Command Palette
Search for a command to run...
برنامج تعليمي عبر الإنترنت | سرعة توليد أسرع تصل إلى 4 مرات: يمكن لـ DiffusionGemma توليد كتل كاملة من النصوص في وقت واحد، مع تحسين مستمر يعتمد على إزالة الضوضاء المتوازية متعددة الجولات.

في الحادي عشر من يونيو، أطلقت جوجل رسميًا برنامج DiffusionGemma مفتوح المصدر، وهو نموذج لتوليد النصوص مبني على تقنية الانتشار المنفصل. يستفيد هذا البرنامج من قدرات الذكاء الرائدة في مجال معالجة كل مُعامل في سلسلة Gemma 4، بالإضافة إلى أحدث أبحاث Gemini Diffusion، مع دمج رأس انتشار جديد لزيادة سرعة التوليد إلى أقصى حد. على عكس النماذج التقليدية الكبيرة التي تُخرج النص كلمةً كلمة، يُمكن لبرنامج DiffusionGemma توليد كتل نصية كاملة في وقت واحد، وتحسين النتائج باستمرار من خلال جولات متعددة من إزالة التشويش المتوازي.وينتج عن ذلك زيادة في سرعة التوليد تصل إلى 4 أضعاف.
تُظهر البيانات الرسمية أن DiffusionGemma يمكنها تحقيق سرعة توليد تزيد عن 1100 رمز/ثانية على وحدة معالجة الرسومات NVIDIA H100 واحدة وأكثر من 700 رمز/ثانية على GeForce RTX 5090، متجاوزة بكثير النماذج التراجعية التلقائية من نفس المستوى.
من منظور الهندسة المعمارية،يستخدم برنامج DiffusionGemma تصميمًا خبيرًا هجينًا على مستوى المعلمات (MoE) مكونًا من 26 مليار معلمة.يبلغ إجمالي عدد المعاملات حوالي 25.2 مليار معامل، ولكن لا يتم تفعيل سوى 3.8 مليار معامل أثناء الاستدلال، مما يقلل بشكل كبير من الحمل الحسابي مع الحفاظ على قدرات استدلال قوية. يعتمد النموذج على بنية مُشفِّر-مُفكِّك، ويتضمن آلية انتباه ثنائية الاتجاه، مما يُمكِّنه من معالجة 256 رمزًا بالتوازي في آنٍ واحد. كما يدعم مهامًا تعتمد بشكل كبير على السياق العام، مثل تحرير النصوص المضمنة، وإكمال التعليمات البرمجية، وتوليد البنى الرياضية.
بالإضافة إلى ذلك، يدعم DiffusionGemma سياقات طويلة تصل إلى 256 ألف رمز، وإدخال متعدد الوسائط للرسوم البيانية والنصوص، وأنماط الاستدلال التي يتم تنشيطها بواسطة <|think|>، مما يوفر للمطورين خيارات تقنية جديدة لاستكشاف تطبيقات الذكاء الاصطناعي عالية الكفاءة من الجيل التالي.
على الرغم من أن جوجل لا تزال تؤكد أن معيار Gemma 4 أكثر ملاءمة لبيئات الإنتاج من حيث الجودة المُولدة، إلا أن قدرات توليد النصوص القائمة على الانتشار التي أظهرها DiffusionGemma قد تفتح مسارًا جديدًا جديرًا بالملاحظة لتطوير نماذج اللغة الكبيرة.
ولتسهيل تجربة المطورين لـ DiffusionGemma بأقل جهد ممكن، قامت HyperAI بمتابعة سريعة بعد أن أصبح النموذج مفتوح المصدر، وأطلقت الآن جهاز كمبيوتر محمول سهل النشر، والذي يمكنه التحقق من القدرات القوية للنموذج باستخدام بطاقة رسومات NVIDIA RTX Pro 6000 واحدة فقط.
تشغيل عبر الإنترنت:https://go.hyper.ai/879dB
المزيد من الدروس التعليمية عبر الإنترنت:
تشغيل تجريبي
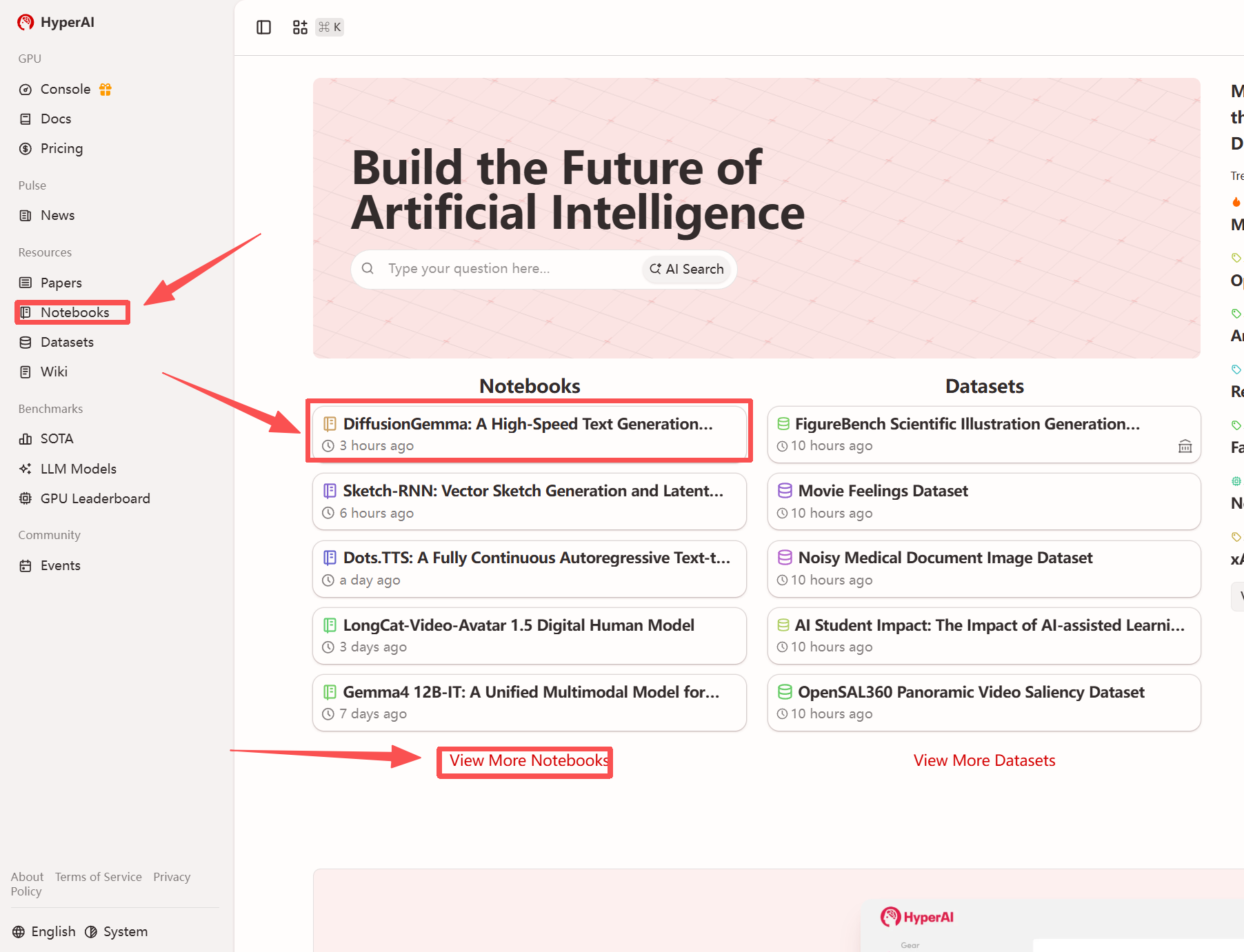
1. بعد الدخول إلى الصفحة الرئيسية لموقع hyper.ai، حدد صفحة "الدروس التعليمية"، أو انقر فوق "عرض المزيد من الدروس التعليمية"، وحدد "DiffusionGemma: نموذج توليد النصوص عالي السرعة القائم على الانتشار المنفصل"، وانقر فوق "تشغيل هذا البرنامج التعليمي".
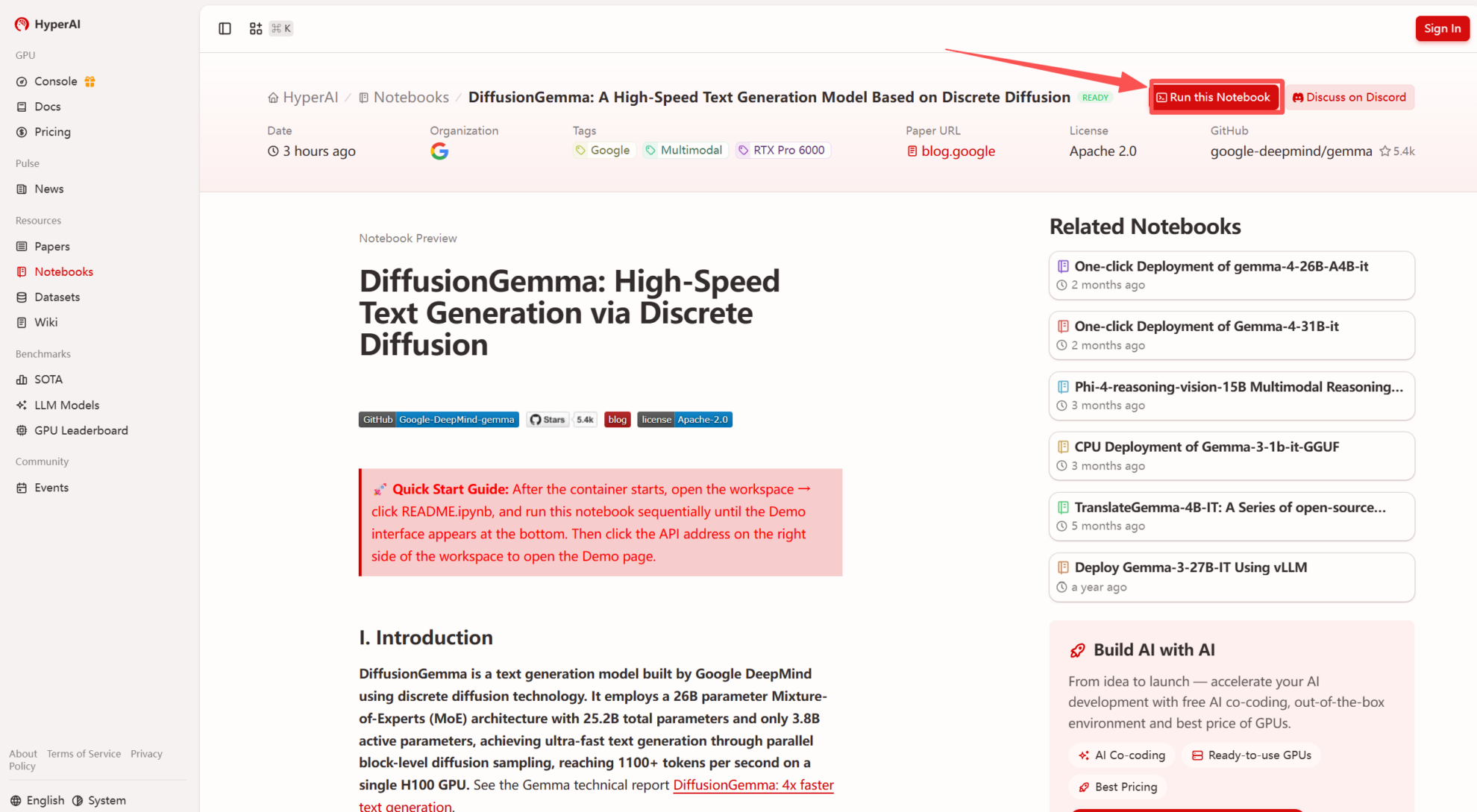
2. بعد إعادة توجيه الصفحة، انقر فوق "استنساخ" في الزاوية اليمنى العليا لاستنساخ البرنامج التعليمي في الحاوية الخاصة بك.
ملاحظة: يمكنك تبديل اللغات في الزاوية العلوية اليمنى من الصفحة. حاليًا، اللغتان الصينية والإنجليزية متاحتان. سيوضح هذا البرنامج التعليمي الخطوات باللغة الإنجليزية.
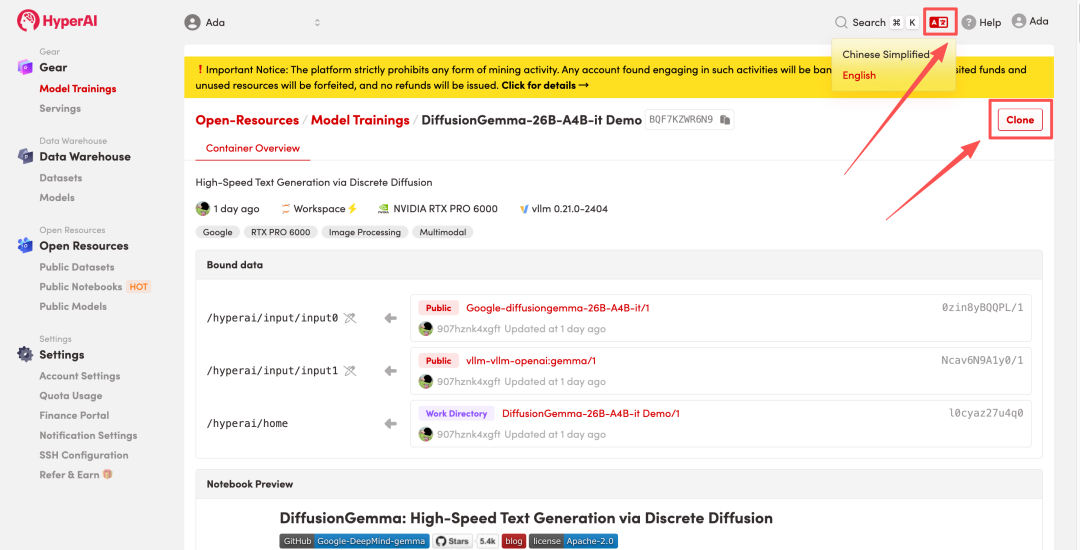
3. حدد صور "NVIDIA RTX Pro 6000" و "vLLM"، وانقر فوق "متابعة تنفيذ المهمة".
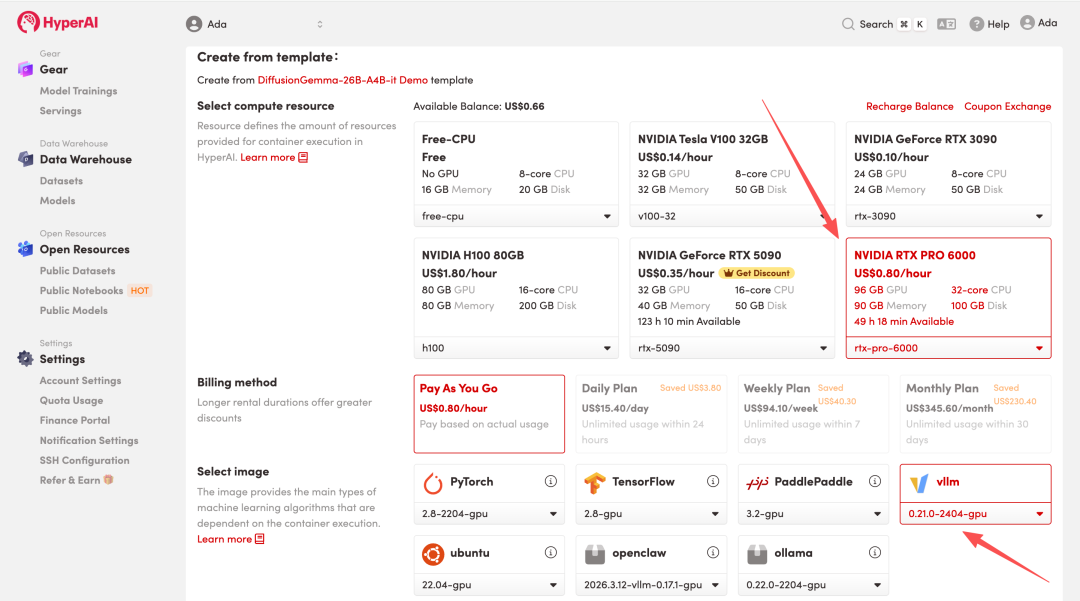
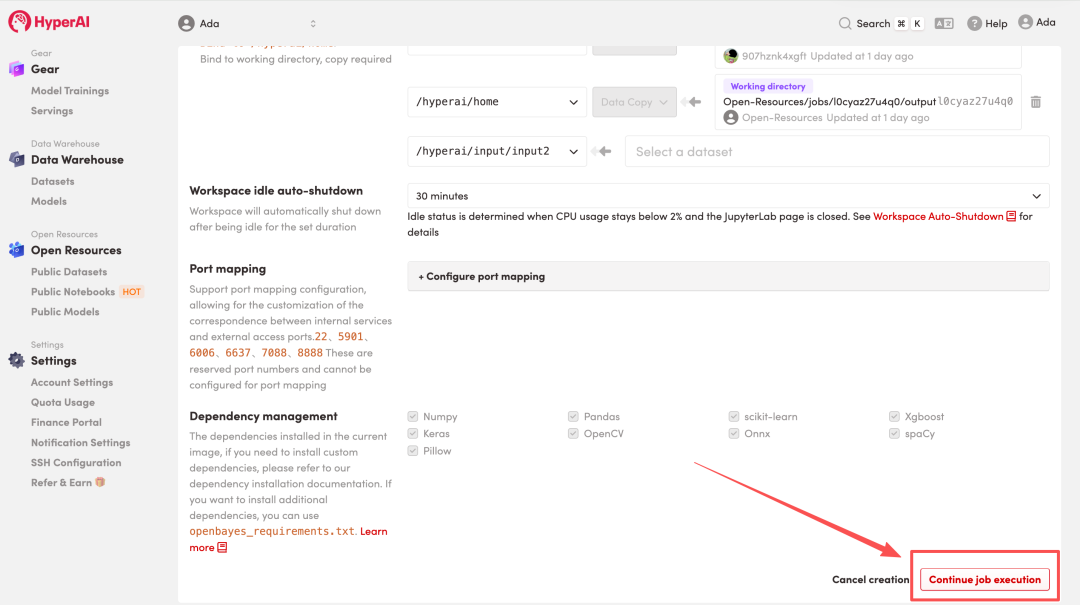
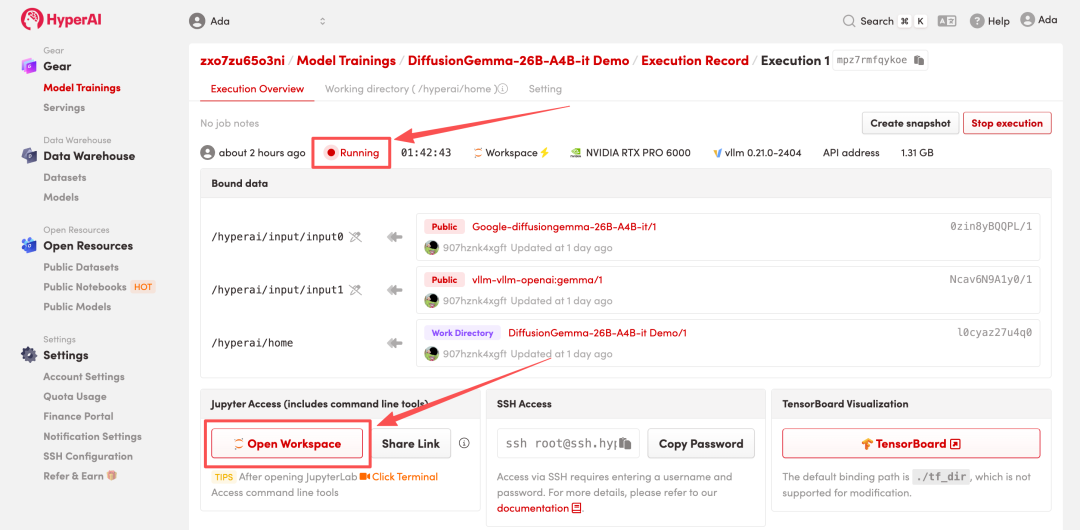
4. انتظر حتى يتم تخصيص الموارد. بمجرد أن تتغير الحالة إلى "قيد التشغيل"، انقر فوق "فتح مساحة العمل" للدخول إلى مساحة عمل Jupyter.
عرض التأثير
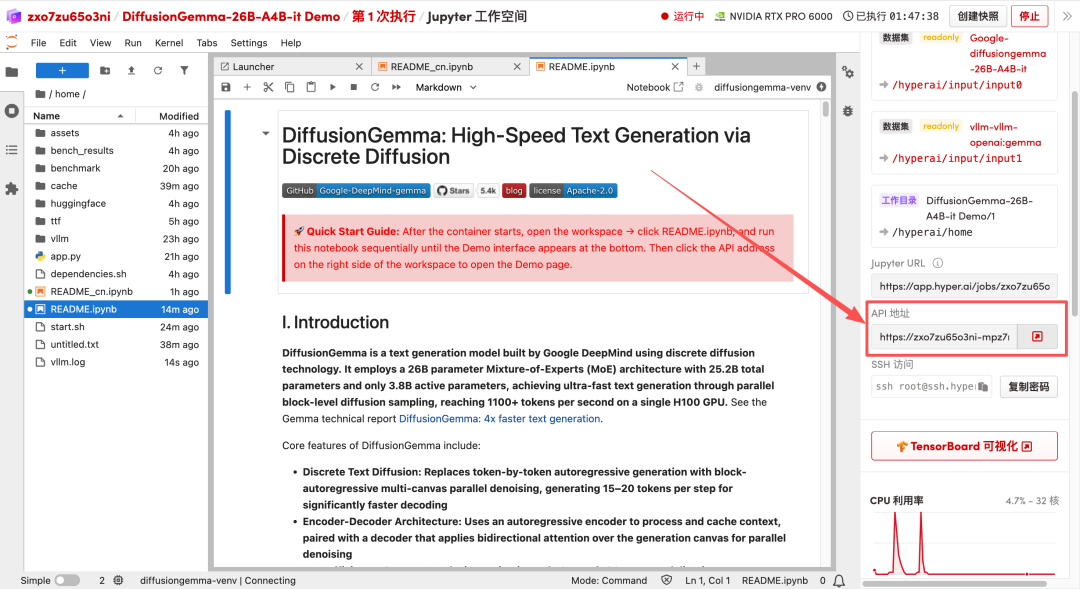
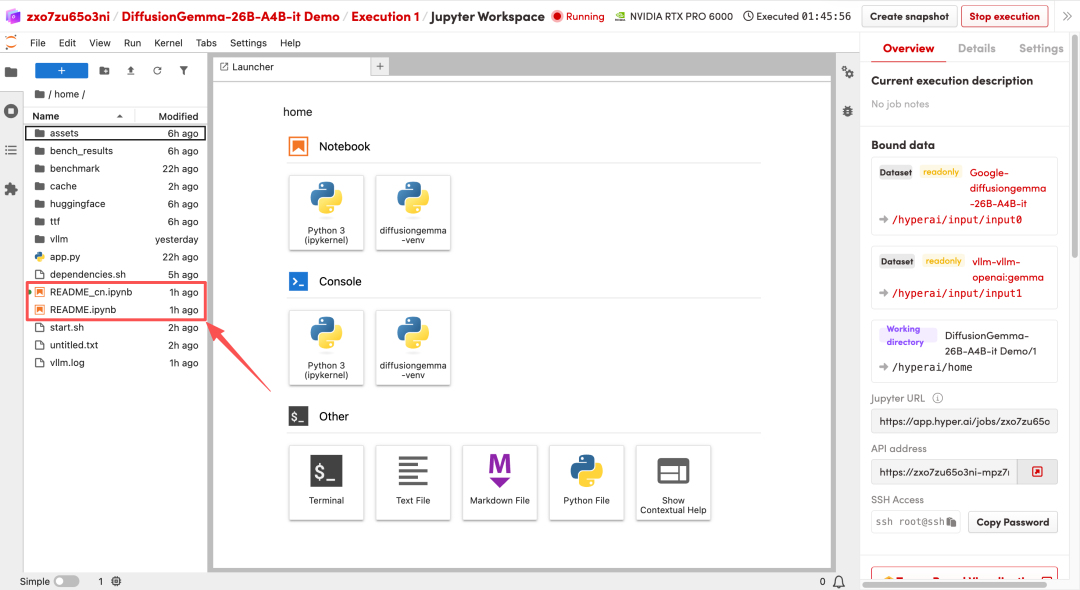
1. بعد إعادة توجيه الصفحة، انقر على ملف README الموجود على اليسار، ثم انقر على تشغيل في الأعلى.
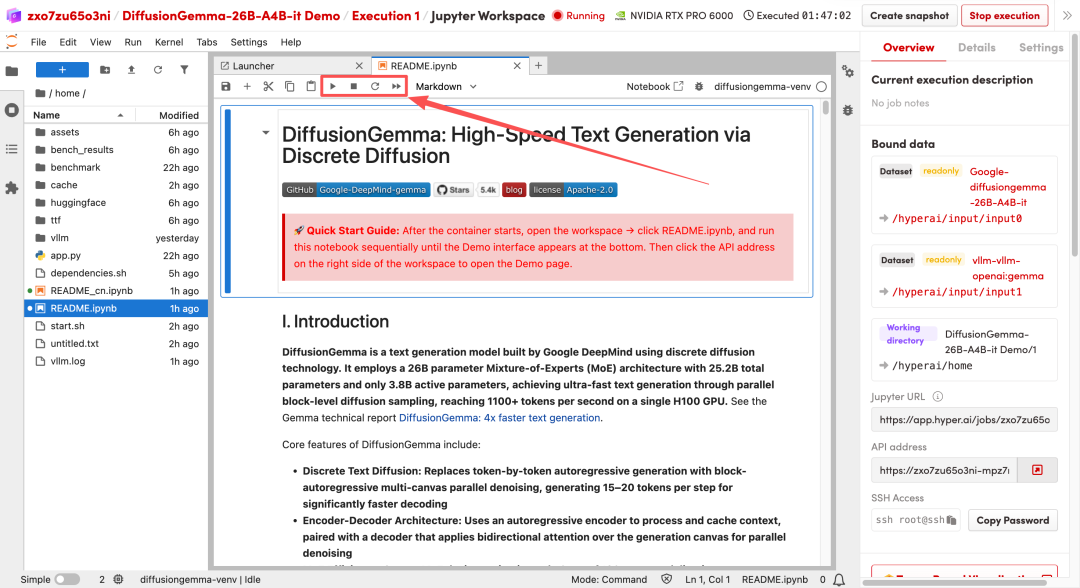
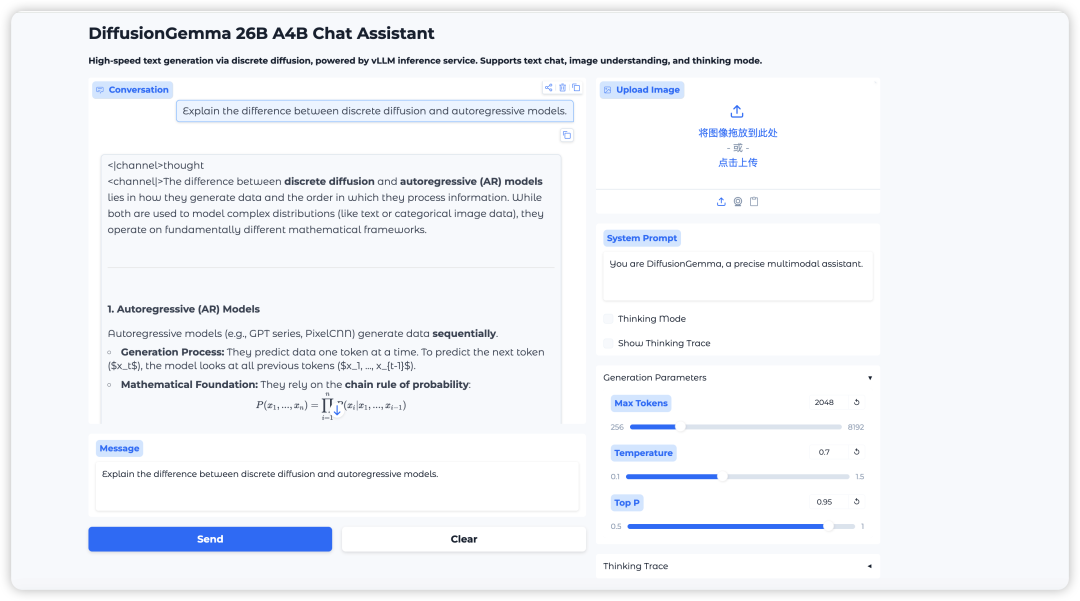
2. بعد اكتمال العملية، انقر فوق عنوان API الموجود على اليمين لفتح واجهة العرض التوضيحي.