Command Palette
Search for a command to run...
هل يمكن للرموز التعبيرية التحكم في توليد الكلام؟ Irodori-TTS هو نظام تحويل النص إلى كلام ياباني يعتمد على بنية RF-DiT؛ مجموعات بيانات أمراض الجلد الأكزيما والسعفة: يدعم تصنيف الصور الطبية والتعلم بالنقل.

Irodori-TTS، وهو مشروع مفتوح المصدر أصدره المطور Aratako في عام 2026، هو جيل جديد من توليف الكلام الياباني ونموذج الاستنساخ بدون تدريب يجمع بين جودة الصوت عالية الدقة وقابلية التشغيل القوية.يعتمد نموذجها الأساسي، Irodori-TTS-500M-v3، الذي يحتوي على 500 مليون معلمة، على مساحة DACVAE الكامنة المستمرة وبنية RF-DiT، والتي يمكنها إخراج صوت احترافي بثبات عند 48 كيلو هرتز مع ضمان الكفاءة الحسابية.في التطبيقات العملية، حقق النموذج إنجازين رئيسيين: أولاً، فهو يتيح "استنساخ الصوت بدون عينة" بسرعة فائقة، حيث يحتاج المستخدمون فقط إلى توفير 3-10 ثوانٍ من الصوت المرجعي لتكرار النبرة المستهدفة بدقة دون أي ضبط دقيق؛ ثانياً، فهو يتيح "التحكم متعدد الأبعاد في الأسلوب"، والذي يجمع بين التعليقات التوضيحية المبتكرة للرموز التعبيرية والتنبؤ التلقائي بالمدة لتحقيق ضبط دقيق للعواطف والنبرة والتعبيرات غير اللفظية الدقيقة.
يعرض موقع HyperAI الآن برنامج "Irodori-TTS-500M-v3: توليف الكلام الياباني والتحكم في نمط الرموز التعبيرية". جربه الآن!
الاستخدام عبر الإنترنت:https://go.hyper.ai/pFPM5
نظرة سريعة على تحديثات موقع hyper.ai الإلكتروني من 27 يونيو إلى 3 يوليو:
* مجموعات بيانات عامة عالية الجودة: 4
* مجموعة مختارة من الدروس التعليمية عالية الجودة: 12
* تحليل مقالات المجتمع: مقال واحد
* إدخالات الموسوعة الشعبية: 5
قم بزيارة الموقع الرسمي:هايبر.اي
مجموعات البيانات العامة المختارة
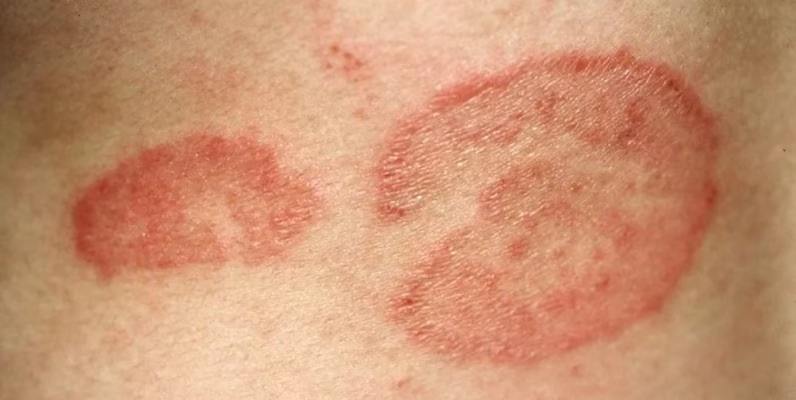
1. مجموعة بيانات أمراض الجلد الأكزيما والسعفة
مجموعة بيانات أمراض الجلد الإكزيما والسعفة هي مجموعة بيانات صور طبية خاصة بأمراض الجلد الإكزيما والسعفة. تهدف هذه المجموعة إلى توفير دعم بيانات أكثر دقة وعملية لمهام تصنيف الصور الثنائية، وتُستخدم على نطاق واسع في تصنيف صور أمراض الجلد، وتدريب نماذج التعلم العميق وتقييمها، وأبحاث التعلم باستخدام عدد قليل من الأمثلة والتعلم بالنقل، وتدريس وتحليل الصور الطبية. تحتوي مجموعة البيانات على 2147 صورة لأمراض جلدية.
الاستخدام عبر الإنترنت:https://go.hyper.ai/nheob
2. مجموعة بيانات التعرف على الأوردة الراحية تحت الجلد SASH-VPV
SASH-VPV هي مجموعة بيانات مرجعية للقياسات الحيوية للأوردة في راحة اليد باستخدام الأشعة تحت الحمراء القريبة، وتُستخدم في أبحاث التعرف على القياسات الحيوية ورؤية الحاسوب. تهدف هذه المجموعة إلى دراسة التحقق من هوية هياكل الأوردة تحت الجلد في راحة اليد، وتُستخدم على نطاق واسع في تطوير أنظمة القياسات الحيوية، وتدريب نماذج التعلم العميق، وأبحاث المتانة عبر الجلسات.
الاستخدام عبر الإنترنت:https://go.hyper.ai/B9xrr

3. مجموعة بيانات تصنيف وتقييم الأنمي النهائية
يُعدّ Ultimate Anime، الذي صدر عام 2026، مجموعة بيانات لتقييم وتصنيف الأنمي، مصممة لدعم بناء أنظمة توصية الأنمي، وتصور بيانات التحليل الاستكشافي، وتحليل اتجاهات الجودة والشعبية على المدى الطويل في صناعة الأنمي. تحتوي هذه المجموعة على بيانات من 3994 عملاً أنمي من قواعد بيانات الأنمي AniList وMyAnimeList، وتغطي معلومات متعددة الأبعاد مثل العنوان، والنوع، وتقييم مجتمع AniList، وإجمالي عدد الحلقات، وحالة البث، والسنة، والملخص، وشركة الإنتاج، والمصدر الأصلي، والشعبية والترتيب، وصورة الغلاف، ووقت البث.
الاستخدام عبر الإنترنت:https://go.hyper.ai/tXtT5
4. مجموعة بيانات أمراض أوراق الورد
تُعدّ مجموعة بيانات أمراض أوراق الورد مجموعة بياناتٍ مُصممة لتوفير صور عالية الجودة تُستخدم في تطوير نماذج الكشف عن هذه الأمراض وتقييمها، وتُستخدم على نطاق واسع في بناء أنظمة مراقبة النباتات. تحتوي النسخة الأصلية من هذه المجموعة على 2458 صورة لأوراق ورد من بنغلاديش، مُصنفة إلى خمسة أنواع: البقعة السوداء، والبياض الزغبي، ولفحة الأوراق، والأوراق السليمة، وثقوب الحشرات.
الاستخدام عبر الإنترنت:https://go.hyper.ai/IuPUO

دروس تعليمية عامة مختارة
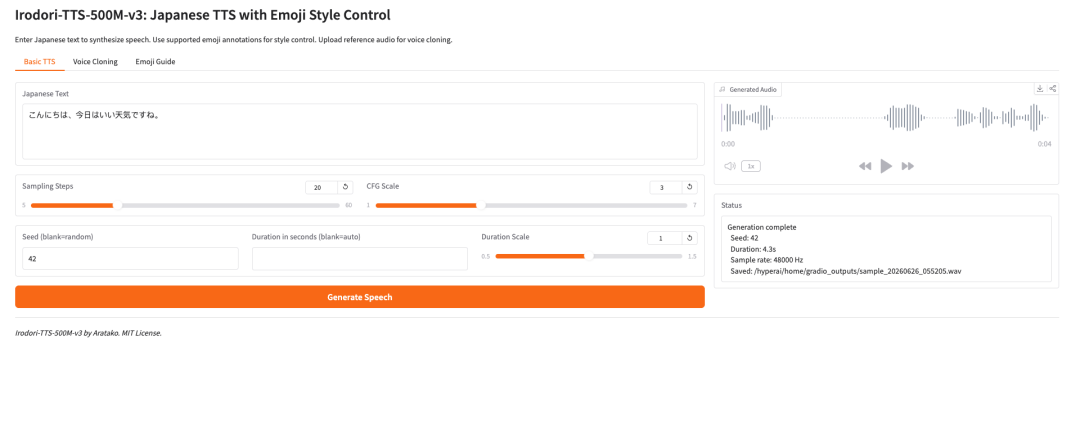
1. Irodori-TTS-500M-v3: توليف الكلام الياباني والتحكم بنمط الإيموجي
مشروع Irodori-TTS، الذي أطلقه المطور أراتاكو في مايو 2026، مخصص لتحويل النص الياباني إلى كلام، واستنساخ الصوت بدون عينات، والتحكم في أسلوب الكلام باستخدام الرموز التعبيرية. تكمن ابتكاراته في استخدام محول انتشار التيار المقوم (RF-DiT) لتوليد كلام بتردد 48 كيلوهرتز في فضاء DACVAE كامن مستمر، بالإضافة إلى شروط صوتية مرجعية، وتوقع تلقائي للمدة، ودقة الرموز التعبيرية للتحكم في النبرة، والعاطفة، والزخارف غير اللفظية.
تشغيل عبر الإنترنت:https://go.hyper.ai/pFPM5
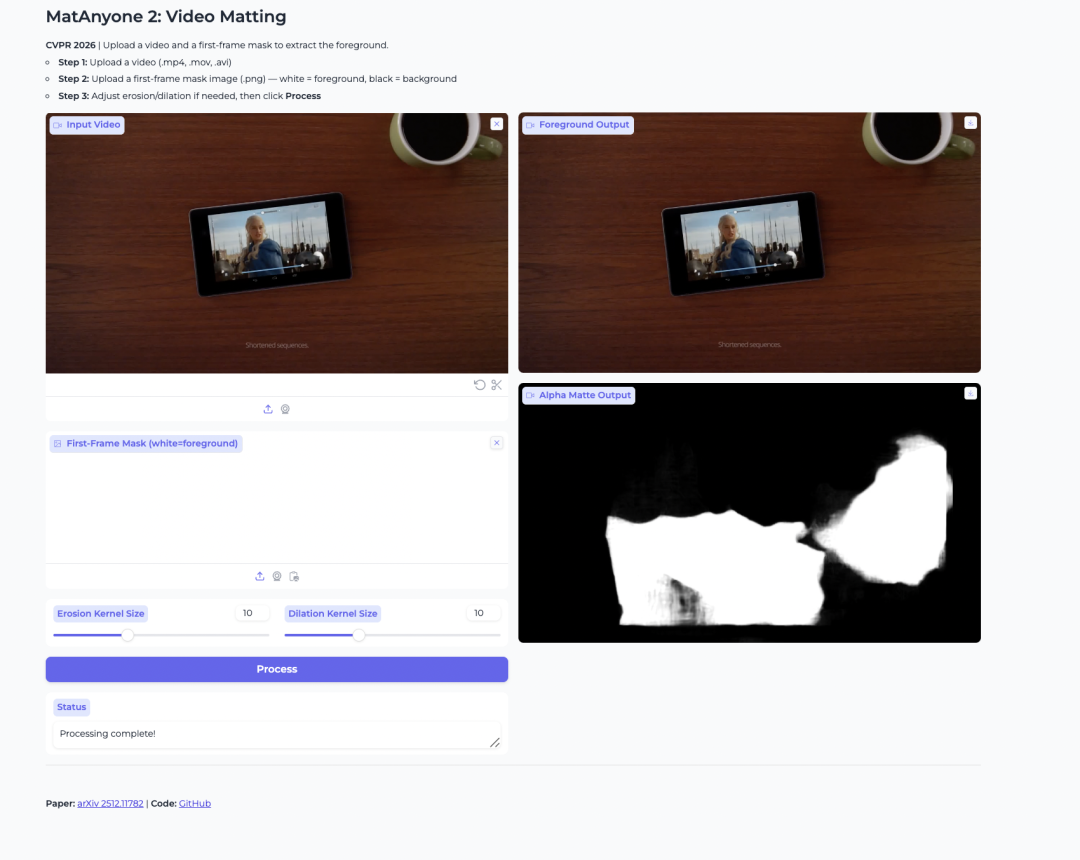
2. نموذج مفتاح الفيديو MatAnyone 2
يُستخدم مشروع MatAnyone 2، الذي أُطلق عام 2026 من قِبل مختبر S التابع لجامعة نانيانغ التكنولوجية وشركة SenseTime، لإزالة خلفية الشخصيات، واستخراج العناصر الأمامية، وتطبيق قناع ألفا في مقاطع الفيديو. ويعتمد ابتكاره على مُقيِّم جودة مُطوَّر ذاتيًا لتحقيق إزالة خلفية مستقرة، والقضاء على تشوهات حدود الصورة، والحفاظ بدقة على تفاصيل الشعر، ودعم إزالة الخلفية المُحدَّدة لشخصيات متعددة.
تشغيل عبر الإنترنت:https://go.hyper.ai/yNeFK
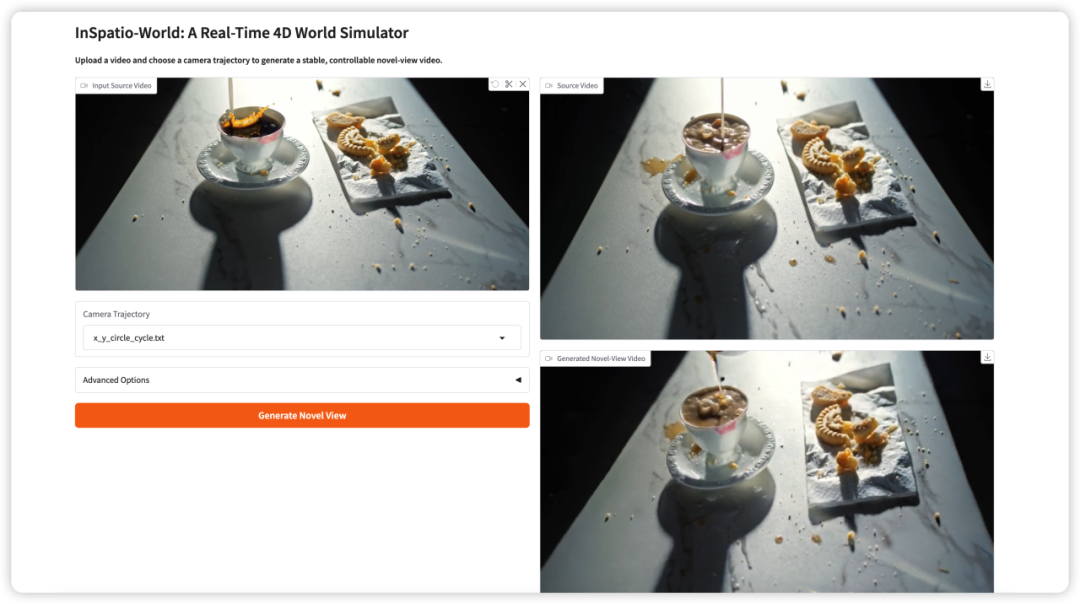
3. إنسباتيو-وورلد: محاكي عالم رباعي الأبعاد في الوقت الحقيقي
InSpatio-World هو محاكي عالم رباعي الأبعاد في الوقت الحقيقي يعتمد على النمذجة الانحدارية المكانية الزمنية، وقد أصدره فريق InSpatio في 19 مارس 2026. يمكنه إنشاء مقاطع فيديو منظور جديدة مستقرة وقابلة للتحكم بناءً على مقاطع الفيديو المدخلة ومسارات الكاميرا المحددة، مما يحقق تحكمًا حرًا في مسارات الكاميرا وتطور العالم المتسق زمنيًا.
تشغيل عبر الإنترنت:https://go.hyper.ai/8FRRy
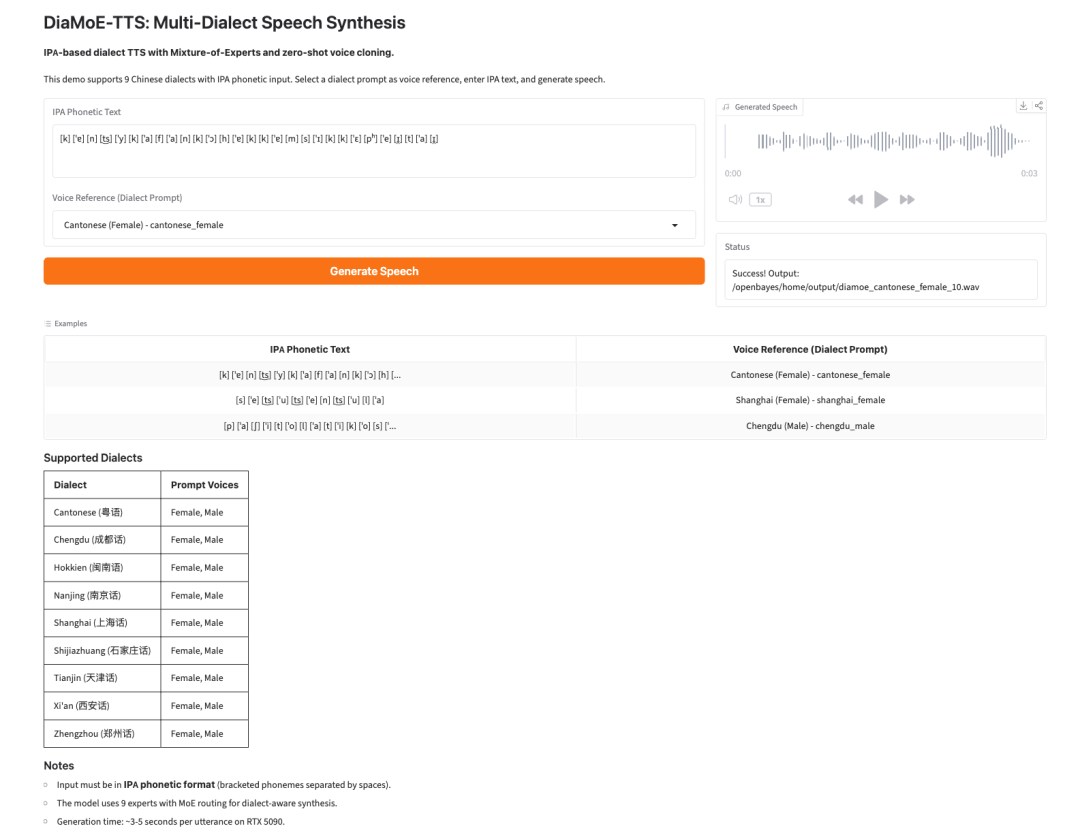
4. DiaMoE-TTS: دليل تعليمي حول توليف الكلام متعدد اللهجات باستخدام الأبجدية الصوتية الدولية (IPA)
يُستخدم مشروع DiaMoE-TTS، الذي أطلقه مختبر Giant AI Lab في سبتمبر 2025، لتوليف الكلام متعدد اللهجات باستخدام الأبجدية الصوتية الدولية (IPA) كواجهة أمامية موحدة. تكمن ابتكاراته في دمج المعرفة الخاصة بكل لهجة في توجيه الخبراء (MoE) وتحقيق تكيف سريع بدون عينات مع اللهجات الجديدة من خلال أساليب معلمات فعالة مثل LoRA / Conditioning Adapter.
تشغيل عبر الإنترنت:https://go.hyper.ai/wn9i5
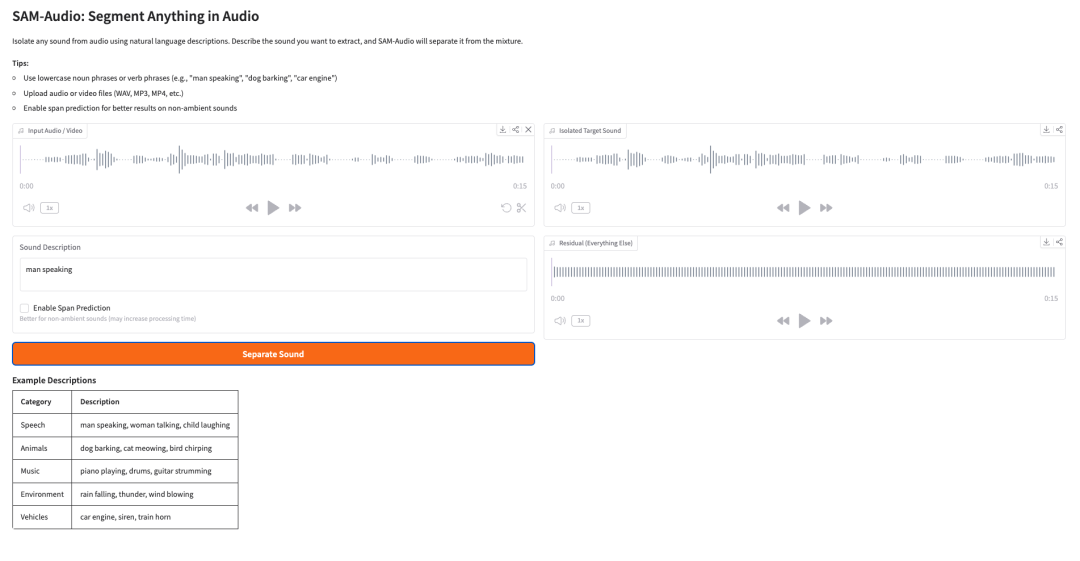
5. SAM-Audio: يفصل الأصوات العشوائية عن الصوت باستخدام معالجة اللغة الطبيعية.
SAM-Audio هو نموذج أساسي لفصل مصادر الصوت أصدرته شركة Meta في ديسمبر 2025. هذا النموذج قادر على فصل أصوات محددة من مزيج صوتي معقد باستخدام أساليب مثل أوصاف اللغة الطبيعية أو الإشارات المرئية للفيديو أو المقاطع الزمنية.
تشغيل عبر الإنترنت:https://go.hyper.ai/svjXe
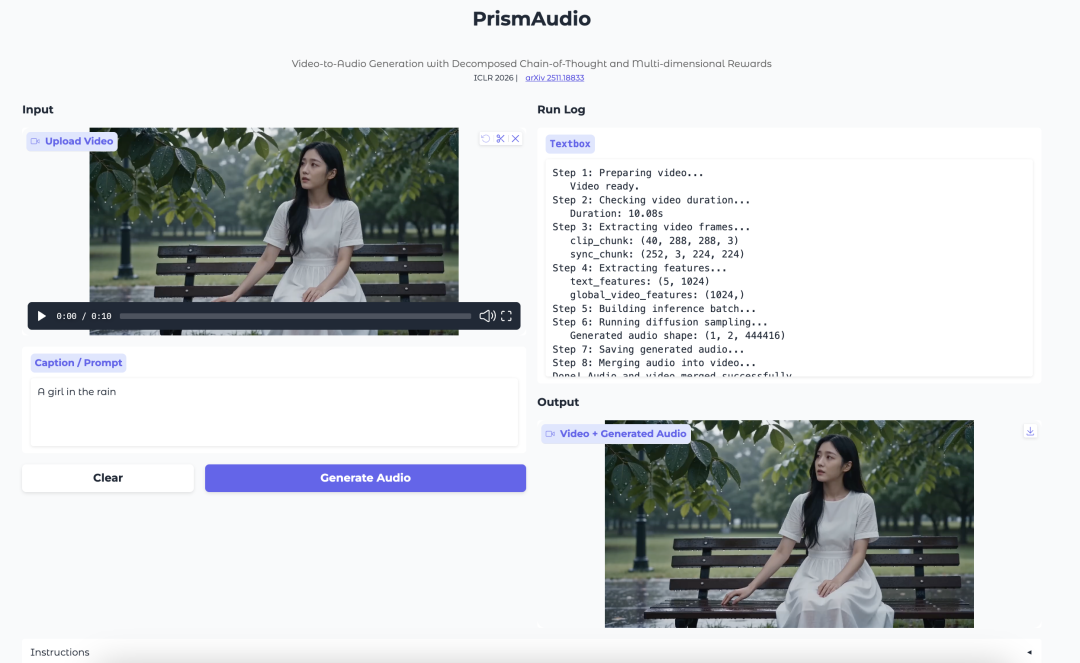
6. PrismAudio: V2A يعتمد على تحليل CoT والمكافآت متعددة الأبعاد
PrismAudio هو نموذج لتوليد الصوت من الفيديو (V2A) أطلقته شركة Tongyi Labs في نوفمبر 2025. يُعد هذا النموذج أول إطار عمل يُدخل التعلم المعزز في توليد الصوت من الفيديو، وهو مبني على آلية تخطيط سلسلة الأفكار (CoT) الخاصة بشركة ThinkSound. يُقسّم النموذج عملية الاستدلال الواحدة إلى أربع وحدات متخصصة ضمن سلسلة الأفكار: الدلالية، والزمانية، والجمالية، والمكانية، ويُزوّد كل وحدة بوظيفة مكافأة مُستهدفة، مما يُحقق تحسينًا متعدد الأبعاد للتعلم المعزز ويُحسّن جودة الاستدلال بشكل شامل عبر جميع الأبعاد الإدراكية.
تشغيل عبر الإنترنت:https://go.hyper.ai/BRGSk
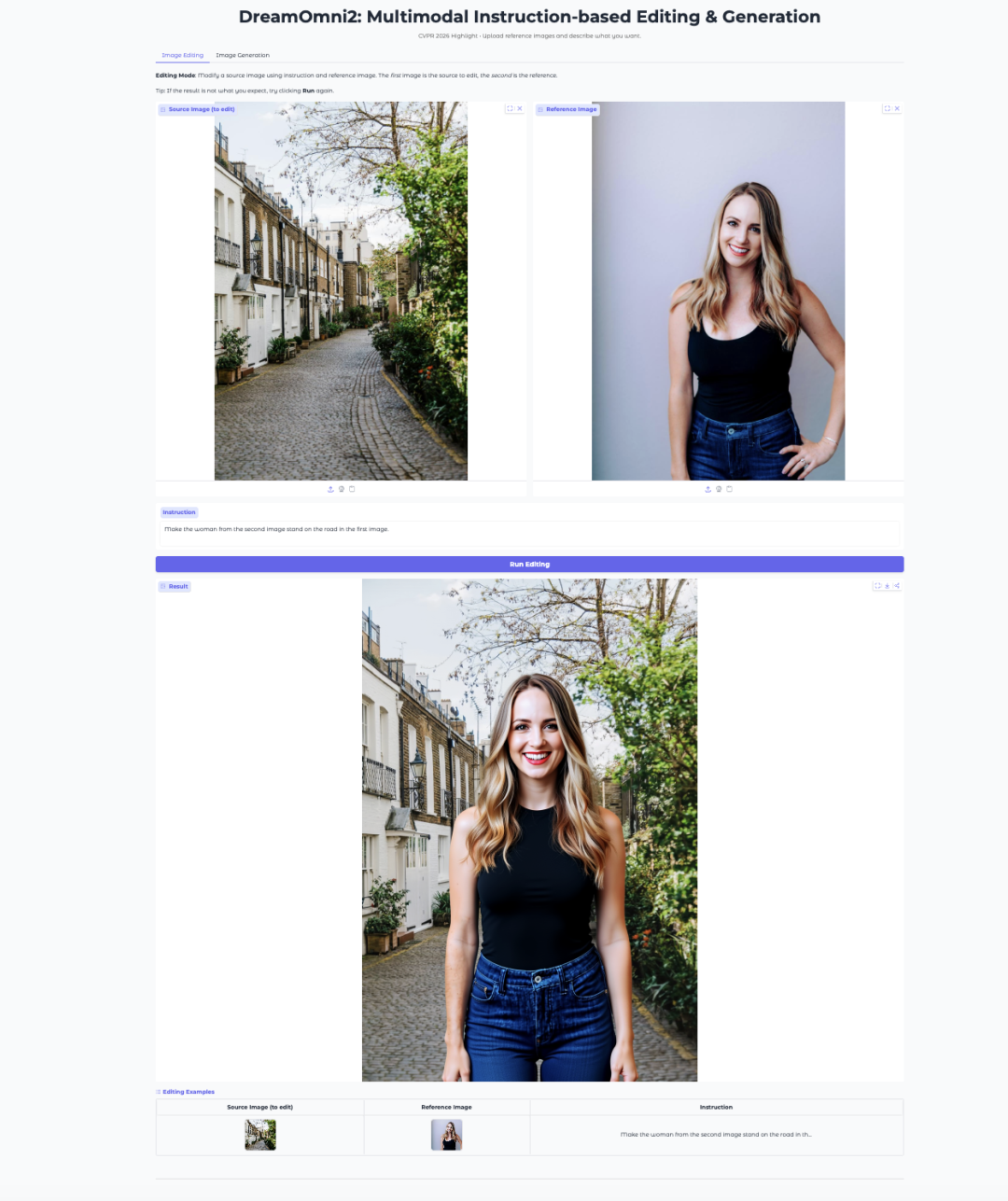
7. دريم أومني 2: تحرير الصور وإنشاؤها باستخدام تعليمات متعددة الوسائط
DreamOmni2 هو نموذج متعدد الوسائط لتحرير الصور وإنشائها، يعتمد على التعليمات، وقد أصدره مختبر JIA في الجامعة الصينية في هونغ كونغ في أكتوبر 2025. وقد تم قبول الورقة البحثية كإحدى الأوراق البحثية المميزة في مؤتمر CVPR 2026. يعتمد هذا النموذج على النموذج الأساسي FLUX.1-Kontext-dev، ويجمعه مع نموذج اللغة المرئية Qwen2.5-VL-7B المُحسَّن بدقة، مما يدعم تحرير الصور وإنشائها من خلال تعليمات اللغة الطبيعية المقترنة بالصور المرجعية.
تشغيل عبر الإنترنت:https://go.hyper.ai/1iqNO
8. PixelRefer: إطار عمل موحد لفهم دقيق للكائنات في الصور ومقاطع الفيديو.
أطلقت أكاديمية علي بابا دامو برنامج PixelRefer في أكتوبر 2025، بهدف تمكين تحديد مركز الكائنات بدقة عالية، وإنشاء التعليقات التوضيحية، والإجابة على الأسئلة في الصور والفيديوهات. ويكمن ابتكاره في اعتماده على إطار عمل موحد متعدد المستويات للنماذج الخطية على مستوى المنطقة (MLLM)، بالإضافة إلى مُجزئ كائنات متكيف مع المقياس (SAOT) وإطار عمل PixelRefer-Lite الفعال الخاص بالكائنات، وذلك لإنشاء تمثيلات مُختصرة للكائنات.
تشغيل عبر الإنترنت:https://go.hyper.ai/ETjjw
9. التعرف الضوئي على الأحرف غير المحدود: نشر بنقرة واحدة لتقنية التعرف الضوئي على الأحرف وتحليل تخطيط المستندات الطويلة
أطلق فريق بايدو مشروع Unlimited-OCR في يونيو 2026. يستهدف هذا المشروع التعرف الضوئي على الأحرف (OCR) وتحليل تخطيطات المستندات الطويلة، بهدف أساسي هو الحفاظ على كفاءة تحليل مستقرة ضمن سياق طويل، وتحقيق تحليل شامل من أول مرة. يستطيع النموذج معالجة صور المستندات المفردة، والصور متعددة الصفحات، وصور الصفحات المحولة من ملفات PDF، مما يجعله مناسبًا للتعرف على النصوص والتحليل المنظم للأوراق والتقارير والمستندات الممسوحة ضوئيًا والجداول الطويلة والمستندات متعددة الصفحات.
تشغيل عبر الإنترنت:https://go.hyper.ai/Bp69q
10. EdgeTAM: نموذج تجزئة الصور والفيديو الممكّن بالإشارات للأجهزة الطرفية.
مشروع EdgeTAM، الذي أطلقته شركة Meta Reality Labs بالتعاون مع مختبر S-Lab التابع لجامعة نانيانغ التكنولوجية في يناير 2025، مصمم لتجزئة الصور وتتبع الأجسام في الفيديو باستخدام الإشارات على الأجهزة ذات الموارد المحدودة. ويكمن ابتكاره الأساسي في استخدام مُدرك مكاني ثنائي الأبعاد مُدمج مع عملية تقطير، مما يقلل من عنق الزجاجة في الذاكرة والانتباه في SAM 2 مع الحفاظ على جودة التجزئة، وبالتالي يُتيح تفاعلاً فعالاً على الجهاز لتتبع أي شيء.
تشغيل عبر الإنترنت:https://go.hyper.ai/yZoqO
11. Step-Audio-EditX: استنساخ الكلام بدون لقطات وتحرير الصوت القائم على التعبيرات، بالاعتماد على 3B LLM
يستهدف مشروع Step-Audio-EditX، الذي أطلقته شركة StepFun في نوفمبر 2025، استنساخ الكلام بدون تدريب مسبق ومهام تحرير الصوت التعبيرية المتكررة. تكمن ابتكاراته في دمج نموذج لغوي ضخم يحتوي على 3 مليارات مُعامل مع التعلم المعزز، مما يجعل العاطفة وأسلوب الكلام والأحداث شبه اللغوية عناصر تحكم منفصلة قابلة للتركيب. يدعم النموذج لغات الماندرين والإنجليزية والسيتشوانية والكانتونية واليابانية والكورية.
تشغيل عبر الإنترنت:https://go.hyper.ai/UL7Hg
12. نيموترون 3.5 ASR Streaming 0.6B: نموذج ASR خفيف الوزن للتعرف على الكلام المتدفق
يُعدّ Nemotron 3.5 ASR Streaming 0.6B نموذجًا للتعرف التلقائي على الكلام ونسخ النصوص المتدفقة بزمن استجابة منخفض، ويحتوي على 60 مليون مُعامل، وقد أطلقته شركة NVIDIA في يونيو 2026. يستخدم هذا النموذج بنية FastConformer-RNNT المُدركة لذاكرة التخزين المؤقت، والتي تُعيد استخدام سياق المُشفّر أثناء الاستدلال المتدفق، مما يُقلل من العمليات الحسابية الزائدة. كما يدعم شروط الإشارة إلى مُعرّف اللغة، مما يُتيح النسخ عبر مناطق لغوية مُتعددة.
تشغيل عبر الإنترنت:https://go.hyper.ai/mFejg
تفسير مقالة المجتمع
1. تقترح شركة Meta علماء بيانات الذكاء الاصطناعي، وتقوم شركة Autodata ببناء مجموعات بيانات تدريب/تقييم عالية الجودة.
اقترح فريق أبحاث الذكاء الاصطناعي الأساسي في ميتا طريقة عامة تُسمى "البيانات التلقائية"، حيث يتولى وكيل ذكي، يعمل كـ"عالم بيانات"، مسؤولية بناء البيانات وتنظيمها. ويحاكي سلوكه عملية عالم البيانات البشري لإنتاج بيانات عالية الجودة. لا تقتصر هذه العملية على توليد البيانات الأولية فحسب، بل تشمل أيضًا مرحلة تحليل البيانات، وتقييم أدائها، وتلخيص التجارب، وتوليد حلول بيانات أفضل بشكل متكرر بناءً على هذه التجارب.
شاهد التقرير الكامل:https://go.hyper.ai/UThkc
مقالات موسوعية شعبية
1. نموذج اللغة الكبير (LLM)
2. نموذج العمل العالمي (WAM)
3. المتوسط التوافقي
4. الفحص الافتراضي
5. التعلم المعزز القائم على التغذية الراجعة من الذكاء الاصطناعي (RLAIF)
فيما يلي مئات المصطلحات المتعلقة بالذكاء الاصطناعي التي تم تجميعها لمساعدتك على فهم "الذكاء الاصطناعي" هنا:
إن ما ورد أعلاه هو كل محتوى اختيار المحرر لهذا الأسبوع. إذا كان لديك موارد تريد تضمينها على الموقع الرسمي لـ hyper.ai، فنحن نرحب بك أيضًا لترك رسالة أو إرسال مقال لإخبارنا بذلك!
نراكم في الاسبوع القادم!
حول HyperAI
HyperAI (hyper.ai) هي شركة رائدة في مجال الذكاء الاصطناعي والحوسبة عالية الأداء في الصين.نحن ملتزمون بأن نصبح البنية التحتية في مجال علوم البيانات في الصين وتوفير موارد عامة غنية وعالية الجودة للمطورين المحليين. حتى الآن، لدينا:
* يوفر نقاط تنزيل محلية معجلة لأكثر من 2100 مجموعة بيانات عامة
* يتضمن أكثر من 700 درس تعليمي كلاسيكي وشائع عبر الإنترنت
* تحليل أكثر من 300 دراسة حالة من أوراق بحثية حول الذكاء الاصطناعي للعلوم
* يدعم البحث عن أكثر من 700 مصطلح ذي صلة
* استضافة أول وثائق كاملة حول Apache TVM باللغة الصينية في الصين
قم بزيارة الموقع الرسمي لبدء رحلة التعلم الخاصة بك:








