HyperAI
Command Palette
Search for a command to run...
Voxtral-Small-24B-2507 音声理解モデルデモ
1. チュートリアルの概要
Voxtralは、Mistral AIが2025年7月に発表した高度な音声モデルです。優れた音声転写機能と深い理解能力に基づき、音声を人間とコンピュータの自然なインタラクション手段として推進しています。Voxtralには24Bバージョンと3Bバージョンがあり、それぞれ実稼働環境とローカル展開に適しています。Voxtralは、複数の言語、長いテキストコンテキスト、組み込みの質問と回答機能、要約機能をサポートし、バックエンド関数の直接呼び出しも可能です。Voxtralのパフォーマンスは、複数のベンチマークにおいて既存のオープンソースモデルや独自APIを上回り、低コストで様々なシナリオで広く利用されていることから、音声インタラクションの普及に貢献しています。
主な機能:
- 長いテキストのコンテキスト処理: 最大 30 分の音声文字変換と 40 分の音声理解をサポートし、複雑な長文コンテンツを処理できます。
- 組み込みの Q&A と要約: 追加の ASR および言語モデルを必要とせずに、オーディオ コンテンツについて直接質問したり、構造化された要約を生成したりできます。
- 多言語サポート: 自動言語検出、複数の一般的な言語 (英語、スペイン語、フランス語、ポルトガル語、ヒンディー語、ドイツ語など) のサポートにより、世界中のユーザーのニーズに応えます。
- 音声トリガー関数呼び出し: 中間解析手順を必要とせずに、ユーザーの音声意図に基づいてバックエンド関数、ワークフロー、または API 呼び出しを直接トリガーします。
- テキスト理解機能: Mistral Small 3.1 のテキスト理解機能は保持され、テキストの入力と処理をサポートします。
- 最適化された転写パフォーマンス: コスト効率が高く、大規模なアプリケーションに適した、高度に最適化された転写エンドポイントを提供します。
このチュートリアルのコンピューティングリソースにはデュアルカードRTX A6000を使用し、デプロイするモデルはVoxtral-Small-24B-2507です。テスト用に、音声文字起こしと音声理解の2つの機能が用意されています。
付録: 3B Voxtral モデルのデモのワンクリック展開
2. エフェクト表示
音声文字起こし
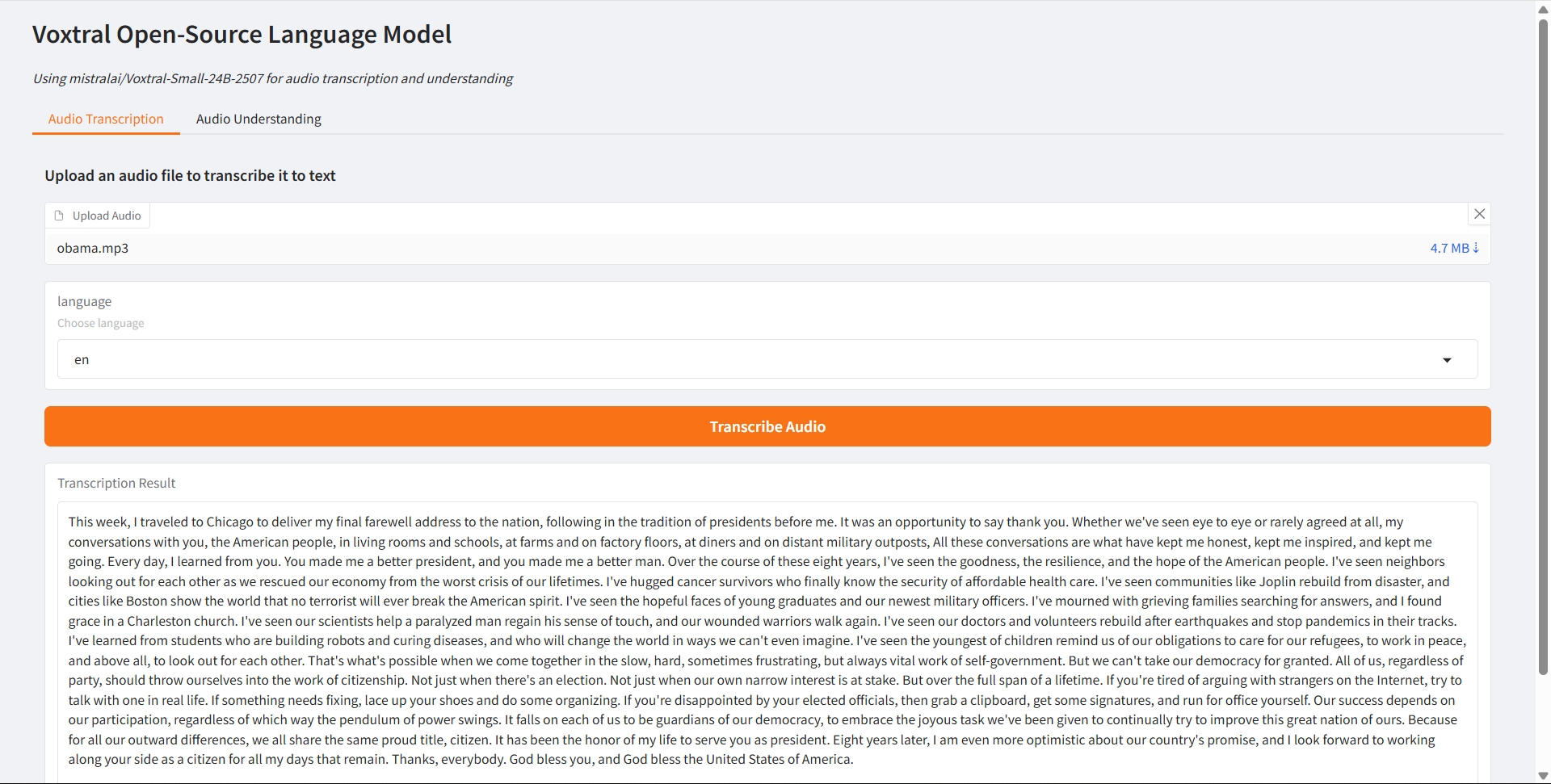
音声理解
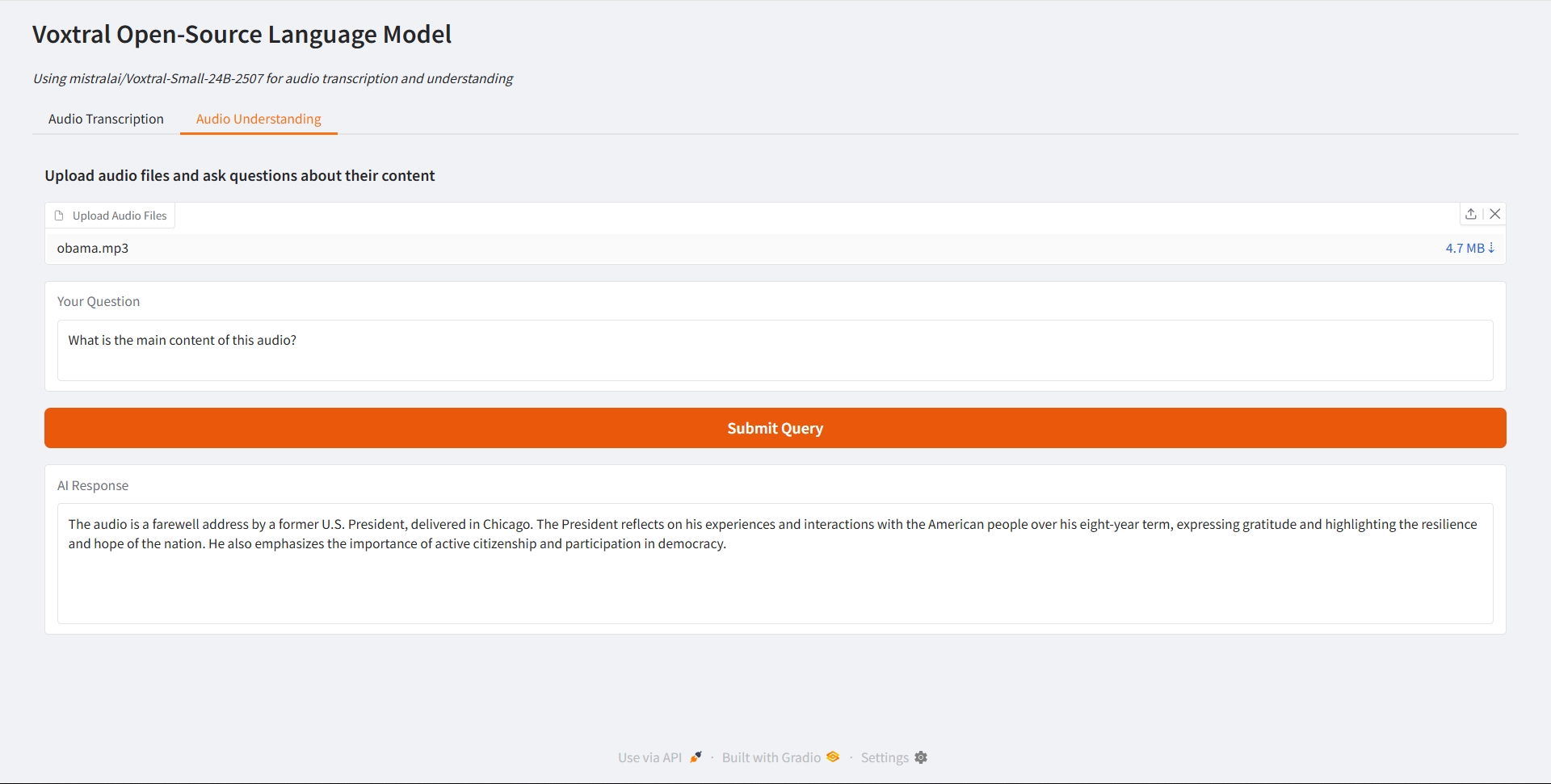
3. 操作手順
1. コンテナを起動します
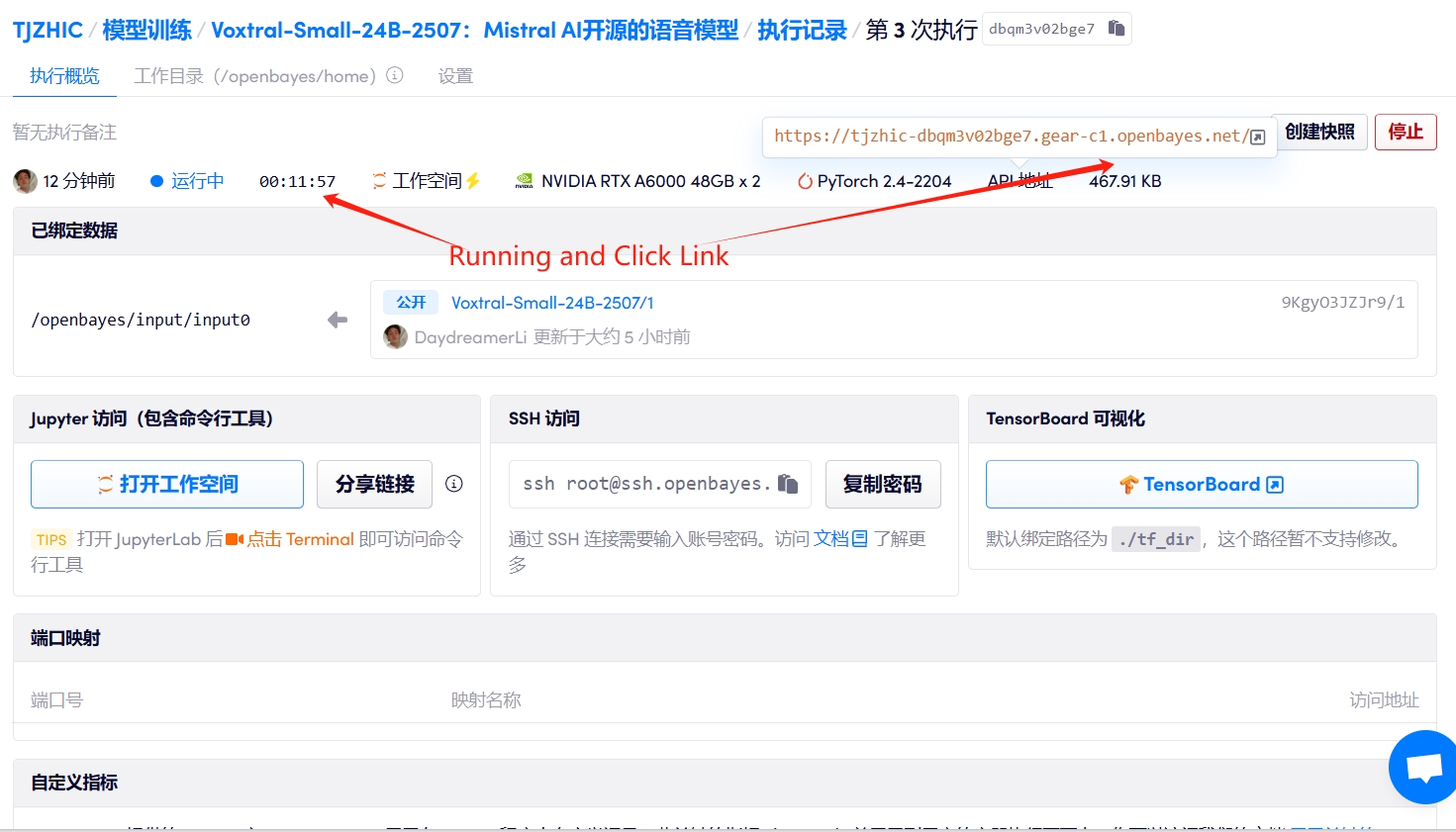
2. 使用手順
「Bad Gateway」と表示される場合は、モデルが初期化中であることを意味します。モデルのサイズが大きいため、5~10分ほど待ってからページを更新してください。
1. 音声文字起こし
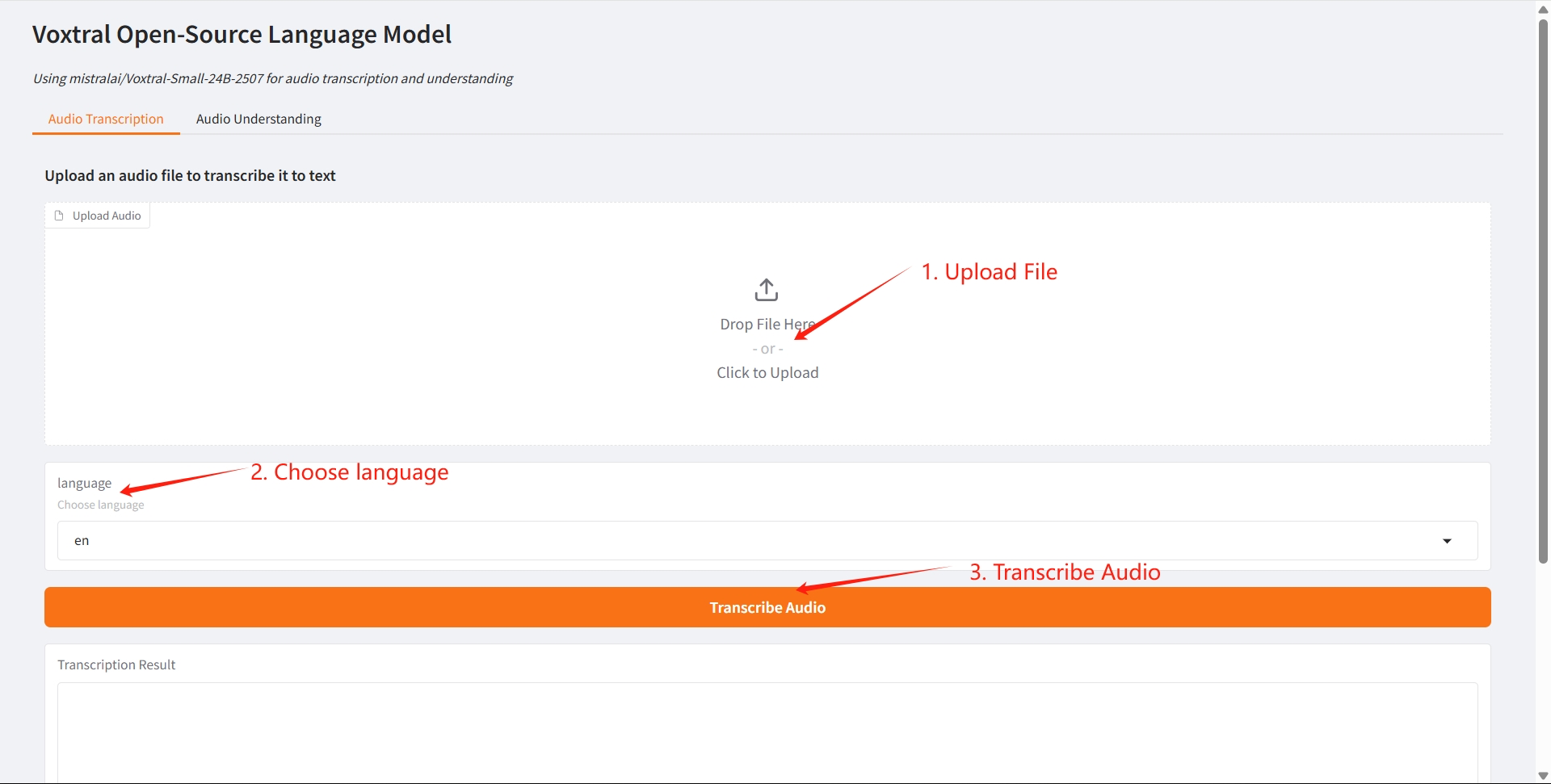
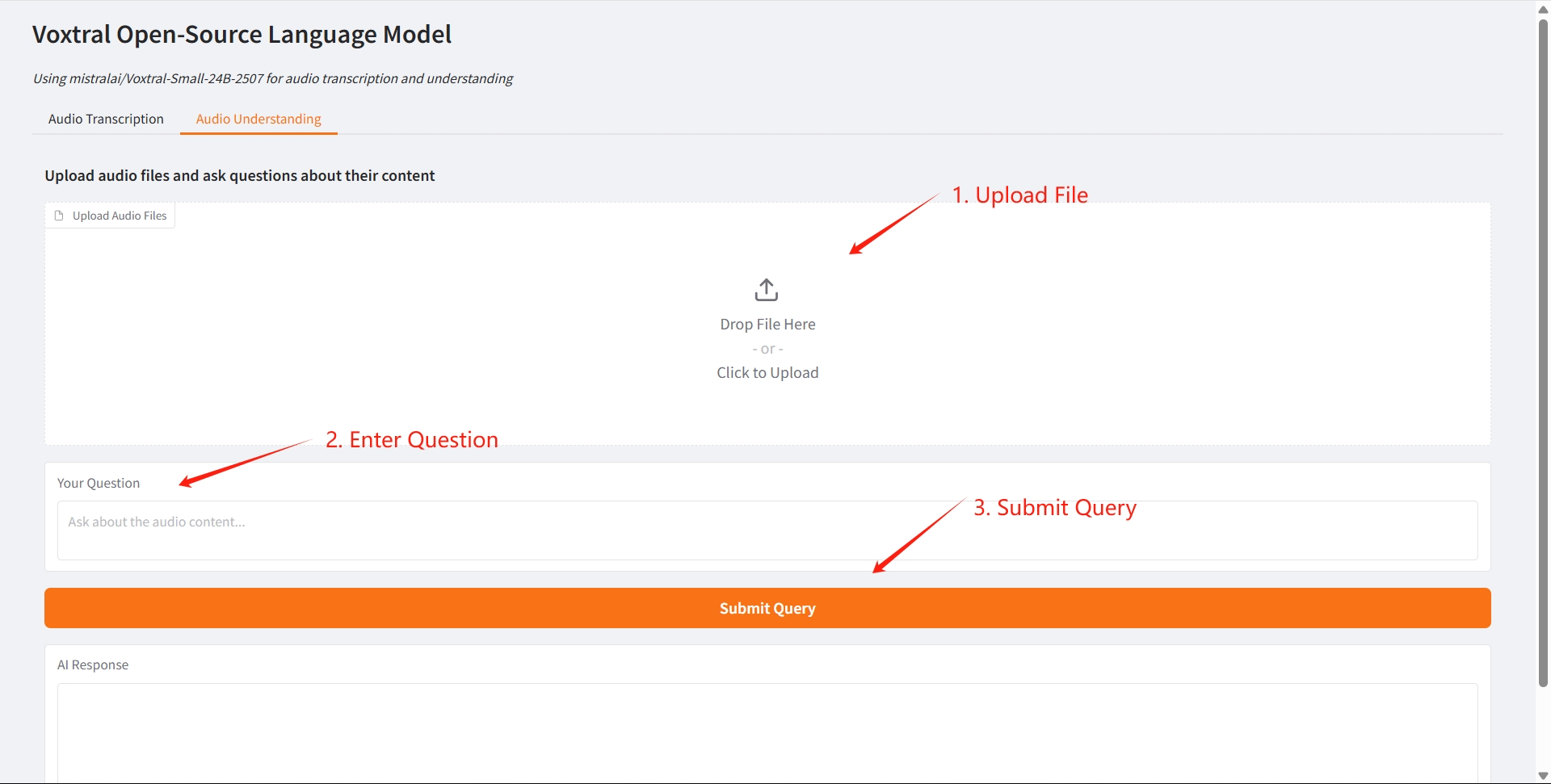
2. 音声理解
4. 議論
🖌️ 高品質のプロジェクトを見つけたら、メッセージを残してバックグラウンドで推奨してください。さらに、チュートリアル交換グループも設立しました。お友達はコードをスキャンして [SD チュートリアル] に参加し、さまざまな技術的な問題について話し合ったり、アプリケーションの効果を共有したりできます。

このノートブックはコミュニティユーザーによって提供されたものであり、教育および情報提供のみを目的としています。コンテンツに著作権侵害が含まれる場合は、[email protected]までご連絡ください。速やかに確認し、削除いたします。