HyperAI
Command Palette
Search for a command to run...
Long-VITA:百万 Token 多模态理解 Demo
一、教程简介

Long-VITA 是由腾讯优图实验室、南京大学、厦门大学于 2025 年 2 月发布的长上下文多模态大模型研究成果。该模型在保证短上下文精度领先的同时,将上下文长度扩展至 100 万 Tokens,实现文本、图像等多模态输入的高效处理。相关论文为「Long-VITA: Scaling Large Multi-modal Models to 1 Million Tokens with Leading Short-Context Accuracy」。
本教程采用资源为单卡 RTX 4090,部署的模型为 Long-VITA-16K_HF 。
二、效果示例
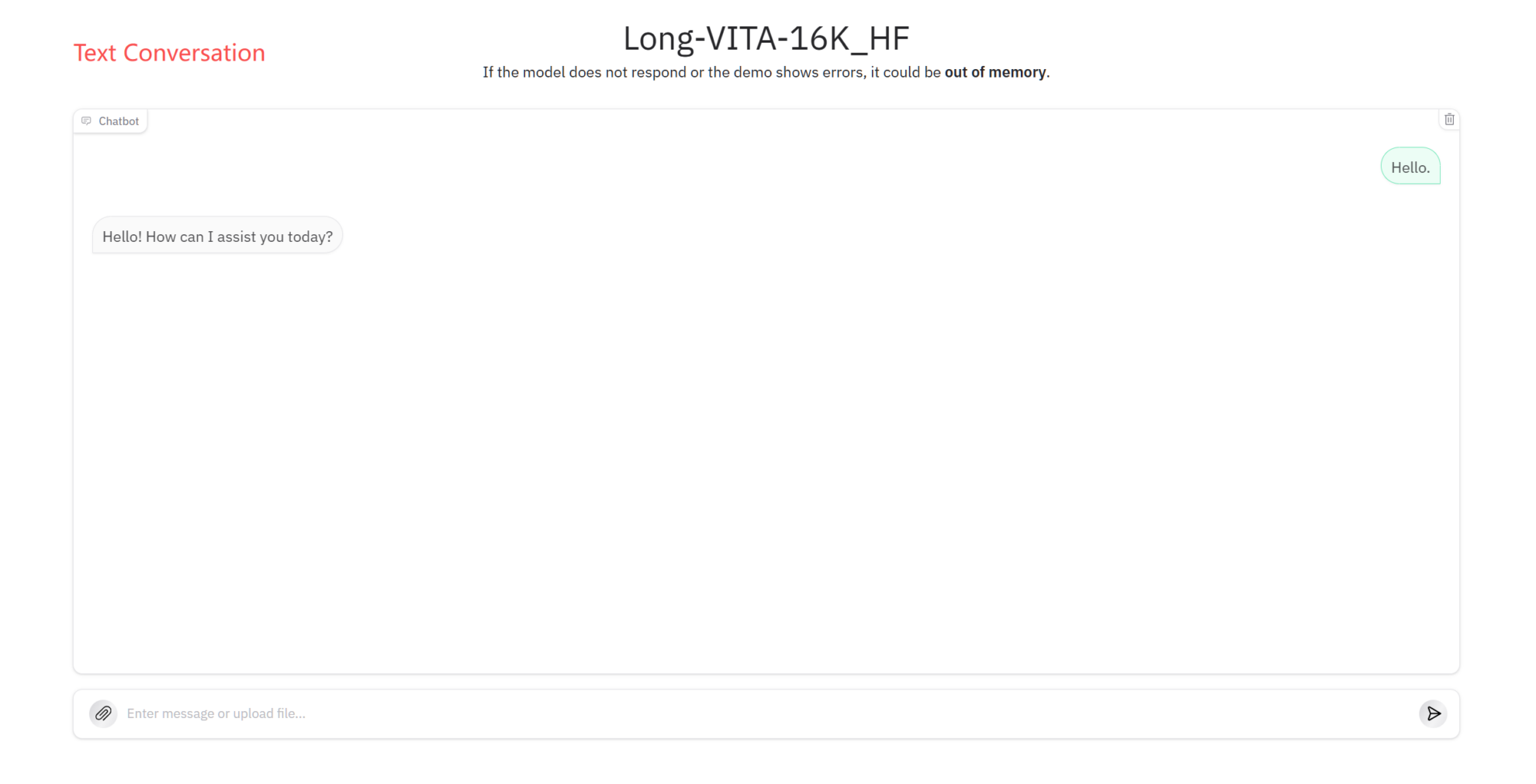
文本对话
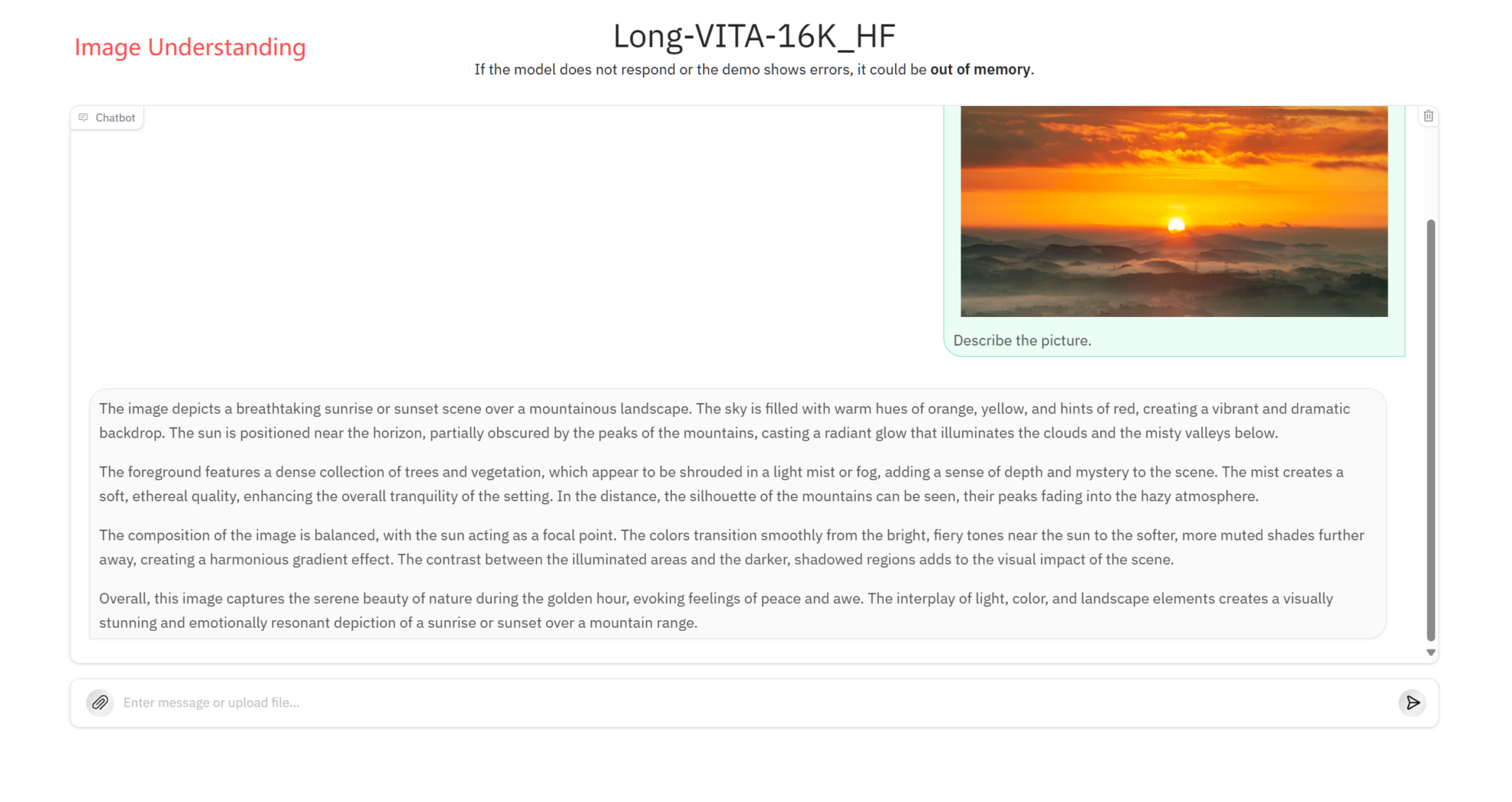
图片理解
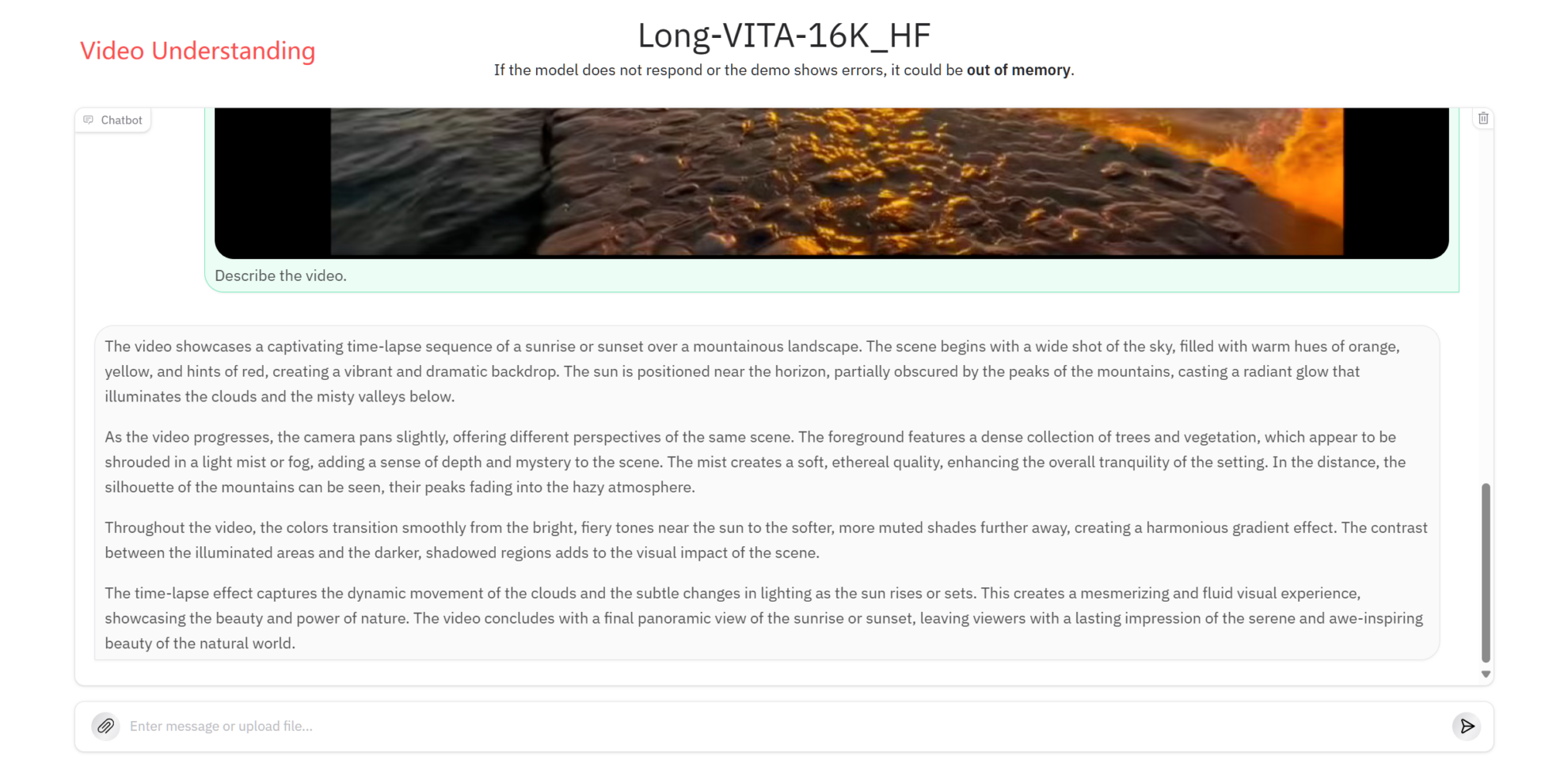
视频理解
三、运行步骤
1. 启动容器后点击 API 地址即可进入 Gradio 交互界面
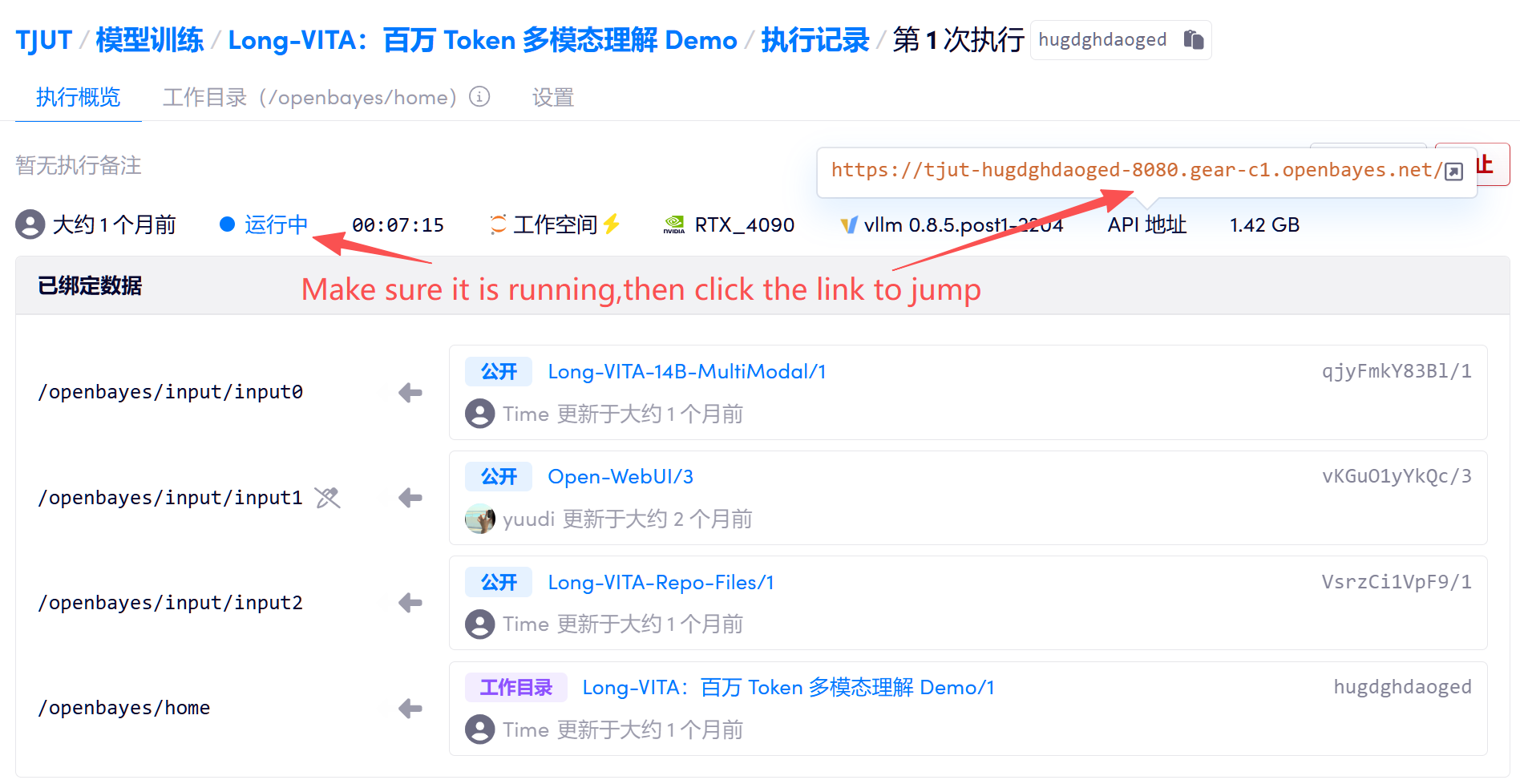
2. 进入网页后,即可使用模型
若显示「Bad Gateway」,这表示模型正在初始化,由于模型较大,请等待约 2-3 分钟后刷新页面。
注意事项
- 长上下文输入请确保显存充足,建议分批加载超大文本。
- 图像输入建议 ≤ 2048 像素边长,以降低推理延迟。
- 若推理失败,请检查输入格式,或缩短输入长度后重试。
交流探讨
🖌️ 如果大家看到优质项目,欢迎后台留言推荐!另外,我们还建立了教程交流群,欢迎小伙伴们扫码备注【SD 教程】入群探讨各类技术问题、分享应用效果↓

引用信息
本项目引用信息如下:
@misc{shen2025longvitascalinglargemultimodal,
title={Long-VITA: Scaling Large Multi-modal Models to 1 Million Tokens with Leading Short-Context Accuracy},
author={Yunhang Shen and Chaoyou Fu and Shaoqi Dong and Xiong Wang and Yi-Fan Zhang and Peixian Chen and Mengdan Zhang and Haoyu Cao and Ke Li and Xiawu Zheng and Yan Zhang and Yiyi Zhou and Ran He and Caifeng Shan and Rongrong Ji and Xing Sun},
year={2025},
eprint={2502.05177},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2502.05177},
}本笔记本由社区用户贡献,仅用于教育和信息传播目的。如果任何内容涉及版权侵权,请通过 [email protected] 联系我们,我们将及时审核并删除。