Command Palette
Search for a command to run...
이번 주 논문 소식 | ProgramBench는 AI가 처음부터 소프트웨어를 작성할 수 있도록 지원하며, 9개의 주요 모델이 일제히 실패했습니다. ExoActor는 추가적인 실제 데이터 없이도 뛰어난 장면 일반화 능력을 보여주었습니다… 이번 주 최첨단 AI 논문들을 간략하게 살펴보겠습니다.

장기적인 소프트웨어 개발에서 언어 모델의 사용이 증가함에 따라, 기존 벤치마크로는 시스템 아키텍처 설계, 모듈 분할 및 전반적인 엔지니어링 구현에서의 성능을 측정하기에 더 이상 충분하지 않습니다. 이러한 문제를 해결하기 위해 SWE-Bench 팀은 ProgramBench 벤치마크를 제안했습니다. 이 벤치마크는 모델에게 실행 파일과 사용 설명서만 제공하고, 모델이 코드를 다시 작성하여 프로그램의 동작을 재현하도록 요구합니다.
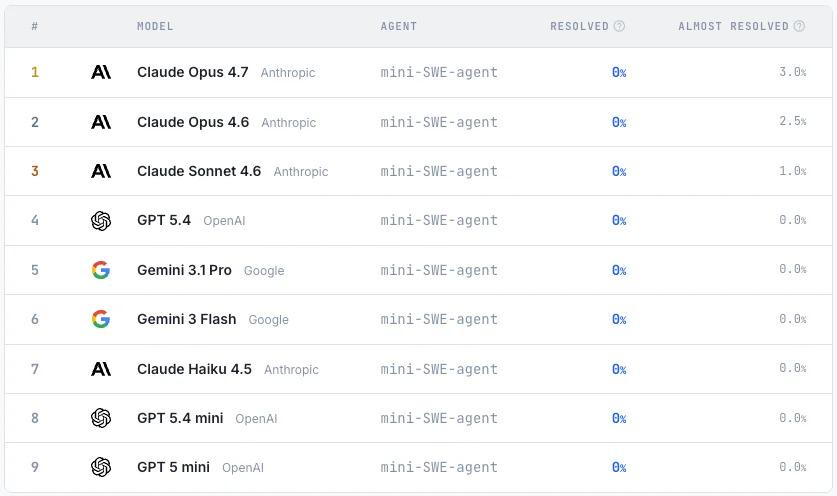
본 연구에서는 데이터베이스, 컴파일러, 명령줄 도구 등 다양한 소프트웨어 유형을 포괄하는 200개의 작업을 구성하고, 동작 테스트를 통해 모델이 생성한 프로그램과 원본 프로그램 간의 일관성을 평가했습니다.실험 결과에 따르면 현재 주류 모델들은 여전히 복잡한 소프트웨어 재구성 작업을 완료하는 데 어려움을 겪고 있으며, 모든 테스트를 통과하는 모델은 없습니다.가장 뛰어난 성능을 보인 Claude Opus 4.7조차도 몇몇 작업에서만 높은 통과율을 달성했는데, 이는 대규모 언어 모델이 전반적인 소프트웨어 엔지니어링 능력 측면에서 여전히 상당한 한계를 가지고 있음을 나타냅니다.
논문 링크:https://go.hyper.ai/wExzR
최신 AI 논문:https://go.hyper.ai/hzChC
더 많은 사용자들이 학계의 인공지능 분야 최신 동향을 이해할 수 있도록 돕기 위해,HyperAI 웹사이트(hyper.ai)에 최신 AI 연구 논문으로 정기적으로 업데이트되는 "최신 논문" 섹션이 추가되었습니다.추천할 만한 인기 AI 논문 8편을 소개합니다. 이번 주 최신 AI 성과를 간단히 살펴보겠습니다 ⬇️
이번 주 논문 추천
1. 프로그램벤치
논문 제목:
ProgramBench: 언어 모델로 프로그램을 처음부터 다시 만들 수 있을까요?
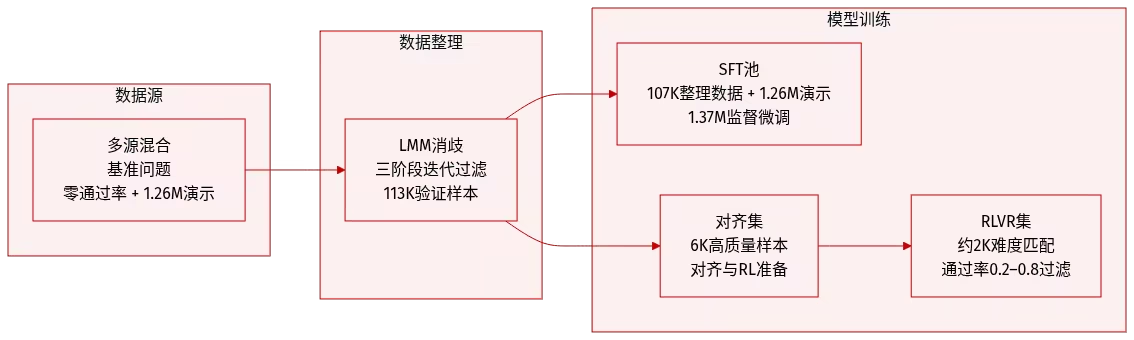
연구팀은 소프트웨어 엔지니어링 에이전트가 처음부터 완전한 소프트웨어 프로젝트를 구축하는 능력을 평가하기 위해 ProgramBench를 제안했습니다. 이 벤치마크는 에이전트가 프로그램과 문서만을 기반으로 참조 실행 파일과 일관되게 동작하는 코드베이스를 구현하고, 에이전트 기반 퍼즈 테스트를 통해 엔드 투 엔드 평가를 수행하도록 요구합니다.
ProgramBench는 CLI 도구, FFmpeg, SQLite, PHP 인터프리터 등 다양한 소프트웨어 유형을 다루는 200개의 태스크를 포함하고 있습니다. 9개의 언어 모델에 대한 실험 결과, 현재 모델들은 전반적인 성능에 한계가 있는 것으로 나타났습니다. 가장 성능이 좋은 모델조차도 3% 태스크에서 95% 테스트를 겨우 통과했으며, 생성된 코드는 일반적으로 단일 파일 구조를 보이는데, 이는 인간의 소프트웨어 엔지니어링 관행과는 상당히 다릅니다.
논문 및 상세 해석:https://go.hyper.ai/wExzR
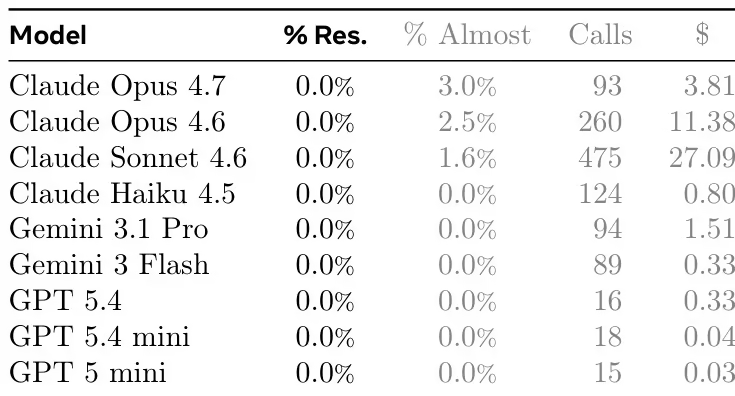
데이터셋 구성 및 출처: 저자들은 오픈소스 GitHub 저장소에서 200개의 태스크 인스턴스를 수집했습니다. 소스는 주로 Rust, Go 또는 C/C++로 작성된 독립 실행형 실행 파일을 생성하는 프로젝트에서 선택되었습니다. 이 컬렉션에는 텍스트 처리, 시스템 유틸리티, 언어 인터프리터와 같은 다양한 기능 범주가 포함됩니다.

2. 유니-OPD
논문 제목:
Uni-OPD: 이중 관점 레시피를 통해 온-정책 증류를 통합합니다
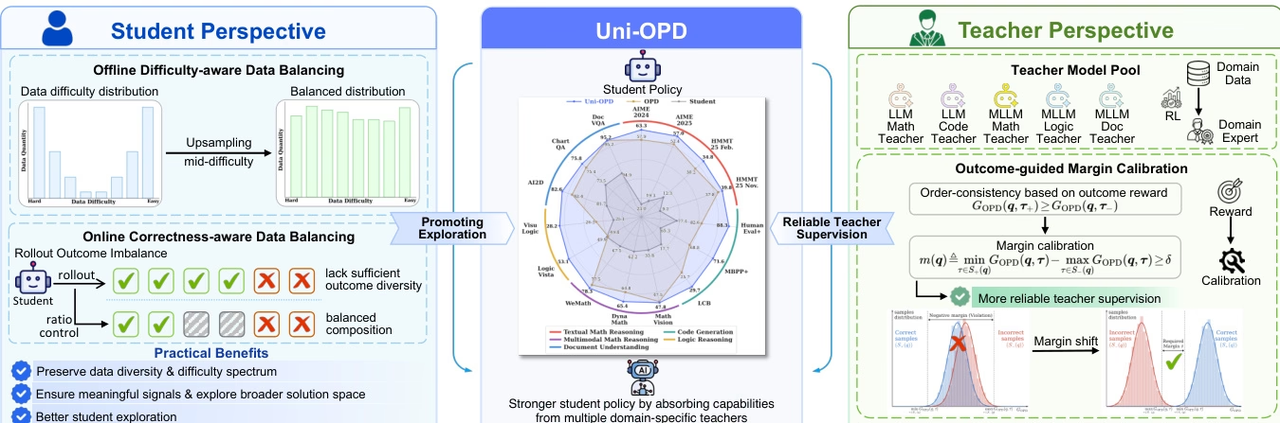
Uni-OPD는 LLM 및 MLLM을 위한 통합 온라인 증류 프레임워크로, 다중 전문가 지식을 학생 모델로 효과적으로 전달하도록 설계되었습니다. 기존 OPD 방법은 주로 두 가지 문제점, 즉 고정보 상태에 대한 불충분한 탐색과 교사의 신뢰할 수 없는 지도 신호로 인해 한계가 있다는 연구 결과가 있습니다.
이 문제를 해결하기 위해 Uni-OPD는 이중 관점 최적화 전략을 채택합니다. 학생 측면에서는 정보량이 풍부한 상태 탐색을 강화하기 위해 데이터 균형 전략을 도입하고, 교사 측면에서는 정답 및 오답 궤적 간의 순차적 일관성을 복원하여 지도 학습의 신뢰성을 향상시키는 결과 기반 주변 보정 메커니즘을 제안합니다. 단일 교사, 다중 교사, 강-약 모드 증류, 교차 모드 증류 등 다양한 설정을 포함하는 5개 도메인과 16개 벤치마크에 대한 실험을 통해 이 방법의 효과성을 검증했습니다.
논문 및 상세 해석:https://go.hyper.ai/8k4du
3. 충실한 불확실성
논문 제목:
환각은 신뢰를 무너뜨립니다. 메타인지가 해결책입니다.
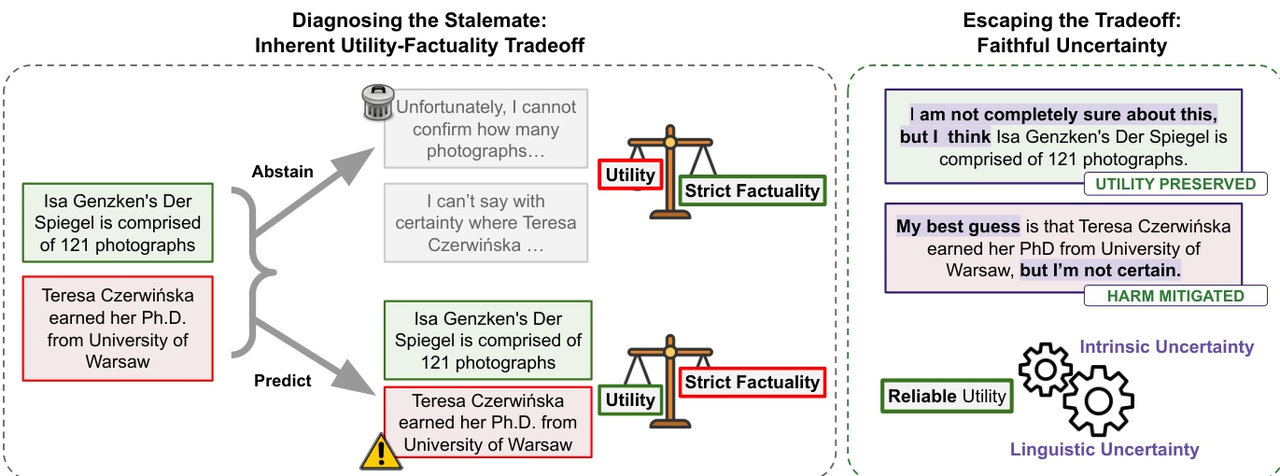
연구팀은 대규모 언어 모델이 사실적 신뢰성 측면에서 지속적으로 개선되고 있지만, 특히 외부 도구가 부족한 사실 기반 질의응답 시나리오에서 '착각' 문제가 여전히 만연해 있다고 지적합니다. 연구는 현재의 발전이 모델이 '알려진 것'과 '알려지지 않은 것'을 진정으로 구분하는 능력보다는 지식의 규모를 확장하는 데서 비롯된 것이라고 주장합니다. 따라서 착각을 완전히 제거하는 것은 모델의 실용성과 자연스러운 상충 관계가 될 수 있습니다.
이러한 관점을 바탕으로, 본 연구는 모델이 자신의 불확실성을 진실되게 표현하여 언어적 불확실성과 내부적 인지 사이의 일관성을 보장해야 한다는 점을 강조하는 "충실한 불확실성"이라는 개념을 제안합니다. 이러한 메타인지 능력은 모델의 신뢰도를 향상시킬 뿐만 아니라 지능형 에이전트 시스템에서 탐색 및 의사결정을 위한 더욱 신뢰할 수 있는 제어 메커니즘을 제공합니다.
논문 및 상세 해석:https://go.hyper.ai/G77rj
데이터셋 구성 및 출처: 저자는 Nakkiran et al.(2025)이 기록한 경험적 신뢰 분포 특성을 재현하기 위해 25,000개의 샘플을 포함하는 합성 데이터셋을 구성했습니다.

4. 프리즘
논문 제목:
SFT-to-RL을 넘어서: 다중 모드 강화 학습을 위한 블랙박스 온폴리션 증류를 통한 사전 정렬
대규모 멀티모달 모델의 미세 조정 과정에서 발생하는 분포 변화가 후속 강화 학습에 미치는 영향을 해결하기 위해 연구팀은 PRISM이라는 3단계 프로세스를 제안했습니다. 이 방법은 지도 미세 조정과 강화 학습 사이에 정책 내 증류 기반의 분포 정렬 단계를 삽입하고, 하이브리드 전문가(MoE) 판별기를 활용하여 분리 보정 신호를 제공합니다.
PRISM은 113,000개의 고품질 Gemini 데모 데이터셋을 사용하여 Qwen3-VL 실험에서 후속 강화 학습 성능을 크게 향상시켰으며, 4B 및 8B 모델의 정확도를 각각 4.4점 및 6.0점 높였습니다.
논문 및 상세 해석:https://go.hyper.ai/5fsD3
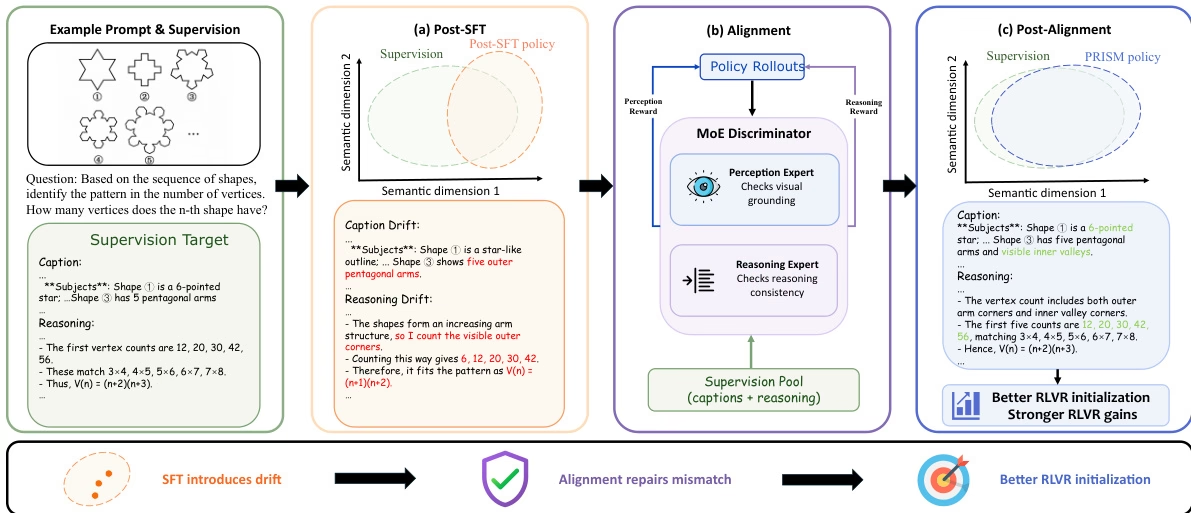
데이터셋 구성 및 출처: 본 논문은 수학적 추론, 과학 그래프 이해, 그래프 해석 및 공간 추론을 다루는 공개 벤치마크 테스트에서 추출한 데이터를 사용하여 멀티모달 추론 코퍼스를 구축합니다. 적용 범위와 안정성을 확장하기 위해 신중하게 선정된 이 데이터셋에 동일한 Gemini 모델 시리즈에서 생성된 126만 개의 공개 데모 데이터를 추가했습니다.
5. 엑소액터
논문 제목:
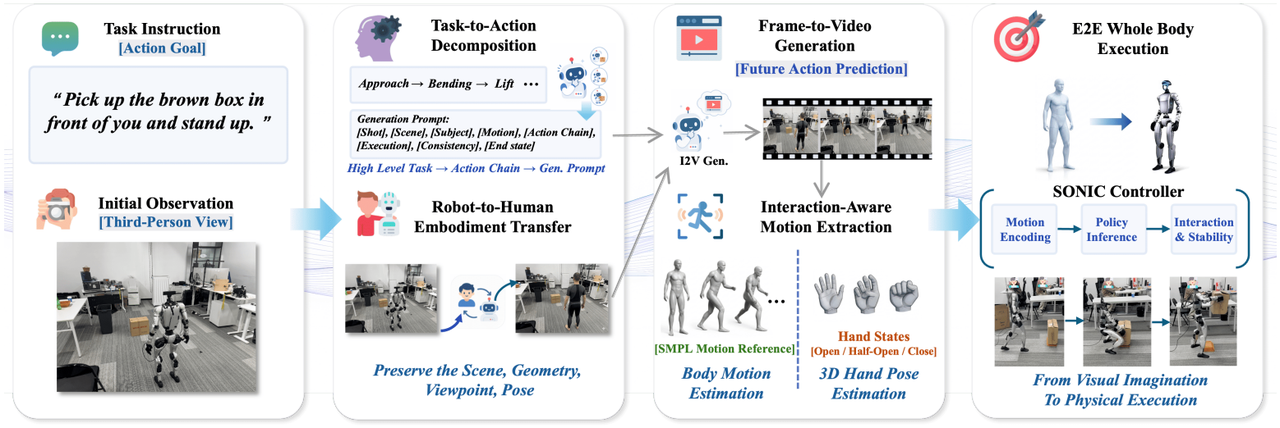
ExoActor: 일반화 가능한 대화형 휴머노이드 제어로서의 외향적 비디오 생성
연구팀은 로봇, 환경 및 사물 간의 협력적 상호작용을 암묵적으로 인코딩하는 통합 인터페이스로서 외향적 비디오 생성을 활용하는 ExoActor 프레임워크를 제안했습니다. 또한, 합성된 실행 비디오를 인간 동작 추정 및 범용 모션 컨트롤러를 통해 실행 가능한 휴머노이드 로봇 동작으로 변환하여, 추가적인 현장 데이터 수집 없이도 새로운 시나리오에 일반화할 수 있는 능력을 입증했습니다.
논문 및 상세 해석:https://go.hyper.ai/OE5IH
6. 편집-R1
논문 제목:
이미지 편집에서 검증자 기반 강화 학습 활용
연구팀은 이미지 편집을 위한 강화 학습 프레임워크인 Edit-R1을 제안했습니다. 기존의 보상 모델은 단순히 전체 점수만 출력하는 반면, Edit-R1은 편집 지시를 여러 원칙으로 분해하고 사고 연쇄 추론을 기반으로 편집 결과를 항목별로 검증하여 더욱 세밀하고 해석 가능한 보상 신호를 생성합니다. 또한, 본 연구는 지도 미세 조정과 GCPO 강화 학습 전략을 결합하여 보상 모델이 인간의 선호도를 더 잘 반영하도록 개선하고, GCPO를 활용하여 하위 편집 모델을 학습시킵니다.
실험 결과에 따르면 Edit-RRM은 이미지 편집 평가에서 Seed-1.5-VL 및 Seed-1.6-VL과 같은 강력한 VLM보다 우수한 성능을 보였으며, FLUX.1-kontext와 같은 편집 모델의 성능을 크게 향상시켰을 뿐만 아니라 매개변수 확장을 통해 상당한 이점을 얻을 수 있음을 보여주었습니다.
논문 및 상세 해석:https://go.hyper.ai/MtBLB
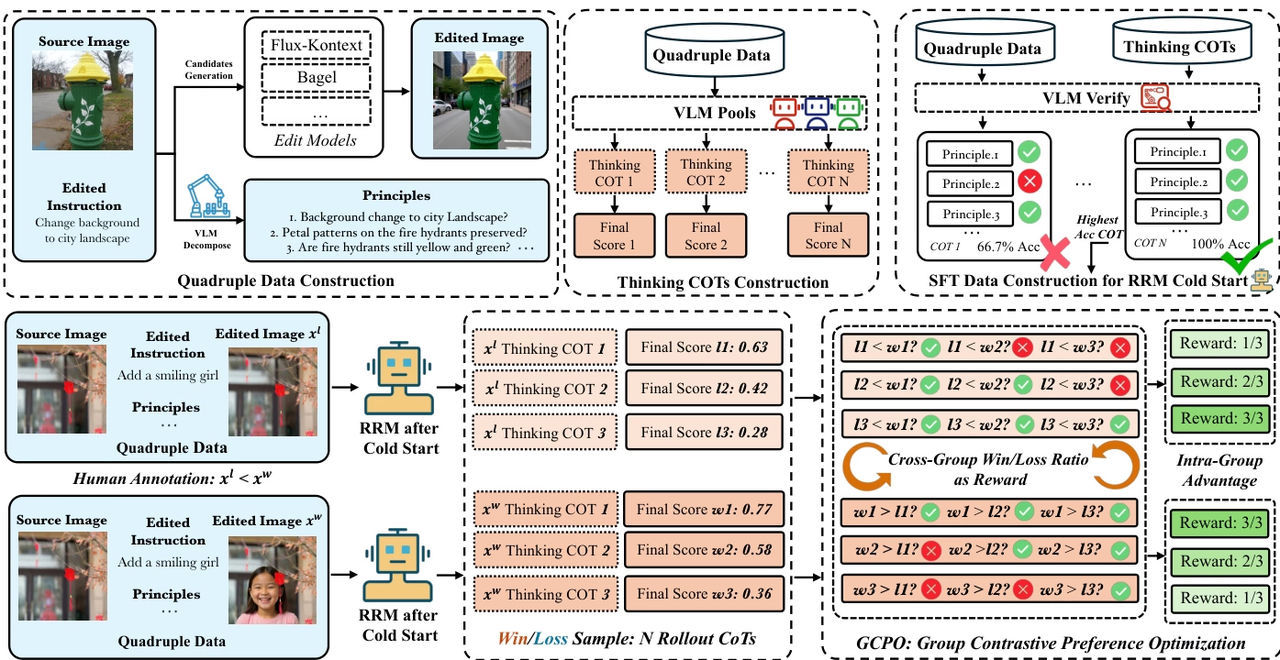
데이터셋 구성 및 출처: 연구팀은 공개적으로 이용 가능한 이미지 편집 벤치마크에서 20만 개의 샘플을 수집하여 콜드 스타트 추론 보상 모델을 위한 지도 학습 데이터셋을 구축했습니다. 이 초기 데이터셋은 다중 모델 생성 및 체계적인 검증을 통해 약 200만 개의 데이터로 확장되었습니다.

7. 공진화하는 정책 정제
논문 제목:
공진화하는 정책 정제
연구팀은 RLVR과 OPD라는 두 가지 주류 사후 훈련 패러다임을 통합적으로 분석하여, 여러 전문가 역량을 통합하는 과정에서 각 패러다임이 서로 다른 한계를 가지고 있음을 지적했습니다. 하이브리드 RLVR은 "역량 간 차이로 인한 비용"이 발생하기 쉬운 반면, "전문가를 먼저 훈련한 후 OPD를 시행하는" 전통적인 방식은 역량 충돌을 피할 수 있지만, 교사와 학생 간의 행동 양식 차이가 크기 때문에 전문가 역량을 완벽하게 계승하기 어렵다는 한계가 있습니다.
본 연구에서는 이러한 문제를 해결하기 위해 전문가들이 RLVR(참조 기반 RLVR)을 지속적으로 학습하는 동안 양방향 OPD(광학 처리 파생)를 동시에 도입하는 공진화 전략인 CoPD(공진화 처리)를 제안합니다. 이를 통해 전문가들은 서로에게 스승 역할을 하며 함께 진화함으로써 상호 보완적인 능력을 유지하면서 행동 일관성을 향상시킬 수 있습니다. 실험 결과는 CoPD가 텍스트, 이미지 및 비디오 추론 능력을 효과적으로 통합하여 하이브리드 RLVR 및 MOPD와 같은 강력한 기준 모델들을 크게 능가하고, 일부 작업에서는 도메인 전문가 모델보다도 우수한 성능을 보임을 보여줍니다.
논문 및 상세 해석:https://go.hyper.ai/cCyrG
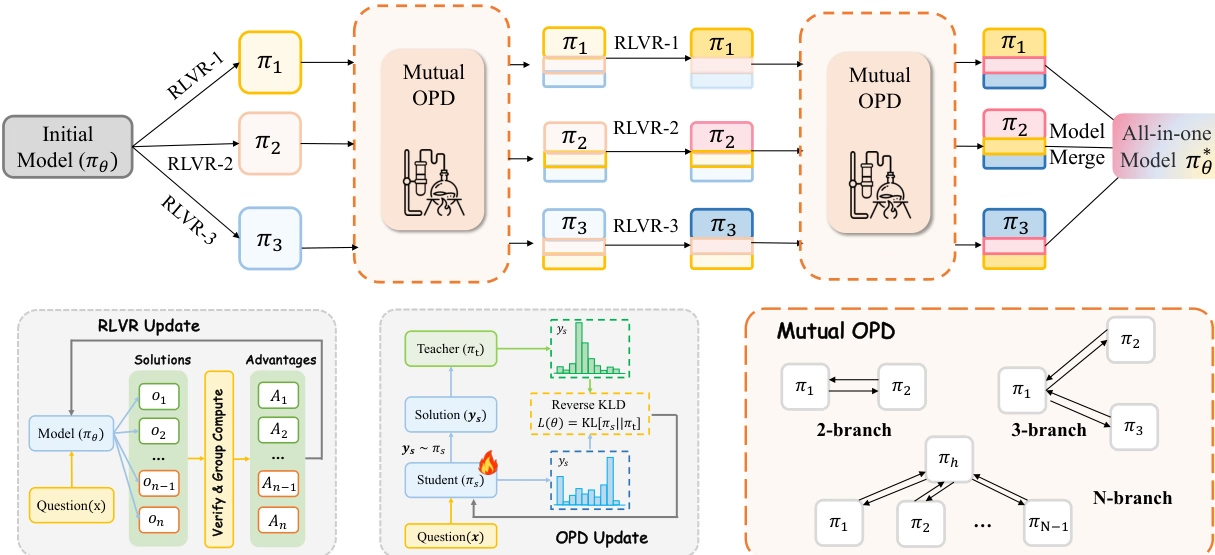

8. 클로짐
논문 제목:
ClawGym: 효과적인 클로 에이전트 구축을 위한 확장 가능한 프레임워크
연구팀은 로컬 파일, 도구 호출 및 영구적인 작업 공간 상태를 포함하는 복잡하고 다단계적인 워크플로를 지원하기 위해 Claw 스타일 개인 에이전트 개발의 전체 수명 주기를 위한 확장 가능한 프레임워크인 ClawGym을 제안했습니다.
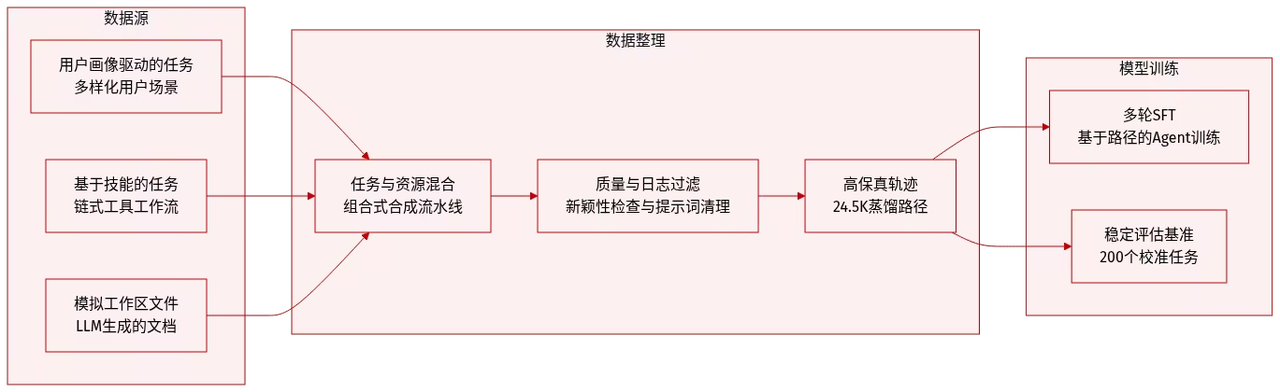
이 프레임워크는 13,500개의 엄선된 작업을 포함하는 합성 데이터셋인 ClawGym-SynData를 기반으로 하며, 인간의 의도, 스킬 조작, 시뮬레이션된 작업 공간, 그리고 하이브리드 검증 메커니즘을 결합합니다. ClawGym-Agents는 블랙박스 롤아웃 궤적을 기반으로 학습되며, 경량 강화 학습 파이프라인을 통해 성능이 향상됩니다. 또한, 신뢰할 수 있는 평가를 위해 인간과 LLM이 공동으로 검토 및 보정하고 자동으로 선정하는 벤치마크 데이터셋인 ClawGym-Bench가 구축되어 있습니다.
논문 및 상세 해석:https://go.hyper.ai/yZwa5
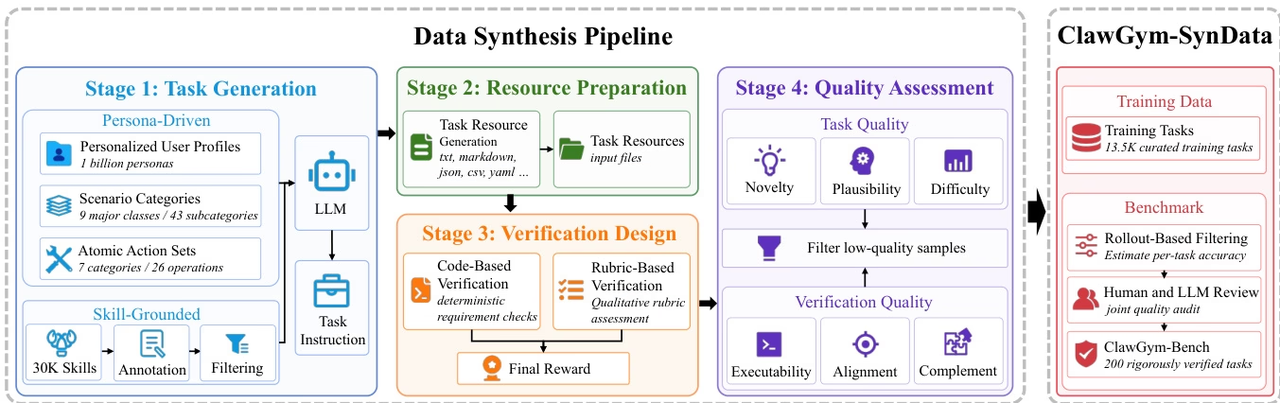
데이터셋 출처: 연구팀은 ClawGym-SynData 프레임워크를 사용하여 학습 데이터를 생성했습니다. 이 프레임워크는 다양한 사용자 시나리오에 맞춰 성격 기반의 하향식 합성과 OpenClaw 기능을 실제 워크플로우에 연결하는 기술을 기반으로 한 상향식 합성을 결합합니다.
이번 주 논문 추천 내용은 여기까지입니다. 더 많은 최첨단 AI 연구 논문을 보시려면 hyper.ai 공식 웹사이트의 "최신 논문" 섹션을 방문하세요.
또한, 연구팀의 고품질 연구 결과와 논문 제출을 환영합니다. 관심 있는 분은 NeuroStar WeChat(WeChat ID: Hyperai01)을 추가해 주세요.
다음주에 뵙겠습니다!








