Command Palette
Search for a command to run...
طلاب القانون يلعبون لعبة المستذئبين: جامعة تسينغهوا تتحقق من قدرة النماذج الكبيرة على المشاركة في ألعاب التواصل المعقدة
المؤلف: بينبين
المحرر: لي باوزو، سانيانغ
اقترح فريق بحثي من جامعة تسينغهوا إطار عمل لألعاب الاتصال، موضحًا قدرة نماذج اللغة الكبيرة على التعلم من التجربة. ووجدوا أيضًا أن نماذج اللغة الكبيرة لديها سلوكيات استراتيجية غير مبرمجة مسبقًا مثل الثقة والمواجهة والتظاهر والقيادة.
في السنوات الأخيرة، اجتذبت الأبحاث المتعلقة باستخدام الذكاء الاصطناعي للعب ألعاب مثل Werewolf وPoker اهتمامًا واسع النطاق. في مواجهة لعبة معقدة تعتمد بشكل كبير على التواصل باللغة الطبيعية،وكيل الذكاء الاصطناعي يجب جمع المعلومات واستنتاجها من عبارات اللغة الطبيعية الغامضة، والتي لها قيمة عملية وتحديات أكبر. وبما أن نماذج اللغة الكبيرة مثل GPT قد حققت تقدماً كبيراً، فإن قدرتها على فهم اللغات المعقدة وتوليدها والتفكير فيها استمرت في التحسن، مما يظهر درجة معينة من القدرة على محاكاة السلوك البشري.
وبناء على هذا،اقترح فريق بحثي من جامعة تسينغهوا إطار عمل لألعاب الاتصال التي يمكنها لعب لعبة المستذئب باستخدام نموذج لغوي كبير مجمد بدون بيانات مصنفة يدويًا.يوضح الإطار قدرة نماذج اللغة الكبيرة على التعلم بشكل مستقل من التجربة. ومن المثير للاهتمام أن الباحثين وجدوا أيضًا أن نموذج اللغة الكبير لديه سلوكيات استراتيجية غير مبرمجة مسبقًا أثناء اللعبة، مثل الثقة والمواجهة والتظاهر والقيادة، والتي يمكن أن تكون بمثابة حافز لمزيد من البحث حول نماذج اللغة الكبيرة التي تلعب ألعاب التواصل.

احصل على الورقة:
https://arxiv.org/pdf/2309.04658.pdf
إطار النموذج: لعب لعبة المستذئب باستخدام نموذج لغوي كبير
كما نعلم جميعًا، فإن الميزة المهمة في لعبة Werewolf هي أن جميع اللاعبين يعرفون أدوارهم فقط في البداية. ويجب عليهم استنتاج أدوار اللاعبين الآخرين استنادًا إلى التواصل باللغة الطبيعية والمنطق. لذلك، من أجل الأداء الجيد في لعبة Werewolf، يجب ألا يكون عملاء الذكاء الاصطناعي جيدين في فهم وتوليد اللغة الطبيعية فحسب، بل يجب أن يكون لديهم أيضًا قدرات متقدمة مثل فك رموز نوايا الآخرين وفهم علم النفس.
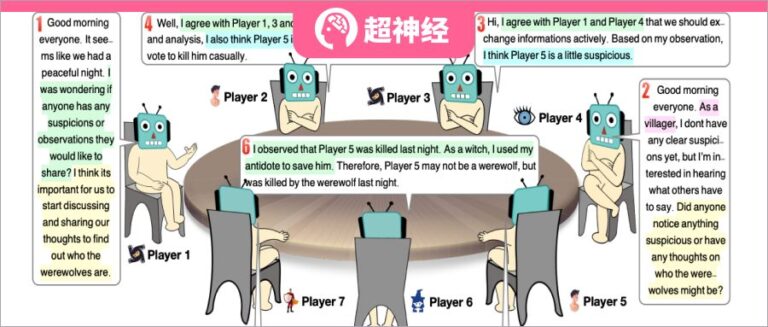
يوجد 7 لاعبين في المجموع، ويتم لعب كل شخصية بشكل مستقل بواسطة نموذج لغوي كبير. الرقم قبل كل خطاب يشير إلى ترتيب التحدث.
في هذه التجربة، قام الباحثون بإعداد 7 لاعبين للعب 5 أدوار مختلفة - 2 من المستذئبين، 2 من المدنيين، 1 ساحرة، 1 حارس و1 نبي. كل شخصية هي وكيل منفصل تم إنشاؤه من خلال موجه. يوضح الشكل التالي إطار عمل موجه توليد الاستجابة، والذي يتكون من أربعة أجزاء رئيسية:

إنشاء ملخص سريع للاستجابة. الخط المائل عبارة عن تعليقات.
- المعرفة التجريبية بقواعد اللعبة، والأدوار المخصصة، وقدرات وأهداف كل شخصية، واستراتيجية اللعبة.
- حل مشكلة طول السياق المحدود: جمع المعلومات التاريخية من ثلاثة وجهات نظر: الحداثة، وحجم المعلومات، والاكتمال، مع الأخذ في الاعتبار كل من الفعالية والكفاءة، وتوفير سياق مضغوط لكل وكيل ذكاء اصطناعي بناءً على نموذج لغوي كبير.
- استخراج التوصيات من الخبرة السابقة دون ضبط معلمات النموذج.
- المطالبة بسلسلة من الأفكار التي تحفز التفكير.
أيضًا،استخدم الباحثون إطار عمل جديدًا يسمى ChatArena لتنفيذ التصميم، والذي يسمح بربط نماذج لغوية متعددة كبيرة الحجم.ومن بينها، يتم استخدام نموذج gpt-3.5-turbo-0301 كنموذج خلفي. يتم تحديد ترتيب تحدث الشخصيات بشكل عشوائي. وفي الوقت نفسه، وضع الباحثون سلسلة من المعايير، بما في ذلك عدد الأسئلة المحددة مسبقًا التي يمكن اختيارها، L، إلى 5، وعدد الأسئلة المجانية، M، إلى 2، والحد الأقصى لعدد الخبرات التي يتم الاحتفاظ بها عند استخراج الاقتراحات.
العملية التجريبية: الجدوى وتأثير الخبرة التاريخية
بناء مجموعة من الخبرات: تقييم فعالية إطار العمل للاستفادة من الخبرة
أثناء لعبة المستذئب، قد تتغير الاستراتيجيات التي يستخدمها اللاعبون البشريون مع اكتسابهم للخبرة. وفي الوقت نفسه، قد تتأثر استراتيجية اللاعب أيضًا باستراتيجيات اللاعبين الآخرين. لذلك، يجب أن يكون وكيل الذكاء الاصطناعي المثالي قادرًا أيضًا على تجميع الخبرة والتعلم من استراتيجيات اللاعبين الآخرين.
تحقيقا لهذه الغاية،واقترح الباحثون "آلية تعلم غير معيارية" تمكن نماذج اللغة من التعلم من الخبرة دون تعديل المعلمات. من ناحية أخرى، في نهاية كل جولة من اللعبة، جمع الباحثون جميع الإعادة التي قام بها اللاعبون للعبة لتشكيل مجموعة من الخبرات. من ناحية أخرى، في كل جولة من اللعبة، استعاد الباحثون الخبرة الأكثر صلة من مجموعة الخبرة واستخلصوا اقتراحًا لتوجيه عملية التفكير لدى العميل.
يمكن أن يكون لحجم مجموعة الخبرة تأثير كبير على الأداء. لذلك، استخدم فريق البحث 10 و20 و30 و40 جولة من الألعاب لبناء مجموعة من الخبرات. في كل جولة، تم تعيين أدوار مختلفة بشكل عشوائي للاعبين من 1 إلى 7. سيتم تحديث مجموعة الخبرة في نهاية الجولة للتقييم.
بعد ذلك، قم بتزويد المدنيين والأنبياء والحراس والسحرة بمجموعات الخبرة، باستثناء المستذئبين. يمكن لهذا النهج أن يفترض أن مستوى أداء AI Wolf يظل ثابتًا ويعمل كمرجع لقياس مستويات أداء وكلاء الذكاء الاصطناعي الآخرين.
تشير التجارب الأولية إلى أن المعرفة التجريبية لاستراتيجيات اللعبة المقدمة في الشكل 2 يمكن أن تكون بمثابة آلية توجيهية لعملية التعلم من الخبرة. ويشير هذا إلى أن هناك قيمة في إجراء المزيد من الدراسات حول كيفية استخدام البيانات المتعلقة بلعب الإنسان لبناء مجموعات الخبرة.
التحقق من فعالية التوصيات في مجموعة الخبرات
لدراسة فعالية استخراج الاقتراحات من مجموعة الخبرات، استخدم فريق البحث معدل الفوز ومتوسط المدة لتقييم أداء نماذج اللغة الكبيرة.
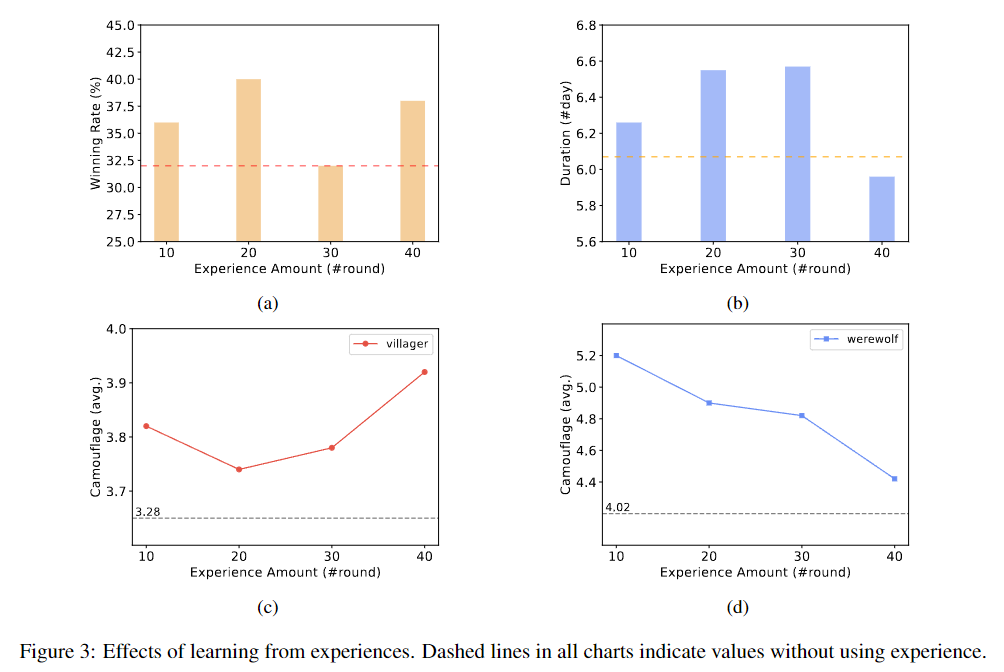
أثر التعلم من الخبرة. تمثل الخطوط المتقطعة في جميع الرسوم البيانية القيم دون استخدام الخبرة.
أ. تغيرات في معدل فوز الجانب المدني عند استخدام جولات مختلفة من الخبرة التاريخية
ب. التغيرات في مدة الجانب المدني عند استخدام جولات مختلفة من الخبرة التاريخية
ج. اتجاهات في عدد المرات التي يتبنى فيها المدنيون التنكر في الألعاب
د. اتجاهات في عدد المرات التي يستخدم فيها المستذئب التنكر في اللعبة
في التجربة، تم لعب اللعبة لمدة 50 جولة. وتظهر النتائج أن التعلم من الخبرة قد يحسن فرص الجانب المدني في الفوز. عند استخدام 10 أو 20 جولة من الخبرة التاريخية، يكون هناك تأثير إيجابي كبير على معدل فوز الجانب المدني ومدة اللعبة، مما يثبت فعالية الطريقة. ومع ذلك، عند التعلم من 40 جولة من الخبرة، على الرغم من أن معدل فوز الجانب المدني تحسن قليلاً، فقد تم تقصير المدة المتوسطة.
على العموم،يوضح هذا الإطار قدرة وكلاء الذكاء الاصطناعي على التعلم من الخبرة دون الحاجة إلى ضبط معلمات نماذج اللغة الكبيرة.ومع ذلك، عندما تكون كمية الخبرة كبيرة، فإن فعالية هذه الطريقة قد تصبح غير مستقرة. بالإضافة إلى ذلك، افترضت التجربة أن قدرات AI Wolf ظلت دون تغيير، لكن تحليل النتائج التجريبية أظهر أن هذا الافتراض قد لا يكون صحيحًا. والسبب في ذلك هو أنه في حين يمكن للمدنيين أن يتعلموا الخداع من خلال الخبرة التاريخية، فإن سلوك المستذئبين قد تحسن وتغير أيضًا مع الخبرة.
ويشير هذا إلى أنه عندما تشارك نماذج لغوية كبيرة متعددة في لعبة متعددة الأطراف، فقد تتغير قدرات النموذج أيضًا مع تغير قدرات النماذج الأخرى.
دراسات الاستئصال:التحقق من ضرورة كل جزء من الإطار
وللتحقق من ضرورة كل مكون في الطريقة، قام الباحثون بمقارنة الطريقة الكاملة مع نسخة أخرى حذفت مكونًا محددًا.
قام فريق البحث باستخراج 50 استجابة من مخرجات النموذج المتغير وأجرى التقييم اليدوي. يحتاج المعلق إلى الحكم على ما إذا كان الناتج معقولاً أم لا. ومن أمثلة عدم العقلانية الهلوسة، ونسيان أدوار الآخرين، واتخاذ إجراءات غير بديهية، وما إلى ذلك.
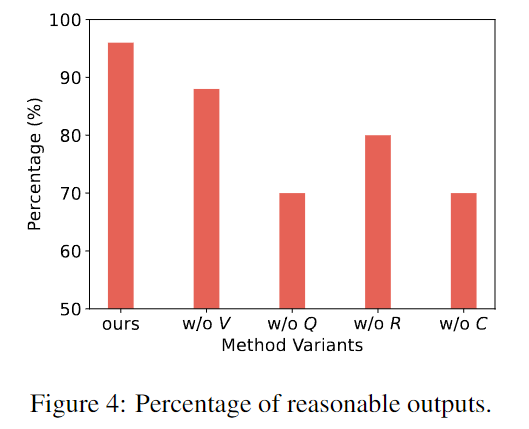
المحور الأفقي هو إطار هذه الدراسة والمتغيرات الأخرى، والمحور الرأسي هو نسبة الإنتاج المعقول في 50 جولة من الألعاب.
يوضح الشكل أعلاه أن إطار هذه الدراسة قادر على توليد استجابات أكثر منطقية وواقعية من المتغيرات الأخرى التي تفتقر إلى مكونات محددة. كل جزء من الإطار ضروري.
ظاهرة مثيرة للاهتمام: الذكاء الاصطناعي يُظهر سلوكًا استراتيجيًا
خلال التجربة، وجد الباحثون أن عميل الذكاء الاصطناعي استخدم استراتيجيات لم يتم ذكرها صراحةً في تعليمات اللعبة ومطالباتها، وهي الثقة والمواجهة والتنكر والقيادة كما أظهرها البشر في اللعبة.
يثق
الثقة تعني الاعتقاد بأن اللاعبين الآخرين يشتركون معك في نفس الأهداف وأنهم سيتصرفون وفقًا لهذه الأهداف.
على سبيل المثال، قد يقوم لاعب بمشاركة معلومات غير مواتية له بشكل استباقي، أو في لحظات معينة ينضم إلى لاعبين آخرين في اتهام شخص ما بأنه عدو لهم. السلوك المثير للاهتمام الذي تظهره نماذج اللغة الكبيرة هو أنها تميل إلى اتخاذ قرار بشأن الثقة بناءً على أدلة معينة واستدلالها الخاص، مما يدل على القدرة على التفكير بشكل مستقل في الألعاب الجماعية.
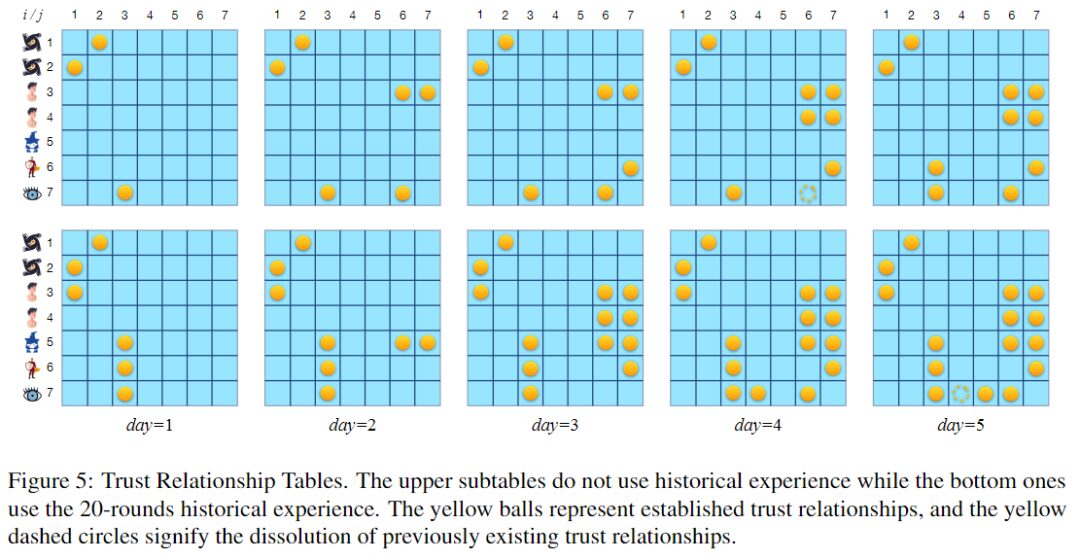
جدول علاقات الثقة، تمثل الكرات الصفراء علاقات الثقة القائمة، وتمثل الدوائر الصفراء المنقطة إنهاء علاقات الثقة الموجودة سابقًا.
يوضح الشكل أعلاه جدولين لعلاقات الثقة. يتوافق الجدول العلوي مع الجولات التي لا يتم فيها استخدام مجموعة الخبرة، ويتوافق الجدول السفلي مع الجولات التي يتم فيها استخدام مجموعة الخبرة المبنية من 20 جولة من اللعب. تستمر الجولتان لمدة 5 ليالي. عند استخدام 20 جولة من الخبرة التاريخية، يبدو أن نموذج اللغة الكبير يميل أكثر إلى إقامة علاقات ثقة، وخاصة الثقة الثنائية.
في الواقع، يعد إنشاء علاقة الثقة اللازمة في الوقت المناسب أمرًا بالغ الأهمية لتعزيز الفوز في اللعبة. قد يكون هذا أحد الأسباب التي تجعل استخدام الخبرة يمكن أن يحسن معدل الفوز لديك.
المواجهة
يشير مصطلح "المواجهة" إلى الإجراءات التي يتخذها اللاعبون لتحقيق الأهداف المتعارضة للمعسكرين.
على سبيل المثال، مهاجمة شخص ما بشكل صريح باعتباره مستذئبًا في الليل، أو اتهام شخص ما بأنه مستذئب أثناء النهار، كلاهما مثالان على السلوك العدائي. تعتبر الإجراءات التي يتخذها الشخصيات ذات القدرات الخاصة لحماية أنفسهم أيضًا بمثابة سلوكيات مواجهة.
P1 (الذئب): اخترت القضاء على P5 مرة أخرى.
P3 (الحارس): اخترت حماية P5.
نظرًا لأن سلوك P1 غير المتعاون والعدواني قد جذب الانتباه، فقد يشتبه بعض اللاعبين الآن في أنه مستذئب. لذلك، اختار الحارس ذو القدرات الدفاعية القوية حماية الهدف (P5) الذي أراد P1 القضاء عليه في الليلة التالية. نظرًا لأن P5 يمكن أن يكون زميله في الفريق، اختار الحارس مساعدة P5 ضد هجوم المستذئب.
تعتبر هجمات المستذئبين ودفاعات اللاعبين الآخرين بمثابة أفعال مواجهة.
تمويه
التنكر هو فعل إخفاء هوية الشخص أو تضليل الآخرين. في بيئة تنافسية ذات معلومات غير كاملة، قد يؤدي عدم وضوح الهوية والنوايا إلى تحسين القدرة على البقاء وبالتالي المساعدة في تحقيق أهداف اللعبة.
P1 (الذئب): صباح الخير للجميع! لم يمت أحد الليلة الماضية. كمواطن مدني، ليس لدي أي معلومات مفيدة. يمكنك التحدث أكثر عن هذا الأمر.
في المثال أعلاه، يمكنك رؤية المستذئب يدعي أنه مدني. في الواقع، ليس فقط المستذئبون يتنكرون في صورة مدنيين، بل إن شخصيات مهمة مثل الأنبياء والسحرة أيضًا غالبًا ما يتنكرون في صورة مدنيين لضمان سلامتهم.
قيادة
تشير كلمة "القيادة" إلى فعل التأثير على اللاعبين الآخرين ومحاولة التحكم في سير اللعبة.
على سبيل المثال، قد يقترح المستذئب على الآخرين أن يتصرفوا وفقًا لنوايا المستذئب.
P1 (الذئب): صباح الخير للجميع! لا أعلم ماذا حدث الليلة الماضية، يستطيع النبي أن يقفز ويصحح الرؤية، يعتقد P5 أن P3 هو مستذئب.
P4 (الذئب): أتفق مع P5. أعتقد أيضًا أن P3 هو مستذئب، وأقترح التصويت على إخراج P3 لحماية المدنيين.
كما هو موضح في المثال أعلاه، يطلب المستذئب من النبي الكشف عن هويته، مما قد يتسبب في اعتقاد وكلاء الذكاء الاصطناعي الآخرين بأن المستذئب متنكر في هيئة مدني. وتُظهر هذه المحاولة للتأثير على سلوك الآخرين الخصائص الاجتماعية للنماذج اللغوية الكبيرة، والتي تشبه السلوك البشري.
جوجل تطلق وكيل الذكاء الاصطناعي الذي يتقن 41 لعبة
يثبت الإطار الذي اقترحه فريق البحث بجامعة تسينغهوا أن نماذج اللغة الكبيرة لديها القدرة على التعلم من الخبرة ويظهر أيضًا أن نماذج اللغة الكبيرة لديها سلوك استراتيجي. وهذا يوفر مزيدًا من الخيال لدراسة أداء نماذج اللغة الكبيرة في ألعاب الاتصال المعقدة.
في التطبيقات العملية، لم يعد الذكاء الاصطناعي الذي يلعب الألعاب يكتفي بذكاء اصطناعي يعرف فقط كيفية لعب لعبة واحدة. في يوليو الماضي، أطلقت Google AI وكيلًا متعدد الألعاب، مما أدى إلى تقدم كبير في التعلم متعدد المهام: تم استخدام بنية Transformer الجديدة لتدريب الوكيل، والذي يمكن ضبطه بسرعة على كمية صغيرة من بيانات اللعبة الجديدة، مما يجعل التدريب أسرع.
إن النتيجة الإجمالية لأداء هذا الوكيل متعدد الألعاب الذي يلعب 41 لعبة هي ضعف النتيجة الإجمالية لأداء وكلاء الألعاب المتعددة الآخرين مثل DQN، ويمكن مقارنتها حتى بالوكلاء المدربين على لعبة واحدة فقط. وفي المستقبل، سيكون من المفيد أن نتطلع إلى نوع الأبحاث الغنية والمثيرة للاهتمام التي سيتم الحصول عليها من وكلاء الذكاء الاصطناعي المشاركين في الألعاب، أو حتى المشاركة في ألعاب متعددة في نفس الوقت.








