Command Palette
Search for a command to run...
MOSS-TTS: نموذج توليد كلام منفصل وعالي الجودة يعتمد على بنية CAT؛ كسر حاجز تحليل الخلية الواحدة: بناء معيار مرجعي لأطلس المناعة عبر السرطان باستخدام مجموعة بيانات Pan-Cancer scRNA-Seq.

تُثبت نماذج توليد الكلام الأحادي حاليًا عدم كفايتها في مواجهة متطلبات العالم الحقيقي المعقدة. ففي التطبيقات العملية، لا يقتصر الأمر على ضرورة محاكاة الكلام لنبرة صوتية محددة بدقة، بل يجب أيضًا أن ينتقل بسلاسة بين أنماط الكلام المختلفة عبر المحتوى المتنوع، وأن يظل ثابتًا طوال سرد يمتد لعشرات الدقائق. علاوة على ذلك، يجب أن يدعم صيغًا متعددة كالحوار، ولعب الأدوار، والتفاعل الفوري. تتجاوز هذه المتطلبات بكثير قدرات النموذج الأحادي.
وفي هذا السياق،أصدرت MOSI.AI و OpenMOSS عائلة نماذج توليد الكلام MOSS-TTS.بدلاً من بناء نموذج واحد ضخم، تفصل هذه المجموعة من النماذج عملية توليد الكلام إلى خمسة نماذج جاهزة للاستخدام، تشمل نموذج MOSS-TTS عالي الدقة، ونموذج MOSS-TTSD للحوار متعدد المتحدثين. تعتمد تقنيتها الأساسية على مُجزئ الصوت MOSS Audio-Tokenizer واسع النطاق ذي 1.6 مليار مُعامل، والذي يستخدم بنية Transformer خالصة (CAT، مُجزئ الصوت السببي مع Transformer) لتحقيق إعادة بناء صوتية عالية الدقة. تُعالج هذه السلسلة من النماذج العديد من تحديات التطبيقات في السيناريوهات المعقدة، مُوفرةً مجموعة أدوات في مجال توليد الكلام يُمكن دمجها مباشرةً في عملية التأليف.
يعرض موقع HyperAI الإلكتروني الآن "MOSS-TTS: نموذج عالي الدقة لتوليد الكلام متعدد المشاهد". جربه!
الاستخدام عبر الإنترنت:https://go.hyper.ai/AtKvk
نظرة سريعة على تحديثات الموقع الرسمي لشركة hyper.ai من 2 مارس إلى 6 مارس:
* مجموعات البيانات العامة عالية الجودة: 3
* مجموعة مختارة من الدروس التعليمية عالية الجودة: 8
* تفسير مقالة المجتمع: 3 مقالات
* إدخالات الموسوعة الشعبية: 5
* أفضل المؤتمرات مع الموعد النهائي في مارس: 4
قم بزيارة الموقع الرسمي:هايبر.اي
مجموعات البيانات العامة المختارة
1. مجموعة بيانات الكشف الصوتي عن صوت الطائرات بدون طيار
تحتوي هذه المجموعة من البيانات على تسجيلات صوتية لفئتين: مجهولة وطائرات بدون طيار. صُممت هذه المجموعة خصيصًا لمهام التصنيف الصوتي الثنائي، بهدف الكشف عن أصوات الطائرات بدون طيار في بيئات واقعية. تُقدم الملفات الصوتية في هذه المجموعة بتنسيقات قياسية (مثل WAV)، مما يجعلها مناسبة لتقنيات المعالجة المسبقة، مثل استخراج مخطط ميل الطيفي، واستخراج ميزات MFCC، وتحويل فورييه قصير المدى (STFT)، ونماذج التعلم العميق للموجات الصوتية الخام.
الاستخدام المباشر:https://go.hyper.ai/vKHJC
2. مجموعة بيانات محاكاة التفاعلات الدوائية الضارة
صُممت هذه المجموعة من البيانات لمحاكاة تقارير اليقظة الدوائية المتعلقة بالتفاعلات الدوائية الضارة، وتهدف إلى دعم البحوث وتجارب التعلم الآلي وتطوير الخوارزميات في مجال مراقبة سلامة الأدوية. وتُنشأ تقارير سلامة الحالات (ICSRs) اصطناعياً، مستوحاة من أنظمة اليقظة الدوائية الواقعية مثل نظام الإبلاغ عن الأحداث الضائرة التابع لإدارة الغذاء والدواء الأمريكية (FDA FAERS) ونظام EudraVigilance التابع لوكالة الأدوية الأوروبية (EMA).
الاستخدام المباشر:https://go.hyper.ai/Jex4v
3. مجموعة بيانات أطلس النسخ الجيني للخلايا المفردة بتقنية تسلسل الحمض النووي الريبوزي أحادي الخلية (scRNA-Seq) الشاملة للسرطان
تحتوي هذه المجموعة من البيانات على بيانات التعبير الجيني لـ 7930 خلية مفردة، تغطي ثلاث حالات بيولوجية مختلفة: الحالة المناعية الأساسية السليمة، والورم السائل (سرطان الدم النخاعي)، والبيئة الدقيقة للورم الصلب (الورم الميلانيني). وتهدف إلى بناء معيار تحليل متكامل للخلايا المفردة عبر مجموعات متعددة، لتوفير معيار لتقييم أداء الخوارزميات والمقارنة المنهجية، وتصحيح تأثير الدُفعات متعددة المجموعات، وتحليل حالة الإنهاك المناعي، واستخراج المؤشرات الحيوية عبر أنواع الأورام المختلفة.
الاستخدام المباشر:https://go.hyper.ai/CnZTc
دروس تعليمية عامة مختارة
1. ACE-Step 1.5: عرض توضيحي لتوليد الموسيقى
يُعدّ ACE-Step 1.5 نموذجًا أساسيًا مفتوح المصدر لتوليد الموسيقى، تم إطلاقه بالاشتراك بين ACE Studio و StepFun، بهدف توسيع آفاق إمكانيات توليد الموسيقى مفتوحة المصدر. يستخدم هذا النموذج بنية توليد مبتكرة ثنائية المراحل، مما يحقق توليد محتوى موسيقي عالي الجودة وطويل المدة من خلال التكامل التعاوني بين مُحوِّل الانتشار (DiT) ونموذج اللغة (LM).
تشغيل عبر الإنترنت:https://go.hyper.ai/QZ6oi

2.Qwen3-ASR-1.7B: نظام التعرف على الكلام من الجيل الجديد
Qwen3-ASR هو جيل جديد من نماذج التعرف التلقائي على الكلام (ASR) مفتوحة المصدر، تم إطلاقه من قبل فريق تونغي تشيان وين في علي بابا كلاود. يعتمد هذا النموذج على نموذج Qwen3-Omni متعدد الوسائط، بالإضافة إلى مُشفِّر كلامي مطوّر ذاتيًا، ويركز على تحقيق دقة عالية، ودعم لغات متعددة، ومعالجة الصوت الطويل، وتوحيد إمكانيات تحويل الكلام إلى نص، سواءً كان متدفقًا أو غير متدفق. يستقبل النموذج إشارات صوتية خام كمدخلات، ثم يقوم بتحويلها مباشرةً إلى نص منظم من خلال بنية متكاملة، مع دعم محاذاة الطابع الزمني على مستوى الأحرف/الكلمات ومستوى أجزاء من الثانية. وهو مناسب للعديد من التطبيقات، مثل نسخ الاجتماعات، والترجمة الذكية، وأرشفة مكالمات خدمة العملاء الصوتية، والتفاعل الصوتي القائم على اللهجات.
تشغيل عبر الإنترنت:https://go.hyper.ai/zb0Vi

3.نشر vLLM+Open WebUI باستخدام Qwen3-Coder-Next
Qwen3-Coder-Next هو نموذج خفيف الوزن لتوليد الشفرة البرمجية، مفتوح المصدر، من تطوير تونغي تشيان وين من شركة Alibaba Cloud، ويركز على مهام مساعدة البرمجة وتوليد الشفرة البرمجية في جميع السيناريوهات. تتمثل مزاياه الأساسية في "الأداء العالي، وسهولة الاستخدام، وسهولة النشر". يعتمد النموذج على بنية Qwen3 المُحسّنة لنموذج اللغة الكبيرة، ويدمج بيانات مُدرّبة مسبقًا خاصة بمجال الشفرة البرمجية (تغطي أكثر من 80 لغة برمجة شائعة وأكثر من مليار مقطع برمجي) مع تحسين محاذاة الشفرة البرمجية باستخدام RLHF (التعلم المعزز بالتغذية الراجعة البشرية). وقد حقق أداءً متميزًا بين نماذج المصادر المفتوحة في ثلاثة معايير مرجعية موثوقة للشفرة البرمجية: HumanEval+ وMBPP وMultiPL-E، حيث يقترب أداؤه من أداء CodeLlama-70B. وهو مناسب لمختلف سيناريوهات البرمجة، بما في ذلك كتابة الخوارزميات، وتوليد شفرة الأعمال، والتعليق على الشفرة البرمجية، وتحويل الشفرة البرمجية بين اللغات، وإصلاح الأخطاء.
تشغيل عبر الإنترنت:https://go.hyper.ai/ukxPt
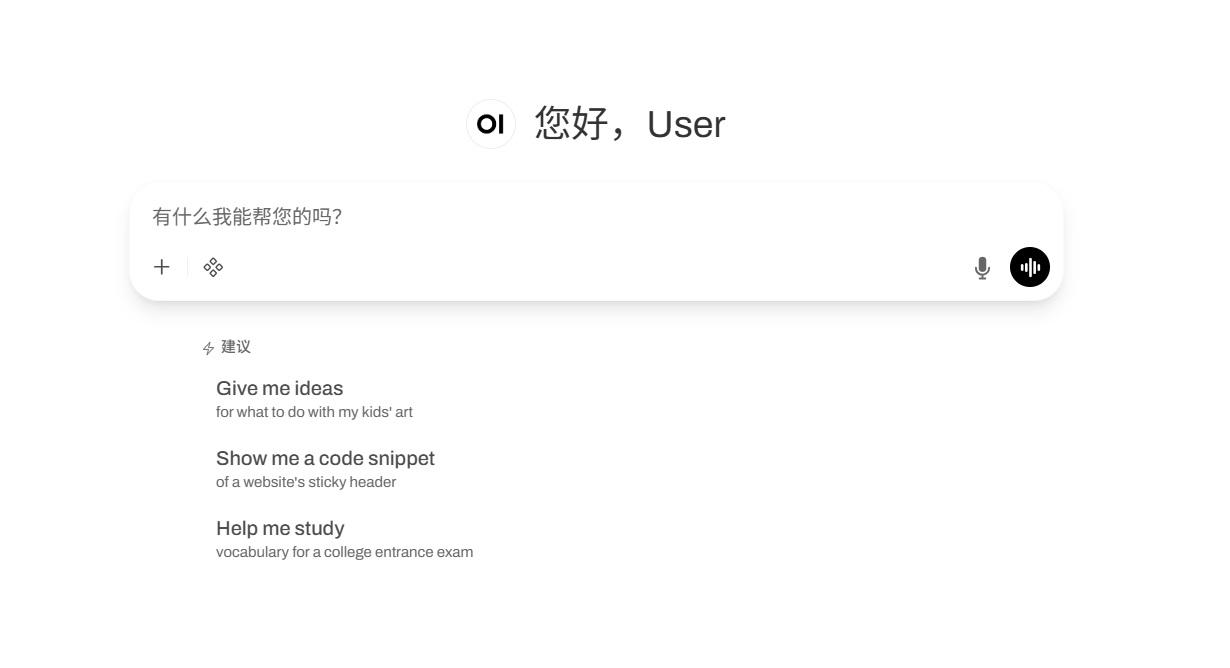
4. VibeVoice-ASR: عرض توضيحي متعدد الوظائف للتعرف على الكلام من البداية إلى النهاية
VibeVoice-ASR هو نموذج عالي الأداء ومتعدد الوظائف للتعرف على الكلام (ASR) من البداية إلى النهاية، وهو مفتوح المصدر من مايكروسوفت، ومصمم لتقديم خدمات تحويل الكلام إلى نص منظمة ومراعية للسياق للمحتوى الصوتي الطويل. يستخدم هذا النموذج بنية نمذجة صوتية موحدة متقدمة، قادرة على معالجة ملفات صوتية تصل مدتها إلى 60 دقيقة في المرة الواحدة. يدعم النموذج إنشاء مخرجات منظمة تحتوي على هوية المتحدث (Who) والطوابع الزمنية (When) والمحتوى المكتوب (What)، ويتيح للمستخدمين إضافة معلومات سياقية لتحسين دقة التعرف. تكمن أهم إنجازاته التقنية في قدراته الفعالة على نمذجة التسلسلات الطويلة وآلية التعلم متعدد المهام عبر اللغات، مما يحل تمامًا مشكلات المحاذاة الزمنية والترابط الدلالي التي تواجهها نماذج ASR التقليدية عند معالجة الملفات الصوتية الطويلة.
تشغيل عبر الإنترنت:https://go.hyper.ai/8eMFX
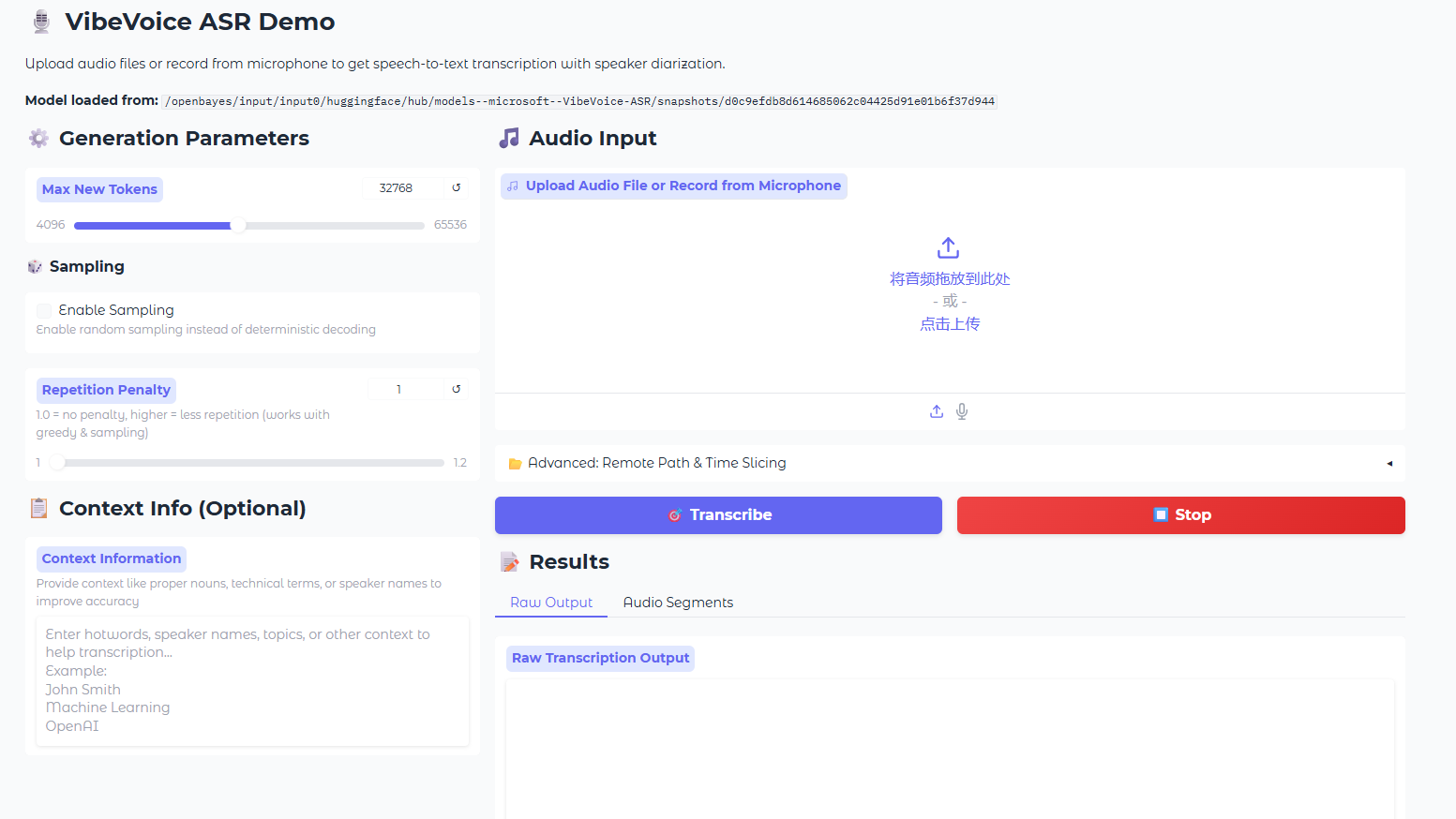
5. MOSS-TTS: نموذج عالي الدقة لتوليد الكلام متعدد المشاهد
سلسلة MOSS-TTS هي سلسلة نماذج مفتوحة المصدر لتوليد الكلام، أطلقتها MOSI.AI وفريق OpenMOSS. عندما يتطلب الأمر أن يبدو مقطع صوتي واحد شبيهاً بالصوت البشري، مع نطق دقيق لكل كلمة، وتغيير أنماط الكلام عبر محتوى مختلف، والحفاظ على استقرار الصوت لعشرات الدقائق، ودعم الحوار، ولعب الأدوار، والتفاعل الفوري، فإن نموذج تحويل النص إلى كلام واحد غالباً ما يكون غير كافٍ. لذلك، يفصل هذا المشروع عملية توليد الكلام إلى خمسة نماذج عالية الجودة يمكن استخدامها بشكل مستقل أو مجتمعة، بما في ذلك نموذج MOSS-TTS الأساسي، ونموذج MOSS-TTSD للحوار متعدد اللغات، ونموذج MOSS-VoiceGenerator لتصميم الصوت، ونموذج MOSS-SoundEffect لتوليد المؤثرات الصوتية، ونموذج MOSS-TTS-Realtime للتفاعل الفوري. تدعم هذه السلسلة 20 لغة وتتناول في المقام الأول تحديات التطبيقات الواقعية مثل استنساخ الكلام عالي الدقة بدون عينة، وتوليف النصوص الطويلة المستقرة لمدة تصل إلى ساعة واحدة، وتوليد متعدد اللغات ومختلط بين الصينية والإنجليزية، والتحكم الدقيق في مدة النطق ومستوى الصوتيات في السيناريوهات المعقدة.
تشغيل عبر الإنترنت:https://go.hyper.ai/AtKvk
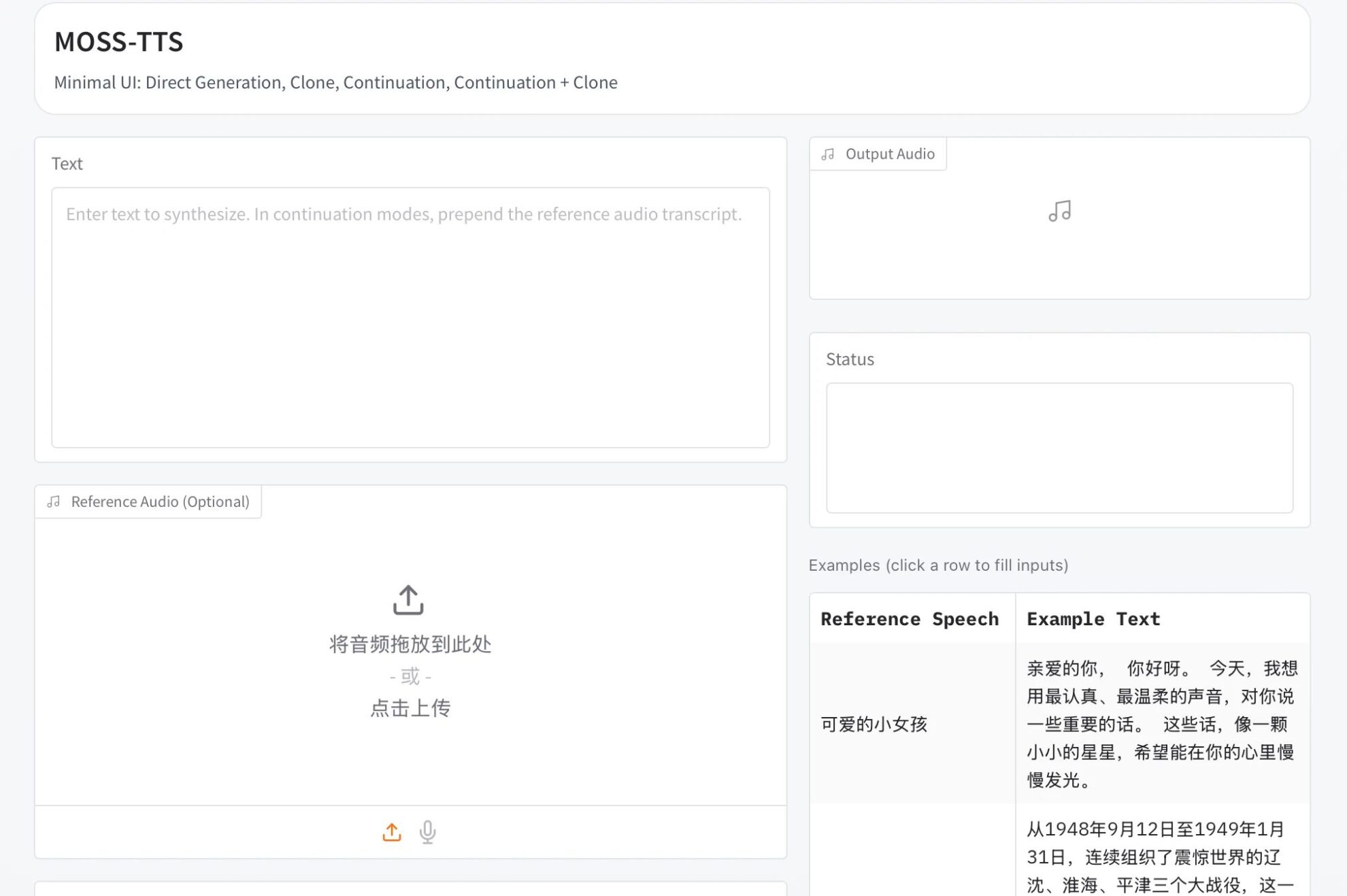
6.Z-Image: نموذج الصور النصي مفتوح المصدر من شركة علي بابا، ويحتوي على 6 مليارات مُعامل.
Z-Image هو جيل جديد من نماذج توليد الصور عالية الكفاءة، أطلقه فريق تونغي تشيان وين في علي بابا كلاود. بعد إصدار النسخة المُحسّنة Z-Image-Turbo، وتصدرها قائمة النماذج مفتوحة المصدر في مجال التحليل الاصطناعي، أطلق فريق Z-Image رسميًا النسخة القياسية Z-Image Standard كمصدر مفتوح. تُعد النسخة القياسية، وهي النموذج الأساسي لسلسلة Z-Image، نموذجًا متكاملًا غير مُحسّن، يتميز بجودة توليد صور عالية، وتنوع في الأنماط، ودعم تطوير ثانوي. وتهدف إلى تزويد مطوري المجتمع بأساس قوي ومرن لتوليد الصور، مما يفتح آفاقًا أوسع للتطوير المُخصّص والضبط الدقيق.
تشغيل عبر الإنترنت:https://go.hyper.ai/SsDMv
7. Qwen3-TTS: عرض توضيحي عالي الجودة وقابل للتحكم في توليف الكلام متعدد اللغات
يُعدّ Qwen3-TTS-12Hz-1.7B-CustomVoice جيلاً جديداً من نماذج تحويل النص إلى كلام (TTS) عالية الجودة، أطلقها فريق Alibaba Tongyi. يركز هذا النموذج على تحقيق توليف كلام متعدد اللغات، والتحكم في متحدثين متعددين (Custom Voice)، وتعديل أسلوب الكلام والعاطفة بناءً على النص، وتوليد كلام طبيعي للغاية ومنخفض التأخير، كل ذلك ضمن إطار عمل موحد. وبفضل اعتماده على إطار عمل للنمذجة الصوتية بتردد 12 هرتز و1.7 مليار مُعامل، يُظهر النموذج أداءً ممتازاً في وضوح الكلام، وتناسق النبرة، والاستقرار عبر اللغات. ومن خلال آلية CustomVoice، يستطيع النموذج التبديل مباشرةً بين المتحدثين المُعدّين مسبقاً خلال مرحلة الاستدلال دون الحاجة إلى تدريب إضافي، وبالاقتران مع تعليمات أسلوب اللغة الطبيعية، يُحقق تحكماً أكثر دقة في التعبير.
تشغيل عبر الإنترنت:https://go.hyper.ai/xWsQ6
8. نظام أسئلة وأجوبة الفيديو من FoundationMotion
FoundationMotion هو نظام لفهم الفيديو والإجابة على الأسئلة، طُوّر بالتعاون بين NVIDIA وMIT، ويعتمد على تقنية Qwen2.5-VL المُحسّنة. يهدف النظام إلى فهم الحركة المكانية في مقاطع الفيديو وتحليلها. وبفضل دمج تقنية التدريب المسبق للغة المرئية، يستطيع النموذج تحليل محتوى الفيديو المُحمّل بذكاء والإجابة على الأسئلة ذات الصلة.
تشغيل عبر الإنترنت:https://go.hyper.ai/JlGZk
تفسير مقالة المجتمع
1. تجاوز قيود التكامل متعدد الوسائط التقليدي! يقترح معهد ماساتشوستس للتكنولوجيا إطار عمل أبولو، الذي يحقق فصلاً واضحاً بين المعلومات المشتركة بين الخلايا والمعلومات الخاصة بكل خلية.
مع التطور المستمر لتقنية الخلايا المفردة والنمو السريع لحجم البيانات، أصبح دمج البيانات متعددة الوسائط بكفاءة وتلقائية، مع الفصل الواضح بين المعلومات المشتركة والمعلومات الخاصة بكل وسيط، تحديًا أساسيًا يواجه علم الأحياء الخلوي المفرد. ولمعالجة هذا التحدي، اقترح فريق بحثي مشترك من معهد ماساتشوستس للتكنولوجيا (MIT) والمعهد الفدرالي السويسري للتكنولوجيا في زيورخ (ETH Zurich) إطار عمل حاسوبي عام للتعلم العميق، يُسمى APOLLO (المشفّر التلقائي ذو الفضاء الكامن المتداخل جزئيًا والمتعلم من خلال التحسين الكامن). يوفر هذا الإطار مسارًا تقنيًا عمليًا لتحليل أكثر شمولًا ودقة لحالات الخلايا ومنطقها التنظيمي، وذلك من خلال نمذجة المعلومات المشتركة والمعلومات الخاصة بكل وسيط بشكل صريح.
شاهد التقرير الكامل:https://go.hyper.ai/jaCKf
2. برنامج تعليمي عبر الإنترنت | استنادًا إلى 5 ملايين ساعة من بيانات الصوت، يحقق Qwen3-TTS استنساخ الصوت وضبطه بدقة في 3 ثوانٍ.
عندما يتجاوز الذكاء الاصطناعي التوليدي مجرد "توليد النصوص" ويبدأ فعلياً في "إنتاج الصوت"، يرتقي الكلام من مجرد قناة معلومات إلى وسيلة تعبير قابلة للبرمجة والتعديل. وفي هذا المسار التطوري التكنولوجي، يسعى الجيل الجديد من النماذج إلى تجاوز حدود تقنية تحويل النص إلى كلام التقليدية، ليس فقط من خلال السعي إلى دقة أعلى، بل أيضاً من خلال التركيز على التعميم متعدد اللغات والتحكم الدقيق. يعتمد برنامج Qwen3-TTS، الذي أطلقه فريق Qwen مؤخراً كمصدر مفتوح، على بنية نموذج لغوي ثنائي المسار، مما يتيح تحكماً دقيقاً في الكلام الناتج مع توليده في الوقت الفعلي.
شاهد التقرير الكامل:https://go.hyper.ai/eKr7T
3. قام معهد ماساتشوستس للتكنولوجيا بتطوير نموذج Pichia-CLM لتعلم "لغة" الحمض النووي للخميرة، مما قد يزيد من إنتاج البروتين الخارجي بما يصل إلى 3 أضعاف.
في الوقت الراهن، طُوّرت في الصناعة أدوات وأساليب متنوعة لتحسين الكودونات تعتمد على وحدات الكودونات المضيفة، إلا أن هذه الأساليب قد لا تُنتج باستمرار تركيبات عالية التعبير. في السنوات الأخيرة، ومع تطور الذكاء الاصطناعي، ولا سيما تقنية نمذجة التسلسل، بدأ الباحثون في التعامل مع تسلسلات الجينات كنوع من "اللغة"، ساعين إلى استخلاص القواعد الضمنية فيها من خلال أساليب مشابهة لمعالجة اللغة الطبيعية. في هذا السياق، اقترح فريق بحثي من معهد ماساتشوستس للتكنولوجيا نموذجًا لغويًا قائمًا على التعلم العميق، يُدعى Pichia-CLM، لتحسين الكودونات في المضيف الصناعي Pichia pastoris بهدف تحسين إنتاجية البروتينات المؤتلفة.
شاهد التقرير الكامل:https://go.hyper.ai/a4H2G
مقالات موسوعية شعبية
1. نموذج اللغة المرئي (VLM)
2. الشبكات الفائقة
3. الانتباه المُوجَّه
4. الإنسان في الحلقة (HITL)
5. مجال الإشعاع العصبي (NeRF)
فيما يلي مئات المصطلحات المتعلقة بالذكاء الاصطناعي التي تم تجميعها لمساعدتك على فهم "الذكاء الاصطناعي" هنا:
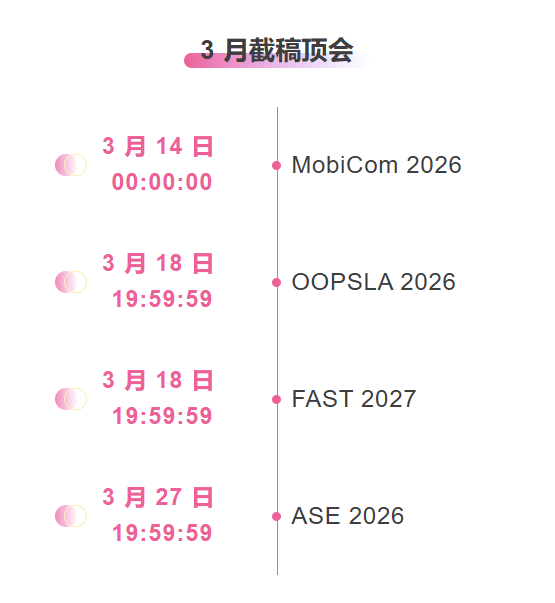
تتبع شامل لأفضل المؤتمرات الأكاديمية في مجال الذكاء الاصطناعي:https://go.hyper.ai/event
إن ما ورد أعلاه هو كل محتوى اختيار المحرر لهذا الأسبوع. إذا كان لديك موارد تريد تضمينها على الموقع الرسمي لـ hyper.ai، فنحن نرحب بك أيضًا لترك رسالة أو إرسال مقال لإخبارنا بذلك!
نراكم في الاسبوع القادم!








