HyperAI
Command Palette
Search for a command to run...
SoulX-Podcast 面向多方言的播客级长文本语音生成
一、教程简介

SoulX-Podcast 是一款为播客风格的多轮、多说话人对话式语音生成而设计的模型,同时在传统的独白 TTS 任务中也表现出色。
为了满足多轮对话语音生成中更高的自然度要求,SoulX-Podcast 集成了一系列副语言控制,支持中文普通话、英语以及多个中国方言,包括四川话、河南话和粤语,使得播客风格的语音生成更加个性化。相关技术细节可参考论文成果为 SoulX-Podcast: Multi-Speaker, Multi-Dialect Long-Form Podcast Speech Generation。
本教程默认使用资源为单卡 RTX 5090 。
二、项目示例
以下展示了在 OpenBayes 平台中运行 SoulX-Podcast WebUI 的实际界面截图,帮助你快速了解整个流程。
方言演示示例
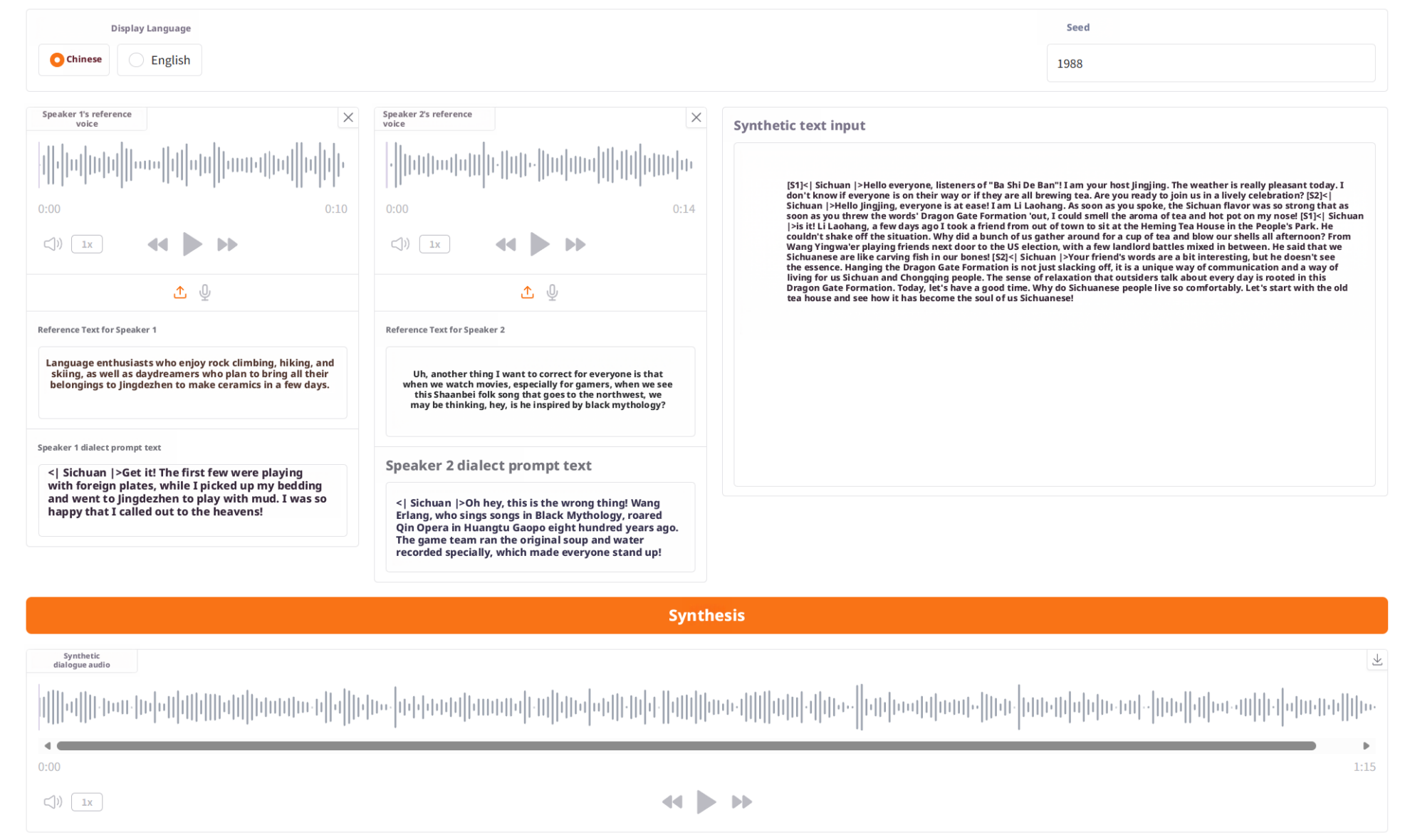
三、运行步骤
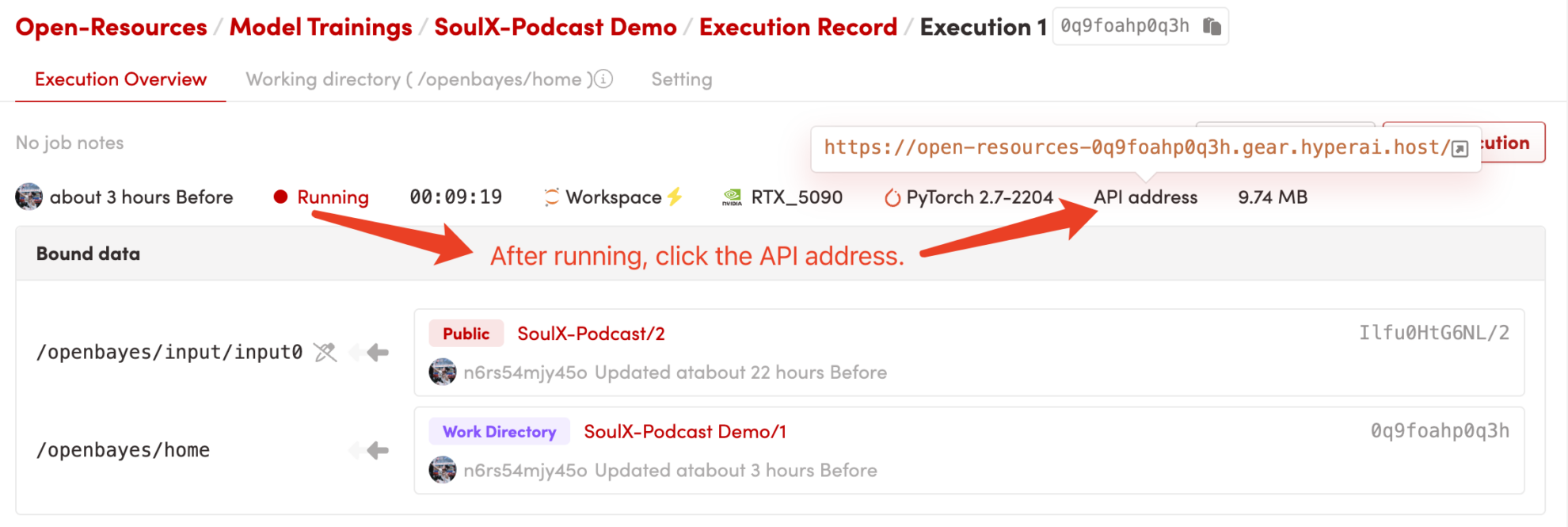
1. 启动容器后点击 API 地址即可进入 Web 界面
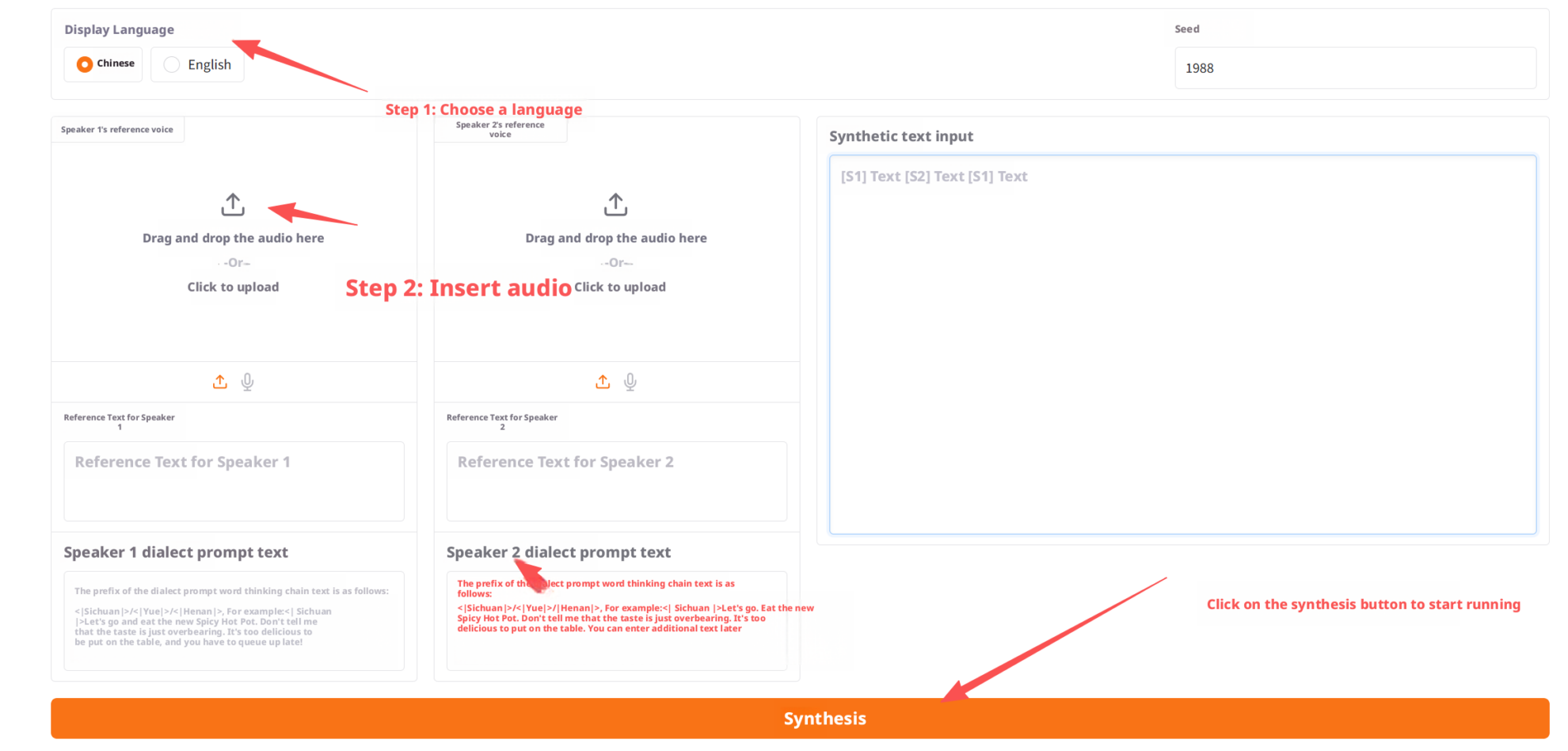
2. 使用步骤
进入 WebUI 后,即可:
- 上传两个说话人的参考音频
- 输入参考文本(可选方言提示)
- 输入完整播客对话脚本
- 点击「生成」按钮
- 查看并播放最终生成的播客音频
示例操作截图如下:
3. 方言提示文本使用步骤
通过为模型提供额外的方言示例文本,可以显著提升生成语音的方言自然度。
流程共 4 步,简单易用。
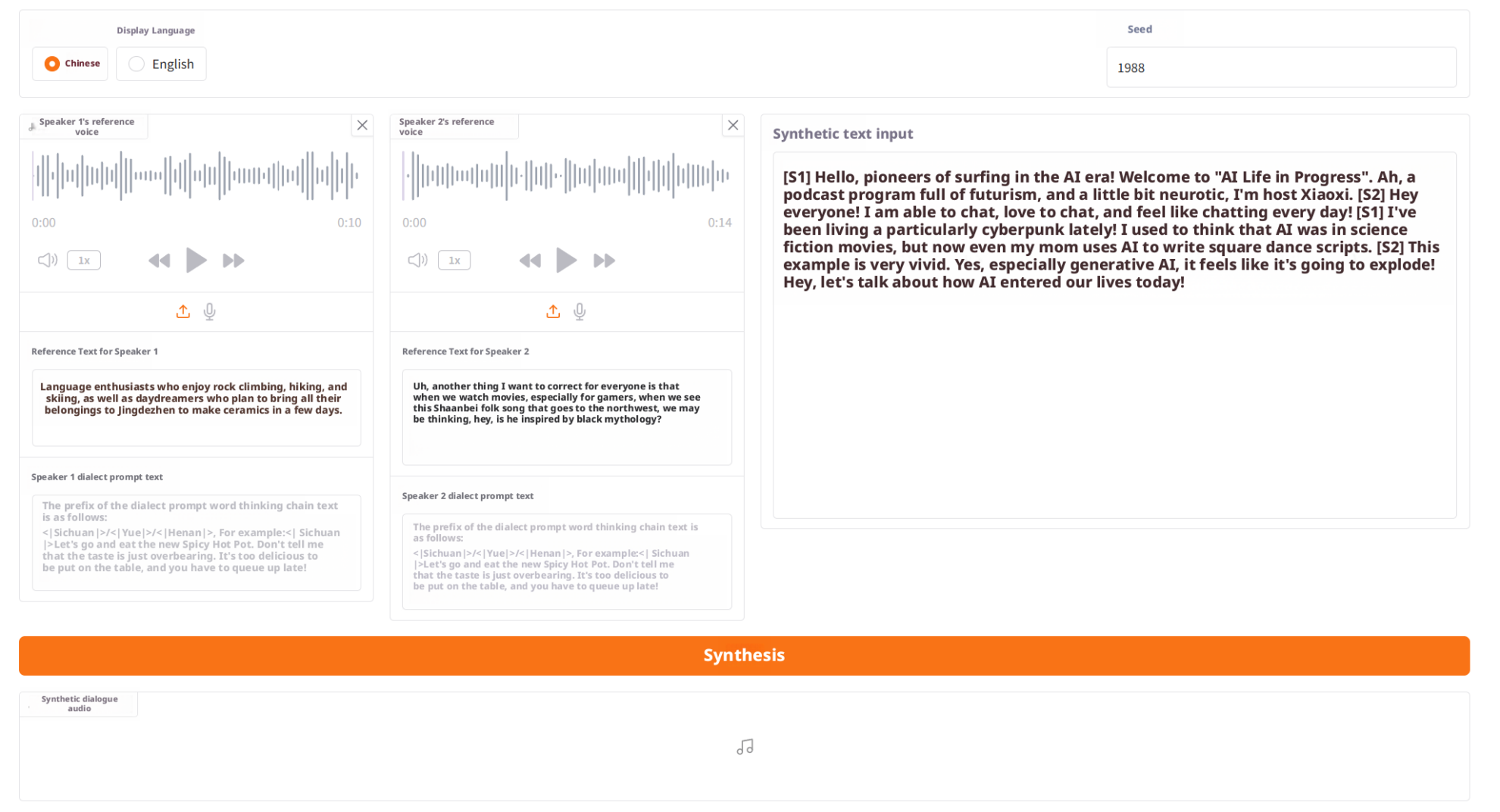
步骤 1:完成基础提示输入
为 S1 和 S2 分别上传或填写:
- 参考语音(Prompt Audio)
- 参考文本(Prompt Text)该步骤用于确定说话人的音色、语气与角色特征,此时尚未启用方言增强。
步骤 2:选择方言
展开方言提示文本选择器,选择希望增强的方言类型。
选择后系统将自动载入该方言的典型示例句。

步骤 3:选择方言示例
为 S1 和 S2 分别选择一条示例句。
点击示例后,内容会自动填入对应的方言提示文本输入框。这些示例将作为方言风格提示,使生成的语音更加地道自然。
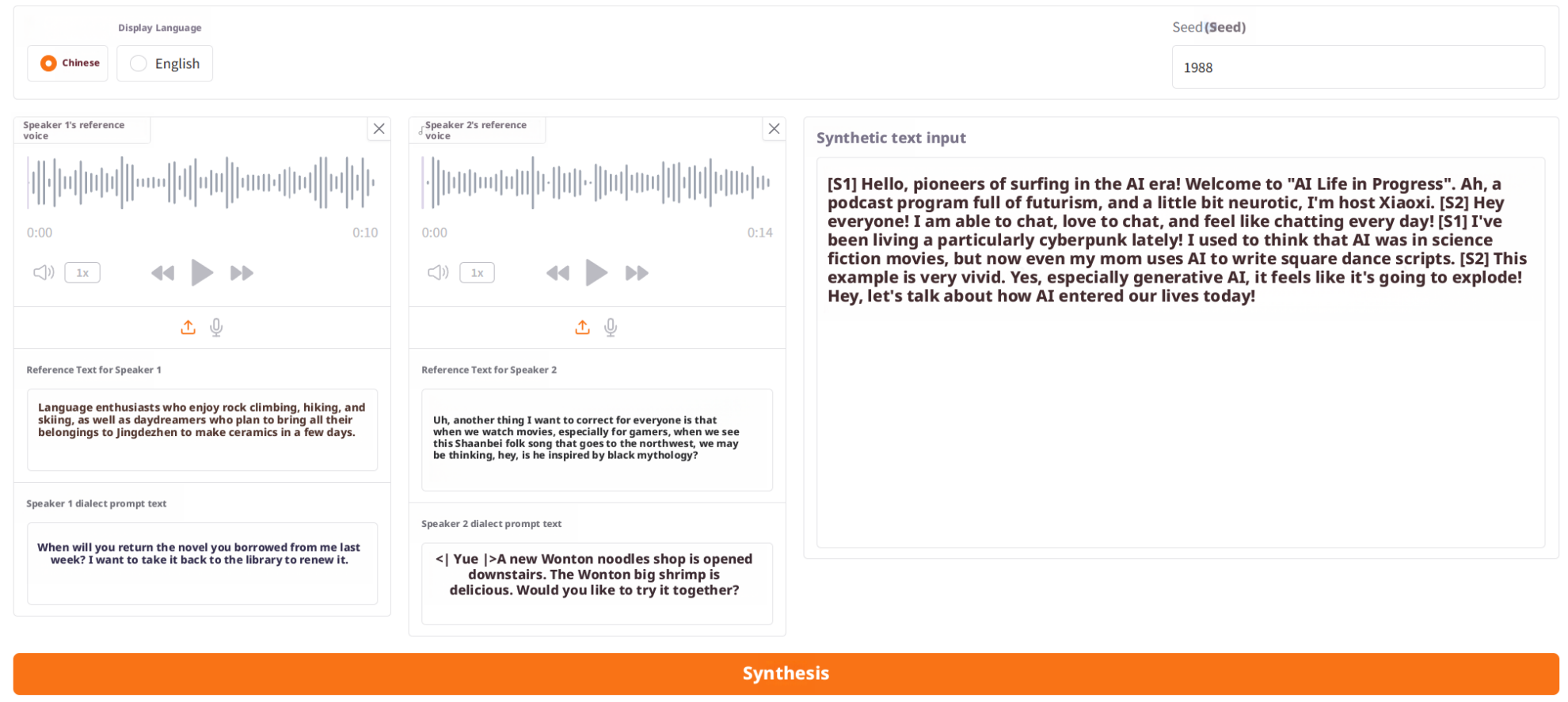
步骤 4:输入合成文本并生成
四、交流探讨
🖌️ 如果大家看到优质项目,欢迎后台留言推荐!另外,我们还建立了教程交流群,欢迎小伙伴们扫码备注【SD 教程】入群探讨各类技术问题、分享应用效果↓

项目支持
@misc{SoulXPodcast, title = {SoulX-Podcast: Towards Realistic Long-form Podcasts with Dialectal and Paralinguistic Diversity}, author = {Hanke Xie and Haopeng Lin and Wenxiao Cao and Dake Guo and Wenjie Tian and Jun Wu and Hanlin Wen and Ruixuan Shang and Hongmei Liu and Zhiqi Jiang and Yuepeng Jiang and Wenxi Chen and Ruiqi Yan and Jiale Qian and Yichao Yan and Shunshun Yin and Ming Tao and Xie Chen and Lei Xie and Xinsheng Wang}, year = {2025}, archivePrefix={arXiv}, url = {https://arxiv.org/abs/2510.23541}}
本笔记本由社区用户贡献,仅用于教育和信息传播目的。如果任何内容涉及版权侵权,请通过 [email protected] 联系我们,我们将及时审核并删除。