Command Palette
Search for a command to run...
يدعم إطار عمل توليد الفيديو متعدد الأنماط مفتوح المصدر من Meituan، LongCat 1.5، توليد الفيديو الحي والرسوم المتحركة والفيديو القائم على الحيوانات؛ كما أنه يعزز قدرات إعادة بناء المخططات واستخراج الجداول لمجموعة بيانات VLM ChartNet، التي تدعم ملايين نقاط البيانات.

LongCat-Video-Avatar 1.5، الذي أطلقه فريق Meituan LongCat في مايو 2026، هو إطار عمل جديد تمامًا مفتوح المصدر لتوليد الفيديو المدفوع بالصوت (AI2V).كل ما يحتاجه المستخدمون هو تقديم صورة مرجعية ثابتة ومقطع صوتي لإنشاء فيديو أفاتار ديناميكي مع مزامنة دقيقة لحركة الشفاه.يستخدم هذا النموذج تقنية استخلاص ميزات الكلام المعتمدة على الهمس؛ حيث تعمل تقنية التقطير التدريجي على ضغط عملية توليد الصور الرقمية إلى 8 خطوات فقط، مما يضمن ليس فقط صورًا عالية الدقة، بل أيضًا إنتاج محتوى فيديو طويل. وتشمل قدرته الشاملة على التعميم صورًا شخصية واقعية، وشخصيات أنمي ثنائية وثلاثية الأبعاد، وصورًا رمزية لحيوانات، مما يوفر حلاً فعالاً وموثوقًا لإنتاج فيديوهات متعددة المشاهد.
يعرض موقع HyperAI الآن "نموذج الإنسان الرقمي LongCat-Video-Avatar 1.5"، لذا تفضلوا بتجربته!
الاستخدام عبر الإنترنت:https://go.hyper.ai/NROTv
نرحب بكم لزيارة موقعنا الإلكتروني الرسمي لمزيد من المعلومات:
نظرة سريعة على تحديثات الموقع الرسمي لشركة hyper.ai من 6 يونيو إلى 12 يونيو:
* مجموعات البيانات العامة عالية الجودة: 6
* مجموعة مختارة من الدروس التعليمية عالية الجودة: 3
* تفسير مقالة المجتمع: 3 مقالات
* إدخالات الموسوعة الشعبية: 5
قم بزيارة الموقع الرسمي:هايبر.اي
مجموعات البيانات العامة المختارة
1. مجموعة بيانات ChartNet متعددة الوسائط لفهم الرسوم البيانية
ChartNet هي مجموعة بيانات متعددة الوسائط واسعة النطاق وعالية الجودة، أُصدرت عام 2026 من قِبل معهد ماساتشوستس للتكنولوجيا بالتعاون مع قسم الأبحاث في شركة IBM ومؤسسات أخرى. تهدف هذه المجموعة إلى معالجة أوجه القصور في النماذج الحالية في الاستدلال المشترك باستخدام الأنماط البصرية الهندسية والبيانات الرقمية المنظمة والأوصاف النصية. تحتوي مجموعة البيانات على 4.2 مليون عينة من الرسوم البيانية الاصطناعية، و94,643 عينة من الرسوم البيانية التي تم التحقق من صحتها يدويًا، و30,000 رسم بياني من العالم الحقيقي، تغطي 24 نوعًا من الرسوم البيانية و6 مكتبات للرسم.
الاستخدام عبر الإنترنت:https://go.hyper.ai/0CNr7
2. مجموعة بيانات بروز الفيديو البانورامي OpenSAL360
تُعدّ OpenSAL360 حاليًا أكبر مجموعة بيانات شاملة لتحليل بروز مقاطع الفيديو، وهي مصممة لدعم الأبحاث في مجال الانتباه البصري، والتنبؤ بالبروز، وتحليل الفيديو متعدد الوسائط. تحتوي مجموعة البيانات على 500 مقطع فيديو بانورامي متنوع من يوتيوب، بمتوسط مدة 18.1 ثانية، وقد تمّت إضافة تعليقات توضيحية للبيانات من قِبل أكثر من 2000 مُشاهد.
الاستخدام عبر الإنترنت:https://go.hyper.ai/u7NqD
3. مجموعة بيانات مشاعر الأفلام
"مشاعر الأفلام" هي مجموعة بيانات لخصائص المشاعر في الأفلام، مصممة لتوصيف دقيق للمشاعر التي تثيرها الأفلام، متجاوزةً بذلك قيود التصنيفات التقليدية القائمة فقط على المشاعر الإيجابية/السلبية أو المشاعر الأساسية. تحتوي هذه المجموعة على 1500 فيلمًا مميزًا ومؤثرًا ثقافيًا، تغطي الفترة من 1920 إلى 2024، وتشمل 50 حالة عاطفية.
الاستخدام عبر الإنترنت:https://go.hyper.ai/b4m71
4. FigureBench: إنشاء مجموعات بيانات مرجعية للرسوم التوضيحية العلمية.
FigureBench هي مجموعة بيانات مرجعية لتوليد الرسوم التوضيحية العلمية، صدرت عام 2026 من مختبر ذكاء النصوص بجامعة ويستليك. تهدف هذه المجموعة إلى حل مشكلة توليد رسوم توضيحية علمية عالية الجودة تلقائيًا من نصوص علمية طويلة، مما يوفر منصة اختبار متنوعة ومليئة بالتحديات لأبحاث توليد الرسوم التوضيحية العلمية تلقائيًا.
الاستخدام عبر الإنترنت:https://go.hyper.ai/Agaku
5. تأثير الذكاء الاصطناعي على الطلاب: يؤثر التعلم المدعوم بالذكاء الاصطناعي على مجموعات البيانات.
تُعدّ مجموعة بيانات تأثير الذكاء الاصطناعي على الطلاب مجموعة بيانات واسعة النطاق لسلوكيات التعليم، تشمل أبعادًا متعددة، ومصممة لتحليل تأثير أدوات الذكاء الاصطناعي التوليدي في بيئات التعلّم في التعليم العالي بشكل منهجي. تحتوي هذه المجموعة على 50,000 عينة من الطلاب و16 حقلًا من السمات المنظمة، تغطي بيانات مثل الخلفية الأكاديمية للطلاب، وسلوك استخدام الذكاء الاصطناعي، وسلوك التعلّم، والخلفية المؤسسية، والحالة الصحية النفسية، وسيناريوهات التطبيق.
الاستخدام عبر الإنترنت:https://go.hyper.ai/zWoGM
6. مجموعة بيانات صور المستندات الطبية المشوشة
مجموعة بيانات "الوثائق الطبية المشوشة" هي مجموعة بيانات تضم صورًا لوثائق طبية مُحسّنة بالتشويش، مصممة خصيصًا لمهام التعرف الضوئي على الحروف (OCR) وفهم الوثائق الطبية. تهدف هذه المجموعة إلى محاكاة التشويش المعقد الذي يُصادف عند مسح الوثائق في سيناريوهات طبية واقعية، مما يُحسّن من متانة وقدرة نماذج التعرف الضوئي على الحروف وفهم الوثائق على التعميم في بيئات واقعية. تحتوي مجموعة البيانات على 1000 صورة اصطناعية عالية الدقة لوثائق طبية، تشمل 500 فاتورة مستشفى و500 ملخص خروج من المستشفى.
الاستخدام عبر الإنترنت:https://go.hyper.ai/kL7gc
دروس تعليمية عامة مختارة
1. نموذج الإنسان الرقمي LongCat-Video-Avatar 1.5
يُعدّ LongCat-Video-Avatar 1.5، الذي أصدره فريق Meituan في مايو 2026، إطار عمل مُطوّرًا حديثًا ومفتوح المصدر لإنشاء فيديوهات تعتمد على الصوت (AI2V). يُمكنه إنشاء فيديوهات أفاتار ديناميكية عالية الواقعية ومتزامنة تمامًا مع حركة الشفاه، وذلك باستخدام صورة مرجعية ثابتة ومقطع صوتي فقط، كما يُسهّل التعامل مع المشاهد الواقعية المعقدة، بالإضافة إلى المواضيع المُنمّقة مثل الرسوم المتحركة والحيوانات.
تشغيل عبر الإنترنت:https://go.hyper.ai/NROTv
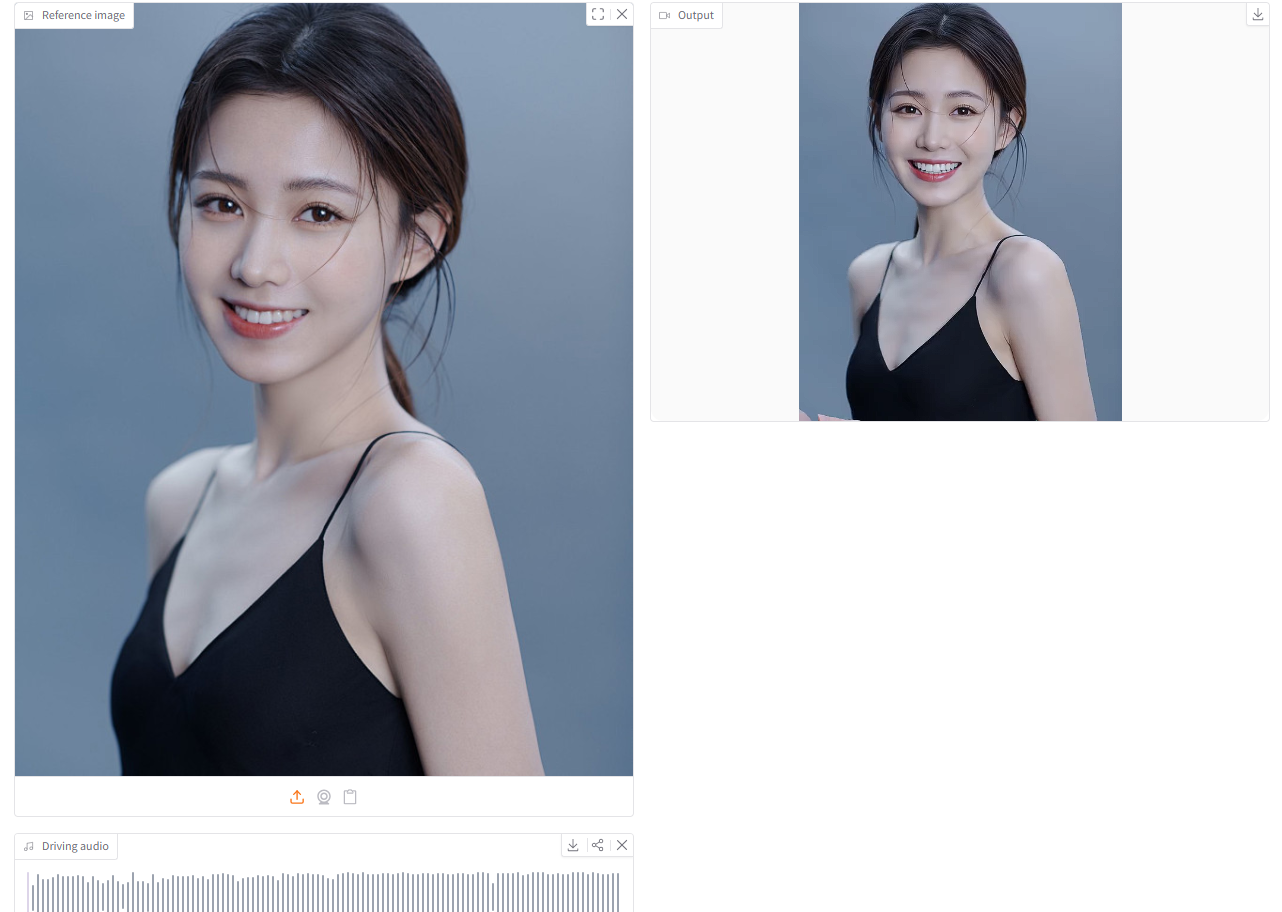
2. dots.tts: نظام تحويل النص إلى كلام ذاتي التراجع متصل بالكامل
أصدرت شركة rednote-hilab في يونيو 2026 نظام dots.tts، وهو نظام تحويل نص إلى كلام متكامل ومستمر بالكامل، يعتمد على تقنية الانحدار الذاتي، ويتكون من 2B مُعامل. يتألف هيكله الأساسي من مُشفّر دلالي، ونموذج خطي موجي (LLM)، ورأس صوتي مُطابق للتدفق بتقنية الانحدار الذاتي. يقوم النظام بنمذجة تمثيلات الصوت المستمرة مباشرةً باستخدام AudioVAE بتردد 48 كيلوهرتز، دون الحاجة إلى استخدام رموز كلامية منفصلة.
تشغيل عبر الإنترنت:https://go.hyper.ai/YT3g3
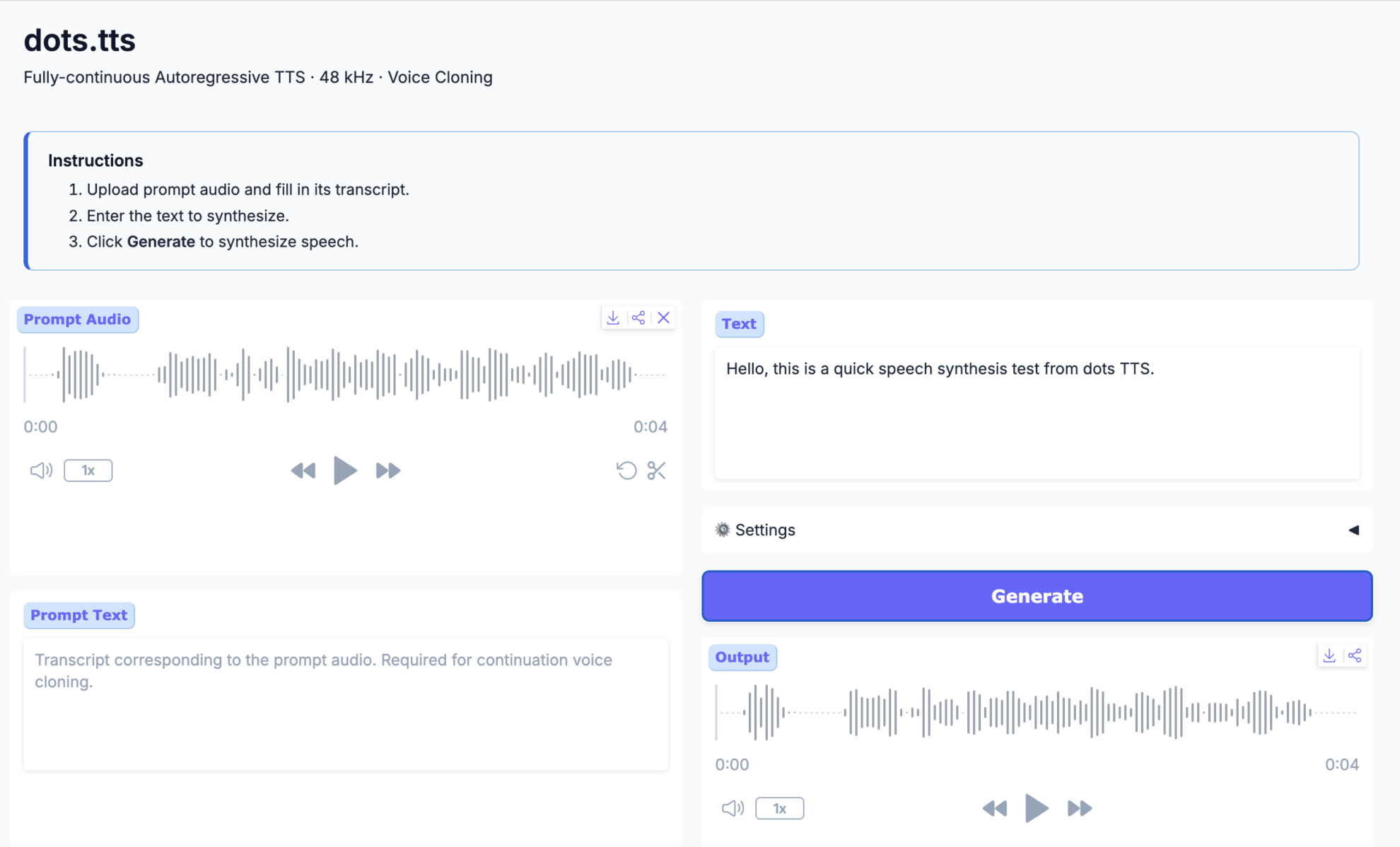
3. Gemma4 12B-it: نموذج متعدد الوسائط موحد للرسوم البيانية والنصوص والصوت.
يُعدّ Gemma 4 12B-it نموذجًا موحدًا متعدد الوسائط ضمن سلسلة Gemma 4 التي أصدرتها Google DeepMind. يعتمد هذا النموذج على بنية لا تعتمد على مُشفّر، حيث يقوم بإسقاط الصور والصوت مباشرةً في فضاء تضمين LLM. يستطيع معالجة النصوص والصور والصوت دون الحاجة إلى مُشفّر منفصل، ويحقق قدرات استدلال وتشفير وفهم متعدد الوسائط فائقة على مستوى 12B من المعاملات.
تشغيل عبر الإنترنت:https://go.hyper.ai/0713z
تفسير مقالة المجتمع
1. استنادًا إلى 220 نوعًا من البكتيريا البحرية، أعاد العلماء بناء نظام تصنيف الميكروبات غيرية التغذية باستخدام نموذج على نطاق الجينوم، وحددوا ثمانية أنواع من النباتات الأيضية.
استخدم فريق بقيادة جامعة جنوب كاليفورنيا قاعدة بيانات عالمية للميكروبات البحرية ونماذج أيضية على مستوى الجينوم لتحليل كميات هائلة من جينومات البكتيريا البحرية. ومن خلال تحديد حساسية الكائنات الدقيقة لاستخدام 11 نوعًا من الركائز العضوية، تمكنوا من تحديد 8 مجتمعات أيضية متباينة.
شاهد التقرير الكامل:https://go.hyper.ai/dfq8T
2. تصل دقة تقدير العمق إلى 0.9؛ يقترح Meta نموذج VLM³، مما يدل على أن النماذج المرئية قادرة بطبيعتها على تعلم ثلاثي الأبعاد، ويحقق نمذجة موحدة لمهام متعددة بناءً على Qwen3-VL-4B.
اقترحت شركة ميتا، بالتعاون مع جامعة برينستون، نموذج VLM³، الذي يعتمد على نموذج اللغة البصرية القياسي، ويحقق نمذجة موحدة لأربعة أنواع من المهام - فهم ثلاثي الأبعاد على مستوى الكائن، وتقدير العمق المتري، ومطابقة البكسل، وحل وضعية الكاميرا - من خلال طريقة موحدة لتنظيم البيانات ونموذج تدريب موحد. كما قيّم النموذج بشكل منهجي حدود قدرات نموذج اللغة البصرية القياسي في الإدراك ثلاثي الأبعاد الدقيق.
شاهد التقرير الكامل:https://go.hyper.ai/NihJA
3. اقترحت جامعة كامبريدج وآخرون نموذجًا أساسيًا على مستوى البكسل لمهام مراقبة الأرض، محققين دقة عالية في العديد من المهام.
طوّر فريق بحثي مشترك من جامعات كامبريدج وآلتو وبريستول نموذجًا جديدًا لتعلم الخصائص الزمنية، قائمًا على خوارزمية بارلو التوأمية. يُمكّن هذا النموذج النماذج من تعلّم التغيرات المكانية والزمانية المستقرة لسطح الأرض تلقائيًا، ما يُتيح تكوين تمثيلات لخصائص الاستشعار عن بُعد مع الحفاظ على ثباتها مع مرور الوقت. وانطلاقًا من هذا الأساس، اقترح الفريق أيضًا نموذج TESSERA، وهو نموذج أساسي للاستشعار عن بُعد على مستوى البكسل، مُصمّم خصيصًا لبيانات Sentinel-1/Sentinel-2 الزمنية متعددة الوسائط.
شاهد التقرير الكامل:https://go.hyper.ai/S3KBr
مقالات موسوعية شعبية
1. نموذج العمل العالمي (WAM)
2. الذكاء الاصطناعي القابل للتفسير (XAI)
3. نموذج اللغة المرئية والفعل (VLA)
4. نظام قائم على القواعد
5. دمج الرتب المتبادل
فيما يلي مئات المصطلحات المتعلقة بالذكاء الاصطناعي التي تم تجميعها لمساعدتك على فهم "الذكاء الاصطناعي" هنا:
إن ما ورد أعلاه هو كل محتوى اختيار المحرر لهذا الأسبوع. إذا كان لديك موارد تريد تضمينها على الموقع الرسمي لـ hyper.ai، فنحن نرحب بك أيضًا لترك رسالة أو إرسال مقال لإخبارنا بذلك!
نراكم في الاسبوع القادم!
حول HyperAI
HyperAI (hyper.ai) هي شركة رائدة في مجال الذكاء الاصطناعي والحوسبة عالية الأداء في الصين.نحن ملتزمون بأن نصبح البنية التحتية في مجال علوم البيانات في الصين وتوفير موارد عامة غنية وعالية الجودة للمطورين المحليين. حتى الآن، لدينا:
* يوفر نقاط تنزيل محلية معجلة لأكثر من 2100 مجموعة بيانات عامة
* يتضمن أكثر من 700 درس تعليمي كلاسيكي وشائع عبر الإنترنت
* تحليل أكثر من 300 دراسة حالة من أوراق بحثية حول الذكاء الاصطناعي للعلوم
* يدعم البحث عن أكثر من 700 مصطلح ذي صلة
* استضافة أول وثائق كاملة حول Apache TVM باللغة الصينية في الصين
قم بزيارة الموقع الرسمي لبدء رحلة التعلم الخاصة بك:








