Command Palette
Search for a command to run...
سيدي، لقد تغيرت أوقات فينسنت فان جوخ مرة أخرى! قام أعضاء فريق SD الأساسيون بتأسيس شركتهم الخاصة، وكان النموذج الأول FLUX.1 بمثابة معركة شرسة ضد SD 3 وMidjourney

لفترة طويلة، من Midjourney مع الأساليب الفنية المتنوعة، إلى DALL-E المدعوم من OpenAI، إلى Stable Diffusion مفتوح المصدر (SD باختصار)، تم ترقية جودة إنشاء وسرعة نموذج الرسم البياني القائم على النص بشكل مستمر، وأصبح الفهم السريع ومعالجة التفاصيل أيضًا اتجاهات جديدة للتداول الداخلي للنماذج الرئيسية.
بعد دخولها عام 2024، قامت Midjourney وStable Diffusion، اللتان دخلتا مرحلة "السباق بين الحصانين"، بجهود متتالية. تم إصدار SD 3 أولاً، ثم تم أيضًا تحديث Midjourney V6.1 وتكراره. ومع ذلك، عندما يكون الناس لا يزالون منغمسين في المقارنة بين SD 3 و Midjourney،لقد ولد جيل جديد من "الشيطان" بهدوء - ظهر FLUX من العدم.
عندما يقوم برنامج FLUX بإنشاء شخصيات، وخاصة مشاهد الأشخاص الحقيقيين، يكون التأثير قريبًا جدًا من اللقطات الواقعية. التفاصيل مثل تعبير الشخصية، لمعان البشرة، تسريحة الشعر واللون واقعية للغاية.لقد تم الترحيب به ذات يوم باعتباره خليفة لـ Stable Diffusion.ومن المثير للاهتمام أن الاثنين لديهما علاقة وثيقة.
روبن رومباتش، مؤسس Black Forest Labs، الفريق الذي يقف وراء FLUX، هو أحد المطورين المشاركين لـ Stable Diffusion. بعد مغادرة شركة Stability AI، أسس روبن شركة Black Forest Labs.وأطلقت نموذج FLUX.1.
حاليًا، يوفر FLUX.1 ثلاثة إصدارات: Pro وDev وSchnell. الإصدار الاحترافي هو إصدار مغلق المصدر يتم توفيره من خلال واجهة برمجة التطبيقات (API)، والذي يمكن استخدامه تجاريًا وهو أيضًا الإصدار الأقوى؛ إصدار Dev هو إصدار مفتوح المصدر "مقطر" مباشرة من الإصدار Pro، مع ترخيص غير تجاري؛ إصدار Schnell هو الإصدار الأسرع والأكثر انسيابية، والذي يقال أنه يعمل بسرعة تصل إلى 10 مرات أسرع. إنه مفتوح المصدر ويستخدم ترخيص Apache 2، وهو مناسب للتطوير المحلي والاستخدام الشخصي.
أعتقد أن الكثير منكم يريدون بالفعل تجربة هذا الجيل الجديد من الصور الأدبية الراقية!أطلق الآن قسم البرامج التعليمية في الموقع الرسمي لشركة HyperAI (hyper.ai) "FLUX ComfyUI (بما في ذلك إصدار تدريب Black Myth Wukong LoRA)"، وهو إصدار ComfyUI من FLUX [dev] ويدعم أيضًا تدريب LoRA.
الأصدقاء المهتمين، تعالوا لتجربتها! لقد جربته من أجلك، والنتيجة جيدة تمامًا مثل SD 3 وMidjourney↓

نفس المطالبة، تم إنشاؤها بواسطة 3 نماذج
* موجه: فتاة تحمل لافتة مكتوب عليها "أنا ذكاء اصطناعي"
بالإضافة إلى ذلك، قام Jack-Cui، وهو أحد خبراء Up Master المشهورين على Bilibili، بإنشاء برنامج تعليمي تفصيلي للعملية لتعليم الجميع خطوة بخطوة!
عنوان البرنامج التعليمي:
فيديو العملية:
https://www.bilibili.com/video/BV1xSpKeVEeM
تشغيل تجريبي
تشغيل FLUX ComfyUI
1. قم بتسجيل الدخول إلى hyper.ai، في صفحة البرنامج التعليمي، انقر فوق تشغيل هذا البرنامج التعليمي عبر الإنترنت. "FLUX ComfyUI (بما في ذلك إصدار تدريب Black Myth Wukong LoRA)"، انقر فوق "تشغيل هذا البرنامج التعليمي عبر الإنترنت".
2. بعد الانتقال إلى الصفحة التالية، انقر فوق "استنساخ" في الزاوية اليمنى العليا لاستنساخ البرنامج التعليمي في الحاوية الخاصة بك.
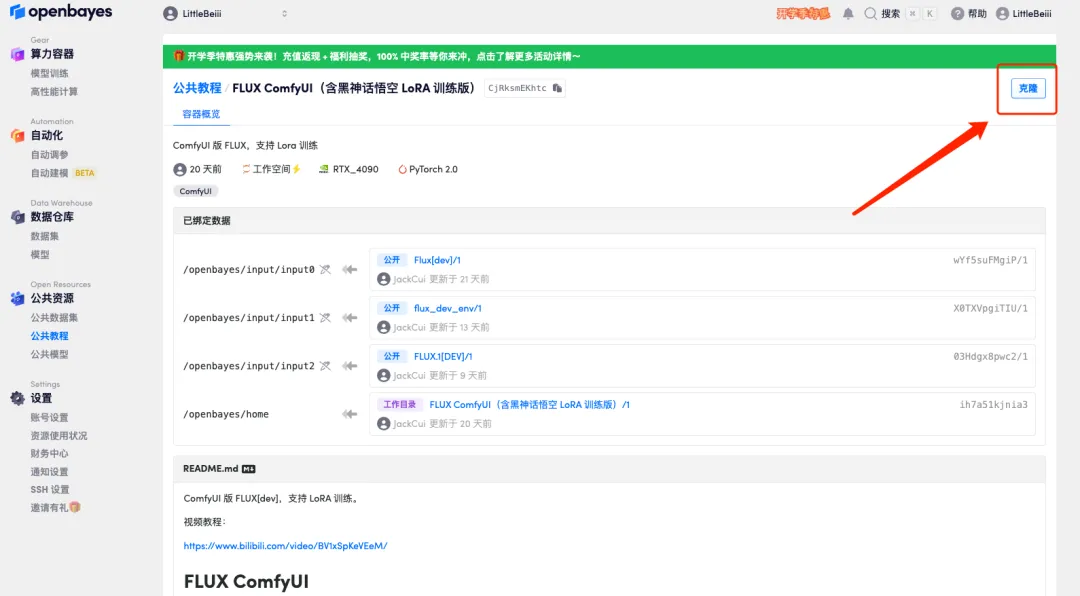
3. انقر فوق "التالي: حدد معدل التجزئة" في الزاوية اليمنى السفلية.
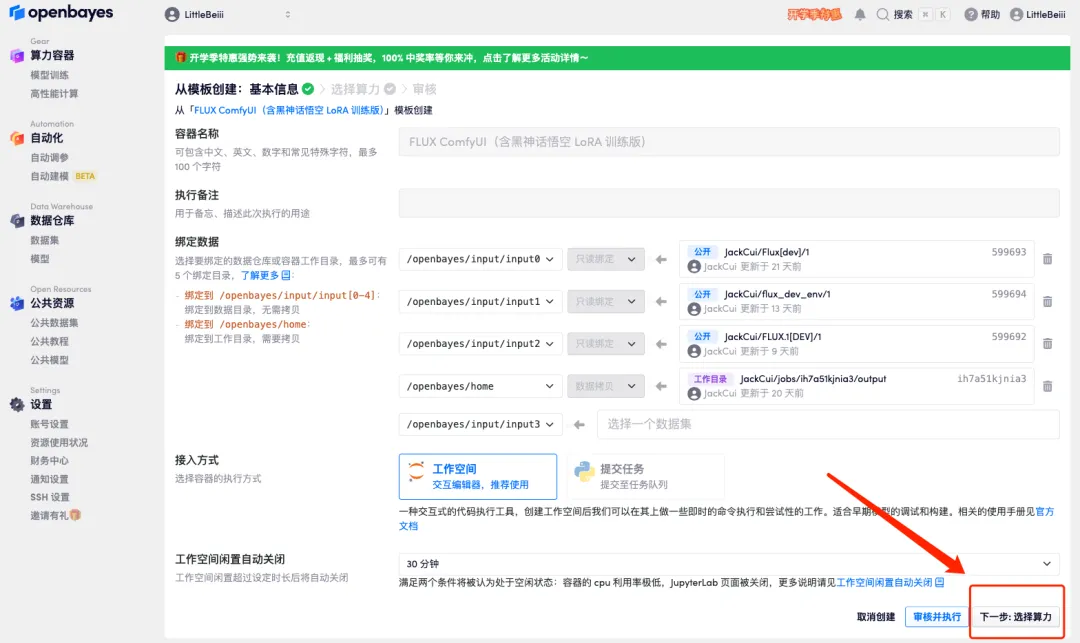
4. بعد الانتقال إلى الصفحة التالية، حدد "NVIDIA RTX 4090" وصورة "PyTorch"، ثم انقر فوق "التالي: المراجعة".يمكن للمستخدمين الجدد التسجيل باستخدام رابط الدعوة أدناه للحصول على 4 ساعات من RTX 4090 + 5 ساعات من وقت فراغ وحدة المعالجة المركزية!
رابط دعوة حصرية لـ HyperAI (انسخ وافتح في المتصفح):
https://openbayes.com/console/signup?r=6bJ0ljLFsFh_Vvej
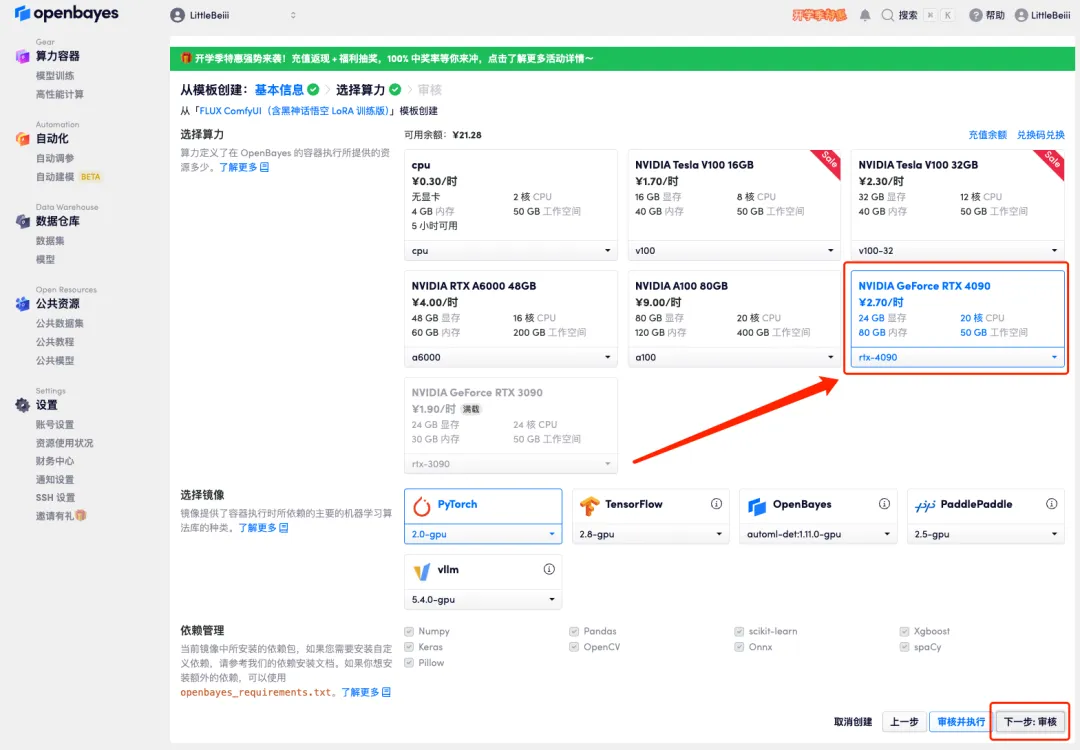
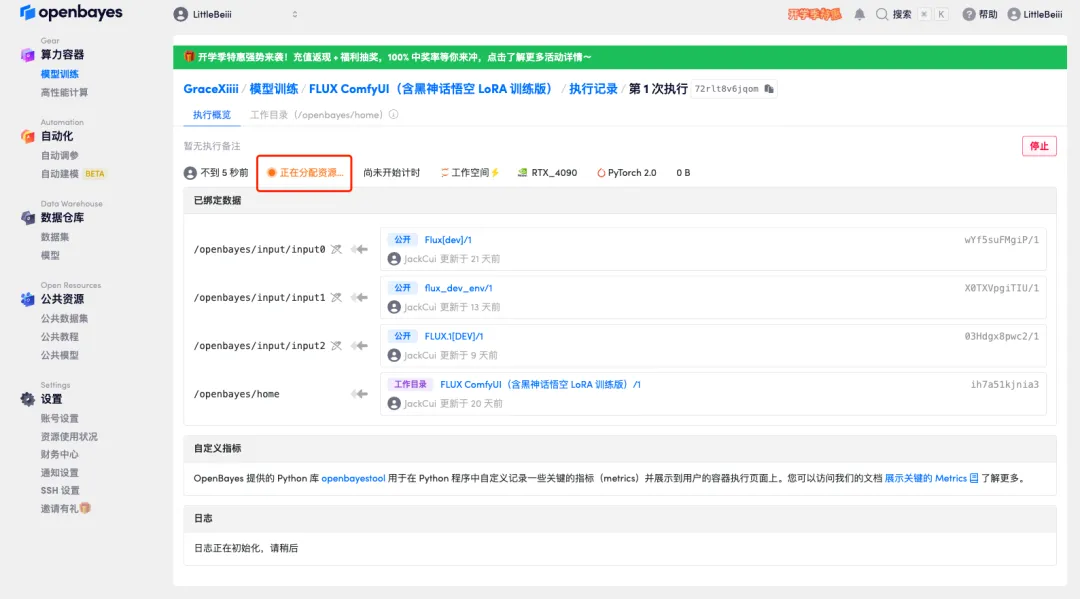
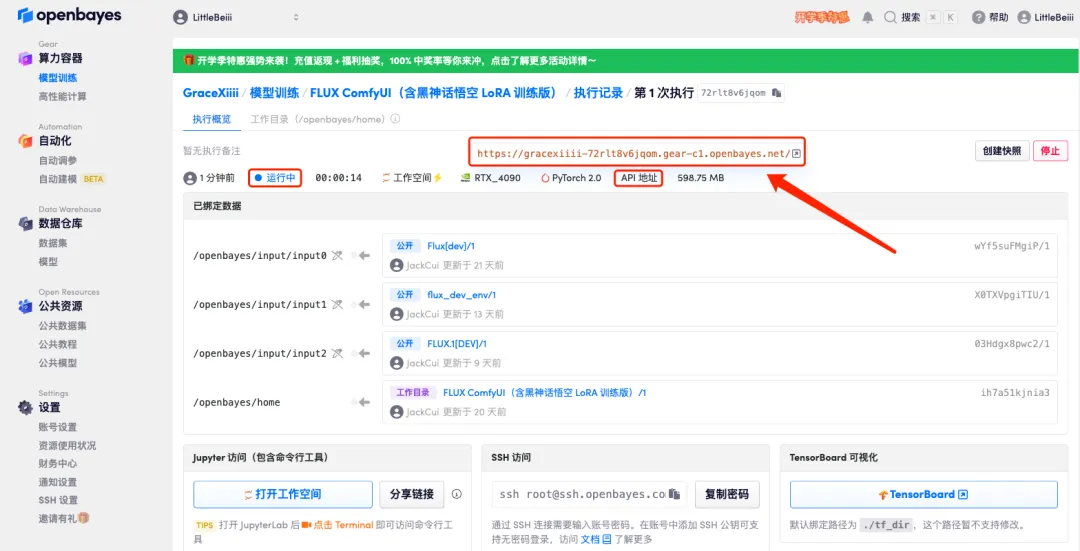
5. بعد التأكيد، انقر فوق "متابعة" وانتظر حتى يتم تخصيص الموارد. ستستغرق عملية الاستنساخ الأولى حوالي 1-2 دقيقة. عندما تتغير الحالة إلى "قيد التشغيل"، انقر فوق سهم الانتقال بجوار "عنوان API" للانتقال إلى صفحة العرض التوضيحي.يرجى ملاحظة أنه يجب على المستخدمين إكمال مصادقة الاسم الحقيقي قبل استخدام وظيفة الوصول إلى عنوان API.
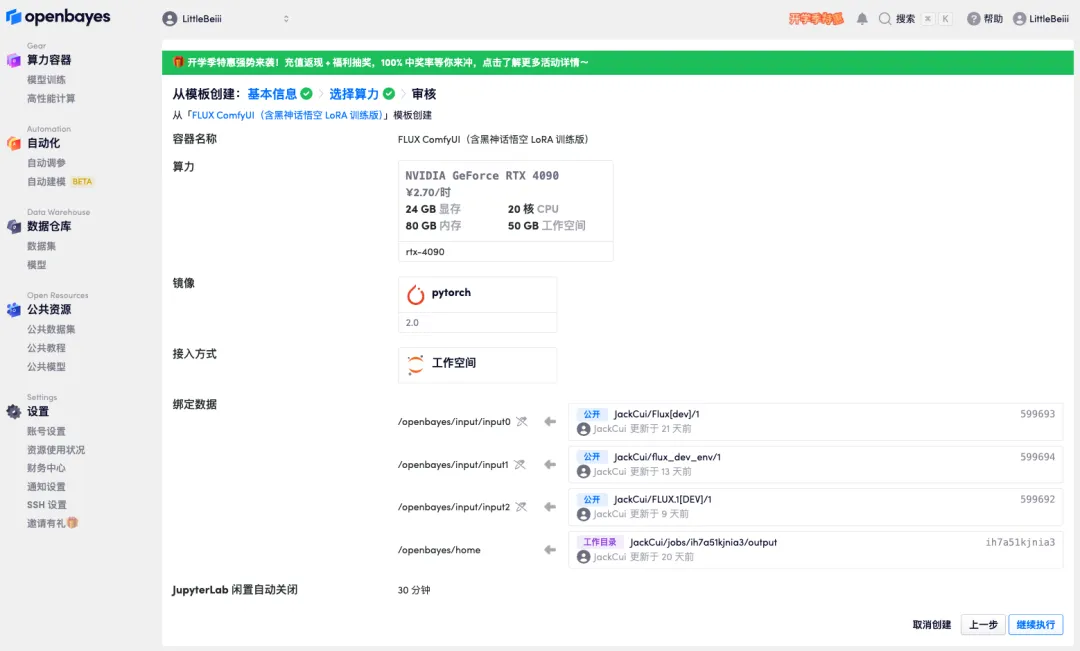
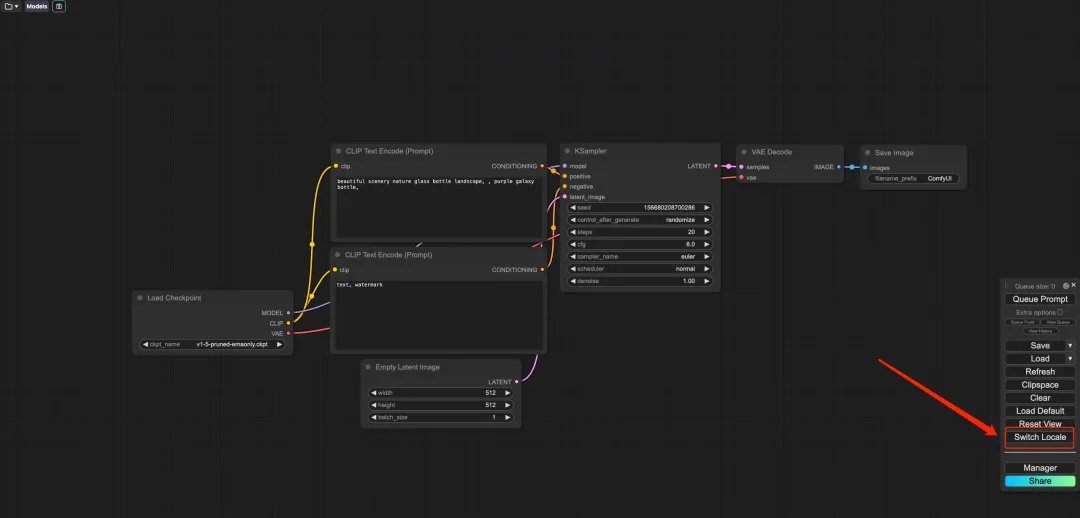
6. بعد فتح النسخة التجريبية، انقر فوق "تبديل الإعدادات المحلية" لتبديل اللغة إلى اللغة الصينية.
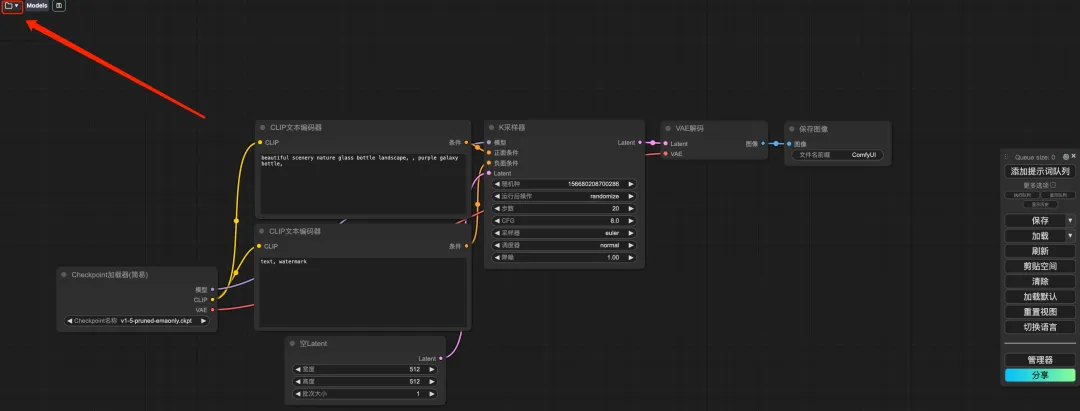
7. بعد تبديل اللغة، انقر فوق أيقونة المجلد في الزاوية اليسرى العليا لتحديد سير العمل المطلوب.
* ووكونج: عرض توضيحي لصورة ووكونج الأسطورية السوداء
* TED: عرض توضيحي لخطاب TED المباشر
* 3mm4w: عرض توضيحي لكتابة نص على الصور
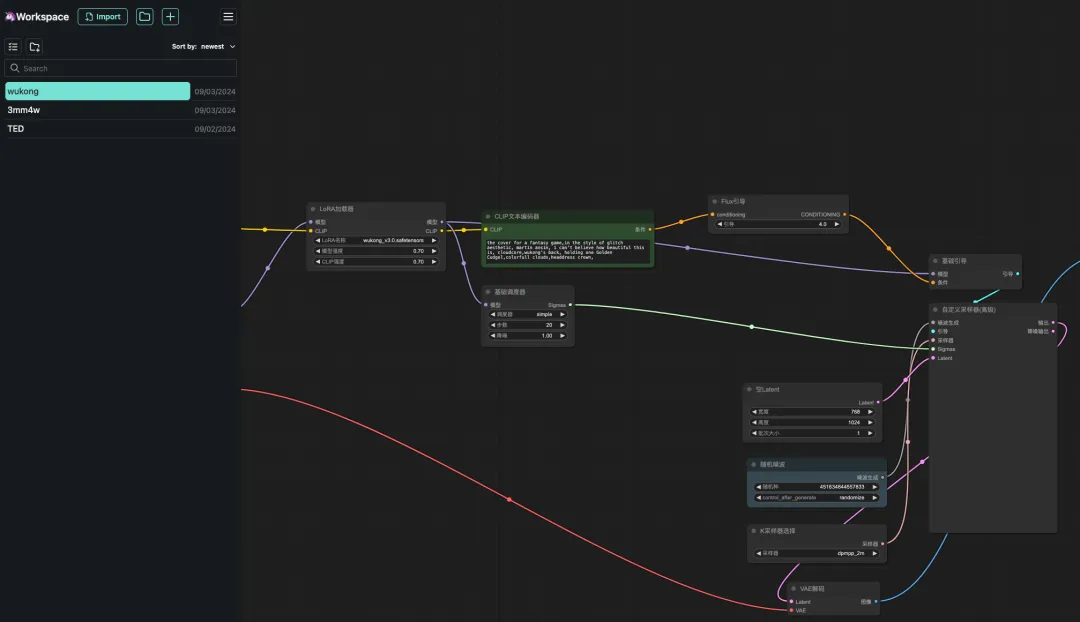
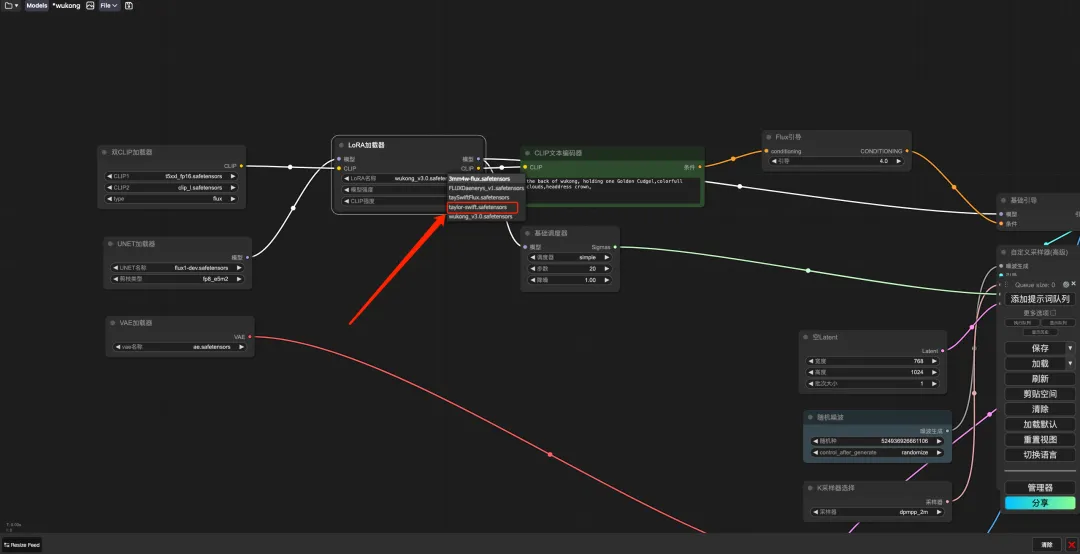
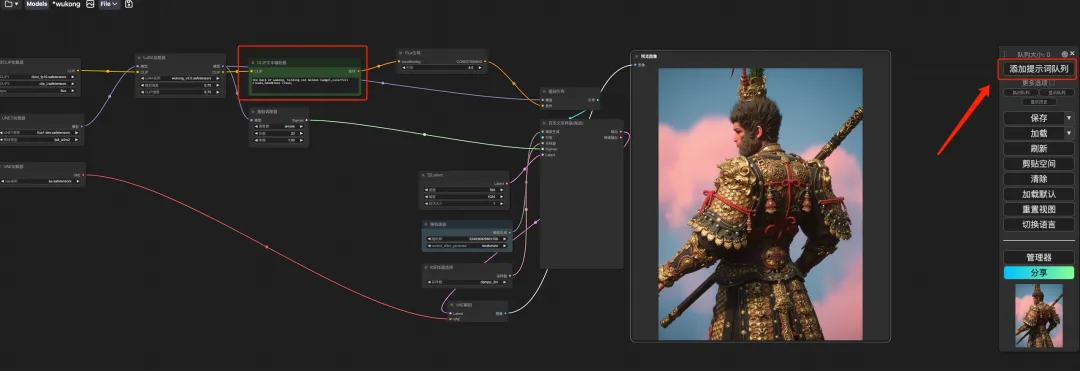
8. حدد سير عمل "وو كونغ"، وأدخل Prompt في مولد نص CLIP (على سبيل المثال: الجزء الخلفي من وو كونغ، يحمل هراوة ذهبية واحدة، سحب ملونة، تاج غطاء للرأس)، انقر فوق "إضافة قائمة انتظار كلمات المطالبة لتوليد الصورة"، ويمكنك أن ترى أن الصورة المولدة جميلة جدًا.

تدريب FLUX LoRA
1. لتخصيص سير العمل، نحتاج إلى تدريب نموذج LoRA أولاً. ارجع إلى واجهة الحاوية الآن، وانقر فوق "فتح مساحة العمل" وقم بإنشاء محطة طرفية جديدة.
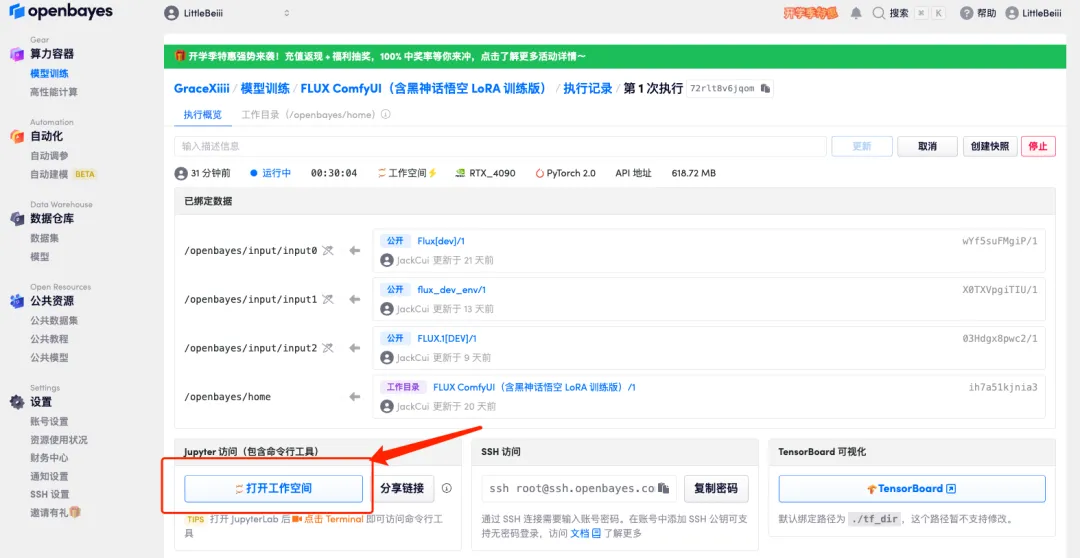
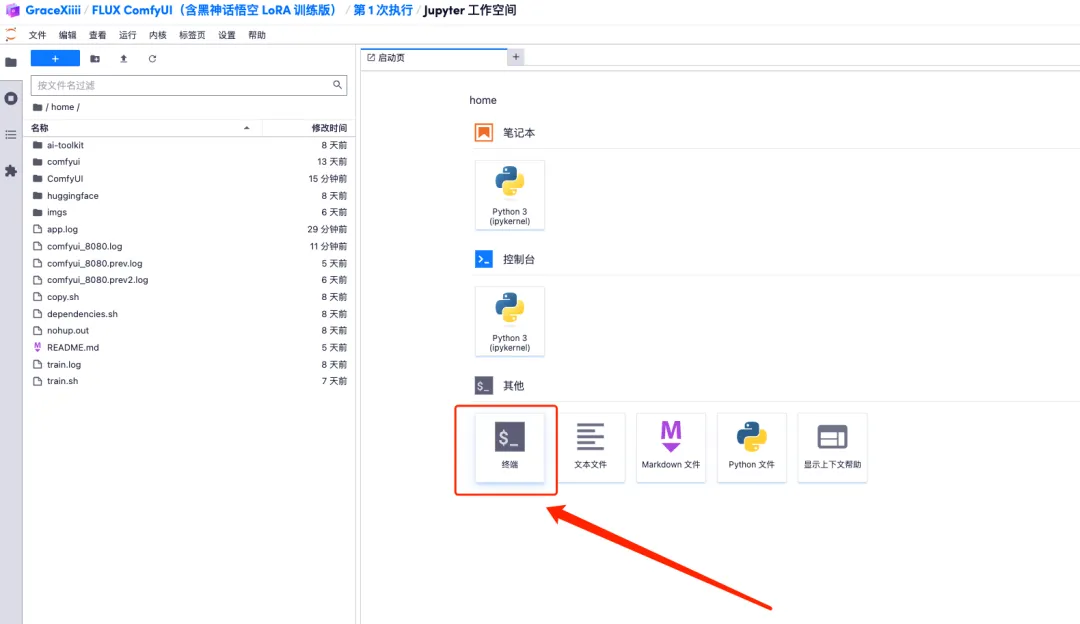
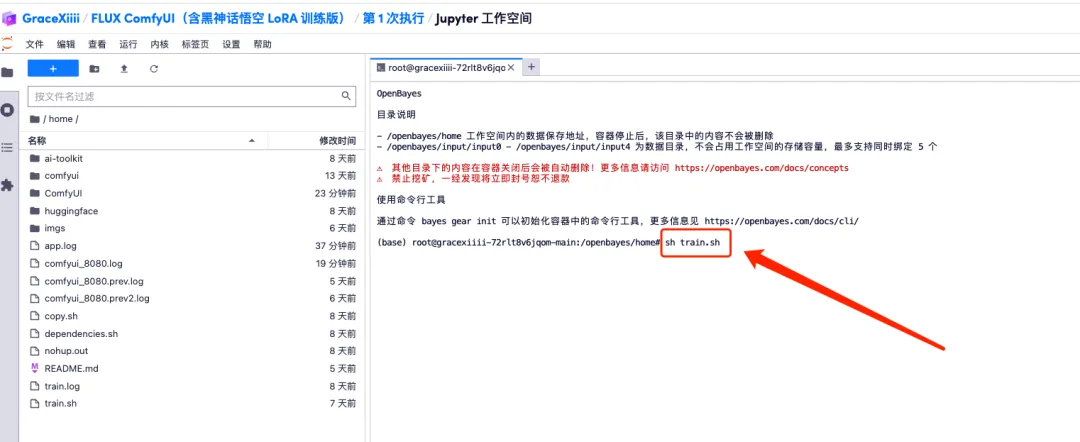
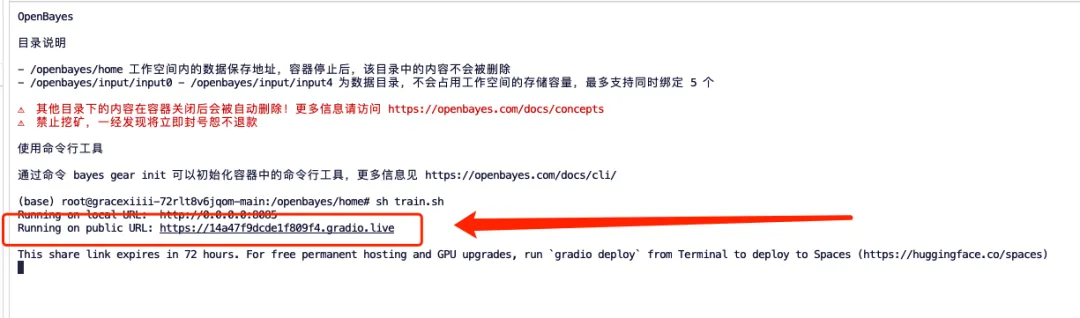
2. أدخل "sh train.sh" في المحطة الطرفية واضغط على Enter للتشغيل. عند ظهور "التشغيل على عنوان URL العام"، انقر فوق الرابط.
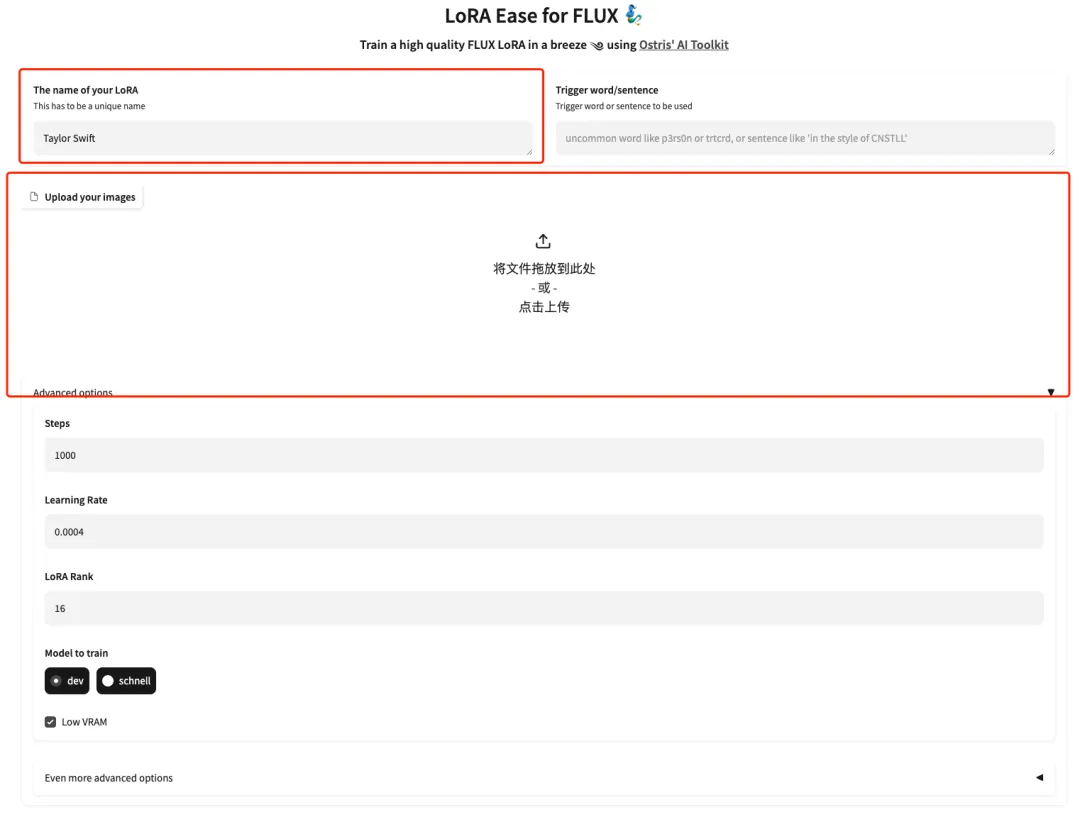
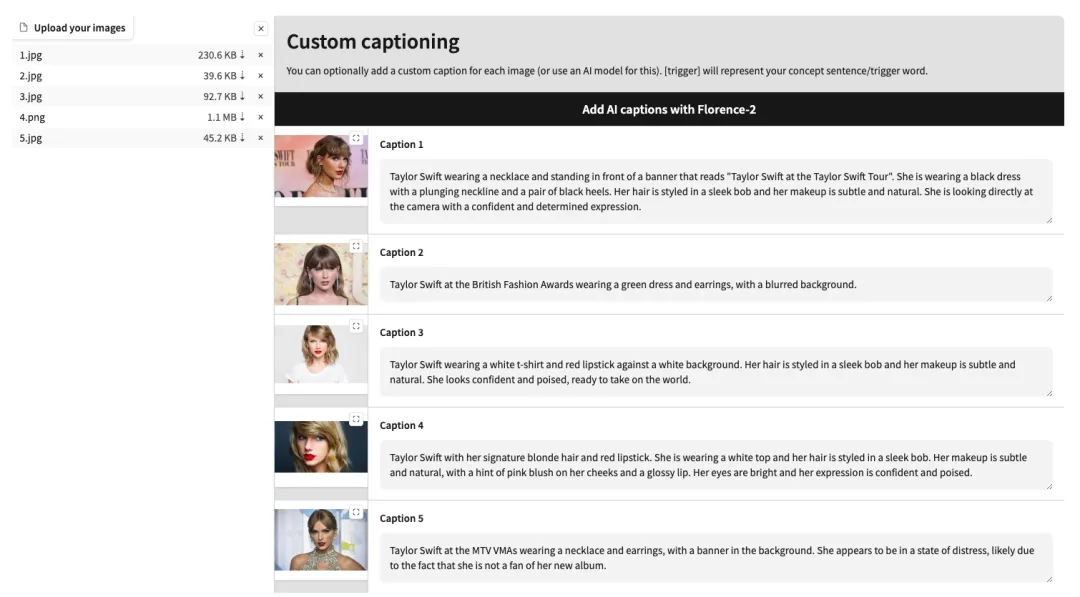
3. بعد الانتقال إلى الصفحة التالية، أدخل طراز النموذج وقم بتحميل الصور. إليكم 5 صور لتايلور سويفت.يرجى ملاحظة أن الصورة يجب أن تكون صورة أمامية عالية الدقة مع نسبة وجه أكبر. كلما كانت جودة الصورة أفضل، كلما كان تأثير التدريب أفضل.
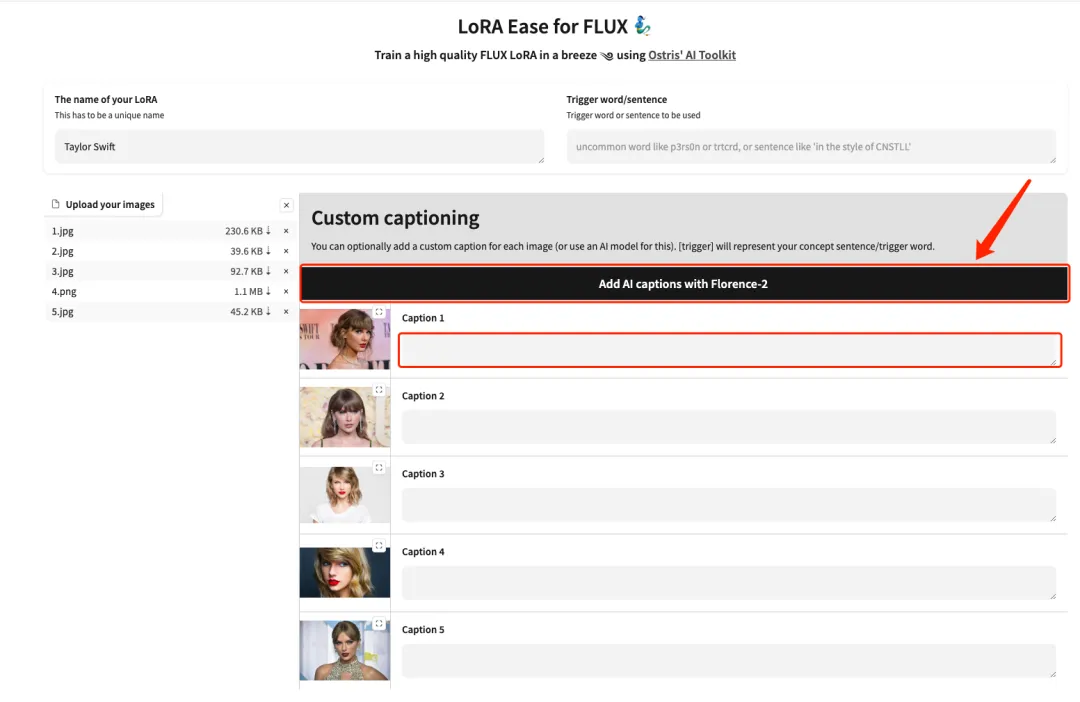
4. بعد نجاح التحميل، قم بإضافة أوصاف نصية باللغة الإنجليزية يدويًا بعد كل صورة، أو انقر فوق "إضافة تسميات توضيحية بالذكاء الاصطناعي مع Florence-2" لإنشاء أوصاف نصية تلقائيًا.
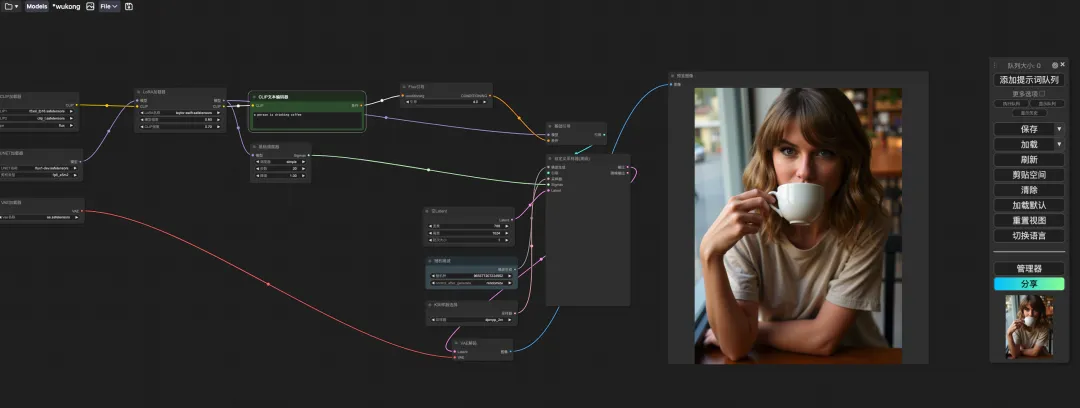
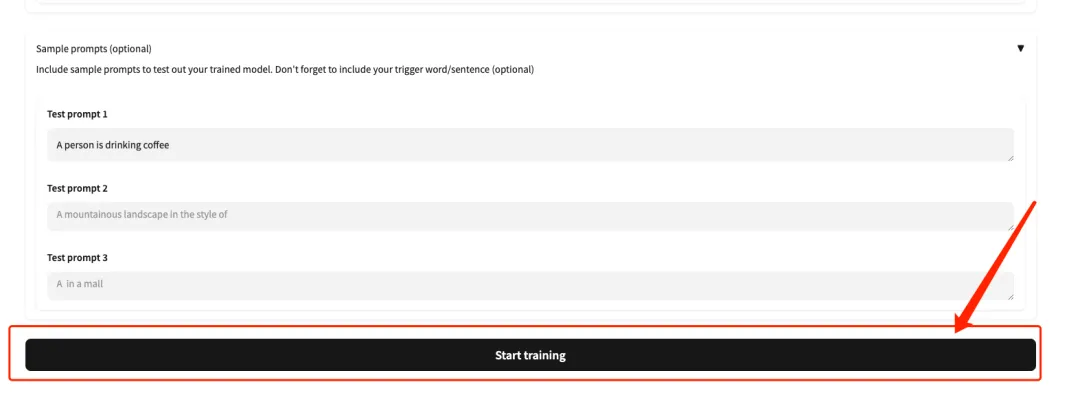
5. قم بالتمرير إلى أسفل الصفحة، وأدخل مطالبة الاختبار (على سبيل المثال: شخص يشرب القهوة)، ثم انقر فوق "بدء التدريب".
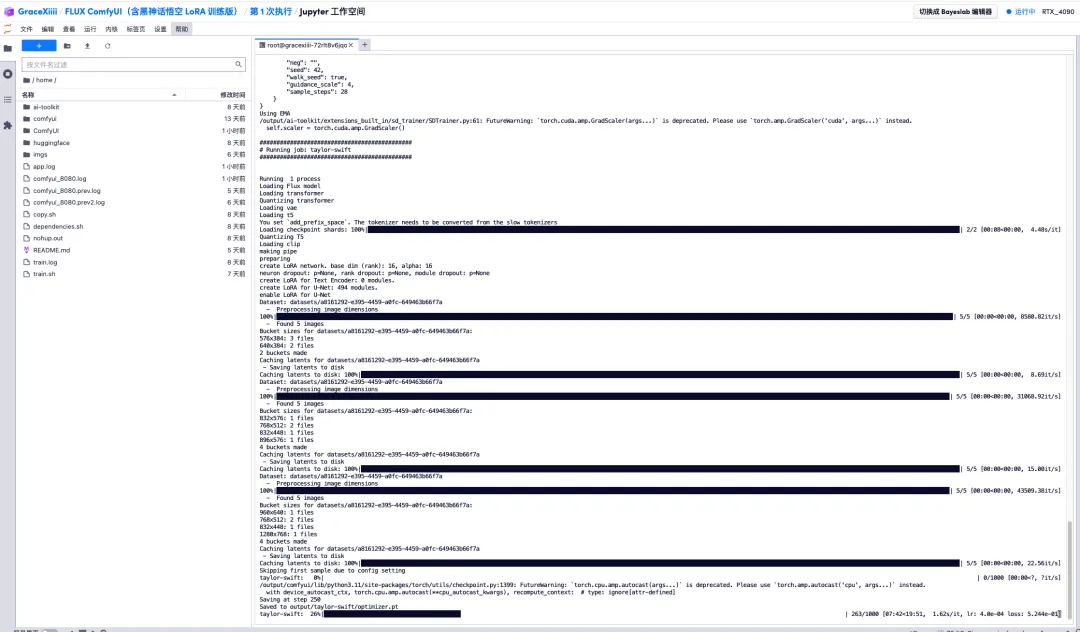
6. بعد الانتظار لبضع دقائق، نعود إلى واجهة المحطة ويمكننا رؤية شريط تقدم التدريب. سيتم الانتهاء من التدريب في حوالي 40 دقيقة. عندما يظهر "تم الحفظ في output/taylor-swift/optimizer.pt"، فهذا يعني اكتمال التدريب.
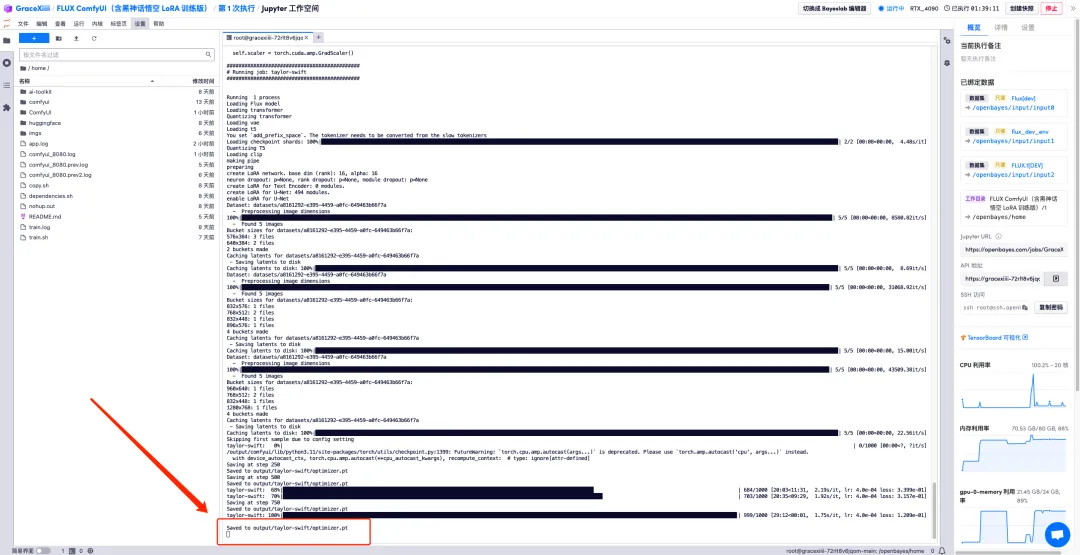
7. في ملف "ai-toolkit" - "output" - "taylor swift" - "sample" على اليسار، يمكنك رؤية تأثير Test Prompt الخاص بنا. إذا كان التأثير جيدًا، فهذا يثبت أن نموذجنا تم تدريبه بنجاح.
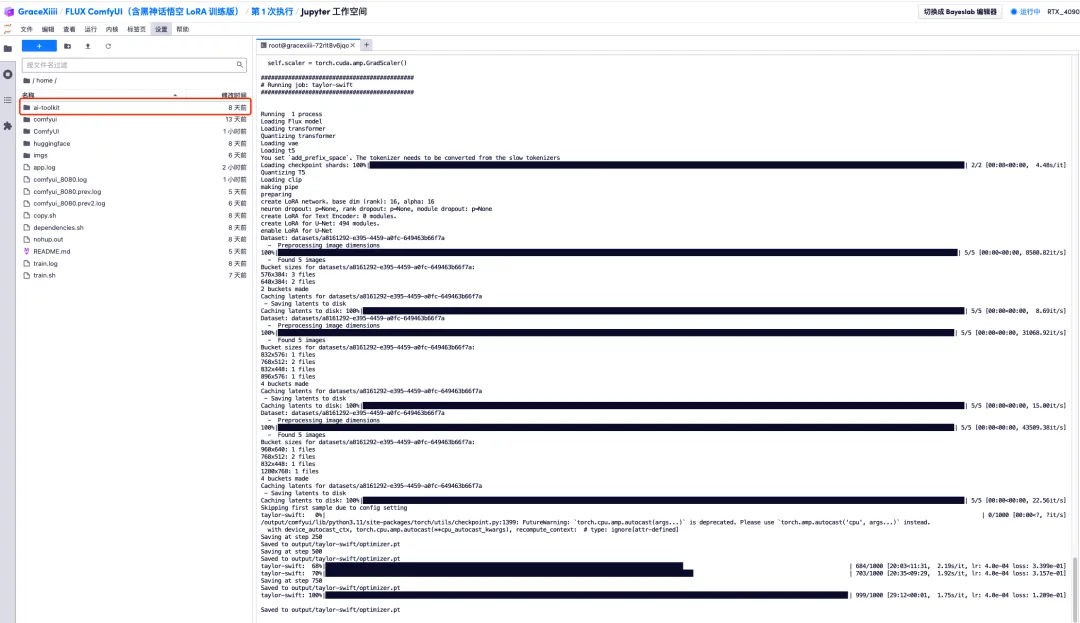
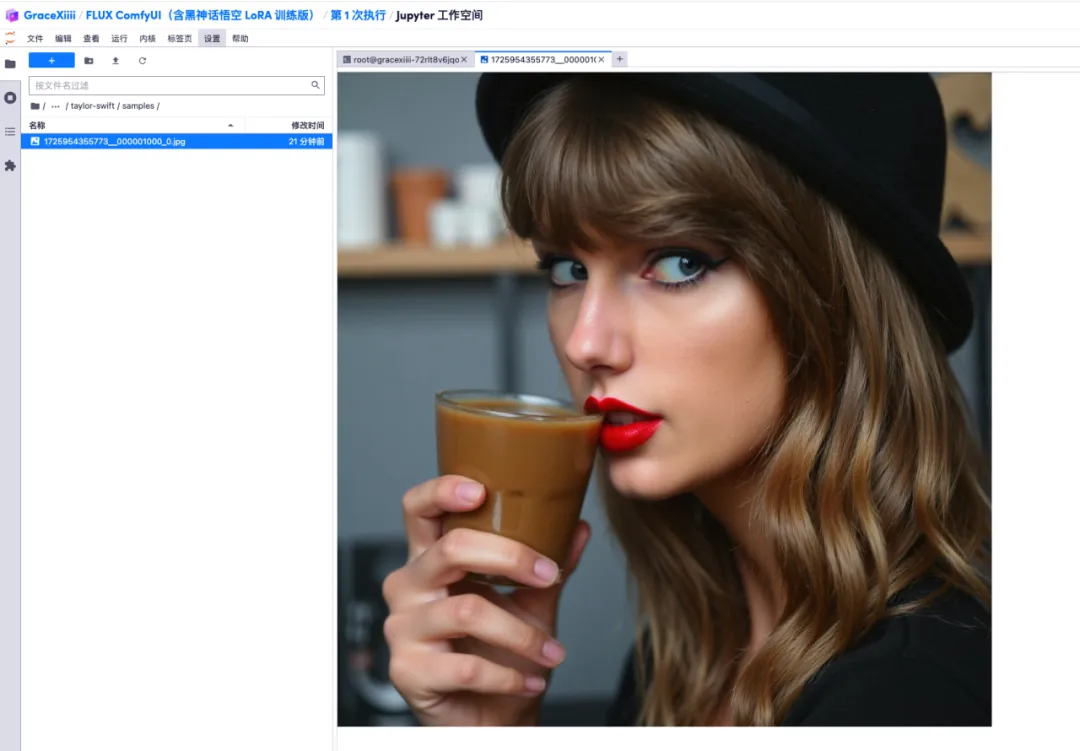
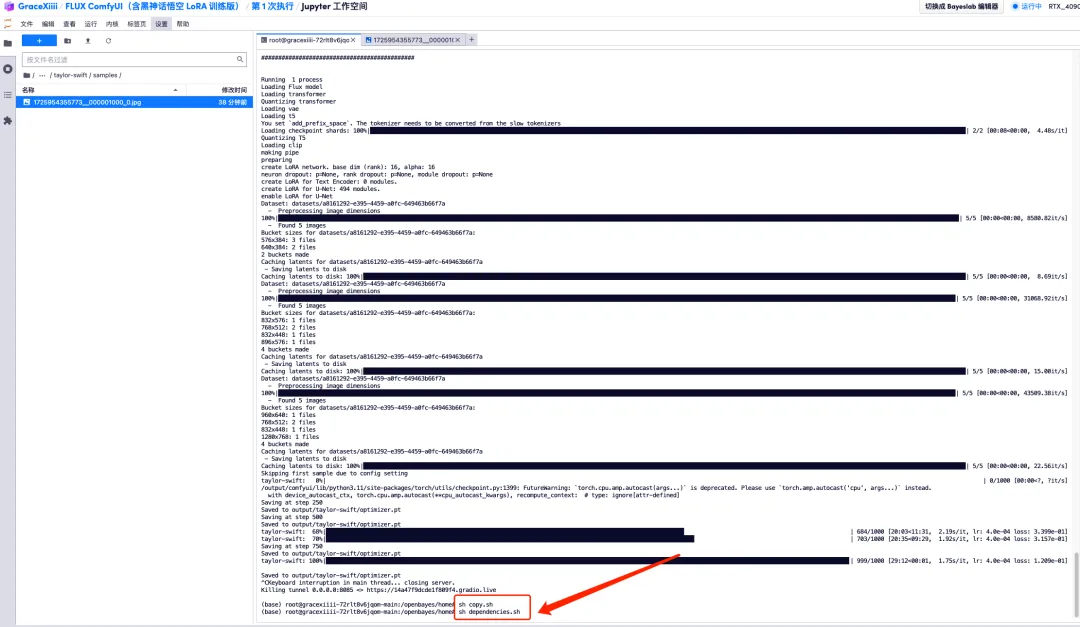
8. بعد تدريب النموذج، نحتاج إلى إيقاف تشغيل خدمة التدريب لتحرير موارد وحدة معالجة الرسومات، والعودة إلى واجهة المفاتيح الآن، والضغط على "Ctrl+C" لإنهاء التدريب.
9. قم بتشغيل "sh copy.sh"، ثم قم بتشغيل "sh dependencies.sh" لبدء ComfyUI، وانتظر لمدة دقيقتين، ثم افتح عنوان API على اليمين.
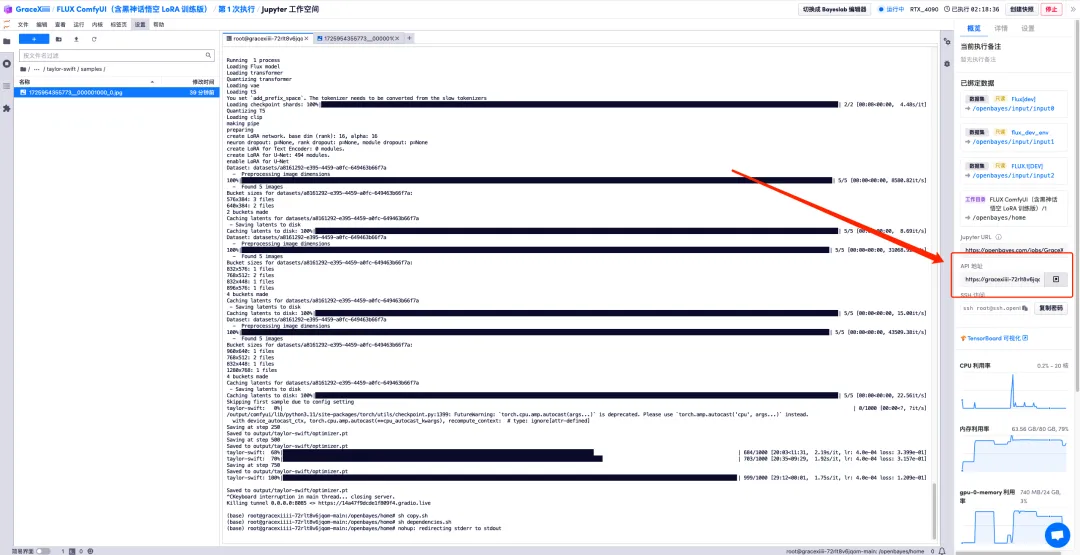
10. بعد الانتقال إلى الصفحة التالية، حدد النموذج المدرب في "LoRA Loader"، وأدخل Prompt (على سبيل المثال: شخص يشرب القهوة) في "CLIP"، وانقر فوق "إضافة قائمة انتظار كلمات المطالبة" لتوليد الصورة.