Command Palette
Search for a command to run...
يتباهى Qwen3-Max بأكثر من تريليون معلمة، ويحقق SOTA على معايير متعددة، وإصدار معزز بالاستدلال المتوقع يحقق الدرجة المثالية في أولمبياد الرياضيات.

اليوم (24 سبتمبر)، افتُتح مؤتمر يونكي السنوي رسميًا. على هذه المنصة التي تُبرز فيها علي بابا كلاود قوتها، يُمثل الذكاء الاصطناعي بلا شك محور الاهتمام. من نماذج المصدر المفتوح إلى تطبيقات الوكلاء، إلى البنية التحتية كالخوادم ومنظومة المطورين، برهنت الشركة على قدرتها التنافسية التكنولوجية في هذه الجولة من منافسات الذكاء الاصطناعي.وفقًا لقائمة Hugging Face، وصل عدد النماذج المشتقة التي تم تطويرها بناءً على Tongyi Qianwen إلى 170 ألفًا، متجاوزًا سلسلة American Llama ويحتل المرتبة الأولى في العالم.
لعلّ متابعي علي بابا يعلمون أنه قبل يوم واحد فقط من افتتاح مؤتمر يونتشي، كان فريق تونغيي للنماذج الكبيرة التابع لشركة علي بابا قد أطلق ثلاثة نماذج عالية الأداء مفتوحة المصدر - النموذج الكبير متعدد الوسائط الأصلي Qwen3-Omni، ونموذج توليد الكلام Qwen3-TTS، ونموذج تحرير الصور Qwen-Image-Edit-2509. وقد حققت جميعها أداءً يُضاهي النماذج السائدة، بل وحتى مستوى SOTA، في مجالاتها.
يبدو الآن أن هذه مجرد مُقدّمات. في حفل افتتاح مؤتمر يونكي الذي اختتم مؤخرًا، كُشف النقاب رسميًا عن Qwen3-Max. ويُقال إن هذا الطراز هو الأكبر والأقوى حتى الآن. بإجمالي قوة دفع تبلغ 1T، تفوق على العديد من معايير التقييم. بالإضافة إلى ذلك،كما قدم المؤتمر نماذج مثل Qwen3-VL و Qwen3-Coder.
Qwen3-Max: الأكبر والأقوى حتى الآن
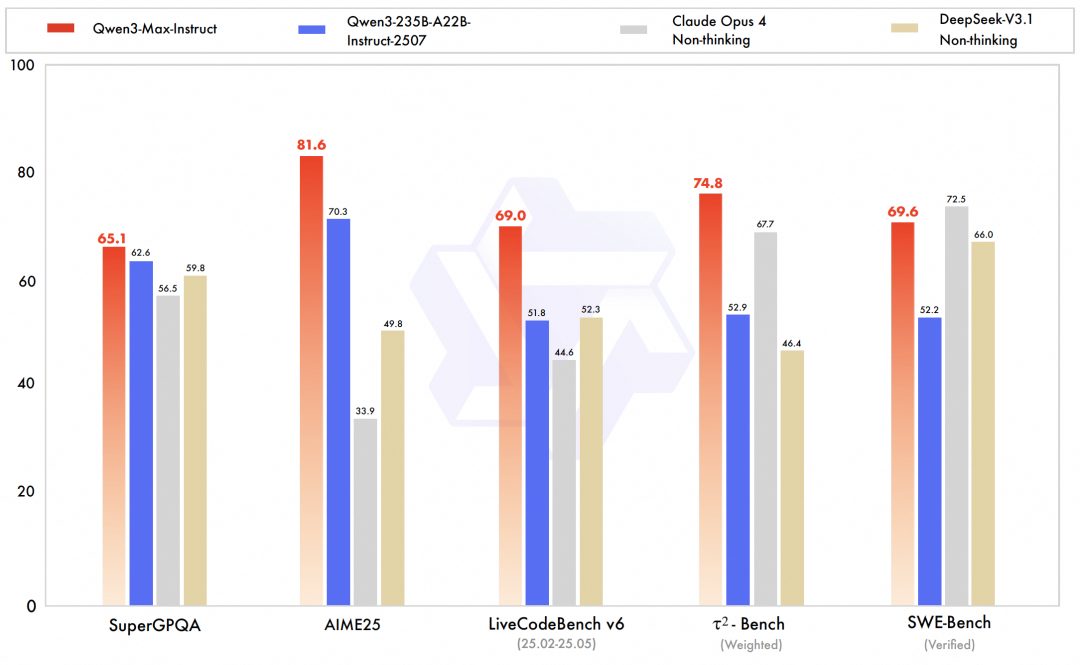
يُعدّ Qwen3-Max أبرز ما في هذا الإصدار بلا منازع. بصفته أكبر وأكفأ نموذج للفريق حتى الآن، احتلّت النسخة التجريبية من Qwen3-Max-Instruct المركز الثالث في قائمة LMArena النصية، متجاوزةً GPT-5-Chat.يعمل الإصدار الرسمي على تحسين قدرات الكود وقدرات الوكيل بشكل أكبر، حيث يصل إلى مستوى SOTA في اختبارات معيارية شاملة تغطي المعرفة، والتفكير، والبرمجة، واتباع التعليمات، ومواءمة التفضيلات البشرية، ومهام الوكيل الذكي، وفهم اللغات المتعددة.على سبيل المثال، في معيار SWE-Bench Verified، الذي يُركز على حل تحديات البرمجة الواقعية، حقق Qwen3-Max-Instruct درجة ممتازة بلغت 69.6 نقطة. وفي معيار Tau2-Bench، الذي يُقيّم قدرات استدعاء الأدوات للوكلاء الأذكياء، تفوق Qwen3-Max-Instruct على Claude Opus 4 وDeepSeek-V3.1 بنتيجة 74.8 نقطة.
على وجه التحديد، يتجاوز إجمالي معلمات نموذج Qwen3-Max 1T، ويتم استخدام 36T رمزًا للتدريب المسبق.تتبع بنية النموذج تصميم نموذج MoE لسلسلة Qwen3، وتستخدم خسارة موازنة الأحمال على دفعات عالمية، مما يضمن خسارة ثابتة وسلسة قبل التدريب. التدريب سلس، دون أي طفرات أو تعديلات في الخسارة، مثل التراجع عن التدريب أو تغييرات في توزيع البيانات.
وفقًا للإعلان الرسمي، وبفضل تحسين استراتيجية التوازي الفعال متعدد المراحل لخط أنابيب PAI-FlashMoE، تحسنت كفاءة تدريب Qwen3-Max-Base بشكل ملحوظ، كما تحسنت وحدة MFU الخاصة به بمقدار 30% مقارنةً بـ Qwen2.5-Max-Base. في سيناريو التدريب المتسلسل الطويل، استخدم الفريق استراتيجية ChunkFlow لتحقيق إنتاجية أعلى بثلاث مرات من حل التوازي المتسلسل، مما يدعم تدريب سياق Qwen3-Max الطويل بطول مليون نقطة. في الوقت نفسه، ومن خلال وسائل متنوعة مثل SanityCheck وEasyCheckpoint وتحسين رابط الجدولة،يتم تقليل خسارة الوقت الناجمة عن فشل الأجهزة في Qwen3-Max على مجموعة واسعة النطاق إلى خمس ما في Qwen2.5-Max.
ومن الجدير بالذكر أنه على الرغم من أن النسخة المعززة للتفكير المنطقي من Qwen3-Max Qwen3-Max-Thinking لم يتم الإعلان عنها رسميًا، وفقًا للبيانات التي أصدرها الفريق، فإن قدراتها على التفكير المنطقي العميق وصلت إلى مستوى جديد، حيث حققت الدرجات الكاملة في معايير التفكير الرياضي الصعبة للغاية AIME 25 و HMMT، وحتى الوصول إلى الدرجات الكاملة في مسابقة الرياضيات الأولمبية.
Qwen3-VL-235B: تحديث SOTA والحصول على المرتبة الأولى في العالم
Qwen3-VL هو فرع من نماذج الرؤية واللغة متعددة الوسائط (VLM) ضمن سلسلة Qwen3. يهدف إلى تحقيق توازن وتطور كبير بين قدرات الفهم البصري وقدرات توليد النصوص. يصفه الفريق بأنه أقوى نموذج رؤية ولغة في سلسلة Qwen حتى الآن. يُظهر Qwen3-VL تحسينات ملحوظة في فهم النصوص الخالصة وتوليدها، وإدراك المحتوى البصري والتفكير فيه، ودعم طول السياق، وفهم العلاقات المكانية والفيديو الديناميكي، وحتى في أدائه أثناء تفاعلات الوكلاء.
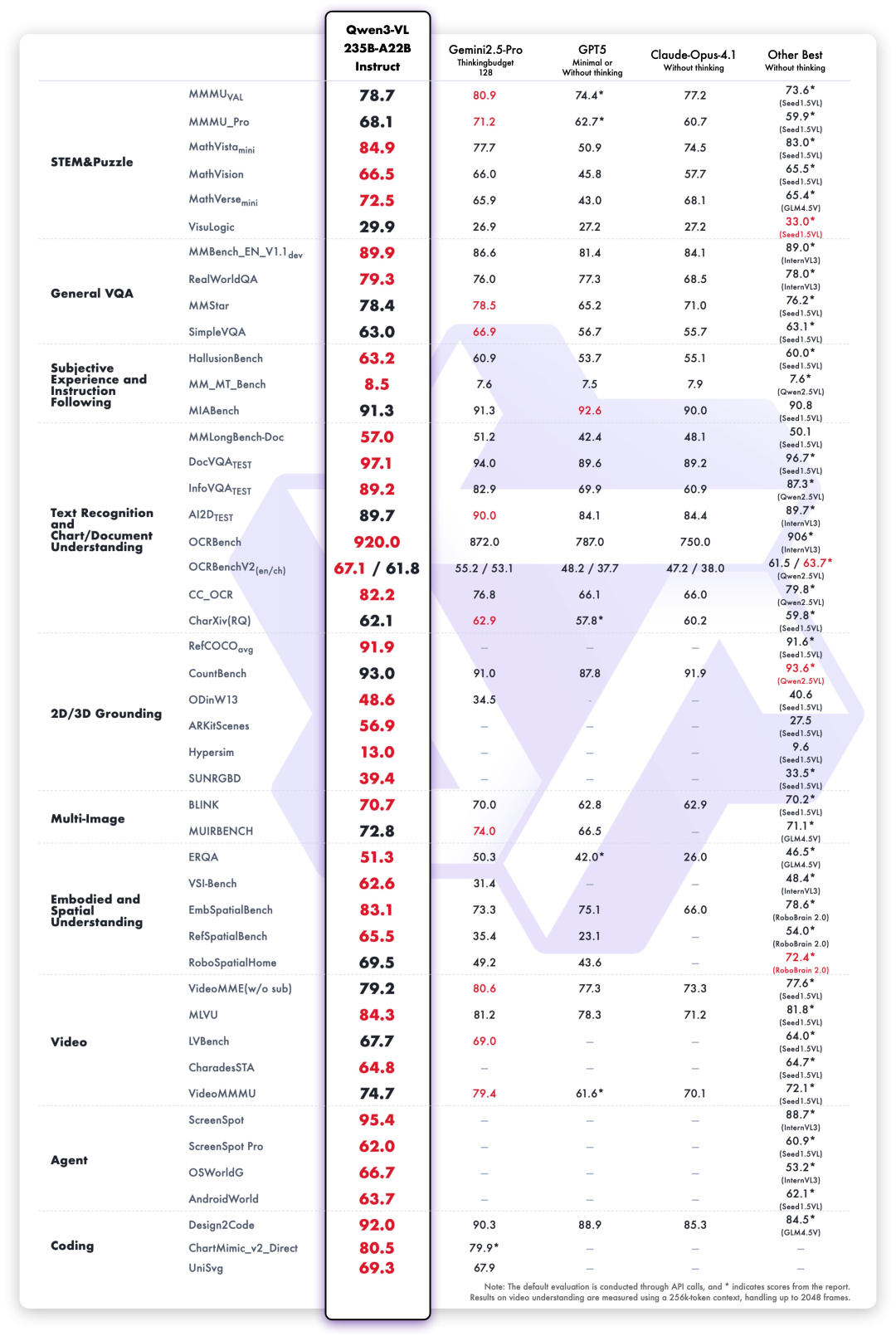
تم تصنيف الطراز الرائد الجديد مفتوح المصدر Qwen3-VL-235B الذي تم إصداره هذه المرة في المرتبة الأولى في العالم من حيث الأداء العام، وقد حسن أداءه بشكل كبير في الصور المعقدة عالية الدقة ومشاهد التعرف الدقيقة.يتضمن كلا من الإصدارين Instruct وThinking.
في إطار تقييم 10 أبعاد تشمل الأسئلة الجامعية الشاملة، والتفكير الرياضي والعلمي، والألغاز المنطقية، والإجابة على الأسئلة البصرية العامة، والخبرة الذاتية واتباع التعليمات، والتعرف على النصوص متعددة اللغات، وتحليل مستندات المخططات،يؤدي Qwen3-VL-235B-A22B-Instruct أفضل أداء في معظم المؤشرات بين النماذج غير الاستدلالية.إنه يتفوق بشكل كبير على النماذج المغلقة المصدر مثل Gemini 2.5 Pro و GPT-5، في حين يقوم بتحديث أفضل نتائج النماذج المتعددة الوسائط مفتوحة المصدر، مما يدل على قدرته القوية على التعميم والأداء الشامل في المهام المرئية المعقدة.
على وجه التحديد، خضعت Qwen3-VL لترقيات منتظمة في أبعاد متعددة للقدرات الرئيسية:
الوكيل المرئي:يستطيع Qwen3-VL تشغيل واجهات الحاسوب والهواتف المحمولة، وتحديد عناصر واجهة المستخدم الرسومية، وفهم وظائف الأزرار، واستدعاء الأدوات، وتنفيذ المهام. وقد حقق مستويات رائدة عالميًا في معايير مثل OS World، ويمكنه تحسين أدائه بفعالية في مهام الإدراك الدقيقة من خلال استدعاء الأدوات.
تتنافس إمكانيات النص العادي مع تلك الموجودة في نماذج اللغة العليا:يستخدم Qwen3-VL مزيجًا من النصوص والوسائط المرئية للتدريب التعاوني في المراحل الأولى من التدريب المسبق، مما يُعزز قدراته النصية باستمرار. في النهاية، يُضاهي أداءه في مهام النصوص الصرفة أداء نموذج النصوص الصرفة الرائد Qwen3-235B-A22B-2507. إنه نموذج لغة بصرية من الجيل التالي، يتميز بأساس نصي متين وتعدد استخدامات متعدد الوسائط.
تم تحسين قدرات الترميز المرئي بشكل كبير:نفّذ كود توليد الصور والفيديو. على سبيل المثال، عند رؤية رسم تصميمي، يُولّد الكود كود Draw.io/HTML/CSS/JS، مُطبّقًا بذلك مبدأ "ما تراه هو ما تحصل عليه" في البرمجة المرئية.
تم تحسين القدرة على الإدراك المكاني بشكل كبير:يتغير التأريض ثنائي الأبعاد من إحداثيات مطلقة إلى إحداثيات نسبية، مما يدعم تقدير اتجاه الأجسام، وتغيرات المنظور، وعلاقات التداخل. ويمكنه تحقيق تأريض ثلاثي الأبعاد، ووضع الأساس للاستدلال المكاني والمشاهد المجسدة في سيناريوهات معقدة.
دعم السياق الطويل وفهم الفيديو الطويل:تدعم عائلة النماذج بأكملها، بشكل أصلي، طول سياق يبلغ ٢٥٦ ألف رمز، ويمكن توسيعها إلى مليون رمز. هذا يعني أنه سواءً كان مستندًا تقنيًا من مئات الصفحات، أو كتابًا دراسيًا كاملًا، أو فيديو مدته ساعتان، يُمكن إدخاله بالكامل وحفظه بالكامل واسترجاعه بدقة، مما يدعم تحديد الفيديو بدقة متناهية.
تم تعزيز القدرة على التفكير المتعدد الوسائط بشكل كبير:يُعطي نموذج التفكير الأولوية لمهارات العلوم والتكنولوجيا والهندسة والرياضيات (STEM) والتفكير الرياضي. عند مواجهة أسئلة متخصصة، يُركز النموذج على التفاصيل، ويكشف التعقيدات، ويُحلل العلاقة بين السبب والنتيجة، ويُقدم إجابات منطقية وواضحة. وقد حقق أداءً رائدًا في تقييمات موثوقة مثل MathVision وMMMU وMathVista.
تم ترقية قدرات الإدراك البصري والتعرف بشكل شامل: من خلال تحسين جودة واتساع بيانات ما قبل التدريب، يمكن للنموذج الآن التعرف على مجموعة أكثر ثراءً من فئات الكائنات - من المشاهير وشخصيات الأنمي والسلع والمعالم إلى النباتات والحيوانات، وتغطية احتياجات "التعرف على كل شيء" في الحياة اليومية والمجالات المهنية.
يدعم OCR المزيد من اللغات والسيناريوهات المعقدة:تم توسيع عدد اللغات المدعومة بخلاف الصينية والإنجليزية من 10 إلى 32 لغة، لتغطي المزيد من البلدان والمناطق؛ كما أصبح الأداء أكثر استقرارًا في سيناريوهات التصوير الواقعية الصعبة مثل الإضاءة المعقدة والضبابية والميل؛ كما تم تحسين دقة التعرف على الأحرف النادرة والشخصيات القديمة والمصطلحات المهنية بشكل كبير؛ وتم تعزيز القدرة على فهم المستندات الطويلة للغاية واستعادة الهياكل الدقيقة بشكل أكبر.
Qwen3 Coder Plus:كفاءة البرمجةأعلى وأكثر دقة
باعتباره نموذج الترميز الحصري لسلسلة Qwen3، يُعدّ Qwen3 Coder ترقية شاملة للجيل السابق من Coder. يعتمد على واجهة برمجة تطبيقات مغلقة المصدر لتوفير كفاءة ودقة برمجة أعلى. وقد أصبح من أشهر نماذج البرمجة عالميًا، ويحظى بإعجاب واسع من المطورين.
تم إصدار Qwen3 Coder Plus هذه المرة وهو إصدار خاص من Qwen3 Coder 480B A35B مفتوح المصدر من Alibaba.باعتباره نموذجًا قويًا لوكيل الترميز، فهو يتفوق في البرمجة المستقلة من خلال استدعاءات الأدوات والتفاعلات البيئية، من خلال الجمع بين قدرات الترميز ومجموعة متنوعة من القدرات العامة.
أهم النقاط الفنية:
* التدريب المشترك مع أنظمة Qwen Code وClaude Code يحسن أداء تطبيق CLI بشكل كبير
* سرعة تفكير أسرع وتنفيذ مهام أكثر كفاءة * تحسين أمان الكود، والانتقال نحو الذكاء الاصطناعي المسؤول
أطلق الموقع الرسمي لـ HyperAI Hyperneural (hyper.ai) عددًا من دروس النماذج مفتوحة المصدر عالية الجودة، استنادًا إلى فريق Tongyi Qianwen. جرّب رابط البرنامج التعليمي للنشر بنقرة واحدة: https://hyper.ai/tutorials








