Command Palette
Search for a command to run...
MOSS-TTS: CAT 아키텍처 기반의 분리형 상용 음성 생성 모델; 단일 세포 분석의 한계 극복: 범암 scRNA-Seq 데이터셋을 활용한 다양한 암종 면역 아틀라스 벤치마크 구축.

현재 단일 음성 생성 모델은 복잡한 실제 요구 사항을 충족하기에 역부족입니다. 실제 응용 프로그램에서 음성은 특정 음색을 충실히 모방해야 할 뿐만 아니라, 다양한 콘텐츠에 걸쳐 자연스럽게 말하는 스타일을 전환하고 수십 분에 걸친 내러티브 전반에 걸쳐 안정적인 음성을 유지해야 합니다. 또한 대화, 역할극, 실시간 상호작용과 같은 다양한 형식을 지원해야 합니다. 이러한 요구 사항은 단일 모델의 역량을 훨씬 뛰어넘습니다.
이러한 맥락에서,MOSI.AI와 OpenMOSS는 음성 생성 모델 제품군인 MOSS-TTS 패밀리를 출시했습니다.이 모델 제품군은 단일의 방대한 모델을 구축하는 대신, 음성 생성 워크플로우를 고음질 음성 기반 모델인 MOSS-TTS와 다중 화자 대화 모델인 MOSS-TTSD를 포함한 5개의 프로덕션급 모델로 분리합니다. 핵심 기술은 16억 개의 파라미터를 가진 대규모 오디오 토크나이저인 MOSS Audio-Tokenizer를 기반으로 하며, 순수 트랜스포머 아키텍처(CAT, Causal Audio Tokenizer with Transformer)를 사용하여 고음질 오디오 복원을 구현합니다. 이 모델 시리즈는 복잡한 시나리오에서 발생하는 다양한 응용 문제를 해결하며, 음성 생성 분야에서 저작 워크플로우에 직접 통합할 수 있는 툴체인을 제공합니다.
HyperAI 웹사이트에서 "MOSS-TTS: 고품질 다중 장면 음성 생성 모델"을 만나보세요! 한번 사용해 보세요!
온라인 사용:https://go.hyper.ai/AtKvk
3월 2일부터 3월 6일까지 hyper.ai 공식 웹사이트의 주요 업데이트 사항을 간략하게 살펴보겠습니다.
* 고품질 공개 데이터 세트: 3개
* 고품질 튜토리얼 선택: 8개
* 커뮤니티 기사 해석 : 3개 기사
* 인기 백과사전 항목: 5개
* 3월 마감일 상위 컨퍼런스: 4
공식 웹사이트를 방문하세요:하이퍼.AI
선택된 공개 데이터 세트
1. 드론 소리 오디오 감지 데이터 세트
이 데이터셋은 '알 수 없는 소리'와 '드론 소리' 두 가지 범주의 오디오 녹음 파일을 포함합니다. 실제 환경에서 드론 소리를 감지하는 이진 오디오 분류 작업에 적합하도록 설계되었습니다. 데이터셋의 오디오 파일은 WAV와 같은 표준 형식으로 제공되므로 멜 스펙트로그램 추출, MFCC 특징 추출, 단시간 푸리에 변환(STFT) 및 원시 파형에 대한 딥러닝 모델과 같은 전처리 기법에 활용할 수 있습니다.
직접 사용:https://go.hyper.ai/vKHJC
2. 약물 부작용 시뮬레이션 데이터 세트
이 데이터 세트는 약물 부작용(ADR)에 대한 약물감시 보고서를 모방하도록 설계되었으며, 약물 안전성 모니터링 분야의 연구, 머신러닝 실험 및 알고리즘 개발을 지원하는 것을 목표로 합니다. 사례 안전성 보고서(ICSR)는 FDA FAERS 및 EMA EudraVigilance와 같은 실제 약물감시 시스템에서 영감을 받아 인위적으로 생성되었습니다.
직접 사용:https://go.hyper.ai/Jex4v
3. 범암 scRNA-Seq 단일 세포 전사체 아틀라스 데이터 세트
이 데이터 세트는 건강한 면역 상태, 혈액암(골수성 백혈병), 고형암 미세환경(흑색종)의 세 가지 생물학적 상태를 포괄하는 7,930개의 단일 세포에서 얻은 전사체 발현 데이터를 포함합니다. 본 연구는 알고리즘 성능 평가 및 방법론 비교, 다중 코호트 배치 효과 보정, 면역 소진 상태 분석, 그리고 다양한 종양 유형에 적용 가능한 바이오마커 발굴을 위한 기준점을 제공하기 위해 여러 코호트를 통합한 단일 세포 분석 벤치마크를 구축하는 것을 목표로 합니다.
직접 사용:https://go.hyper.ai/CnZTc
선택된 공개 튜토리얼
1. ACE-Step 1.5: 음악 생성 데모
ACE-Step 1.5는 ACE Studio와 StepFun이 공동으로 개발한 오픈소스 음악 생성 기반 모델로, 오픈소스 음악 생성 기능의 한계를 뛰어넘는 것을 목표로 합니다. 이 모델은 혁신적인 2단계 생성 아키텍처를 채택하여 확산 변환기(DiT)와 언어 모델(LM)의 협력적 통합을 통해 고품질의 장시간 음악 콘텐츠 생성을 구현합니다.
온라인으로 실행:https://go.hyper.ai/QZ6oi

2.Qwen3-ASR-1.7B: 차세대 음성 인식 시스템
Qwen3-ASR은 알리바바 클라우드의 통이첸원(Tongyi Qianwen) 팀에서 출시한 차세대 오픈 소스 엔드투엔드 자동 음성 인식(ASR) 모델 시리즈입니다. Qwen3-Omni 멀티모달 기반 모델과 자체 개발한 AuT 음성 인코더를 기반으로 하는 이 모델은 고정밀, 다국어, 장문 오디오, 그리고 스트리밍 및 비스트리밍 음성-텍스트 변환 기능을 통합적으로 구현하는 데 중점을 두고 있습니다. 원시 오디오 신호를 입력으로 받아 엔드투엔드 아키텍처를 통해 구조화된 텍스트 출력으로 직접 변환하며, 문자/단어 수준의 밀리초 단위 타임스탬프 정렬을 지원합니다. 회의록 작성, 지능형 자막 생성, 고객 서비스 음성 아카이빙, 방언 기반 음성 상호 작용 등 다양한 시나리오에 적합합니다.
온라인으로 실행:https://go.hyper.ai/zb0Vi

3.Qwen3-Coder-Next를 사용하여 vLLM+Open WebUI 배포
Qwen3-Coder-Next는 알리바바 클라우드의 통이첸원(Tongyi Qianwen)이 오픈소스로 공개한 경량 코드 생성 모델로, 모든 시나리오의 프로그래밍 지원 및 코드 생성 작업에 특화되어 있습니다. 이 모델의 핵심 장점은 "높은 성능, 낮은 진입 장벽, 간편한 배포"입니다. 최적화된 Qwen3 대규모 언어 모델 아키텍처를 기반으로, 코드 도메인에 특화된 사전 학습 데이터(80개 이상의 주요 프로그래밍 언어와 10억 개 이상의 코드 스니펫 포함)와 RLHF(인간 피드백 강화 학습) 코드 정렬 최적화 기술을 통합했습니다. HumanEval+, MBPP, MultiPL-E 등 세 가지 권위 있는 코드 벤치마크에서 오픈소스 모델 중 최고 수준의 성능을 달성했으며, CodeLlama-70B에 근접하는 성능을 보여줍니다. 알고리즘 작성, 비즈니스 코드 생성, 코드 주석 작성, 언어 간 코드 변환, 버그 수정 등 다양한 프로그래밍 시나리오에 적합합니다.
온라인으로 실행:https://go.hyper.ai/ukxPt
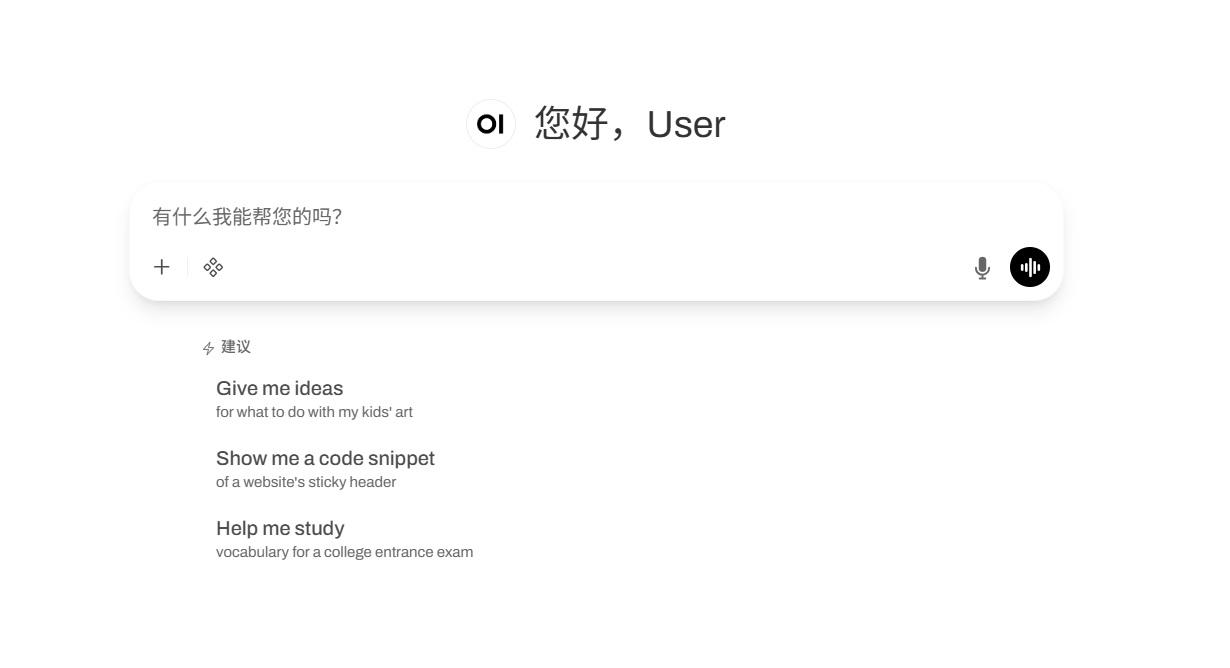
4. VibeVoice-ASR: 다기능 엔드투엔드 음성 인식 데모
VibeVoice-ASR은 마이크로소프트에서 오픈소스로 공개한 고성능 다기능 엔드투엔드 음성 인식(ASR) 모델로, 긴 오디오 콘텐츠에 대해 구조화되고 문맥을 고려한 음성-텍스트 변환 서비스를 제공하도록 설계되었습니다. 이 모델은 고급 통합 오디오 모델링 아키텍처를 사용하여 최대 60분 길이의 오디오 파일을 동시에 처리할 수 있습니다. 화자 정보(누구), 타임스탬프(언제), 텍스트 내용(무엇)을 포함하는 구조화된 출력을 생성하며, 사용자가 문맥 정보를 제공하여 인식 정확도를 향상시킬 수 있도록 지원합니다. 핵심 기술적 혁신은 효율적인 장음열 모델링 기능과 다국어 다중 작업 학습 메커니즘에 있으며, 이를 통해 긴 오디오 파일을 처리할 때 기존 ASR 모델이 겪었던 시간적 정렬 및 의미적 일관성 문제를 완벽하게 해결합니다.
온라인으로 실행:https://go.hyper.ai/8eMFX
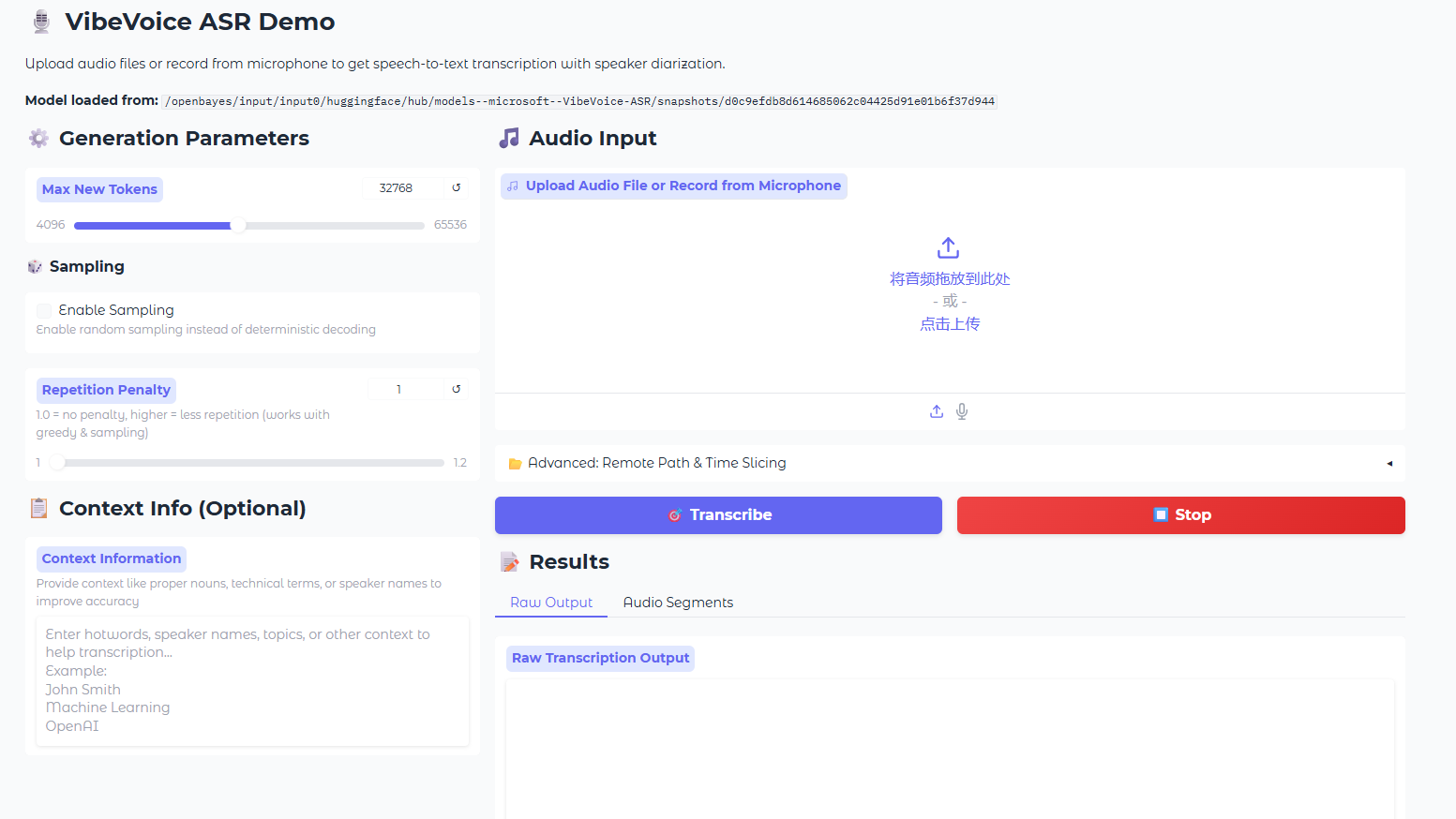
5. MOSS-TTS: 고음질 다중 장면 음성 생성 모델
MOSS-TTS 시리즈는 MOSI.AI와 OpenMOSS 팀이 개발한 오픈 소스 음성 생성 모델 시리즈입니다. 단일 오디오 세그먼트가 사람처럼 들리도록 각 단어의 정확한 발음, 다양한 콘텐츠에 따른 자연스러운 말하기 스타일 전환, 수십 분 동안의 안정적인 음성 유지, 대화, 역할극 및 실시간 상호작용 지원 등 다양한 요구 사항을 충족해야 할 때, 단일 TTS 모델로는 부족한 경우가 많습니다. 따라서 본 프로젝트는 음성 생성 워크플로우를 핵심 기본 모델인 MOSS-TTS, 다국어 대화 모델인 MOSS-TTSD, 음성 디자인 모델인 MOSS-VoiceGenerator, 효과음 생성 모델인 MOSS-SoundEffect, 그리고 실시간 상호작용 모델인 MOSS-TTS-Realtime 등 5개의 상용급 모델로 분리하여 독립적으로 또는 조합하여 사용할 수 있도록 했습니다. 이 시리즈는 20개 언어를 지원하며, 주로 고충실도 제로 샘플 음성 복제, 최대 1시간 분량의 안정적인 장문 텍스트 합성, 다국어 및 중국어-영어 혼합 생성, 복잡한 시나리오에서의 세밀한 길이 및 음소 수준 발음 제어와 같은 실제 응용 분야의 과제를 해결합니다.
온라인으로 실행:https://go.hyper.ai/AtKvk
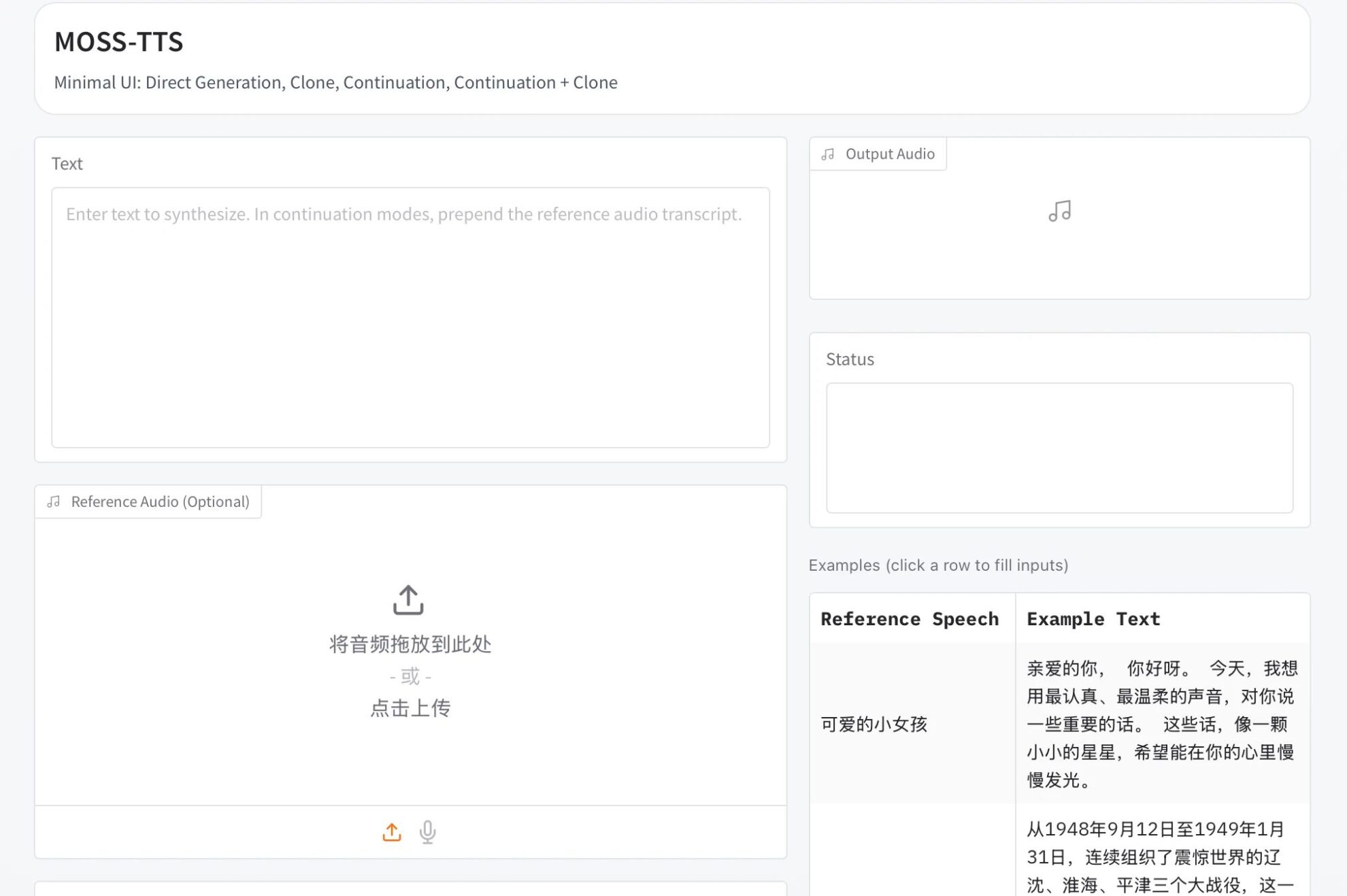
6.Z-Image: 알리바바가 개발한 60억 개의 파라미터를 가진 오픈소스 텍스트 기반 이미지 모델
Z-Image는 알리바바 클라우드 통이천원 팀에서 개발한 차세대 고효율 이미지 생성 모델입니다. Z-Image-Turbo 정제 버전을 출시하여 Artificial Analysis의 오픈소스 모델 순위에서 1위를 차지한 후, Z-Image 팀은 Z-Image Standard 버전을 공식 오픈소스로 공개했습니다. Z-Image 시리즈의 주요 커뮤니티 기반 모델인 Standard 버전은 생성 품질, 스타일 다양성, 2차 개발 지원 측면에서 뛰어난 완성도 높은 모델입니다. 커뮤니티 개발자들에게 강력하고 유연한 이미지 생성 기반을 제공하여 맞춤형 개발 및 세밀 조정에 더 많은 가능성을 열어주는 것을 목표로 합니다.
온라인으로 실행:https://go.hyper.ai/SsDMv
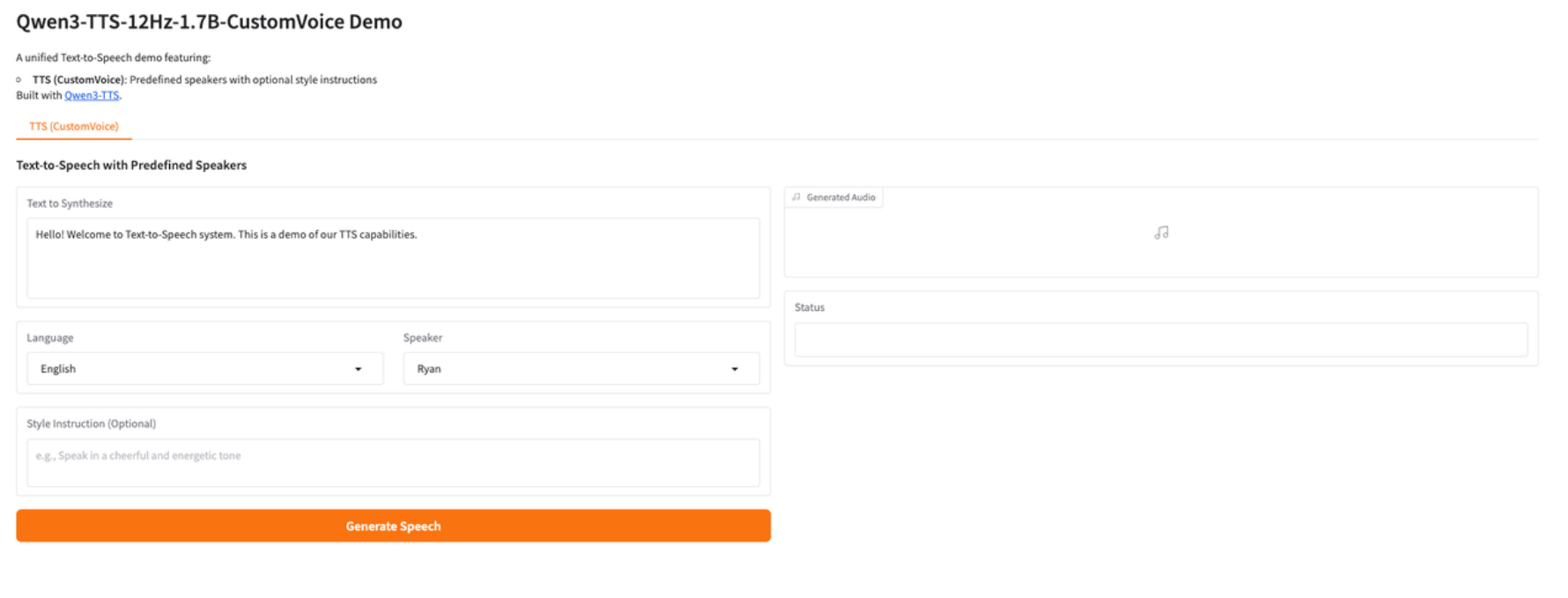
7. Qwen3-TTS: 고품질, 제어 가능한 다국어 음성 합성 데모
Qwen3-TTS-12Hz-1.7B-CustomVoice는 알리바바 통이 팀에서 출시한 차세대 고품질 텍스트 음성 변환(TTS) 모델입니다. 이 모델은 다국어 음성 합성, 다중 화자(커스텀 보이스) 제어, 텍스트 기반 스타일 및 감정 조정, 높은 자연스러움과 낮은 지연 시간의 음성 생성을 단일 통합 프레임워크 내에서 구현하는 데 중점을 두었습니다. 17억 개의 파라미터를 사용하는 12Hz 음향 모델링 프레임워크를 기반으로, 이 모델은 음성 명료도, 운율 일관성, 다국어 안정성에서 뛰어난 성능을 보여줍니다. 커스텀 보이스 메커니즘을 도입하여 추가 학습 없이 추론 단계에서 사전 설정된 화자를 직접 전환할 수 있으며, 자연어 스타일 지침과 결합하여 더욱 정교한 표현 제어를 구현합니다.
온라인으로 실행:https://go.hyper.ai/xWsQ6
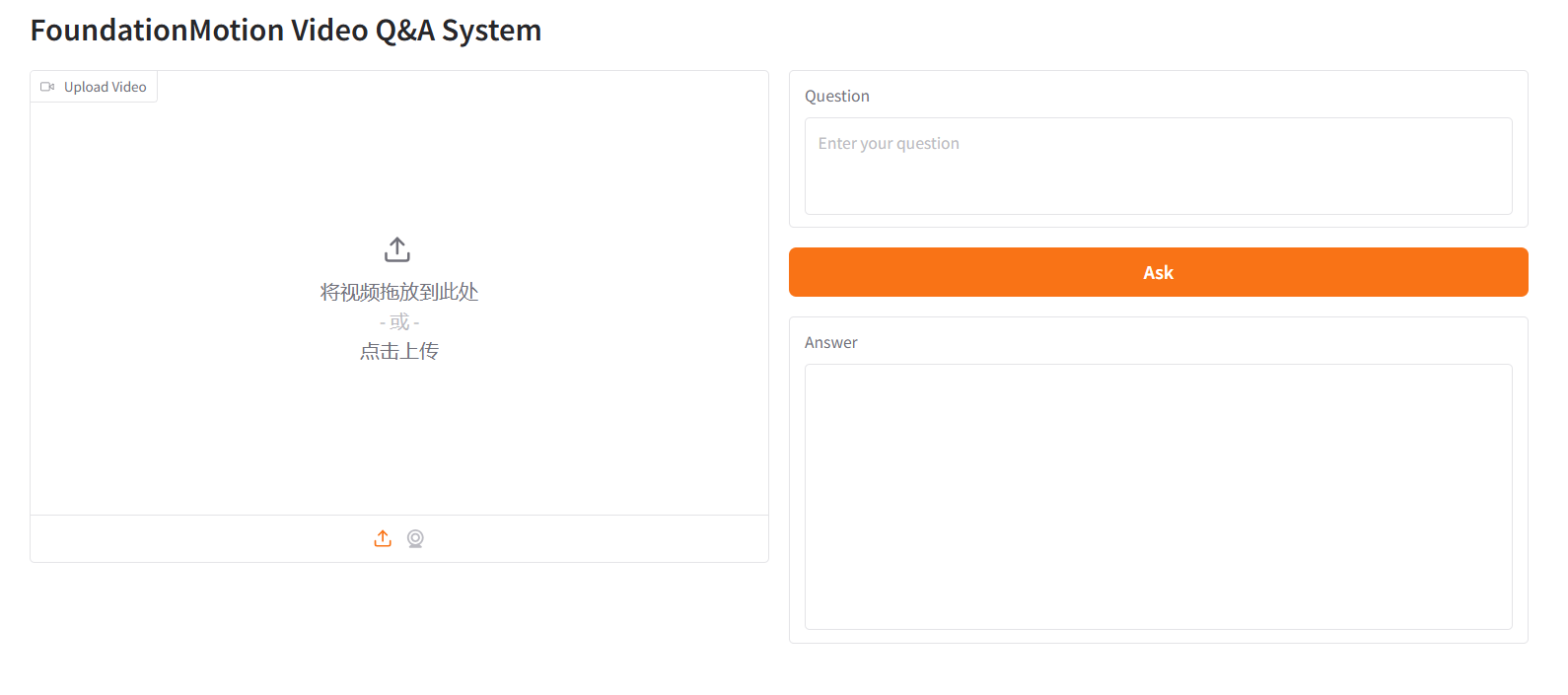
8. 파운데이션모션 비디오 Q&A 시스템
FoundationMotion은 NVIDIA와 MIT가 공동 개발한 Qwen2.5-VL 파인튜닝 기반의 비디오 이해 및 질의응답 시스템입니다. 비디오 속 공간적 움직임을 이해하고 추론하는 것을 목표로 하며, 시각 언어 사전 학습 기술을 접목하여 업로드된 비디오 콘텐츠를 지능적으로 분석하고 관련 질문에 답변할 수 있습니다.
온라인으로 실행:https://go.hyper.ai/JlGZk
커뮤니티 기사 해석
1. 기존 멀티모달 통합의 한계를 뛰어넘다! MIT는 셀 공유 정보와 셀별 정보를 명확하게 분리하는 APOLLO 프레임워크를 제안합니다.
단일 세포 기술의 지속적인 발전과 데이터 규모의 급속한 증가에 따라, 공유 정보와 각 모달리티별 정보를 명확하게 분리하면서 다중 모달 데이터를 효율적이고 자동으로 통합하는 것은 단일 세포 생물학이 직면한 핵심 과제가 되었습니다. 이러한 과제를 해결하기 위해 MIT와 취리히 연방 공과대학교(ETH Zurich)의 공동 연구팀은 APOLLO(Autoencoder with a Partially Overlapping Latent Space Learned through Latent Optimization)라는 범용 딥러닝 컴퓨팅 프레임워크를 제안했습니다. 이 프레임워크는 공유 정보와 각 모달리티별 정보를 명시적으로 모델링함으로써 세포 상태와 그 조절 논리를 보다 포괄적이고 정확하게 분석할 수 있는 실현 가능한 기술적 경로를 제시합니다.
전체 보고서 보기:https://go.hyper.ai/jaCKf
2. 온라인 튜토리얼 | 500만 시간 분량의 음성 데이터를 기반으로 Qwen3-TTS는 3초 만에 음성 복제 및 미세 조정을 구현합니다.
생성형 AI가 단순히 "텍스트 생성"에 그치지 않고 진정으로 "소리 생성"에 도달하게 되면, 음성은 단순한 정보 전달 채널에서 프로그래밍 가능하고 변형 가능한 표현 매체로 진화하게 됩니다. 이러한 기술 발전 과정에서 차세대 모델들은 기존 TTS(텍스트 음성 변환)의 한계를 뛰어넘어, 높은 정확도뿐 아니라 다국어 지원 및 세밀한 제어 기능을 강조하고 있습니다. 최근 Qwen 팀에서 오픈소스로 공개한 Qwen3-TTS는 듀얼 트랙 언어 모델(LM) 아키텍처를 기반으로 하여, 실시간으로 음성을 합성하는 동시에 출력 음성을 세밀하게 제어할 수 있습니다.
전체 보고서 보기:https://go.hyper.ai/eKr7T
3. MIT는 효모 DNA의 "언어"를 학습하는 Pichia-CLM 모델을 개발하여 외인성 단백질 생산량을 최대 3배까지 늘릴 가능성을 열었습니다.
현재 업계에서는 숙주 CUB(코돈 최적화 단위) 기반의 다양한 코돈 최적화 도구와 방법이 개발되었지만, 이러한 방법들은 여전히 높은 발현율을 보이는 재조합 단백질을 일관되게 생산하지 못하는 경우가 있습니다. 최근 인공지능, 특히 서열 모델링 기술의 발전과 함께 연구자들은 유전자 서열을 일종의 "언어"로 간주하고 자연어 처리와 유사한 방법을 통해 그 안에 내재된 규칙을 학습하려는 시도를 하고 있습니다. 이러한 배경에서 MIT 연구팀은 산업용 숙주인 피치아 파스토리스(Pichia pastoris)의 코돈 최적화를 위한 딥러닝 기반 언어 모델인 Pichia-CLM을 제안하여 재조합 단백질 수율을 향상시키고자 했습니다.
전체 보고서 보기:https://go.hyper.ai/a4H2G
인기 백과사전 기사
1. 시각 언어 모델(VLM)
2. 하이퍼네트워크
3. 제한된 관심
4. 인간 참여형(HITL)
5. 신경 복사장(NeRF)
다음은 "인공지능"을 이해하는 데 도움이 되는 수백 가지 AI 관련 용어입니다.
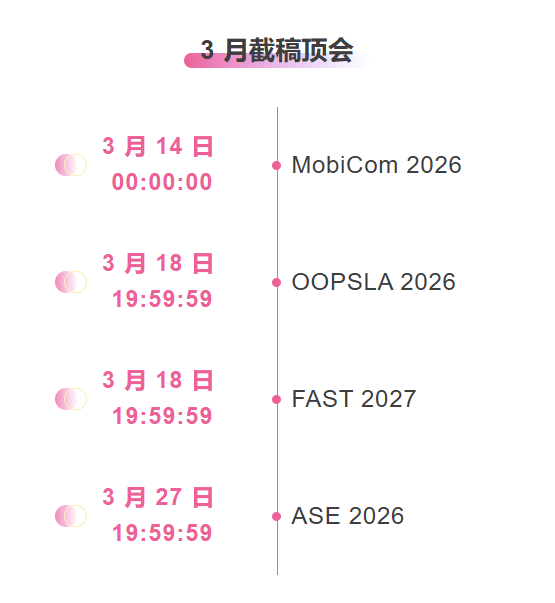
최고 AI 학술 컨퍼런스에 대한 원스톱 추적:https://go.hyper.ai/event
위에 적힌 내용은 이번 주 편집자 추천 기사의 전체 내용입니다. hyper.ai 공식 웹사이트에 포함시키고 싶은 리소스가 있다면, 메시지를 남기거나 기사를 제출해 알려주세요!
다음주에 뵙겠습니다!








