Command Palette
Search for a command to run...
MIT 등이 개발한 GPU 전력 예측 프레임워크인 EnergAIzer는 평균 1.8초 만에 예측을 완료하며, 오차 범위는 약 81 TP3T입니다.

로렌스 버클리 국립 연구소의 추산에 따르면, 인공지능의 폭발적인 성장으로 인해,2028년까지 데이터 센터는 미국 전체 전력 사용량의 121 TP3T를 소비할 것으로 예상됩니다.인공지능(AI) 워크로드의 주요 가속기인 그래픽 처리 장치(GPU)는 전력 소비의 주요 원인이 되었으며, 최신 NVIDIA H100 및 GB200의 열 설계 전력(TDP)은 각각 700W 및 1200W에 달합니다. 점점 더 심각해지는 에너지 문제 속에서,AI 워크로드에 필요한 GPU 성능과 에너지 소비량을 신속하게 예측하는 것이 매우 중요해졌습니다.
전력 소비 모델은 일반적으로 다양한 GPU 모듈(예: DRAM 및 Tensor 코어)의 사용 강도를 특성화하기 위해 하드웨어 활용률 정보를 입력으로 필요로 합니다. 동적 전력 소비는 모듈 활동에 직접 비례하기 때문입니다. 기존 방법은 주로 두 가지 접근 방식을 통해 이 정보를 얻습니다. 하나는 명령어 수준 시뮬레이터를 사용하여 GPU 실행 사이클을 사이클 단위로 시뮬레이션함으로써 모듈 활용률을 도출하는 것입니다.하지만 중간 규모의 작업 부하에서도 이처럼 상세한 시뮬레이션을 완료하는 데는 몇 시간이 걸릴 수 있습니다.두 번째는 런타임 성능 분석(프로파일링)입니다.하지만 이는 분석 오버헤드를 증가시킬 뿐만 아니라 사용 가능한 하드웨어 리소스에도 의존하게 됩니다.
이러한 배경에서MIT와 MIT-IBM 왓슨 AI 연구소의 연구원들이 AI 워크로드를 위한 빠른 GPU 전력 예측 프레임워크인 EnergAIzer를 개발했습니다.이 시스템은 값비싼 시뮬레이션이나 성능 분석 없이도 전력 소비 모델에 필요한 하드웨어 활용 정보를 직접 제공할 수 있습니다.이 새로운 프레임워크는 전력 소비량 예측을 처음부터 끝까지 평균 1.8초 만에 완료할 수 있습니다.NVIDIA Ampere GPU에서 EnergAIzer는 약 81 TP3T의 전력 소비 오차를 달성했는데, 이는 복잡한 주기적 시뮬레이션이나 하드웨어 성능 분석에 의존하는 기존 모델과 비교했을 때 경쟁력 있는 수준입니다.
연구진은 또한 EnergAIzer의 주파수 확장 및 아키텍처 구성 탐색 기능을 시연했습니다.NVIDIA H100의 전력 소비량 예측을 포함하더라도 오차는 7%에 불과합니다.EnergAIzer는 AI 워크로드에 대한 빠르고 정확한 전력 소비 예측 기능을 제공합니다. 데이터 센터 운영자는 이러한 예측값을 활용하여 제한된 리소스를 여러 AI 모델과 프로세서에 효과적으로 할당함으로써 에너지 효율을 향상시킬 수 있습니다.
"EnergAIzer: AI 워크로드를 위한 빠르고 정확한 GPU 전력 예측 프레임워크"라는 제목의 관련 연구 결과는 arXiv에 사전 공개되었습니다.
연구 하이라이트:
* 새로운 프레임워크는 단 몇 초 만에 신뢰할 수 있는 전력 소비량 추정치를 생성하는 반면, 기존 모델링 기법은 결과를 도출하는 데 몇 시간 또는 며칠이 걸릴 수 있습니다.
* 새로운 예측 도구는 아직 출시되지 않은 새로운 설계까지 포함하여 광범위한 하드웨어 구성에 적용할 수 있습니다.
이 도구는 알고리즘 개발자와 모델 제공업체가 새로운 모델을 배포하기 전에 잠재적인 에너지 소비량을 평가하는 데 도움이 됩니다.

서류 주소:
https://arxiv.org/abs/2604.20105
저희 공식 위챗 계정을 팔로우하고 백그라운드에서 "전력 소비 예측"이라고 답장하시면 전체 PDF 파일을 받으실 수 있습니다.
데이터셋: 다양한 주요 연산자 유형과 텐서 형태를 포함합니다.
모든 실험에서,연구원들은 NVIDIA A100-40GB-PCIE 및 A10 GPU를 기반으로 오프라인 커널 데이터베이스를 구축했습니다.EnergAIzer 학습에 사용되는 다양한 주요 연산자 유형 및 텐서 형태에 대한 자세한 내용은 아래 표를 참조하십시오.
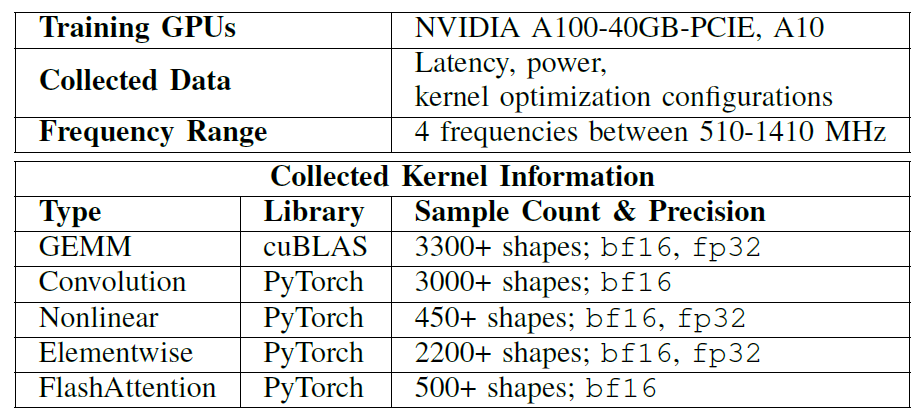
포함하다:
* GEMM 유형 행렬 계산
* 합성곱
* 비선형
* 요소별
* 플래시 주의
연구진은 EnergAIzer에 실험 자원을 제공했습니다.여기에는 추정 프레임워크의 소스 코드, 경험적 적합을 위한 사전 수집된 데이터베이스, 그리고 예측을 검증하기 위한 실제 측정 데이터가 포함됩니다.이 데이터베이스에는 실험 재현 스크립트, 단일 커널 수준의 전력 및 지연 시간 추정치 생성, AI 워크로드에 대한 엔드 투 엔드 추정치 생성 등의 리소스가 포함되어 있습니다.
EnergAIzer 커널 레벨 예측 모델 구축을 위한 세 단계
ENERGAIZER의 핵심은 연구원들이 세 단계를 거쳐 구축하는 커널 수준 예측 모델입니다.첫 번째,타일링, 스레드 블록 스케줄링, 파이프라인과 같은 소프트웨어 최적화 전략과 같은 워크로드 표현 방식을 확립하면 성능 모델의 기반이 되는 구조화된 실행 패턴이 형성됩니다.둘째,이러한 패턴을 기반으로 성능 모델을 구축하고 실증 데이터를 적용합니다.마침내,전력 소비 모델은 예측된 이용률을 사용하여 동적 전력 소비량을 추정합니다.
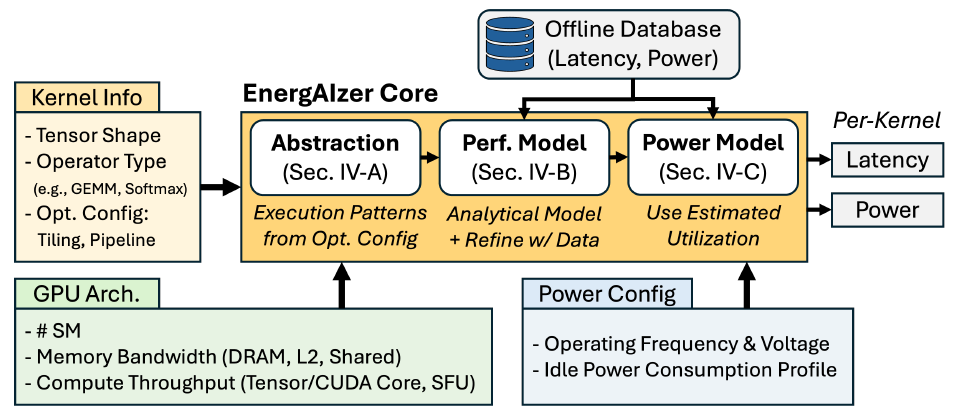
작업 부하 구조 모델링 레이어
최적화 전략
텐서는 GPU 실행의 다양한 레벨에서 데이터 타일로 계층적으로 분할됩니다. 스레드 블록 스위즐링은 동일한 입력 타일에 접근하는 스레드 블록을 인접한 텐서에 스케줄링하여 L2 캐시 재사용성을 향상시킵니다. 소프트웨어 파이프라인은 데이터 전송과 계산을 시간적으로 중첩시킵니다. 파이프라인 구조는 노출되는 지연 시간을 결정하며, 이는 성능 모델링의 핵심 요소입니다.
GEMM을 넘어서
이를 바탕으로 연구진은 서비스 전력 모델링을 위한 모듈 수준 활용도를 도출하기 위해 AI의 모든 주요 커널 유형(비선형, 요소별, 융합 커널 포함)으로 분석을 체계적으로 확장했습니다.
확인하다
연구진은 분석 방법을 사용하여 공유 메모리, L2 캐시 및 DRAM의 총 부하 트래픽을 도출하고 NVIDIA A100-40GB-PCIE GPU에서 NCU 성능 분석을 통해 얻은 하드웨어 카운터 데이터와 비교했습니다. 790개 이상의 GEMM 코어, 70개 이상의 Softmax 코어 및 380개 이상의 FlashAttention 코어에서 거의 완벽한 상관관계가 관찰되었으며, 이는 블록 매개변수와 이상적인 스레드 블록 재배열이 메모리 트래픽을 결정한다는 것을 입증합니다.
성능 모델 레이어
타임라인 구축
성능 모델은 세분화되지 않은 작업들로 구성된 실행 타임라인을 구축합니다. 틸팅은 작업의 세분화 정도(예: 데이터 로딩/저장, 연산 명령어 수)를 결정하고, 파이프라인은 이러한 작업들이 종속성을 기반으로 어떻게 중첩되는지를 결정합니다. 이 타임라인은 분석의 틀을 형성하며, 아래 그림과 같이 모듈 수준의 활용도를 파악하는 데 사용됩니다.
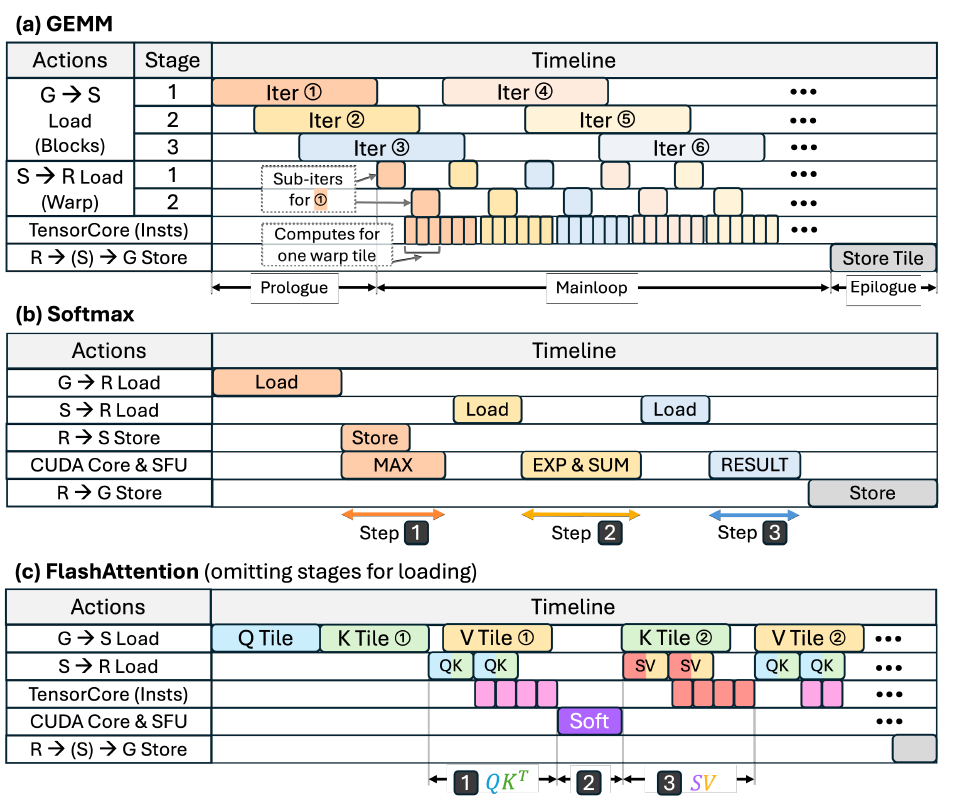
지연 예측
타임라인 구조를 설정한 후, 각 작업의 지연 시간을 계산하는 방법을 설명하고, 이어서 이러한 개별 작업의 지연 시간을 합산하여 파이프라인의 영향을 반영하는 전체 실행 시간을 산출합니다.
활용 파생
빌드 타임라인을 기반으로 DRAM, L2 캐시, 공유 메모리, 텐서 코어, CUDA 코어(일반 부동 소수점 연산용), 특수 기능 장치(지수 및 기타 비선형 함수용) 등 6개 핵심 모듈의 활용률을 추출했습니다. 각 모듈의 활용률은 해당 모듈이 활성화된 시간을 전체 커널 실행 시간으로 나눈 비율로 정의했습니다.
전력 소비 모델 레이어
연구진은 성능 모델에서 얻은 모듈 수준 활용률을 기반으로 표준 동적 전력 소비 공식을 사용하여 이를 추정했습니다. 이 방법은 기존 전력 소비 모델링과 형식적으로는 동일하지만, 핵심적인 차이점은 활용률 α를 도출하는 방식에 있습니다. 오프라인 데이터베이스는 여러 동작 주파수에서의 전력 소비 측정값을 포함하고 있으므로, C 계수는 전체 주파수 범위에서 오차를 최소화하도록 조정됩니다. 따라서 추론 단계에서 추가 측정 없이 모든 주파수에서의 전력 소비를 추정할 수 있습니다.
평균적으로 작업 부하당 지연 시간과 전력 소비량을 동시에 추정하는 데 1.8초밖에 걸리지 않습니다.
연구진은 EnergAIzer의 예측력과 다양한 설계 옵션 탐색에 있어 그 적용 가능성을 실험적으로 평가했습니다.
AI 워크로드에 대한 지연 시간 및 전력 소비량 추정의 정확도
아래 그림은 다양한 언어 모델(BERT-Large, GPT-2, OPT-1.3B, Qwen2-1.5B)과 시각 모델(ResNet101, ViT, MobileViT)에 대한 종단 간 지연 시간 및 전력 소비량 추정 결과를 보여줍니다.
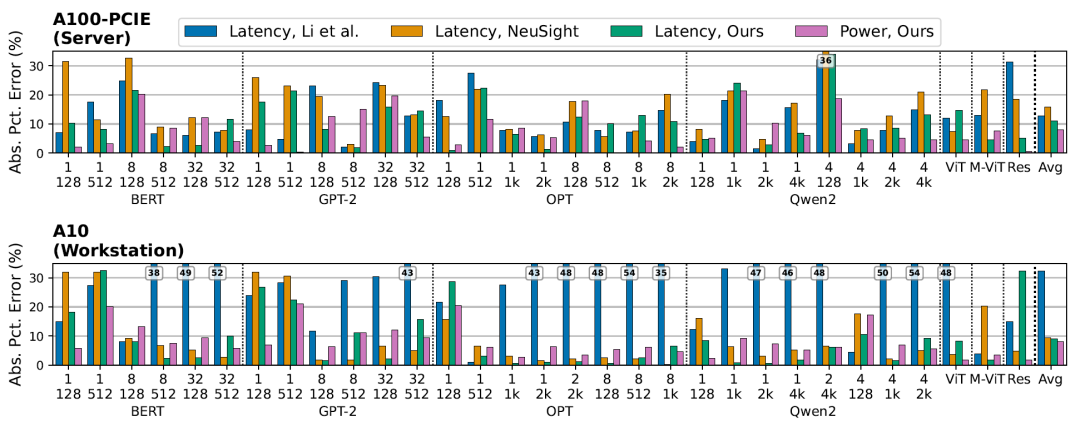
EnergAIzer는 서버급 GPU(A100-40GB-PCIE)에서 평균 지연 시간 오차 11.01 TP3T, 전력 소비 오차 8.01 TP3T를 달성했습니다.워크스테이션급 GPU(A10)에서는 각각 8.8%와 8.2%입니다.이 결과는 모든 워크로드에 걸쳐 평균화된 값입니다. 지연 시간 예측 측면에서 EnergAIzer는 최첨단 경량 성능 모델(Li et al., NeuSight)과 경쟁력 있는 성능을 보이며, 이러한 모델들이 제공할 수 없는 전력 예측 기능도 제공합니다.
EnergAIzer는 작업 부하당 평균 1.8초 만에 지연 시간과 전력 소비량을 동시에 추정합니다.언어 모델의 경우, 단일 예측에 1.1초에서 2.8초가 소요됩니다. 반면, NCU를 사용한 하드웨어 카운터 획득은 452초에서 8192초가 소요되므로, 317배에서 3856배의 속도 향상을 달성합니다.
전압-주파수 조절에 대해 알아보세요.
전압-주파수 조절은 다양한 작동 지점에서 정확한 전력 소비 예측을 통해 이점을 얻을 수 있는 일반적인 전력 관리 기술입니다. 연구진은 A100-40GB-PCIE 보드에서 EnergAIzer를 사용하여 다양한 주파수(510~1410MHz)에서의 전력 소비량을 예측하는 능력을 평가했습니다. 실험에서는 EnergAIzer의 전력 구성 입력 매개변수(목표 주파수, 전압, 해당 주파수에서의 대기 전력 소비량)만 조정했습니다. 다음 그림은 실제 측정값과 예측 전력 소비량의 비교를 보여줍니다.
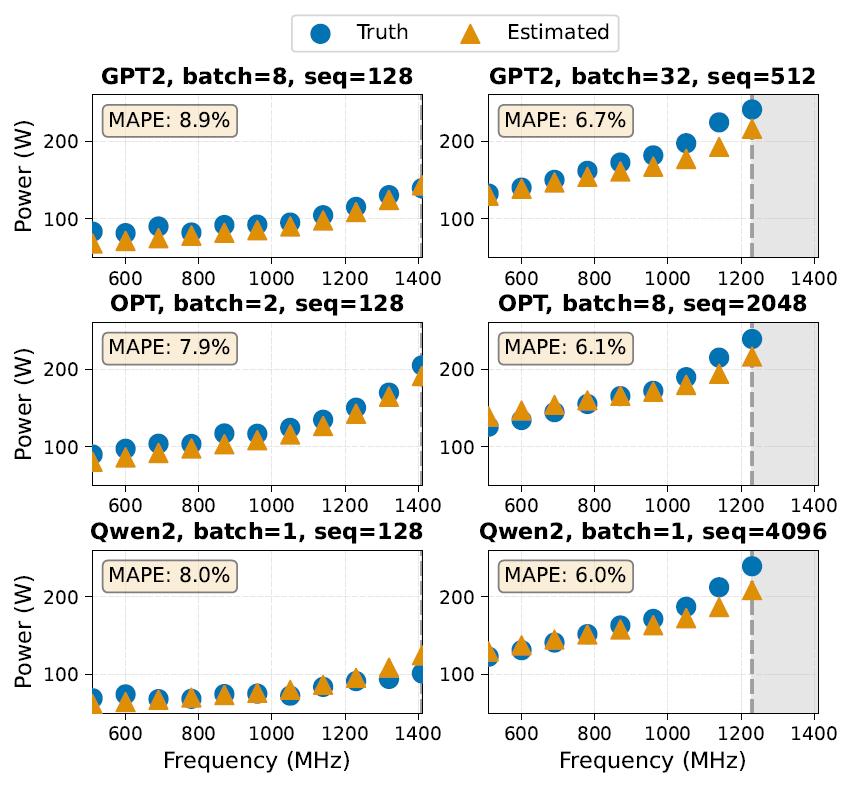
EnergAIzer 프레임워크는 다양한 워크로드 유형에 대한 일반적인 확장 동작을 포착할 수 있습니다. 여기에는 사용률이 낮은 워크로드(소규모 배치/시퀀스, 왼쪽 그림)와 전력 제약이 있는 워크로드(대규모 배치/시퀀스, 오른쪽 그림)가 포함됩니다.서로 다른 주파수에서의 평균 절대 백분율 오차(MAPE)는 6%~9%입니다.
GPU 아키텍처 구성 살펴보기
이 프레임워크는 또한 GPU 아키텍처 매개변수(예: SM 개수, 메모리 대역폭, 컴퓨팅 처리량)를 입력으로 조정하여 다양한 GPU 아키텍처 구성을 탐색하는 것을 지원합니다.이를 통해 목표 하드웨어 데이터 수집 없이도 새로운 아키텍처의 전력 소비량을 예측할 수 있습니다. 연구진은 동일한 GPU 아키텍처 세대 내에서의 탐색과 여러 아키텍처 세대에 걸친 탐색이라는 두 가지 시나리오를 평가했습니다. 목표 GPU 구성은 아래 표에 요약되어 있습니다.
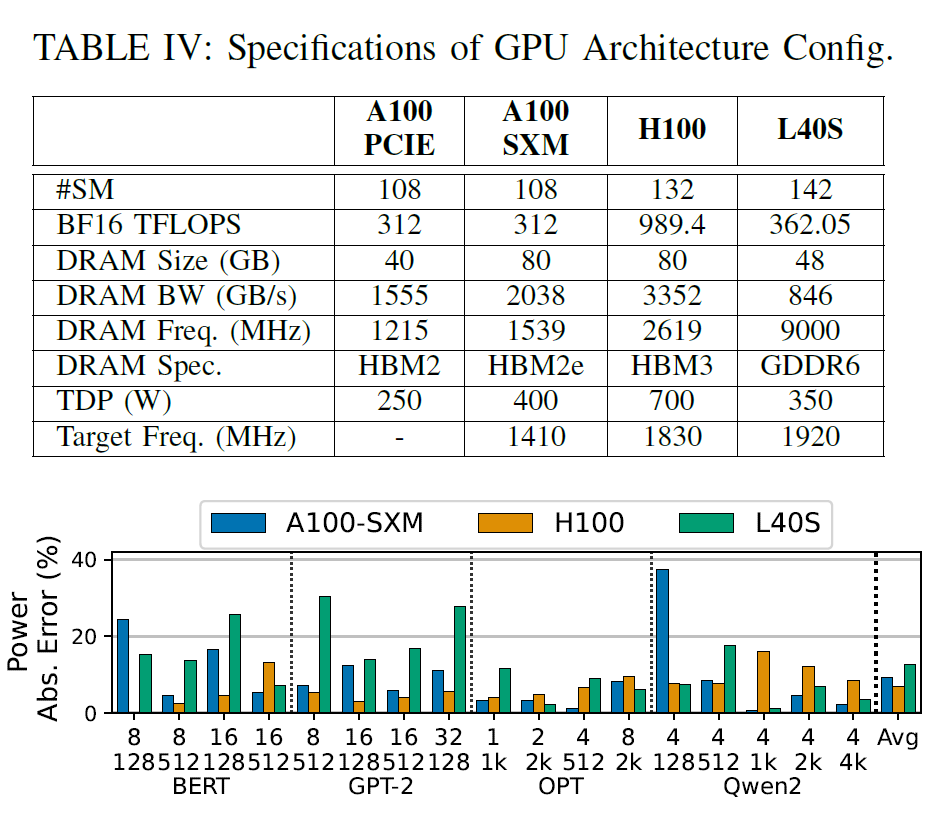
첫째, 암페어 아키텍처 내에서 연구원들은 A100-40GB-PCIE에서 수집한 데이터베이스만을 사용하여 A100-80GB-SXM의 전력 소비량을 예측했으며, 평균 오차는 9.11 TP3T였습니다. 둘째, 세대 간 비교 시나리오에서 암페어 아키텍처 데이터베이스를 사용하여 호퍼(H100)와 러브레이스(L40S)의 전력 소비량을 예측한 결과, 오차는 각각 6.71 TP3T와 12.71 TP3T였습니다.
전반적으로 EnergAIzer는 AI 워크로드에 대한 빠르고 정확한 전력 소비 예측을 제공합니다.
결론
데이터 센터 운영자의 경우, EnergAIzer는 다양한 GPU 구성, 주파수 전략 및 리소스 스케줄링 방식의 에너지 소비 성능을 신속하게 평가하여 더욱 정교한 리소스 오케스트레이션과 에너지 효율성 최적화를 지원합니다. AI 모델 개발자에게는 이 프레임워크가 새로운 "하드웨어 인식" 도구를 제공합니다. 모델 설계 단계에서 다양한 정밀도와 운영자 구현 방식에 따른 성능과 전력 소비 간의 상충 관계를 평가할 수 있으므로, 배포 단계에서만 드러나는 에너지 소비 문제를 사전에 방지할 수 있습니다.
물론, 현재 프레임워크는 멀티 GPU 협업 컴퓨팅, 통신 오버헤드, 불규칙적인 희소 컴퓨팅에 대한 모델링 기능 개선 필요성 등 몇 가지 한계를 여전히 가지고 있습니다. 그러나 방법론적 관점에서 EnergAIzer는 GPU 전력 소비 모델링이 "측정에 크게 의존하는" 오프라인 분석 도구에서 "경량화되고 내장 가능한" 온라인 의사 결정 기능으로 진화하고 있다는 분명한 추세를 보여주었습니다. AI 컴퓨팅 성능의 지속적인 확장과 에너지 제약이 점점 더 심화되는 상황에서 이러한 기술의 가치는 빠르게 증가하고 있습니다. 앞으로 모델의 복잡성과 하드웨어 이질성이 더욱 증가함에 따라 EnergAIzer와 같은 프레임워크는 단순한 연구 도구를 넘어 AI 인프라의 필수적인 부분이 될 가능성이 높습니다.
참고 자료
https://news.mit.edu/2026/faster-way-to-estimate-ai-power-consumption-0427
https://arxiv.org/pdf/2604.20105








