HyperAI
Command Palette
Search for a command to run...
Papers
최신 AI 트렌드를 파악할 수 있도록 매일 업데이트되는 최첨단 AI 연구 논문

LongStraw: 고정 GPU 예산 하에서 2백만 토큰을 넘어서는 장문맥 강화학습

원격 탐사에서의 딥러닝: 리뷰

























LongStraw: 고정 GPU 예산 하에서 2백만 토큰을 넘어서는 장문맥 강화학습
원격 탐사에서의 딥러닝: 리뷰
심층 신경망 기반 음성 향상을 위한 회귀 접근법
음성 인식에서 음향 모델링을 위한 심층 신경망
RoboTTT: 로봇 정책을 위한 컨텍스트 스케일링
SWE-agent: 에이전트-컴퓨터 인터페이스를 통한 자동화된 소프트웨어 공학
벡터 공간에서 단어 표현의 효율적 추정
다중 스케일 심층망을 이용한 단일 영상 깊이 맵 예측
TabNet: 주의 집중 기반 해석 가능한 테이블 데이터 학습
AudioPaLM: 말하고 들을 수 있는 대규모 언어 모델
SQuAD: 기계 독해를 위한 10만 개 이상의 질문 데이터셋
DeepPose: 심층 신경망을 통한 인간 자세 추정
현대 에이전트 시스템의 자기 개선: 서베이
에이전트 강화 학습을 위한 단일 롤아웃 비동기 최적화
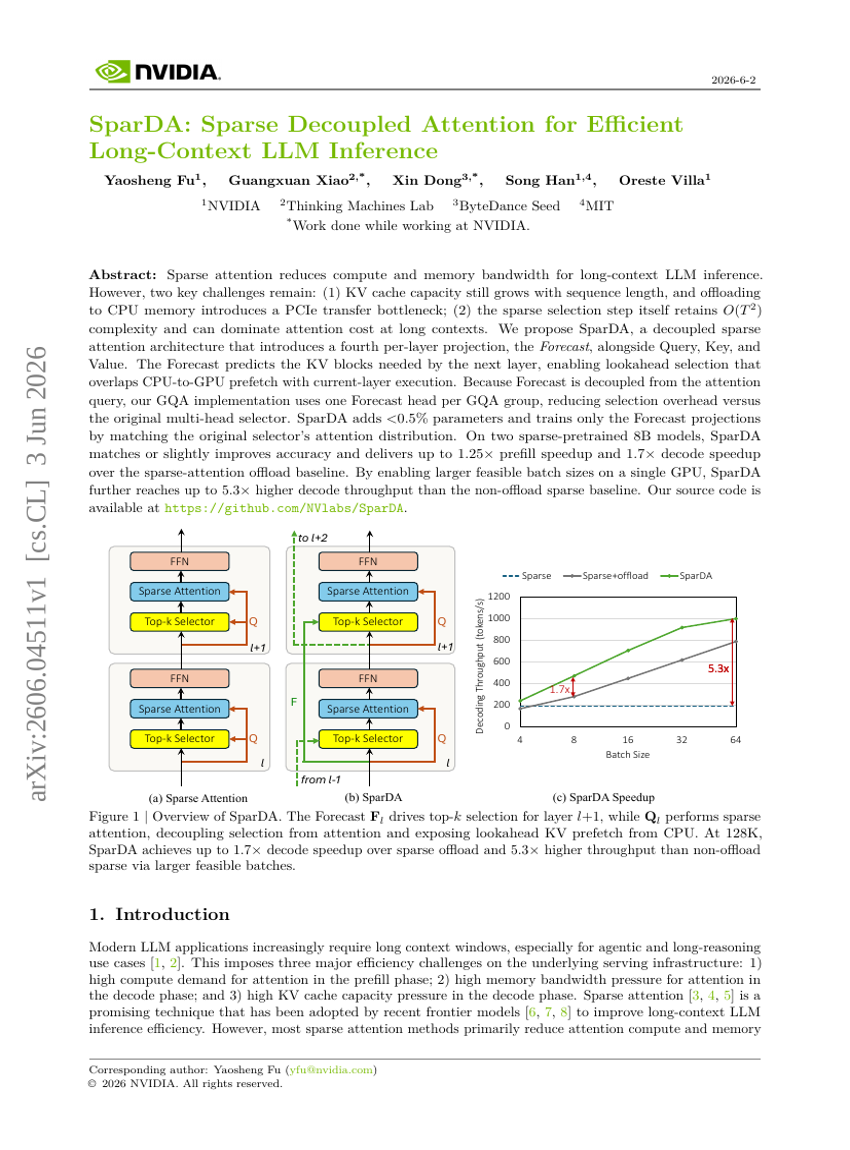
SparDA: 효율적인 장문 LLM 추론을 위한 희소 분리형 어텐션
MetaView: 스케일 인지 암시적 기하학 사전 정보를 활용한 단안 신규 시점 합성
PolicyShiftGuard: 정책 적응형 이미지 가드레일 벤치마킹 및 개선
KnowAct-GUIClaw: 깊이 알고 완벽하게 행동하라, 자기 진화형 메모리와 기술을 갖춘 개인 GUI 어시스턴트
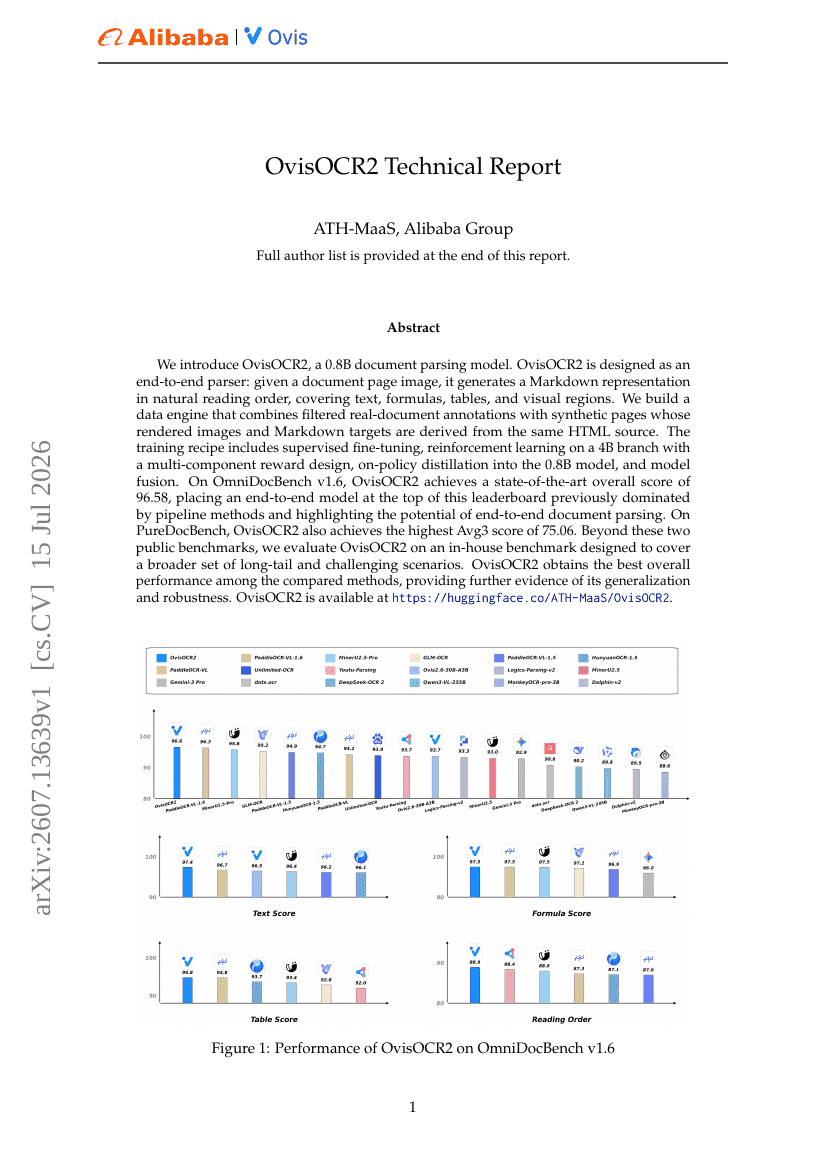
OvisOCR2 기술 보고서
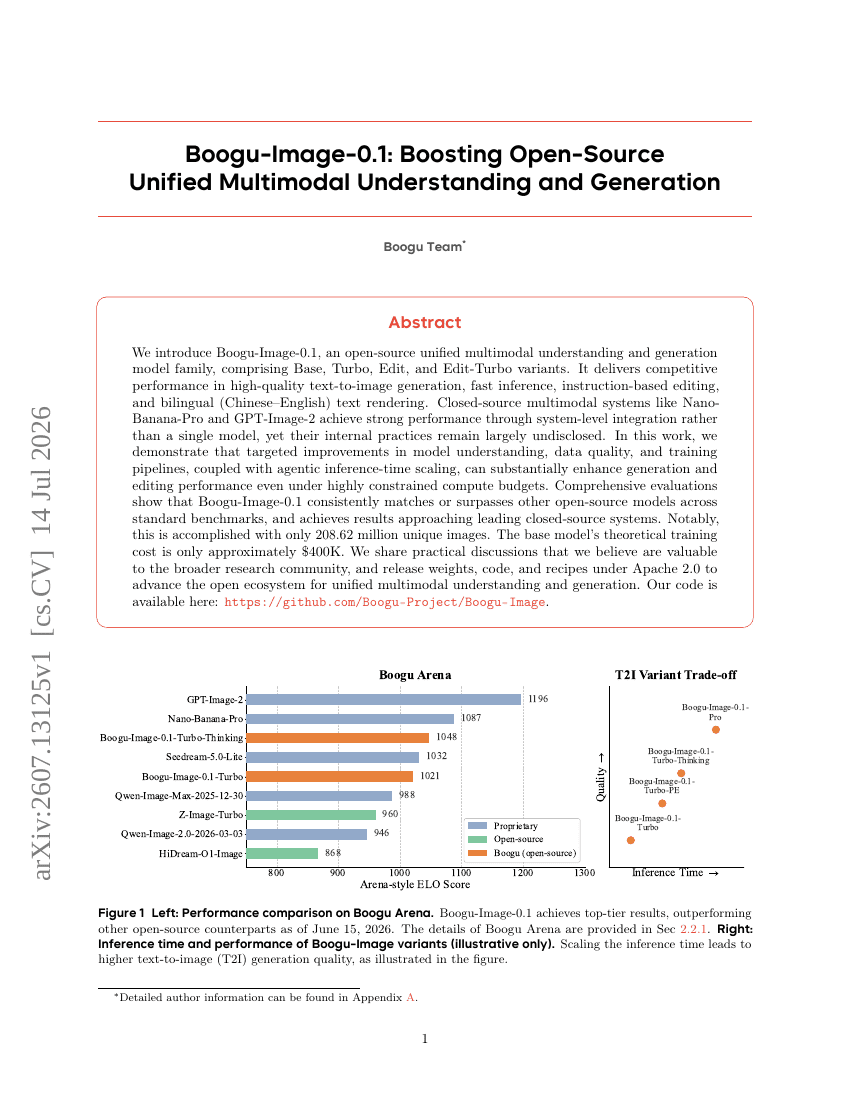
Boogu-Image-0.1: 오픈소스 통합 멀티모달 이해 및 생성 모델의 성능 향상
하네스 핸드북: 진화하는 에이전트 하네스를 읽기 쉽고, 탐색 가능하며, 편집 가능하게 만들기
Qwen-Music 기술 보고서
탐색, 정제 및 모델 병합을 위한 스펙트럼 재배선
에이전트를 위한 하네스 진화 평가의 재고
Ring-Zero: 창발적 추론을 위한 1조 파라미터 규모로의 제로 RL 확장
순환형 트랜스포머를 통한 잠재적 추론과 명시적 추론 간 격차 해소
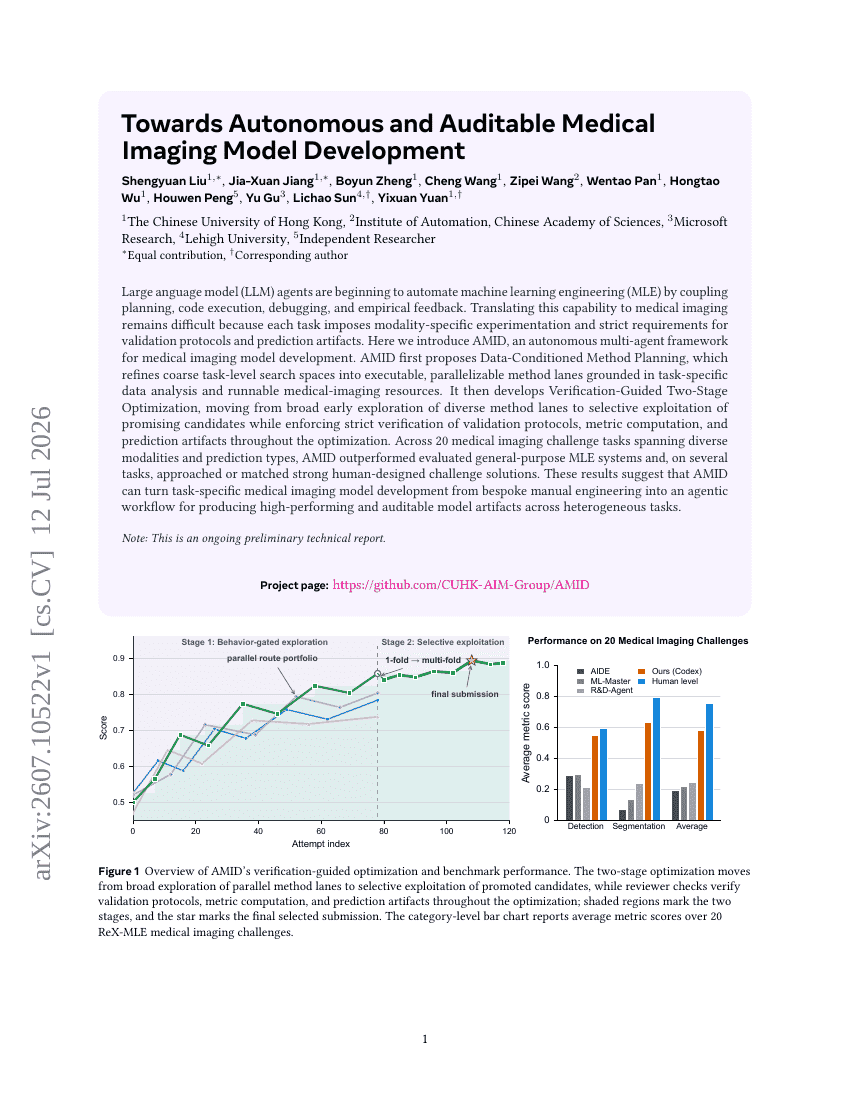
자율적이고 감사 가능한 의료 영상 모델 개발을 향하여
MuScriptor: 다중 악기 음악 채보를 위한 개방형 모델
심층 강화 학습 평가 및 설계 패러다임에 대한 원칙적 분석
고치기 전에 알라: 소프트웨어 이슈 해결을 위한 QA 기반 저장소 지식 습득
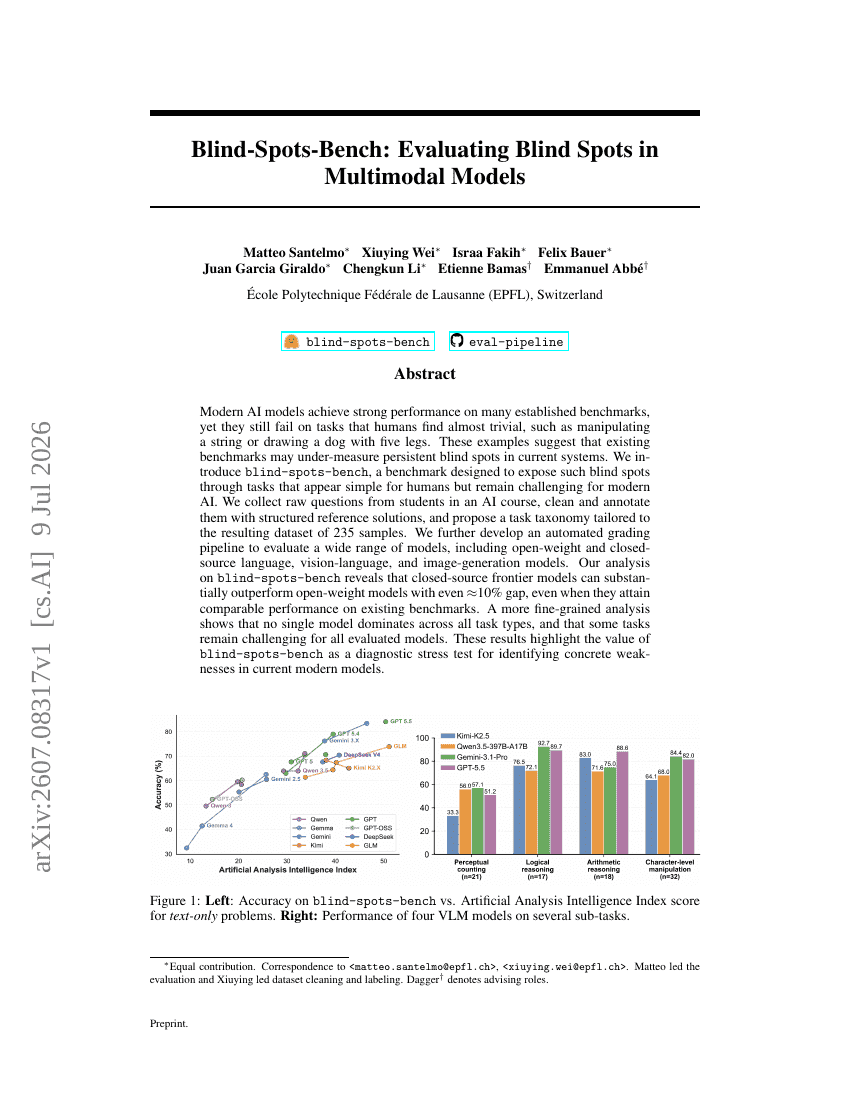
Blind-Spots-Bench: 멀티모달 모델의 맹점 평가
Read It Back: 사전 학습된 MLLM은 텍스트-이미지 생성을 위한 제로샷 보상 모델이다
심층 신경망 기반 음성 향상을 위한 회귀 접근법
음성 인식에서 음향 모델링을 위한 심층 신경망
RoboTTT: 로봇 정책을 위한 컨텍스트 스케일링
SWE-agent: 에이전트-컴퓨터 인터페이스를 통한 자동화된 소프트웨어 공학
벡터 공간에서 단어 표현의 효율적 추정
다중 스케일 심층망을 이용한 단일 영상 깊이 맵 예측
TabNet: 주의 집중 기반 해석 가능한 테이블 데이터 학습
AudioPaLM: 말하고 들을 수 있는 대규모 언어 모델
SQuAD: 기계 독해를 위한 10만 개 이상의 질문 데이터셋
DeepPose: 심층 신경망을 통한 인간 자세 추정
현대 에이전트 시스템의 자기 개선: 서베이
에이전트 강화 학습을 위한 단일 롤아웃 비동기 최적화
SparDA: 효율적인 장문 LLM 추론을 위한 희소 분리형 어텐션
MetaView: 스케일 인지 암시적 기하학 사전 정보를 활용한 단안 신규 시점 합성
PolicyShiftGuard: 정책 적응형 이미지 가드레일 벤치마킹 및 개선
KnowAct-GUIClaw: 깊이 알고 완벽하게 행동하라, 자기 진화형 메모리와 기술을 갖춘 개인 GUI 어시스턴트
OvisOCR2 기술 보고서
Boogu-Image-0.1: 오픈소스 통합 멀티모달 이해 및 생성 모델의 성능 향상
하네스 핸드북: 진화하는 에이전트 하네스를 읽기 쉽고, 탐색 가능하며, 편집 가능하게 만들기
Qwen-Music 기술 보고서
탐색, 정제 및 모델 병합을 위한 스펙트럼 재배선
에이전트를 위한 하네스 진화 평가의 재고
Ring-Zero: 창발적 추론을 위한 1조 파라미터 규모로의 제로 RL 확장
순환형 트랜스포머를 통한 잠재적 추론과 명시적 추론 간 격차 해소
자율적이고 감사 가능한 의료 영상 모델 개발을 향하여
MuScriptor: 다중 악기 음악 채보를 위한 개방형 모델
심층 강화 학습 평가 및 설계 패러다임에 대한 원칙적 분석
고치기 전에 알라: 소프트웨어 이슈 해결을 위한 QA 기반 저장소 지식 습득
Blind-Spots-Bench: 멀티모달 모델의 맹점 평가
Read It Back: 사전 학습된 MLLM은 텍스트-이미지 생성을 위한 제로샷 보상 모델이다