HyperAI
Command Palette
Search for a command to run...
Depth-Anything-3:从任何视角恢复视觉空间
一、教程简介

Depth-Anything-3(DA3)是由 ByteDance-Seed 团队于 2025 年 11 月发布的突破性视觉几何模型,相关论文成果为 Depth Anything 3: Recovering the Visual Space from Any Views 。
该模型以「极简建模」理念革新视觉几何任务:仅采用单一普通 Transformer(如 vanilla DINO 编码器)作为骨干网络,通过「深度射线表示」替代复杂多任务学习,即可从任意视觉输入(已知/未知相机姿态均可)中预测空间一致的几何结构。其性能显著超越前代模型 DA2(单目深度估计)与同类方案 VGGT(多视图深度/姿态估计),所有模型均基于公开学术数据集训练,兼顾精度与可复现性。
核心特性:
- 多任务合一:单一模型支持单目深度估计、多视图深度融合、相机姿态估计、 3D 高斯生成等任务
- 高精度输出:在 HiRoom 数据集单目深度精度达 94.6%,ETH3D 重建精度超越 VGGT 等模型
- 多模型适配:提供 Main(全能)、 Metric(度量深度)、 Monocular(单目专用)及 Nested(嵌套融合)系列模型
- 灵活导出:支持 GLB 、 NPZ 、 PLY 、 3DGS 视频等格式,无缝对接下游 3D 工具(如 Blender)
本教程使用 Gradio 部署 DA3 核心模型,算力资源采用「RTX_5090」,可满配运行 3D 高斯生成(高分辨率)、多视图 3D 重建等重型任务,无显存/内存瓶颈。
二、效果展示
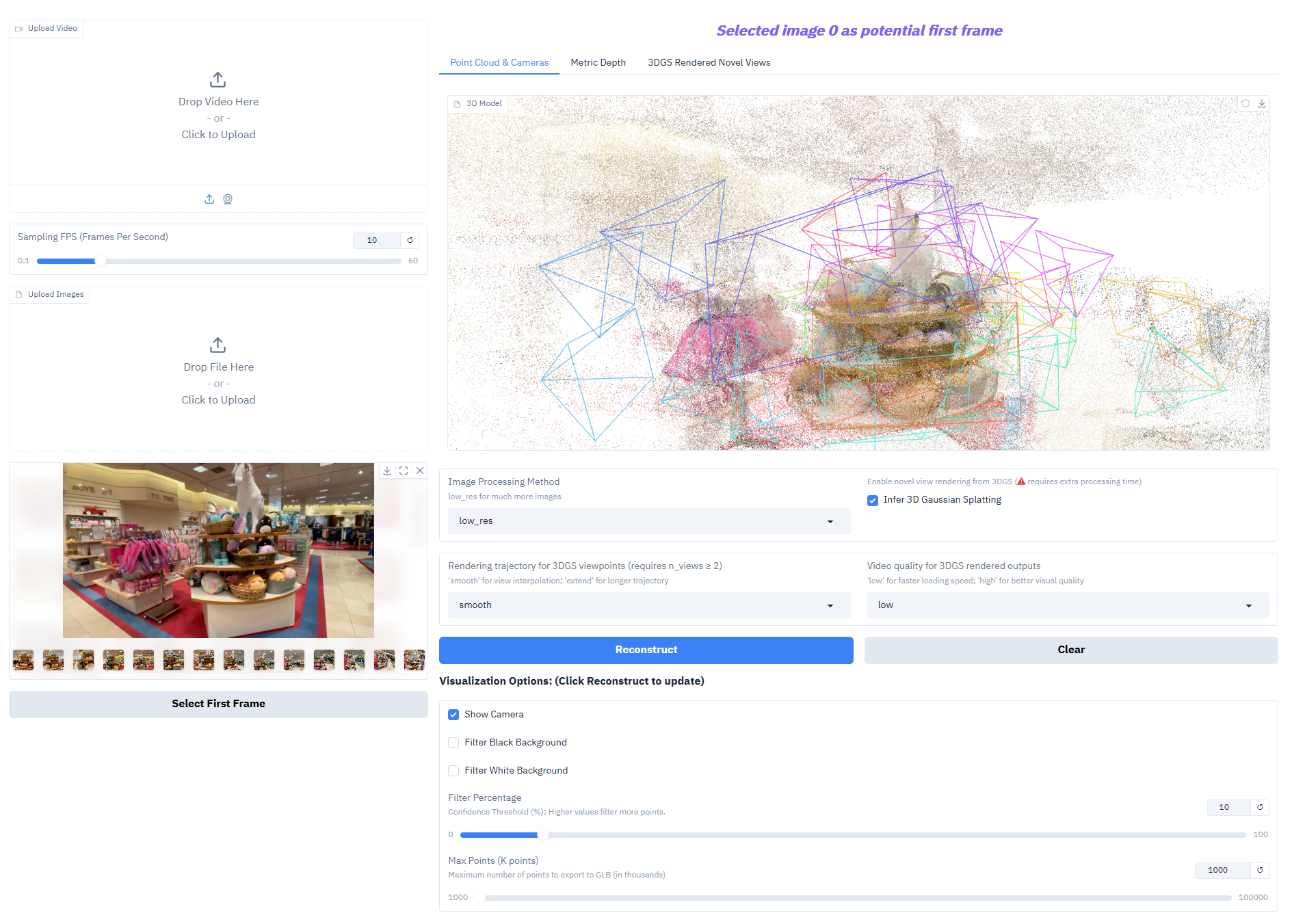
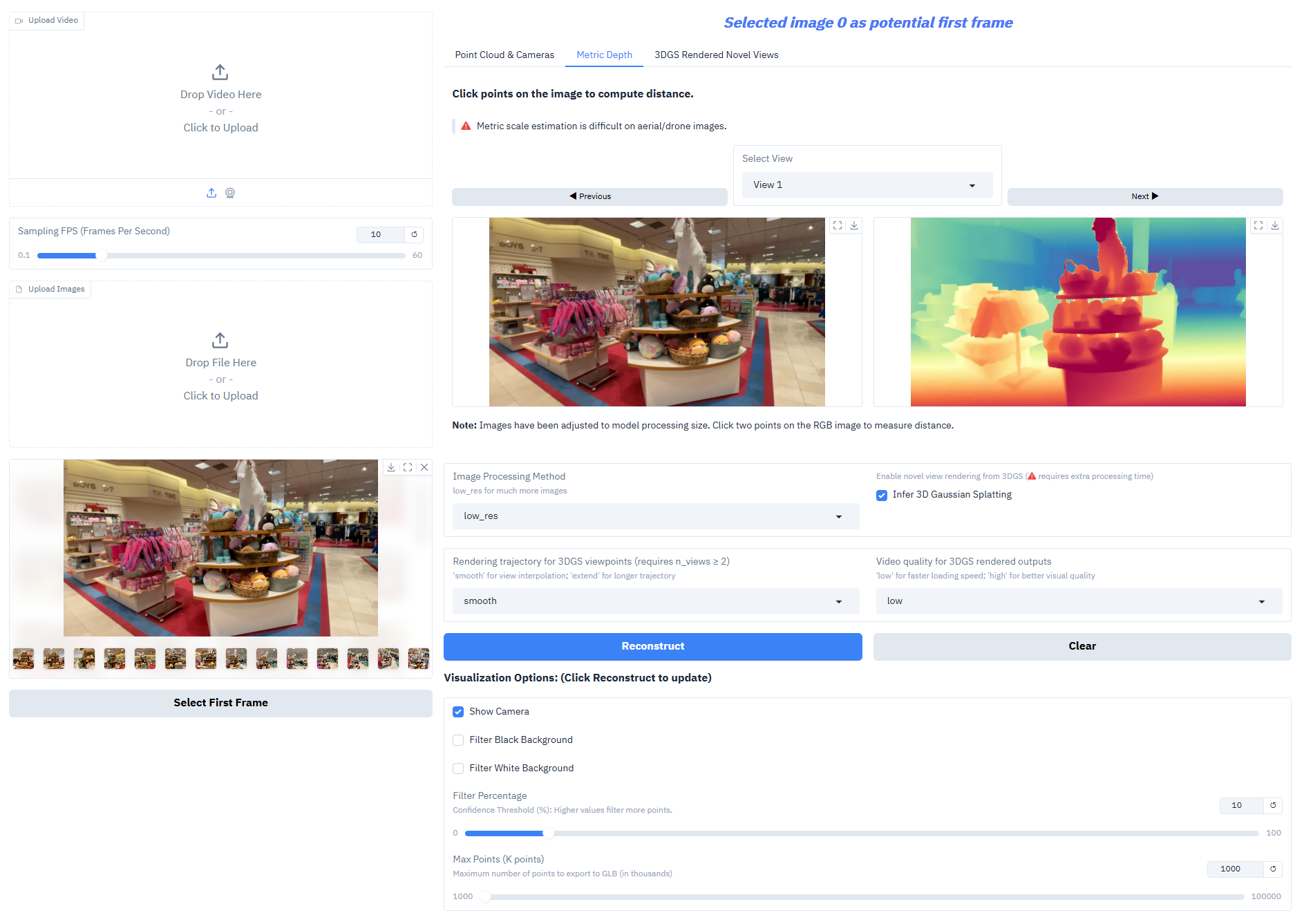
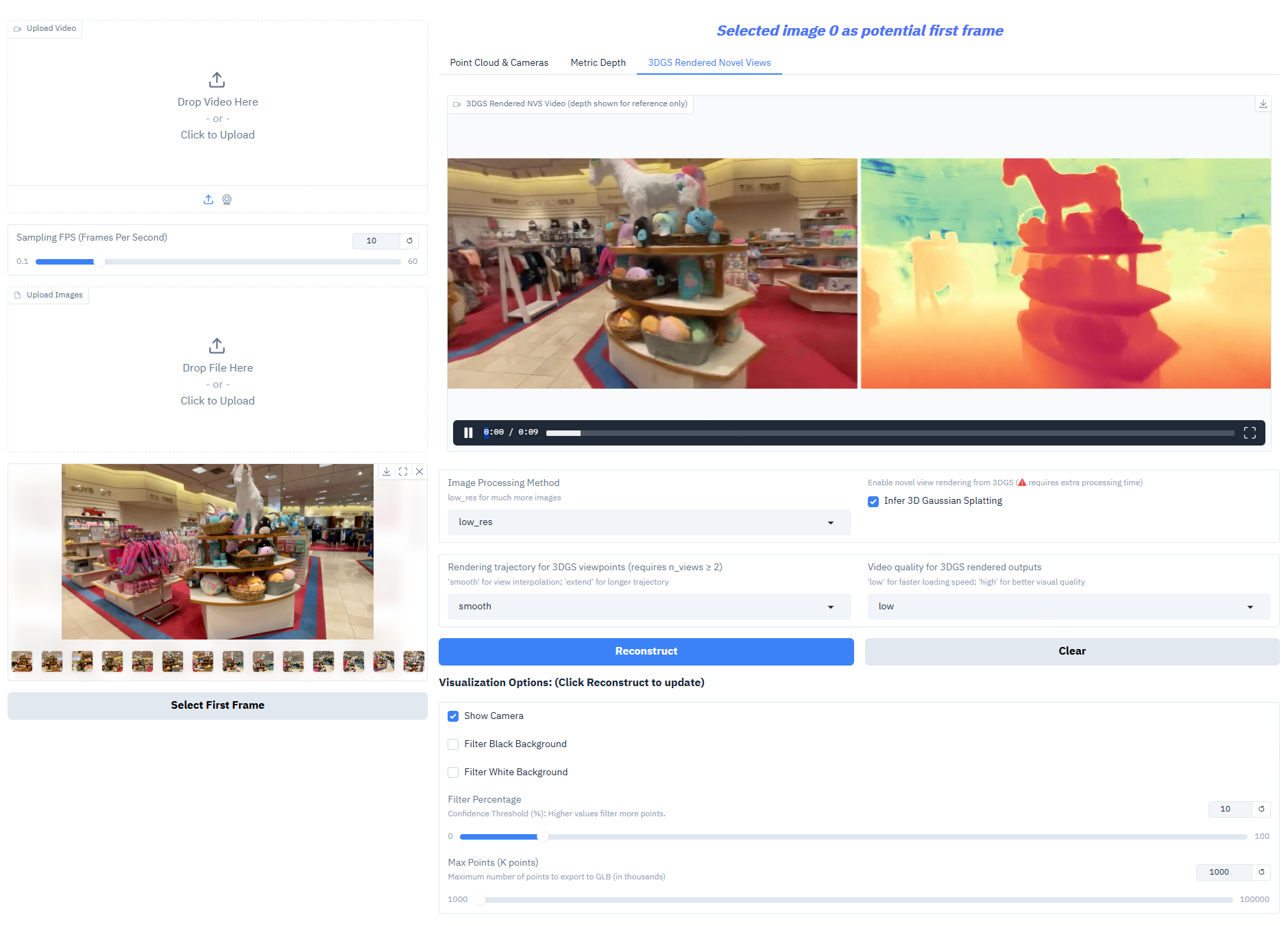
Depth-Anything-3 在核心任务上表现优异:
- 单目深度估计:从单张 RGB 图像生成高精度深度图,还原场景空间层次
- 多视图深度融合:基于多张同场景图像生成一致深度场,支撑高质量 3D 重建
- 相机姿态估计:精准预测相机内外参(外参 [N,3,4] 、内参 [N,3,3]),适配多视角协同任务
- 3D 高斯生成:直接输出高保真 3D 高斯模型,支持新颖视图合成(帧率 ≥30 fps)
- 度量深度输出:Nested 系列模型可生成真实尺度深度,满足测绘、室内设计等场景需求
三、运行步骤
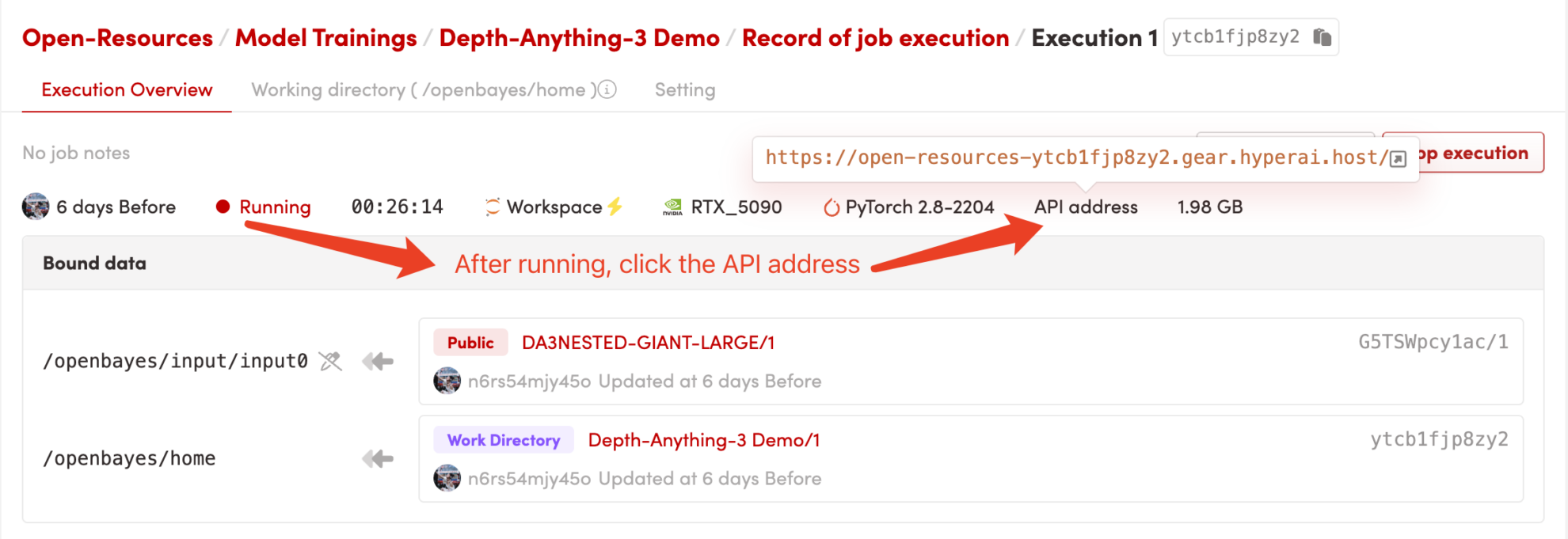
1. 启动容器
启动容器后点击 API 地址即可进入 Web 界面
2. 开始使用
若显示「Bad Gateway」, 这表示模型正在初始化,由于模型较大,请等待 2-3 分钟后刷新页面。
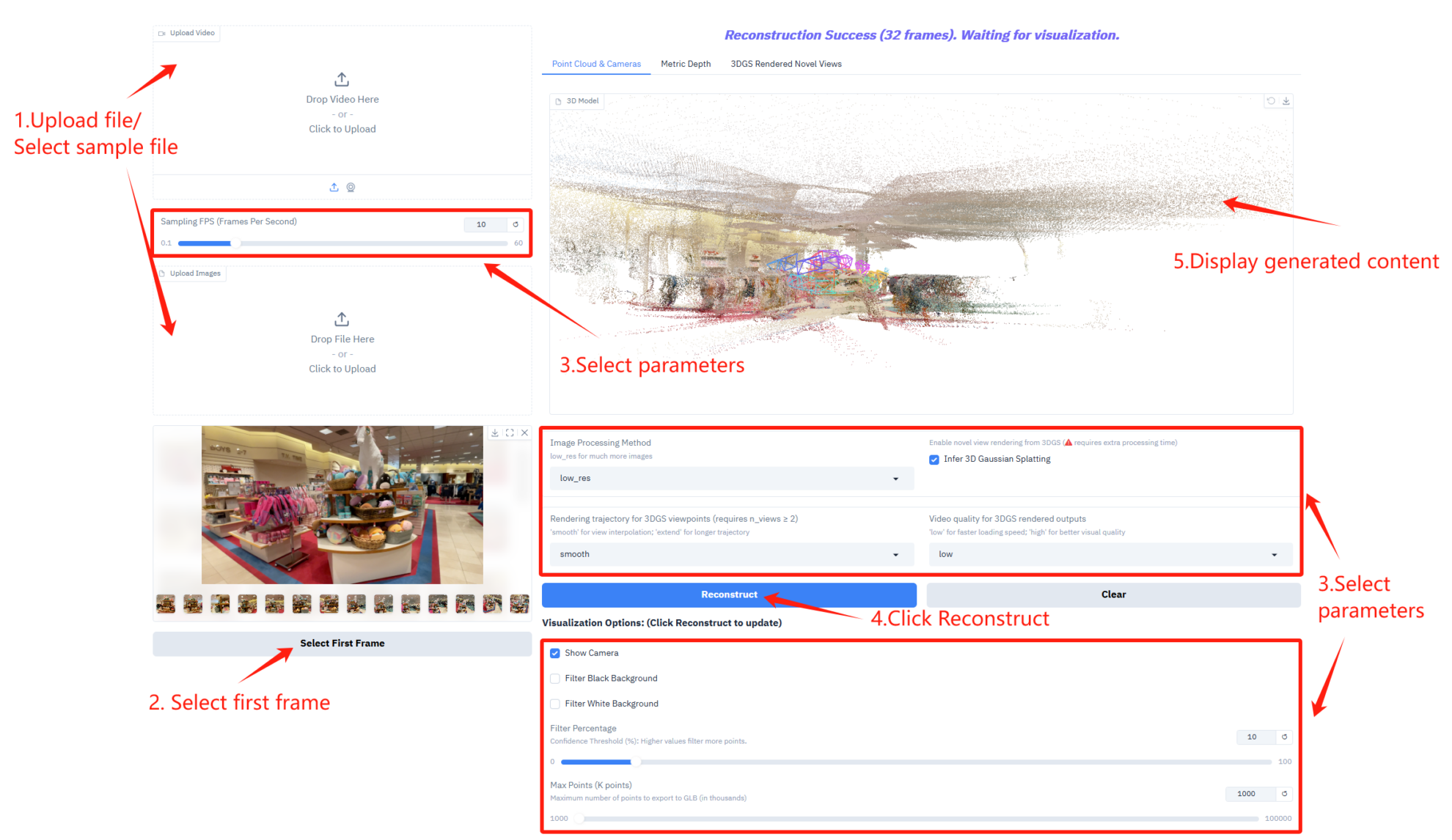
参数说明
- 采样帧率设置
- Sampling FPS (Frames Per Second):控制视频采样的每秒帧数。
- 图像处理与 3D 推理设置
- Image Processing Method:选择图像处理模式,适配更多图像数量。
- Infer 3D Gaussian Splatting:启用 3D 高斯溅射推理,生成 3D 模型需额外处理时间。
- 渲染轨迹与视频质量设置
- Rendering trajectory for 3DGS viewpoints:选择 3DGS 视角的渲染轨迹类型。
- Video quality for 3DGS rendered outputs:控制 3DGS 渲染输出的视频质量。
- 可视化选项
- Show Camera:在 3D 视图中显示相机轨迹。
- Filter Black Background:过滤点云中的黑色背景区域。
- Filter White Background:过滤点云中的白色背景区域。
- Filter Percentage:控制点云过滤强度。
- Max Points (K points):设置导出 GLB 格式 3D 模型的最大点数。
四、交流探讨
🖌️ 如果大家看到优质项目,欢迎后台留言推荐!另外,我们还建立了教程交流群,欢迎小伙伴们扫码备注【SD 教程】入群探讨各类技术问题、分享应用效果↓

引用信息
本项目引用信息如下:
@article{depthanything3,
title={Depth Anything 3: Recovering the visual space from any views},
author={Haotong Lin and Sili Chen and Jun Hao Liew and Donny Y. Chen and Zhenyu Li and Guang Shi and Jiashi Feng and Bingyi Kang},
journal={arXiv preprint arXiv:2511.10647},
year={2025}
}本笔记本由社区用户贡献,仅用于教育和信息传播目的。如果任何内容涉及版权侵权,请通过 [email protected] 联系我们,我们将及时审核并删除。