HyperAI
Command Palette
Search for a command to run...
论文
每日更新的前沿人工智能研究论文,帮助您紧跟最新的人工智能趋势
用于微调MLLMs的定向推理注入

语言模型是单射的,因此可逆

自由Transformer

























用于微调MLLMs的定向推理注入
语言模型是单射的,因此可逆
自由Transformer
基于机器学习的量子处理单元(QPU)处理时间预测
量子遍历性边缘的建设性干涉观测
VideoAgentTrek:从无标签视频中进行计算机使用预训练
GigaBrain-0:基于世界模型的视觉-语言-行动模型
LoongRL:面向长上下文的高级推理强化学习
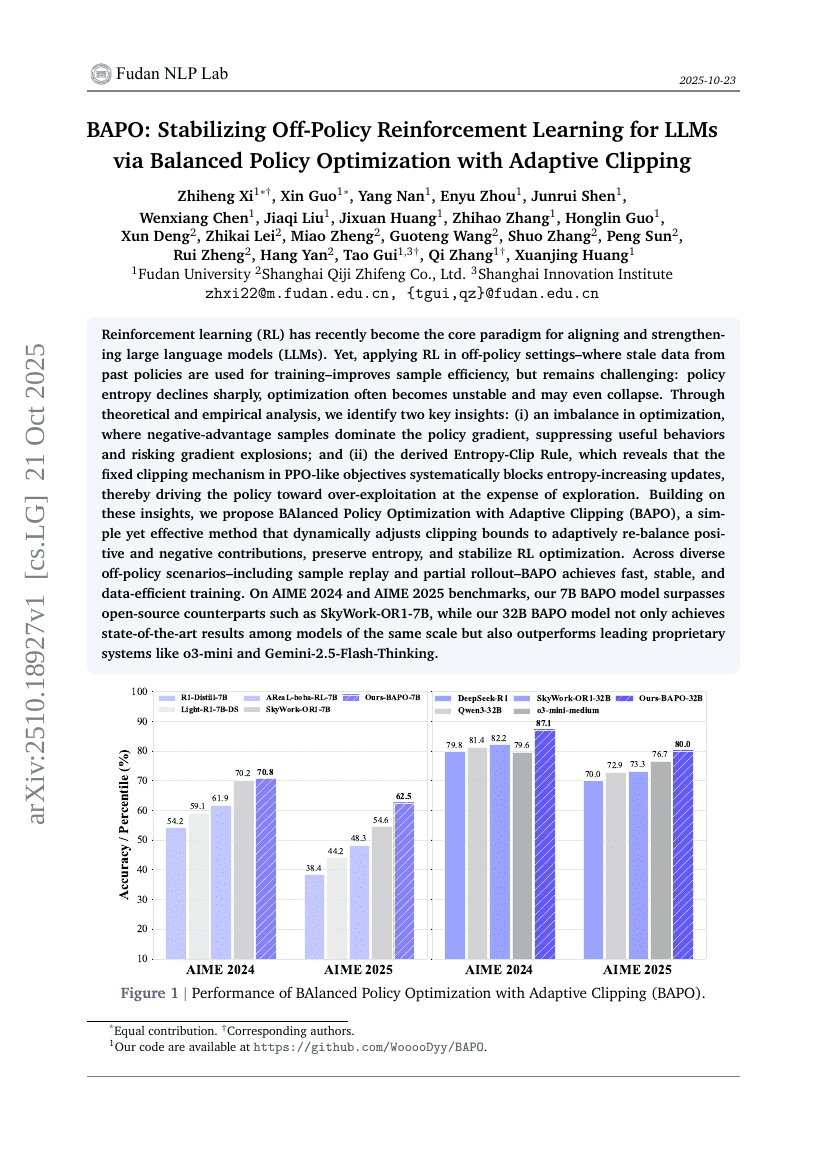
BAPO:通过自适应裁剪的平衡策略优化稳定化LLM的离策略强化学习
每个Attention都至关重要:一种用于长上下文推理的高效混合架构
正确着色:连接感知色彩空间与文本嵌入以提升扩散生成效果
基于视觉-语言模型的自指多视角场景空间推理
LoFT:面向开放世界场景中长尾半监督学习的参数高效微调
FLOWER:通过高效的视觉-语言-动作流策略实现通用机器人策略的民主化
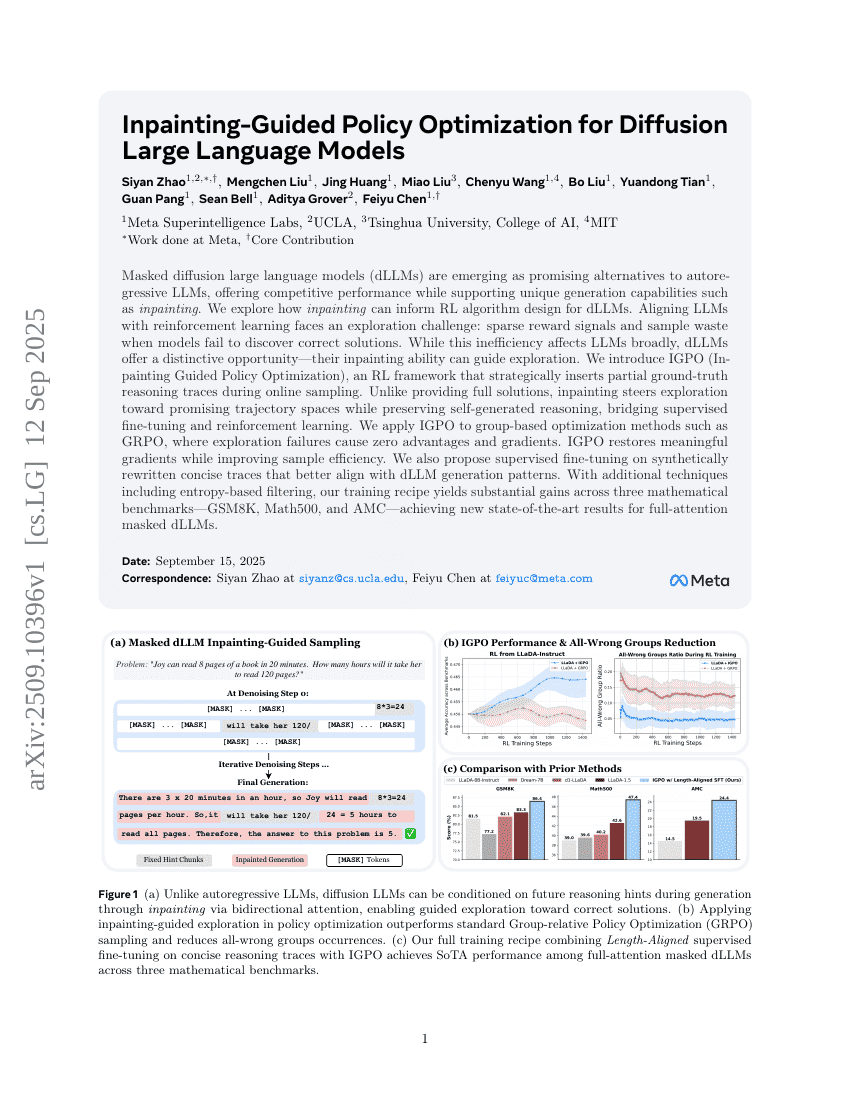
基于图像修复引导的扩散型大语言模型策略优化
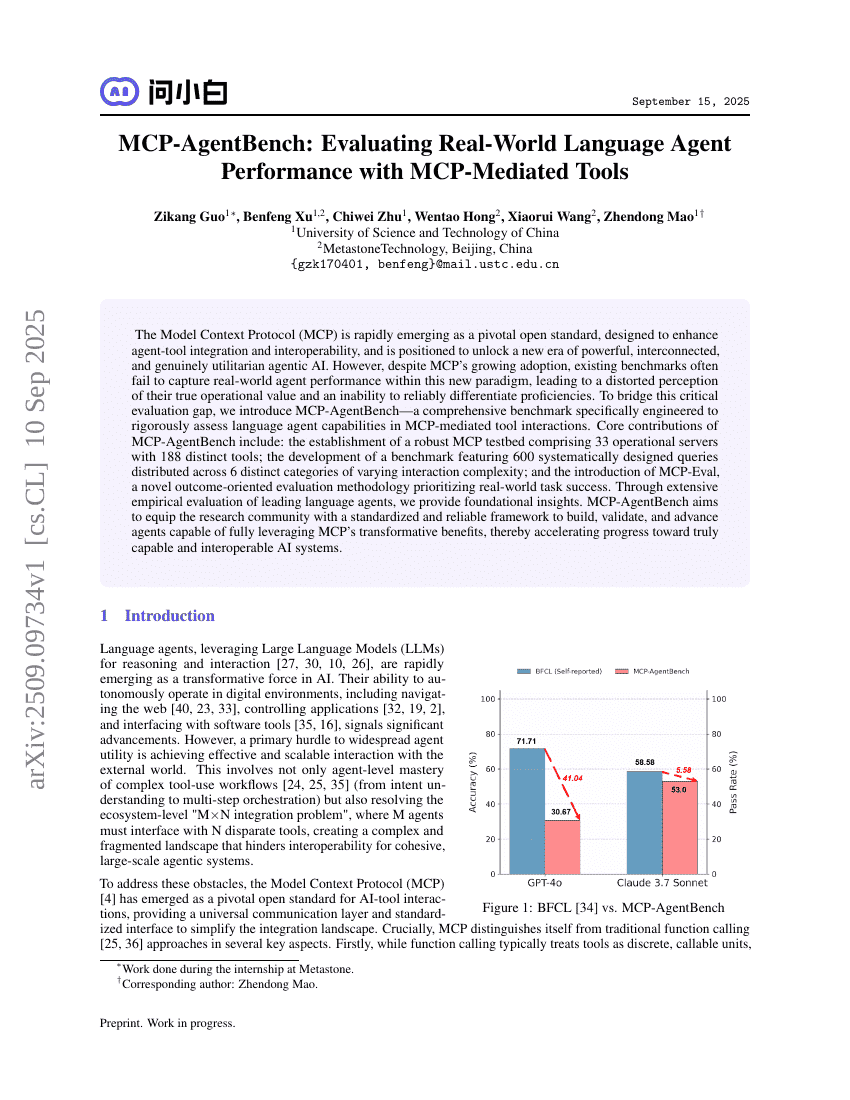
MCP-AgentBench:通过MCP中介工具评估真实世界语言Agent性能
扩散模型中的缓存方法综述:面向高效多模态生成
重新思考驾驶世界模型作为感知任务的合成数据生成器
空间可变对焦
何时进行集成:识别用于稳定且快速LLM集成的token级点
面向通用检索增强生成的混合模态检索
FineVision:开放数据即所需全部
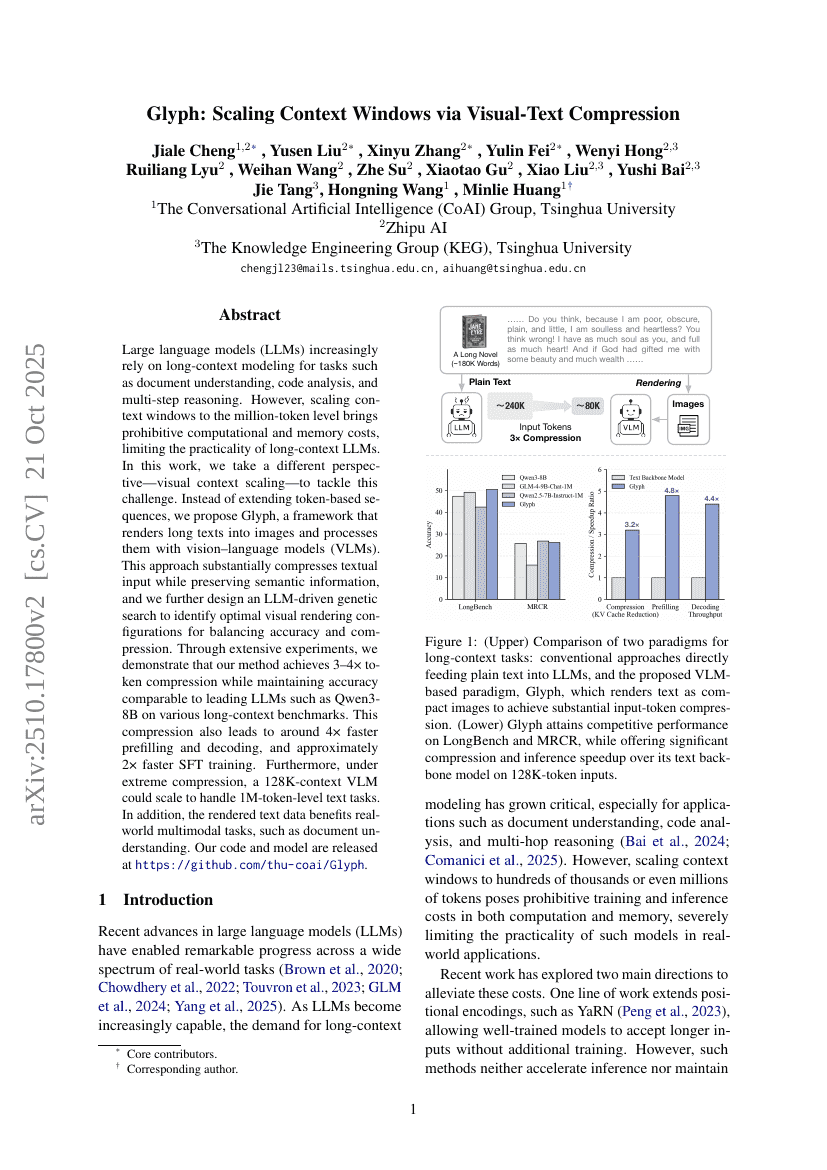
Glyph:通过视觉-文本压缩扩展上下文窗口
PICABench:我们离物理上真实的图像编辑还有多远?
DeepAnalyze:用于自主数据科学的智能体大型语言模型
基于自注意力机制的算子学习3D-IC热仿真
Earth AI:基于基础模型与跨模态推理解锁地理空间洞察
从统计学视角重新思考跨语言鸿沟
通过结构化组件化奖励机制释放科学推理能力以生成生物实验协议
Skyfall-GS:从卫星影像合成沉浸式3D城市场景
上下文学习导致的涌现性错位:有限的上下文示例可导致广泛错位的LLM
NANO3D:一种无需训练的高效3D编辑方法,无需掩码
基于机器学习的量子处理单元(QPU)处理时间预测
量子遍历性边缘的建设性干涉观测
VideoAgentTrek:从无标签视频中进行计算机使用预训练
GigaBrain-0:基于世界模型的视觉-语言-行动模型
LoongRL:面向长上下文的高级推理强化学习
BAPO:通过自适应裁剪的平衡策略优化稳定化LLM的离策略强化学习
每个Attention都至关重要:一种用于长上下文推理的高效混合架构
正确着色:连接感知色彩空间与文本嵌入以提升扩散生成效果
基于视觉-语言模型的自指多视角场景空间推理
LoFT:面向开放世界场景中长尾半监督学习的参数高效微调
FLOWER:通过高效的视觉-语言-动作流策略实现通用机器人策略的民主化
基于图像修复引导的扩散型大语言模型策略优化
MCP-AgentBench:通过MCP中介工具评估真实世界语言Agent性能
扩散模型中的缓存方法综述:面向高效多模态生成
重新思考驾驶世界模型作为感知任务的合成数据生成器
空间可变对焦
何时进行集成:识别用于稳定且快速LLM集成的token级点
面向通用检索增强生成的混合模态检索
FineVision:开放数据即所需全部
Glyph:通过视觉-文本压缩扩展上下文窗口
PICABench:我们离物理上真实的图像编辑还有多远?
DeepAnalyze:用于自主数据科学的智能体大型语言模型
基于自注意力机制的算子学习3D-IC热仿真
Earth AI:基于基础模型与跨模态推理解锁地理空间洞察
从统计学视角重新思考跨语言鸿沟
通过结构化组件化奖励机制释放科学推理能力以生成生物实验协议
Skyfall-GS:从卫星影像合成沉浸式3D城市场景
上下文学习导致的涌现性错位:有限的上下文示例可导致广泛错位的LLM
NANO3D:一种无需训练的高效3D编辑方法,无需掩码