Command Palette
Search for a command to run...
텐센트가 Hy-MT1.5 번역 모델을 오픈소스로 공개했습니다. 440MB 용량으로 최고 수준의 번역 기능을 구현합니다. 또한 MIT는 27,000개의 실제 올림피아드 수학 문제를 포함하는 멀티모달 수학 추론 벤치마크인 MathNet을 공동으로 발표했습니다.

Hy-MT1.5-1.8B-1.25bit는 텐센트에서 출시한 경량 기계 번역 모델입니다. Hy-MT1.5-1.8B를 기반으로 하며, 기계 번역 사전 학습, 지도 미세 조정, 증류 및 강화 학습을 포함한 다단계 학습을 통해 최적화되었습니다.이 모델은 33개 언어, 5개 방언 및 소수 언어, 그리고 1,056개의 번역 방향을 지원합니다.단 18억 개의 매개변수만으로도 이 모델의 번역 성능은 일부 대규모 오픈 소스 모델이나 주류 상용 번역 API를 능가합니다.
HyperAI 웹사이트에서 "Hy-MT1.5-1.8B-1.25bit: 경량 다국어 번역 모델"을 만나보세요! 한번 사용해 보세요!
온라인 사용:https://go.hyper.ai/PCK8X
더 자세한 정보를 원하시면 저희 공식 웹사이트를 방문해 주세요.
5월 6일부터 5월 15일까지 hyper.ai 공식 웹사이트의 주요 업데이트 사항을 간략하게 살펴보겠습니다.
* 고품질 공개 데이터 세트: 12개
* 엄선된 고품질 튜토리얼: 7개
* 커뮤니티 기사 해석 : 3개 기사
* 인기 백과사전 항목: 5개
공식 웹사이트를 방문하세요:하이퍼.AI
선택된 공개 데이터 세트
1. QCalEval 양자 교정 그래프 이해 데이터 세트
NVIDIA에서 2026년에 공개한 QCalEval은 양자 컴퓨팅 실험에서 그래프 이해를 위한 시각 언어 데이터셋입니다. 이 데이터셋은 시각 언어 모델(VLM)이 양자 컴퓨팅 캘리브레이션 실험 결과를 해석, 분류, 추론하는 능력을 평가하는 것을 목표로 하며, 시각 언어 모델 및 과학 이미지 이해 연구에 널리 활용되고 있습니다. QCalEval은 309개의 PNG 형식 2차원 과학 이미지, 243개의 벤치마크 항목, 그리고 236개의 few-shot 벤치마크 항목으로 구성되어 있으며, 22개의 실험 시리즈와 87개의 장면 유형을 포함합니다.
온라인 사용:https://go.hyper.ai/Ke7cu
2. Claw-Eval 실세계 벤치마크 데이터셋
2026년 베이징대학교와 홍콩대학교가 공동 개발한 Claw-Eval은 실제 환경에서 인공지능 에이전트의 성능을 평가하기 위한 투명한 엔드투엔드 벤치마크 데이터셋입니다. 이 데이터셋은 자율 에이전트의 작업 실행, 도구 활용, 멀티모달 이해, 다단계 상호작용 능력을 실제 환경에서 평가하는 것을 목표로 합니다. 영어와 중국어를 모두 지원하며, 일반, 멀티모달, 다단계의 세 가지 핵심 작업 그룹으로 구성되어 통신, 금융, 사무, 생산성 도구 등 24개 작업 범주를 포괄합니다.
온라인 사용:https://go.hyper.ai/Tznpa
3. MathNet 멀티모달 수학 벤치마크 추론 데이터셋
MathNet은 MIT 연구팀이 킹 압둘라 과학기술대학교 및 기타 기관과 협력하여 2026년에 공개한 대규모, 다국어, 다중 모드 수학적 추론 데이터셋입니다. 이 데이터셋은 올림피아드 수준의 수학적 추론 및 구조화된 검색 작업에서 대규모 모델의 성능을 평가하고 개선하는 것을 목표로 하며, 수학적 추론 평가, RAG 연구, 다중 모드 AI 훈련 등에 널리 사용되고 있습니다.
온라인 사용:https://go.hyper.ai/HLxNw
4. RSRCC 원격 감지 영역 변화 이해 기준 데이터 세트
2026년 구글 리서치에서 공개한 RSRCC는 원격 감지에서 의미 변화를 이해하기 위한 벤치마크 데이터셋입니다. 이 데이터셋은 다중 시점 영상 증거와 자연어 질의응답을 결합하여 원격 감지 장면의 시간적 변화를 심층적으로 이해하는 것을 목표로 하며, 기존의 이진 변화 탐지 방식을 의미 변화 설명 차원으로 끌어올립니다. RSRCC 데이터셋은 신규 건설, 철거, 도로 변화, 식생 변화, 주거 개발 등 다양한 시나리오를 포괄하는 126,000개의 원격 감지 변화 탐지 질의응답 샘플을 포함하고 있습니다.
온라인 사용:https://go.hyper.ai/jtCaK
5. 의료 폐기물 탐지 데이터 세트
의료 폐기물 데이터셋은 의료 폐기물의 지능형 식별 및 목표물 탐지를 위해 설계된 고해상도 이미지 데이터셋입니다. 복잡한 의료 환경에서 컴퓨터 비전 모델이 의료 폐기물을 자동으로 탐지하고 분류할 수 있도록 지원하는 것을 목표로 하며, 스마트 헬스케어, 공중 보건, 자동 폐기물 분류, 로봇 비전 등의 연구 분야에서 널리 활용되고 있습니다.
온라인 사용:https://go.hyper.ai/PrUKd
6. 포도잎 질병 데이터 세트
포도잎 질병 데이터셋은 정밀 농업 분야의 질병 탐지 작업을 위해 특별히 설계된 포도잎 이미지 데이터셋으로, 실제 농업 환경에서 컴퓨터 비전 모델의 질병 탐지, 분류 및 위치 파악 능력을 향상시키는 것을 목표로 합니다. 이 데이터셋은 건강한 포도잎과 흑부병, 에스카페 풀바병, 잎마름병 등 세 가지 일반적인 질병에 걸린 포도잎을 포함한 총 4,195개의 이미지로 구성되어 있습니다.
온라인 사용:https://go.hyper.ai/tJrkm
7. 수생 야생동물 도감: 전 세계 수생 생물 데이터 세트.
수생 야생동물 아틀라스: 글로벌 종 기록(Aquatic Wildlife Atlas: Global Species Records)은 수생 생태 연구 및 생물 다양성 분석을 위해 설계된 대규모 수생 동물 관찰 데이터 세트입니다. 이 데이터 세트는 연구자, 학생 및 데이터 과학자에게 고품질의 수생 생태 데이터 자원을 제공하는 것을 목표로 합니다. 20만 건의 수생 동물 관찰 기록을 포함하고 있으며, 100종 이상의 수생 생물을 포괄하고 산호초, 열대 강, 북극해, 최대 7,000미터 깊이의 심해 지역을 포함한 전 세계 주요 수생 생태계를 아우릅니다.
온라인 사용:https://go.hyper.ai/calNa
8. 전 세계 규모 4.5 지진: 규모 4.5 이상의 지진에 대한 전 세계 데이터 세트입니다.
전 세계 규모 4.5 이상 지진 데이터 세트는 지진 활동 분석 및 지리 공간 연구를 위해 설계되었습니다. 이 데이터 세트는 연구자들이 장기간에 걸친 지진 활동의 빈도, 분포 및 규모 변화를 분석하는 데 도움을 주기 위해 만들어졌습니다. 데이터 세트에는 1900년부터 2026년까지 전 세계에서 발생한 규모 4.5 이상의 지진 기록 230,608건이 포함되어 있습니다.
온라인 사용:https://go.hyper.ai/D7j95
9. 합성 약물 효능 데이터 세트
합성 약물 효과 데이터 세트는 약물 안전성 분석 및 임상 위험 평가를 지원하기 위해 설계된 합성 약물 데이터 세트로, 데이터 분석, 모델 구축 및 실험 연구에 적합합니다. 이 데이터 세트는 약물 사용 및 부작용 모니터링에 대한 구조화된 의학 정보를 포함합니다. 각 기록은 고유한 보고서 번호로 색인화되며, 환자의 나이와 성별과 같은 기본 정보와 약물명, 용량, 사용 기간, 병용 약물과 같은 치료 세부 정보를 포함합니다.
온라인 사용:https://go.hyper.ai/1ZaA0
10. 안저 질환 분류 데이터 세트
안저 영상 분류를 위해 설계된 의료 비전 데이터셋인 안저 영상 분류 데이터셋은 안과 질환 식별 및 진단 지원 시나리오에서 컴퓨터 비전 모델의 분류 능력을 향상시키는 것을 목표로 합니다. 이 데이터셋은 백내장, 당뇨병성 망막증, 녹내장, 정상 안저 등 네 가지 범주의 안저 영상 6,086개를 포함합니다.
온라인 사용:https://go.hyper.ai/FFFE7
11. 유방암: 다중 모달 융합 데이터셋
유방암: 멀티모달 융합(Breast Cancer: Multi-Modal Fusion)은 침습성 유방암(BRCA) 환자를 위해 구축된 전처리된 멀티모달 데이터셋으로, 멀티모달 융합 네트워크 구축을 위한 간편한 기반을 제공하도록 설계되었습니다. 이 데이터셋은 122명의 BRCA 환자로부터 얻은 다양한 소스의 데이터를 엄격하게 정렬하며, 모든 샘플은 TCGA 사례 ID를 사용하여 각 모달리티에 걸쳐 매핑되어 거시적 의료 영상(MRI), 미시적 디지털 병리(조직병리), 분자 오믹스(멀티오믹스), 임상 치료 정보 간의 일대일 대응을 구현합니다.
온라인 사용:https://go.hyper.ai/199WV
12. 장거리 산불 및 연기 감지 데이터 세트
장거리 산불 및 연기 감지 데이터셋은 산불 조기 경보 및 환경 모니터링을 위해 설계된 컴퓨터 비전 데이터셋입니다. 이 데이터셋은 장거리 산림 모니터링 시나리오에서 연기와 산불을 감지하는 모델의 능력을 향상시키는 것을 목표로 합니다. 산불 감시탑이나 능선 감시 카메라와 같은 고각 장거리 모니터링 시나리오를 모사하는 완전 합성 방식을 사용하여 생성되었으며, 특히 산불 초기 단계에 쉽게 관찰할 수 있는 산불 연기 기둥을 감지하는 데 중점을 두었습니다.
온라인 사용:https://go.hyper.ai/LnuXC
선택된 공개 튜토리얼
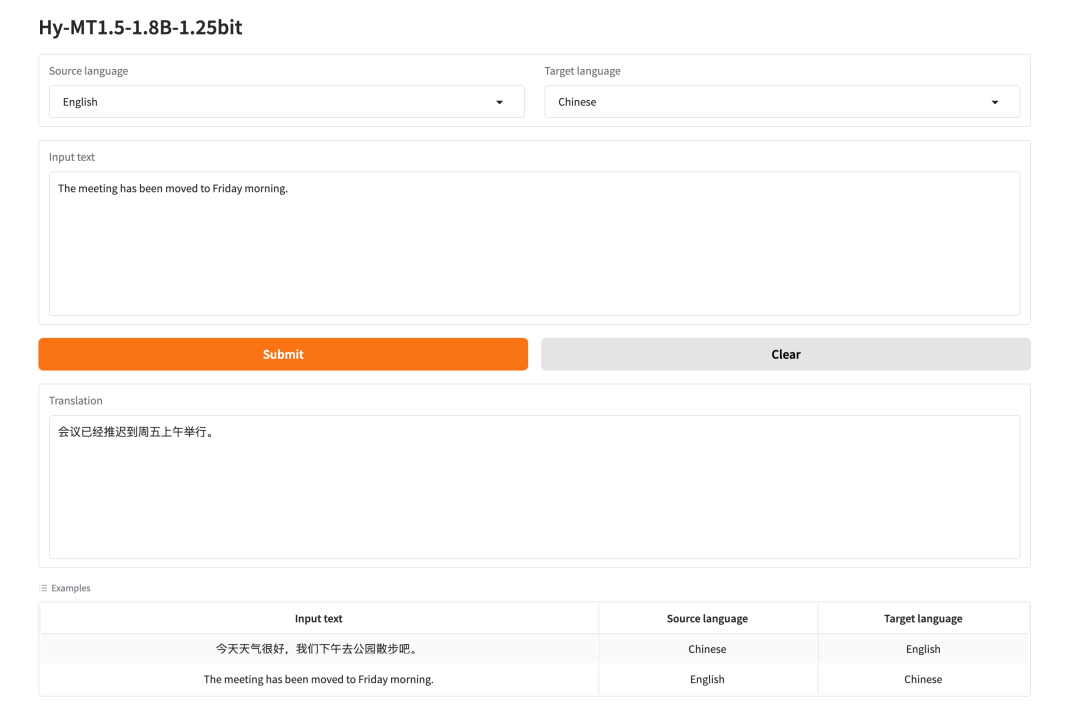
1. Hy-MT1.5-1.8B-1.25bit: 경량 다국어 번역 모델
텐센트가 2026년 4월에 발표한 Hy-MT1.5-1.8B-1.25bit는 Hy-MT1.5-1.8B를 기반으로 하는 1.25비트 양자화 다국어 번역 모델입니다. 이 모델의 핵심 가치는 고품질 다국어 번역 기능을 보다 가벼운 형태로 압축하여 제공하는 데 있습니다.
온라인으로 실행:https://go.hyper.ai/PCK8X
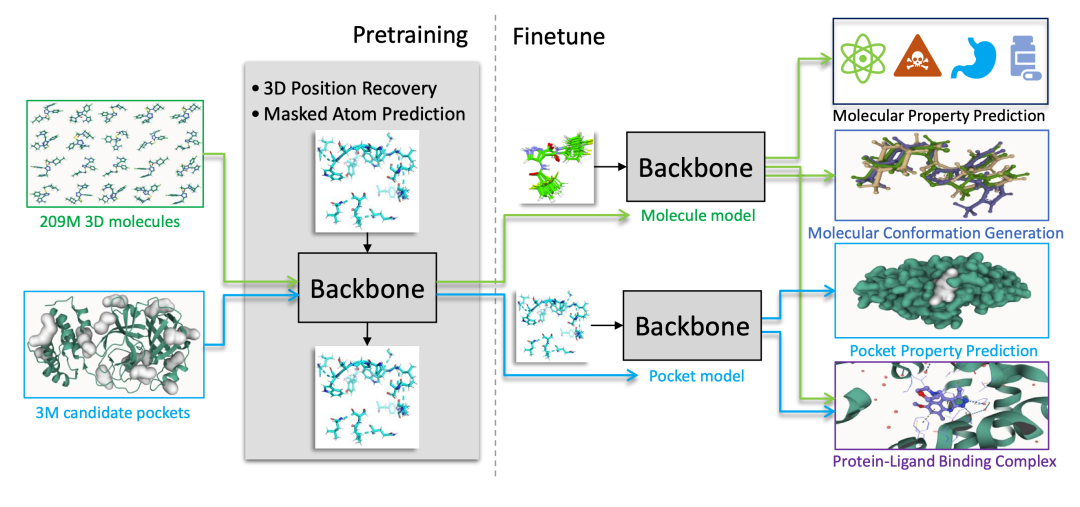
2. Uni-Mol: 범용 3D 분자 표현 학습 프레임워크
Uni-Mol은 DP Technology에서 2022년에 출시한 범용 3D 분자 사전 학습 프레임워크입니다. Uni-Mol은 대규모 3D 분자 구조 사전 학습을 통해 분자 표현 기능을 확장하며, 신약 설계, 분자 특성 예측, 단백질-리간드 상호작용 모델링 등의 작업에 활용될 수 있습니다.
온라인으로 실행:https://go.hyper.ai/RukIx
3. Mistral-Medium-3.5-128B의 원클릭 배포
2025년 Mistral AI에서 출시한 Mistral Medium 3.5는 1280억(128B) 개의 파라미터와 256,000개의 컨텍스트 윈도우를 갖춘 플래그십 융합 모델로, 단일 가중치 세트 내에서 명령어 준수, 추론 및 프로그래밍 기능을 통합합니다. 이 모델은 이전의 Mistral Medium 3.1 및 Magistral 모델을 대체했으며, Vibe 프로그래밍 에이전트에서 Devstral 2도 대체했습니다.
온라인으로 실행:https://go.hyper.ai/PXiHc
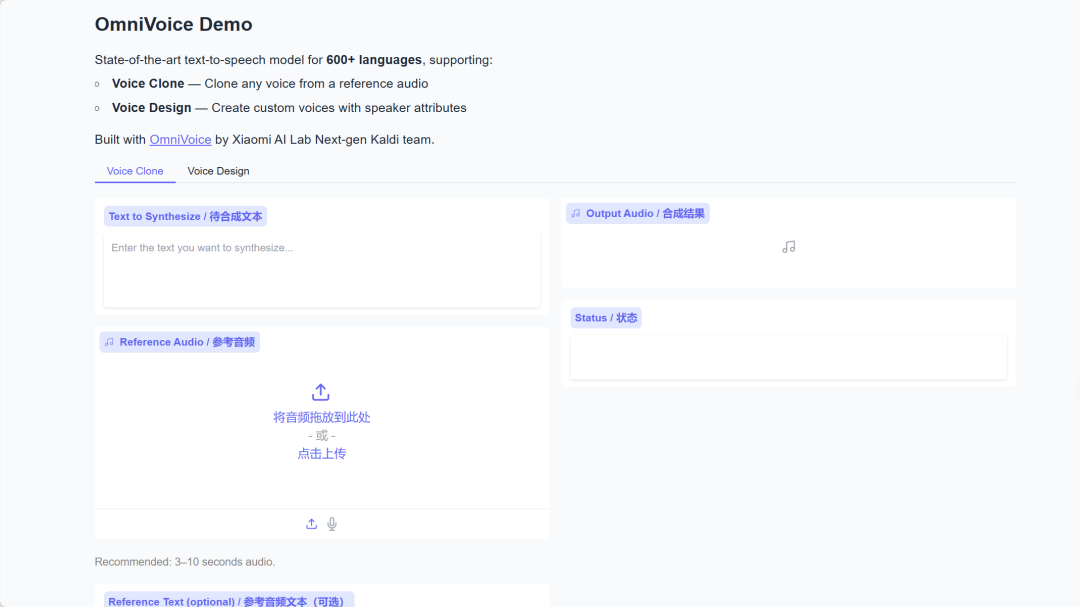
4. OmniVoice: 600개 이상의 언어로 고품질 TTS를 지원합니다.
OmniVoice는 샤오미 AI 연구소의 차세대 Kaldi 팀에서 개발한 다국어 텍스트 음성 변환(TTS) 모델로, 600개 이상의 언어로 고품질 음성 합성을 지원합니다. 반복적인 마스크 해제 디코딩 아키텍처를 기반으로 음성 복제, 음성 디자인, 자동 음성 생성이라는 세 가지 핵심 기능을 구현합니다.
온라인으로 실행:https://go.hyper.ai/7F7IR
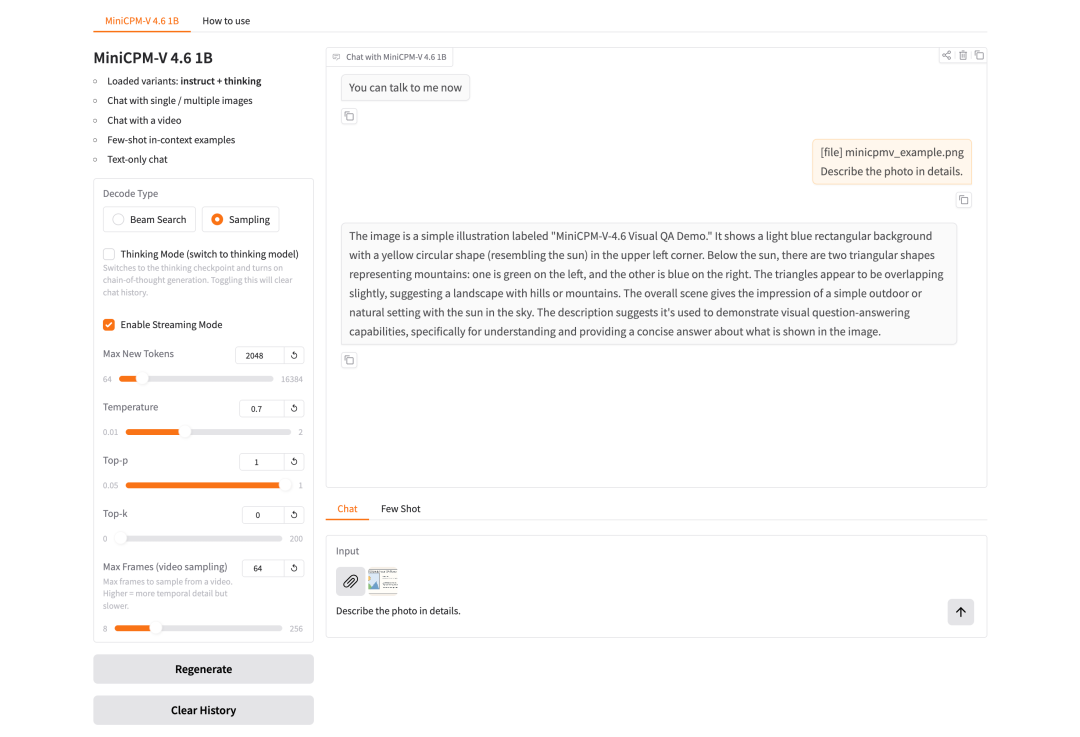
5. MiniCPM-V-4.6: 엣지 디바이스용 고효율 멀티모달 시각 언어 모델
2026년 5월 OpenBMB 팀과 칭화대학교 자연어 처리 연구실에서 출시한 MiniCPM-V-4.6은 이미지 이해, 비디오 이해, 시각적 질의응답, OCR, 그리고 다단계 멀티모달 대화 시나리오를 위한 효율적인 엣지 기반 멀티모달 시각 언어 모델입니다. MiniCPM-V-4.6의 핵심 가치는 비교적 작은 모델 크기로 일반적인 멀티모달 이해 작업을 처리할 수 있다는 점에 있으며, 따라서 리소스가 제한된 환경에서 이미지 질의응답, 짧은 비디오 요약, 스크린샷 이해, 문서 이미지 OCR, 그리고 다단계 멀티모달 대화 검증에 더욱 적합합니다.
온라인으로 실행:https://go.hyper.ai/azdHU
6. LingBot-Map: 스트리밍 3D 재구성을 위한 기하학적 컨텍스트 변환기
LingBot-Map은 Robbyant 팀에서 2026년 4월에 출시한 스트리밍 3D 재구성 프로젝트입니다. 이 프로젝트는 이미지 시퀀스 또는 비디오 프레임을 입력으로 받아 피드포워드 방식으로 온라인 3D 장면 재구성을 수행할 수 있습니다. 포인트 클라우드, 카메라 궤적 및 프레임별 결과는 브라우저의 3D 뷰어를 통해 볼 수 있습니다.
온라인으로 실행:https://go.hyper.ai/BR4me

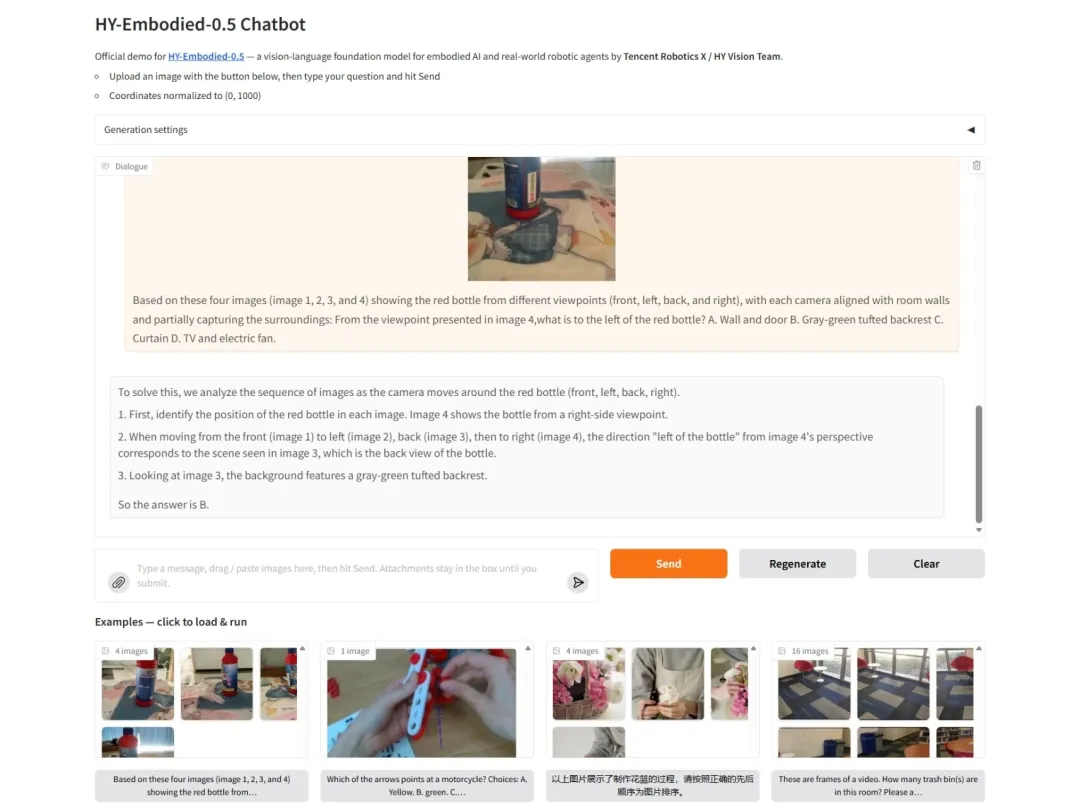
7. HY-Embodied-0.5: 실세계 지능형 에이전트를 위한 구체화된 기반 모델
HY-Embodied-0.5는 체화된 지능을 위해 특별히 설계된 기반 모델로, 텐센트의 훈위안 팀과 텐센트 로보틱스 X 랩이 2026년 4월 공동으로 오픈소스 공개했습니다. 이 모델 시리즈는 범용 기반 모델을 단순히 수정한 것이 아니라, 아키텍처부터 학습 패러다임까지 완전히 새롭게 재구축한 것입니다. 팀은 동시에 두 가지 주요 모델, 즉 실시간 엣지 응답에 초점을 맞춘 MoT-2B(총 파라미터 40억 개, 활성화 함수 20억 개)와 최고의 추론 성능을 추구하는 MoE-32B(총 파라미터 4억 700만 개, 활성화 함수 3200만 개)를 공개했습니다.
온라인으로 실행:https://go.hyper.ai/u8lJk
커뮤니티 기사 해석
1. MIT 등이 개발한 GPU 전력 예측 프레임워크인 EnergAIzer는 평균 1.8초 만에 예측을 완료하며, 오차 범위는 약 81 TP3T입니다.
MIT와 MIT-IBM 왓슨 AI 연구소의 연구진은 AI 워크로드용 고속 GPU 전력 예측 프레임워크인 EnergAIzer를 개발했습니다. 이 프레임워크는 비용이 많이 드는 시뮬레이션이나 성능 분석 없이 하드웨어 사용률 정보를 전력 모델에 직접 제공합니다. 새로운 EnergAIzer 프레임워크는 전력 예측을 처음부터 끝까지 평균 1.8초 만에 완료합니다. NVIDIA Ampere GPU에서 EnergAIzer는 약 81 TP3T의 전력 오차를 달성했는데, 이는 복잡한 주기적 시뮬레이션이나 하드웨어 성능 분석에 의존하는 기존 모델과 비교해도 경쟁력 있는 수준입니다.
전체 보고서 보기:https://go.hyper.ai/1PeMV
2. 토큰 사용량이 30% 감소했습니다. "아바타"에서 영감을 받은 이기종 지능형 에이전트 프레임워크인 Eywa는 언어 모델과 도메인별 기본 모델을 효율적으로 결합합니다.
일리노이 대학교 어바나-샴페인(UIUC) 연구팀은 언어 에이전트와 도메인별 기초 모델을 연결하는 이종 에이전트 프레임워크인 Eywa를 제안했습니다. 연구팀은 도메인별 기초 모델과 언어 모델을 결합하여 새로운 EywaAgent를 개발했는데, 이 설계는 언어 에이전트가 기초 모델의 추론, 계획 및 의사 결정 과정을 특정 작업에서 안내할 수 있도록 합니다.
전체 보고서 보기:https://go.hyper.ai/CzRL4
3. 100여 개 대학이 세계 최대 규모의 다중 코호트 단백질유전체학 연구를 시작했으며, 이를 통해 약 8만 명의 참가자로부터 얻은 데이터를 기반으로 질병을 유발하는 유전자를 밝혀내고 기존 약물의 용도를 변경할 수 있을 것으로 기대된다.
퀸 메리 런던 대학교와 케임브리지 대학교를 포함한 100여 개 대학 및 연구기관의 연구팀이 세계 최대 규모의 다중 코호트 단백질유전체학 연구 결과를 발표했습니다. 38개의 독립적인 연구 코호트와 총 78,664명의 참가자를 대상으로 한 대규모 단백질유전체학 메타분석을 기반으로, 이 연구는 24,738개의 단백질 양적 형질 유전자좌(QTL)를 체계적으로 식별하고, 이들을 1,116개의 순환 단백질과 연관시켜 단백질 수준에서 광범위한 근접 및 거리 유전적 조절 특성을 종합적으로 밝혀냈습니다.
전체 보고서 보기:https://go.hyper.ai/lGD68
인기 백과사전 기사
1. 세계 모델
2. 검정 곡선
3. 제한된 관심
4. 인간 참여형
5. 상호 순위 융합
다음은 "인공지능"을 이해하는 데 도움이 되는 수백 가지 AI 관련 용어입니다.
위에 적힌 내용은 이번 주 편집자 추천 기사의 전체 내용입니다. hyper.ai 공식 웹사이트에 포함시키고 싶은 리소스가 있다면, 메시지를 남기거나 기사를 제출해 알려주세요!
다음주에 뵙겠습니다!
HyperAI 소개
HyperAI(hyper.ai)는 중국을 선도하는 인공지능 및 고성능 컴퓨팅 커뮤니티입니다.우리는 중국 데이터 과학 분야의 인프라가 되고 국내 개발자들에게 풍부하고 고품질의 공공 리소스를 제공하기 위해 최선을 다하고 있습니다. 지금까지 우리는 다음과 같습니다.
* 2100개 이상의 공개 데이터 세트에 대한 국내 가속 다운로드 노드를 제공합니다.
* 700개 이상의 고전 및 인기 온라인 강좌가 포함되어 있습니다.
* 300개 이상의 AI4Science 논문 사례 분석
* 700개 이상의 관련 용어 검색을 지원합니다.
* 중국에서 최초의 완전한 Apache TVM 중국어 문서 호스팅
학습 여정을 시작하려면 공식 웹사이트를 방문하세요.








