HyperAI
Command Palette
Search for a command to run...
论文
每日更新的前沿人工智能研究论文,帮助您紧跟最新的人工智能趋势
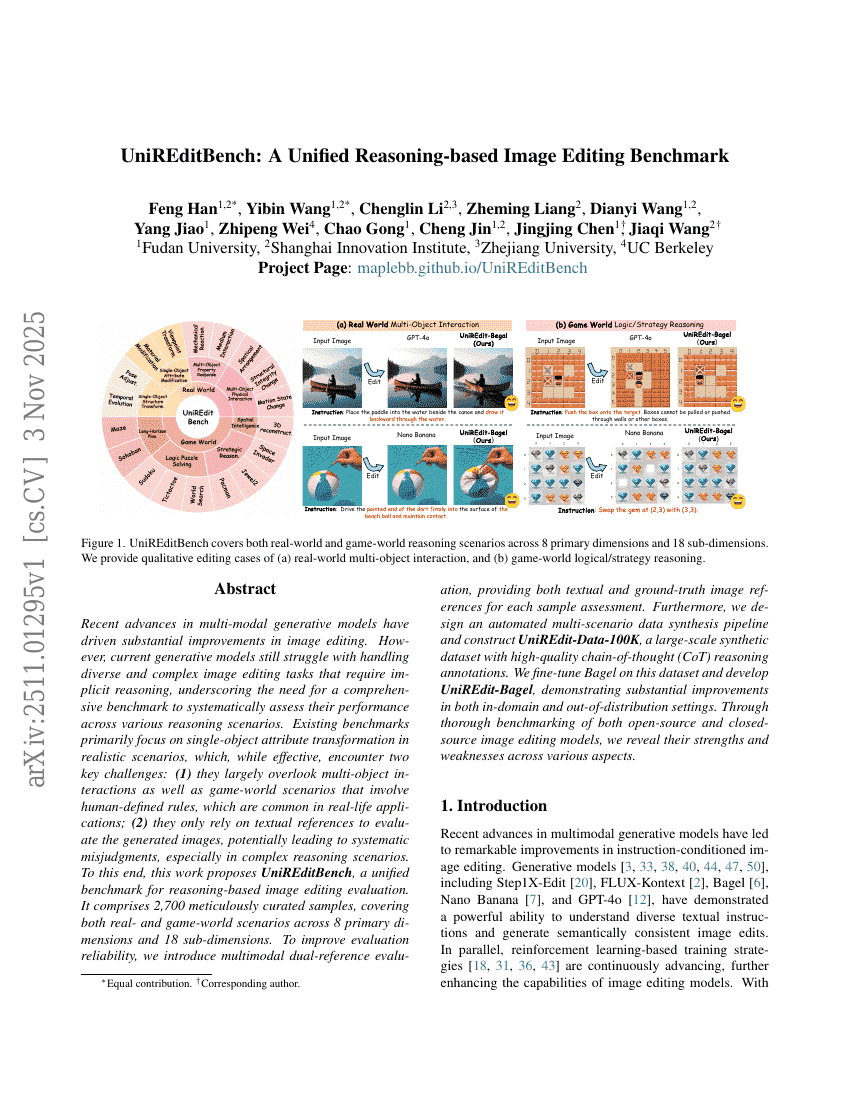
UniREditBench:一个统一的基于推理的图像编辑基准

将测试时计算最优缩放泛化为可优化图




























UniREditBench:一个统一的基于推理的图像编辑基准
将测试时计算最优缩放泛化为可优化图
UniLumos:基于物理合理反馈的快速统一图像与视频重光照
视觉模型在图结构理解中的被低估的力量
每一次激活都更进一步:将通用推理器扩展至1万亿开放语言基础
NOBLE - 具有生物启发的潜在嵌入的神经算子,用于捕捉生物神经元模型中的实验变异性
胶质细胞:一种受人类启发的用于自动化系统设计与优化的AI
上下文工程2.0:上下文工程的上下文
空间-SSRL:通过自监督强化学习增强空间理解
连续自回归语言模型
π𝚁𝙻:基于流的视觉-语言-动作模型的在线RL微调
INT 与 FP:细粒度低比特量化格式的综合研究
ThinkMorph:多模态交错思维链推理中的涌现特性
OS-Sentinel:通过在真实工作流中混合验证实现安全增强的移动GUI Agent
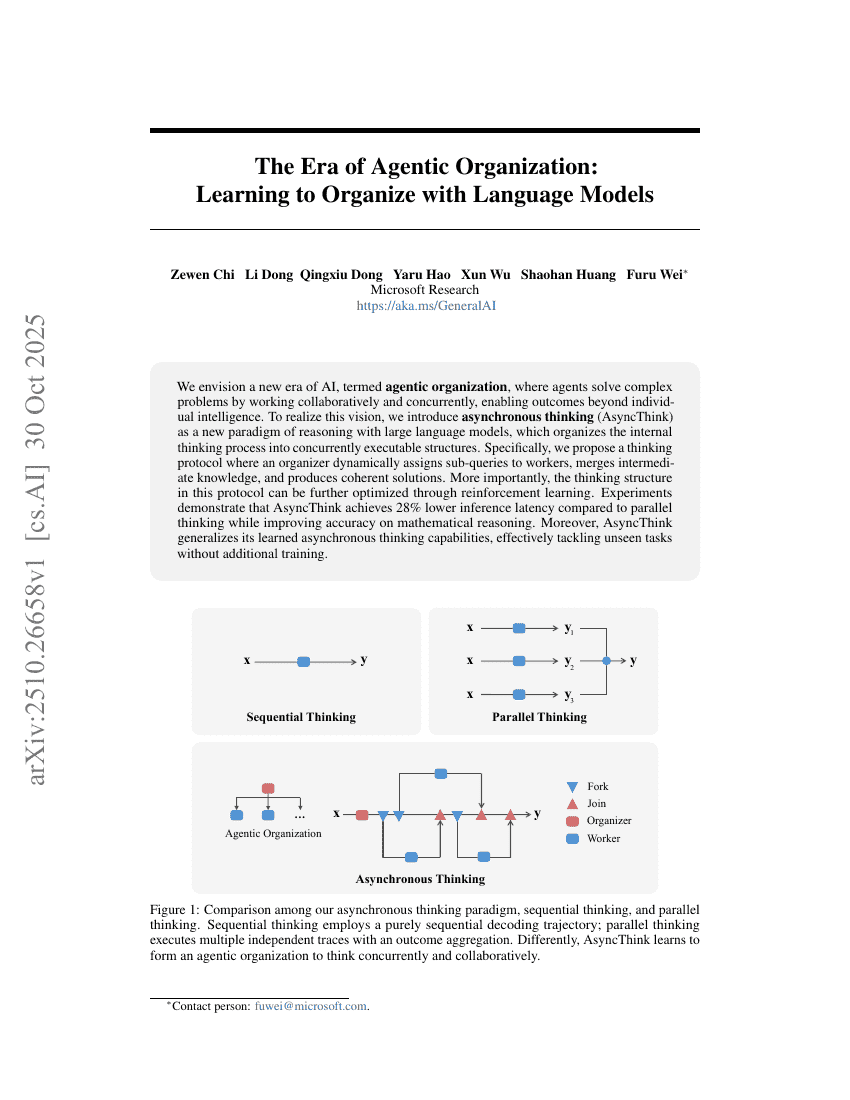
代理型组织时代:与语言模型共同学习组织之道
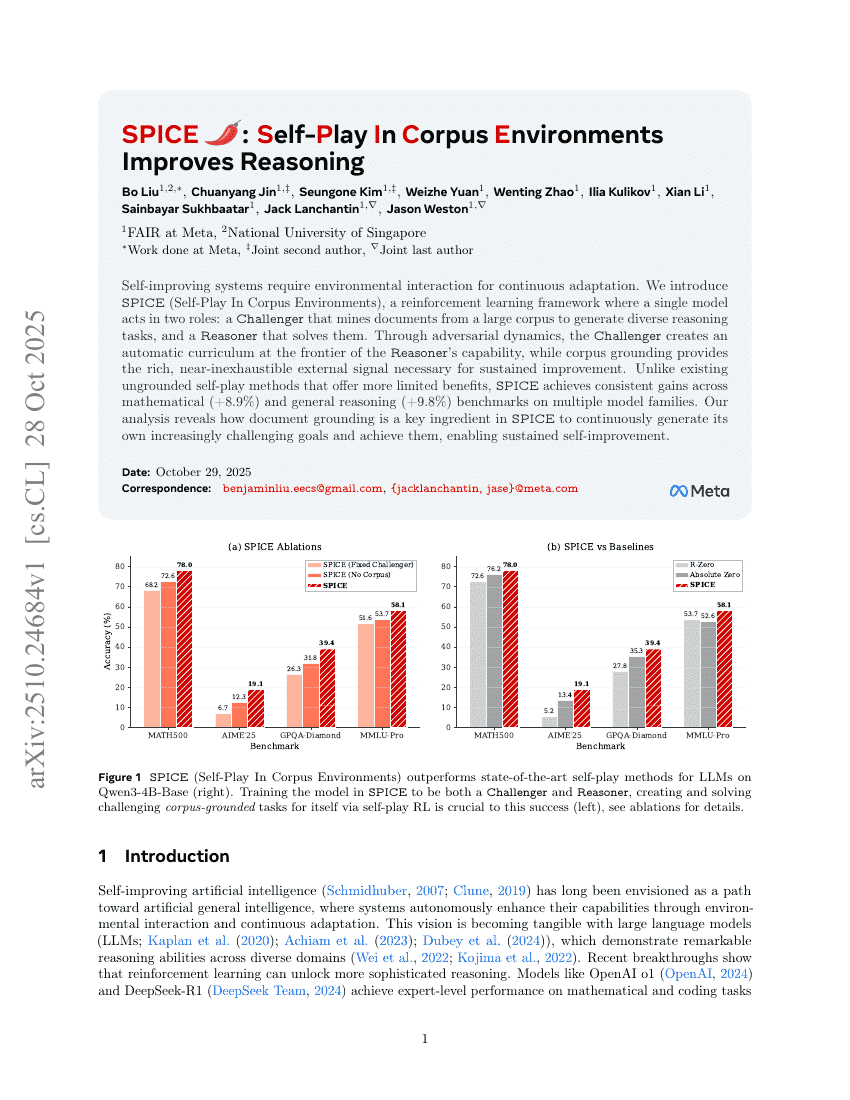
SPICE:在语料库环境中进行自对弈提升推理能力
Surfer 2:下一代跨平台计算机使用Agent
扩散模型在机器人控制中的应用条件探索
Agent 能否征服网络?探索 ChatGPT Atlas Agent 在网络游戏中的前沿应用
Kimi Linear:一种表达性强、高效的Attention架构
Emu3.5:原生多模态模型是世界学习者
手动解码的终结:迈向真正端到端的语言模型
人类与AI的互补性:增强监督的目标
GPTOpt:面向高效基于LLM的黑箱优化
VFXMaster:通过上下文学习解锁动态视觉效果生成
基于流程挖掘的推理感知GRPO
通过循环语言模型实现潜在推理的扩展
ReForm:基于前瞻性有限序列优化的反思式自动形式化
Video-Thinker:通过强化学习激发“用视频进行思考”
JanusCoder:迈向代码智能的基础性视觉-程序化接口
MCP-Flow:助力LLM Agent掌握现实世界中多样化且可扩展的MCP工具
OmniCast:一种用于跨时间尺度天气预报的掩码潜在扩散模型
UniLumos:基于物理合理反馈的快速统一图像与视频重光照
视觉模型在图结构理解中的被低估的力量
每一次激活都更进一步:将通用推理器扩展至1万亿开放语言基础
NOBLE - 具有生物启发的潜在嵌入的神经算子,用于捕捉生物神经元模型中的实验变异性
胶质细胞:一种受人类启发的用于自动化系统设计与优化的AI
上下文工程2.0:上下文工程的上下文
空间-SSRL:通过自监督强化学习增强空间理解
连续自回归语言模型
π𝚁𝙻:基于流的视觉-语言-动作模型的在线RL微调
INT 与 FP:细粒度低比特量化格式的综合研究
ThinkMorph:多模态交错思维链推理中的涌现特性
OS-Sentinel:通过在真实工作流中混合验证实现安全增强的移动GUI Agent
代理型组织时代:与语言模型共同学习组织之道
SPICE:在语料库环境中进行自对弈提升推理能力
Surfer 2:下一代跨平台计算机使用Agent
扩散模型在机器人控制中的应用条件探索
Agent 能否征服网络?探索 ChatGPT Atlas Agent 在网络游戏中的前沿应用
Kimi Linear:一种表达性强、高效的Attention架构
Emu3.5:原生多模态模型是世界学习者
手动解码的终结:迈向真正端到端的语言模型
人类与AI的互补性:增强监督的目标
GPTOpt:面向高效基于LLM的黑箱优化
VFXMaster:通过上下文学习解锁动态视觉效果生成
基于流程挖掘的推理感知GRPO
通过循环语言模型实现潜在推理的扩展
ReForm:基于前瞻性有限序列优化的反思式自动形式化
Video-Thinker:通过强化学习激发“用视频进行思考”
JanusCoder:迈向代码智能的基础性视觉-程序化接口
MCP-Flow:助力LLM Agent掌握现实世界中多样化且可扩展的MCP工具
OmniCast:一种用于跨时间尺度天气预报的掩码潜在扩散模型