Command Palette
Search for a command to run...
단 3초 분량의 오디오로 "자유로운 음성 해설"을 구현하세요: Mistral 오픈 소스 음성 모델 Voxtral-4B-TTS-2603; 데이터 품질의 새로운 기준을 제시하는 Sutra 10B 사전 학습.

현재 경량 음성 모델은 복잡한 다국어 환경과 장문의 더빙을 처리할 때 자연스러움과 배포 효율성 사이의 균형을 맞추는 데 어려움을 겪는 경우가 많습니다. 실제 응용 분야에서 음성 에이전트 및 콘텐츠 방송은 매우 높은 수준의 언어 이해력뿐만 아니라 로컬 환경에서 낮은 지연 시간으로 실행되고 여러 언어 간의 원활한 전환을 지원해야 합니다. 이러한 까다로운 시나리오는 기존 오픈 소스 모델의 파라미터 규모와 엔지니어링 역량에 어려움을 야기합니다.
이러한 맥락에서,미스트랄(Mistral)은 복스트랄-4B-TTS-2603 모델을 공식 출시했습니다. Voxtral TTS는 하이브리드 모델링 프레임워크 기반의 다국어 제로샷 텍스트 음성 변환 모델입니다. Voxtral 코덱을 사용하여 음성을 의미 토큰과 음향 토큰으로 인코딩합니다. 의미 부분은 ASR 증류 과정을 통해 텍스트와 정렬됩니다. 생성 단계에서는 디코더만을 사용하는 자기회귀 모델이 의미 토큰을 점진적으로 생성하여 장거리 일관성을 보장합니다. 동시에, 연속 공간에서 음향 토큰을 효율적으로 생성하기 위해 흐름 매칭 모델이 도입되어 생성 품질과 계산 효율성의 균형을 맞춥니다. "의미 자기회귀 + 음향 흐름 매칭"의 이러한 하이브리드 아키텍처는 이산 모델링과 연속 모델링의 장점을 효과적으로 통합하여 약 3초 분량의 참조 음성만으로도 고품질 음성 복제를 달성하고 다국어 환경에서 우수한 일반화 능력을 보여줍니다.
HyperAI 웹사이트에서 "Voxtral 4B TTS 2603 다국어 음성 생성"을 새롭게 선보입니다. 한번 사용해 보세요!
온라인 사용:https://go.hyper.ai/AoY2t
3월 30일부터 4월 5일까지 hyper.ai 공식 웹사이트의 주요 업데이트 사항을 간략하게 살펴보겠습니다.
* 고품질 공개 데이터 세트: 8개
* 엄선된 고품질 튜토리얼: 10개
* 커뮤니티 기사 해석 : 3개 기사
* 인기 백과사전 항목: 5개
4월에 마감되는 주요 컨퍼런스: 6개
공식 웹사이트를 방문하세요:하이퍼.AI
선택된 공개 데이터 세트
1. 구인 게시판 대학생 구직 데이터 세트
이 데이터셋은 최근 대학 졸업생의 구직 과정을 시뮬레이션한 10만 건의 데이터로 구성된 합성 데이터셋입니다. 데이터셋에는 학생들의 인구통계학적 정보(전공, 대학 순위, 지역 등), 학업 성적(GPA, 인턴십 등), 그리고 구직 과정(지원서 제출, 1차 면접, 2차 면접, 최종 합격)에 대한 정보가 포함되어 있습니다. 최종 합격한 학생들의 경우, 연봉, 기업 규모, 직무 적합도 등의 주요 변수도 함께 제공됩니다.
직접 사용:https://go.hyper.ai/Rj94B
2. Groundsource 글로벌 홍수 발생 데이터 세트
이 데이터셋은 전 세계 뉴스 데이터를 기반으로 자동 구축된 고해상도 역사적 홍수 발생 데이터셋으로, 150개국 이상에서 발생한 260만 건의 홍수 기록을 포함하고 있습니다. 데이터 처리 과정에서 연구팀은 제미니 대규모 언어 모델(LLM)을 활용하여 비정형 뉴스 텍스트에서 홍수 발생 시간 및 위치와 같은 정형 정보를 체계적으로 추출함으로써 대규모 역사적 재해 데이터를 자동으로 구축했습니다.
직접 사용:https://go.hyper.ai/Aj8bq
3. 수트라 10B 사전 학습 교육 및 훈련 데이터 세트
이 데이터셋은 대규모 언어 모델 사전 학습을 위한 고품질 교육용 데이터셋입니다. Sutra 프레임워크를 사용하여 생성된 이 데이터셋은 구조화된 교육 콘텐츠를 제공하고 언어 모델 사전 학습을 최적화합니다. Sutra 시리즈 중 가장 큰 규모의 데이터셋으로, 밀도 높고 잘 선별된 데이터셋이 소규모 언어 모델에 최적의 사전 학습 성능을 제공할 수 있음을 보여주기 위해 설계되었습니다.
직접 사용:https://go.hyper.ai/okKgZ
4. zh-meme-sft-8k 중국 인터넷 밈 문화 데이터셋
이 데이터셋은 중국 인터넷 밈 문화에 대한 세부 학습 데이터셋으로, 주로 유행하는 인터넷 밈을 이해하고 활용하는 대화 모델을 학습하는 데 사용됩니다. 이 데이터셋은 Douyin, Xiaohongshu, Bilibili와 같은 소셜 미디어 플랫폼의 댓글 상호작용을 기반으로 구축되었으며, 여러 차례의 정제 및 개선 과정을 거쳤습니다. 실제 출처에서 추출한 대화 구조, 여러 차례의 정제 과정을 통해 보존된 유행 밈의 높은 품질, 그리고 ChatML 형식을 사용한 표준화 등이 특징입니다.
직접 사용:https://go.hyper.ai/O0asZ
5. 크리에이티브 전문가를 위한 창의적 작업 지침 데이터 세트
이 데이터셋은 멀티모달 AI 에이전트의 학습, 평가 및 미세 조정을 위해 설계된 대규모의 고품질 합성 작업 데이터셋입니다. 36개의 창의적, 기술적, 엔지니어링 소프트웨어 환경을 포괄하는 1,070,917개의 에이전트 명령 작업으로 구성되어 있으며, 복잡한 소프트웨어 상호작용과 다단계 추론 과정을 탐구하는 데 목적이 있습니다.
직접 사용:https://go.hyper.ai/Da6qF
6. 네모트론 페르소나 프랑스 (프랑스 합성 인간 데이터셋)
NVIDIA가 Pleias와 협력하여 2026년에 공개한 이 데이터셋은 프랑스 인구 통계, 지리 및 성격 특성을 기반으로 생성된 합성 캐릭터 데이터셋입니다. 프랑스의 지리적 분포와 성격 특성을 반영하여 다양한 합성 캐릭터 데이터를 제공함으로써 모델 개발을 지원하는 것을 목표로 합니다.
직접 사용:https://go.hyper.ai/8CmKo
7. 학생 정신 건강 데이터 세트(학생 정신 건강 및 소진)
이 데이터셋은 학업, 심리 및 생활 습관 요인을 통해 학생들의 소진 수준을 분석하고 예측하기 위해 설계된 대규모 합성 데이터셋입니다. 15만 건의 학생 기록을 포함하고 있으며, 수치형 및 범주형 특징을 혼합하여 머신러닝, 분류 및 데이터 분석 작업에 적합합니다.
직접 사용:https://go.hyper.ai/YL24S
8. 역사적 팬데믹 및 전염병: 글로벌 역사적 전염병 데이터 세트
이 데이터 세트는 역사상 발생한 주요 세계적 대유행병에 대한 포괄적인 기록으로, 분석에 바로 활용할 수 있는 자료를 제공하도록 설계되었습니다. 서기 165년의 안토니우스 역병부터 2023년의 코로나19와 원숭이두창까지, 모든 시대, 지역, 병원체 유형을 아우르는 50개의 주요 대유행병을 포함하고 있습니다.
직접 사용:https://go.hyper.ai/AbhHY
선택된 공개 튜토리얼
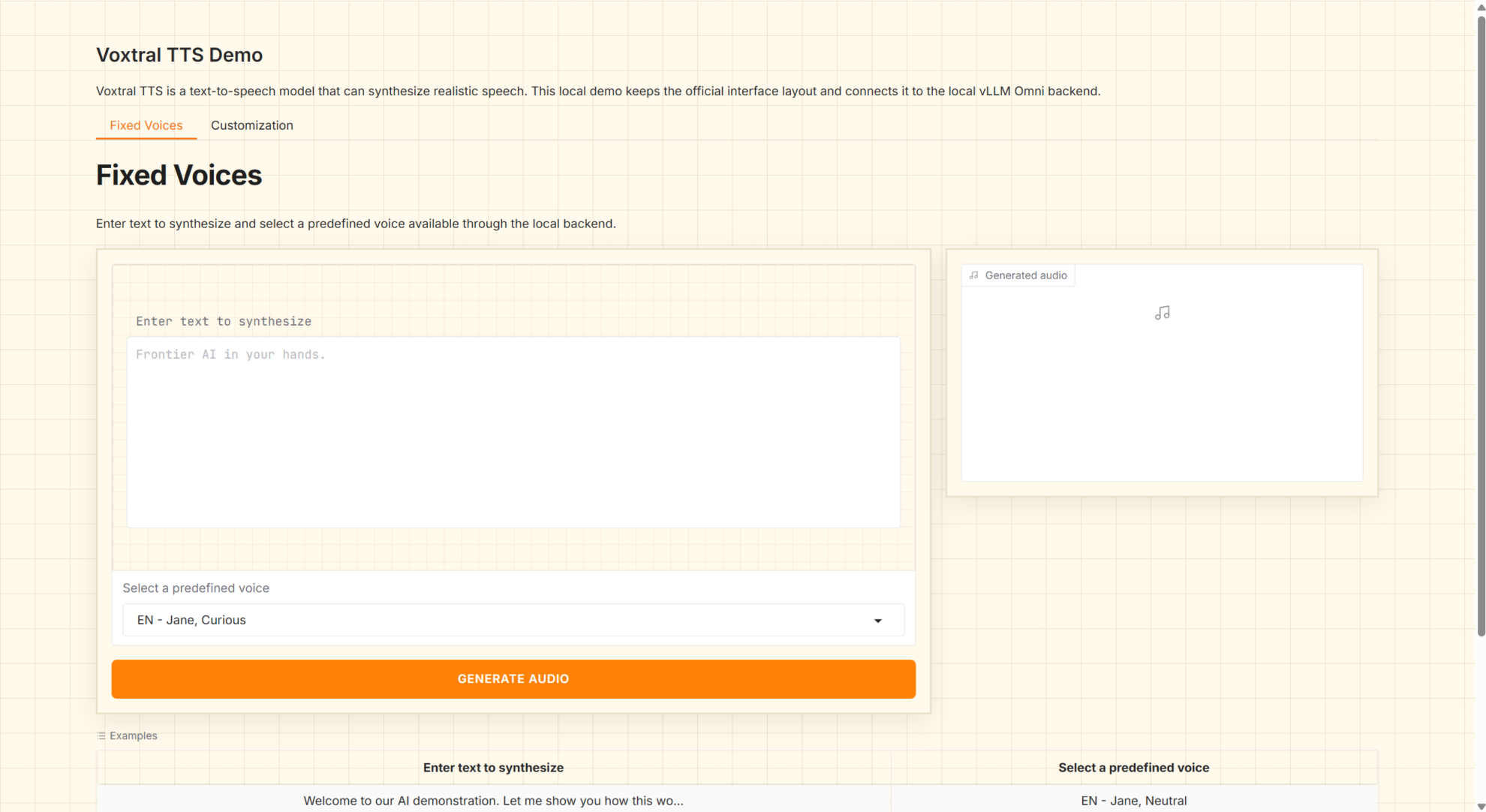
1. Voxtral 4B TTS 2603 다국어 음성 생성
Voxtral-4B-TTS-2603은 Mistral AI에서 2026년 3월에 출시한 4B급 텍스트 음성 변환(TTS) 모델입니다. 개방형 가중치와 다국어 음성 생성 기능을 제공하며, 자연어 텍스트를 재생 가능한 오디오로 직접 합성하는 것을 지원합니다. 이 모델은 음성 에이전트, 음성 방송, 콘텐츠 더빙, 현지화된 TTS 서비스와 같은 시나리오에 적합하며, 표준화된 서비스 인터페이스를 사용하여 로컬에 배포 및 호출할 수 있습니다.
온라인으로 실행:https://go.hyper.ai/AoY2t
2. 링봇월드: 오픈 소스 세계 모델
LingBot-World는 비디오 생성 기반의 오픈 소스 월드 시뮬레이터입니다. 최고 수준의 월드 모델로서, 높은 수준의 환경 구현, 장기 기억 기능, 그리고 실시간 상호작용을 자랑합니다. LingBot-World는 입력 이미지, 텍스트 프롬프트, 카메라 포즈 신호를 기반으로 시공간적 일관성을 갖춘 고품질 비디오를 생성할 수 있는 고급 비디오 생성 아키텍처를 사용합니다.
온라인으로 실행:https://go.hyper.ai/fzF6R
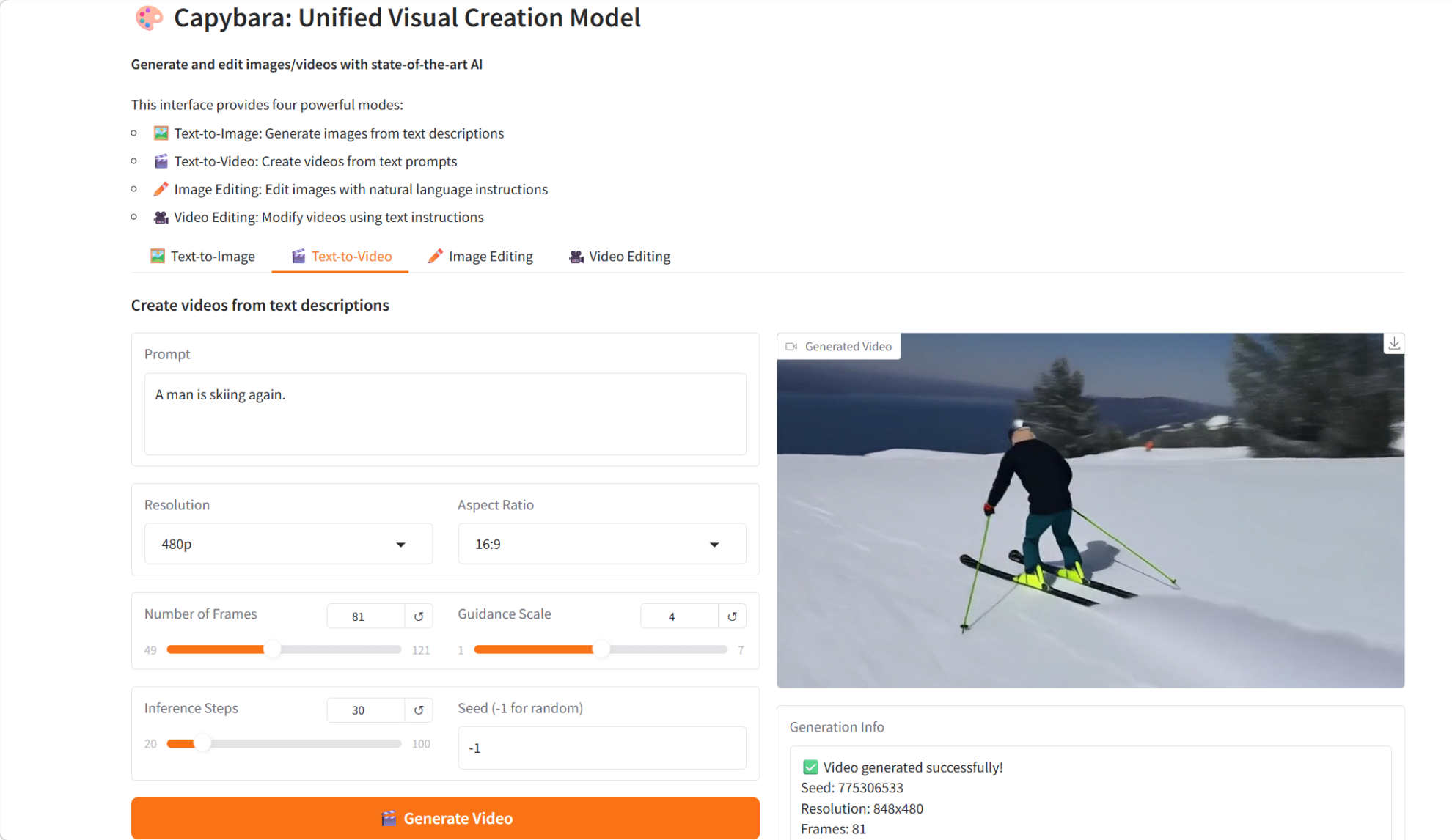
3. 카피바라: 통합된 시각적 창작 모델
2026년 2월 xgen-universe 팀에서 출시한 Capybara는 텍스트를 이미지로 변환, 텍스트를 비디오로 변환, 명령 기반 이미지 편집, 명령 기반 비디오 편집 등 다양한 시각 콘텐츠 생성 작업을 처리하도록 설계된 통합 시각 콘텐츠 생성 모델입니다. 고급 확산 모델과 트랜스포머 아키텍처를 기반으로 구축된 Capybara는 시각 콘텐츠 생성 및 편집을 위한 통합적이고 효율적인 프레임워크를 제공하는 것을 목표로 합니다.
온라인으로 실행:https://go.hyper.ai/yX0Pc
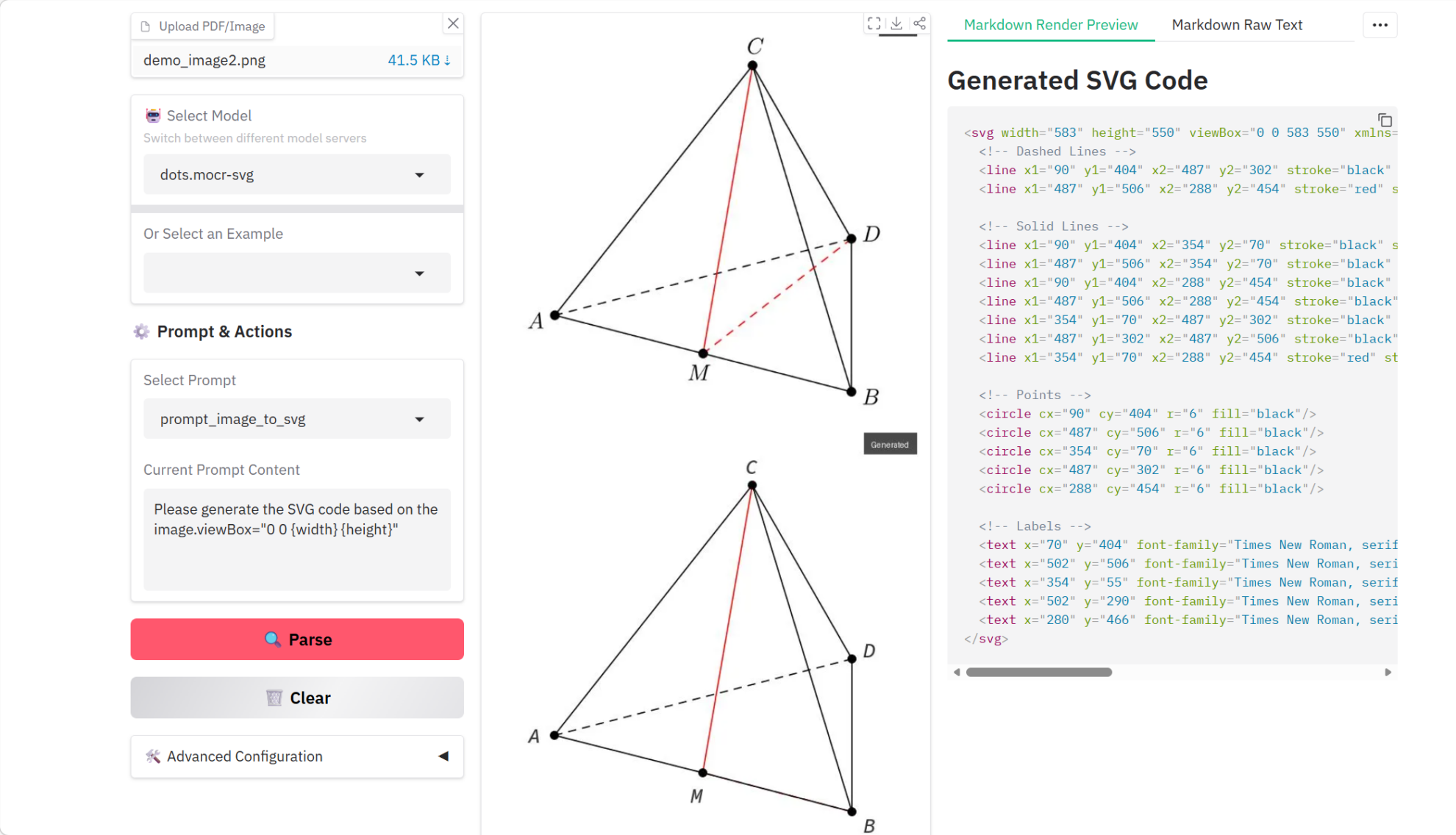
4. dots.mocr 멀티모달 문서 구문 분석 튜토리얼
dots.mocr은 화중과학기술대학교와 샤오홍슈 HI-Lab이 공동으로 2026년 3월에 발표한 멀티모달 OCR 문서 파싱 모델입니다. 비슷한 규모의 모델들 중에서 표준 다국어 문서 파싱 작업에서 최첨단(SOTA) 성능을 달성했습니다. 문서 파싱 외에도 dots.mocr은 차트, UI 레이아웃, 과학 도표 등과 같은 구조화된 그래픽을 SVG 코드로 직접 변환하는 데에도 탁월한 성능을 보여줍니다.
온라인으로 실행:https://go.hyper.ai/g2oB3
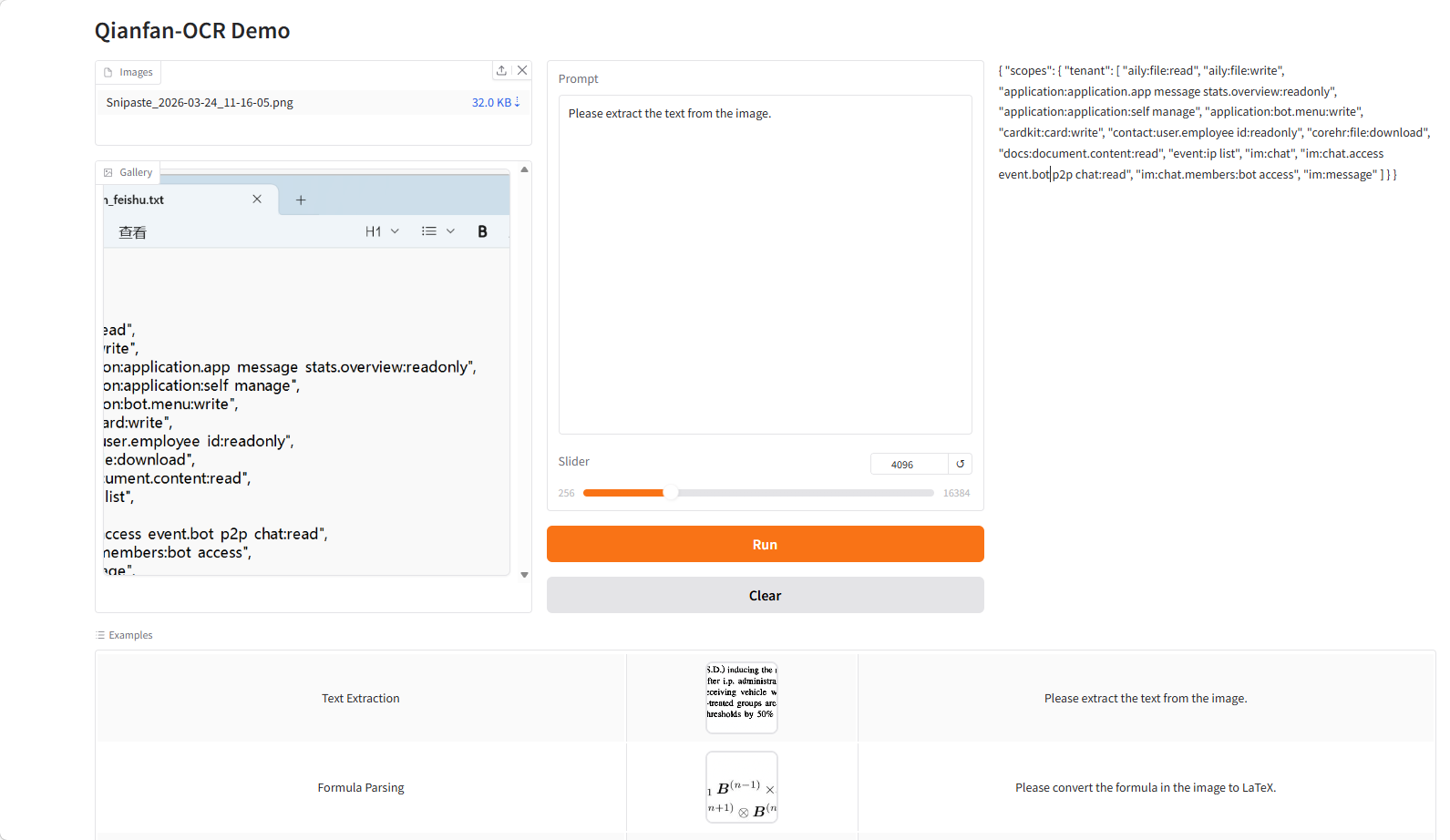
5. Qianfan-OCR: 엔드투엔드 지능형 문서 모델
Qianfan-OCR은 Baidu AI 클라우드 Qianfan에서 2026년 3월에 오픈소스로 공개한 엔드투엔드 문서 인텔리전스 모델입니다. 40억 개 파라미터로 구성된 시각 언어 아키텍처를 기반으로 문서 구문 분석, 레이아웃 분석, 텍스트 인식 및 의미 이해를 통합합니다. 핵심 혁신은 '레이아웃 기반 사고(Layout-as-Thought)' 메커니즘에 있습니다. 모델은 결과를 생성하기 전에 '사고 단계'에 들어가 문서 구조(요소 위치, 유형, 읽는 순서 등)를 명시적으로 모델링한 후 전체 구문 분석을 완료합니다. 이를 통해 구조 인식과 의미 이해의 균형을 맞춘 통합 프레임워크를 구현하여 복잡한 문서 환경에서도 정확성과 안정성을 향상시킵니다.
온라인으로 실행:https://go.hyper.ai/WZIRF
6. vLLM + Open WebUI를 사용하여 sarvam-30b 배포
Sarvam-30B는 Sarvam AI에서 2026년 3월에 공개한 오픈 소스 대규모 언어 모델입니다. Sarvam의 최신 오픈 소스 모델 시리즈 중 30B 버전인 Sarvam-30B는 Mixture-of-Experts(MoE) 아키텍처를 채택했으며, 총 파라미터 크기는 30B이고 토큰당 약 24억 개의 파라미터가 활성화됩니다. 다국어 대화, 추론, 인코딩 및 실제 배포 시나리오에 최적화되어 있습니다.
온라인으로 실행:https://go.hyper.ai/UUJWe
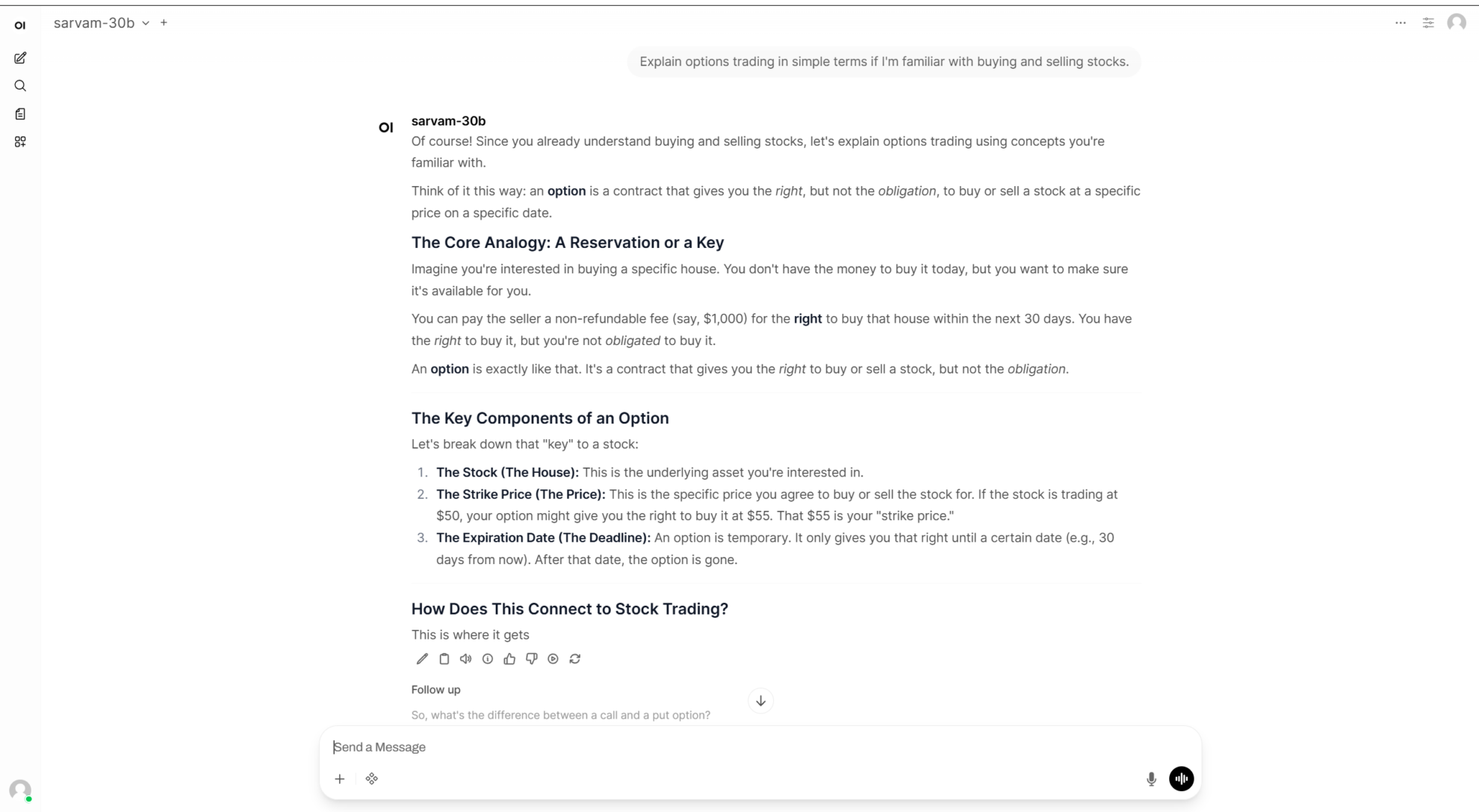
7. Phi-4-추론-시각-15B 멀티모달 추론 시각 모델 데모
Phi-4-reasoning-vision-15B는 마이크로소프트가 2026년 3월에 공개한 150억 개의 파라미터를 가진 멀티모달 추론 시각 언어 모델입니다. Phi-4 아키텍처를 기반으로 하는 이 모델은 강력한 텍스트 추론 및 시각적 이해 기능을 결합하여 복잡한 텍스트-이미지 추론 작업을 처리할 수 있습니다.
온라인으로 실행:https://go.hyper.ai/JQlDE
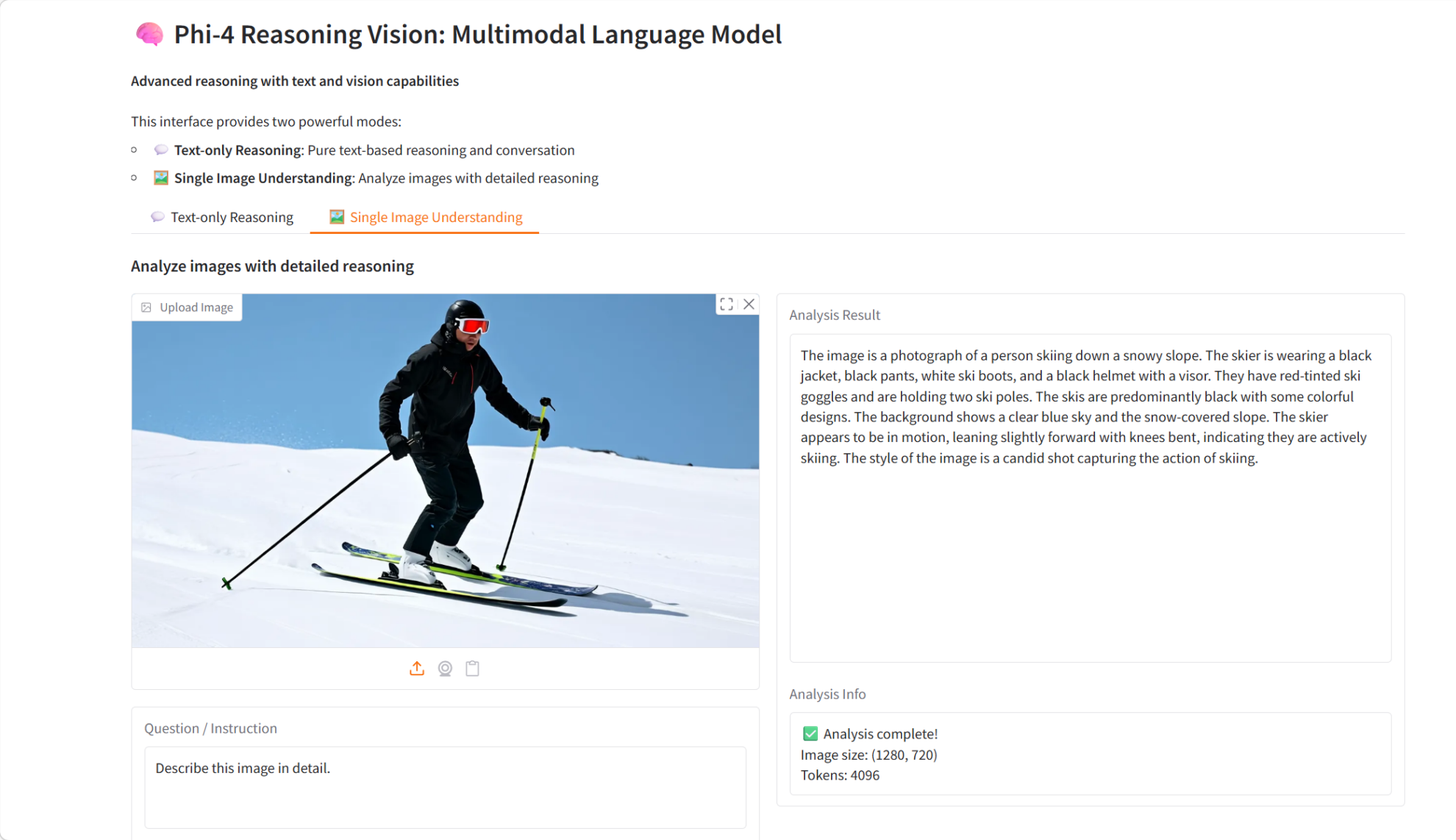
8. Slime: 강화 학습 확장을 위해 설계된 SGLang 기반 사후 학습 프레임워크
Slime은 칭화대학교 지식공학연구소(THUDM)에서 개발한 LLM(Learning Leadership Model) 사후 학습 프레임워크로, 강화 학습 확장을 위해 특별히 설계되었습니다. 이 프레임워크는 Megatron과 SGLang을 결합하여 고성능 학습과 유연한 데이터 생성을 완벽하게 구현합니다.
온라인으로 실행:https://go.hyper.ai/Xrxev
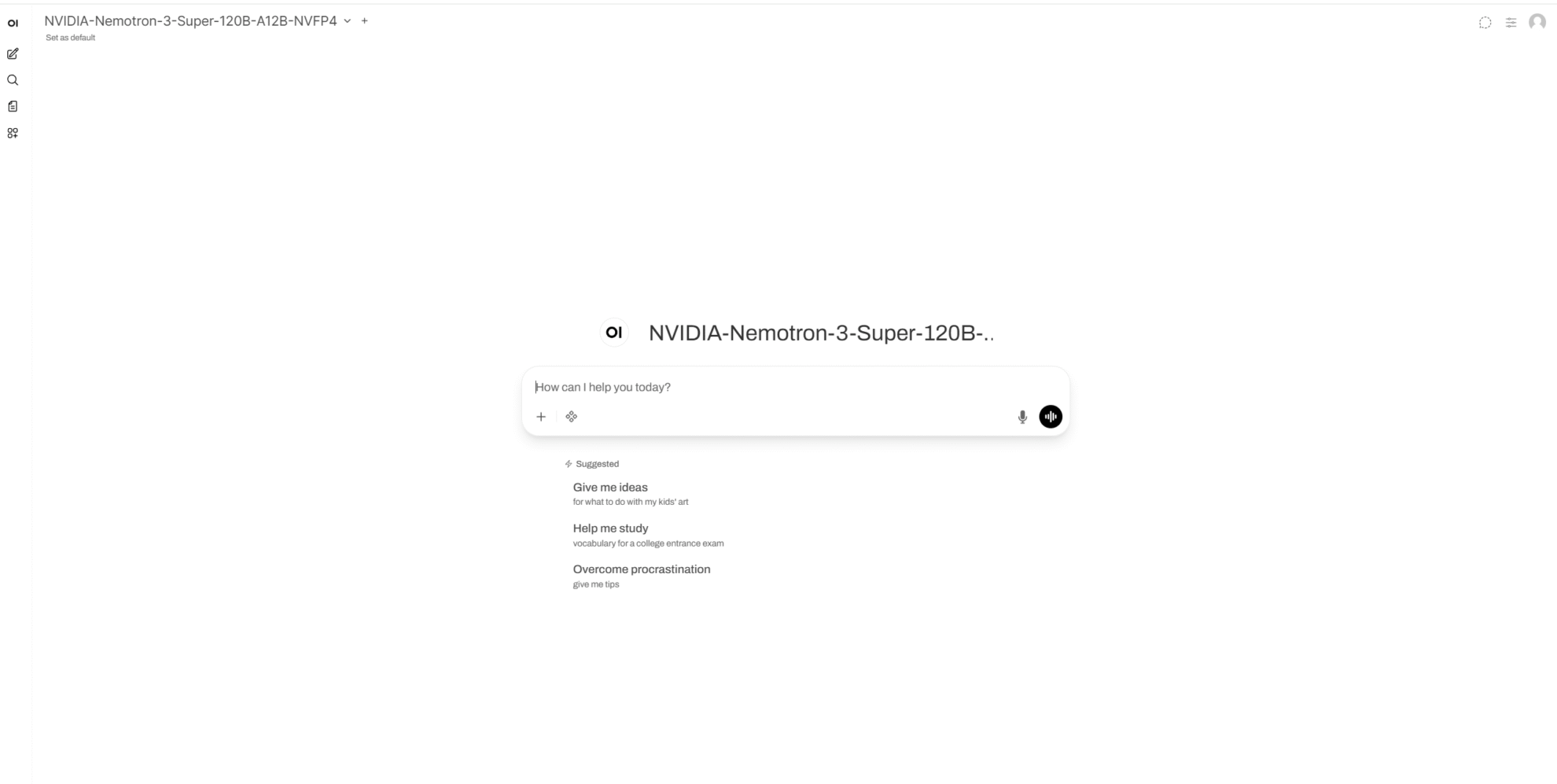
9. NVIDIA-Nemotron-3-Super-120B-A12B-NVFP4의 원클릭 배포
NVIDIA Nemotron 3 Super NVFP4는 NVIDIA Corporation에서 2026년 3월에 출시되었습니다. 이 모델은 총 120개의 파라미터와 12개의 활성화 파라미터를 가진 대규모 언어 모델로, LatentMoE 하이브리드 아키텍처를 사용하며 최대 100만 개의 토큰을 지원하는 컨텍스트를 제공합니다. 장기 컨텍스트 추론, 에이전트 워크플로, 도구 호출, RAG(Real-Assisted Group) 및 고처리량 질의응답 시나리오에 적합하도록 설계되었습니다. 상호 작용 측면에서, 이 모델은 추론 모드 활성화 및 비활성화를 모두 지원하며, 표준화된 채팅 템플릿 파라미터를 통해 일반 질의응답 모드와 향상된 추론 모드 간 전환을 허용합니다.
온라인으로 실행:https://go.hyper.ai/WJmbe
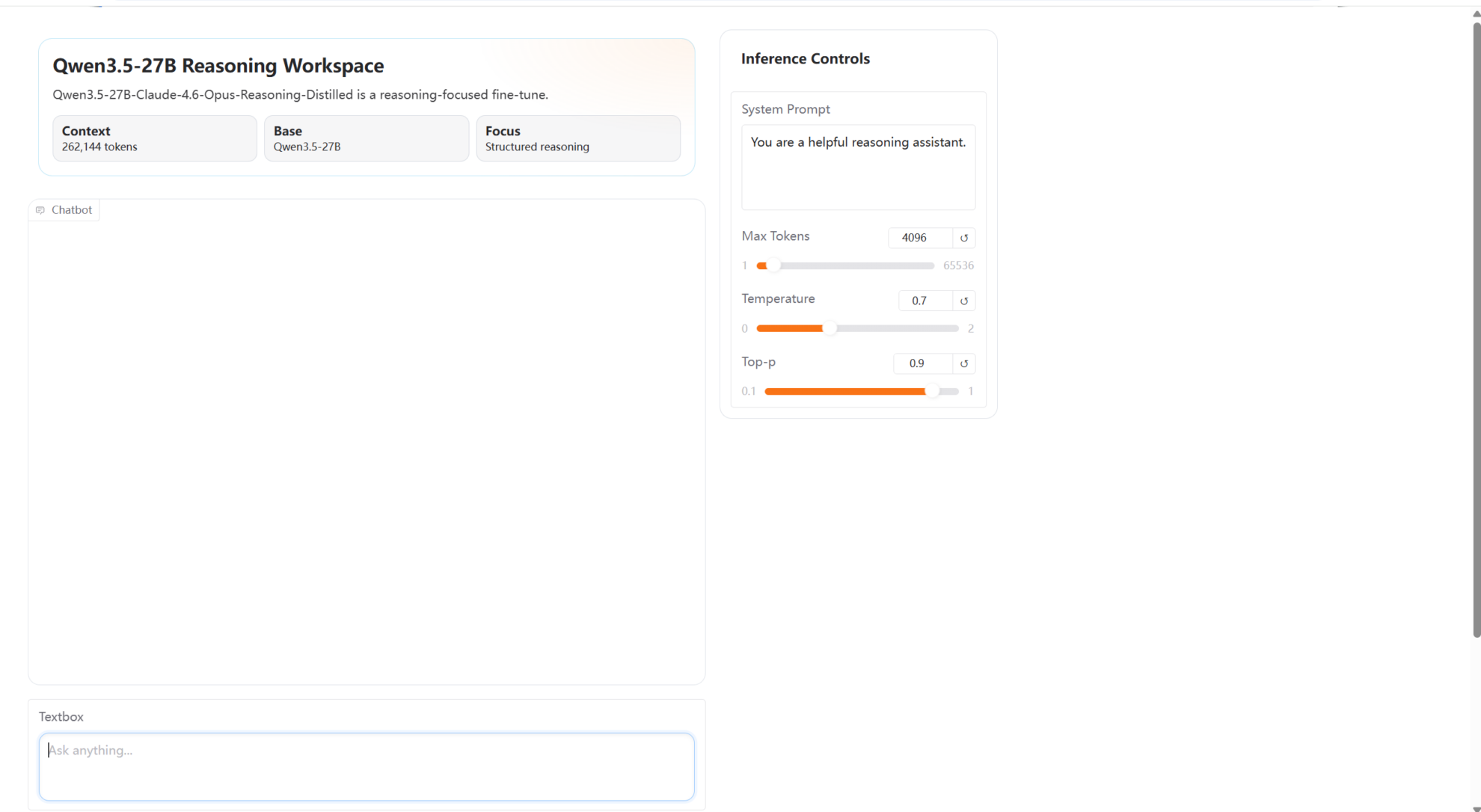
10. Qwen 3.5-27B-Claude-4.6-Opus-Reasoning-Distilled의 원클릭 배포
Qwen3.5-27B-Claude-4.6-Opus-Reasoning-Distilled는 Jackrong에서 2026년 3월에 개발한 고성능 대화 모델입니다. Qwen3.5-27B 플랫폼 모델을 기반으로 Claude-4.6 및 Opus 추론 기능을 통합하여 지식을 추출합니다. 이 모델은 기존 언어 이해 기능을 유지하면서 복잡한 추론 능력과 상호작용적인 대화 경험을 크게 향상시킵니다.
온라인으로 실행:https://go.hyper.ai/SNlOk
커뮤니티 기사 해석
1. MIT 연구팀은 2,000개 반도체 재료의 시뮬레이션된 스펙트럼 데이터를 기반으로 6가지 공존 치환 결함을 분석할 수 있는 DefectNet을 제안했습니다.
MIT 연구팀은 진동 스펙트럼으로부터 치환점결함의 화학적 유형과 농도를 직접 예측할 수 있는 기본적인 기계 학습 모델인 DefectNet을 제안했습니다. 이 모델은 여러 원소가 공존하는 경우에도 적용 가능하며, 56개 원소를 포함하는 미지의 결정에서도 우수한 일반화 능력을 보여주고 실험 데이터를 활용하여 미세 조정할 수 있습니다.
전체 보고서 보기:https://go.hyper.ai/4qtAH
2. AI가 118개의 새로운 외계행성을 발견했습니다! 워릭 대학교 연구팀은 RAVEN이라는 도구를 제안했는데, 이 도구는 행성 시나리오와 각각의 오탐지 시나리오를 일대일로 비교할 수 있게 해줍니다.
워릭대학교 연구팀은 TESS 후보를 선별하고 검증하는 새로운 프로세스인 RAVEN을 제안했습니다. 이 프로세스는 합성 학습 데이터셋을 도입하여, 기존처럼 TESS 작업 자체에서 생성되는 임계값 초과(TCE) 이벤트 데이터에만 의존하는 방식을 넘어섰습니다. 이러한 개선을 통해 기계 학습 모델이 다룰 수 있는 행성 및 오탐지 시나리오의 매개변수 공간이 크게 확장되고 향상되었습니다. 1361개의 사전 분류된 TESS 후보로 구성된 독립적인 외부 테스트 세트에서, 이 프로세스는 91%의 전체 정확도를 달성하여 TESS 후보를 자동으로 순위 매기는 데 효과적임을 입증했습니다.
전체 보고서 보기:https://go.hyper.ai/phEO5
3. MIT는 서열과 진동 간의 양방향 매핑을 구현하는 최초의 엔드투엔드 동적 단백질 생성 모델인 VibeGen을 제안했습니다.
MIT와 카네기멜론 대학교의 연구팀이 서열 생성과 진동 역학 예측을 결합하여 새로운 단백질 설계를 가능하게 하는 지능형 단백질 생성 에이전트 모델인 VibeGen을 제안했습니다. 연구 결과에 따르면 이 생성 에이전트로 설계된 단백질은 안정적이고 새로운 구조로 접힐 뿐만 아니라 주쇄 수준에서 목표 진동 진폭의 분포 특성까지 재현할 수 있는 것으로 나타났습니다.
전체 보고서 보기:https://go.hyper.ai/jDaSW
인기 백과사전 기사
1. 역방향 정렬과 RRF의 결합
2. 인공신경망(NN)
3. 시각 언어 모델(VLM)
4. 회전 위치 인코딩(RoPE)
5. 양방향 장단기 메모리(Bi-LSTM)
다음은 "인공지능"을 이해하는 데 도움이 되는 수백 가지 AI 관련 용어입니다.
위에 적힌 내용은 이번 주 편집자 추천 기사의 전체 내용입니다. hyper.ai 공식 웹사이트에 포함시키고 싶은 리소스가 있다면, 메시지를 남기거나 기사를 제출해 알려주세요!
다음주에 뵙겠습니다!








