HyperAI
Command Palette
Search for a command to run...
Ovis-U1-3B:多模态理解与生成模型
一、教程简介

Ovis-U1-3B 是由阿里巴巴集团 Ovis 团队于 2025 年 6 月 29 日发布的多模态统一模型。模型集成多模态理解、文本到图像生成和图像编辑三种核心能力,基于先进的架构和协同统一训练方式,实现高保真图像合成和高效的文本视觉交互。在多模态理解、生成和编辑等多个学术基准测试中,Ovis-U1 均取得领先的成绩,展现出强大的泛化能力和出色的性能表现。相关论文成果为 Ovis-U1 Technical Report 。
本教程采用资源为单卡 RTX 4090 。本教程提供 Image + Text → Image 、 Text → Image 和 Image → Text 三个示例供测试。
二、项目示例

三、运行步骤
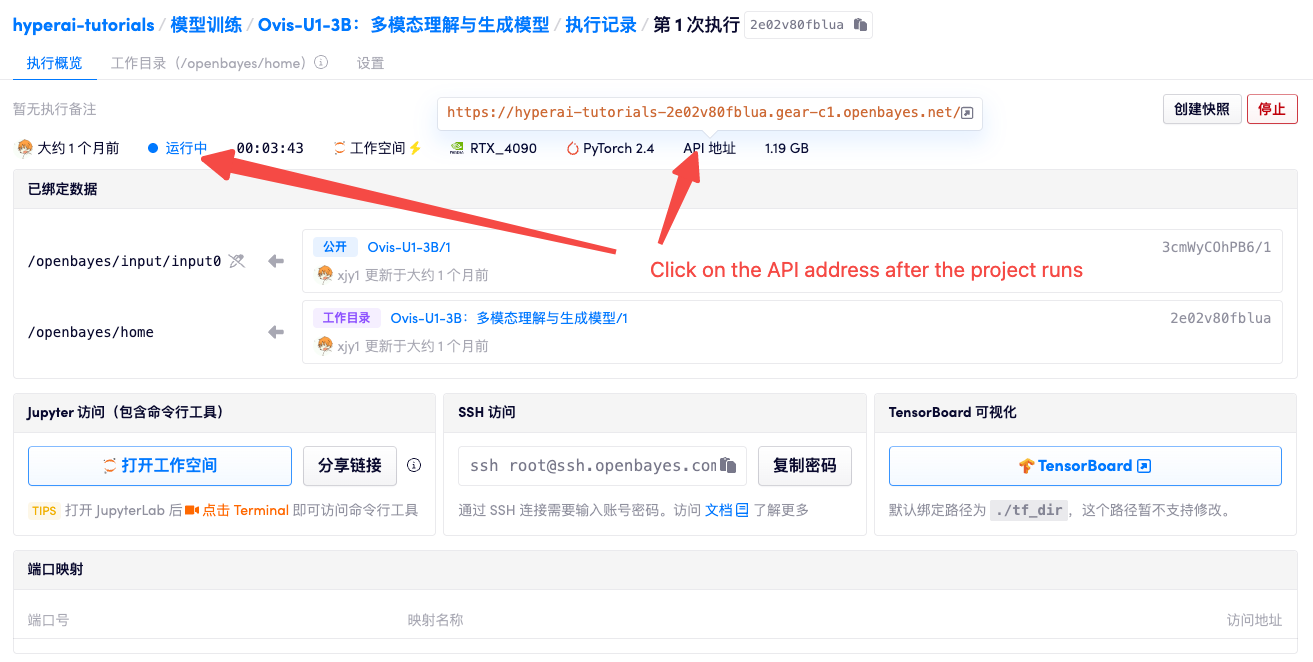
1. 启动容器后点击 API 地址即可进入 Web 界面
2. 使用步骤
若显示「Bad Gateway」,这表示模型正在初始化,由于模型较大,请等待约 2-3 分钟后刷新页面。
2.1 Image + Text → Image
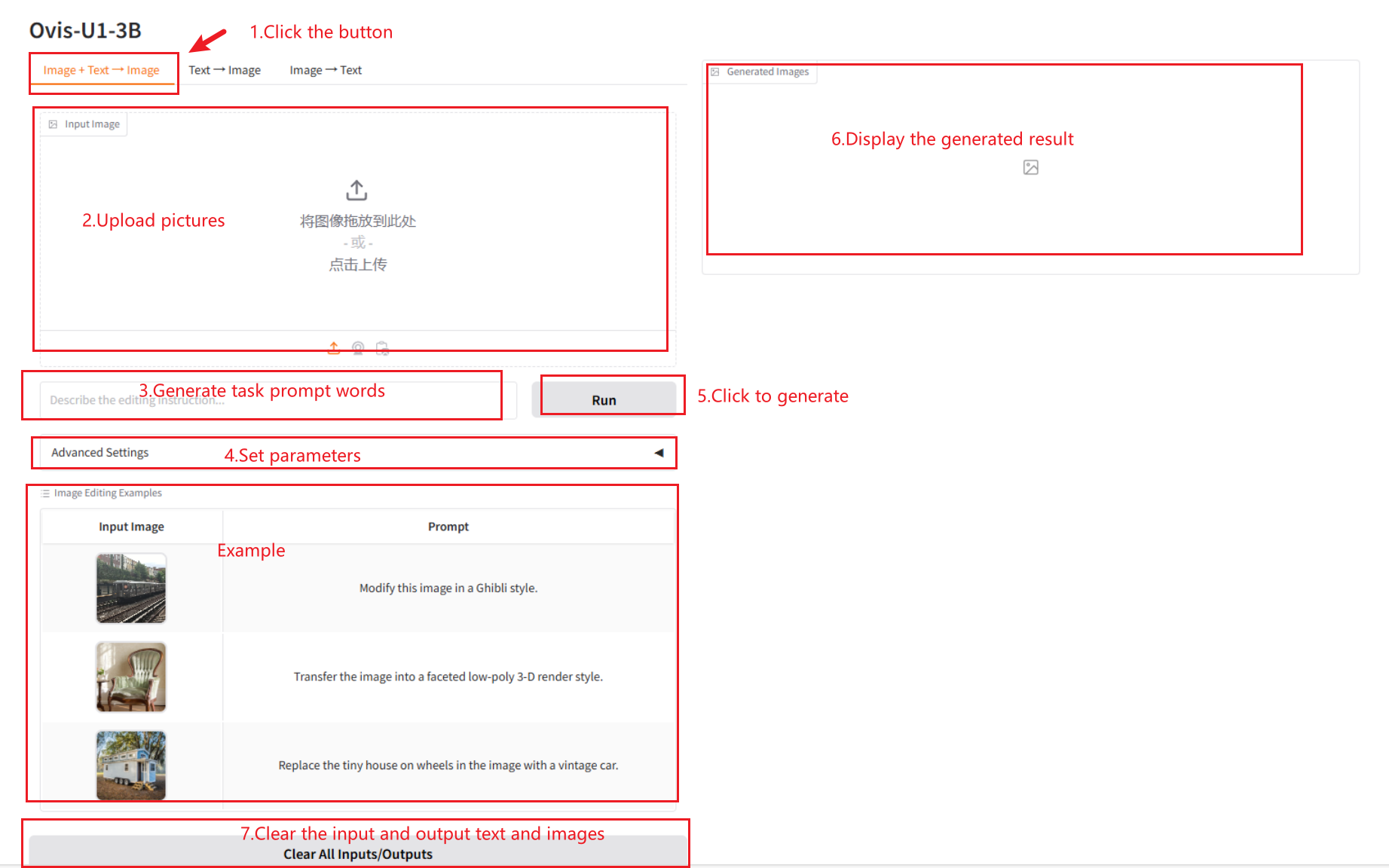
参数说明
- Advanced Settings
- Image Guidance Scale:控制文本提示对生成图像的影响强度。
- Text Guidance Scale:控制输入图像对生成图像的影响强度。
- Steps:图像生成迭代步数。
- Seed:随机种子,用于图像生成过程的可重复性。
- Randomize seed:随机化种子,每次生成图像时都会随机生成一个新的种子。
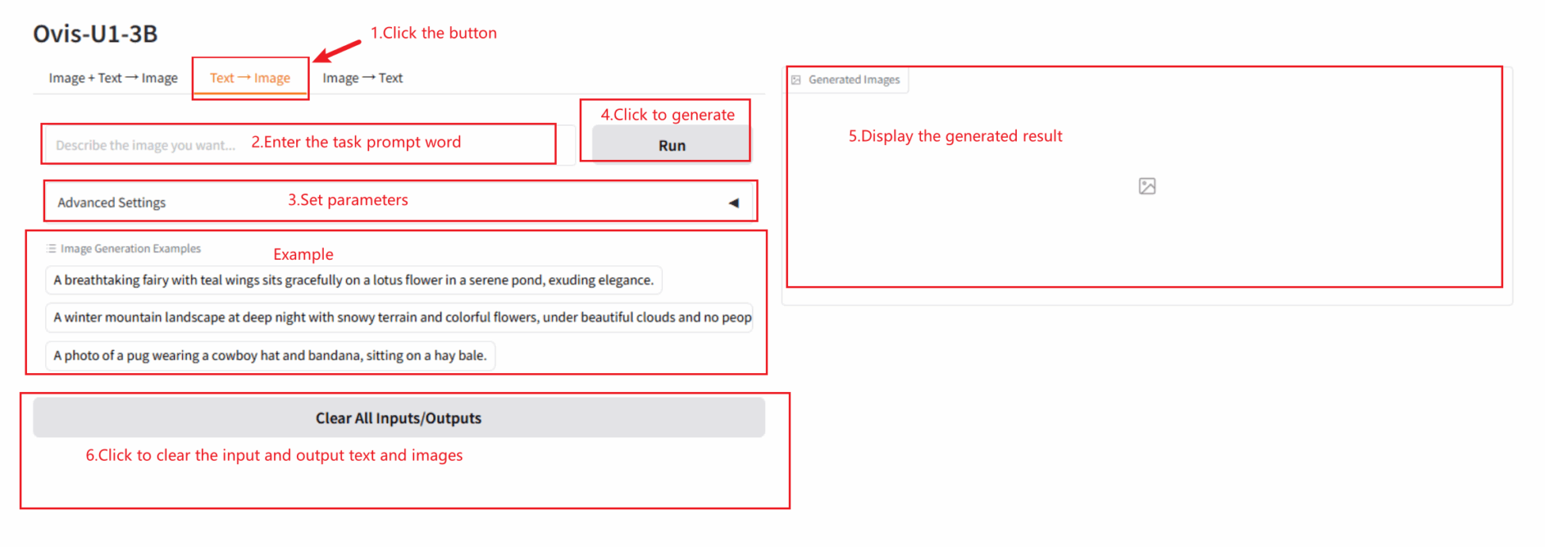
2.2 Text → Image
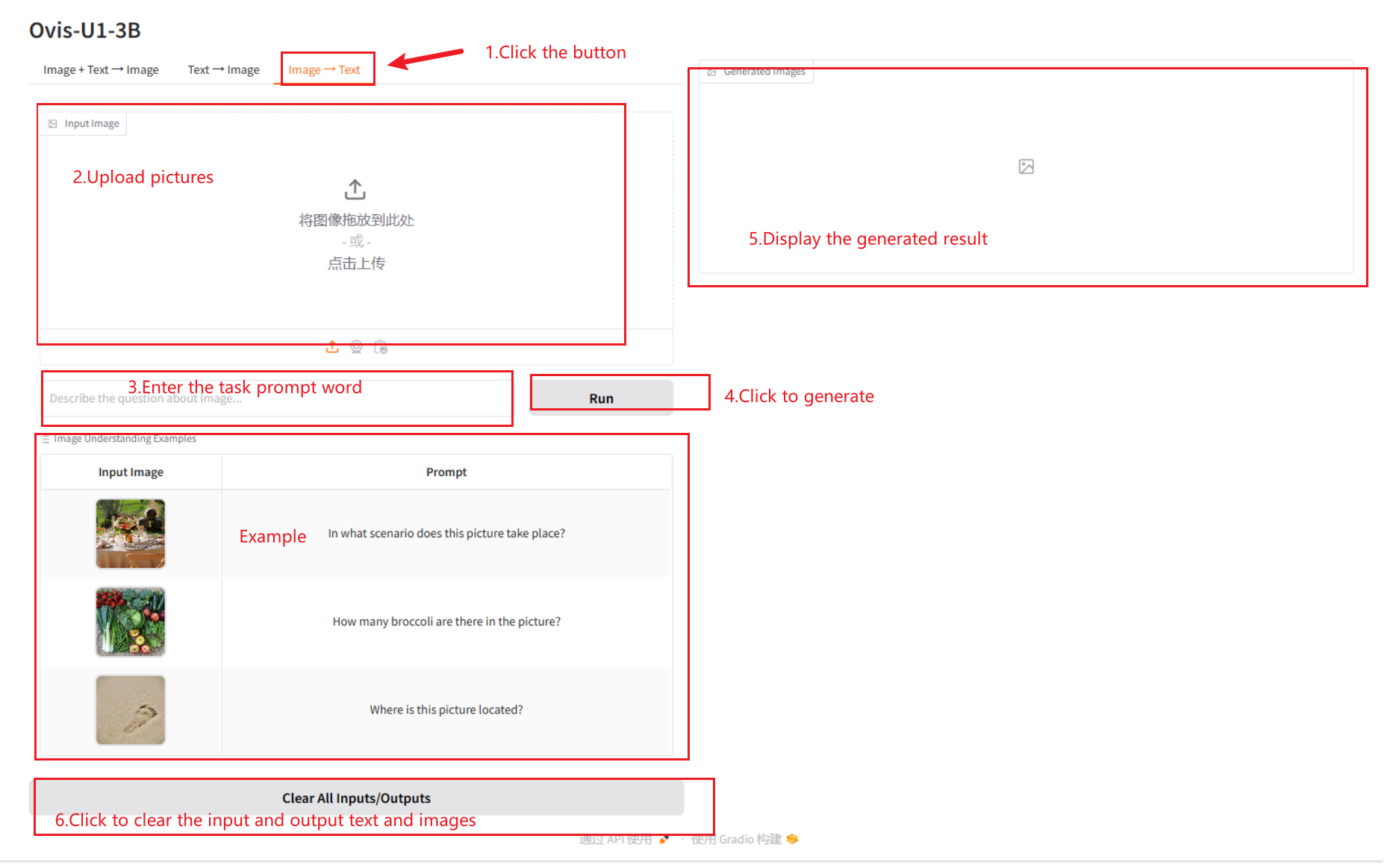
2.3 Image → Text
四、交流探讨
🖌️ 如果大家看到优质项目,欢迎后台留言推荐!另外,我们还建立了教程交流群,欢迎小伙伴们扫码备注【SD 教程】入群探讨各类技术问题、分享应用效果↓

引用信息
本项目引用信息如下:
@article{wang2025ovisu1,
title={Ovis-U1 Technical Report},
author={Wang, Guo-Hua and Zhao, Shanshan and Zhang, Xinjie and Cao, Liangfu and Zhan, Pengxin and Duan, Lunhao and Lu, Shiyin and Fu, Minghao and Zhao, Jianshan and Li, Yang and Chen, Qing-Guo},
journal={arXiv preprint arXiv:2506.23044},
year={2025}
}本笔记本由社区用户贡献,仅用于教育和信息传播目的。如果任何内容涉及版权侵权,请通过 [email protected] 联系我们,我们将及时审核并删除。