Command Palette
Search for a command to run...
دورة تعليمية عبر الإنترنت | تحليل سياقي لعشرات الصفحات من المستندات دفعة واحدة: برنامج بايدو مفتوح المصدر للتعرف الضوئي على الأحرف غير المحدود، إعادة هيكلة السيناريوهات المعقدة مع المستندات الطويلة

على مدى السنوات القليلة الماضية، تطورت تقنية التعرف الضوئي على الحروف (OCR) تدريجيًا من مجرد "التعرف على النصوص في الصور" إلى مهمة فهم شاملة للمستندات. لا تحتاج المؤسسات والمطورون إلى استخراج النصوص فحسب، بل يرغبون أيضًا في نماذج قادرة على التعرف على تخطيطات الصفحات المعقدة، وتحليل الجداول والصيغ، وفهم التخطيطات متعددة الأعمدة، وفي النهاية إخراج نتائج منظمة مناسبة لتطبيقات RAGs وقواعد المعرفة وأتمتة المكاتب. ومع ذلك، عند معالجة المستندات الطويلة مثل التقارير الممسوحة ضوئيًا والأوراق وعروض PowerPoint والعقود وملفات PDF متعددة الصفحات...غالباً ما تتطلب عمليات التعرف الضوئي على الأحرف التقليدية استدلالاً صفحة بصفحة متبوعاً بالمعالجة اللاحقة والدمج، وهو أمر ليس غير فعال فحسب، بل إنه عرضة أيضاً للتسبب في تجزئة المعلومات السياقية.
تُحسّن نماذج التعرف الضوئي على الأحرف (OCR) الشاملة من الجيل التالي، مثل DeepSeek OCR، دقة التعرف وقدرات تحليل التخطيطات المعقدة بشكل ملحوظ من خلال دمج نموذج لغوي ضخم كوحدة فك تشفير والاستفادة الكاملة من المعلومات اللغوية المسبقة. ومع ذلك، يبرز تحدٍ جديد: فمع ازدياد حجم المحتوى الناتج، تتراكم ذاكرة التخزين المؤقت للقيم الرئيسية للنموذج، مما يؤدي إلى زيادة استهلاك الذاكرة وتباطؤ سرعة الإنتاج. بعبارة أخرى،كلما اقترب النموذج من نهاية المستند، زادت تكلفة الاستدلال.
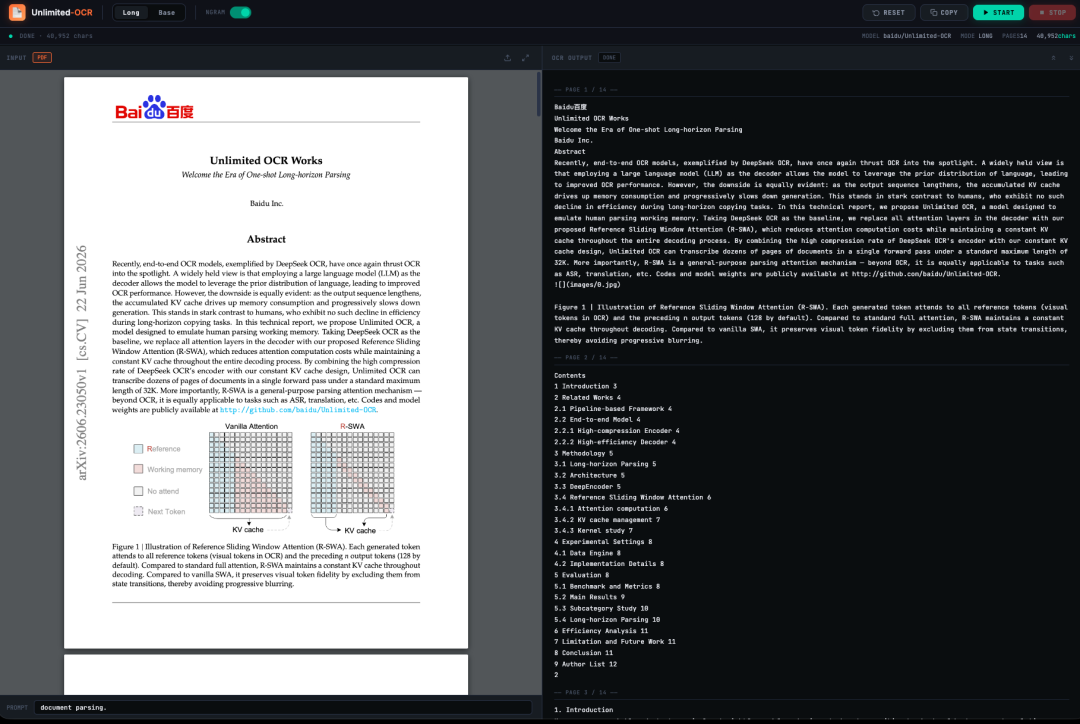
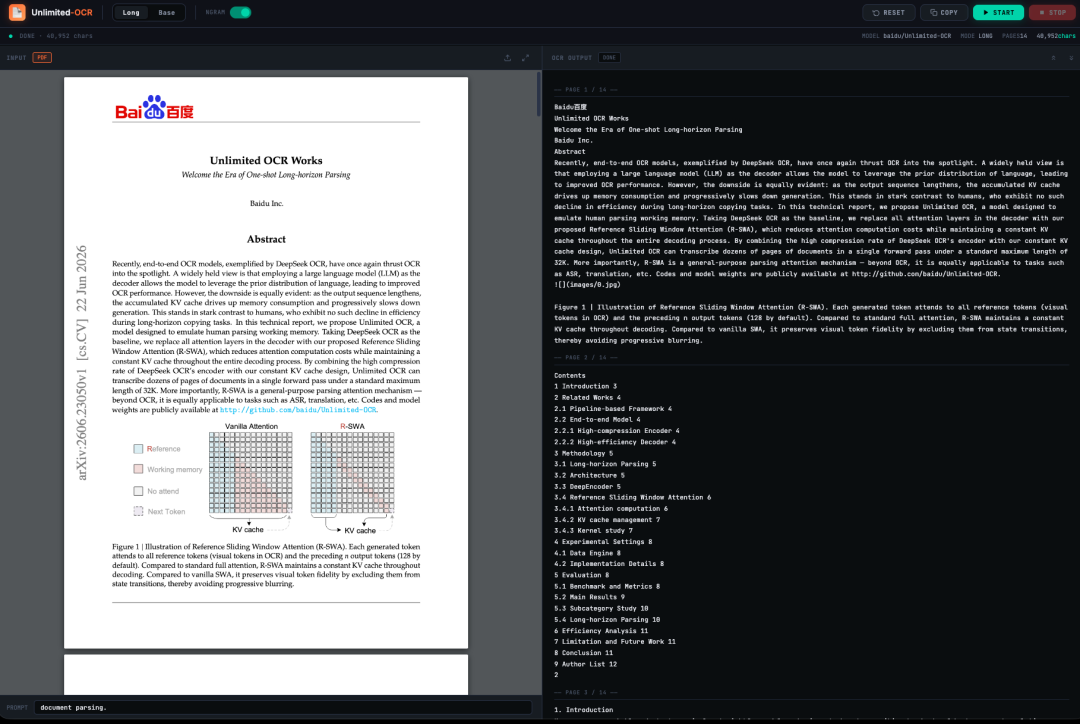
يُعالج نظام التعرف الضوئي على الأحرف غير المحدود (Unlimited OCR) الذي أطلقته بايدو مؤخرًا كمصدر مفتوح هذه المشكلة في الصناعة. يعتمد هذا النظام على تقنية DeepSeek OCR، ويُقدم آلية انتباه جديدة تعتمد على نافذة منزلقة مرجعية (R-SWA)، لتحل محل آلية الانتباه التقليدية في وحدة فك التشفير. يُقلل هذا من التكلفة الحسابية للانتباه مع الحفاظ على حجم ذاكرة التخزين المؤقت للقيم والمفاتيح ثابتًا طوال عملية فك التشفير. وبالإضافة إلى قدرات ضغط المعلومات العالية لوحدة تشفير DeepSeek OCR،يمكن لتقنية التعرف الضوئي على الأحرف غير المحدودة إكمال التعرف الضوئي على الأحرف وتحليل تخطيط عشرات الصفحات من المستندات في استدلال أمامي واحد، ضمن طول السياق الافتراضي البالغ 32 كيلوبايت.يُقدّم هذا نهجًا جديدًا وأكثر جدوى هندسيًا لمعالجة المستندات الطويلة. والأهم من ذلك، أن R-SWA لا يقتصر تطبيقه على التعرف الضوئي على الأحرف (OCR) فحسب، بل لديه أيضًا إمكانية التوسع ليشمل مهام تحليل التسلسلات الطويلة مثل التعرف التلقائي على الكلام (ASR) والترجمة الآلية.
أطلقت شركة HyperAI (hyper.ai) مؤخرًا البرنامج التعليمي "التعرف الضوئي على الأحرف غير المحدود: نشر بنقرة واحدة للتعرف الضوئي على الأحرف وتحليل تخطيط المستندات الطويلة"، مما يقلل من عتبة النشر ويساعد على التحقق من صحة النماذج بسرعة. ⬇️
تشغيل عبر الإنترنت:https://go.hyper.ai/YfaB5
عرض الأوراق ذات الصلة:https://go.hyper.ai/PZsJo
المزيد من الدروس التعليمية عبر الإنترنت:
تشغيل تجريبي
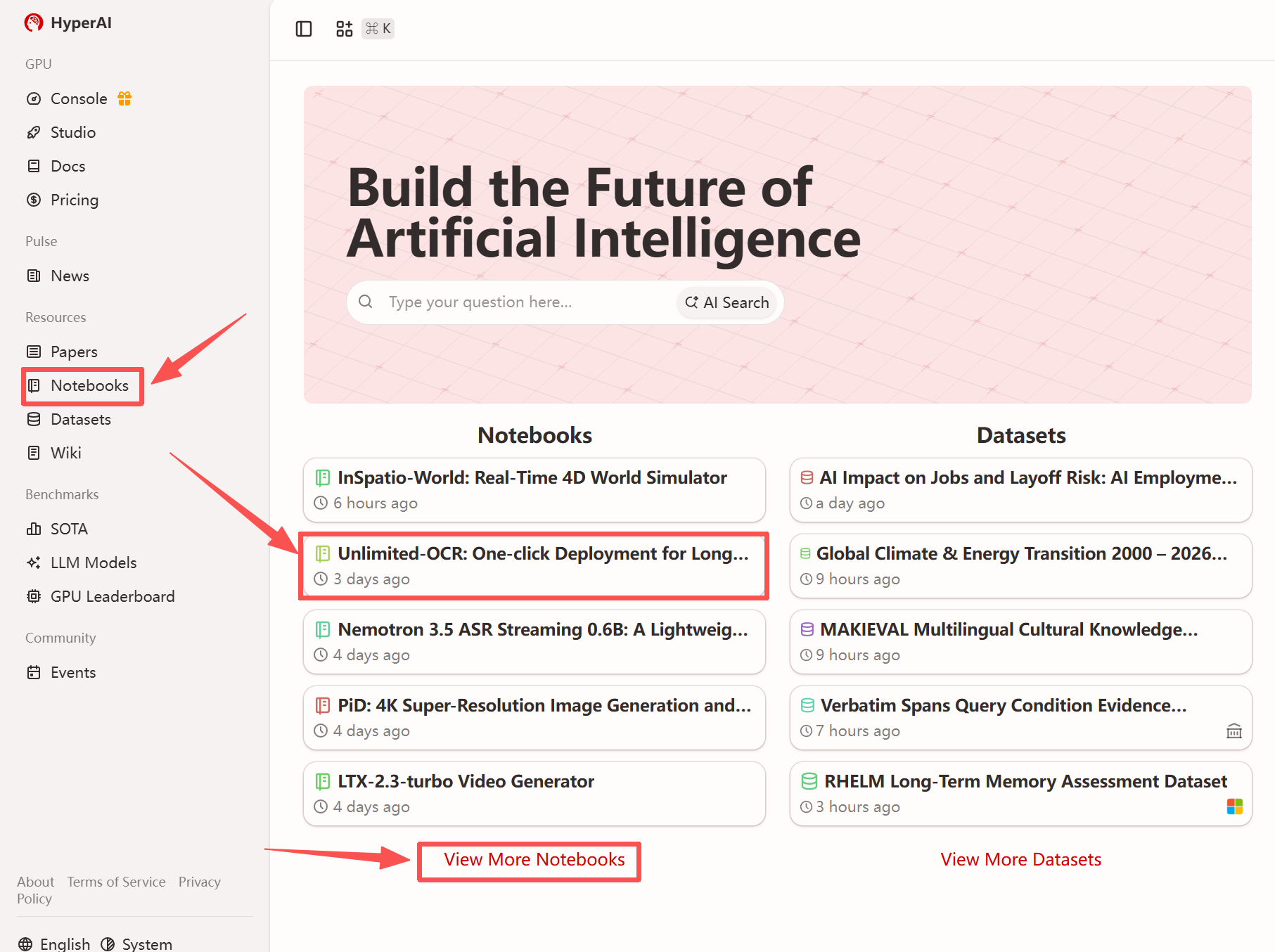
1. بعد الدخول إلى الصفحة الرئيسية لموقع hyper.ai، حدد صفحة "الدروس التعليمية"، أو انقر فوق "عرض المزيد من الدروس التعليمية"، وحدد "Unlimited-OCR: One-Click Deployment of Long Document OCR and Layout Parsing"، ثم انقر فوق "تشغيل هذا البرنامج التعليمي".
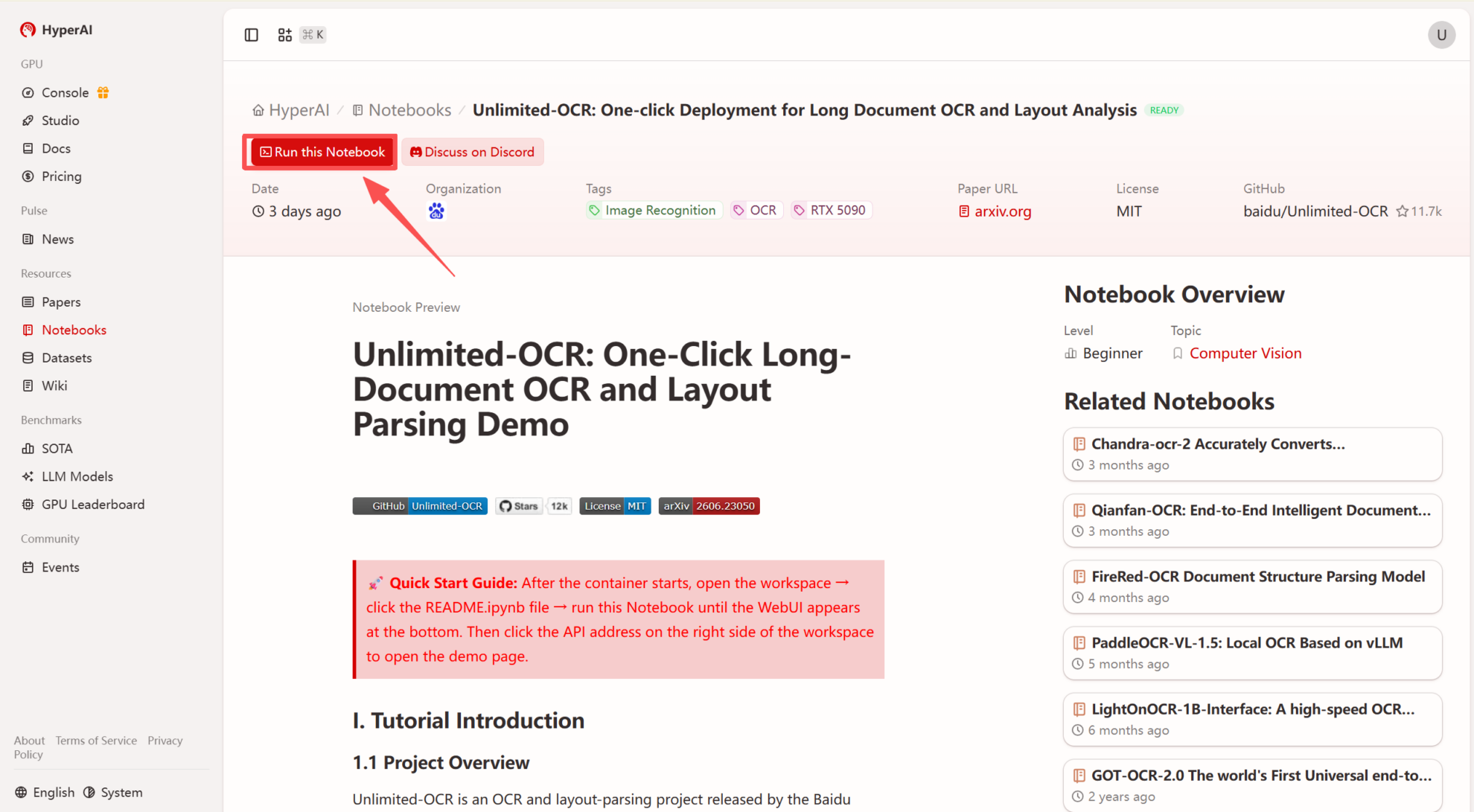
2. بعد إعادة توجيه الصفحة، انقر فوق "استنساخ" في الزاوية اليمنى العليا لاستنساخ البرنامج التعليمي في الحاوية الخاصة بك.
ملاحظة: يمكنك تبديل اللغات في الزاوية العلوية اليمنى من الصفحة. حاليًا، اللغتان الصينية والإنجليزية متاحتان. سيوضح هذا البرنامج التعليمي الخطوات باللغة الإنجليزية.
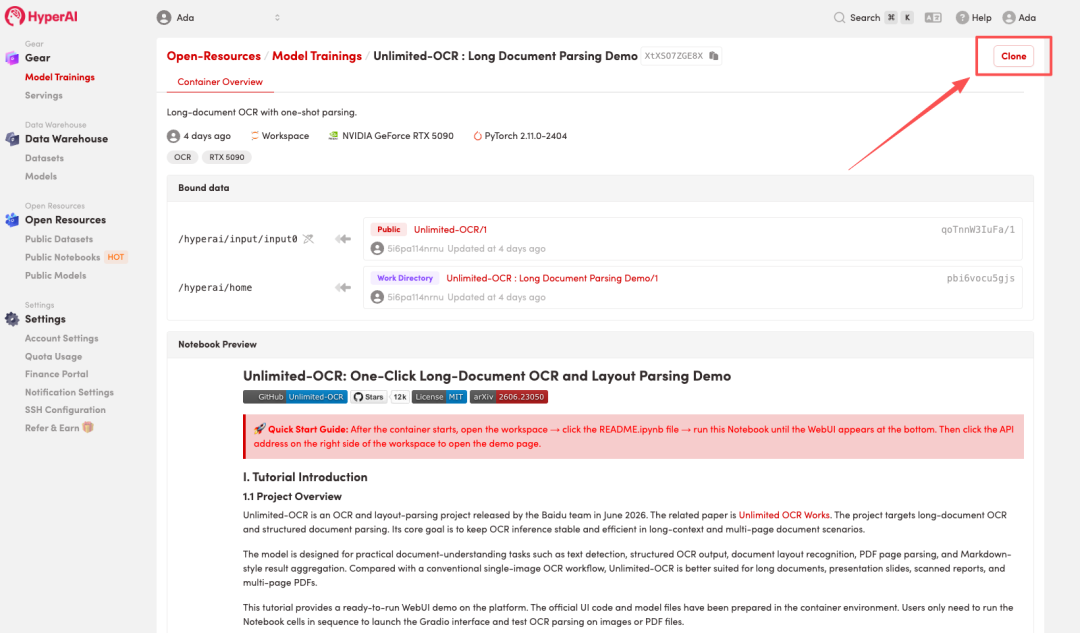
3. حدد صور "NVIDIA RTX 5090" و "PyTorch"، وانقر فوق "متابعة تنفيذ المهمة".
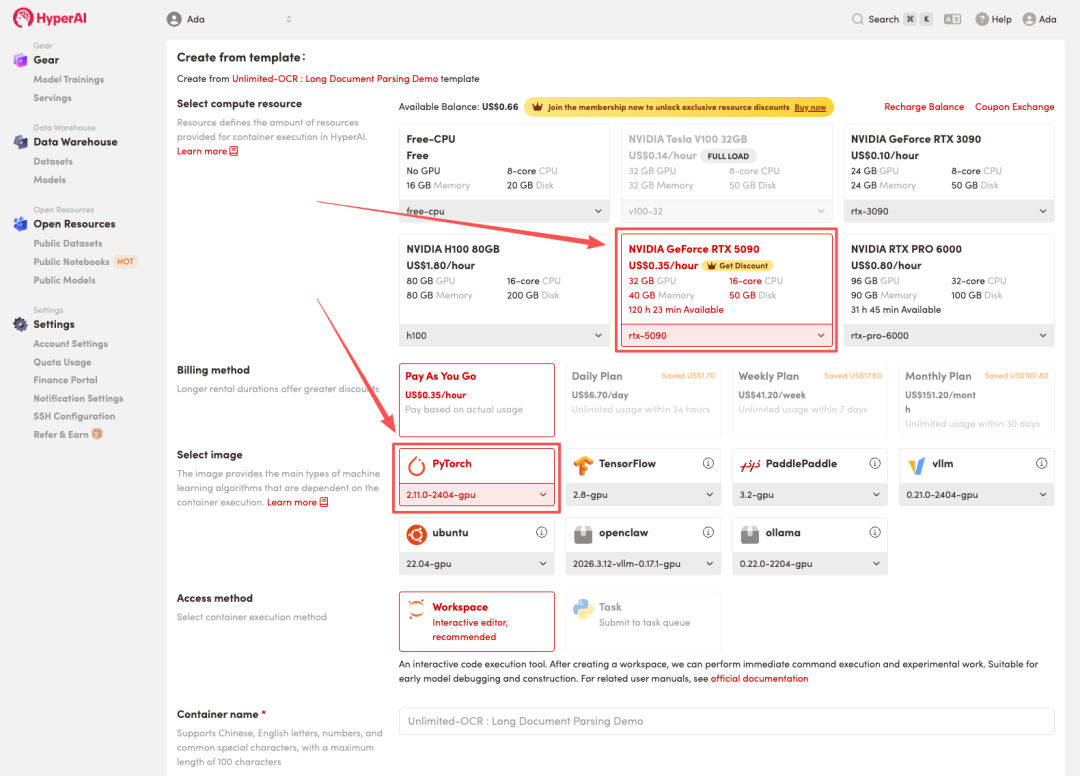
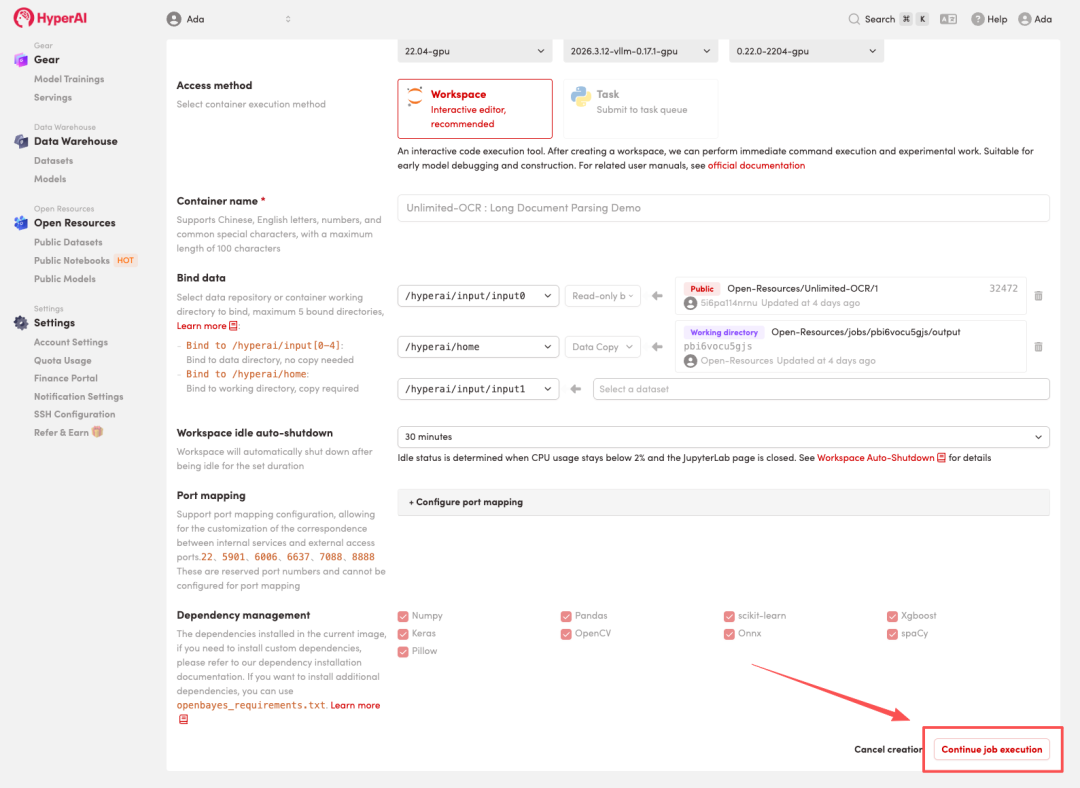
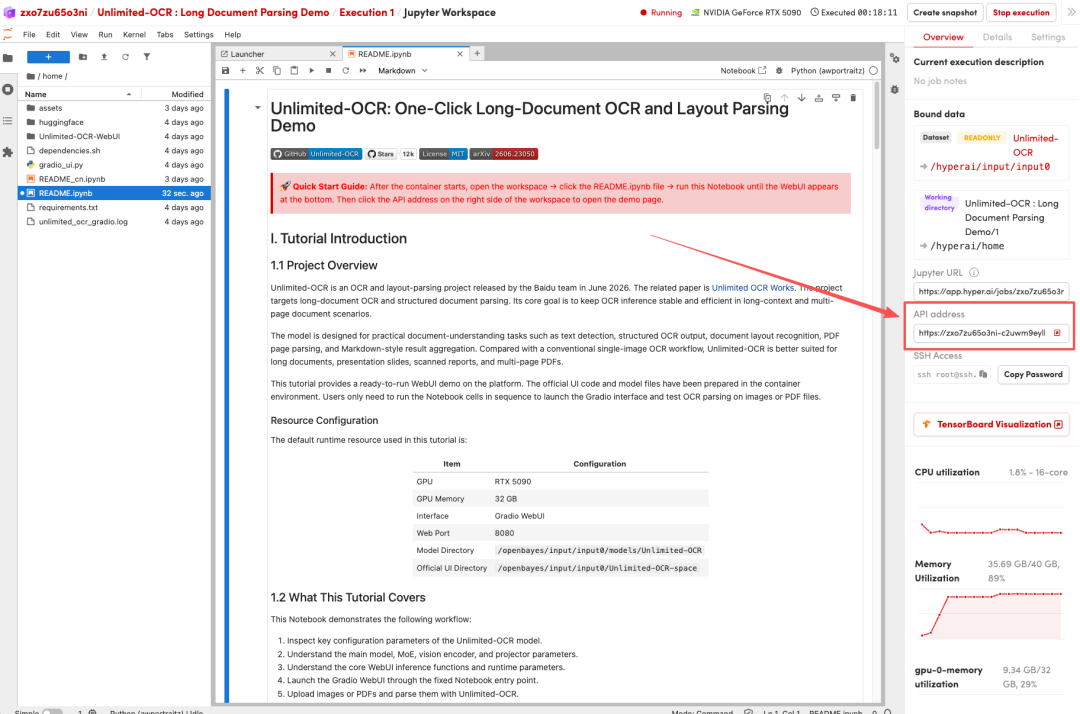
4. انتظر حتى يتم تخصيص الموارد. بمجرد أن تتغير الحالة إلى "قيد التشغيل"، انقر فوق "فتح مساحة العمل" للدخول إلى مساحة عمل Jupyter.
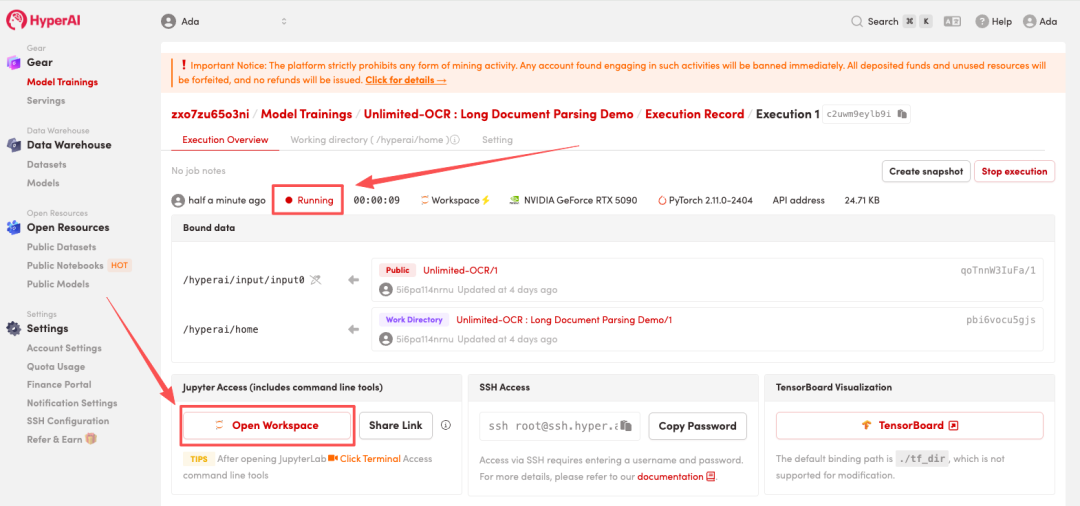
عرض التأثير
1. بعد إعادة توجيه الصفحة، انقر على ملف README الموجود على اليسار، ثم انقر على تشغيل في الأعلى.
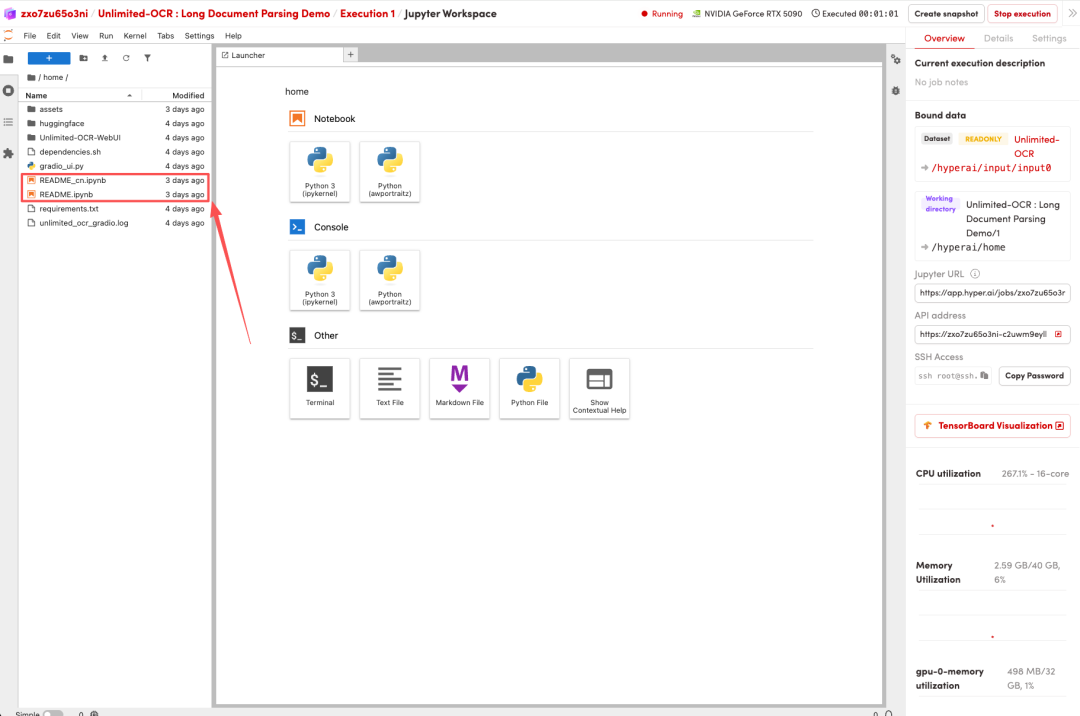
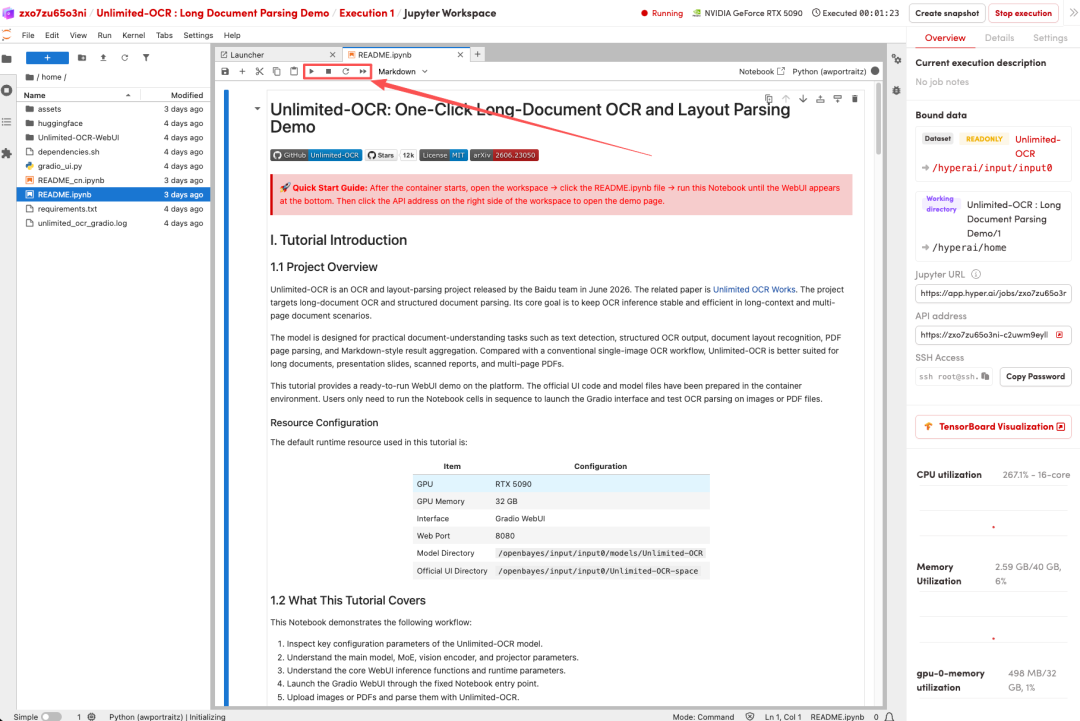
2. بعد اكتمال العملية، انقر فوق عنوان API الموجود على اليمين لفتح واجهة العرض التوضيحي.