Command Palette
Search for a command to run...
نُشرت في مجلة العلوم! أصدرت جامعة شنغهاي جياو تونغ ومختبر شنغهاي للذكاء الاصطناعي بشكل مشترك نموذج تصميم متحولة بروتينية يتفوق على أكثر الطرق تقدمًا

البروتين ليس فقط منفذًا لأنشطة الحياة البشرية، بل يلعب أيضًا دورًا مهمًا في العديد من المجالات مثل الطب الحيوي، ومعالجة الأغذية، وصناعة التخمير، والصناعة الكيميائية، وما إلى ذلك. لذلك، لم يتوقف الناس أبدًا عن إجراء الأبحاث حول بنية البروتين ووظيفته وما إلى ذلك، لاختيار البروتينات التي تلبي الاحتياجات وهي مستقرة للغاية لسيناريوهات التطبيق الصناعي.
ومع ذلك، فإن الظروف الفيزيائية والكيميائية (مثل درجة الحرارة والرقم الهيدروجيني) المطلوبة للبروتينات "البرية" المستخرجة من الكائنات الحية لتعمل في البيئات الصناعية بعيدة في الغالب عن بيئتها البيولوجية الأصلية. وبعبارة أخرى، فإن استقرار هذا النوع من البروتين يجعل من الصعب عليه التكيف مع البيئات الصناعية القاسية. لذلك، من أجل تلبية احتياجات سيناريوهات التطبيق المختلفة،غالبًا ما تكون الطفرات مطلوبة لتحسين الخصائص الفيزيائية والكيميائية للبروتينات، وبالتالي زيادة استقرارها في ظل ظروف درجات الحرارة/الرقم الهيدروجيني القصوى أو زيادة نشاط الإنزيم وخصوصيته.
تجدر الإشارة إلى أن تغيير النشاط البيولوجي للبروتين يتطلب سنوات من البحث التجريبي حول آلية عمله، وهو أمر ليس فقط يستغرق وقتًا طويلاً ويتطلب جهدًا شاقًا، بل ويصعب أيضًا تلبية احتياجات التعديل المتغيرة بسرعة. في السنوات الأخيرة، أدى ظهور نماذج لغة البروتين إلى تحسين دقة التنبؤ بملاءمة البروتين بشكل كبير، لكنها لا تزال تفتقر إلى دقة التنبؤ بالاستقرار.
ينبغي للطفرات البروتينية ذات المعنى الحقيقي أن تعمل على تحسين الاستقرار مع الحفاظ على نشاطها البيولوجي، والعكس صحيح. ردًا على ذلك، قامت مجموعة البحث التابعة للبروفيسور هونغ ليانغ في كلية العلوم الطبيعية/كلية الفيزياء والفلك بجامعة شنغهاي جياو تونغ، بالتعاون مع تان بان، وهو باحث شاب في مختبر الذكاء الاصطناعي في شنغهاي، ومتعاونين من جامعة شنغهاي للتكنولوجيا وكلية الطب في هانغتشو التابعة للأكاديمية الصينية للعلوم،لقد قاموا بشكل مشترك بتطوير نموذج لغة كبيرة لتسلسل البروتين الجديد باستخدام طريقة التدريب المسبق PRIME،وفي الوقت نفسه، تم تحقيق أفضل نتائج التنبؤ في نشاط الطفرة البروتينية والتنبؤ باستقرار الطفرة، فضلاً عن التعلم التمثيلي المرتبط بدرجة الحرارة.
تم نشر البحث ذي الصلة، بعنوان "نموذج لغوي عام موجه بدرجة الحرارة لتصميم بروتينات ذات استقرار ونشاط معزز"، في مجلة Science Advances، وهي مجلة معروفة تابعة لـ Science.
أبرز الأبحاث:
* يمكن لـ PRIME التنبؤ بتحسن أداء الطفرات البروتينية المحددة دون الاعتماد على البيانات التجريبية السابقة
* يمكن لـ PRIME التنبؤ بفعالية بخصائص متعددة للبروتين، مما يسمح للباحثين بتصميم البروتينات بنجاح في مناطق غير مألوفة
* يتم تدريب PRIME على أساس نموذج لغوي "واعي لدرجة الحرارة"، والذي يمكنه التقاط خصائص درجة الحرارة لتسلسلات البروتين بشكل أفضل

عنوان الورقة:
https://www.science.org/doi/10.1126/sciadv.adr2641
يجمع المشروع المفتوح المصدر "awesome-ai4s" أكثر من مائة تفسير ورقي لـ AI4S ويوفر مجموعات وأدوات ضخمة من البيانات:
https://github.com/hyperai/awesome-ai4s
مجموعة البيانات: 96 مليون سجل، تستكشف العلاقة بين تسلسل البروتين ودرجة الحرارة
من خلال دمج البيانات العامة من Uniprot (مورد البروتين العالمي) وتسلسلات البروتين التي تم الحصول عليها من العينات البيئية من خلال دراسات الميتاجينوميات،قام الباحثون بتجميع قاعدة بيانات ضخمة، ProteomeAtlas، تحتوي على 4.7 مليار تسلسل بروتيني طبيعي.
* UniProt عبارة عن قاعدة بيانات كبيرة توفر تسلسلات البروتين والتعليقات التوضيحية التفصيلية المرتبطة بها.
خلال عملية فحص التسلسل، احتفظ الباحثون فقط بالتسلسلات كاملة الطول وقاموا بمعالجة هذه التسلسلات باستخدام أداة محاذاة التسلسل البيولوجي MMseqs2، وضبطوا عتبة هوية التسلسل إلى 50% لتقليل التكرار، ثم قاموا بتحديد وتوضيح التسلسلات المرتبطة بدرجات حرارة النمو المثلى (OGT) للسلالات البكتيرية.
أخير،وقد قام الباحثون بشرح 96 مليون تسلسل بروتيني بهذه الطريقة.إنه يوفر موردًا غنيًا لاستكشاف العلاقة بين تسلسل البروتين ودرجة الحرارة.
بالإضافة إلى ذلك، في تحليل القدرة التنبؤية للرصاصة الصفرية للاستقرار الحراري للنموذج، تم اشتقاق مجموعات البيانات المستخدمة لدراسة التغير في درجة حرارة الانصهار (ΔTm) من MPTherm وFireProtDB وProThermDB، وتم إجراء جميع التجارب في ظل نفس ظروف الرقم الهيدروجيني.
ومن بينها، يحتوي MPTherm على بيانات تجريبية تتعلق بالاستقرار الحراري للبروتين؛ يتم استخدام FireProtDB خصيصًا لتخزين بيانات التجارب الطفرية المتعلقة بالاستقرار الحراري للبروتين ووظيفته؛ يقوم ProThermDB على وجه التحديد بجمع البيانات المتعلقة بالخصائص الديناميكية الحرارية للبروتين. وفي الوقت نفسه، قام الباحثون أيضًا بدمج بيانات المسح العميق للطفرات (DMS)، بشكل أساسي من قاعدة بيانات تحليل الطفرات البروتينية ProteinGym.
* مجموعة بيانات طفرة البروتين ProteinGym
https://go.hyper.ai/YlMT5
هندسة النموذج: نموذج التعلم العميق القائم على "إدراك درجة الحرارة"
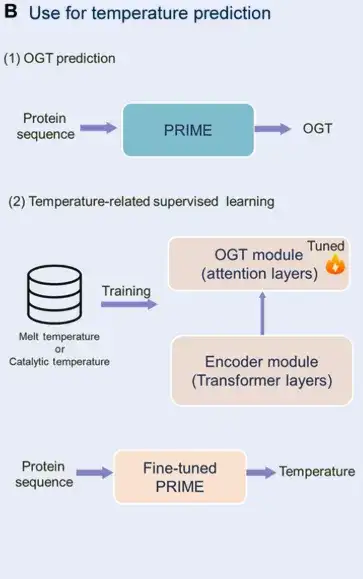
نموذج التعلم العميق الجديد PRIME (نموذج لغة البروتين للتدريب المسبق المقنع الذكي والتنبؤ بالبيئة) الذي اقترحه المعهد،القدرة على التنبؤ بتحسينات الأداء لطفرات البروتين المحددة دون الاعتماد على البيانات التجريبية السابقة.
تم تدريب النموذج على أساس نموذج لغوي "واعي لدرجة الحرارة"، بالاعتماد على مجموعة بيانات مكونة من 96 مليون تسلسل بروتيني، والجمع بين مهمة نمذجة اللغة المقنعة (MLM) على مستوى الرمز وهدف التنبؤ بدرجة حرارة النمو المثلى (OGT) على مستوى التسلسل، وإدخال مصطلح فقدان الارتباط من خلال التعلم متعدد المهام. يمكنه فحص تسلسلات البروتين ذات القدرة على تحمل درجات الحرارة العالية لتحسين استقرارها ونشاطها البيولوجي.
خاصة،يتكون PRIME من 3 أجزاء رئيسية:كما هو موضح في الشكل أدناه. الأول هو وحدة التشفير، وهي عبارة عن مشفر محول يستخدم لاستخراج الميزات الكامنة في التسلسل. أما الوحدة الثانية فهي وحدة MLM، والتي تم تصميمها لمساعدة المبرمج على تعلم التمثيل السياقي للأحماض الأمينية. في الوقت نفسه، يمكن أيضًا استخدام وحدة MLM لتسجيل النتائج الطفرية. المكون الثالث هو وحدة التنبؤ بـ OGT، والتي يمكنها التنبؤ بـ OGT للكائن الحي الذي يوجد فيه البروتين بناءً على التمثيل المحتمل.
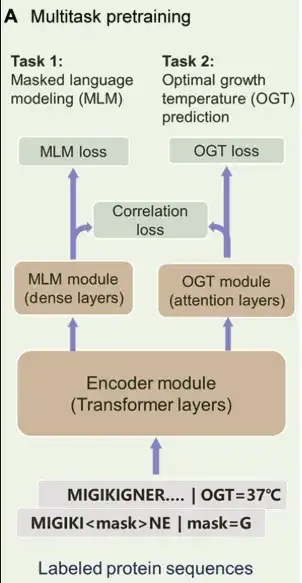
يتضمن التعلم متعدد المهام في PRIME في مرحلة ما قبل التدريب MLM وتوقع OGT وفقدان الارتباط.
في،غالبًا ما يتم استخدام MLM كطريقة تدريب مسبق لتمثيل بيانات التسلسل.في هذه الدراسة، تم استخدام تسلسلات البروتين الصاخبة كمدخلات، وتم إخفاء بعض العلامات أو تمثيلها بعلامات بديلة، وكان هدف التدريب هو إعادة بناء هذه العلامات الصاخبة. يساعد هذا النهج النموذج على التقاط التبعيات بين الأحماض الأمينية والمعلومات السياقية للتسلسل، مع استخدام عملية إعادة البناء هذه أيضًا لتسجيل الطفرات.
تم تحسين مهمة التدريب الثانية في ظل ظروف خاضعة للإشراف، واستخدم الباحثون مجموعة بيانات مكونة من 96 مليون تسلسل بروتيني مع شرحها باستخدام OGT لتدريب نموذج PRIME. مدخلات هذه المهمة هي تسلسل البروتين، وقيم درجة الحرارة التي تولدها وحدة OGT تتراوح من 0 درجة إلى 100 درجة مئوية. ومن الجدير بالذكر أن وحدة OGT ووحدة MLM تعملان باستخدام مشفر مشترك.يتيح هذا الهيكل للنموذج التقاط معلومات سياق الأحماض الأمينية بالإضافة إلى ميزات التسلسل المعتمدة على درجة الحرارة فيها في وقت واحد.
أخيرًا، قدم الباحثون فقدان الارتباط لتسهيل التغذية الراجعة من OGT المتوقعة إلى تصنيف MLM، ومواءمة معلومات المهمة على مستويات الرمز والتسلسل.يتيح هذا للنموذج الكبير التقاط خصائص درجة الحرارة لتسلسلات البروتين بشكل أفضل.
الاستنتاج التجريبي: يتفوق على أكثر الطرق تقدمًا في التنبؤ بقدرة تكيف تسلسلات البروتين المتحولة
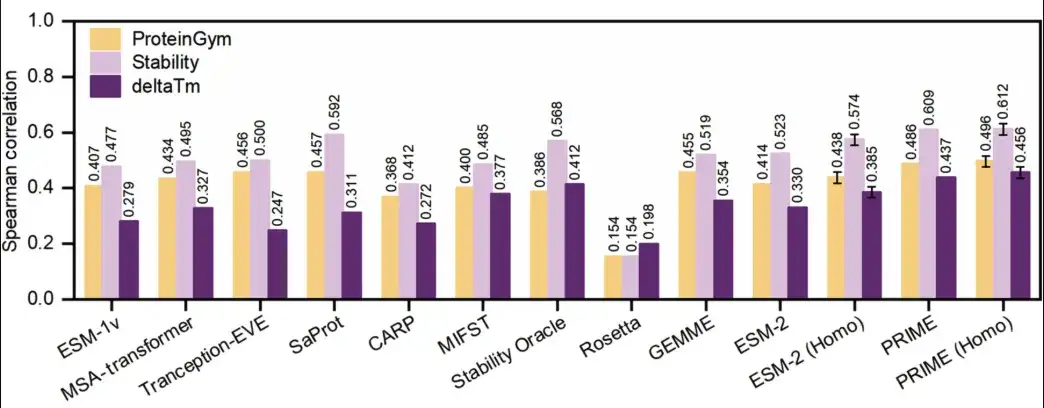
قام الباحثون بمقارنة قدرات التنبؤ بالرصاصة الصفرية لبرنامج PRIME تجريبياً مع قدرات النماذج الأكثر تقدماً للاستقرار الحراري، بما في ذلك نماذج التعلم العميق ESM-1v، وESM-2، وMSA-transformer، وTranception-EVE، وCARP، وMIF-ST، وSaProt، وStability Oracle، والطرق الحسابية التقليدية GEMME وRosetta.
استخدم الباحثون مجموعات البيانات من MPTherm، وFireProtDB، وProThermDB، والتي تحتوي على تغيرات درجة حرارة الانصهار (ΔTm) التي تم جمعها في نفس بيئة الرقم الهيدروجيني وتأكدوا من وجود 10 نقاط بيانات على الأقل لكل بروتين، بإجمالي 66 اكتشافًا. وتضمنت الدراسة أيضًا اختبار مسح الطفرات العميقة (DMS)، باستخدام ProteinGym كمنصة اختبار.
وتظهر النتائج في الشكل أدناه.تتفوق طريقة PRIME على جميع الطرق الأخرى في التنبؤ بتوفر البروتين واستقراره.
وفي معيار ProteinGym (الأصفر في الشكل أدناه)، حصل PRIME على درجة 0.486، وحصل SaProt على المرتبة الثانية على درجة 0.457. في مجموعة بيانات ΔTm (الأرجواني الداكن في الشكل أدناه)، لا يزال PRIME يحتل المرتبة الأولى بنتيجة 0.437، والمركز الثاني بنتيجة 0.412. بالإضافة إلى ذلك، قام الباحثون أيضًا بمقارنة PRIME مع طرق أخرى في مجموعة البيانات الفرعية لاستقرار ProteinGym (اللون الأرجواني الفاتح في الشكل أدناه)، ولا يزال PRIME يتفوق على جميع الطرق الأخرى.
ومن الجدير بالذكر أنه من أجل اختبار فعالية وتأثير PRIME في التطبيق العملي للهندسة البروتينية،وأجرى الباحثون أيضًا تجربة رطبة واختاروا خمسة بروتينات للتحقق منها.تتضمن LbCas12a، وبوليميراز RNA T7، والكرياتيناز، وبوليميراز الأحماض النووية الاصطناعية، ومنطقة السلسلة الثقيلة المتغيرة من جسم مضاد نانوي محدد.
في الاختبارات التجريبية لأفضل 30-45 طفرة نقطة واحدة، كان أكثر من 30% من الطفرات النقطة الواحدة الموصى بها من قبل AI متفوقًا بشكل كبير على البروتينات البرية في الخصائص الرئيسية مثل الاستقرار الحراري، والنشاط الأنزيمي، وتقارب ربط المستضد بالأجسام المضادة، وقدرة بلمرة الأحماض النووية غير الطبيعية، أو التسامح في ظل الظروف القلوية الشديدة، وتجاوز المعدل الإيجابي للبروتينات الفردية 50%.
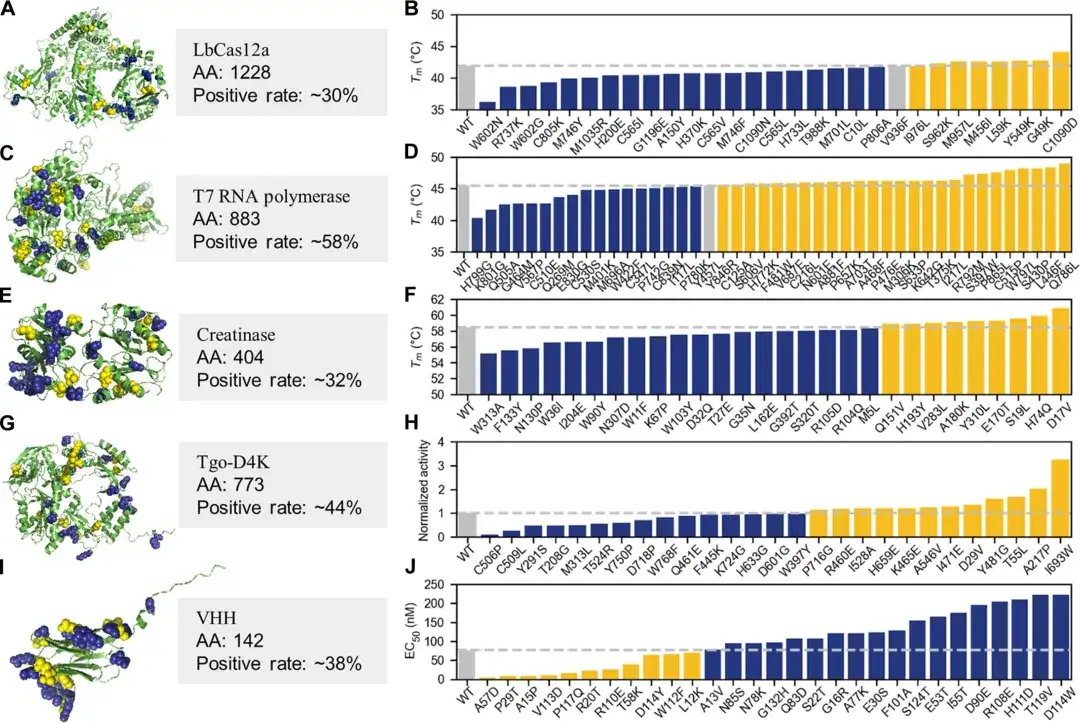
ومن الجدير بالذكر أن الفريق أظهر أيضًا طريقة فعالة تعتمد على PRIME.يمكن الحصول بسرعة على الطفرات متعددة المواقع ذات النشاط والاستقرار المعززين.ومن خلال طريقة الضبط الدقيق للعينة الصغيرة هذه، يمكن إنتاج طفرات بروتينية ممتازة للغاية في 2-4 جولات من التطور مع أقل من 100 عينة تجريبية رطبة.
على سبيل المثال، بعد أربع جولات من التكرارات الجافة والرطبة، نجح بوليميراز RNA T7 في الحصول على طفرات متعددة النقاط ذات نشاط عالٍ واستقرار عالٍ. كان أعلى طفرة متعددة النقاط لها درجة حرارة أعلى بمقدار 12.8 درجة مئوية من النوع البري، وكان نشاطها أعلى بنحو أربعة أضعاف من النوع البري. وتفوق أداء بعض المنتجات على منتجات مماثلة سيطرت على السوق لمدة 10 سنوات من قبل شركة رائدة عالميًا في مجال التكنولوجيا الحيوية (نيو إنجلاند بيولابس). علاوة على ذلك، في تجارب LbCas12a وT7 RNA بوليميراز، يمكن لـ Pro-PRIME فرض طفرات سلبية أحادية النقطة للحصول على طفرات إيجابية متعددة النقاط.
يوضح هذا أن PRIME يمكنه تعلم التأثيرات الإبستاتية لطفرة البروتين من بيانات التسلسل، وهو أمر ذو أهمية كبيرة للهندسة البروتينية التقليدية.
تعميق هندسة البروتين للتغلب على مشكلة العينات الصغيرة
في مجال هندسة البروتين، عادة ما تتطلب عملية التعبير عن البروتين وتنقيته واختباره الوظيفي كواشف وأدوات باهظة الثمن، كما أن التجارب تستغرق وقتا طويلا، مما يحد بشكل كبير من عدد العينات التي يمكن توليدها. في أبحاث وظائف البروتين، يتطلب اختبار تأثيرات طفرات البروتين على الوظائف (مثل النشاط التحفيزي، والاستقرار الحراري، وتقارب الارتباط، وما إلى ذلك) تجارب أكثر دقة وتعقيدًا، ومن الصعب قياس أداء جميع الطفرات المحتملة بطريقة عالية الإنتاجية لمرة واحدة.
وهذا يجعل من الصعب على نماذج التعلم الآلي الحصول على تدريب كافٍ على عينات محدودة، مما يؤدي إلى ضعف أداء النموذج في التنبؤ بالطفرات الجديدة. بالإضافة إلى ذلك، قد تتسبب الأخطاء التجريبية أو الضوضاء في بيانات العينة الصغيرة في حدوث تداخل أكبر في تدريب النموذج. ويمكن القول أنلقد أدى تحدي البيانات الصغيرة إلى الحد من كفاءة البحث ودقته في مجال هندسة البروتين إلى حد ما.وقد حفز هذا الباحثين بشكل كبير على استكشاف التقنيات المبتكرة، والجمع بين التعلم الآلي والتقنيات التجريبية وتحليل البيانات المتعددة الوسائط لكسر قيود العينات الصغيرة.
وقد حقق فريق البحث الموصوف في هذه المقالة أداءً متميزًا في هذا الصدد. بالإضافة إلى PRIME المذكورة أعلاه، نشر فريق البروفيسور هونغ ليانغ والدكتور تان بان أيضًا عددًا من النتائج حول التعلم باستخدام عينات صغيرة.
في السابق، استخدم الفريق مزيجًا من التعلم الانتقالي (MTL)، والتعلم من أجل الترتيب (LTR)، والضبط الدقيق الفعال للمعلمات (PEFT).لقد قمنا بتطوير استراتيجية تدريب، FSFP، يمكنها تحسين نماذج لغة البروتين بشكل فعال عندما تكون البيانات نادرة للغاية.يمكن استخدامه لتعلم قدرة البروتين على التكيف من خلال عينات صغيرة. إنه يحسن بشكل كبير تأثير نماذج التدريب المسبق للبروتين التقليدية الكبيرة في التنبؤ بخصائص الطفرة عند استخدام القليل جدًا من البيانات التجريبية الرطبة، ويظهر أيضًا إمكانات كبيرة في التطبيقات العملية.
وكان عنوان البحث ذي الصلة هو "تعزيز كفاءة نماذج لغة البروتين باستخدام الحد الأدنى من بيانات المختبر الرطب من خلال التعلم من خلال عدد قليل من اللقطات" ونشر في مجلة Nature Communications، وهي شركة تابعة لـ Nature.
وبالإضافة إلى ذلك، شارك البروفيسور هونغ ليانغ أيضًا بالآراء ذات الصلة. ويعتقد أنه "في السنوات الثلاث المقبلة، في مجالات تصميم البروتين، وتطوير الأدوية، وتشخيص الأمراض، واكتشاف الأهداف الجديدة، وتصميم مسارات التخليق الكيميائي، وتصميم المواد، فإن الذكاء الاصطناعي العام في المجالات المهنية سوف يحدث تحولاً نموذجياً واضحاً، ويحول نموذج الاكتشاف العلمي الذي اعتمد على التجربة والخطأ المتقطعين للدماغ البشري في الماضي إلى نموذج تصميم قياسي آلي كبير الحجم للذكاء الاصطناعي".
وتتضمن التغييرات المحددة بناء أساليب التعلم من خلال عينات صفرية أو عينات صغيرة، وبناء نماذج تكنولوجية للتدريب المسبق.في حالة عدم وجود بيانات، يتم إنشاء كمية كبيرة من البيانات المزيفة بدقة أقل قليلاً من خلال جهاز محاكاة مادي للتدريب المسبق، ثم يتم ضبطها باستخدام بيانات حقيقية وقيمة لإكمال التعلم التعزيزي.
أكد البروفيسور هونغ أن "البيانات الزائفة هي بيانات ليست من العالم الحقيقي، ولكنها تتمتع بدرجة معينة من الموثوقية. يمكن توليدها بواسطة الذكاء الاصطناعي أو الحصول عليها من خلال محاكاة حاسوبية فيزيائية لتحسين البيانات. وأخيرًا، تُعد بيانات التجارب الرطبة الحقيقية الأكثر قيمة، وتُستخدم في الضبط النهائي للنموذج".
في الواقع، لا يقتصر تحدي ندرة البيانات على مجال هندسة البروتين فحسب. تعتبر طرق التعلم باستخدام العينات الصغيرة وحتى العينات الصفرية أمرًا بالغ الأهمية. ونحن نتطلع إلى أن يقدم فريق البروفيسور هونغ ليانغ والدكتور تان بان المزيد من النتائج عالية الجودة حول هذه النقطة المؤلمة.








