Command Palette
Search for a command to run...
برنامج تعليمي عبر الإنترنت: تحديث نموذج TTS SOTA، يتم تدريب OpenAudio S1 على أساس 2 مليون ساعة من بيانات الصوت، مما يؤدي إلى فهم عميق للمشاعر وتفاصيل الكلام

في السنوات الأخيرة، خضع نموذج تحويل النص إلى كلام (TTS) لتكرارات، بدءًا من تركيب الكلام المتسلسل، مرورًا بتركيب المعلمات الإحصائية، وصولًا إلى الشبكة العصبية TTS. وقد أظهر هذا النموذج توجهًا نحو دمج شامل للوحدات على المستوى التقني، وأظهر تأثيرًا متطورًا لتعدد اللغات، والوضوح العالي، والتغييرات العاطفية الغنية على مستوى التطبيق.
مع الاستخدام الواسع النطاق لنماذج TTS في المساعدين الصوتيين الافتراضيين والبشر الرقميين والدبلجة بالذكاء الاصطناعي وخدمة العملاء الذكية وغيرها من المجالات، يتزايد الطلب في الصناعة على ردود الفعل في الوقت الفعلي تدريجيًا.ثم تأتي المقايضة بين سرعة الاستدلال ومعلمات النموذج.ويحد الأخير، إلى حد ما، من تكلفة النشر وسيناريوهات التطبيق لنموذج TTS.
وفي ضوء ذلك،أطلقت شركة Fish Audio نموذج TTS جديد مفتوح المصدر، OpenAudio S1.يتضمن البرنامج نسختين: OpenAudio-S1 وOpenAudio-S1-mini. ووفقًا للوثائق الرسمية، تم تدريب OpenAudio S1 على قاعدة بيانات واسعة النطاق تضم أكثر من مليوني ساعة صوتية. وقد وسّع الفريق معلمات النموذج إلى 4 مليارات، وقدم آلية نمذجة مكافآت ذاتية التطوير. وفي الوقت نفسه، طبّق الفريق أيضًا التعلم التعزيزي القائم على تدريب التغذية الراجعة البشرية (RLHF، باستخدام طريقة GRPO).
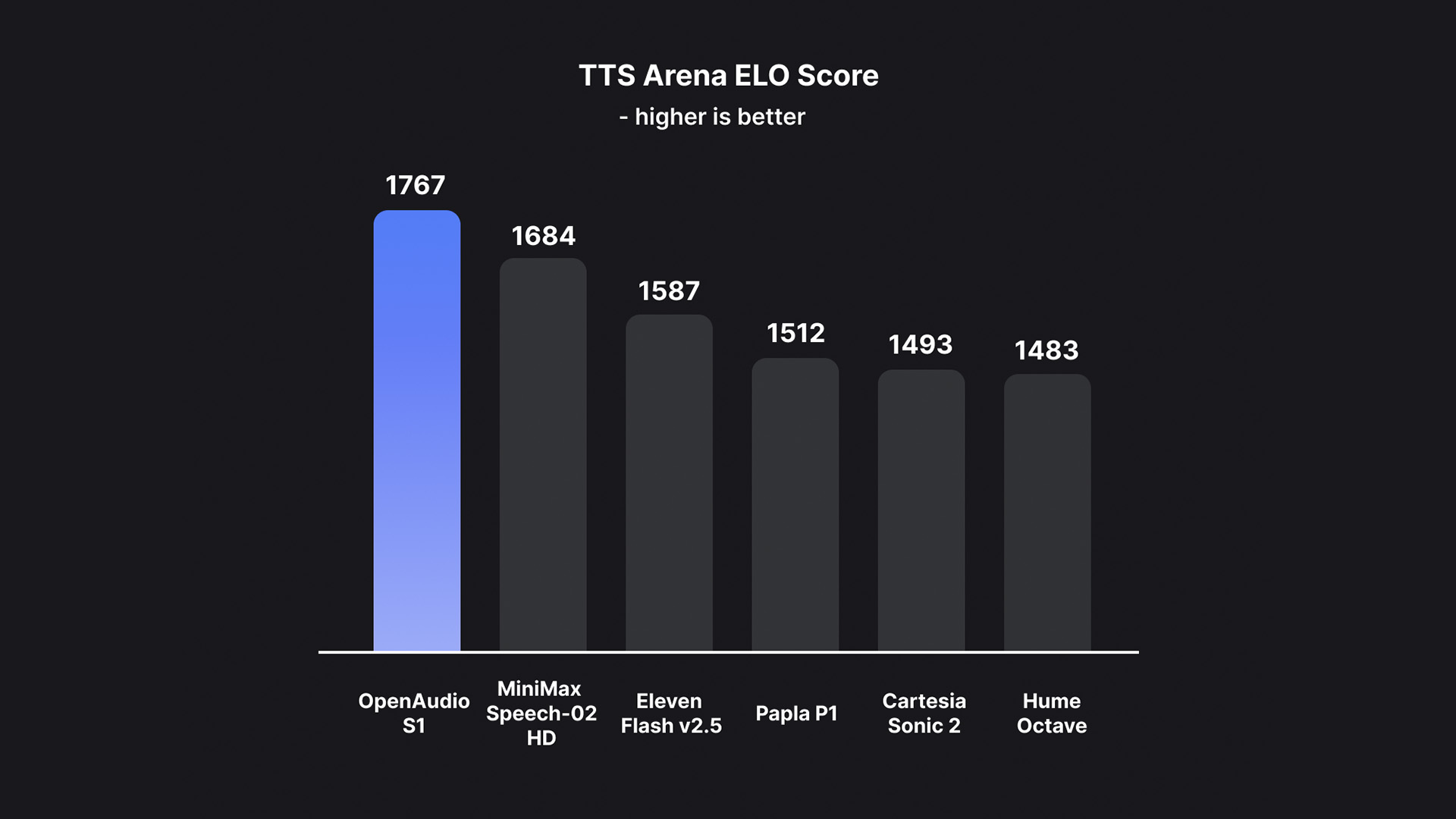
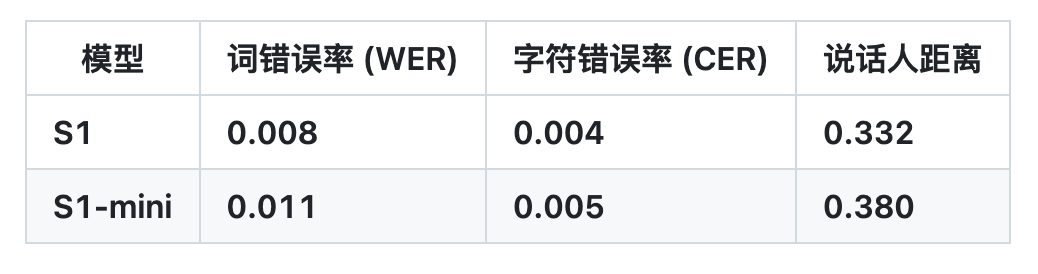
وبناءً على ذلك، نجح OpenAudio S1 في التخلص من الآثار والمفردات غير الصحيحة الناجمة عن فقدان المعلومات عندما تستخدم معظم النماذج الأخرى نماذج دلالية فقط، وبالتالي تجاوز النماذج السابقة من حيث جودة الصوت والتعبير العاطفي وتشابه المتحدث.من الممكن إنشاء مخرجات TTS عالية الجودة باستخدام 10 إلى 30 ثانية فقط من إدخال عينة الكلام.لقد تصدرت حاليًا تصنيفات التقييم الذاتي البشري HuggingFace TTS-Arena-V2، محققة معدل خطأ منخفض في الأحرف (CER) يبلغ حوالي 0.4% ومعدل خطأ في الكلمات (WER) يبلغ حوالي 0.8% على Seed-TTS Eval.
وفقا للفريق،ما يجعل OpenAudio S1 فريدًا حقًا هو قدرته على فهم والتعبير بشكل عميق عن المشاعر الإنسانية وتفاصيل الكلام.يدعم هذا النظام مجموعةً غنيةً من العلامات للتحكم الدقيق في الكلام المُركَّب. ولتدريب نموذج تحويل النص إلى كلام على اتباع التعليمات، طوّر الفريق أيضًا نموذجًا لتحويل الكلام إلى نص (سيُصدر قريبًا) يُمكّن من إنشاء ترجمات صوتية تحتوي على مشاعر، وتجويد، ومعلومات عن المتحدث، وغيرها. وقد تم شرح أكثر من 100,000 ساعة صوتية عشوائيًا بناءً على هذا النموذج لتدريب OpenAudio S1.
لهذا السبب، يدعم OpenAudio S1 العديد من المشاعر، والنغمات، والعلامات الخاصة لتحسين تركيب الكلام. بالإضافة إلى المشاعر الأساسية كالغضب والمفاجأة والسعادة، يدعم أيضًا المشاعر المتقدمة كالازدراء والسخرية والتردد. أما فيما يتعلق بالنغمات، فهو يدعم الهمس والصراخ والبكاء، وغيرها. أما بالنسبة للغة، فهو يدعم حاليًا اللغات الإنجليزية والصينية واليابانية.
والأمر الأكثر أهمية هو أنه فيما يتعلق بالتوازن بين الأداء وتكلفة النشر،يزعم الفريق أن هذا هو أول نموذج SOTA بتكلفة 15 دولارًا فقط لكل مليون بايت ($15/مليون بايت، أي حوالي 0.8 دولارًا في الساعة).
لكي يتمكن الجميع من تجربة الأداء القوي لـ OpenAudio S1 بشكل أسرع،أطلق الآن قسم البرامج التعليمية في الموقع الرسمي لشركة HyperAI (hyper.ai) "OpenAudio-s1-mini: أداة فعالة لتحويل النص إلى كلام".
رابط البرنامج التعليمي:https://go.hyper.ai/rVvkS
لقد أعددنا أيضًا مزايا استخدام موارد RTX 4090 مجانًا للمستخدمين المسجلين حديثًا. استخدم رمز الدعوة أدناه للتسجيل واحصل على فرصة تجربة نماذج TTS عالية الجودة مجانًا.
رابط دعوة حصرية لـ HyperAI (انسخ وافتح في المتصفح):
https://openbayes.com/console/signup?r=Ada0322_NR0n
تشغيل تجريبي
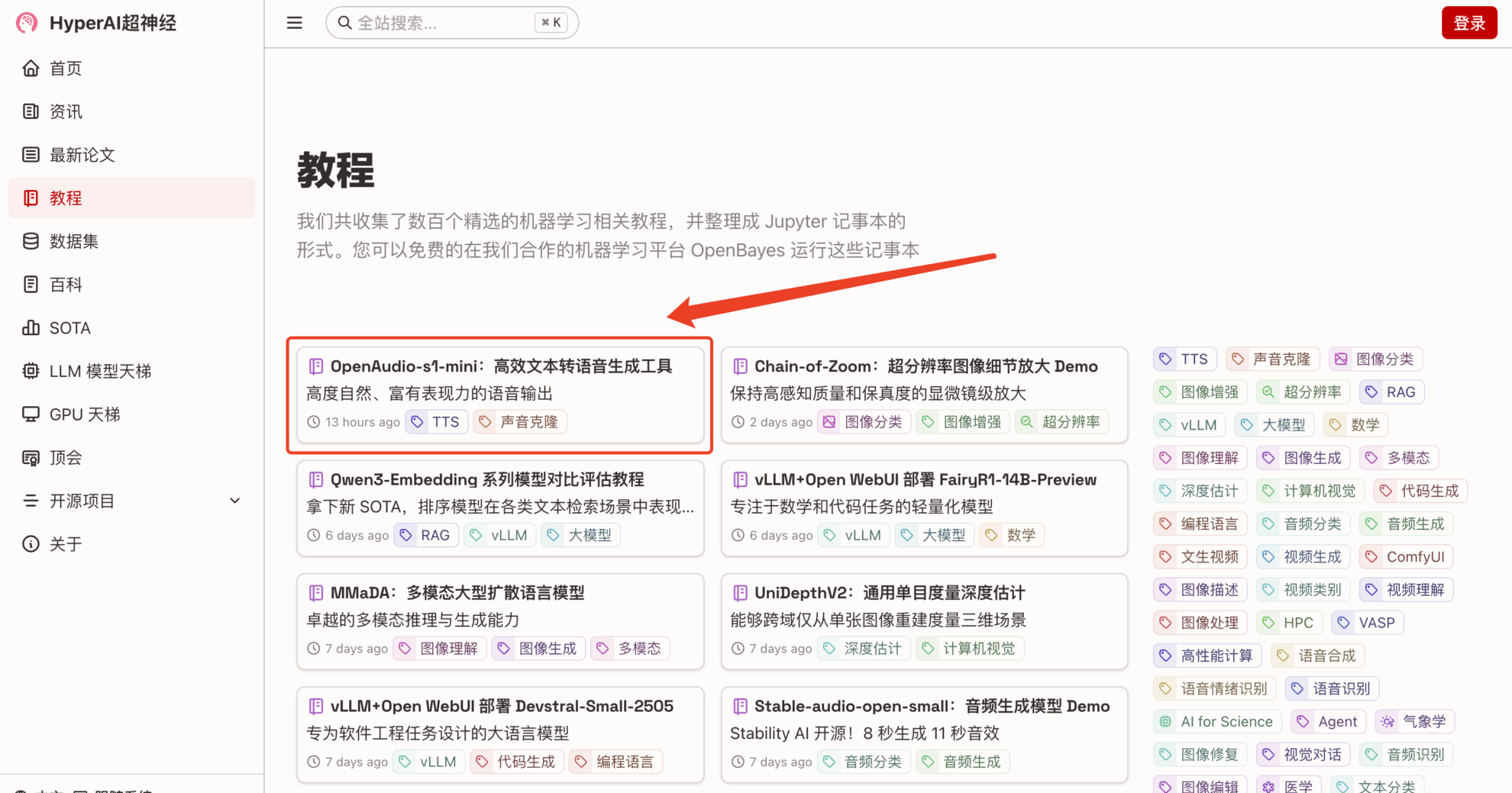
1. بعد الدخول إلى الصفحة الرئيسية لـ hyper.ai، حدد صفحة "البرنامج التعليمي"، ثم حدد "OpenAudio-s1-mini: أداة فعالة لتوليد النص إلى كلام"، وانقر فوق "تشغيل هذا البرنامج التعليمي عبر الإنترنت".
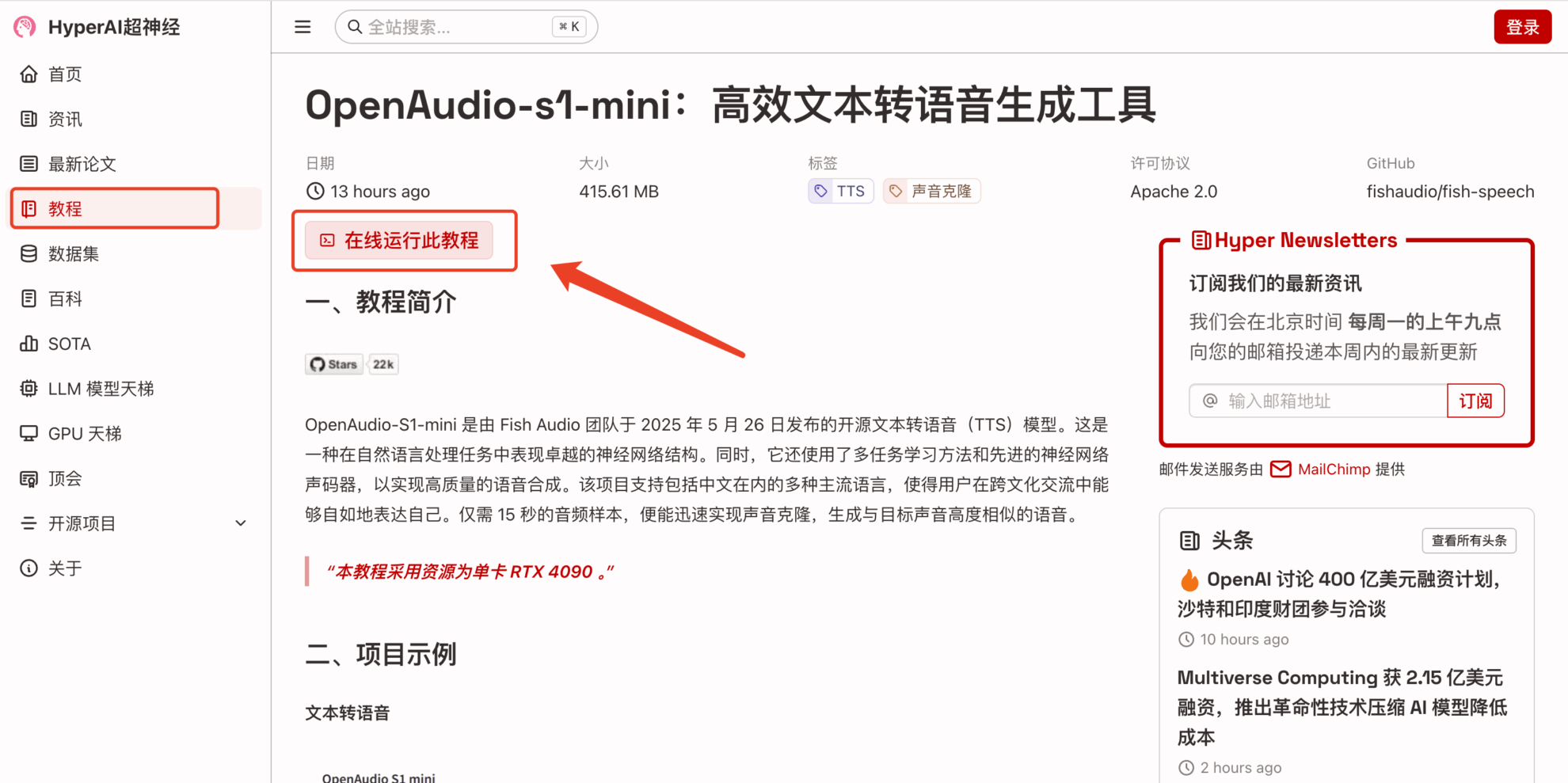
2. بعد الانتقال إلى الصفحة التالية، انقر فوق "استنساخ" في الزاوية اليمنى العليا لاستنساخ البرنامج التعليمي في الحاوية الخاصة بك.
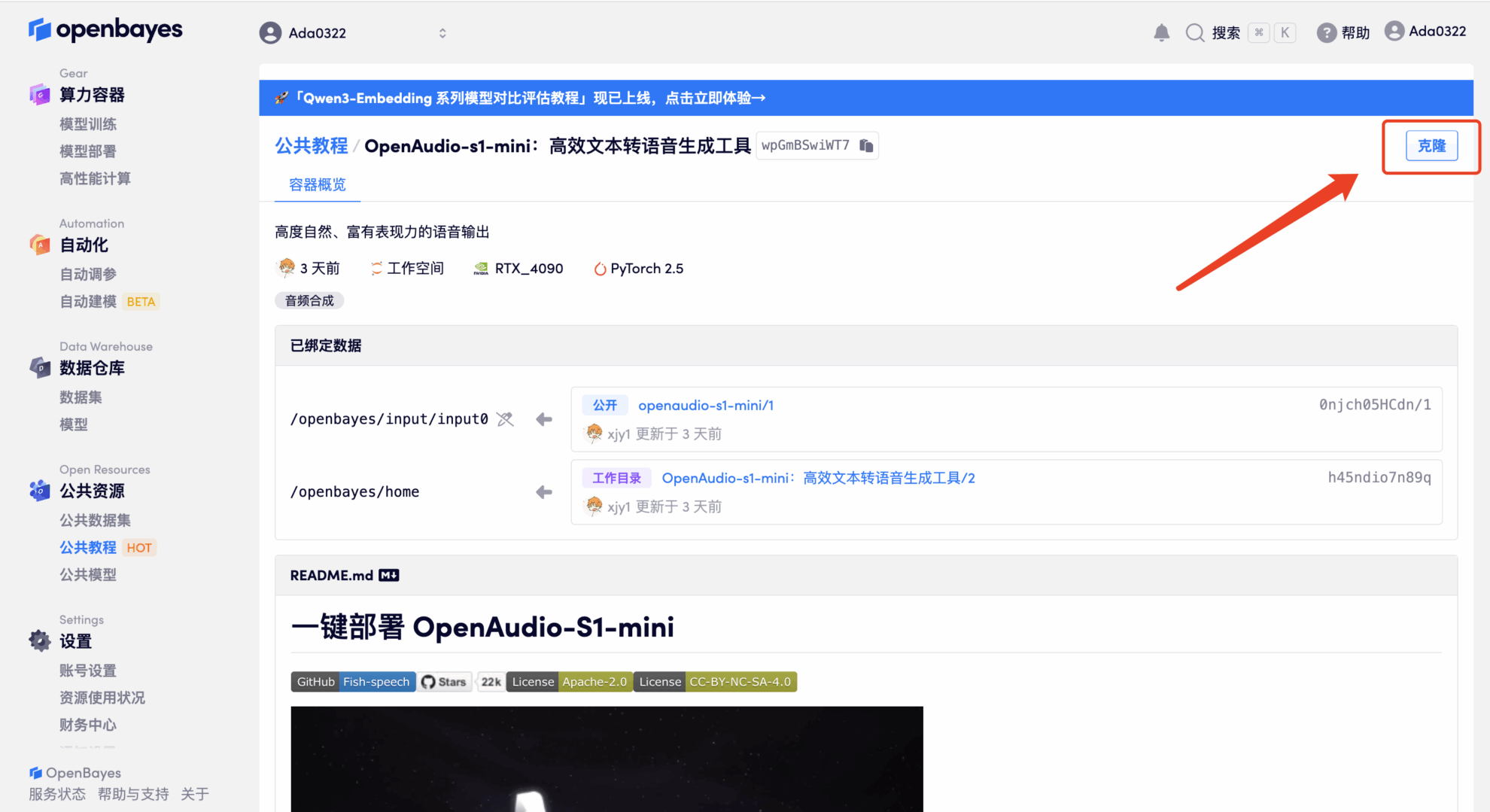
٣. اختر صورتي "NVIDIA RTX 4090" و"PyTorch". توفر منصة OpenBayes أربع طرق دفع. يمكنك اختيار "الدفع الفوري" أو "الدفع يوميًا/أسبوعيًا/شهريًا" حسب احتياجاتك. انقر على "متابعة". يمكن للمستخدمين الجدد التسجيل باستخدام رابط الدعوة أدناه للحصول على ٤ ساعات من بطاقة RTX 4090 + ٥ ساعات من وقت فراغ المعالج!
رابط دعوة حصرية لـ HyperAI (انسخ وافتح في المتصفح):
https://openbayes.com/console/signup?r=Ada0322_NR0n
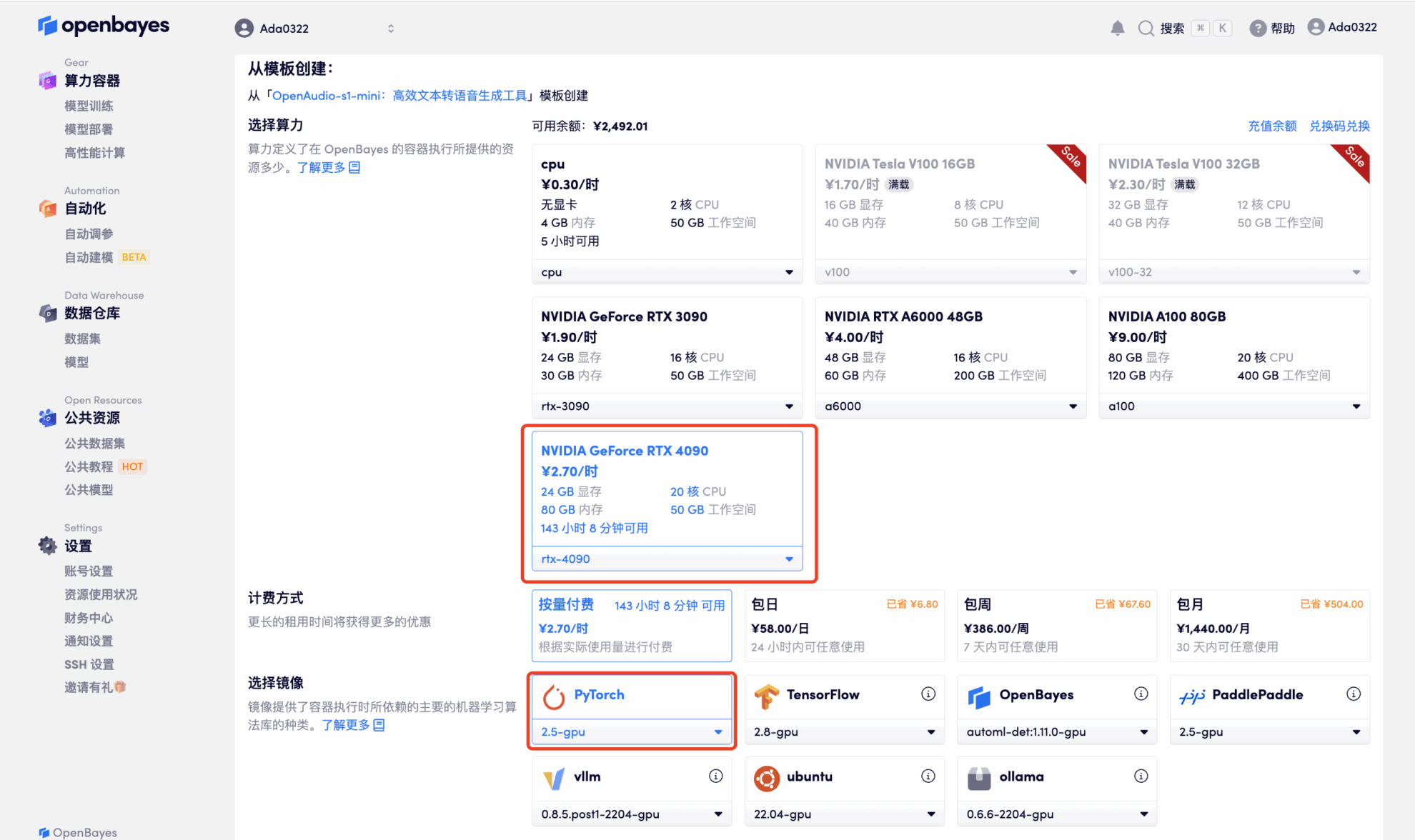
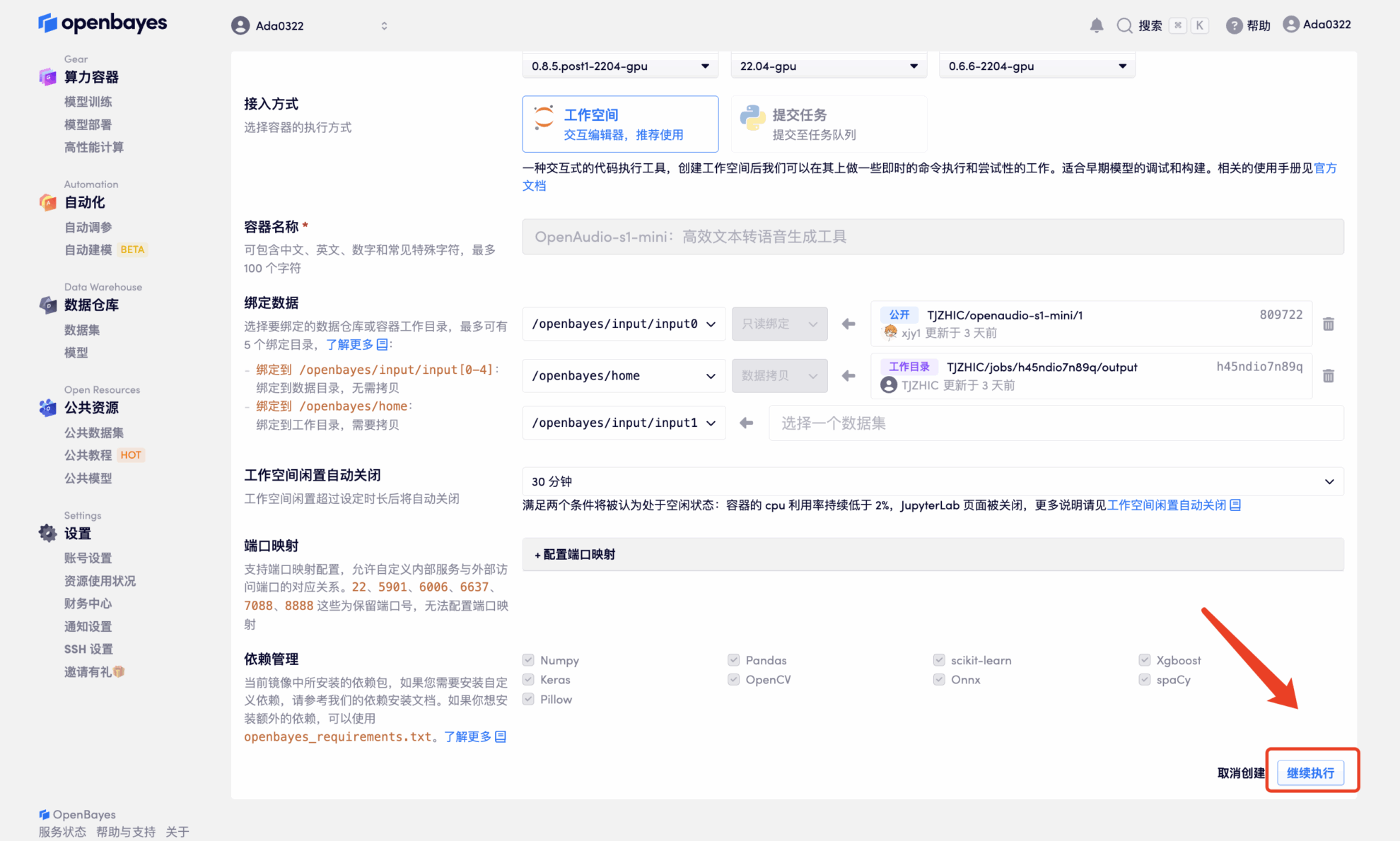
4. انتظر حتى يتم تخصيص الموارد. تستغرق عملية الاستنساخ الأولى حوالي دقيقتين. عندما تتغير الحالة إلى "قيد التشغيل"، انقر فوق سهم الانتقال بجوار "عنوان API" للانتقال إلى صفحة العرض التوضيحي. نظرًا لأن النموذج كبير الحجم، يستغرق عرض واجهة WebUI حوالي 3 دقائق، وإلا فسيتم عرض "البوابة سيئة". يرجى ملاحظة أنه يجب على المستخدمين إكمال مصادقة الاسم الحقيقي قبل استخدام وظيفة الوصول إلى عنوان API.
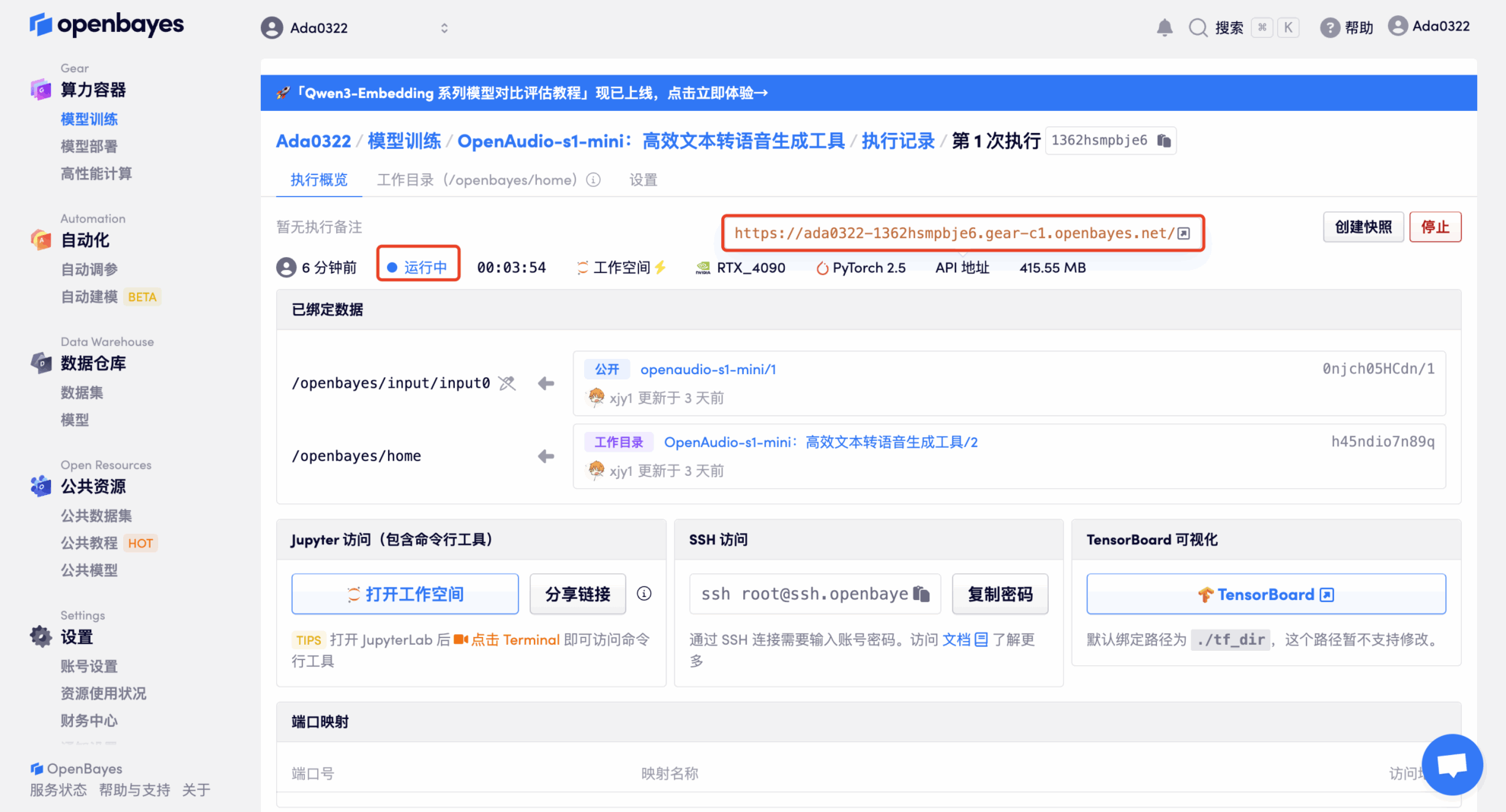
عرض التأثير
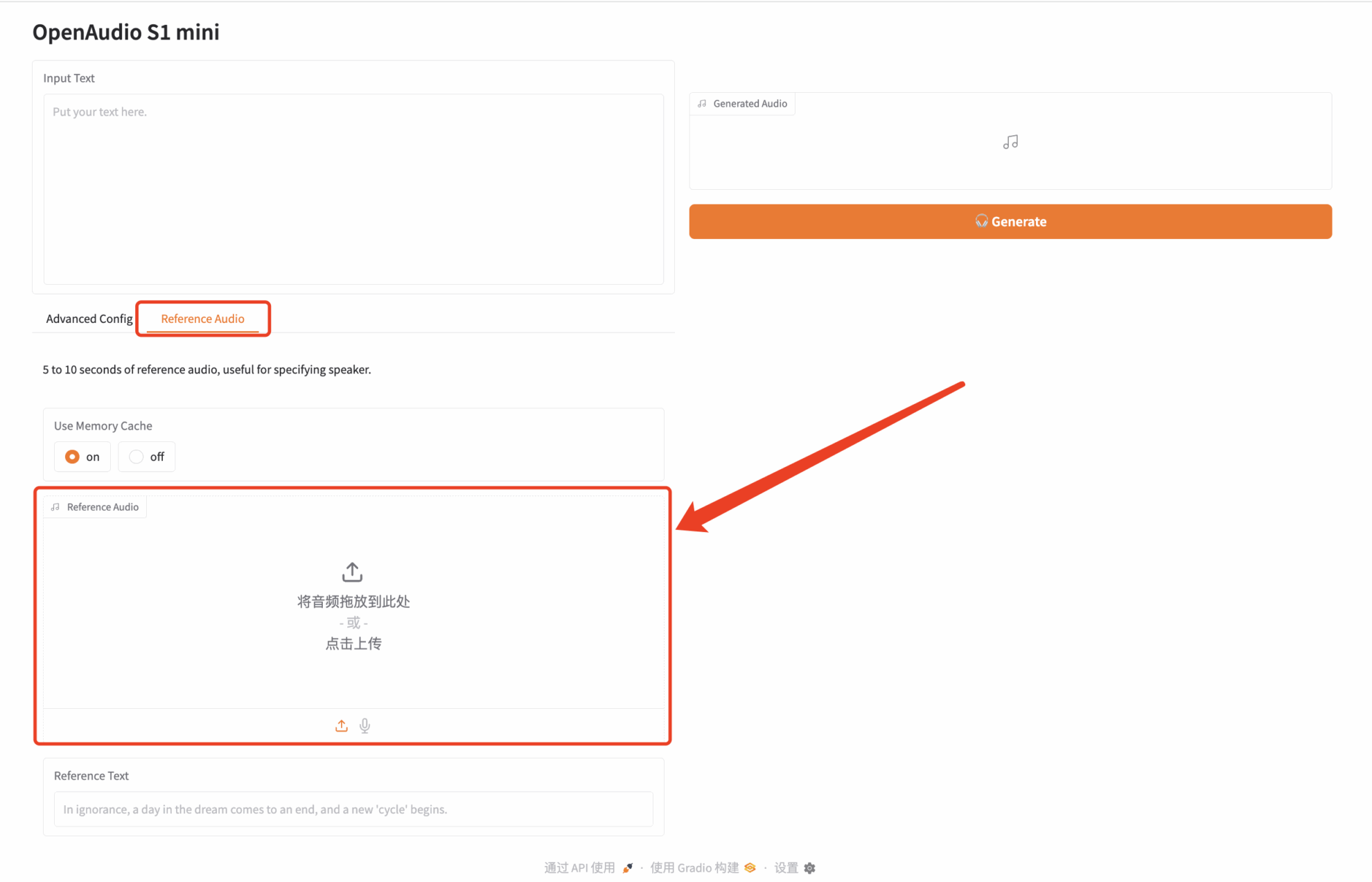
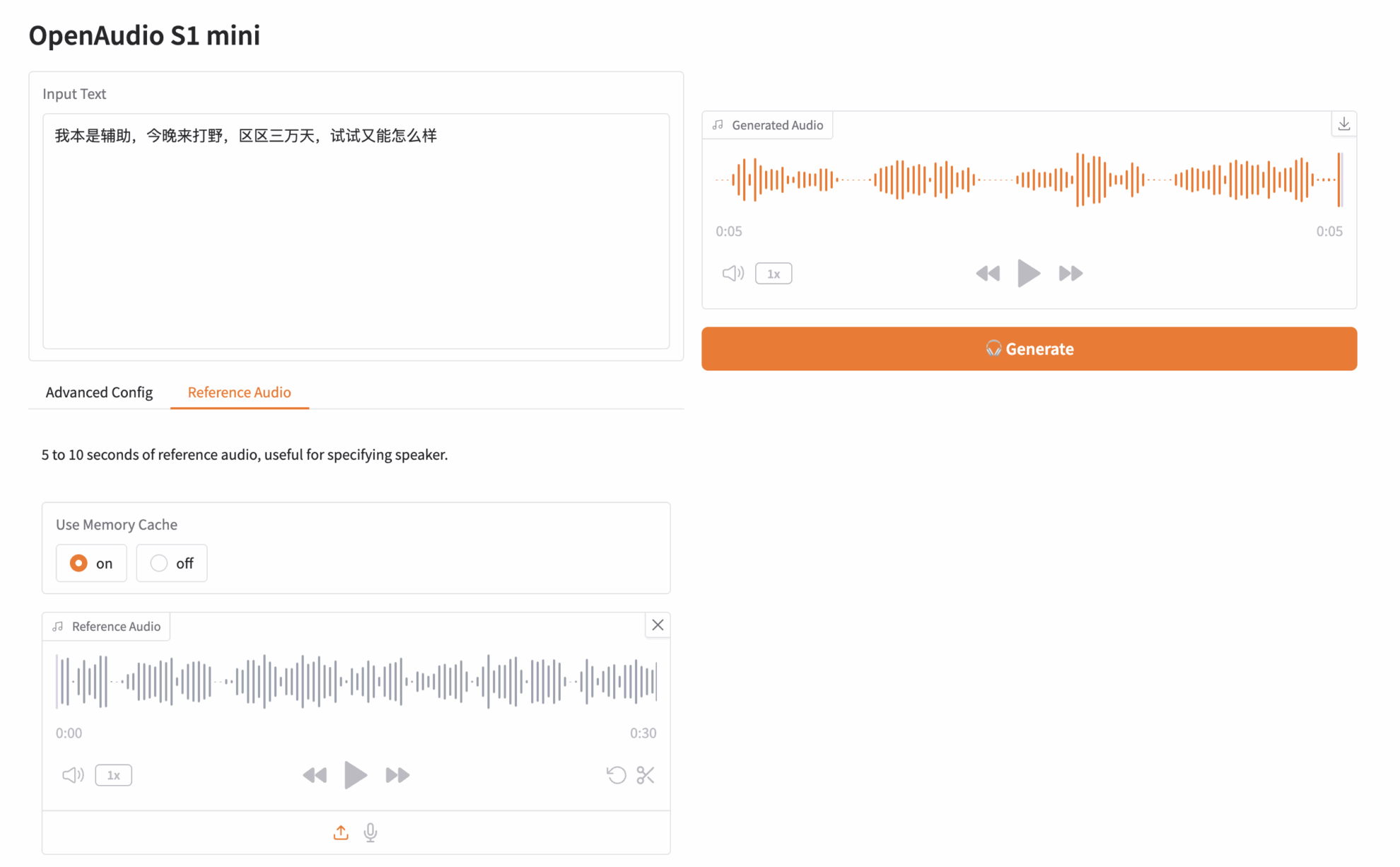
انقر على "عنوان واجهة برمجة التطبيقات" لتجربة النموذج. حمّلتُ مقطعًا صوتيًا لشخصية "بايمون" في لعبة Genshin Impact. النص المُدخل هو كما يلي:
كنتُ في الأصل لاعبًا داعمًا، لكنني جئتُ لألعبَ الغابة الليلة. لم يمضِ سوى 30,000 يوم، فما الضير في تجربتها؟
بعد ذلك، انقر فوق "إنشاء" على اليمين لإنشاء الصوت:
ما سبق هو البرنامج التعليمي الذي توصي به HyperAI هذه المرة. مرحبًا بك لتجربته عبر الإنترنت:








