HyperAI
Command Palette
Search for a command to run...
WIT 图像-文本数据集
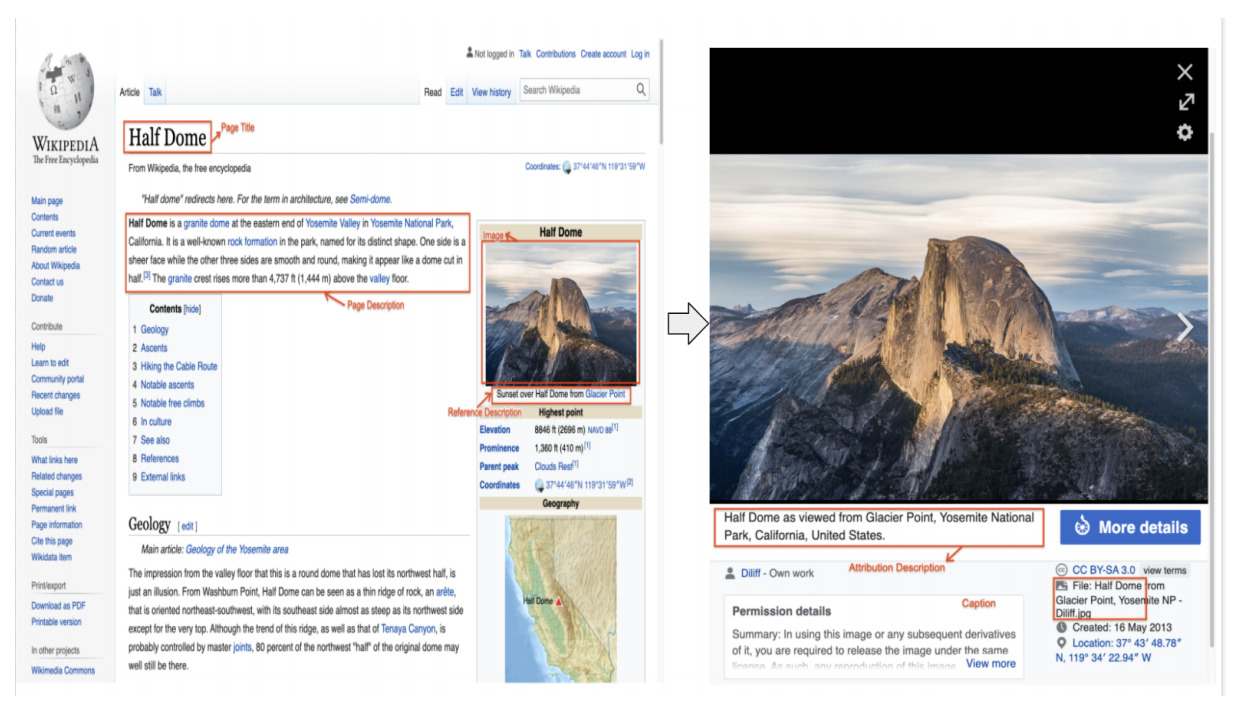
WIT 全称 Wikipedia-based Image Text,是一个大型多模态多语言数据集。该数据集由 3,760 万个实体丰富的图像-文本示例的精选集组成,其中包含 108 种 Wikipedia 语言中的 1,150 万 个唯一图像。该数据集的规模使其可以用作多模态机器学习模型的预训练数据集。 WIT 具有四个独特优势:
- 根据图像文本示例的数量,WIT 是最大的多模式数据集,
- 涵盖了 100 多种语言(每种语言至少有 12,000 个示例),并为许多图像提供了跨语言文本。
- 相对于以前的数据集,WIT 代表了一组更多样化的概念和现实世界实体。
- WIT 提供了一个非常具有挑战性的真实世界测试集。
WIT.torrent
做种 1正在下载 0已完成 611总下载量 809
此数据集由社区用户贡献,仅用于教育和信息目的。如有任何内容涉及版权侵权,请通过 [email protected] 联系我们,我们将及时审核并删除。