HyperAI
Command Palette
Search for a command to run...
论文
每日更新的前沿人工智能研究论文,帮助您紧跟最新的人工智能趋势

CoDA:通过扩散适应进行编码LM
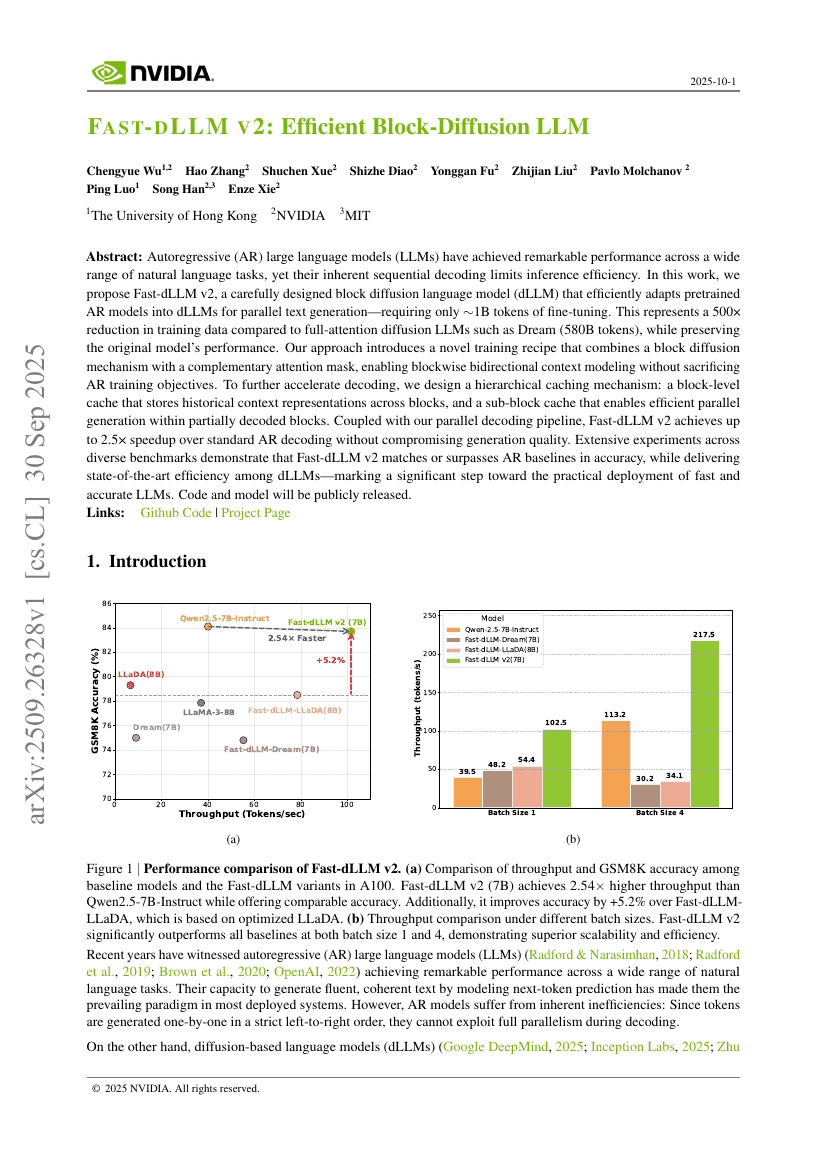
Fast-dLLM v2:高效块扩散LLM










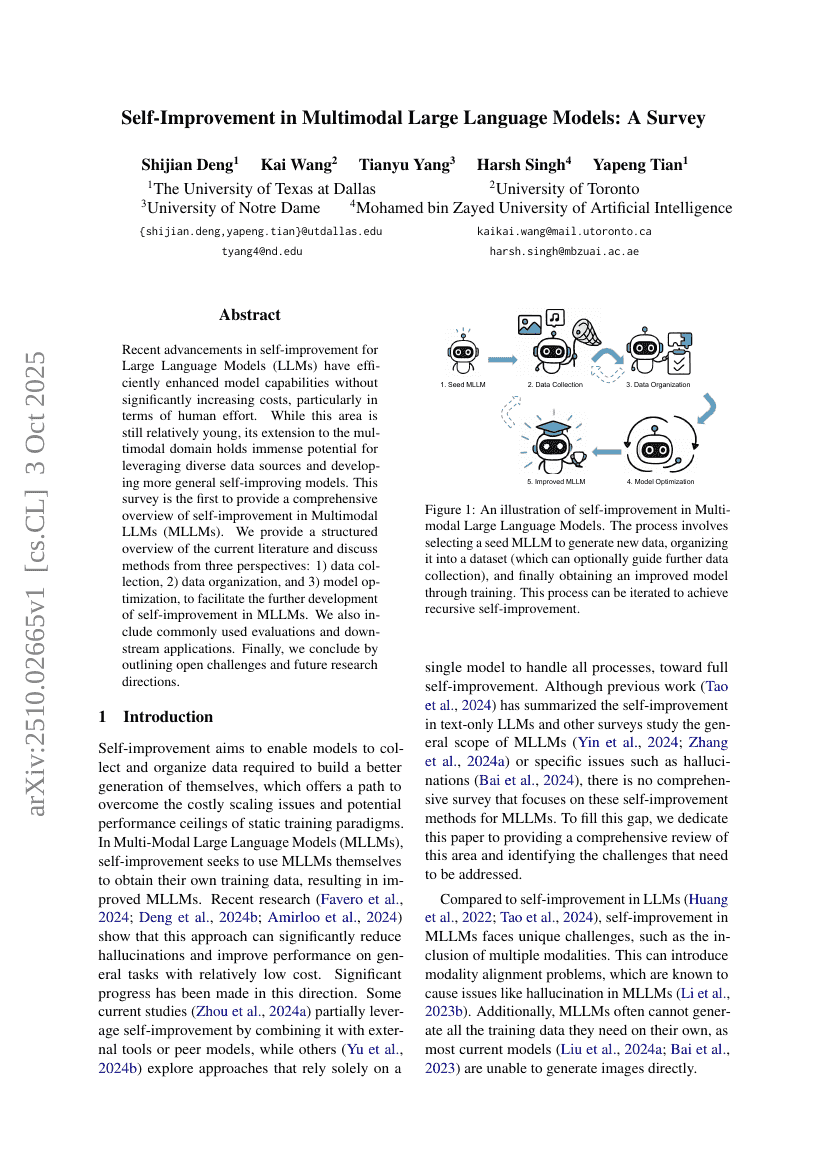

















CoDA:通过扩散适应进行编码LM
Fast-dLLM v2:高效块扩散LLM
少即是多:使用小型网络进行递归推理
Fathom-DeepResearch:解锁长时程信息检索与综合以赋能SLMs
TaTToo:面向表格推理中测试时扩展的工具基础思维PRM
语言模型的混合架构:系统性分析与设计洞察
MITS:通过点互信息增强LLM的树搜索推理
对大型语言模型的不可察觉的越狱攻击
VChain:用于视频生成推理的视觉思维链
视频-LMM后训练:基于大型多模态模型的视频推理深度探究
Paper2Video:从科学论文自动生成视频
微缩扩展FP4量化中的承诺与性能之间的差距
多模态大语言模型中的自提升:一项综述
通过测试时分布级组合改进基于扩散或基于流的机器人策略
大型推理模型从有缺陷的思维中学习到更好的对齐
通过渐进一致性蒸馏实现高效的多模态大型语言模型
Apriel-1.5-15b-Thinker
StockBench:LLM Agent 能否在现实市场中盈利地交易股票?
交互式训练:反馈驱动的神经网络优化
StealthAttack:通过密度引导的幻觉实现鲁棒的3D Gaussian Splatting投毒
ExGRPO:从经验中学习推理
Self-Forcing++:迈向分钟级高质量视频生成
LongCodeZip:为Code LLM压缩长上下文
PIPer:通过在线强化学习实现设备端环境配置
多领域测试时扩展的奖励模型再思考
背包强化学习:通过优化预算分配解锁LLM的探索能力
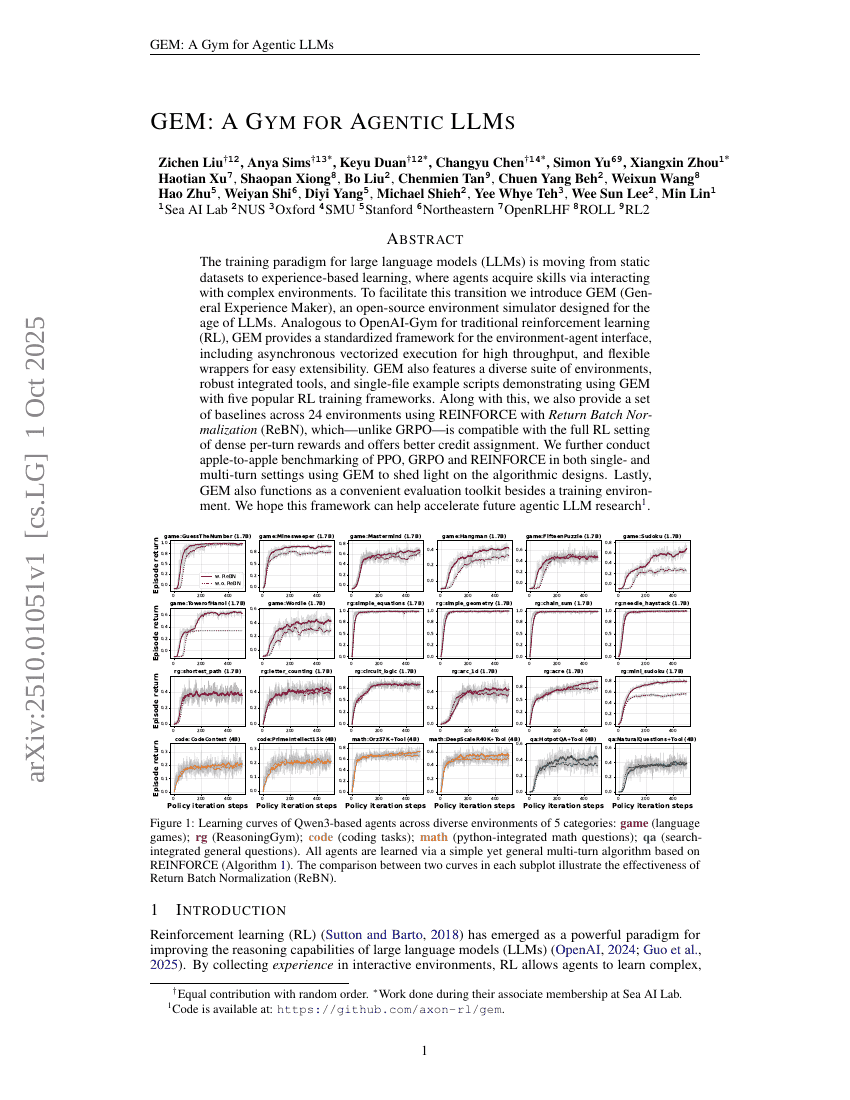
GEM:面向智能体LLM的健身房
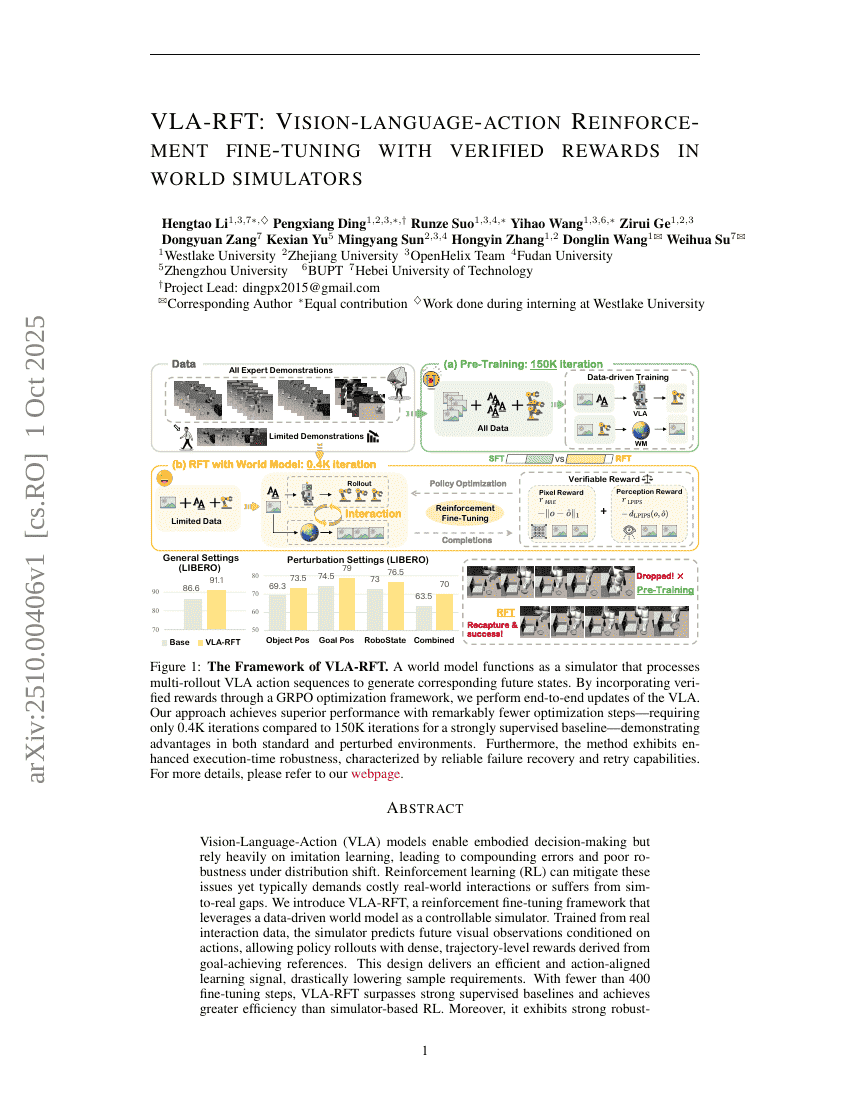
VLA-RFT:基于世界模拟器中验证奖励的视觉-语言-动作强化微调
DeepSearch:通过蒙特卡洛树搜索克服强化学习中可验证奖励的瓶颈
OceanGym:水下具身Agent的基准环境
TruthRL:通过强化学习激励LLM说真话
赢得剪枝赌局:一种面向高效监督微调的联合样本与token剪枝统一方法
少即是多:使用小型网络进行递归推理
Fathom-DeepResearch:解锁长时程信息检索与综合以赋能SLMs
TaTToo:面向表格推理中测试时扩展的工具基础思维PRM
语言模型的混合架构:系统性分析与设计洞察
MITS:通过点互信息增强LLM的树搜索推理
对大型语言模型的不可察觉的越狱攻击
VChain:用于视频生成推理的视觉思维链
视频-LMM后训练:基于大型多模态模型的视频推理深度探究
Paper2Video:从科学论文自动生成视频
微缩扩展FP4量化中的承诺与性能之间的差距
多模态大语言模型中的自提升:一项综述
通过测试时分布级组合改进基于扩散或基于流的机器人策略
大型推理模型从有缺陷的思维中学习到更好的对齐
通过渐进一致性蒸馏实现高效的多模态大型语言模型
Apriel-1.5-15b-Thinker
StockBench:LLM Agent 能否在现实市场中盈利地交易股票?
交互式训练:反馈驱动的神经网络优化
StealthAttack:通过密度引导的幻觉实现鲁棒的3D Gaussian Splatting投毒
ExGRPO:从经验中学习推理
Self-Forcing++:迈向分钟级高质量视频生成
LongCodeZip:为Code LLM压缩长上下文
PIPer:通过在线强化学习实现设备端环境配置
多领域测试时扩展的奖励模型再思考
背包强化学习:通过优化预算分配解锁LLM的探索能力
GEM:面向智能体LLM的健身房
VLA-RFT:基于世界模拟器中验证奖励的视觉-语言-动作强化微调
DeepSearch:通过蒙特卡洛树搜索克服强化学习中可验证奖励的瓶颈
OceanGym:水下具身Agent的基准环境
TruthRL:通过强化学习激励LLM说真话
赢得剪枝赌局:一种面向高效监督微调的联合样本与token剪枝统一方法