Command Palette
Search for a command to run...
구현된 지능에 관한 자료 모음: 로봇 학습 데이터 세트, 온라인 세계 모델링 경험, NVIDIA, ByteDance, Xiaomi 등의 최신 연구 논문 등이 포함되어 있습니다.

지난 10년간 인공지능의 주요 경쟁 분야가 "세상을 이해하는 것"과 "콘텐츠를 생성하는 것"이었다면, 다음 단계의 핵심 과제는 더욱 도전적인 문제로 옮겨가고 있습니다.인공지능이 어떻게 진정으로 물리적 세계에 진입하여 그 안에서 행동하고, 학습하고, 진화할 수 있을까요?"체화된 지능"이라는 용어는 관련 연구 및 논의에서 자주 등장합니다.
이름에서 알 수 있듯이, 체화된 지능은 전통적인 로봇과는 다릅니다.대신, 지능은 지각, 의사 결정 및 행동의 폐쇄 루프 내에서 에이전트와 환경 간의 상호 작용을 통해 형성된다는 점을 강조합니다.이러한 관점에서 지능은 더 이상 모델 매개변수나 추론 능력에만 존재하는 것이 아니라 센서, 액추에이터, 환경 피드백 및 장기 학습에 깊이 내재되어 있습니다. 로봇 공학, 자율 주행, 에이전트, 심지어 인공 일반 지능(AGI)에 대한 논의까지 모두 이 프레임워크에 포함됩니다.
이러한 이유로 지난 2년간 글로벌 기술 대기업과 주요 연구 기관들은 체화된 지능에 큰 관심을 기울여 왔습니다. 테슬라 CEO 일론 머스크는 휴머노이드 로봇 옵티머스가 자율 주행 못지않게 중요하다고 거듭 강조했고, 엔비디아 창립자 젠슨 황은 물리 인공지능을 생성형 인공지능 이후의 차세대 기술로 보고 로봇 시뮬레이션 및 훈련 플랫폼에 막대한 투자를 지속하고 있습니다. 리페이페이, 르쿤 얀 등은 공간 지능, 세계 모델 등의 하위 분야에서 수준 높은 최첨단 분석 및 연구 결과를 꾸준히 발표하고 있으며, 오픈AI, 구글 딥마인드, 메타 또한 멀티모달 모델, 강화 학습 등의 기술을 기반으로 실제 또는 준실제 환경에서 지능형 에이전트의 학습 능력을 탐구하고 있습니다.
이러한 배경에서, 체화된 지능은 더 이상 단일 모델이나 알고리즘의 문제가 아니라, 데이터 세트, 시뮬레이션 환경, 벤치마크 작업 및 체계적인 방법론으로 구성된 연구 생태계로 점차 발전해 왔습니다. 더 많은 독자들이 이 분야의 핵심 흐름을 빠르게 이해할 수 있도록,본 논문에서는 체화된 지능과 관련된 고품질 데이터 세트, 온라인 튜토리얼 및 논문들을 체계적으로 정리하고 추천하여, 향후 학습 및 연구를 위한 참고 자료를 제공하고자 한다.
데이터셋 추천
1. BC-Z 로봇 학습 데이터 세트
예상 크기:32.28 GB
다운로드 주소:https://go.hyper.ai/vkRel

이 데이터셋은 구글, 에브리데이 로봇, UC 버클리, 스탠포드 대학교가 공동으로 개발한 대규모 로봇 학습 데이터셋입니다. 100가지의 다양한 작업 시나리오를 포괄하는 25,877개 이상의 데이터를 포함하고 있습니다. 이러한 작업들은 12대의 로봇과 7명의 작업자가 참여한 전문가 수준의 원격 조작 및 자율 프로세스 공유를 통해 수집되었으며, 총 125시간의 로봇 작동 시간을 기록했습니다. 이 데이터셋은 작업에 대한 언어적 설명이나 작업자의 조작 영상을 기반으로 조정하여 특정 작업을 수행할 수 있는 7자유도 다중 작업 정책 학습을 지원합니다.
2.DexGraspVLA 로봇 파악 데이터 세트
예상 크기:7.29 GB
다운로드 주소:https://go.hyper.ai/G37zQ

Psi-Robot 팀이 제작한 이 데이터셋은 데이터 형식 이해, 코드 실행 및 학습 과정 경험을 위해 51개의 인간 시연 데이터 샘플을 포함하고 있습니다. 이 연구는 특히 미지의 물체, 조명, 배경이 조합된 복잡한 환경에서 민첩한 파지 동작의 성공률을 높이는 데 초점을 맞추었습니다. 목표는 901 TP3T 이상의 성공률을 달성하는 것입니다. 본 프레임워크는 사전 학습된 시각-언어 모델을 고수준 작업 계획기로 사용하고, 확산 기반 정책을 저수준 동작 제어기로 학습합니다. 이 프레임워크의 혁신성은 기본 모델을 활용하여 강력한 일반화 능력을 구현하고, 확산 기반 모방 학습을 통해 민첩한 동작을 습득하는 데 있습니다.
3.EgoThink: 1인칭 시각적 질문 답변 벤치마크 데이터 세트
예상 크기:865.29MB
다운로드 주소:https://go.hyper.ai/5PsDP

칭화대학교에서 제안한 이 데이터셋은 1인칭 시점의 시각적 질문 답변 벤치마크 데이터셋으로, 6가지 핵심 역량을 포괄하는 700개의 이미지로 구성되어 있으며 12개의 차원으로 세분화되어 있습니다. 이미지는 Ego4D 1인칭 비디오 데이터셋에서 추출되었으며, 데이터의 다양성을 확보하기 위해 각 비디오에서 최대 두 개의 이미지만 추출했습니다. 데이터셋 구축 과정에서 1인칭 시점 사고를 명확하게 보여주는 고품질 이미지만을 선별했습니다. EgoThink는 특히 1인칭 시점 작업에서 시각 학습 모델(VLM)의 성능을 평가하고 개선하는 데 폭넓게 활용될 수 있으며, 향후 체화된 인공지능 및 로봇 공학 연구에 귀중한 자원을 제공할 것입니다.
4.EQA 질의응답 데이터세트
예상 크기:839.6KB
다운로드 주소:https://go.hyper.ai/8Uv1o
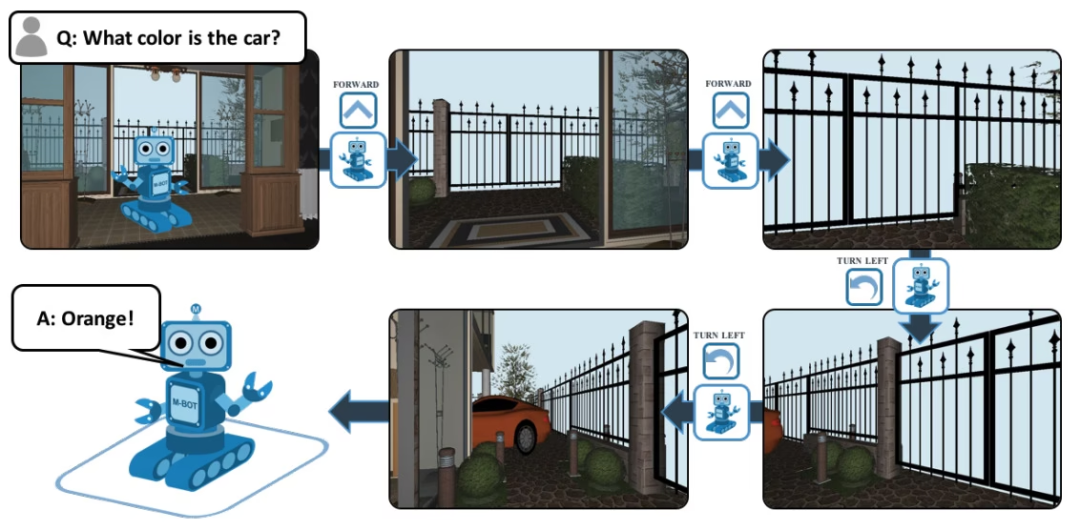
EQA는 Embodied Question Answering의 약자로, House3D를 기반으로 한 시각적 질문 답변 데이터 세트입니다. 질문을 받은 후, 환경 내 어느 위치에 있는 에이전트도 해당 환경에서 유용한 정보를 찾아 질문에 답할 수 있습니다. 예를 들어: 질문: 자동차의 색깔은 무엇입니까? 이 질문에 답하려면 에이전트는 먼저 지능형 탐색 기능을 통해 환경을 탐색하고, 1인칭 관점에서 필요한 시각적 정보를 수집한 다음, '주황색'이라는 질문에 답해야 합니다.
5. 옴니리타겟 글로벌 로봇
모션 리매핑 데이터셋
예상 크기:349.61MB
다운로드 주소:https://go.hyper.ai/IloBI

이 데이터셋은 아마존이 MIT, UC 버클리 및 기타 기관과 협력하여 공개한 휴머노이드 로봇의 전신 동작 리매핑을 위한 고품질 궤적 데이터셋입니다. G1 휴머노이드 로봇이 물체 및 복잡한 지형과 상호작용하는 동작 궤적을 포함하며, 물체 운반, 지형 보행, 물체-지형 혼합 상호작용의 세 가지 시나리오를 다룹니다. 라이선스 제한으로 인해 공개된 데이터셋에는 LAFAN1의 리매핑 버전은 포함되어 있지 않습니다. 이 데이터셋은 총 약 4시간 분량의 동작 궤적 데이터를 포함하는 세 개의 하위 데이터셋으로 구성되어 있습니다.
* 로봇-객체: OMOMO 3.0 데이터에서 도출된 로봇이 운반하는 물체의 궤적;
* 로봇 지형: 내부 모션 캡처 데이터 수집을 통해 생성된 복잡한 지형에서의 로봇 이동 궤적(약 0.5시간 소요);
* 로봇-물체-지형: 이는 물체의 이동 궤적이 지형과 상호 작용하는 것을 포함하며, 약 0.5시간 동안 진행됩니다.
또한, 데이터 세트에는 모델 디렉토리가 포함되어 있으며, 이는 학습용이 아닌 표시용으로 URDF, SDF, OBJ 형식의 시각적 모델 파일을 제공합니다.
더 많은 고품질 데이터 세트를 보려면 다음을 참조하십시오.https://hyper.ai/datasets
튜토리얼 추천
물리적 세계에서의 인지, 이해, 계획 및 행동을 구현하기 위해 체화된 인공지능(embodied AI) 연구는 종종 여러 모델과 모듈을 조합하여 수행합니다. 이러한 모델에는 세계 모델과 추론 모델이 포함됩니다. 본 논문에서는 특히 다음 두 가지 최신 오픈 소스 모델을 추천합니다.
더 많은 고품질 튜토리얼을 보려면 여기를 클릭하세요.https://hyper.ai/notebooks
1.HY-World 1.5: 상호작용형 세계 모델링 시스템을 위한 프레임워크
HY-World 1.5(WorldPlay)는 텐센트의 훈위안 팀에서 출시한 최초의 오픈 소스 실시간 인터랙티브 월드 모델로, 장기적인 기하학적 일관성을 제공합니다. 이 모델은 스트리밍 비디오 확산 기술을 통해 실시간 인터랙티브 월드 모델링을 구현하며, 기존 방식의 속도와 메모리 사용량 간의 상충 관계를 해결합니다.
온라인으로 실행:https://go.hyper.ai/qsJVe
2.vLLM+Open WebUI 배포 네모트론-3 나노
Nemotron-3-Nano-30B-A3B-BF16은 NVIDIA에서 처음부터 자체 개발한 대규모 언어 모델(LLM)입니다. 추론 및 비추론 작업 모두에 적용 가능한 통합 모델로 설계되었으며, 주로 AI 에이전트 시스템, 챗봇, RAG(검색 증강 생성) 시스템 및 기타 다양한 AI 애플리케이션 구축에 사용됩니다.
온라인으로 실행:https://go.hyper.ai/6SK6n
논문 추천
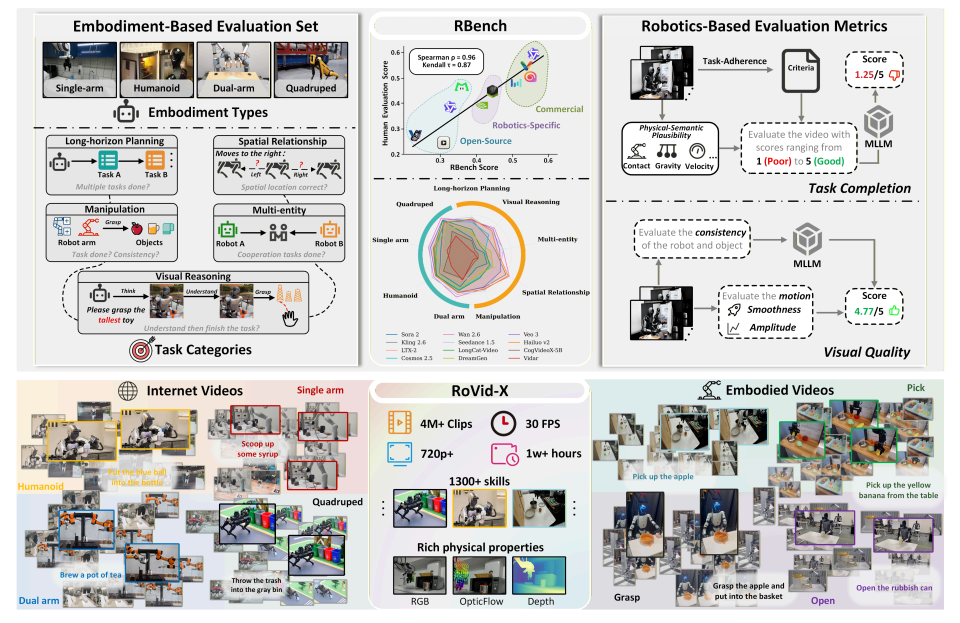
- RBench
논문 제목:몸으로 체현된 세계를 위한 비디오 생성 모델 재고찰
연구팀:베이징대학교, 바이트댄스 시드
논문 보기:https://go.hyper.ai/k1oMT
연구 요약:
연구팀은 5가지 작업 영역과 4가지 로봇 형태를 포괄하는 로봇 비디오 생성 종합 벤치마크인 RBench를 제안했습니다. RBench는 작업 수준의 정확성과 시각적 충실도라는 두 가지 차원에서 로봇 비디오 생성 성능을 평가하며, 구조적 일관성, 물리적 타당성, 동작 완전성 등 재현 가능한 여러 하위 지표를 사용합니다. 25개의 대표적인 비디오 생성 모델에 대한 평가 결과는 기존 방법들이 물리적으로 현실적인 로봇 동작을 생성하는 데 여전히 상당한 한계를 가지고 있음을 보여줍니다. 또한, RBench와 인간 평가 간의 스피어만 상관계수가 0.96에 달하여 모델 품질 측정에 있어 벤치마크의 효과성을 입증합니다.
또한, 본 연구에서는 현재까지 가장 큰 오픈 소스 로봇 비디오 생성 데이터 세트인 RoVid-X를 구축했습니다. RoVid-X는 수천 가지 작업을 다루는 400만 개의 주석이 달린 비디오 클립과 포괄적인 물리적 속성 주석으로 구성되어 있습니다.
2. 존재-H0.5
논문 제목:Being-H0.5: 다양한 신체 환경에 적용 가능한 일반화를 위한 인간 중심 로봇 학습 확장
연구팀:비욘드
논문 보기:https://go.hyper.ai/pW24B
연구 요약:
연구팀은 다양한 로봇 플랫폼에서 강력한 일반화 및 구현 능력을 달성하도록 설계된 비전-언어-행동(VLA) 모델인 Being-H0.5를 제안했습니다. 기존 VLA 모델은 로봇 형태의 상당한 차이와 가용 데이터 부족과 같은 문제로 인해 한계가 있는 경우가 많습니다. 이러한 문제를 해결하기 위해 연구팀은 인간의 상호작용 궤적을 물리적 상호작용 분야의 보편적인 "모국어"로 취급하는 인간 중심 학습 패러다임을 제안했습니다.
동시에, 연구팀은 현재까지 가장 규모가 큰 실체 기반 사전 훈련 솔루션 중 하나인 UniHand-2.0을 공개했는데, 이는 30가지 로봇 형태에 걸쳐 35,000시간 이상의 멀티모달 데이터를 포함하고 있습니다. 방법론적인 측면에서, 연구팀은 서로 다른 로봇의 이질적인 제어 방식을 의미적으로 정렬된 동작 슬롯에 매핑하는 통합 동작 공간(Unified Action Space)을 제안하여, 자원이 부족한 로봇이 인간의 데이터와 자원이 풍부한 플랫폼으로부터 기술을 신속하게 전수하고 학습할 수 있도록 했습니다.

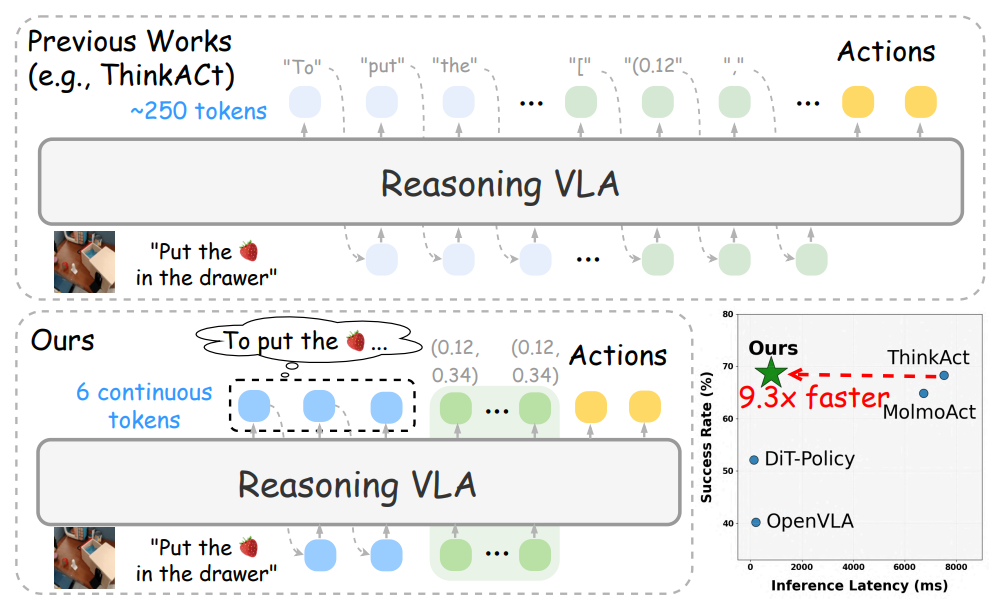
3. 빠른 사고 행동
논문 제목:Fast-ThinkAct: 언어화 가능한 잠재적 계획을 통한 효율적인 시각-언어-행동 추론
연구팀:엔비디아
논문 보기:https://go.hyper.ai/q1h7j
연구 요약:
연구팀은 언어적 잠재 추론 메커니즘을 통해 성능을 유지하면서 더욱 간결한 계획 프로세스를 구현하는 효율적인 추론 프레임워크인 Fast-ThinkAct를 제안했습니다. Fast-ThinkAct는 교사 모델에서 잠재적 CoT(Critical Outcome Time)를 추출하여 효율적인 추론 능력을 학습하고, 선호도 기반 목표 함수에 따라 운영 궤적을 정렬함으로써 언어적 및 시각적 계획 능력을 구체화된 제어로 전환합니다.
다양한 실제 연산 및 추론 작업을 포괄하는 광범위한 실험 결과는 Fast-ThinkAct가 장기 계획 기능, 적은 샘플 적응성 및 오류 복구 기능을 유지하면서 현재 최첨단 추론 기반 VLA 모델에 비해 추론 지연 시간을 최대 89.31 TP3T까지 줄여 성능을 크게 향상시켰음을 보여줍니다.
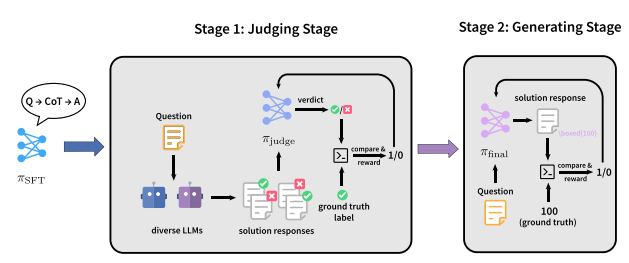
4. JudgeRLVR
논문 제목:JudgeRLVR: 효율적인 추론을 위해 먼저 판단하고, 그 다음에 생성합니다.
연구팀:베이징대학교, 샤오미
논문 보기:https://go.hyper.ai/2yCxp
연구 요약:
연구팀은 "먼저 판별하고 그 다음 생성하는" 2단계 훈련 패러다임인 JudgeRLVR을 제안했습니다. 첫 번째 단계에서는 검증 가능한 답변을 가진 문제 해결 응답을 판별하고 평가하는 모델을 훈련합니다. 두 번째 단계에서는 판별 모델을 초기값으로 사용하여 표준 생성형 RLVR을 통해 동일한 모델을 미세 조정합니다.
동일한 수학적 영역의 훈련 데이터에 사용되는 바닐라 RLVR과 비교했을 때, JudgeRLVR은 Qwen3-30B-A3B에서 더 나은 품질-효율성 균형을 달성합니다. 동일 영역 내 수학적 작업에서는 평균 정확도가 약 3.7% 포인트 향상되는 반면 평균 생성 시간은 42% 감소합니다. 또한, 다른 영역 벤치마크에서는 평균 정확도가 약 4.5% 포인트 향상되어 더 강력한 일반화 능력을 보여줍니다.
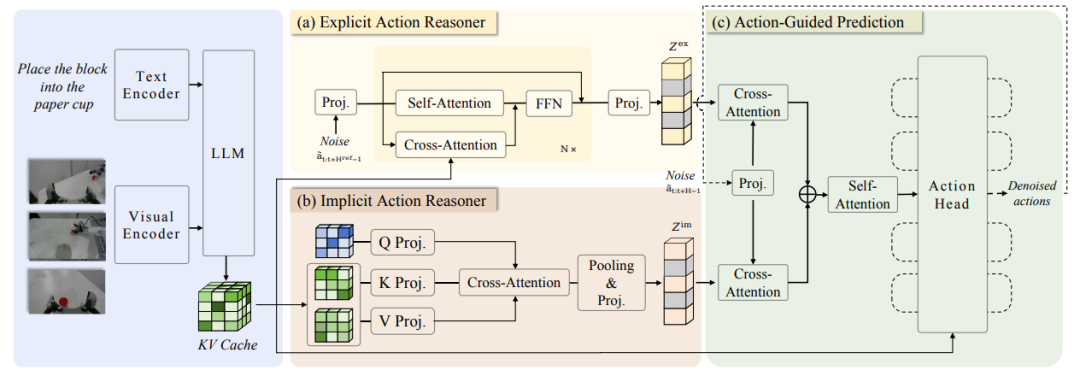
5. ACoT-VLA
논문 제목:ACoT-VLA: 비전-언어-행동 모델을 위한 행동 사고 연쇄
연구팀:베이징 항공우주대학교, AgiBot
논문 보기:https://go.hyper.ai/2jMmY
연구 요약:
연구팀은 먼저 추론 과정 자체를 최종 정책 생성을 안내하는 일련의 구조화된 거시적 행동 의도로 모델링하는 행동 사고 연쇄(ACoT) 모델을 제안했습니다. 그런 다음 ACoT 패러다임을 구체화한 새로운 모델 아키텍처인 ACoT-VLA를 추가로 제안했습니다.
이 설계는 두 가지 상호 보완적인 핵심 구성 요소인 명시적 행동 추론기(EAR)와 암묵적 행동 추론기(IAR)를 도입합니다. EAR은 명시적인 행동 수준 추론 단계 형태로 대략적인 참조 궤적을 제시하고, IAR은 멀티모달 입력의 내부 표현에서 잠재적 행동 사전 정보를 추출합니다. 이 둘은 함께 ACoT를 구성하고 하위 행동 헤드에 조건부 입력으로 작용하여 착륙 제약 조건을 고려한 정책 학습을 달성합니다.
실제 환경과 시뮬레이션 환경 모두에서 수행된 광범위한 실험 결과는 이 방법의 상당한 이점을 입증하며, LIBERO, LIBEROPlus 및 VLABench 벤치마크에서 각각 98.51 TP3T, 84.11 TP3T 및 47.41 TP3T의 점수를 달성했습니다.
최신 논문을 확인하세요:https://hyper.ai/papers








