Command Palette
Search for a command to run...
دورة تعليمية عبر الإنترنت | فريق جامعة هونغ كونغ للعلوم والتكنولوجيا يُطلق أول إطار عمل مفتوح المصدر لعمق الفيديو الحتمي، محققًا أحدث التقنيات بدون عينات.

يُعدّ تقدير العمق من أهمّ المهام الأساسية في مجال الرؤية ثلاثية الأبعاد. فمن القيادة الذاتية وتوجيه الروبوتات إلى الواقع المعزز/الواقع الافتراضي، والتوائم الرقمية، وتوليد محتوى الفيديو، تحتاج الأنظمة إلى فهم دقيق للعلاقات المكانية بين الأجسام والكاميرا في المشهد. مع ذلك، لطالما واجه تقدير عمق الفيديو معضلةً جوهرية: فالأساليب التوليدية، التي تمثلها نماذج الانتشار، تتمتع بقدرات فهم دلالي قوية، ويمكنها استنتاج هياكل المشاهد المعقدة باستخدام كميات هائلة من البيانات المدربة مسبقًا، لكن نتائج تنبؤاتها غالبًا ما تتأثر بعمليات أخذ العينات العشوائية، مما يجعلها عرضةً للأوهام الهندسية، وانحراف المقياس، وعدم الاستقرار الزمني؛ بينما تعتمد الأساليب التمييزية التقليدية، رغم تمتعها بحتمية أفضل، اعتمادًا كبيرًا على البيانات المصنفة واسعة النطاق، مما يؤدي إلى ارتفاع تكاليف التدريب ومحدودية القدرة على التعميم في المشاهد المعقدة.
لمعالجة هذه المشكلة التي تعاني منها الصناعة، اقترح فريق جامعة هونغ كونغ للعلوم والتكنولوجيا (غوانغتشو) تقنية DVD (تقدير عمق الفيديو الحتمي).لأول مرة، تم تحويل نموذج انتشار الفيديو المدرب مسبقًا بشكل حتمي إلى مقدر واحد لعمق الفيديو ذي الانتشار الأمامي.على عكس نماذج الانتشار التقليدية التي تتطلب تكرارات متعددة لتوليد النتائج، يمكن لتقنية DVD إتمام عملية التنبؤ بالعمق بحساب أمامي واحد. هذا لا يُحسّن كفاءة الاستدلال بشكل كبير فحسب، بل يُزيل تمامًا مشكلة الوهم الهندسي الناتجة عن أخذ العينات العشوائية، مما يضمن بشكل أساسي الاتساق الزمني والاستقرار الهيكلي في تسلسلات الفيديو.
والأهم من ذلك،نجح قرص DVD في الحفاظ على كمية كبيرة من المعرفة الهندسية والدلالية المسبقة الموجودة في نموذج الفيديو الأساسي.من خلال آليات التثبيت الهيكلية المبتكرة وتقنية تصحيح التشعب الكامن (LMR)، يمكن للنموذج استعادة حواف الكائنات بدقة، والنسيج عالي التردد، وتفاصيل الحركة مع الحفاظ على استقرار المشهد العالمي، مما يحسن بشكل كبير من الدقة الهيكلية لخرائط العمق.
في العديد من الاختبارات المعيارية المتاحة للجمهور، يصل أداء أقراص DVD بدون أخذ عينات إلى مستويات متطورة للغاية (SOTA).علاوة على ذلك، حقق هذا النموذج مستوىً رائدًا باستخدام 367 ألف إطار فقط من بيانات التدريب، أي بانخفاض قدره 163 ضعفًا تقريبًا مقارنةً بـ 60 مليون إطار تتطلبها أساليب التمييز التقليدية. وهذا لا يؤكد فقط الإمكانات الهائلة للنماذج الأساسية التوليدية في فهم الأشكال الهندسية، بل يفتح أيضًا آفاقًا تقنية جديدة تمامًا لإدراك الفيديو ثلاثي الأبعاد عالي الدقة ومنخفض التكلفة في المستقبل.
لمساعدة المطورين على تجربة أقراص DVD بسرعة، أطلقت HyperAI جهاز Notebook سهل النشر، مما يقلل من عوائق الدخول ويوفر وصولاً بنقرة واحدة إلى أحدث النماذج. ⬇️
تشغيل عبر الإنترنت:https://go.hyper.ai/w8kUO
عنوان المصدر المفتوح:https://github.com/EnVision-Research/DVD
المزيد من الدروس التعليمية عبر الإنترنت:
تشغيل تجريبي
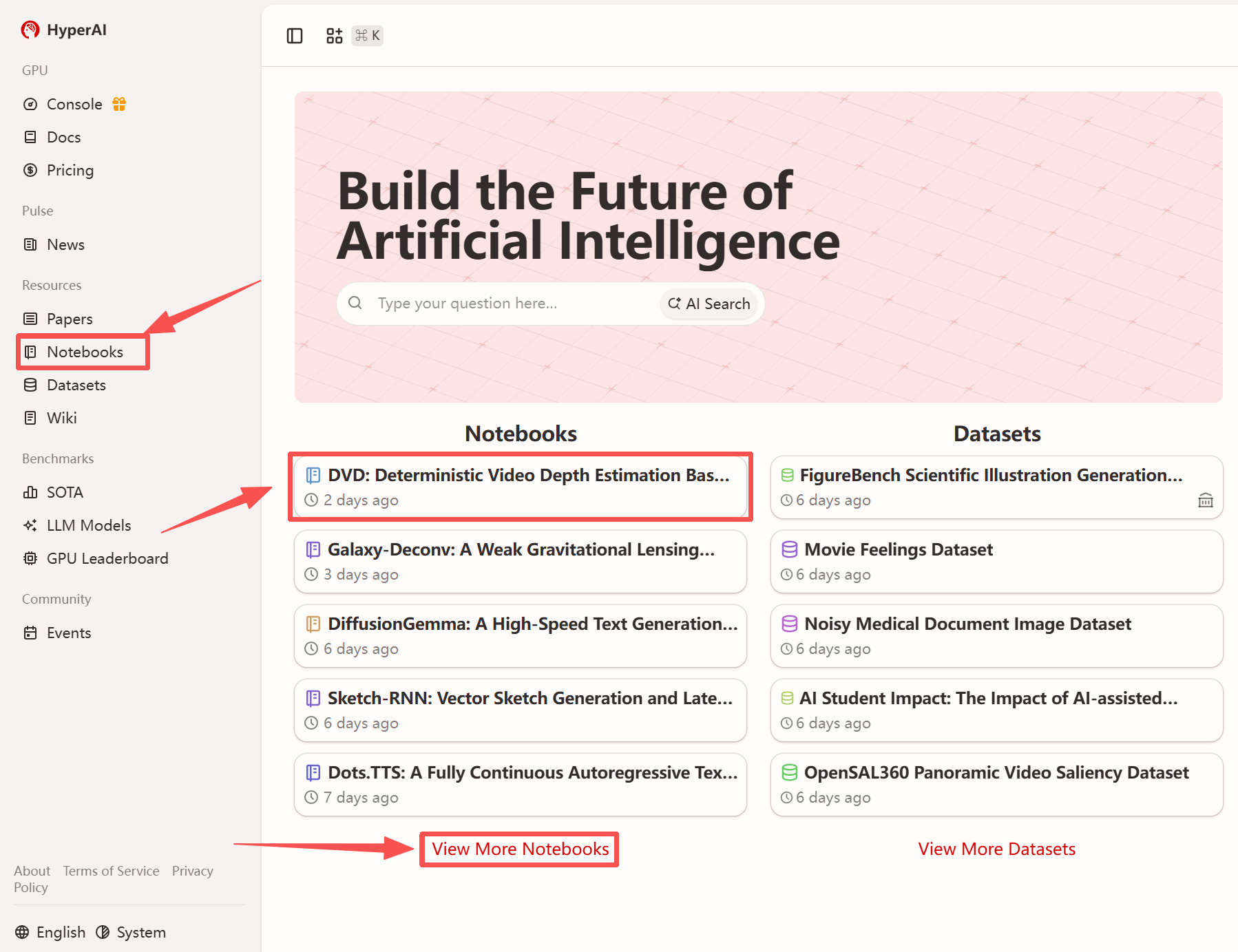
1. بعد الدخول إلى الصفحة الرئيسية لموقع hyper.ai، حدد صفحة "الدروس التعليمية"، أو انقر فوق "عرض المزيد من الدروس التعليمية"، وحدد "DVD: تقدير عمق الفيديو الحتمي بناءً على المعلومات الأولية التوليدية"، وانقر فوق "تشغيل هذا البرنامج التعليمي".
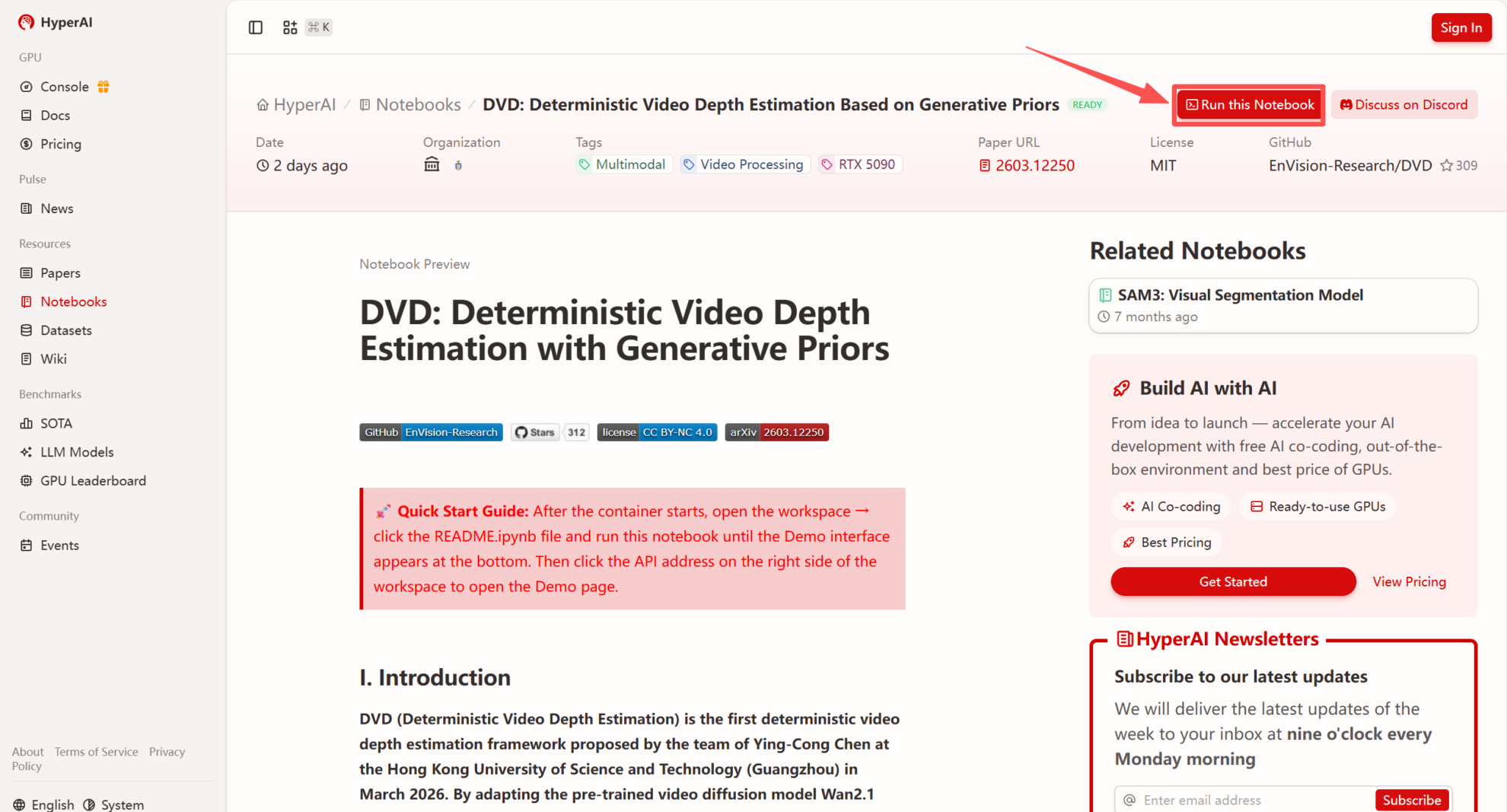
2. بعد إعادة توجيه الصفحة، انقر فوق "استنساخ" في الزاوية اليمنى العليا لاستنساخ البرنامج التعليمي في الحاوية الخاصة بك.
ملاحظة: يمكنك تبديل اللغات في الزاوية العلوية اليمنى من الصفحة. حاليًا، اللغتان الصينية والإنجليزية متاحتان. سيوضح هذا البرنامج التعليمي الخطوات باللغة الإنجليزية.
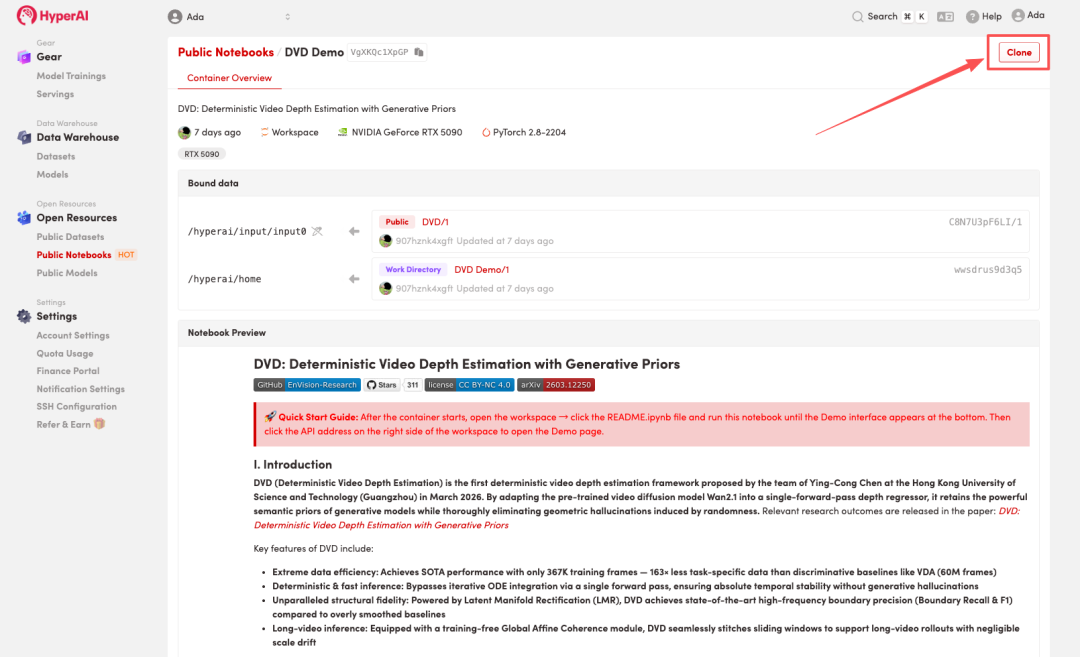
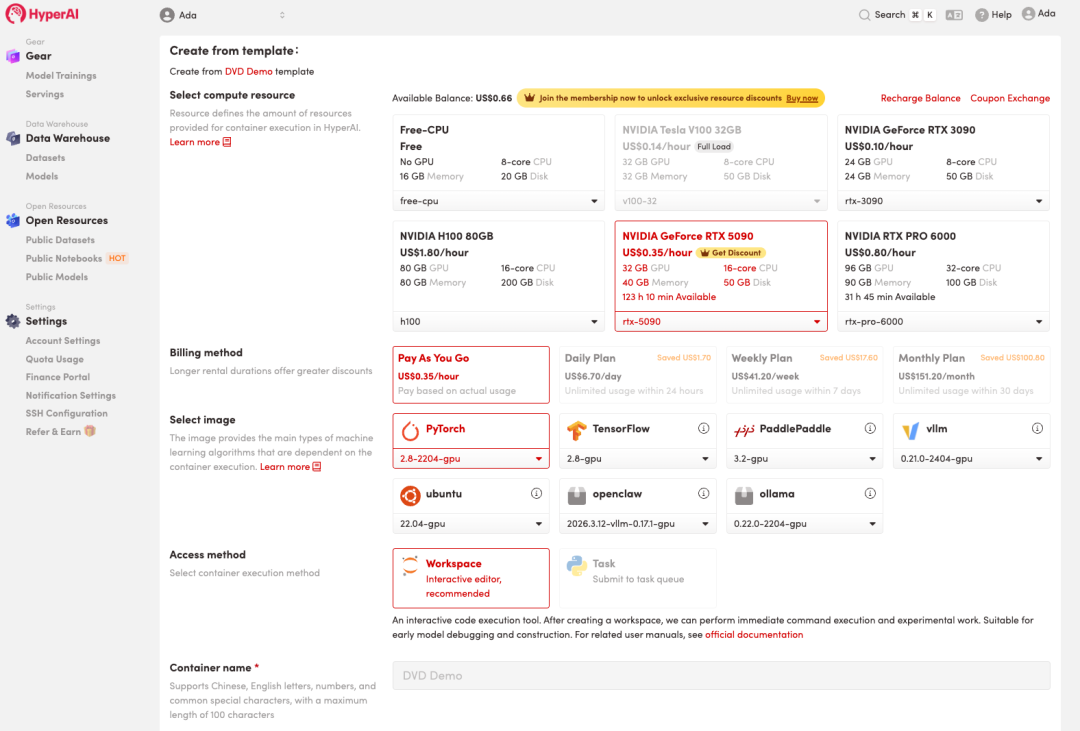
3. حدد صور "NVIDIA RTX 5090" و "PyTorch"، وانقر فوق "متابعة تنفيذ المهمة".
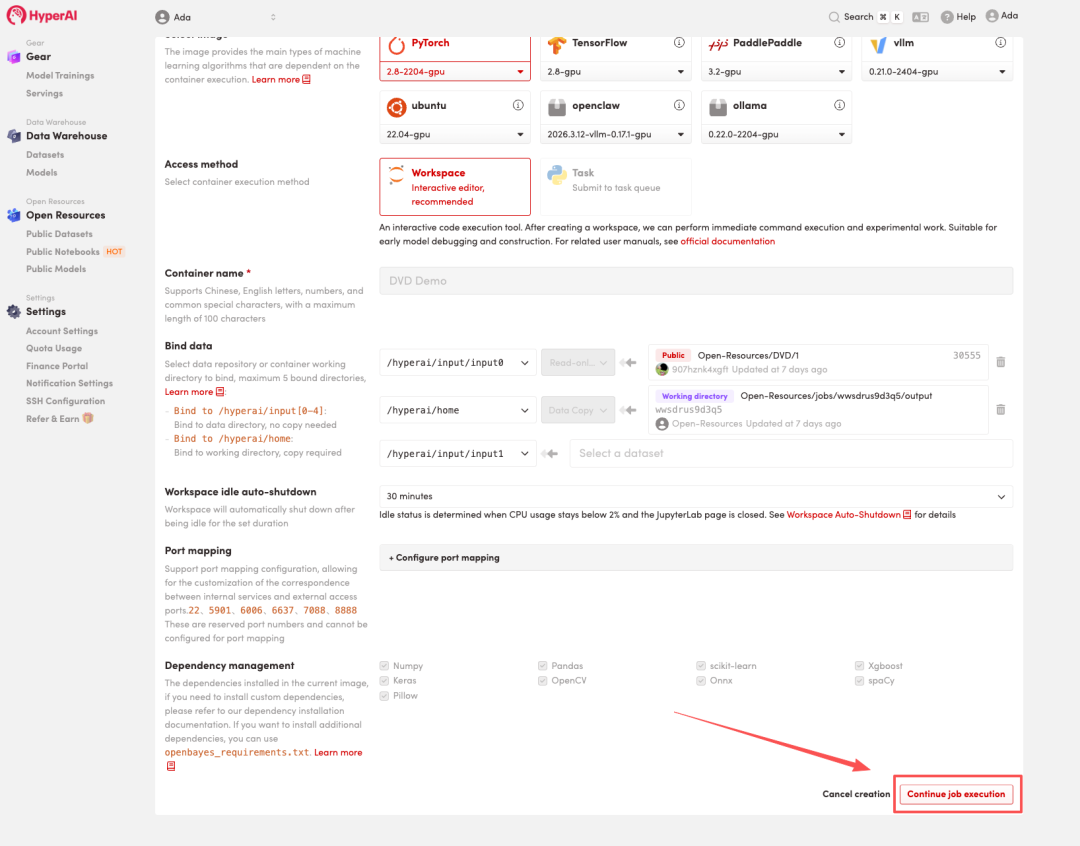
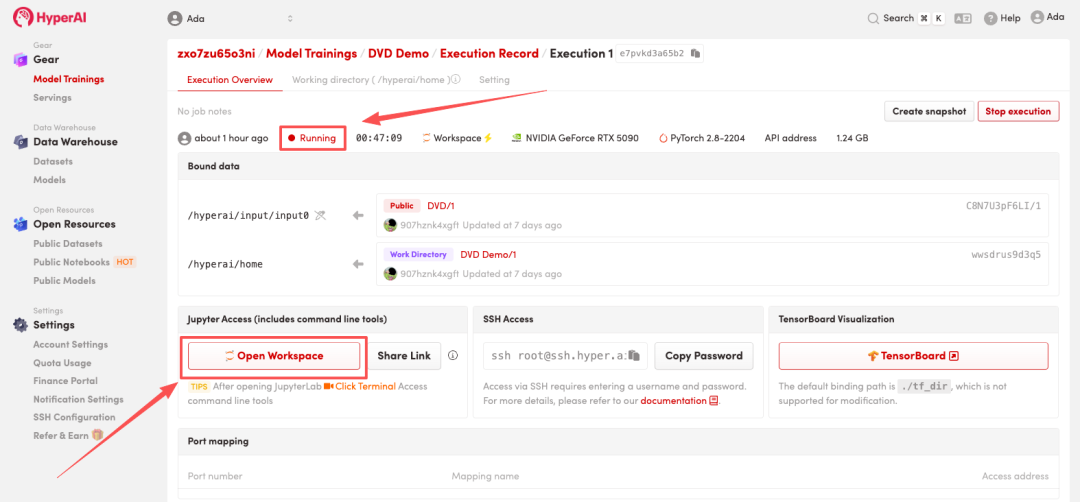
4. انتظر حتى يتم تخصيص الموارد. بمجرد أن تتغير الحالة إلى "قيد التشغيل"، انقر فوق "فتح مساحة العمل" للدخول إلى مساحة عمل Jupyter.
عرض التأثير
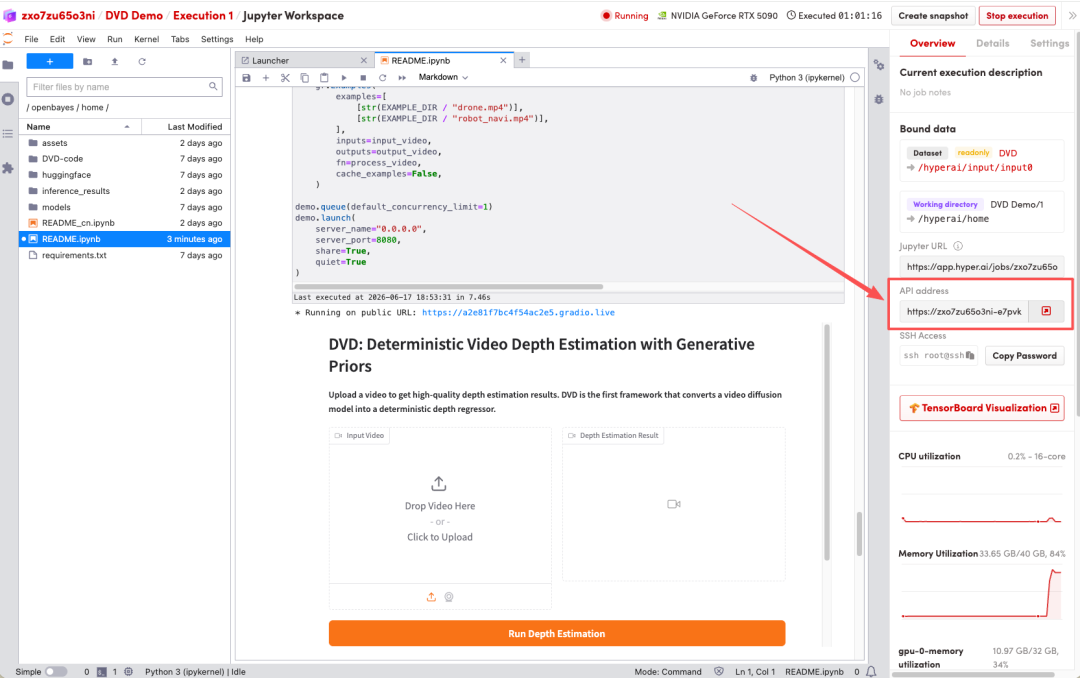
1. بعد إعادة توجيه الصفحة، انقر على ملف README الموجود على اليسار، ثم انقر على تشغيل في الأعلى.
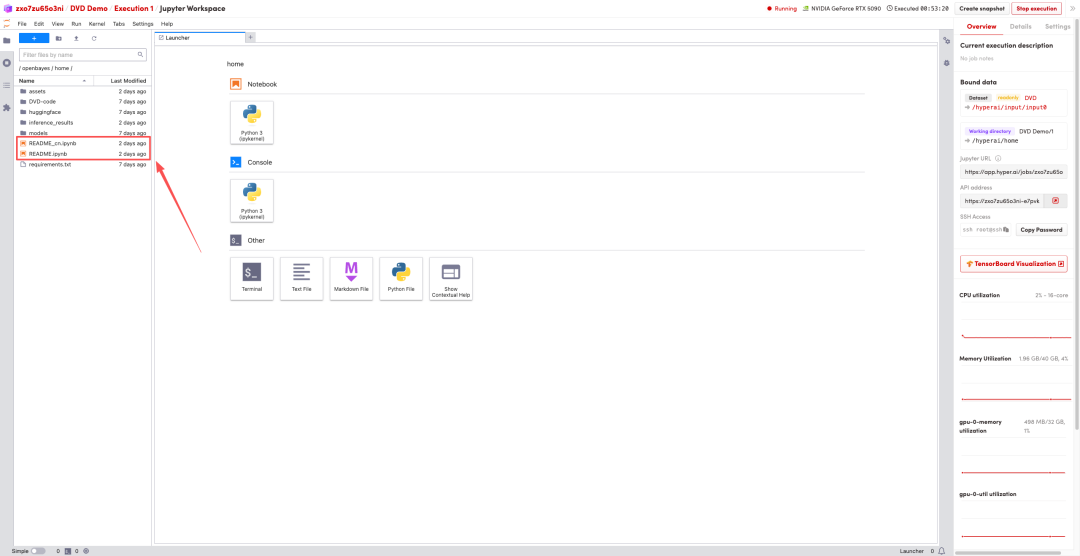
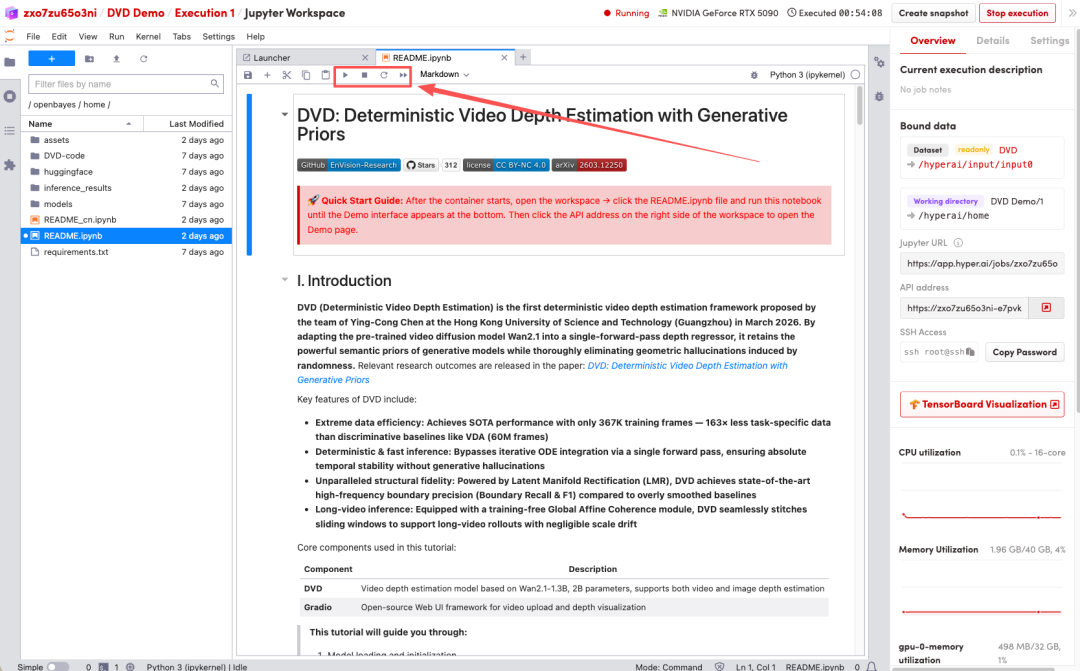
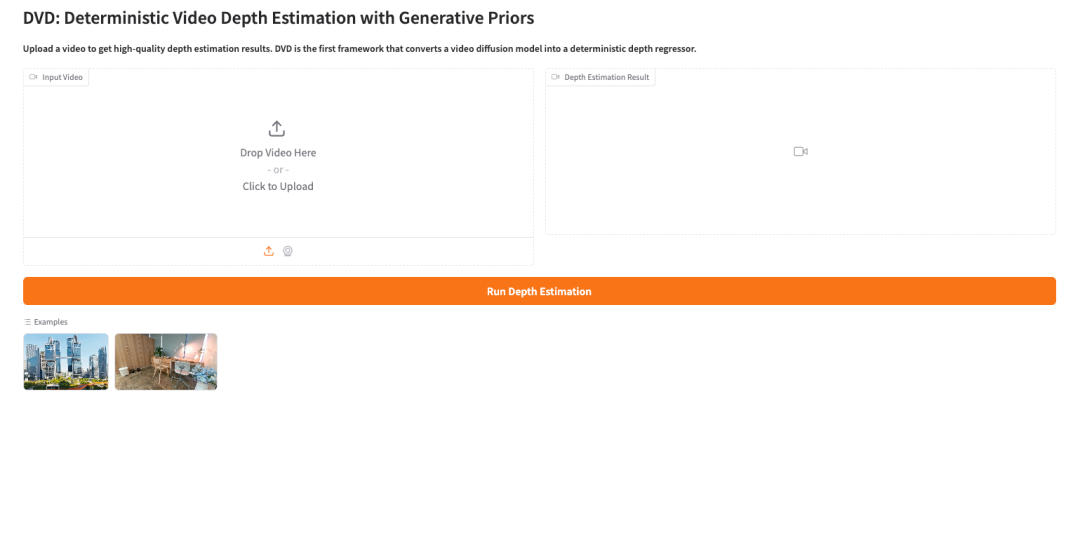
2. بعد اكتمال العملية، انقر فوق عنوان API الموجود على اليمين لفتح واجهة العرض التوضيحي.