Command Palette
Search for a command to run...
حقق "حرية التعليق الصوتي" باستخدام 3 ثوانٍ فقط من الصوت: نموذج الكلام مفتوح المصدر Mistral Voxtral-4B-TTS-2603؛ وضع معيارًا جديدًا لجودة البيانات: Sutra 10B Pretraining.

حالياً، غالباً ما تواجه نماذج الكلام الخفيفة صعوبة في تحقيق التوازن بين سلاسة الكلام وكفاءة النشر عند التعامل مع سياقات متعددة اللغات معقدة ودبلجة طويلة. في التطبيقات العملية، لا تتطلب أنظمة الكلام وبث المحتوى فهماً لغوياً عالياً فحسب، بل تتطلب أيضاً تشغيل النموذج بزمن استجابة منخفض في بيئة محلية ودعم التبديل السلس بين لغات متعددة. تشكل هذه السيناريوهات المعقدة تحديات أمام نطاق المعلمات والقدرات الهندسية للنماذج مفتوحة المصدر الحالية.
وفي هذا السياق،أصدرت شركة ميسترال رسمياً طراز Voxtral-4B-TTS-2603. Voxtral TTS هو نموذج متعدد اللغات لتحويل النص إلى كلام، يعتمد على إطار نمذجة هجين. يقوم بتشفير الكلام إلى رموز دلالية وصوتية باستخدام برنامج Voxtral Codec. تتم محاذاة الجزء الدلالي مع النص من خلال تقطير التعرف التلقائي على الكلام (ASR). خلال مرحلة التوليد، يقوم نموذج الانحدار الذاتي، باستخدام وحدة فك التشفير فقط، بتوليد الرموز الدلالية تدريجيًا لضمان اتساق طويل المدى. في الوقت نفسه، يُستخدم نموذج مطابقة التدفق لتوليد الرموز الصوتية بكفاءة في فضاء متصل، مما يوازن بين جودة التوليد وكفاءة الحساب. يدمج هذا التصميم الهجين "الانحدار الذاتي الدلالي + مطابقة التدفق الصوتي" مزايا النمذجة المنفصلة والمتصلة بفعالية، مما يُمكّن النموذج من تحقيق استنساخ كلامي عالي الجودة باستخدام حوالي 3 ثوانٍ فقط من الكلام المرجعي، ويُظهر قدرة تعميم جيدة في سيناريوهات متعددة اللغات.
يعرض موقع HyperAI الإلكتروني الآن "Voxtral 4B TTS 2603 Multilingual Speech Generation"، لذا جربه!
الاستخدام عبر الإنترنت:https://go.hyper.ai/AoY2t
نظرة سريعة على تحديثات الموقع الرسمي لشركة hyper.ai من 30 مارس إلى 5 أبريل:
* مجموعات البيانات العامة عالية الجودة: 8
* مجموعة مختارة من الدروس التعليمية عالية الجودة: 10
* تفسير مقالة المجتمع: 3 مقالات
* إدخالات الموسوعة الشعبية: 5
أهم المؤتمرات التي تنتهي مواعيدها في أبريل: 6
قم بزيارة الموقع الرسمي:هايبر.اي
مجموعات البيانات العامة المختارة
1. مجموعة بيانات البحث عن وظائف لطلاب الجامعات على لوحات الوظائف
تُعدّ هذه المجموعة من البيانات مجموعة بيانات اصطناعية لعملية البحث عن عمل لخريجي الجامعات الجدد، وتحتوي على 100,000 سجل. وتُفصّل هذه البيانات المعلومات الديموغرافية للطلاب (مثل التخصص، وتصنيف الجامعة، والمنطقة)، وأدائهم الأكاديمي (مثل المعدل التراكمي والتدريب العملي)، وعملية تقديم طلبات التوظيف (تقديم الطلب، والمقابلة الأولى، والمقابلة الثانية، وعرض العمل). وبالنسبة للطلاب الذين حصلوا على عروض عمل، تُضاف متغيرات مستهدفة مثل الراتب، وحجم الشركة، ومدى ملاءمة الوظيفة.
الاستخدام المباشر:https://go.hyper.ai/Rj94B
2. مجموعة بيانات أحداث الفيضانات العالمية من Groundsource
تُعدّ هذه المجموعة من البيانات مجموعة بيانات تاريخية عالية الدقة لأحداث الفيضانات، تم إنشاؤها تلقائيًا من بيانات إخبارية عالمية، وتحتوي على 2.6 مليون سجل للفيضانات تغطي أكثر من 150 دولة. خلال معالجة البيانات، استخدم فريق البحث نماذج جيميني اللغوية الكبيرة (LLMs) لاستخراج معلومات مُهيكلة بشكل منهجي، مثل وقت وموقع أحداث الفيضانات، من نصوص إخبارية غير مُهيكلة، مما أدى إلى بناء آلي لأحداث الكوارث التاريخية واسعة النطاق.
الاستخدام المباشر:https://go.hyper.ai/Aj8bq
3. مجموعة بيانات التدريب والتعليم المسبق Sutra 10B
تُعدّ هذه المجموعة من البيانات مجموعة بيانات تعليمية عالية الجودة لتدريب نماذج اللغة الكبيرة مسبقًا. تم إنشاؤها باستخدام إطار عمل Sutra، وهي تُنشئ محتوى تعليميًا مُهيكلًا وتُحسّن عملية تدريب نماذج اللغة. تُعتبر هذه المجموعة الأكبر في سلسلة Sutra، وقد صُممت لتوضيح كيف يُمكن لمجموعات البيانات الكثيفة والمُنسقة جيدًا أن تُوفر أداءً مثاليًا لتدريب نماذج اللغة الصغيرة مسبقًا.
الاستخدام المباشر:https://go.hyper.ai/okKgZ
4. مجموعة بيانات ثقافة الميمات على الإنترنت الصينية zh-meme-sft-8k
تُعدّ هذه المجموعة من البيانات بمثابة مجموعة بيانات مُحسّنة لتعليمات ثقافة الميمات الصينية على الإنترنت، وتُستخدم بشكل أساسي لتدريب نماذج الحوار على فهم واستخدام الميمات الرائجة على الإنترنت. وقد بُنيت هذه المجموعة من تفاعلات التعليقات على منصات التواصل الاجتماعي مثل Douyin وXiaohongshu وBilibili، وخضعت لعدة جولات من التنظيف والتحسين. وتشمل ميزاتها هياكل الحوار من مصادر موثوقة، والحفاظ على جودة عالية للميمات الرائجة بعد جولات التنظيف المتعددة، والتوحيد القياسي باستخدام تنسيق ChatML.
الاستخدام المباشر:https://go.hyper.ai/O0asZ
5. مجموعة بيانات تعليمات المهام الإبداعية للمهنيين المبدعين
تُعدّ هذه المجموعة من البيانات مجموعة بيانات اصطناعية واسعة النطاق وعالية الدقة، مصممة لتدريب وتقييم وضبط وكلاء الذكاء الاصطناعي متعددي الوسائط. تحتوي على 1,070,917 عملية تحكم للوكلاء، تغطي 36 بيئة برمجية إبداعية وتقنية وهندسية. تهدف هذه المجموعة من البيانات إلى استكشاف التفاعلات البرمجية المعقدة والاستدلال متعدد الخطوات.
الاستخدام المباشر:https://go.hyper.ai/Da6qF
6. Nemotron Personas France (مجموعة بيانات الأشخاص الاصطناعية الفرنسية)
تُعدّ هذه المجموعة من البيانات، التي أصدرتها شركة NVIDIA بالتعاون مع شركة Pleias عام 2026، مجموعة بيانات لشخصيات اصطناعية فرنسية. تحتوي على بيانات شخصيات اصطناعية مُولّدة بناءً على التركيبة السكانية والجغرافية والسمات الشخصية الحقيقية للفرنسيين. والهدف منها هو توفير بيانات شخصيات اصطناعية متنوعة لدعم تطوير النماذج من خلال عكس التوزيع الجغرافي والديموغرافي لفرنسا.
الاستخدام المباشر:https://go.hyper.ai/8CmKo
7. مجموعة بيانات الصحة النفسية للطلاب (الصحة النفسية للطلاب والإرهاق)
تُعدّ هذه المجموعة من البيانات مجموعة بيانات اصطناعية واسعة النطاق، مصممة لتحليل مستويات الإرهاق الطلابي والتنبؤ بها من خلال عوامل أكاديمية ونفسية ونمط الحياة. تحتوي على 150,000 سجل طلابي، وتجمع بين السمات الرقمية والفئوية، مما يجعلها مناسبة لمهام التعلم الآلي والتصنيف وتحليل البيانات.
الاستخدام المباشر:https://go.hyper.ai/YL24S
8. الأوبئة والجائحات التاريخية: مجموعة بيانات الأوبئة التاريخية العالمية
تُعدّ هذه المجموعة من البيانات سجلاً شاملاً للأوبئة العالمية الكبرى، وهي مصممة لتوفير مورد جاهز للتحليل. تحتوي على 50 وباءً رئيسياً، بدءاً من طاعون أنطونين عام 165 ميلادي وصولاً إلى كوفيد-19 وجدري القرود عام 2023، وتغطي جميع العصور والمناطق وأنواع مسببات الأمراض.
الاستخدام المباشر:https://go.hyper.ai/AbhHY
دروس تعليمية عامة مختارة
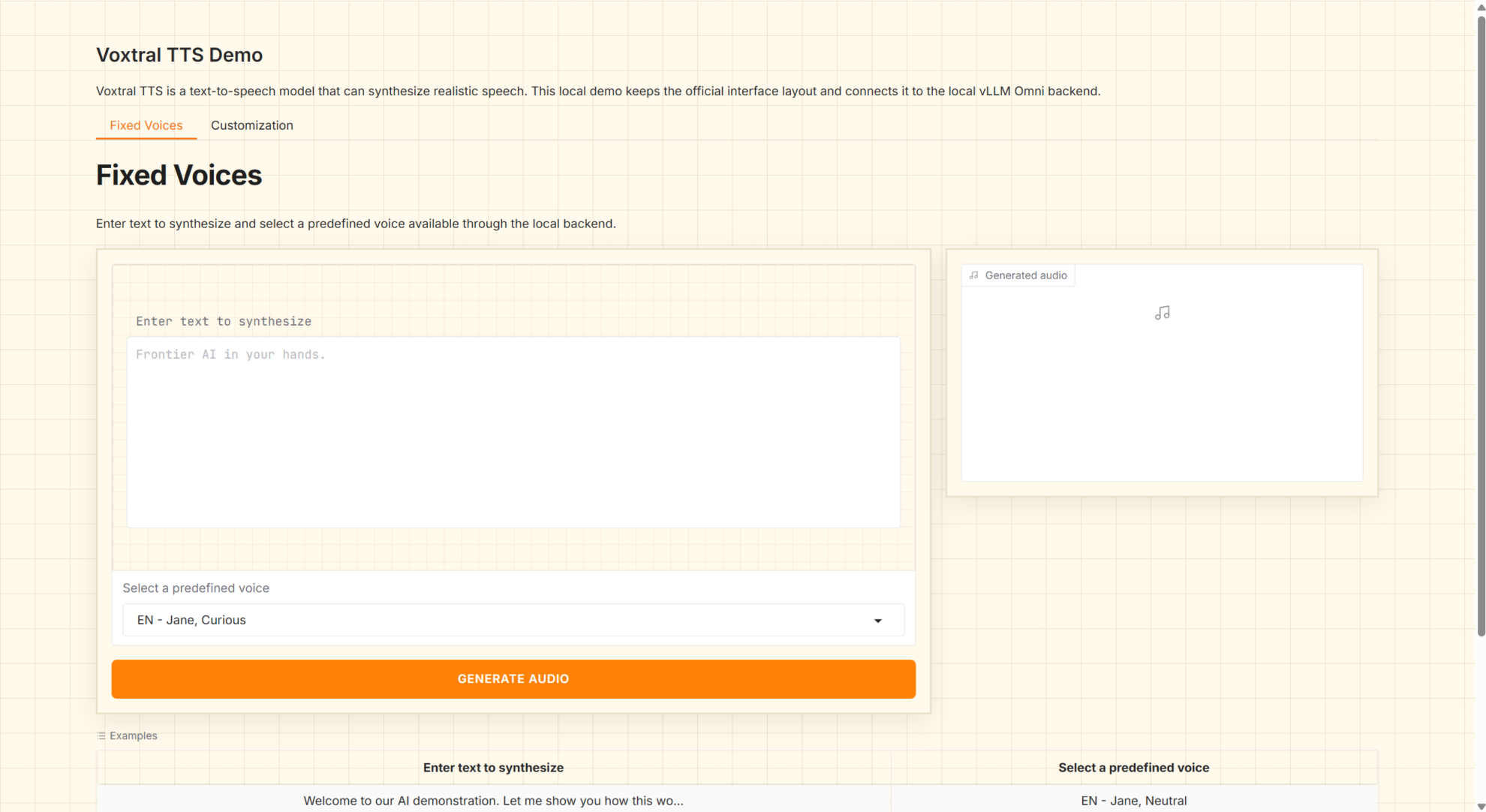
1. برنامج Voxtral 4B TTS 2603 لتوليد الكلام متعدد اللغات
Voxtral-4B-TTS-2603 هو نموذج لتحويل النص إلى كلام (TTS) من المستوى 4B، أطلقته شركة Mistral AI في مارس 2026. يوفر هذا النموذج أوزانًا مفتوحة وقدرات توليد كلام متعددة اللغات، ويدعم توليف النصوص الطبيعية مباشرةً إلى ملفات صوتية قابلة للتشغيل. صُمم هذا النموذج خصيصًا لسيناريوهات مثل وكلاء الصوت، والبث الصوتي، ودبلجة المحتوى، وخدمات تحويل النص إلى كلام المحلية، وهو مناسب للنشر والتشغيل المحلي باستخدام واجهات خدمة موحدة.
تشغيل عبر الإنترنت:https://go.hyper.ai/AoY2t
2. لينغبوت-وورلد: نموذج عالم مفتوح المصدر
LingBot-World هو برنامج محاكاة عوالم مفتوح المصدر يعتمد على توليد الفيديو. وباعتباره نموذجًا عالميًا من الطراز الأول، فإنه يتميز ببيئة عالية الدقة، وقدرات تخزين طويلة المدى، وتفاعل فوري. يستخدم LingBot-World بنية متطورة لتوليد الفيديو، قادرة على إنتاج فيديوهات عالية الجودة بتناسق مكاني وزماني بناءً على الصور المدخلة، والنصوص، وإشارات وضع الكاميرا.
تشغيل عبر الإنترنت:https://go.hyper.ai/fzF6R
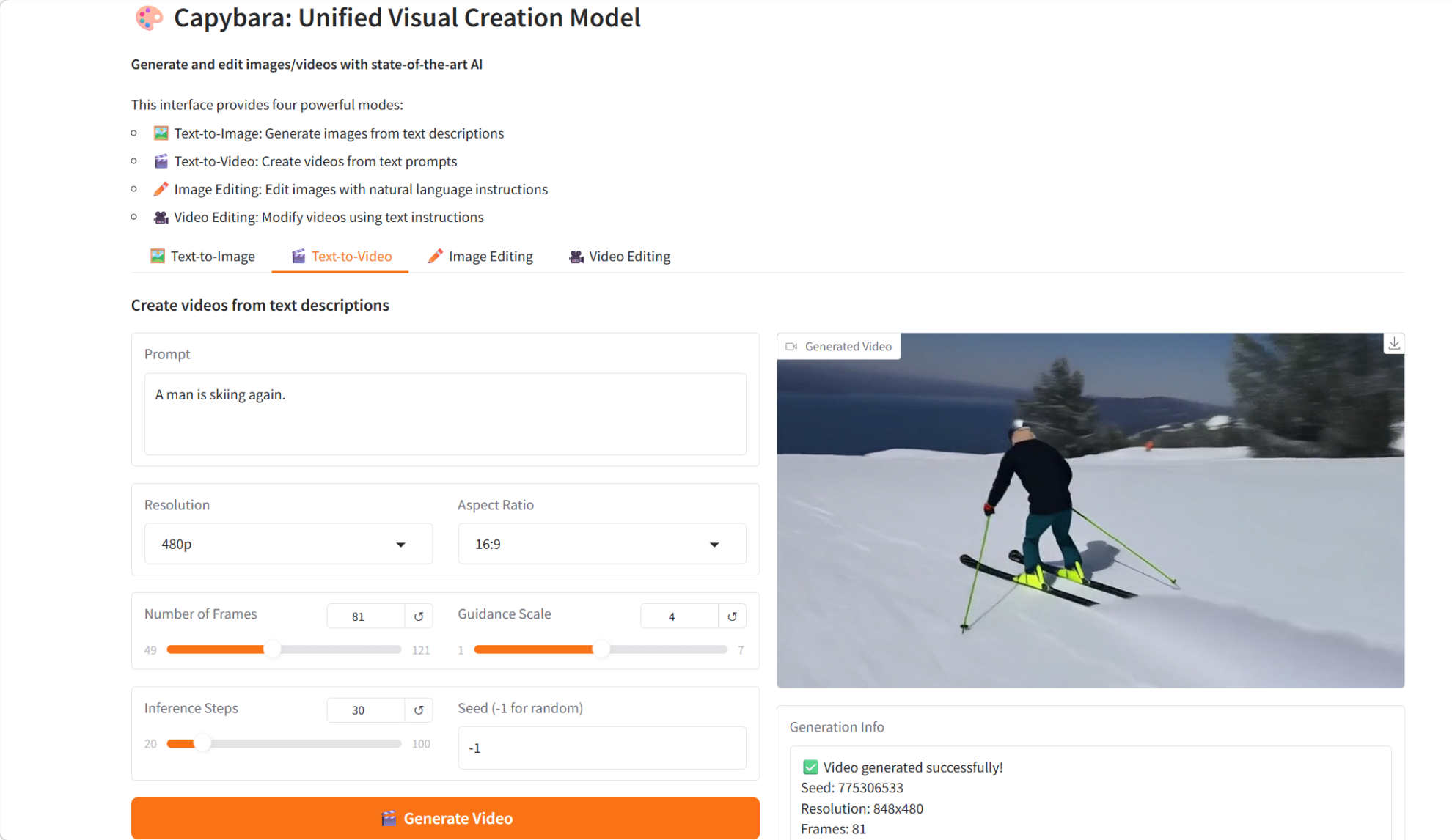
3. الكابيبارا: نموذج موحد للإبداع البصري
كابيبارا، الذي أطلقه فريق xgen-universe في فبراير 2026، هو نموذج موحد لإنشاء المحتوى المرئي، مصمم للتعامل مع مهام متنوعة في هذا المجال، بما في ذلك تحويل النصوص إلى صور، وتحويل النصوص إلى فيديوهات، وتحرير الصور والفيديوهات بناءً على التعليمات. يعتمد كابيبارا على نموذج انتشار متطور وبنية Transformer، ويهدف إلى توفير إطار عمل موحد وفعال لإنشاء المحتوى المرئي وتحريره.
تشغيل عبر الإنترنت:https://go.hyper.ai/yX0Pc
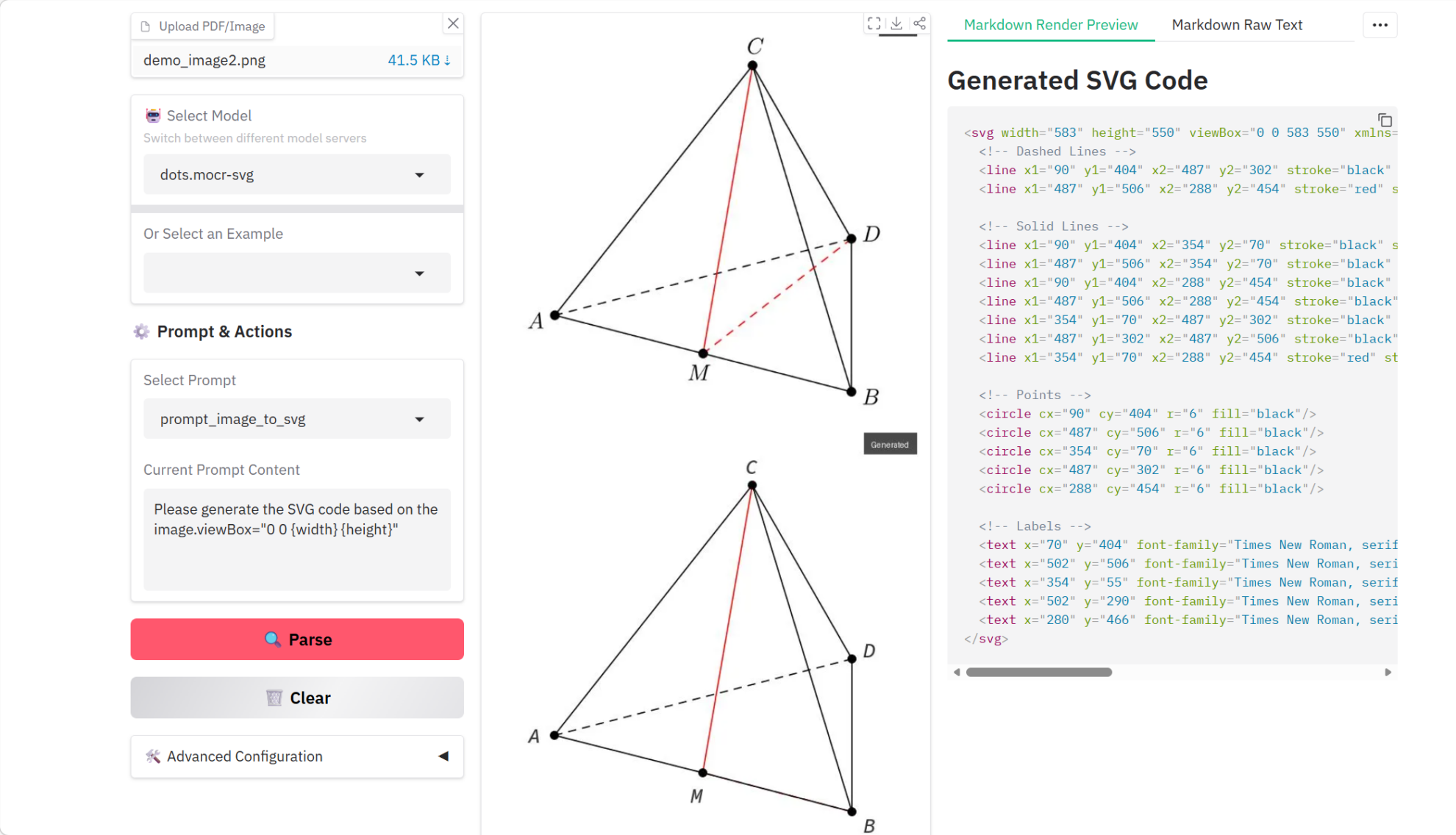
4. برنامج تعليمي لتحليل المستندات متعددة الوسائط dots.mocr
يُعدّ dots.mocr نموذجًا متعدد الوسائط لتحليل المستندات باستخدام تقنية التعرف الضوئي على الحروف (OCR)، وقد أُطلق بالتعاون بين جامعة هوا تشونغ للعلوم والتكنولوجيا ومختبر Xiaohongshu HI-Lab في مارس 2026. ويُحقق هذا النموذج أداءً متميزًا مقارنةً بالنماذج المماثلة في الحجم، حيث يُصنّف ضمن أحدث النماذج في مهام تحليل المستندات متعددة اللغات القياسية. إضافةً إلى تحليل المستندات، يتميز dots.mocr أيضًا بقدرته الفائقة على تحويل الرسومات الهيكلية (مثل المخططات، وتصميمات واجهة المستخدم، والرسوم البيانية العلمية، وغيرها) مباشرةً إلى كود SVG.
تشغيل عبر الإنترنت:https://go.hyper.ai/g2oB3
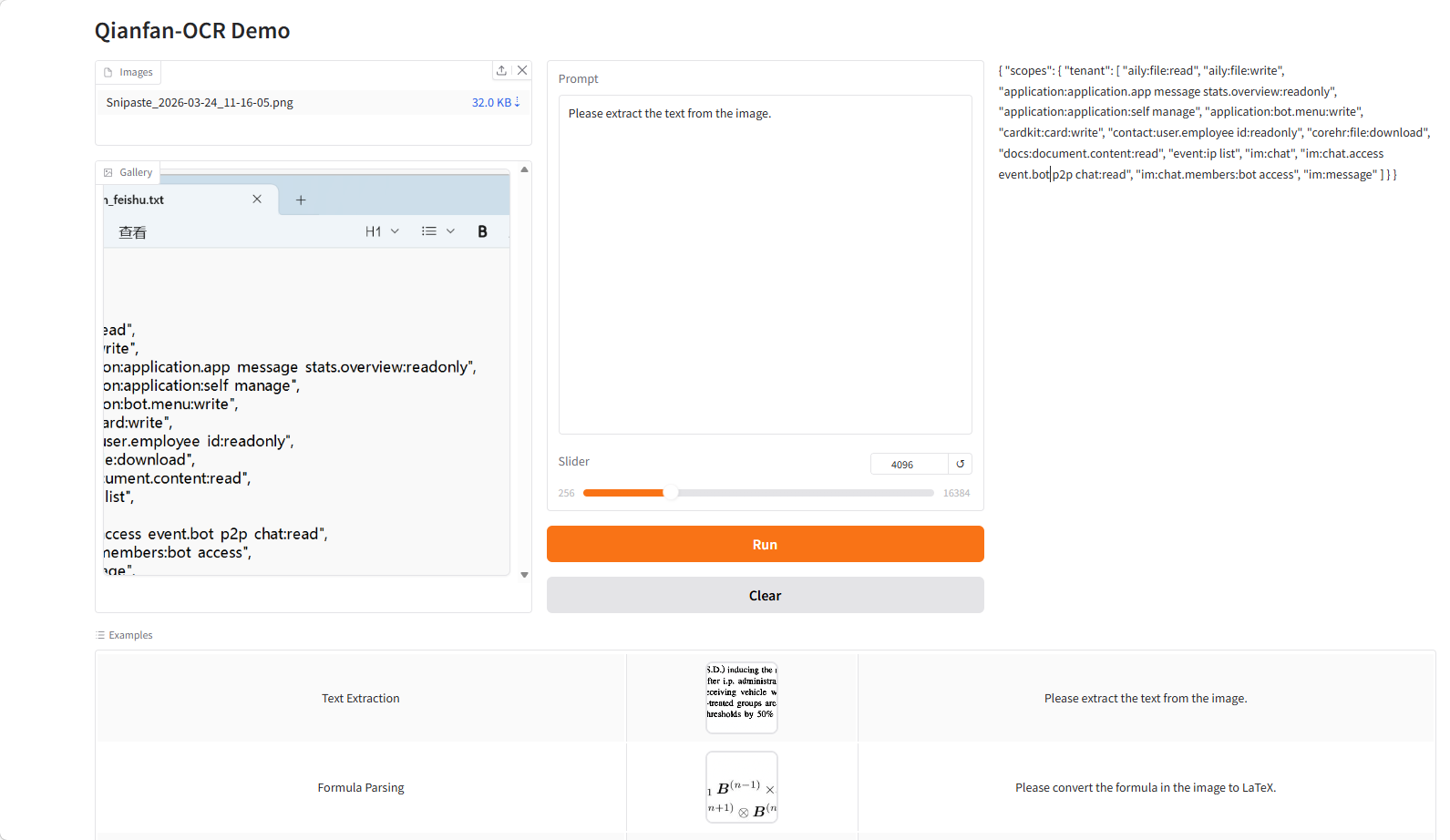
5. Qianfan-OCR: نموذج المستندات الذكي الشامل
Qianfan-OCR هو نموذج ذكاء شامل للمستندات، أطلقته شركة Baidu AI Cloud Qianfan كمصدر مفتوح في مارس 2026. يعتمد النموذج على بنية لغة مرئية ذات 4 مليارات مُعامل، ويدمج تحليل المستندات، وتحليل التخطيط، والتعرف على النصوص، والفهم الدلالي. تكمن فكرته الأساسية في آلية "التخطيط كفكرة": قبل توليد النتائج، يدخل النموذج في "مرحلة تفكير"، حيث يُصمم بنية المستند بشكل صريح (مثل مواقع العناصر وأنواعها وترتيب قراءتها) قبل إتمام عملية التحليل الشاملة. يتيح ذلك إطار عمل موحدًا يوازن بين الوعي بالبنية والفهم الدلالي، مما يُحسّن الدقة والاستقرار في سيناريوهات المستندات المعقدة.
تشغيل عبر الإنترنت:https://go.hyper.ai/WZIRF
6. نشر sarvam-30b باستخدام vLLM + Open WebUI
Sarvam-30B هو نموذج لغوي مفتوح المصدر ذو حجم كبير، أطلقته شركة Sarvam AI في مارس 2026. وباعتباره الإصدار 30B من أحدث سلسلة نماذج مفتوحة المصدر لشركة Sarvam، فإنه يعتمد على بنية مزيج الخبراء (MoE)، ويبلغ حجم معلماته الإجمالي 30 مليار، مع تفعيل ما يقارب 2.4 مليار معلمة لكل رمز. وقد تم تحسينه بشكل منهجي ليتناسب مع الحوار متعدد اللغات، والاستدلال، والترميز، وسيناريوهات النشر العملية.
تشغيل عبر الإنترنت:https://go.hyper.ai/UUJWe
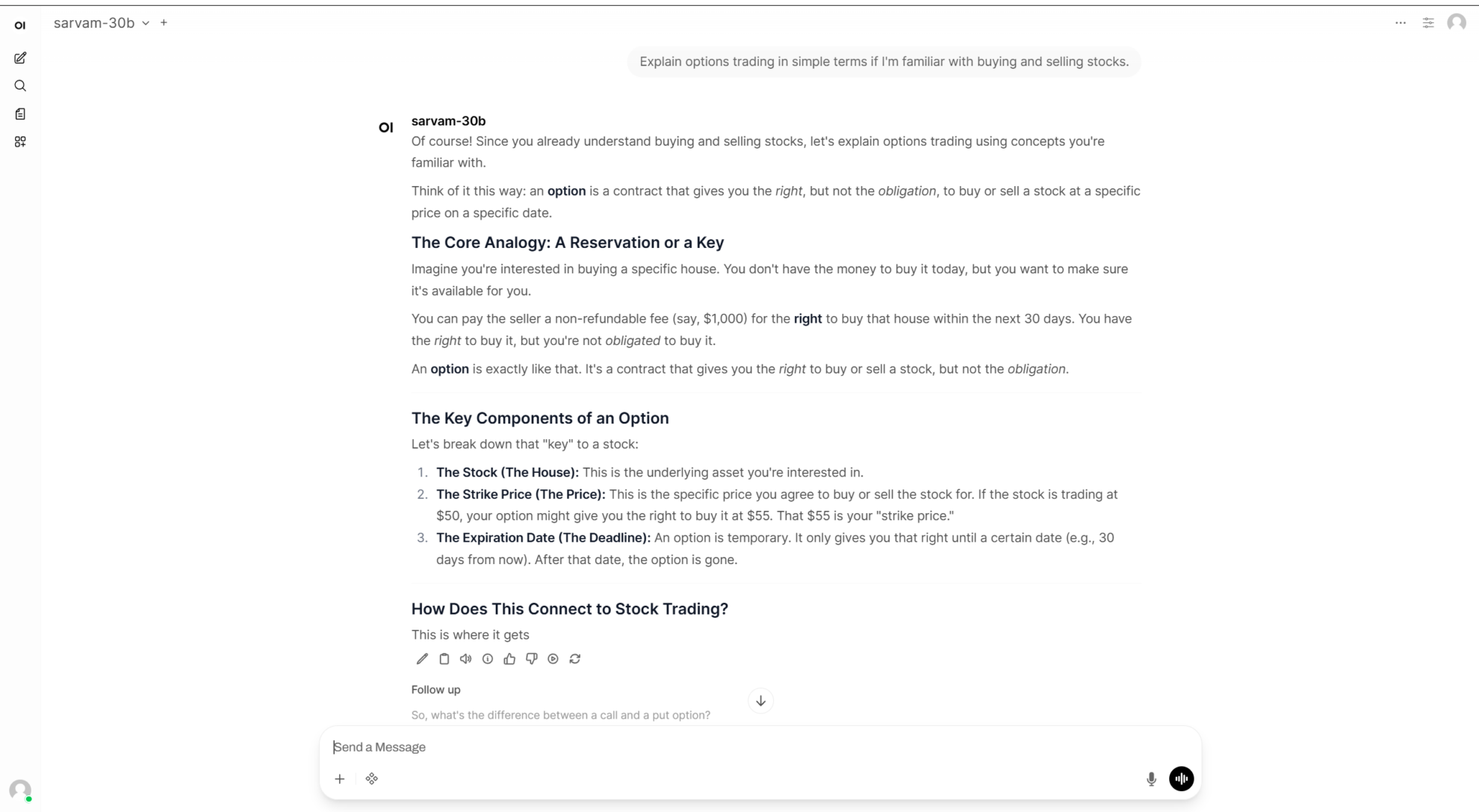
7. عرض توضيحي لنموذج الاستدلال البصري متعدد الوسائط Phi-4-reasoning-vision-15B
Phi-4-reasoning-vision-15B هو نموذج لغة بصرية للاستدلال متعدد الوسائط يحتوي على 15 مليار معلمة، وقد أصدرته مايكروسوفت في مارس 2026. يعتمد هذا النموذج على بنية Phi-4، ويجمع بين قدرات قوية في الاستدلال النصي والفهم البصري، مما يُمكّنه من التعامل مع مهام الاستدلال المعقدة بين النص والصورة.
تشغيل عبر الإنترنت:https://go.hyper.ai/JQlDE
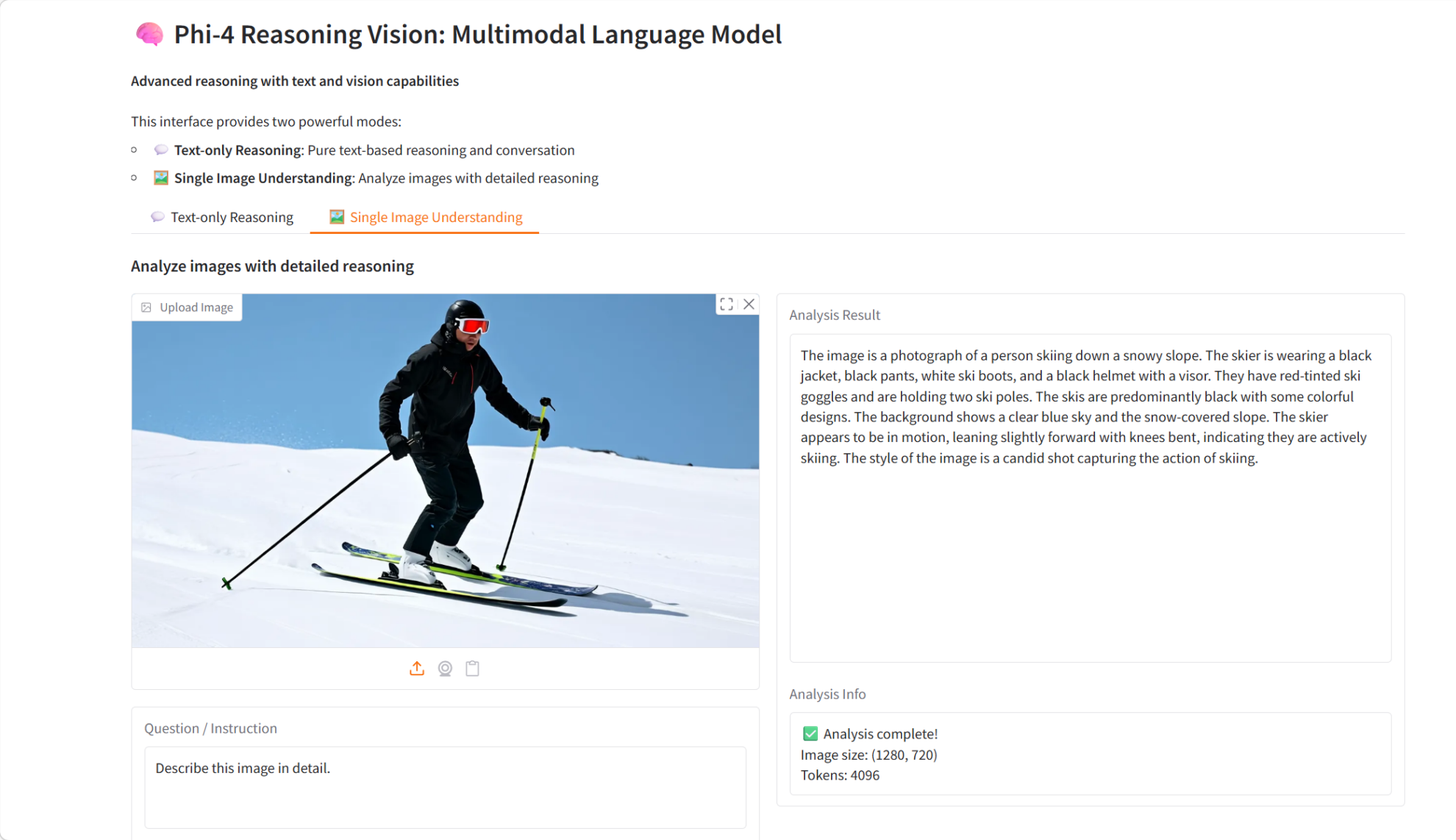
8. Slime: إطار عمل أصلي للغة SGLang مصمم لتوسيع نطاق التعلم المعزز
Slime هو إطار عمل لتدريب نماذج التعلم المعزز بعد التدريب، تم إصداره من قبل مختبر هندسة المعرفة (THUDM) في جامعة تسينغهوا، وهو مصمم خصيصًا لتوسيع نطاق التعلم المعزز. يحقق هذا الإطار مزيجًا مثاليًا من التدريب عالي الأداء وتوليد البيانات المرن من خلال ربط Megatron وSGLang.
تشغيل عبر الإنترنت:https://go.hyper.ai/Xrxev
9. نشر NVIDIA-Nemotron-3-Super-120B-A12B-NVFP4 بنقرة واحدة
أصدرت شركة NVIDIA نموذج NVIDIA Nemotron 3 Super NVFP4 في مارس 2026. وهو نموذج لغوي ضخم يضم 120 مُعاملًا إجماليًا و12 مُعامل تفعيل، ويستخدم بنية LatentMoE الهجينة، ويدعم سياقات تصل إلى مليون رمز. صُمم هذا النموذج خصيصًا لسيناريوهات تتضمن الاستدلال طويل السياق، وسير عمل الوكلاء، واستدعاء الأدوات، ورموز RAG، والإجابة على الأسئلة بكفاءة عالية. أما فيما يتعلق بالتفاعل، فيدعم النموذج تفعيل وتعطيل وضع الاستدلال، ويتيح التبديل بين وضع الإجابة على الأسئلة العادي ووضع الاستدلال المُحسّن عبر مُعاملات قالب الدردشة القياسية.
تشغيل عبر الإنترنت:https://go.hyper.ai/WJmbe
10. تثبيت Qwen 3.5-27B-Claude-4.6-Opus-Reasoning-Distilled بنقرة واحدة
يُعدّ Qwen3.5-27B-Claude-4.6-Opus-Reasoning-Distilled نموذج حوار عالي الأداء طوّرته شركة Jackrong في مارس 2026. وهو مبنيّ على نموذج منصة Qwen3.5-27B، ويُدمج قدرات Claude-4.6 وOpus في مجال الاستدلال لاستخلاص المعرفة. يُحسّن هذا النموذج بشكلٍ ملحوظ قدرات الاستدلال المعقدة وتجربة الحوار التفاعلي، مع الحفاظ على قدرات فهم اللغة الأصلية.
تشغيل عبر الإنترنت:https://go.hyper.ai/SNlOk
تفسير مقالة المجتمع
1. استنادًا إلى بيانات طيفية محاكاة لـ 2000 مادة من أشباه الموصلات، اقترح فريق من معهد ماساتشوستس للتكنولوجيا DefectNet، والذي يمكنه تحليل ستة عيوب استبدال متعايشة.
اقترح فريق بحثي من معهد ماساتشوستس للتكنولوجيا نموذجًا أساسيًا للتعلم الآلي، يُدعى DefectNet، قادرًا على التنبؤ مباشرةً بالأنواع الكيميائية وتركيزات عيوب النقاط الناتجة عن الاستبدال من الأطياف الاهتزازية، حتى في حالة وجود عناصر متعددة متعايشة. يُظهر النموذج قدرة تعميم جيدة في بلورات غير مرئية تحتوي على 56 عنصرًا، ويمكن ضبطه بدقة باستخدام البيانات التجريبية.
شاهد التقرير الكامل:https://go.hyper.ai/4qtAH
2. الذكاء الاصطناعي يكتشف 118 كوكبًا خارجيًا جديدًا! اقترح فريق من جامعة وارويك برنامج RAVEN، مما يتيح مقارنة سيناريوهات الكواكب بشكل فردي مع كل سيناريو إيجابي خاطئ.
اقترح فريق بحثي من جامعة وارويك نظام RAVEN، وهو عملية فرز وتقييم مبتكرة لمرشحي مهمة TESS. يُدخل هذا النظام مجموعة بيانات تدريبية اصطناعية، متجاوزًا الاعتماد فقط على بيانات تجاوز الحدود (TCE) الناتجة عن المهمة نفسها. يُوسّع هذا التحسين بشكل ملحوظ نطاق معلمات سيناريوهات الكواكب والنتائج الإيجابية الخاطئة التي يغطيها نموذج التعلم الآلي، ويُحسّنه. على مجموعة اختبار خارجية مستقلة تضم 1361 مرشحًا مُصنّفًا مسبقًا لمهمة TESS، حقق النظام دقة إجمالية بلغت 91%، مما يُثبت فعاليته في الترتيب التلقائي لمرشحي TESS.
شاهد التقرير الكامل:https://go.hyper.ai/phEO5
3. اقترح معهد ماساتشوستس للتكنولوجيا VibeGen، وهو أول نموذج لتوليد البروتين الديناميكي من البداية إلى النهاية، والذي يحقق رسم خرائط ثنائي الاتجاه بين التسلسل والاهتزاز.
اقترح فريق بحثي من معهد ماساتشوستس للتكنولوجيا وجامعة كارنيجي ميلون نموذج VibeGen، وهو نموذج ذكي لتوليد البروتينات، يُمكّن من تصميم البروتينات من الصفر من خلال الجمع بين توليد التسلسل والتنبؤ بالديناميكيات الاهتزازية. تُظهر النتائج أن البروتينات المصممة بواسطة هذا النموذج لا تقتصر على تكوين هياكل مستقرة وجديدة فحسب، بل تُعيد إنتاج خصائص توزيع سعات الاهتزاز المستهدفة على مستوى السلسلة الرئيسية.
شاهد التقرير الكامل:https://go.hyper.ai/jDaSW
مقالات موسوعية شعبية
1. الفرز العكسي مع RRF
2. الشبكات العصبية الاصطناعية (NNs)
3. نموذج اللغة المرئي (VLM)
4. ترميز الموضع الدوراني (RoPE)
5. الذاكرة طويلة المدى ثنائية الاتجاه (Bi-LSTM)
فيما يلي مئات المصطلحات المتعلقة بالذكاء الاصطناعي التي تم تجميعها لمساعدتك على فهم "الذكاء الاصطناعي" هنا:
إن ما ورد أعلاه هو كل محتوى اختيار المحرر لهذا الأسبوع. إذا كان لديك موارد تريد تضمينها على الموقع الرسمي لـ hyper.ai، فنحن نرحب بك أيضًا لترك رسالة أو إرسال مقال لإخبارنا بذلك!
نراكم في الاسبوع القادم!








