HyperAI
Command Palette
Search for a command to run...
腾讯混元 HunyuanVideo-Foley
一、教程简介

HunyuanVideo-Foley 是由腾讯混元团队(Tencent Hunyuan)于 2025 年 8 月正式发布并开源的端到端的视频音效生成模型,旨在通过输入视频画面和文本描述,自动生成高质量、音画同步的电影机音效,包括环境音、拟音、背景音乐等。该模型突破了传统 AI 生成视频「无声」的局限,具备多模态理解能力,同时解析视觉内容和语义指令,实现「看懂画面、读懂文字、配准声音」的沉浸式音效生成效果。相关论文成果为「HunyuanVideo-Foley: Multimodal Diffusion with Representation Alignment for High-Fidelity Foley Audio Generation」。
该教程算力资源采用单卡 RTX 4090 。目前只支持英文。
二、项目示例
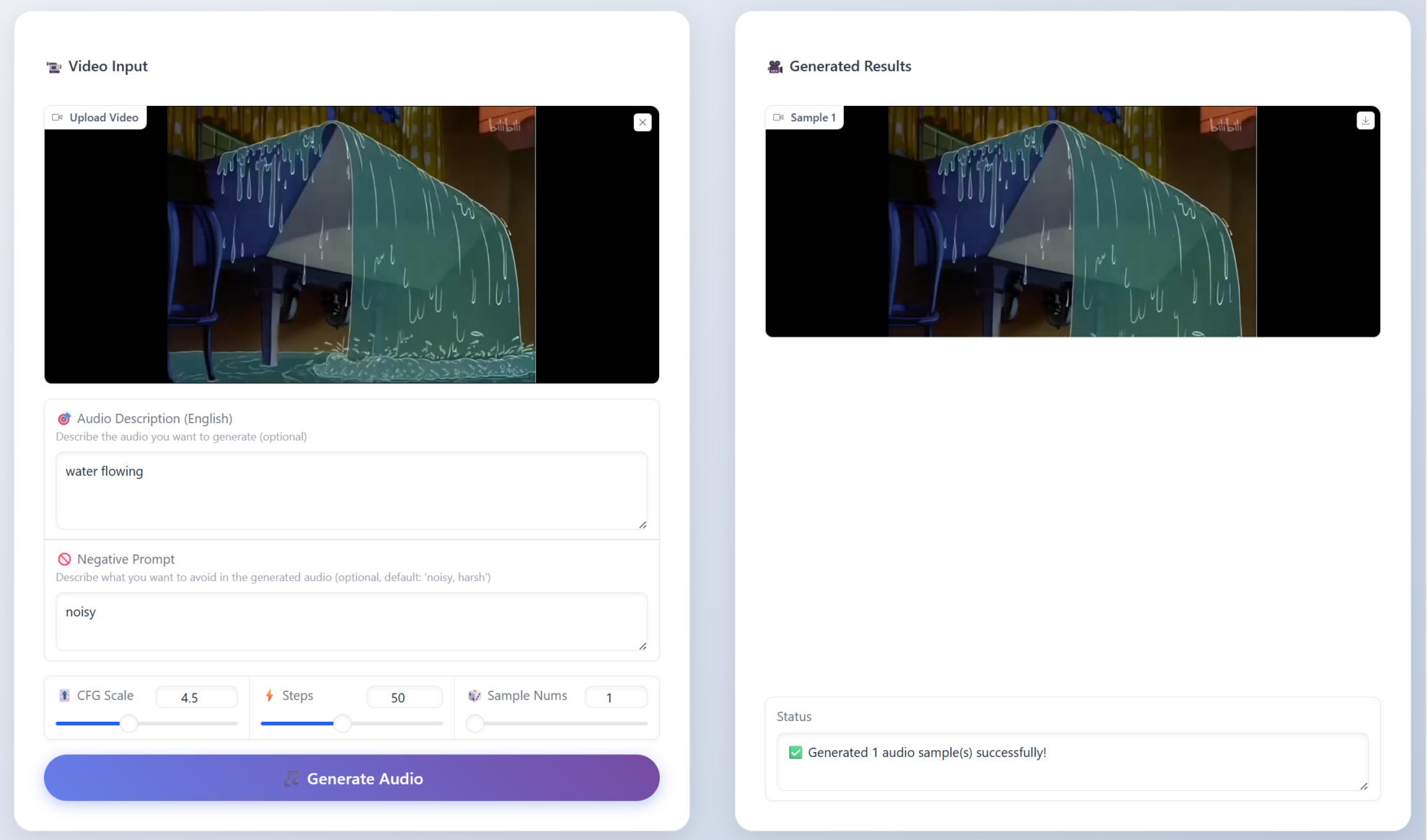
三、运行步骤
1. 启动容器
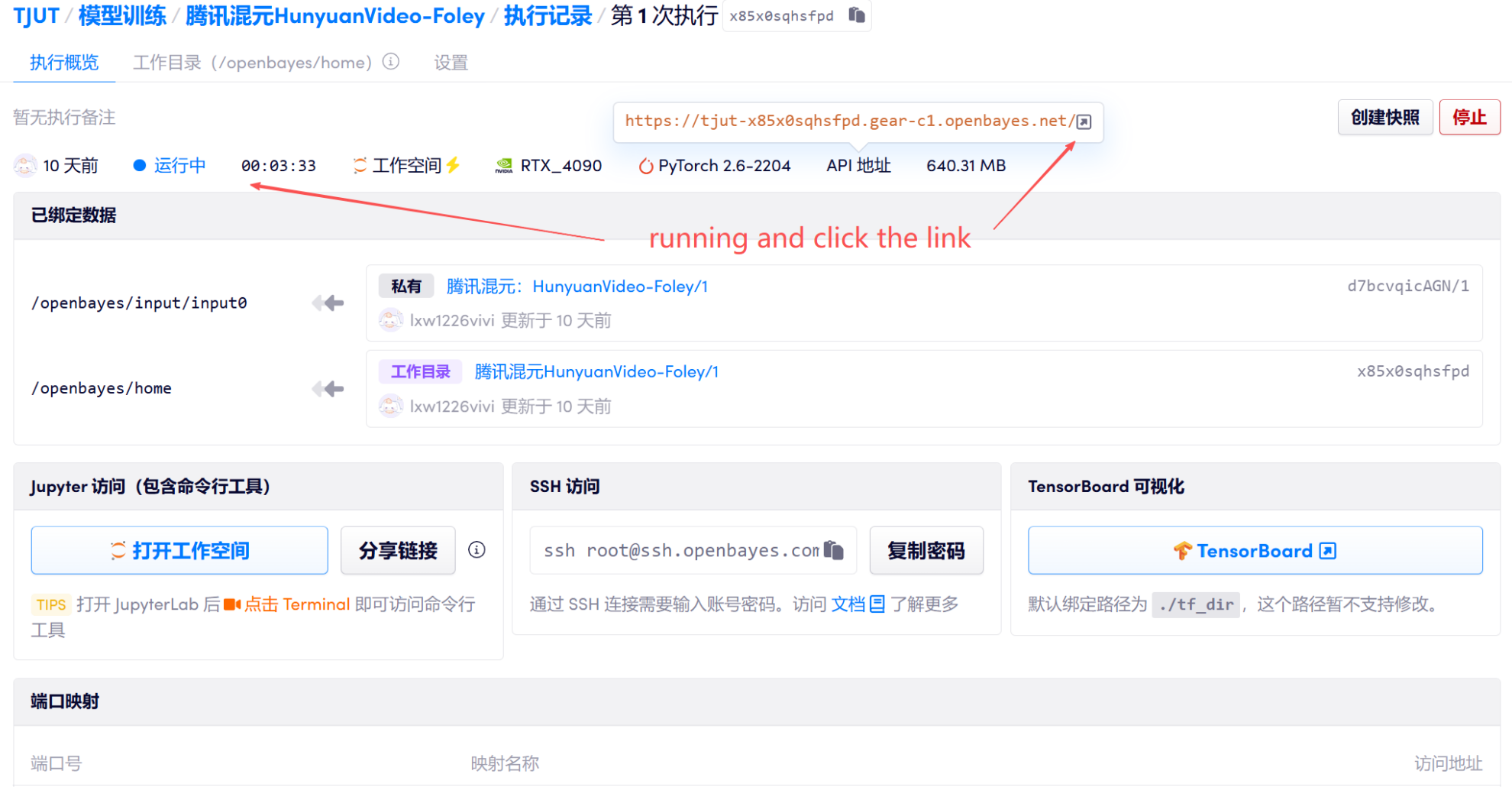
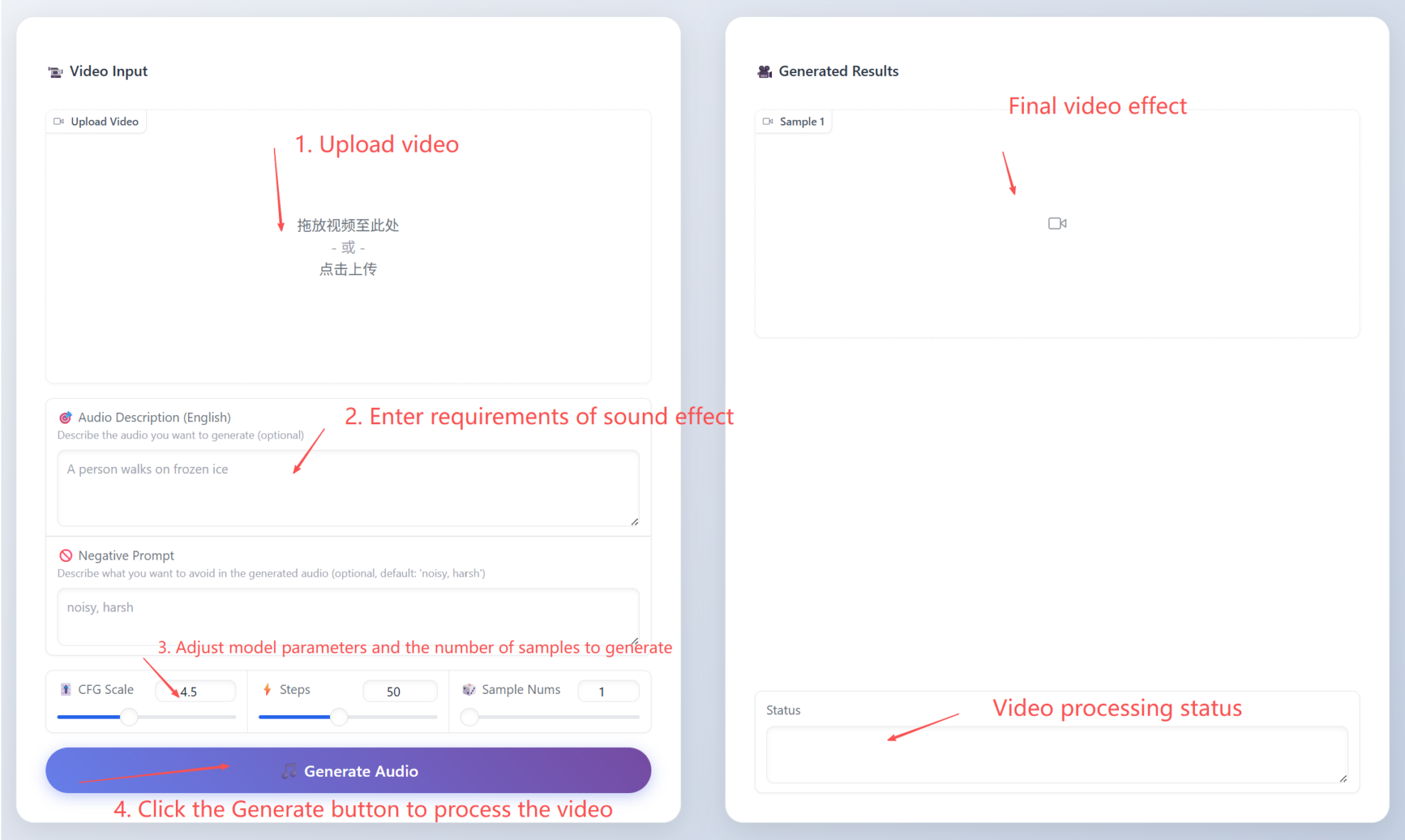
2. 进入网页后,即可进行模型的使用
若显示「Bad Gateway」,这表示模型正在初始化,请等待 2-3 分钟后刷新页面。建议上传 H.264 编码的视频,便于生成结果在网页上的预览和播放。
四、交流探讨
🖌️ 如果大家看到优质项目,欢迎后台留言推荐!另外,我们还建立了教程交流群,欢迎小伙伴们扫码备注【SD 教程】入群探讨各类技术问题、分享应用效果 ↓

引用信息
本项目引用信息如下:
@misc{shan2025hunyuanvideofoleymultimodaldiffusionrepresentation,
title={HunyuanVideo-Foley: Multimodal Diffusion with Representation Alignment for High-Fidelity Foley Audio Generation},
author={Sizhe Shan and Qiulin Li and Yutao Cui and Miles Yang and Yuehai Wang and Qun Yang and Jin Zhou and Zhao Zhong},
year={2025},
eprint={2508.16930},
archivePrefix={arXiv},
primaryClass={eess.AS},
url={https://arxiv.org/abs/2508.16930},
}本笔记本由社区用户贡献,仅用于教育和信息传播目的。如果任何内容涉及版权侵权,请通过 [email protected] 联系我们,我们将及时审核并删除。