Command Palette
Search for a command to run...
برنامج تعليمي عبر الإنترنت | حاسوب محمول بسعة 16 جيجابايت يحقق أداءً يقارب 26 مليار نقطة في البوصة: معالج Gemma 4 12B يعتمد على بنية مبتكرة لمعالجة موحدة للنصوص والصور والصوت

في حين أن المنافسة على النماذج الكبيرة لا تزال تركز على حجم المعلمات، فقد أثبتت جوجل ديب مايند مرة أخرى أن تحسينات الأداء لا تعتمد بالضرورة على النماذج الأكبر حجماً فقط.
أطلقت جوجل ديب مايند مؤخرًا رسميًا أحدث عضو في عائلة جيما 4، وهو جيما 4 12B. يُعد هذا النموذج متعدد الوسائط نموذجًا موحدًا يحتوي على 12 مليار مُعامل فقط، ومع ذلك، فقد أظهر أداءً يقارب أداء نموذج خبير هجين (MoE) يحتوي على 26 مليار مُعامل في العديد من اختبارات القياس المعيارية. وتشير البيانات الرسمية إلى أن أداء جيما 4 12B في مهام مثل الاستدلال، وتوليد الشفرة، وفهم الوسائط المتعددة، يقترب من أداء جيما 4 26B.وفي الوقت نفسه، يحقق مستوى أحدث التقنيات (SOTA) بين نماذج المصادر المفتوحة الحالية من نفس المستوى في بعض مهام الفهم البصري والوكلاء.والأهم من ذلك، أن هذا النموذج لا يتطلب سوى 16 جيجابايت من ذاكرة الفيديو أو الذاكرة الموحدة للتشغيل الأصلي على أجهزة الكمبيوتر المحمولة المخصصة للمستهلكين، مما يحقق توازنًا نادرًا بين الأداء وتكلفة النشر.
باعتبارها أول نموذج متوسط الحجم في سلسلة Gemma يدعم إدخال الصوت بشكل أصلي، فإن أكبر إنجاز لـ Gemma 4 12B لا يكمن في حجم معلماتِها، بل في ابتكارها المعماري. لفترة طويلة، اعتمدت النماذج متعددة الوسائط بشكل عام نهج "المشفّر + نموذج اللغة": حيث تتم معالجة الصور بواسطة مشفّر مرئي، والصوت بواسطة مشفّر كلام، ثم تُمرر النتائج إلى نموذج لغوي كبير للاستدلال. على الرغم من أن هذه البنية ناضجة،ومع ذلك، فإن هذا يؤدي إلى زيادة العبء الحسابي، واستخدام الذاكرة، وزمن استجابة الاستدلال.
لمعالجة هذه المشكلة، صممت جوجل ديب مايند بنية جديدة تمامًا خالية من المشفرات لـ Gemma 4 12B. يتم تغذية الصور مباشرة إلى العمود الفقري LLM بعد مرورها عبر وحدة تضمين خفيفة الوزن، بينما يتم إسقاط الصوت مباشرة في نفس مساحة التمثيل مثل رموز النص.يقوم نفس المحول الذي يعتمد على وحدة فك التشفير فقط بمعالجة النصوص والصور والأصوات بشكل موحد.يشير البيان الرسمي إلى أن هذا التصميم يقلل بشكل كبير من زمن استجابة الاستدلال متعدد الوسائط مع تقليل تعقيد النظام وحجم الذاكرة المستخدمة.
بالإضافة إلى بنيتها الموحدة متعددة الوسائط، تدعم Gemma 4 12B أيضًا نافذة سياق فائقة الطول بسعة 256 كيلوبايت، ووضع استدلال عميق قابل للتبديل، واستدعاء الوظائف الأصلي، وقدرات سير عمل الوكيل. في المعايير القياسية،أداؤها العام قريب من أداء طراز Gemma 4 26B MoE، الذي يزيد حجمه عن ضعف حجمها.تكلفة التشغيل أقل من نصف تكلفة النظام الآخر. بالنسبة للمطورين الذين يرغبون في نشر قدرات الذكاء الاصطناعي المتقدمة محليًا، فهذا يعني أنه بإمكانهم تحقيق تجربة استدلال وتفاعل مع الوكلاء قريبة من تلك التي توفرها نماذج الوسائط المتعددة المتطورة الحالية، دون الحاجة إلى وحدات معالجة رسومية باهظة الثمن.
حالياً، أطلق قسم البرامج التعليمية في الموقع الرسمي لشركة HyperAI (hyper.ai) ميزة "النشر بنقرة واحدة لـ Gemma 4 12B-it"، مما يقلل من عتبة النشر في شكل دفتر ملاحظات ويسهل على المطورين التحقق من النماذج بسرعة.
تشغيل عبر الإنترنت:https://go.hyper.ai/1Jrdl
المزيد من الدروس التعليمية عبر الإنترنت:
تشغيل تجريبي
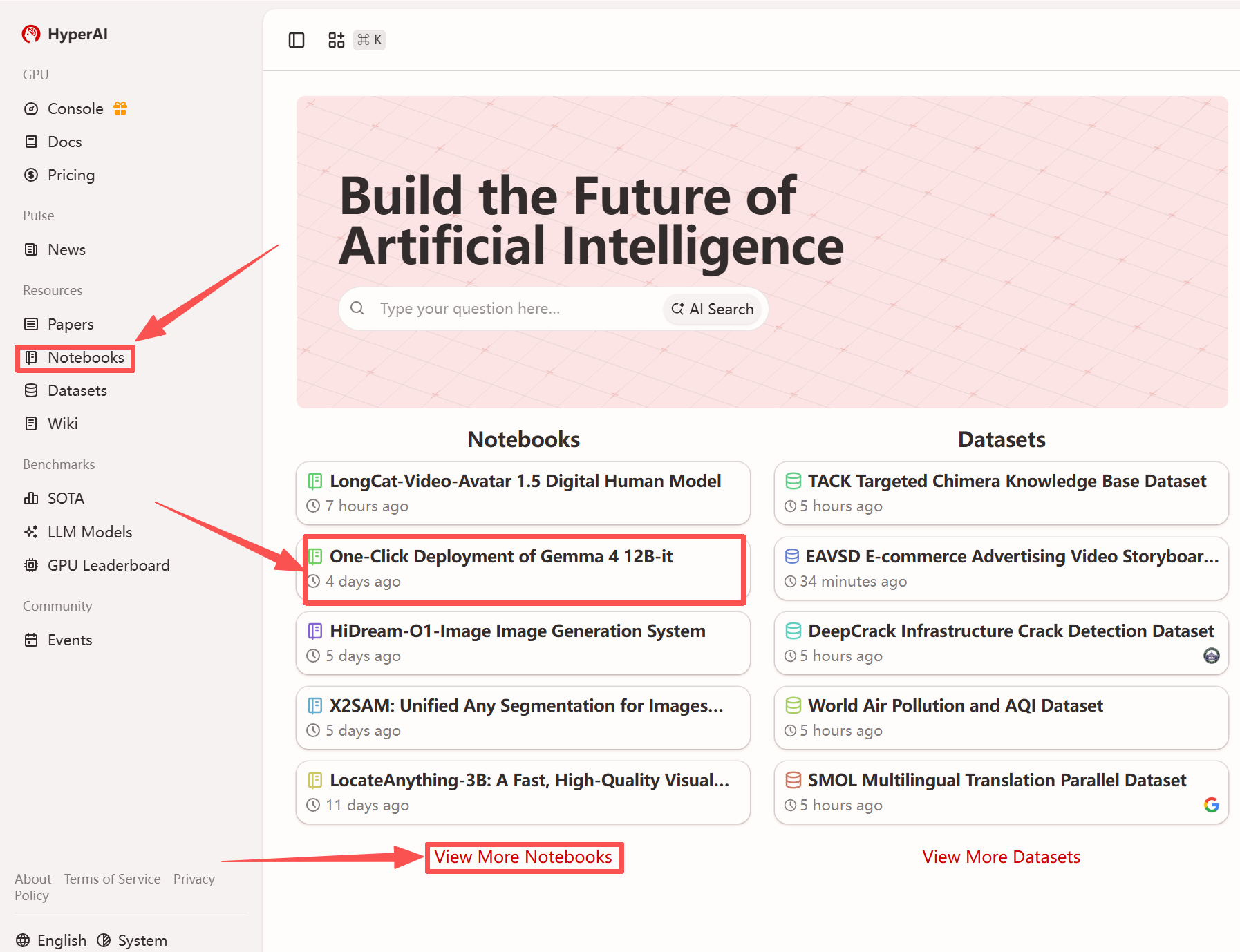
1. بعد الدخول إلى الصفحة الرئيسية لموقع hyper.ai، حدد صفحة "الدروس التعليمية"، أو انقر فوق "عرض المزيد من الدروس التعليمية"، وحدد "النشر بنقرة واحدة لـ Gemma 4 12B-it"، ثم انقر فوق "تشغيل هذا البرنامج التعليمي".
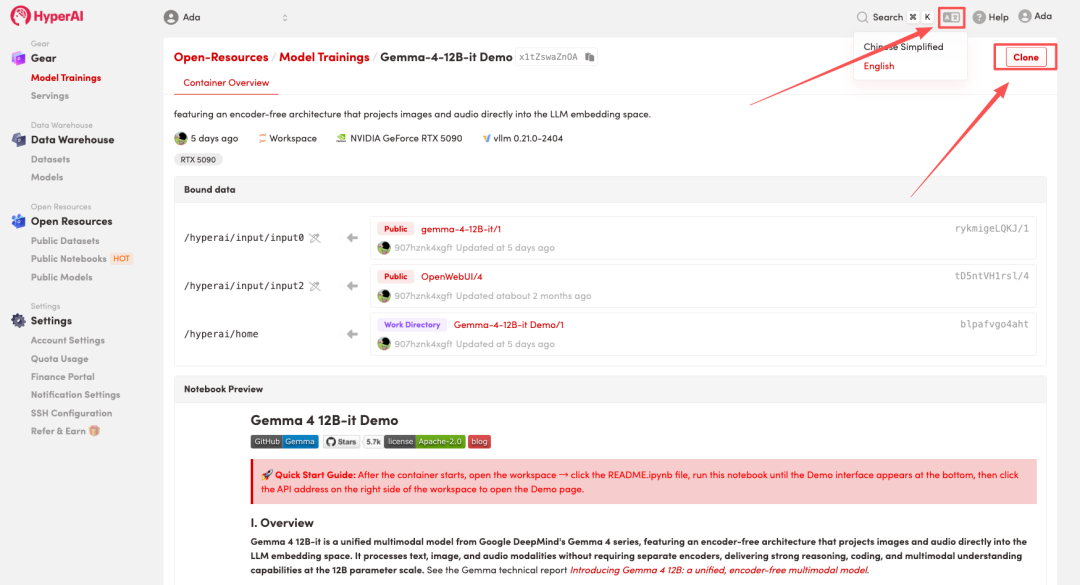
2. بعد إعادة توجيه الصفحة، انقر فوق "استنساخ" في الزاوية اليمنى العليا لاستنساخ البرنامج التعليمي في الحاوية الخاصة بك.
ملاحظة: يمكنك تبديل اللغات في الزاوية العلوية اليمنى من الصفحة. حاليًا، اللغتان الصينية والإنجليزية متاحتان. سيوضح هذا البرنامج التعليمي الخطوات باللغة الإنجليزية.
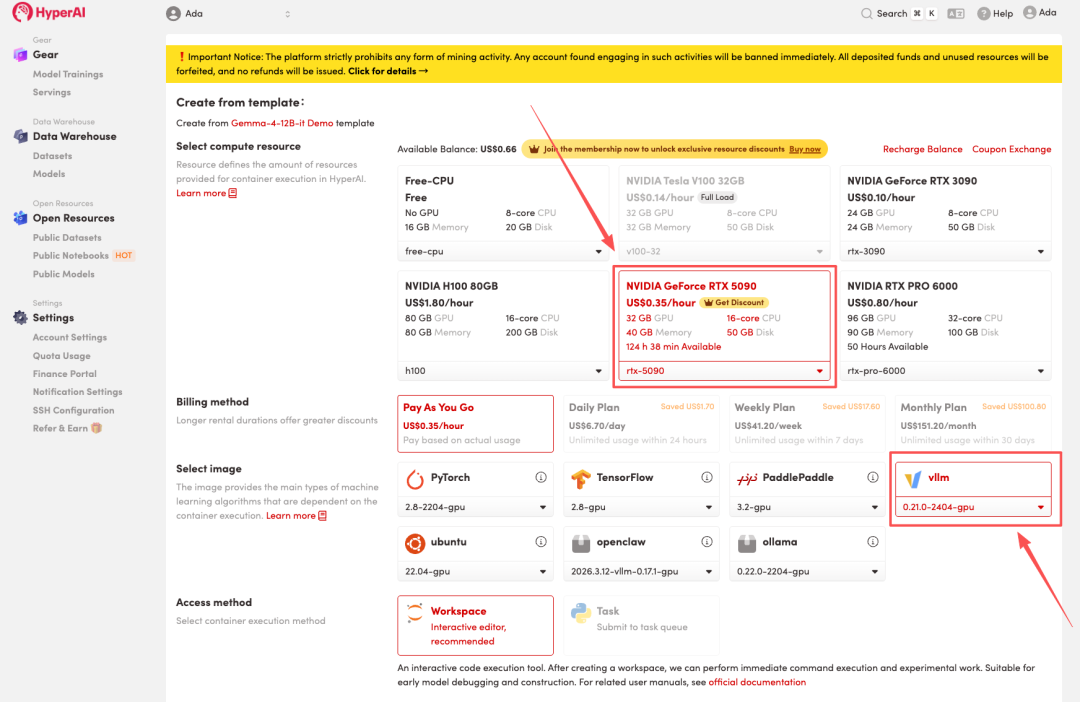
3. حدد صور "NVIDIA RTX 5090" و "vLLM"، وانقر فوق "متابعة تنفيذ المهمة".
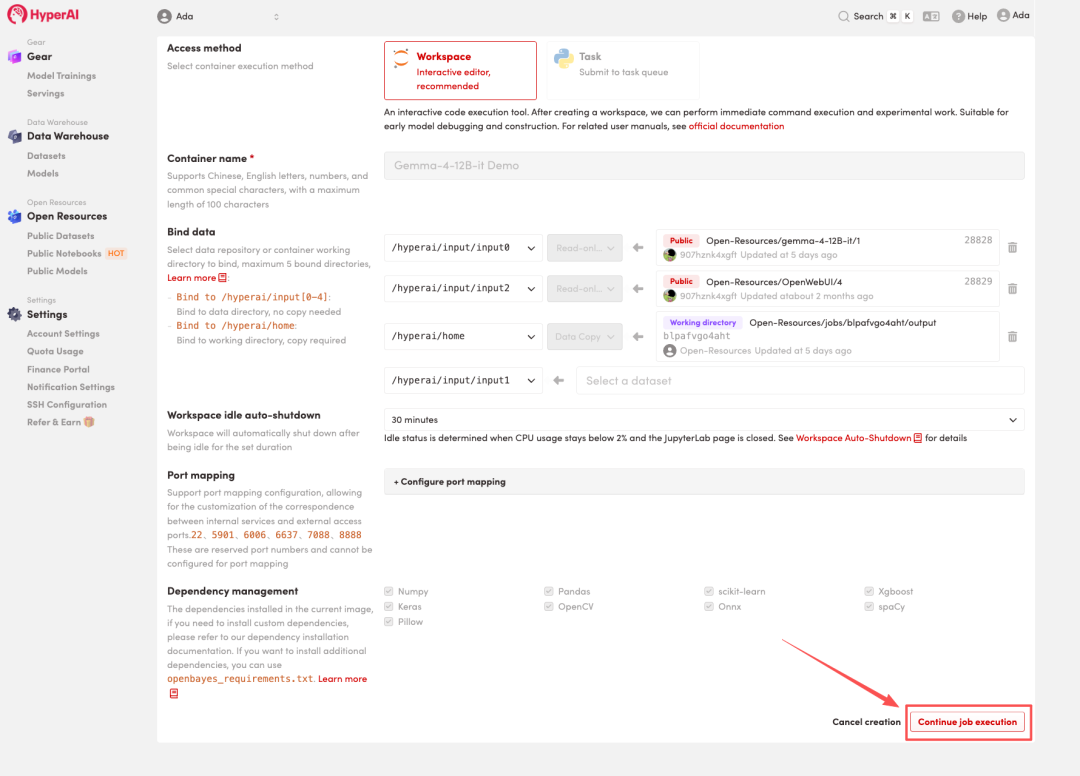
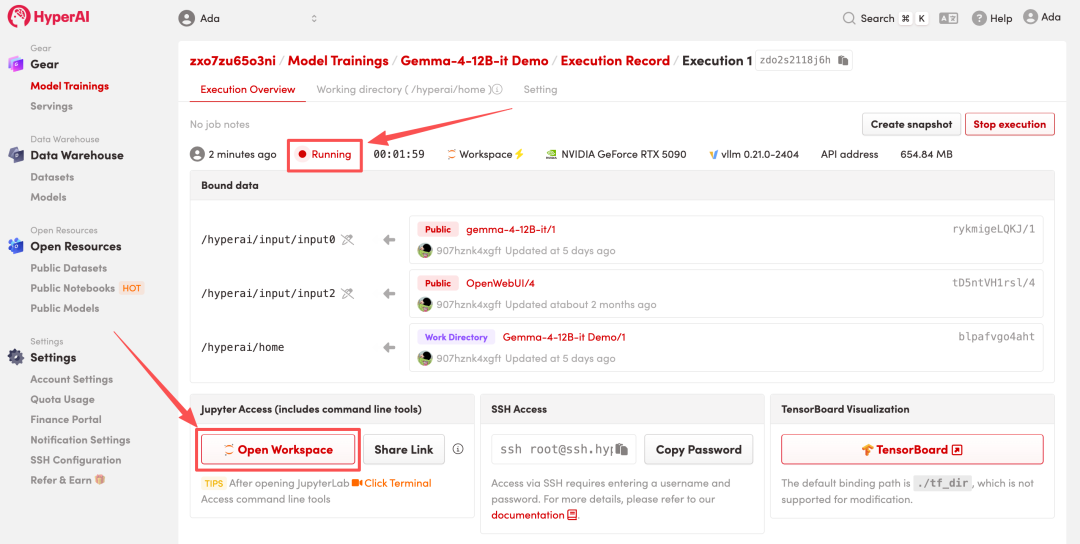
4. انتظر حتى يتم تخصيص الموارد. بمجرد أن تتغير الحالة إلى "قيد التشغيل"، انقر فوق "فتح مساحة العمل" للدخول إلى مساحة عمل Jupyter.
عرض التأثير
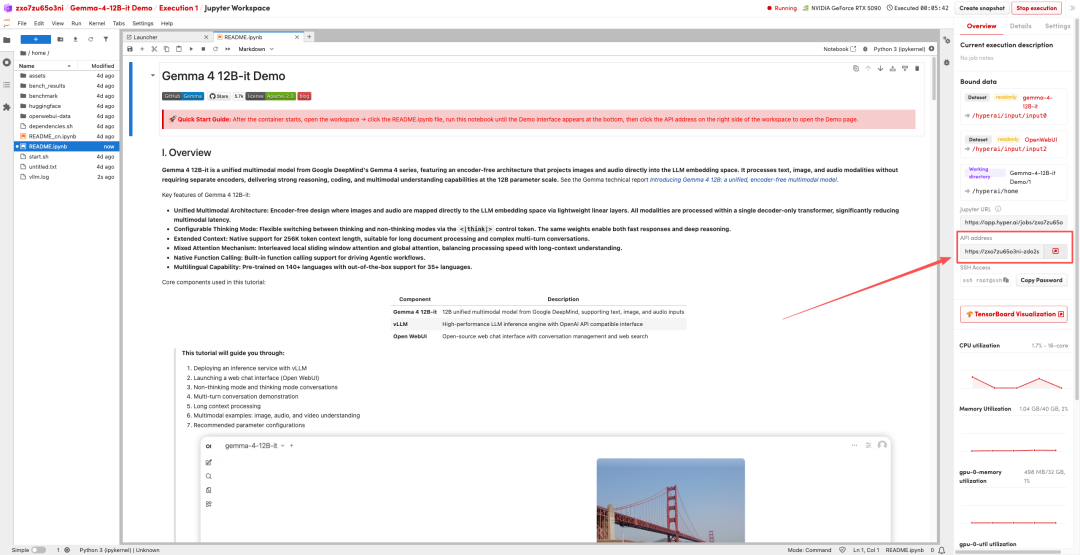
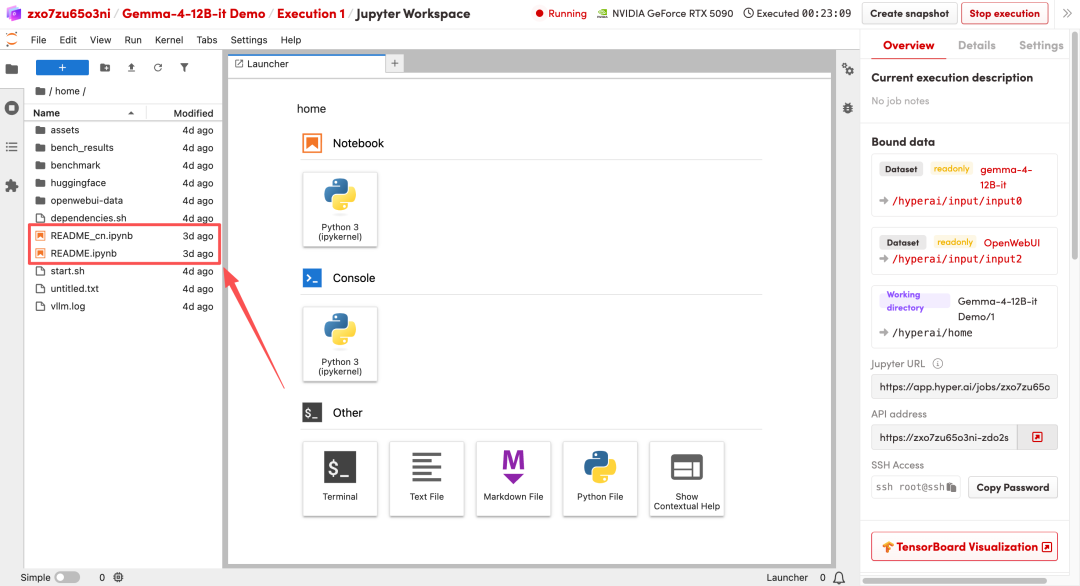
1. بعد إعادة توجيه الصفحة، انقر على ملف README الموجود على اليسار، ثم انقر على تشغيل في الأعلى.
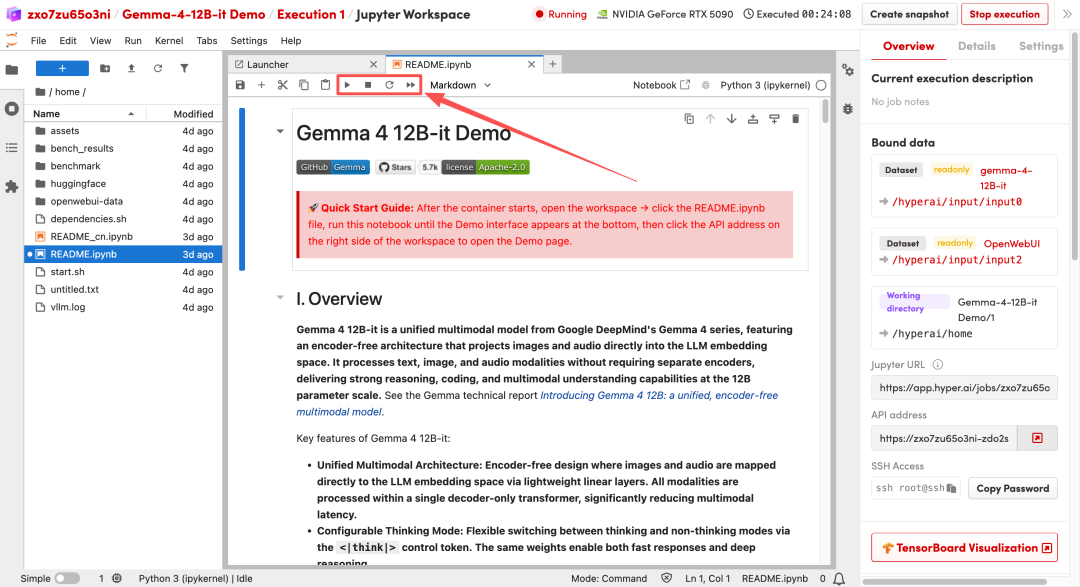
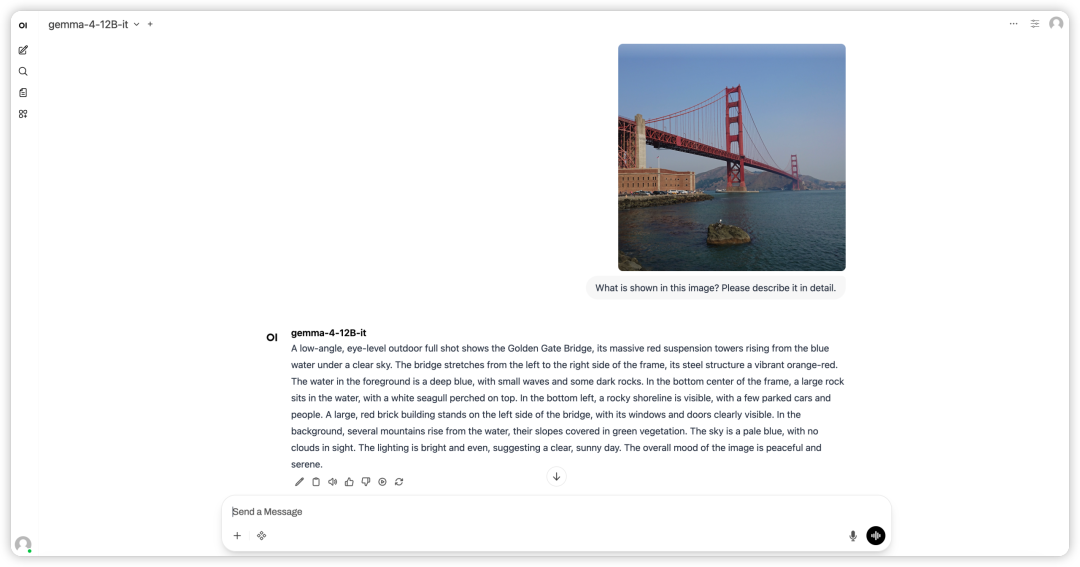
2. بعد اكتمال العملية، انقر فوق عنوان API الموجود على اليمين لفتح واجهة العرض التوضيحي.