und die anderen als 1 (zufrieden) gewertet. Das Verhältnis dieser beiden Kategorien beträgt ungefähr 1:1.
Direkte Verwendung:https://go.hyper.ai/ISf7c
5. CCPD-Datensatz Chinesischer Kennzeichenerkennungsdatensatz
Der CCPD-Datensatz ist ein großer, vielfältiger und sorgfältig kommentierter Datensatz zur Nummernschilderkennung. Der Datensatz wird hauptsächlich auf Parkplätzen in Hefei, China, gesammelt und enthält Nummernschildfotos in einer Vielzahl komplexer Umgebungen, wie Unschärfe, Neigung, Regen und Schnee, was den Datensatz bei der Nummernschilderkennungsaufgabe anspruchsvoller macht.
Direkte Verwendung:https://go.hyper.ai/gZ37Y
6. TinyStories-Datensatz zur Kurzgeschichtensynthese
Dieser Datensatz ist ein synthetischer Datensatz von Kurzgeschichten, der mit GPT-3.5 und GPT-4 generiert wurde, und der enthaltene Wortschatz ist auf das Verständnisspektrum von 3- bis 4-jährigen Kindern beschränkt. Mit diesem Datensatz können Modelle trainiert werden, die Kurzgeschichten erstellen, die flüssig, konsistent und vielfältig sind und eine nahezu perfekte Grammatik aufweisen.
Direkte Verwendung:https://go.hyper.ai/m9ouS
7. Wildfire Smoke Wildfire Smoke Detection Dataset
Dieser Datensatz wurde 2019 gemeinsam von AI for Mankind und HPWREN veröffentlicht. Er enthält insgesamt 737 Bilder, darunter 516 Trainingsbilder, 147 Verifizierungsbilder und 74 Testbilder, wobei das Annotationsformat COCO ist. Ziel ist es, die Fähigkeit des Modells zu verbessern, zwischen Wolken/Nebel und Rauch zu unterscheiden und eine durchgängige Feedbackschleife zu etablieren.
Direkte Verwendung:https://go.hyper.ai/ofGHZ
Dies ist ein gemeinfreier Sprachdatensatz, der aus 13.100 kurzen Audioclips besteht, in denen ein einzelner Sprecher Passagen aus 7 Sachbüchern vorliest. Für jedes Fragment werden Transkriptionen bereitgestellt. Die Länge der Clips variierte zwischen 1 und 10 Sekunden, mit einer Gesamtlänge von ungefähr 24 Stunden.
Direkte Verwendung:https://go.hyper.ai/Eo1bK
9. Chinesische Tierkreiszeichen
Der Datensatz enthält 8.508 Bilder der zwölf chinesischen Tierkreiskategorien. Der Datensatz wurde im Verhältnis 85:7,5:7,5 in Training, Validierung und Test aufgeteilt.
Direkte Verwendung:https://go.hyper.ai/ps2es
10. DISC-Law-SFT Hochwertiger Feinabstimmungsdatensatz zur chinesischen Rechtsaufsicht
Dieser Datensatz enthält fast 300.000 Trainingsdaten und ist speziell für den chinesischen Rechtsbereich konzipiert. Ziel ist es, die Fähigkeiten des Modells bei der Verarbeitung juristischer Texte, beim juristischen Denken sowie beim Wissensabruf und bei der Einhaltung von Vorschriften im juristischen Bereich zu verbessern.
Direkte Verwendung:https://go.hyper.ai/zh9Ij
11. Free Spoken Digit Dataset (FSDD) Digitaler Audioerkennungsdatensatz
Der Free Spoken Digit Dataset (FSDD) ist ein Audiodatensatz, der aus digitalen Sprachaufnahmen in WAV-Dateien mit einer Abtastrate von 8 kHz besteht. Die Aufnahmen wurden bearbeitet, um die Stille am Anfang und Ende zu minimieren.
Direkte Verwendung:https://go.hyper.ai/HZ00d
Weitere öffentliche Datensätze finden Sie unter:
Ausgewählte öffentliche Tutorials
HiDiffusion ist ein Open-Source-Framework für hohe Auflösungen, das von Megvii Technology entwickelt wurde. Es unterstützt nicht nur textgenerierte Bilder und bildgenerierte Bilder, sondern verfügt auch über Funktionen zur Bildwiederherstellung. HyperAI Super Neural hat jetzt das Tutorial „HiDiffusion kann schnell eine Demo für hochwertige 8k-Bilder erstellen“ veröffentlicht. Sie müssen keine Befehle eingeben, klonen Sie es einfach mit einem Klick, um zu starten.
Online ausführen:https://go.hyper.ai/yZ5K5
2. LivePortrait Kuaishou Open Source bildgeneriertes Video digitale Menschendemo
LivePortrait ist ein Framework zur Erstellung von Porträtvideos. Zu seinen Hauptfunktionen gehören das Generieren lebendiger Animationen aus einem einzigen Bild, die präzise Steuerung der Augen- und Lippenbewegungen, das nahtlose Zusammenfügen mehrerer Porträts, die Unterstützung von Porträts in mehreren Stilen, das Generieren hochauflösender Animationen usw. Dieses Tutorial ist eine Demo von LivePortrait, die mit einem Klick ausgeführt wird. Die relevante Umgebung und die Abhängigkeiten wurden installiert. Sie können es erleben, indem Sie es klonen und mit einem Klick starten.
Online ausführen:https://go.hyper.ai/oTs66
3. AuraSR GAN-basierte Superauflösungs-Bildvergrößerungsdemo
AuraSR ist ein auf Deep Learning basierendes Modell zur Wiederherstellung hochauflösender Bilder, das detaillierte Informationen in Bildern intelligent erkennen und fehlende Details beim Vergrößern der Bilder automatisch ergänzen kann. Im Vergleich zu herkömmlichen Bildvergrößerungsmethoden liefert AuraSR nicht nur bessere Ergebnisse, sondern ist auch einfach zu verwenden und kann ohne professionelle Kenntnisse problemlos genutzt werden. Erleben Sie das Modell mit dem Klonen per Mausklick.
Online ausführen:https://go.hyper.ai/y2wIU
Community-Artikel
Aitomatic, ein führendes Unternehmen im Bereich KI-Innovation im Industriesektor, gab die Einführung von SemiKong bekannt, dem weltweit ersten Open-Source-KI-Modell in großer Sprache, das speziell für die Halbleiterindustrie entwickelt wurde. Das Unternehmen hat zuvor einen KI-Agenten namens aiKO auf den Markt gebracht, der exklusive Agenten für Unternehmensbenutzer auf der Grundlage ihres Fachwissens und ihrer Daten erstellt und den Unternehmen das „volle Eigentum“ an ihren Agenten überlässt.
Den vollständigen Bericht ansehen:https://go.hyper.ai/A7eCi
2. Highlights: Huang Renxun und Zuckerbergs „Gespräch des Jahrhunderts“
Am frühen Morgen des 30. Juli führten Nvidia-Gründer und CEO Huang Renxun und Meta-Gründer und CEO Mark Zuckerberg auf der 51. SIGGRAPH-Grafikkonferenz ein „Kamingespräch“. HyperAI hat die Highlights und vollständigen chinesischen Untertitel für das Video zusammengestellt.
Den vollständigen Bericht ansehen:https://go.hyper.ai/rbU2u
Das MIT-Forschungsteam hat hochpräzise Einzelzustandsprädiktoren wie AlphaFold und ESMFold neu aufgesetzt und sie in einem benutzerdefinierten Flow-Matching-Framework fein abgestimmt, um sequenzbedingte Modelle zur Generierung von Proteinstrukturen namens AlphaFLOW und ESMFLOW zu erhalten. Dieser Artikel ist eine detaillierte Interpretation und Weitergabe der relevanten Dokumente.
Den vollständigen Bericht ansehen:https://go.hyper.ai/qupG9
Das Life Basic Model Laboratory der Abteilung für Automatisierung der Tsinghua-Universität hat in Zusammenarbeit mit dem Xiangya-Krankenhaus der Central South University ein präzises KI-Basismodell zur pathologischen Diagnose namens ROAM vorgeschlagen, das auf großen regionalen Interessen und einem Pyramidentransformator basiert und für die Diagnose auf klinischer Ebene und die Entdeckung molekularer Marker von Gliomen verwendet wird und auf die pathologische Diagnose anderer Tumorarten ausgeweitet werden kann.
Den vollständigen Bericht ansehen:https://go.hyper.ai/w4tsr
Beliebte Enzyklopädieartikel
1. Neuronales Strahlungsfeld (NeRF)
2. Gruppenabfrage Aufmerksamkeit GQA
3. Datenerweiterung
4. Umfangreiches Multitasking-Sprachverständnis (MMLU)
5. Langzeit-Kurzzeitgedächtnis
Hier sind Hunderte von KI-bezogenen Begriffen zusammengestellt, die Ihnen helfen sollen, „künstliche Intelligenz“ zu verstehen:
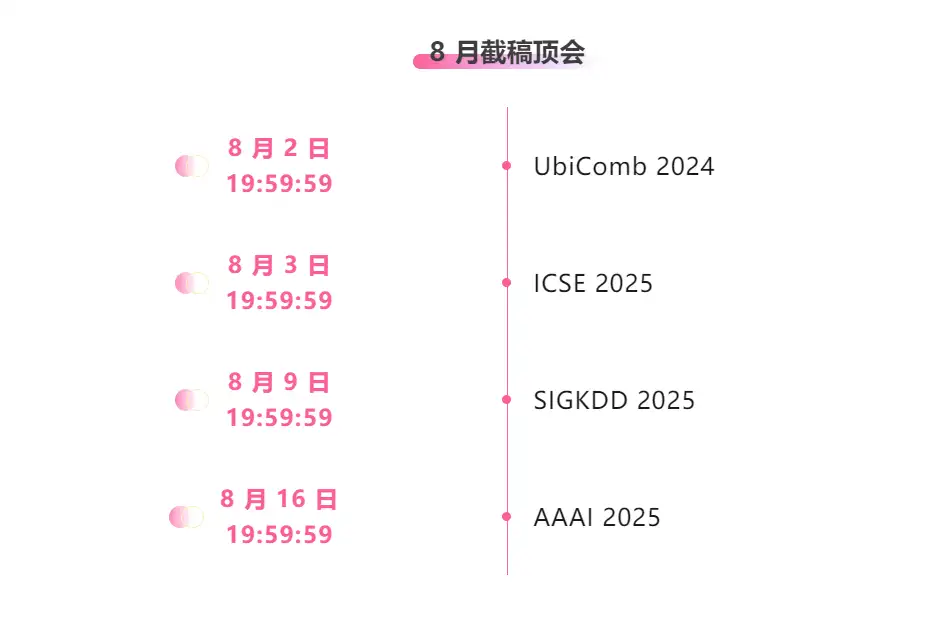
Zentrale Verfolgung der wichtigsten wissenschaftlichen KI-Konferenzen:https://go.hyper.ai/event
Das Obige ist der gesamte Inhalt der Auswahl des Herausgebers dieser Woche. Wenn Sie über Ressourcen verfügen, die Sie auf der offiziellen Website von hyper.ai veröffentlichen möchten, können Sie uns auch gerne eine Nachricht hinterlassen oder einen Artikel einreichen!
Bis nächste Woche!
Über HyperAI
HyperAI (hyper.ai) ist eine führende Community für künstliche Intelligenz und Hochleistungsrechnen in China.Wir haben uns zum Ziel gesetzt, die Infrastruktur im Bereich der Datenwissenschaft in China zu werden und inländischen Entwicklern umfangreiche und qualitativ hochwertige öffentliche Ressourcen bereitzustellen. Bisher haben wir:
* Bereitstellung inländischer beschleunigter Download-Knoten für über 1300 öffentliche Datensätze
* Enthält über 400 klassische und beliebte Online-Tutorials
* Interpretation von über 100 AI4Science-Papierfällen
* Unterstützt die Suche nach über 500 verwandten Begriffen
* Hosting der ersten vollständigen chinesischen Apache TVM-Dokumentation in China
Besuchen Sie die offizielle Website, um Ihre Lernreise zu beginnen:








