Command Palette
Search for a command to run...
3D 비전 분야의 획기적인 발전: ByteSeed는 모든 시점에서 시각 공간 재구성을 가능하게 하는 DA3를 출시했습니다. 7만 건 이상의 실제 산업 환경 데이터를 제공합니다! CHIP은 6D 자세 추정을 위한 산업 데이터의 부족함을 채워줍니다.

시각 입력으로부터 3차원 공간 정보를 인지하고 이해하는 능력은 공간 지능의 초석이며 로봇 공학 및 혼합 현실(ML)과 같은 응용 분야에 필수적인 요소입니다. 이러한 기본적인 능력은 단안 심도 추정, 모션으로부터 구조 복원, 다중 시점 스테레오 비전, 동시 위치 추정 및 지도 작성(SLAM)과 같은 다양한 3차원 비전 작업의 발전을 가져왔습니다.
이러한 작업들은 입력 뷰의 수와 같은 몇 가지 요소에서만 차이가 나는 경우가 많아 개념적으로 상당한 중복성을 보입니다. 그러나 현재 주류 패러다임은 여전히 각 작업에 특화된 모델을 개발하는 데 집중되어 있습니다. 따라서 여러 작업을 처리할 수 있는 통합된 3D 이해 모델을 구축하는 것이 중요한 연구 방향으로 대두되었습니다.하지만 기존 솔루션은 일반적으로 복잡하고 맞춤형으로 설계된 네트워크 아키텍처에 의존하며, 다중 작업 공동 최적화를 통해 처음부터 학습해야 합니다.따라서 대규모 사전 학습 모델의 지식과 장점을 충분히 흡수하고 활용하기는 어렵습니다.
이를 바탕으로,바이트댄스의 시드(Seed) 팀이 뎁스 애니씽 3(DA3)을 출시했습니다.특정 광선 표현을 기반으로 특별히 훈련된 단일 트랜스포머 모델은 어떤 시점에서든 깊이와 자세를 동시에 추정할 수 있습니다. 모델을 극도로 단순화하려는 노력의 일환으로 DA3는 두 가지 핵심적인 결과를 도출했습니다.
*표준 트랜스포머(예: 기본 DINO 인코더) 하나를 백본 네트워크로 사용할 수 있습니다.작업별 구조 사용자 정의는 필요하지 않습니다.
*단 하나의 깊이 광선만을 사용하여 목표물을 예측합니다.복잡한 다중 작업 학습 메커니즘 없이도 뛰어난 성능을 달성할 수 있습니다.
연구팀은 또한 카메라 자세 추정, 임의 시점 기하학 및 시각적 렌더링을 포괄하는 새로운 시각 기하학 벤치마크를 구축했습니다. 이 테스트에서,DA3는 모든 미션의 상태를 새로 고칩니다.카메라 자세 정확도는 VGGT보다 평균 35.71 TP3T 높고, 기하학적 정확도는 23.61 TP3T 향상되었으며, 단안 심도 추정은 이전 모델인 DA2보다 우수합니다. 실험 결과, 이 최소한의 방법으로 카메라 자세를 알고 있는지 여부와 관계없이 이미지 개수에 상관없이 시각 공간을 재구성할 수 있음을 보여줍니다.
HyperAI 웹사이트에 "Depth-Anything-3: 어떤 관점에서든 시각 공간 복원" 기능이 추가되었으니 한번 사용해 보세요!
온라인 사용:https://go.hyper.ai/MXyML
12월 15일부터 12월 19일까지 hyper.ai 공식 웹사이트의 주요 업데이트 사항을 간략하게 살펴보겠습니다.
* 고품질 공개 데이터 세트: 10
* 고품질 튜토리얼 선택: 3개
* 이번 주 추천 논문 : 5
* 커뮤니티 기사 해석 : 5개 기사
* 인기 백과사전 항목: 5개
1월 마감인 주요 학술대회: 11개
공식 웹사이트를 방문하세요:하이퍼.AI
선택된 공개 데이터 세트
1. VideoRewardBench 비디오 보상 모델 평가 데이터셋
중국과학기술대학교와 화웨이 노아의 방주 연구소가 공동으로 개발한 VideoRewardBench는 영상 이해의 네 가지 핵심 영역(인지, 지식, 추론, 보안)을 포괄하는 최초의 종합 평가 벤치마크입니다. 이 벤치마크는 복잡한 영상 이해 시나리오에서 모델의 선호도 판단 및 생성된 결과의 품질 평가 능력을 체계적으로 평가하는 것을 목표로 합니다. 데이터셋은 1,482개의 서로 다른 영상과 1,559개의 서로 다른 질문으로 구성된 1,563개의 레이블링된 샘플로 이루어져 있습니다. 각 샘플은 영상-텍스트 프롬프트, 선호하는 응답, 그리고 거부 응답으로 구성됩니다.
직접 사용:https://go.hyper.ai/JIB1B
2. Arena-Write 작문 생성 평가 데이터 세트
Arena-Write는 싱가포르 기술디자인대학교(SUTD)와 칭화대학교 지식공학연구소(KPL)가 공동으로 개발한 작문 과제 데이터셋입니다. 이 데이터셋은 장문 텍스트 생성 모델을 평가하고, 실제 사용 시나리오에서 장문 콘텐츠 및 복잡한 작문 과제를 생성하는 대규모 언어 모델의 종합적인 역량을 체계적으로 평가하기 위해 설계되었습니다. 데이터셋에는 100개의 사용자 작문 과제가 포함되어 있으며, 각 과제는 실제 작문 프롬프트로 구성되고 해당 작문 시나리오 유형이 레이블링되어 있습니다.
직접 사용:https://go.hyper.ai/4NQdD
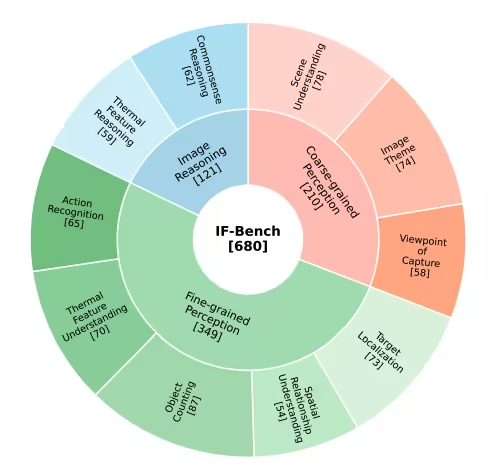
3. IF-Bench 적외선 영상 이해 벤치마크 데이터셋
IF-Bench는 중국과학원 자동화연구소와 중국과학원대학교 인공지능대학이 공동으로 개발한 고품질 적외선 이미지 멀티모달 이해 벤치마크 데이터셋입니다. 이 데이터셋은 적외선 이미지에 대한 멀티모달 대규모 언어 모델(MLLM)의 의미 이해 능력을 체계적으로 평가하는 것을 목표로 합니다. 데이터셋은 499개의 적외선 이미지와 680개의 시각적 질문-답변(VQA) 쌍으로 구성되어 있으며, 이미지는 23개의 서로 다른 적외선 이미지 데이터셋에서 추출되어 전체적으로 비교적 균형 잡힌 분포를 유지하고 있습니다.
직접 사용:https://go.hyper.ai/hty3u
4. CHIP 산업용 의자 6D 자세 추정 데이터셋
CHIP은 FBK-TeV가 Ikerlan 및 Andreu World와 협력하여 공개한 실제 산업 환경에서의 로봇 조작을 위한 6D 자세 추정 데이터셋입니다. 이 데이터셋은 주로 가정용품이나 실험실 환경에 초점을 맞추고 실제 산업 현장의 데이터를 반영하지 못하는 기존 벤치마크의 한계를 극복하는 것을 목표로 합니다. CHIP 데이터셋은 7가지 구조와 재질의 의자 모델을 포함하는 77,811개의 RGB-D 이미지로 구성되어 있습니다.
직접 사용:https://go.hyper.ai/AR5Xm
5. SSRB 반정형 데이터 자연어 질의 데이터셋
SSRB는 하얼빈 공업대학(선전), 홍콩 폴리테크닉 대학교, 칭화 대학교 등 여러 기관이 공동으로 발표한 대규모 반정형 데이터셋으로, 자연어 질의에 대한 성능을 평가하고 향상시키는 것을 목표로 합니다. NeurIPS 2025 데이터셋 및 벤치마크에 선정되었으며, 복잡한 자연어 질의 환경에서 반정형 데이터를 검색하는 모델의 능력을 평가하고 발전시키는 데 기여합니다.
직접 사용:https://go.hyper.ai/szsqF
6. INFINITY-CHAT 실제 개방형 질문 답변 데이터 세트
워싱턴 대학교가 카네기 멜론 대학교 및 앨런 인공지능 연구소와 공동으로 발표한 최초의 대규모 실제 개방형 사용자 질문 데이터셋인 INFINITY-CHAT이 NeurIPS 2025 최우수 논문상(데이터베이스 트랙)을 수상했습니다. 이 데이터셋은 개방형 질문 생성에서 언어 모델의 다양성, 인간 선호도의 차이, 그리고 "인공 군집 효과"와 같은 핵심 문제를 체계적으로 연구하는 것을 목표로 합니다.
직접 사용:https://go.hyper.ai/KmH1N
7. MUVR 멀티모달 자르지 않은 비디오 검색 벤치마크
MUVR은 난징항공우주대학교, 난징대학교, 홍콩공과대학교가 공동으로 발표한 멀티모달 무편집 동영상 검색 벤치마크 데이터셋입니다. NeurIPS 2025 데이터셋 및 벤치마크로 선정되었으며, 장편 동영상 플랫폼에서의 동영상 검색 연구를 촉진하는 것을 목표로 합니다. 이 데이터셋은 빌리빌리(Bilibili)에서 가져온 약 53,000개의 무편집 동영상, 1,050개의 멀티모달 쿼리, 그리고 84,000개의 쿼리-동영상 매칭 관계를 포함하며, 뉴스, 여행, 댄스 등 다양한 일반적인 동영상 유형을 다룹니다.
직접 사용:https://go.hyper.ai/NRaSw

8. OpenGU 그래프 망각 종합 평가 데이터셋
OpenGU는 베이징 공업대학에서 발표한 그래프 망각(GU) 학습을 위한 종합 평가 데이터셋입니다. NeurIPS 2025 데이터셋 및 벤치마크로 선정되었으며, 그래프 신경망의 망각 기법에 대한 통합 평가 프레임워크, 다중 도메인 데이터 리소스 및 표준화된 실험 설정을 제공하는 것을 목표로 합니다.
직접 사용:https://go.hyper.ai/qqHct
9. FrontierScience 추론 연구 과제 평가 데이터 세트
OpenAI에서 공개한 FrontierScience는 추론 및 과학 연구 과제 평가를 위한 데이터셋입니다. 이 데이터셋은 전문가 수준의 과학적 추론 및 연구 하위 과제에서 대규모 모델의 역량을 체계적으로 평가하는 것을 목표로 합니다. FrontierScience는 "전문가 수준의 원본 콘텐츠 + 2단계 과제 구조 + 자동 채점 메커니즘"이라는 설계 방식을 채택하고 있으며, 올림피아드와 리서치 두 가지 하위 데이터셋으로 나뉩니다.
직접 사용:https://go.hyper.ai/fUUzF
10. FirstAidQA 응급처치 지식 질문 답변 데이터셋
FirstAidQA는 이슬람 과학기술대학교에서 공개한 응급처치 및 응급 상황 대응 시나리오에 특화된 질문-답변 데이터셋입니다. 이 데이터셋은 자원이 제한된 응급 환경에서 모델 학습 및 적용을 지원하는 것을 목표로 합니다. FirstAidQA는 다양한 일반적인 응급처치 및 응급 상황 대응 시나리오를 포괄하는 5,500개의 고품질 질문-답변 쌍으로 구성되어 있습니다.
직접 사용:https://go.hyper.ai/QQphC
선택된 공개 튜토리얼
1. Depth-Anything-3: 어떤 관점에서든 시각적 공간을 복원합니다
Depth-Anything-3(DA3)는 ByteDance-Seed 팀에서 출시한 획기적인 시각 기하학 모델입니다. 이 모델은 "미니멀리스트 모델링"이라는 개념을 통해 시각 기하학 작업에 혁명을 일으켰습니다. 기본 DINO 인코더와 같은 단 하나의 일반 트랜스포머만을 백본 네트워크로 사용하고, 복잡한 멀티태스킹 학습 대신 "깊이 광선 표현"을 활용하여 알려진 카메라 포즈와 알려지지 않은 카메라 포즈를 포함한 모든 시각 입력으로부터 공간적으로 일관된 기하학적 구조를 예측합니다.
온라인으로 실행:https://go.hyper.ai/MXyML
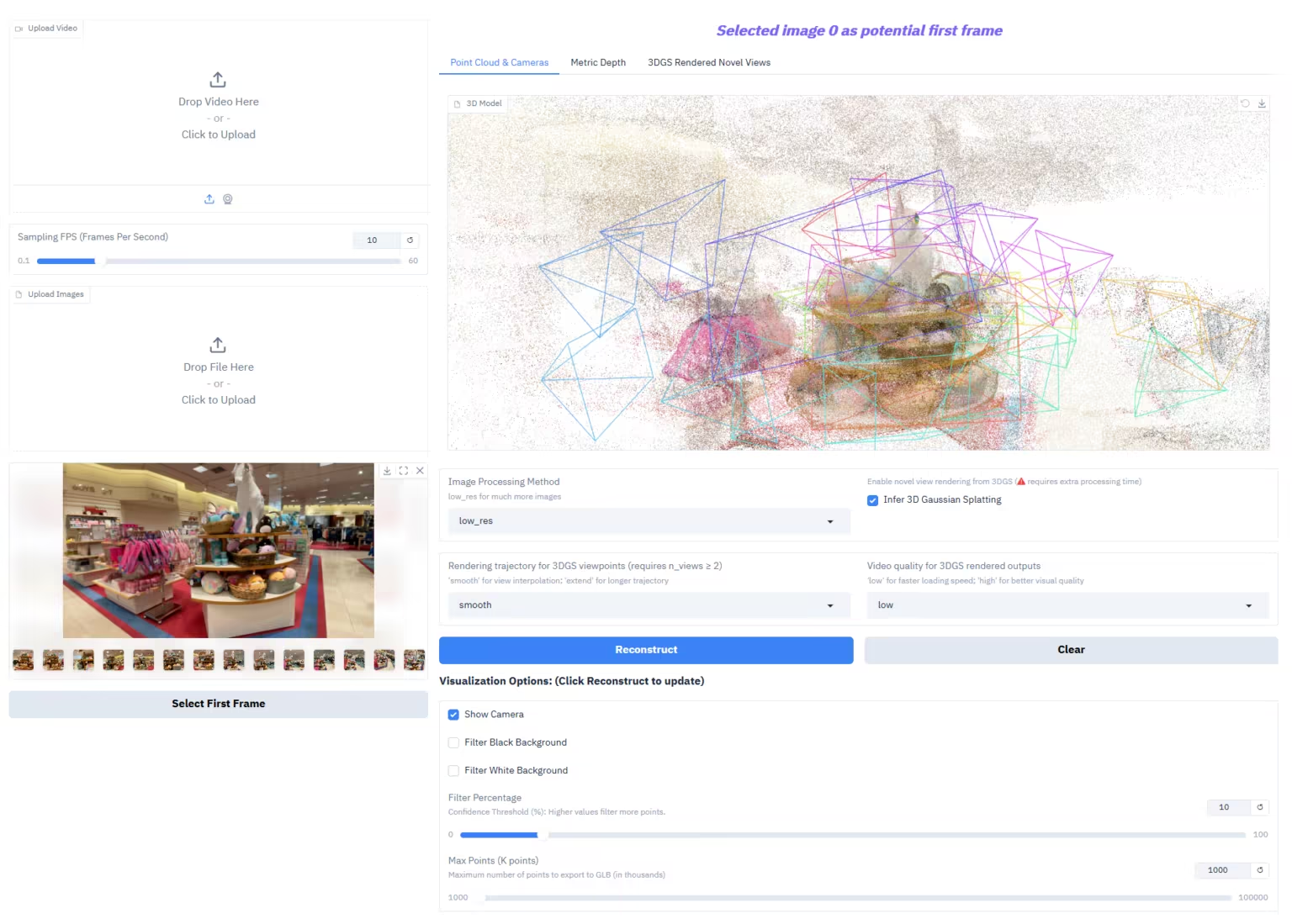
2. MarkItDown, 마이크로소프트의 오픈소스 문서 변환 도구
MarkItDown은 Microsoft에서 개발한 경량의 플러그 앤 플레이 방식 Python 문서 변환 도구입니다. 다양한 일반 문서 및 리치 미디어 형식을 Markdown으로 효율적이고 구조적으로 변환하여, 대규모 언어 모델(LLM)의 텍스트 이해 및 분석 파이프라인에 최적화된 입력 형식을 제공하는 것을 목표로 합니다.
온라인으로 실행:https://go.hyper.ai/7WIGP
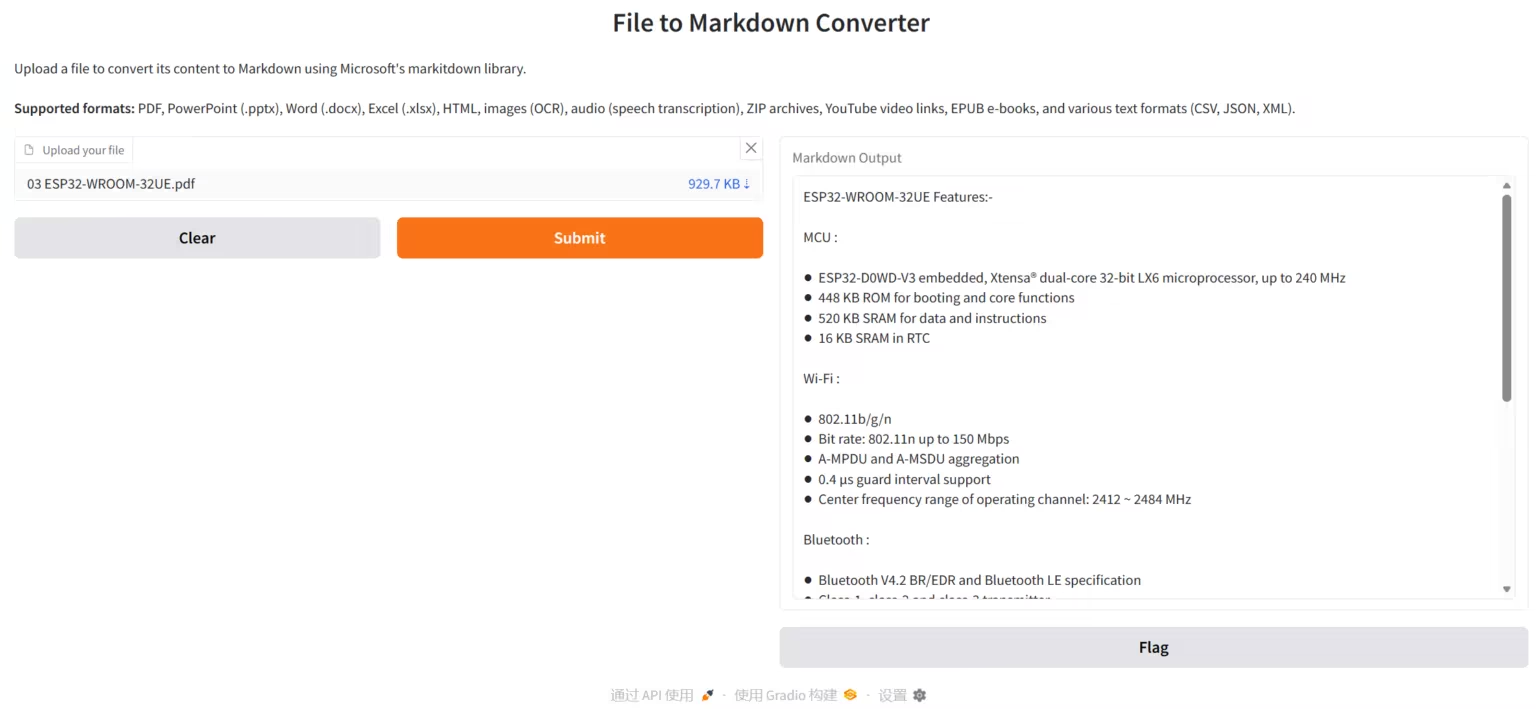
3. 찬드라: 고정밀 문서 OCR
Chandra는 Datalab-to 팀에서 개발한 고정밀 문서 OCR(광학 문자 인식) 시스템으로, 문서 레이아웃 인식 및 텍스트 추출에 중점을 두고 있습니다. Chandra는 PDF 및 이미지 파일을 직접 처리하여 구조화된 텍스트, Markdown 및 HTML 출력물을 생성하고, OCR 결과를 쉽게 검토할 수 있도록 시각적인 레이아웃 다이어그램을 제공합니다.
온라인으로 실행:https://go.hyper.ai/nZhF5
이번 주 논문 추천
1. LongVie 2: 멀티모달 제어 가능 초장시간 비디오 월드 모델
본 논문에서는 장거리 제어 가능성, 시간적 일관성 및 시각적 충실도 측면에서 최첨단 성능을 달성하고 최대 5분 길이의 연속 비디오 생성을 지원하는 엔드투엔드 자기회귀 프레임워크인 LongVie 2를 제안합니다. 이는 통합된 비디오 세계를 모델링하는 데 있어 중요한 진전입니다.
논문 링크:https://go.hyper.ai/toK8K
2. MMGR: 다중 모달 생성 추론
본 논문에서는 물리적 추론, 논리적 추론, 3D 공간 추론, 2D 공간 추론, 시간적 추론이라는 다섯 가지 핵심 추론 능력을 기반으로 하는 체계적인 평가 시스템인 다중모드 생성 추론 평가 및 벤치마킹 프레임워크(MMGR)를 제안합니다. MMGR은 추상적 추론(ARC-AGI, 스도쿠), 실체적 내비게이션(실세계 3D 내비게이션 및 위치 파악), 물리적 상식 이해(스포츠 시나리오 및 복잡한 상호작용 행동)의 세 가지 핵심 영역에서 생성 모델의 추론 능력을 평가합니다.
논문 링크:https://go.hyper.ai/Gxwuz
3. QwenLong-L1.5: 장기 컨텍스트 추론 및 메모리 관리를 위한 훈련 후 레시피
본 논문에서는 체계적인 사후 학습 혁신을 통해 탁월한 장기 컨텍스트 추론 능력을 달성한 모델인 QwenLong-L1.5를 소개합니다. Qwen3-30B-A3B-Thinking 아키텍처를 기반으로 하는 QwenLong-L1.5는 장기 컨텍스트 추론 벤치마크에서 GPT-5 및 Gemini-2.5-Pro에 근접한 성능을 보이며, 기준 모델 대비 평균 9.90점 향상되었습니다. 특히 초장기 작업(100만~400만 토큰)에서는 메모리 에이전트 프레임워크를 통해 기준 에이전트 대비 9.48점의 상당한 성능 향상을 달성했습니다.
논문 링크:https://go.hyper.ai/DxYGd
4. 인공지능 에이전트 시대의 기억
본 논문은 에이전트 메모리 연구의 최신 동향을 체계적으로 검토하는 것을 목표로 한다. 먼저, 에이전트 메모리의 범위를 명확히 하고, 대규모 언어 모델(LLM) 메모리, 검색 증강 생성(RAG), 컨텍스트 엔지니어링과 같은 관련 개념들과 구분한다. 그 후, 형태, 기능, 동역학이라는 세 가지 통합된 관점에서 에이전트 메모리를 분석한다.
논문 링크:https://go.hyper.ai/zfHTr
5. ReFusion: 병렬 자기회귀 디코딩을 사용하는 확산형 대규모 언어 모델
본 논문에서는 토큰 수준에서 더 높은 "슬롯" 수준으로 병렬 디코딩을 확장하여 우수한 성능과 효율성을 달성하는 새로운 마스크 확산 모델인 ReFusion을 제안합니다. 각 슬롯은 고정 길이의 연속적인 부분 시퀀스입니다. ReFusion은 기존 마스크 확산 모델 대비 평균 341 TP3T의 성능 향상과 평균 18배 이상의 추론 속도 향상을 달성했을 뿐만 아니라, 평균 2.33배의 속도 우위를 유지하면서 강력한 자기회귀 모델과의 성능 격차를 크게 줄였습니다.
논문 링크:https://go.hyper.ai/YosaF
더 많은 AI 프런티어 논문:https://go.hyper.ai/iSYSZ
커뮤니티 기사 해석
1. 스위스 로잔 연방 공과대학(EPFL)은 10만 개 미만의 구조화된 데이터 포인트를 훈련에 사용하여 PET-MAD를 제안했으며, 이를 통해 전문 모델과 유사한 원자 시뮬레이션 정확도를 달성했습니다.
스위스 로잔 연방 공과대학(EPFL)에서 제안한 PET-MAD 모델은 광범위한 원자 다양성을 포괄하는 데이터 세트를 사용하여 기존 모델보다 훨씬 적은 훈련 샘플을 활용하면서도 전용 모델과 유사한 정확도를 달성했습니다. 이는 원자 시뮬레이션이 더욱 효율적이고 보편적인 방향으로 발전할 수 있음을 강력하게 보여주는 사례입니다.
전체 보고서 보기:https://go.hyper.ai/cpeR5
2. 온라인 튜토리얼 | 마이크로소프트, VibeVoice 오픈소스 공개: 4개 역할 간 90분간 자연스러운 대화 가능
마이크로소프트는 확장 가능한 장편 다중 화자 음성 합성을 지원하도록 설계된 VibeVoice를 오픈 소스로 공개했습니다. 이 모델은 64KB 컨텍스트 창 내에서 최대 4명의 화자가 참여하는 최대 90분 분량의 음성을 합성할 수 있으며, 더욱 풍부한 음색, 자연스러운 억양, 그리고 현실적인 대화 분위기를 구현합니다. 또한, 다양한 언어 환경에서 뛰어난 전이성을 보여주며, 전반적인 성능 면에서 기존의 오픈 소스 및 상용 대화 모델을 능가합니다.
전체 보고서 보기:https://go.hyper.ai/YfDjq
3. CUDA 초기 개발팀은 cuTile이 Triton을 "특별히 겨냥한" 것이라고 강하게 비판했습니다. 과연 Tile 패러다임은 GPU 프로그래밍 생태계의 경쟁 구도를 재편할 수 있을까요?
CUDA 출시 후 거의 20년 만인 2025년 12월, NVIDIA는 새로운 GPU 프로그래밍 진입점인 "cuTile"을 선보였습니다. 이 새로운 cuTile은 타일 기반 프로그래밍 모델을 사용하여 GPU 커널을 재구성함으로써 개발자가 CUDA C++에 대한 심층적인 지식 없이도 효율적으로 커널을 작성할 수 있도록 지원하며, 커뮤니티 내에서 상당한 논의를 불러일으켰습니다. 아직 초기 단계이지만, 타일 기반 접근 방식의 추상적인 장점, 마이그레이션 도구에 대한 커뮤니티의 탐색, 그리고 실제 적용 시도는 cuTile이 GPU 프로그래밍의 새로운 패러다임이 될 가능성을 시사합니다. cuTile의 미래는 생태계 성숙도, 마이그레이션 비용, 그리고 성능에 달려 있습니다.
전체 보고서 보기:https://go.hyper.ai/H1b0n
4. 사전 예방적 감독을 우선시하는 다리오 아모데이는 오픈AI를 떠난 후 AI 안전을 회사의 사명에 포함시켰습니다.
전 세계적인 AI 경쟁이 가속화되는 가운데, '조기 규제'라는 소수 의견을 고수해 온 다리오 아모데이는 실리콘 밸리에서 막강한 영향력을 행사하고 있습니다. 헌법적 AI를 옹호하는 것부터 유럽과 미국의 규제 프레임워크에 영향력을 행사하는 것에 이르기까지, 그는 AI 시대를 위한 TCP/IP와 유사한 '거버넌스 프로토콜'을 구축하려 하고 있습니다. 이는 단순히 보안 문제만이 아니라, AI가 향후 10년 안에 급속한 기술 발전을 넘어 안정적인 응용 분야로 나아갈 수 있을지에 대한 문제이기도 합니다. 아모데이의 전략은 전 세계 AI 산업의 근본적인 논리를 재편하고 있습니다.
전체 보고서 보기:https://go.hyper.ai/SwyNW
5. 칭화대학교의 리용 교수가 이끄는 연구팀은 60%를 통해 예측 정확도를 향상시킬 수 있는 신경 기호 회귀 방법을 제안했으며, 이를 통해 고정밀 네트워크 동역학 공식을 자동으로 도출했습니다.
칭화대학교 전자공학과 리용 교수 연구팀은 데이터로부터 수학 공식을 자동으로 도출하여 시스템 동역학을 특징짓는 신경 기호 회귀 방법인 ND²를 제안했습니다. 이 방법은 고차원 네트워크에서의 탐색 문제를 1차원 시스템으로 단순화하고, 사전 학습된 신경망을 활용하여 고정밀 공식 발견을 유도합니다.
전체 보고서 보기:https://go.hyper.ai/wVktJ
인기 백과사전 기사
1. 핵 규범
2. 양방향 장단기 메모리(Bi-LSTM)
3. 실제값
4. 구현된 내비게이션
5. 초당 프레임 수(FPS)
다음은 "인공지능"을 이해하는 데 도움이 되는 수백 가지 AI 관련 용어입니다.
최고 컨퍼런스 1월 마감일

최고 AI 학술 컨퍼런스에 대한 원스톱 추적:https://go.hyper.ai/event
위에 적힌 내용은 이번 주 편집자 추천 기사의 전체 내용입니다. hyper.ai 공식 웹사이트에 포함시키고 싶은 리소스가 있다면, 메시지를 남기거나 기사를 제출해 알려주세요!
다음주에 뵙겠습니다!
HyperAI 소개
HyperAI(hyper.ai)는 중국을 선도하는 인공지능 및 고성능 컴퓨팅 커뮤니티입니다.우리는 중국 데이터 과학 분야의 인프라가 되고 국내 개발자들에게 풍부하고 고품질의 공공 리소스를 제공하기 위해 최선을 다하고 있습니다. 지금까지 우리는 다음과 같습니다.
* 1800개 이상의 공개 데이터 세트에 대한 국내 가속 다운로드 노드 제공
* 600개 이상의 고전적이고 인기 있는 온라인 튜토리얼 포함
* 200개 이상의 AI4Science 논문 사례 해석
* 600개 이상의 관련 용어 검색 지원
* 중국에서 최초의 완전한 Apache TVM 중국어 문서 호스팅
학습 여정을 시작하려면 공식 웹사이트를 방문하세요.








