HyperAI
Command Palette
Search for a command to run...
Papers
최신 AI 트렌드를 파악할 수 있도록 매일 업데이트되는 최첨단 AI 연구 논문

모달 간의 충돌 시: 단모달 추론 불확실성이 MLLM에서 선호 동역학을 어떻게 지배하는가

시각적 표현을 일치시키며 VLA를 망각하지 마라: OOD 일반화를 위한 접근
























모달 간의 충돌 시: 단모달 추론 불확실성이 MLLM에서 선호 동역학을 어떻게 지배하는가
시각적 표현을 일치시키며 VLA를 망각하지 마라: OOD 일반화를 위한 접근
시각화가 추론의 첫 번째 단계일 때: 시각적 체인오브사고를 위한 MIRA 벤치마크
VCode: SVG를 기호적 시각 표현으로 사용한 다중모달 코딩 벤치마크
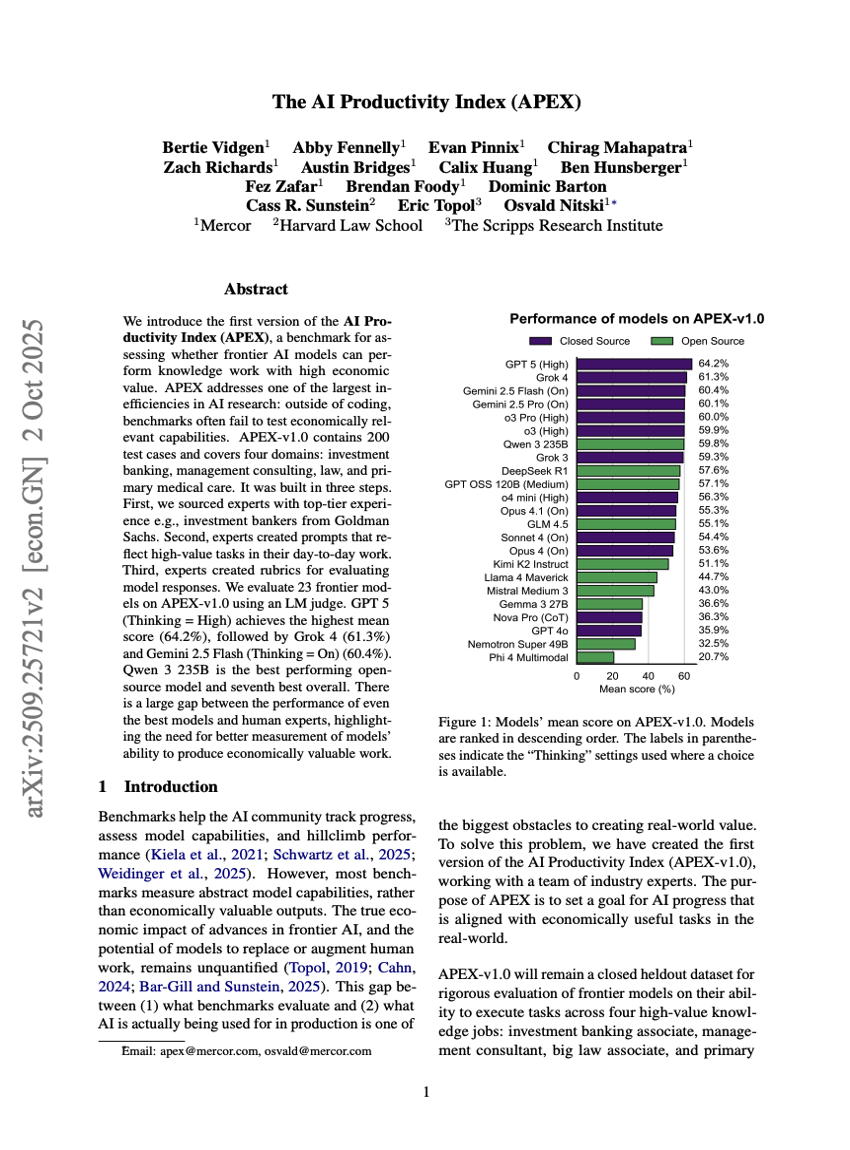
인공지능 생산성 지수(APEX)
프레임 체인: 프레임 인지 추론을 통한 다중모달 LLM의 영상 이해 기술 향상
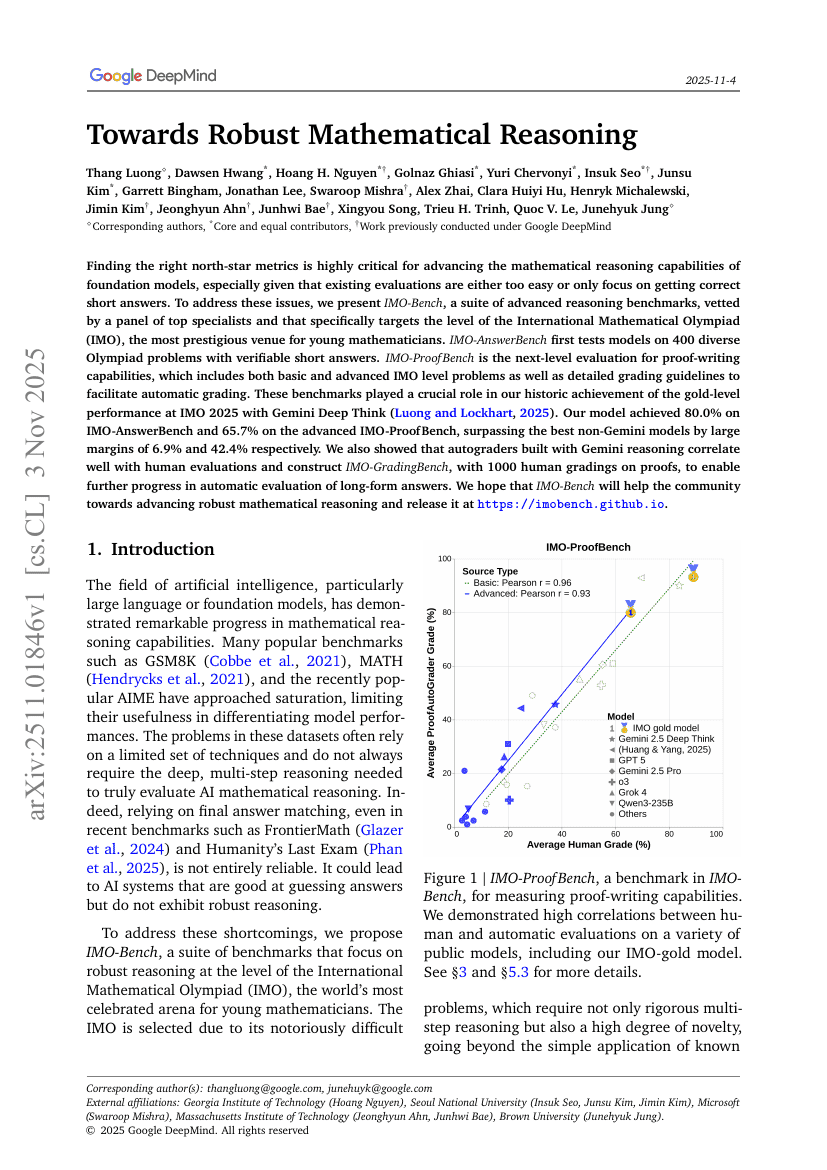
강건한 수학적 추론을 향하여
미래 공간 기반의 고도로 확장 가능한 인공지능 인프라 시스템 설계를 향하여
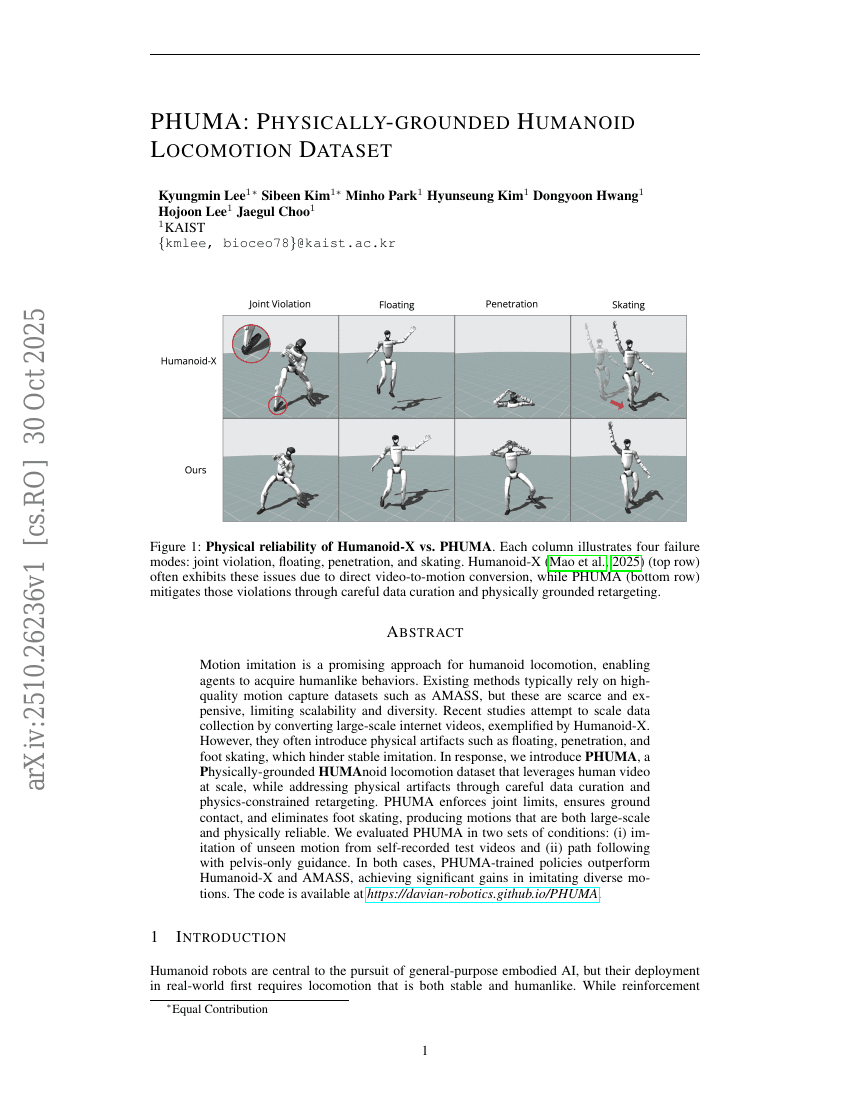
PHUMA: 물리기반 인체형 보행 데이터셋
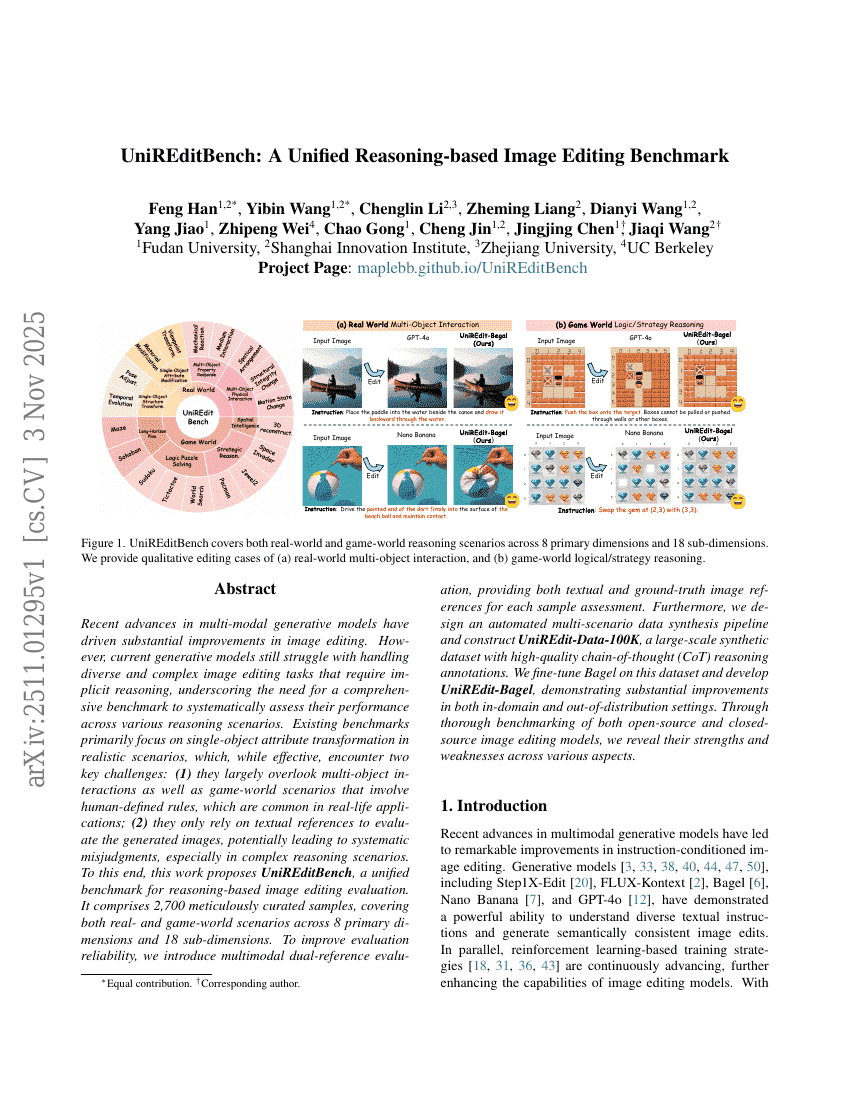
UniREditBench: 통합 추론 기반 이미지 편집 벤치마크
테스트 시 Compute-최적 스케일링을 최적화 가능한 그래프로 일반화하기
UniLumos: 물리학적으로 타당한 피드백을 통한 빠르고 통합적인 이미지 및 비디오 재조명
그래프 구조 이해를 위한 시각 모델의 간과된 힘
모든 활성화를 강화하다: 일반 추론기를 1조 개의 개방형 언어 기반으로 확장하기
NOBLE - 생물학적으로 정보가 반영된 잠재 임베딩을 갖는 신경 연산자: 생물학적 뉴런 모델에서의 실험 변이를 포착하기 위해
글리아: 자동 시스템 설계 및 최적화를 위한 인간 영감형 AI
컨텍스트 엔지니어링 2.0: 컨텍스트 엔지니어링의 맥락
공간-SSRL: 자기지도 강화학습을 통한 공간 인지 향상
지속형 자기회귀 언어 모델
πextttRL: 흐름 기반 시각-언어-행동 모델을 위한 온라인 강화학습 미세조정
INT 대비 FP: 미세한 비트 수준 양자화 형식에 대한 종합적 연구
ThinkMorph: 다중모달 혼합 사고 체인의 부상하는 특성
OS-Sentinel: 현실적인 워크플로우에서 하이브리드 검증을 통한 안전성 향상된 모바일 GUI 에이전트로의 도전
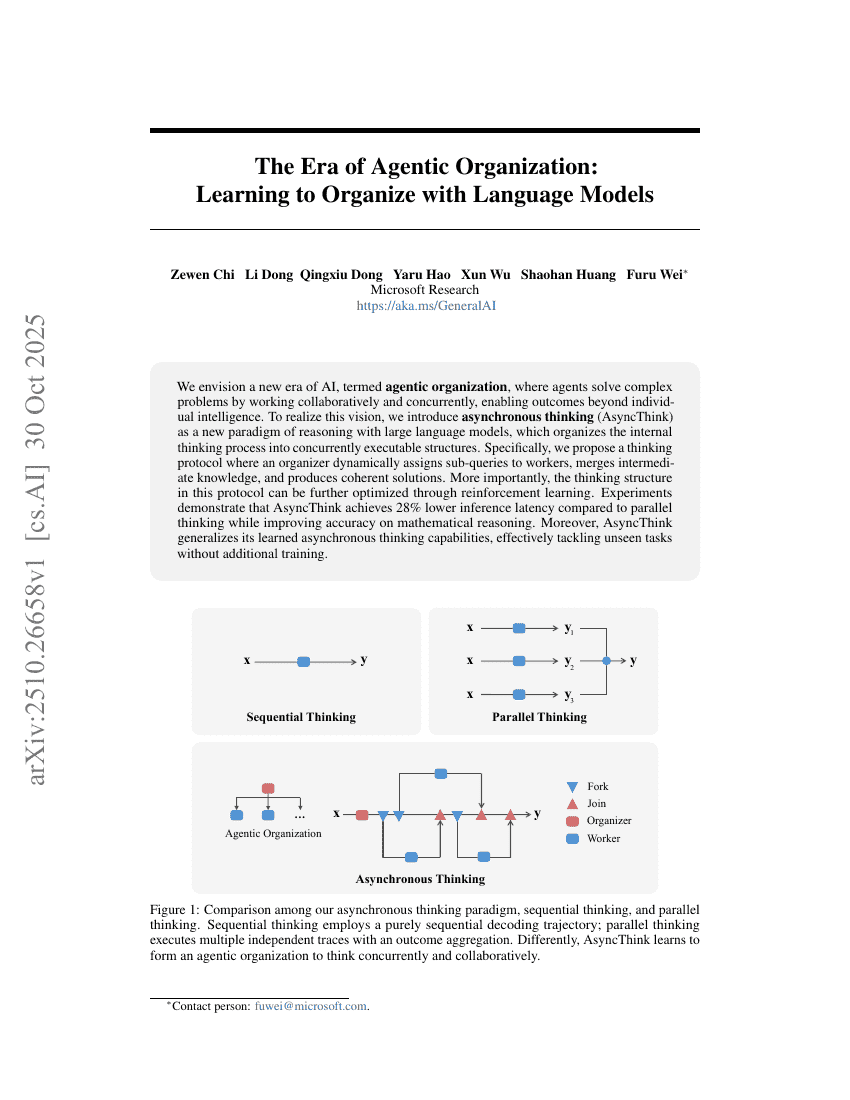
에이전트 조직의 시대: 언어 모델과 함께 조직하는 법을 배우며
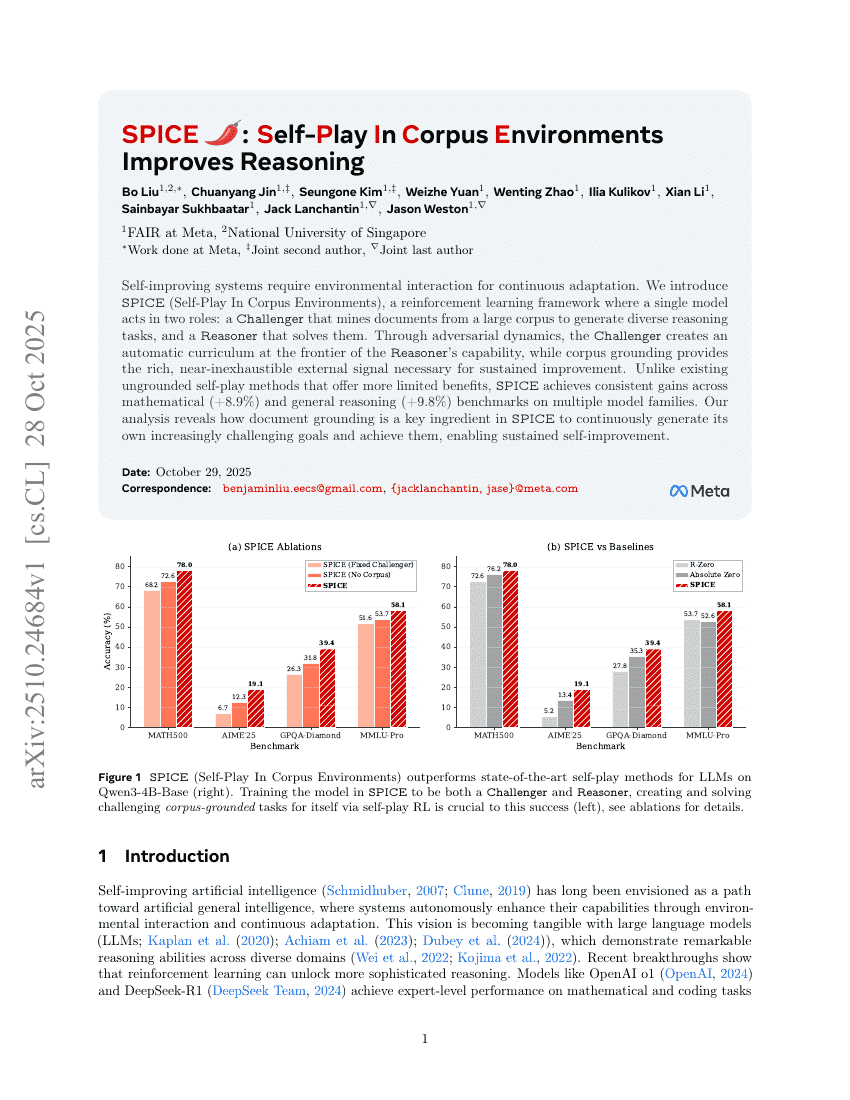
SPICE: 코퍼스 환경에서의 자기대전(self-play)이 추론 능력을 향상시킨다
Surfer 2: 다음 세대의 다중 플랫폼 컴퓨터 사용 에이전트
로보틱 제어에서 확산 모델의 적용 조건 탐색
에이전트는 웹을 정복할 수 있는가? ChatGPT Atlas 에이전트의 웹 게임에서의 경계를 탐색한다
Kimi Linear: 표현력 있고 효율적인 어텐션 아키텍처
에무3.5: 내장형 다중모달 모델은 세계를 학습하는 모델이다
수동 디코딩의 종말: 진정한 엔드투엔드 언어 모델로의 도전
인간-인공지능 상호보완성: 증강된 감시를 위한 목표
시각화가 추론의 첫 번째 단계일 때: 시각적 체인오브사고를 위한 MIRA 벤치마크
VCode: SVG를 기호적 시각 표현으로 사용한 다중모달 코딩 벤치마크
인공지능 생산성 지수(APEX)
프레임 체인: 프레임 인지 추론을 통한 다중모달 LLM의 영상 이해 기술 향상
강건한 수학적 추론을 향하여
미래 공간 기반의 고도로 확장 가능한 인공지능 인프라 시스템 설계를 향하여
PHUMA: 물리기반 인체형 보행 데이터셋
UniREditBench: 통합 추론 기반 이미지 편집 벤치마크
테스트 시 Compute-최적 스케일링을 최적화 가능한 그래프로 일반화하기
UniLumos: 물리학적으로 타당한 피드백을 통한 빠르고 통합적인 이미지 및 비디오 재조명
그래프 구조 이해를 위한 시각 모델의 간과된 힘
모든 활성화를 강화하다: 일반 추론기를 1조 개의 개방형 언어 기반으로 확장하기
NOBLE - 생물학적으로 정보가 반영된 잠재 임베딩을 갖는 신경 연산자: 생물학적 뉴런 모델에서의 실험 변이를 포착하기 위해
글리아: 자동 시스템 설계 및 최적화를 위한 인간 영감형 AI
컨텍스트 엔지니어링 2.0: 컨텍스트 엔지니어링의 맥락
공간-SSRL: 자기지도 강화학습을 통한 공간 인지 향상
지속형 자기회귀 언어 모델
πextttRL: 흐름 기반 시각-언어-행동 모델을 위한 온라인 강화학습 미세조정
INT 대비 FP: 미세한 비트 수준 양자화 형식에 대한 종합적 연구
ThinkMorph: 다중모달 혼합 사고 체인의 부상하는 특성
OS-Sentinel: 현실적인 워크플로우에서 하이브리드 검증을 통한 안전성 향상된 모바일 GUI 에이전트로의 도전
에이전트 조직의 시대: 언어 모델과 함께 조직하는 법을 배우며
SPICE: 코퍼스 환경에서의 자기대전(self-play)이 추론 능력을 향상시킨다
Surfer 2: 다음 세대의 다중 플랫폼 컴퓨터 사용 에이전트
로보틱 제어에서 확산 모델의 적용 조건 탐색
에이전트는 웹을 정복할 수 있는가? ChatGPT Atlas 에이전트의 웹 게임에서의 경계를 탐색한다
Kimi Linear: 표현력 있고 효율적인 어텐션 아키텍처
에무3.5: 내장형 다중모달 모델은 세계를 학습하는 모델이다
수동 디코딩의 종말: 진정한 엔드투엔드 언어 모델로의 도전
인간-인공지능 상호보완성: 증강된 감시를 위한 목표