HyperAI
Command Palette
Search for a command to run...
Chandra: 高精度ドキュメントOCR
1. チュートリアルの概要

Chandraは、2025年10月にDatalab-toチームによって開発された高精度ドキュメントOCR(光学式文字認識)システムで、ドキュメントレイアウト認識とテキスト抽出に重点を置いています。ChandraはPDFファイルや画像ファイルを直接処理し、構造化テキスト、Markdown、HTML出力を生成するだけでなく、OCR結果を容易に検証できる視覚的なレイアウト図も提供します。
コア機能:
- 高精度OCRドキュメント、表、複数列のレイアウトに最適化されており、複雑なページ レイアウトをサポートします。
- レイアウト認識テキスト ブロック、表、画像領域をマークして、視覚的なレイアウト図を生成します。
- マルチフォーマット出力Markdown、HTML、プレーンテキストのダウンロードをサポートします。
- シンプルな導入Streamlit インターフェースに基づいて、ブラウザ内での素早い操作が可能になります。
- 軽量モデル: vLLM への依存関係を追加することなく、Transformers を使用してモデルを直接ロードできます。
このチュートリアルでは、Streamlit を使用して、"RTX_5090" コンピューティング リソースを備えた Chandra OCR コア モデルを展開し、高速なドキュメント推論とレイアウトの視覚化を実現します。
2. エフェクト表示
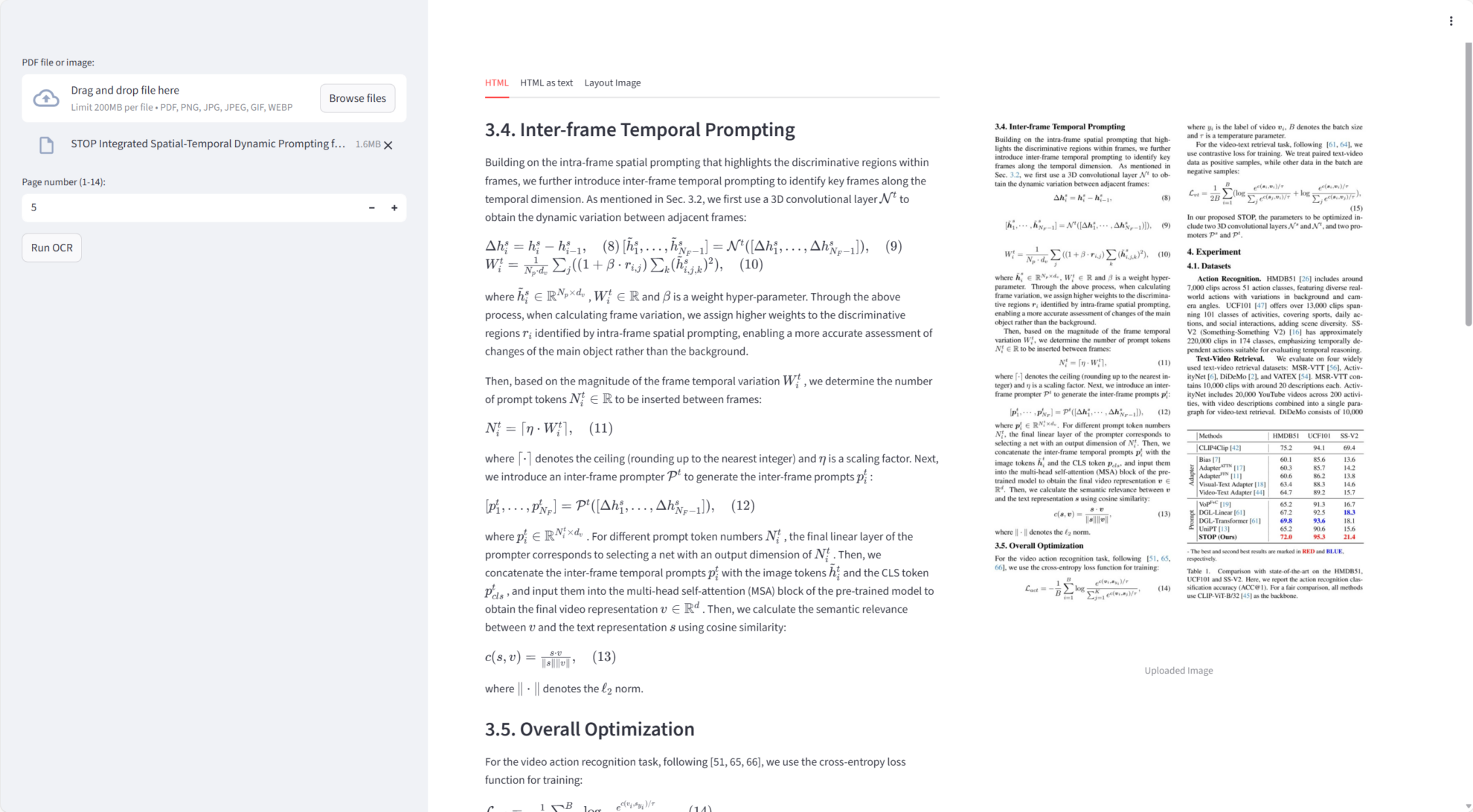
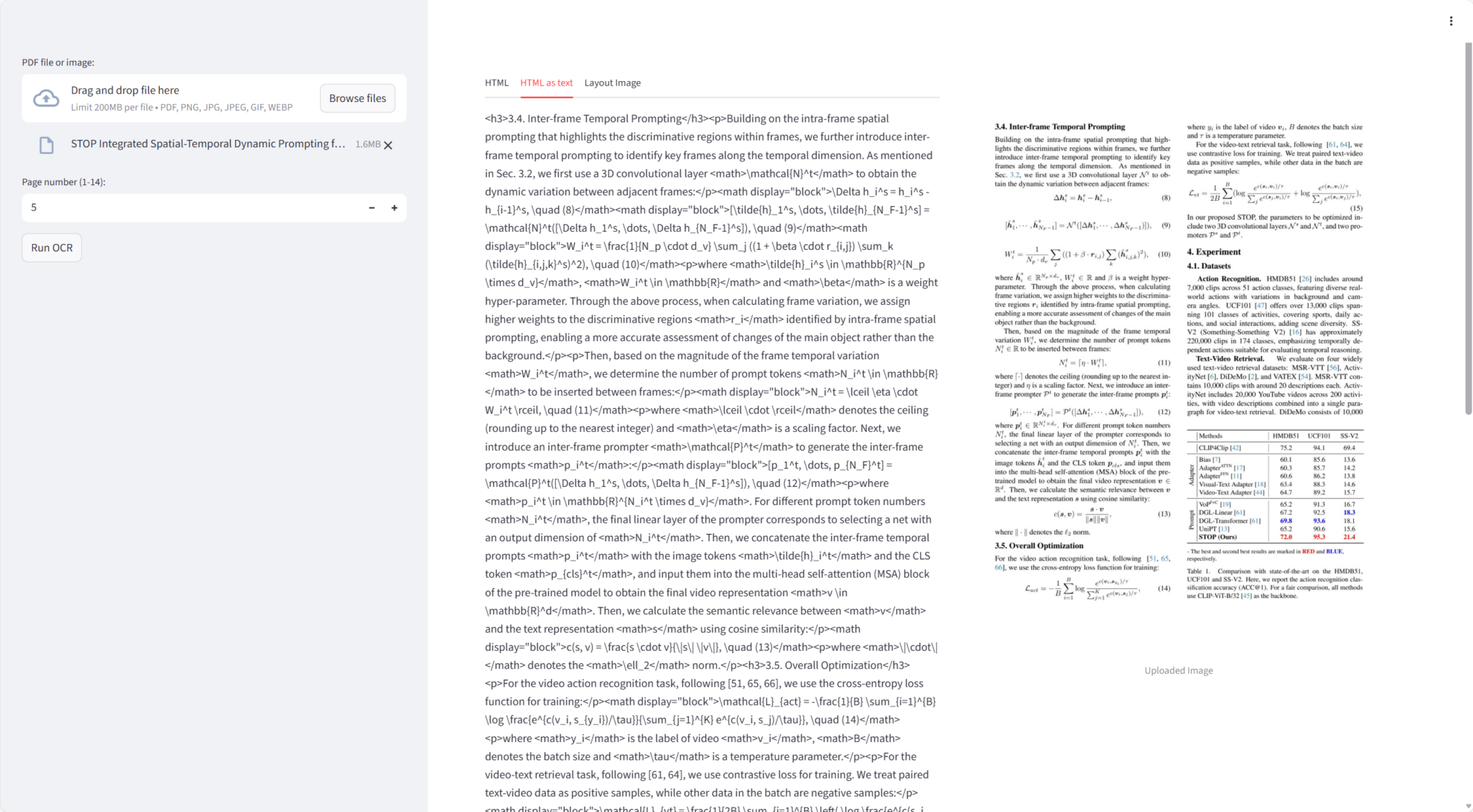

Chandra はコアミッションにおいて非常に優れたパフォーマンスを発揮しました。
- 単一ページ文書OCRPDF または画像から高精度のテキストと Markdown を生成します。
- レイアウト検出テキストブロック、表、画像などの領域を正確に識別し、レイアウトの視覚化をサポートします。
- 複数ページのドキュメントのサポート範囲外エラーを防ぐためにページ番号が 1 から始まるページ単位で PDF ファイルを処理できます。
- MarkdownとHTML出力OCR の結果を Markdown または HTML に自動的に埋め込み、ダウンロードをサポートします。
- 視覚的なレイアウト図OCR の精度を簡単に検証できるように、注釈付きテキスト領域の PIL イメージを生成します。
3. 操作手順
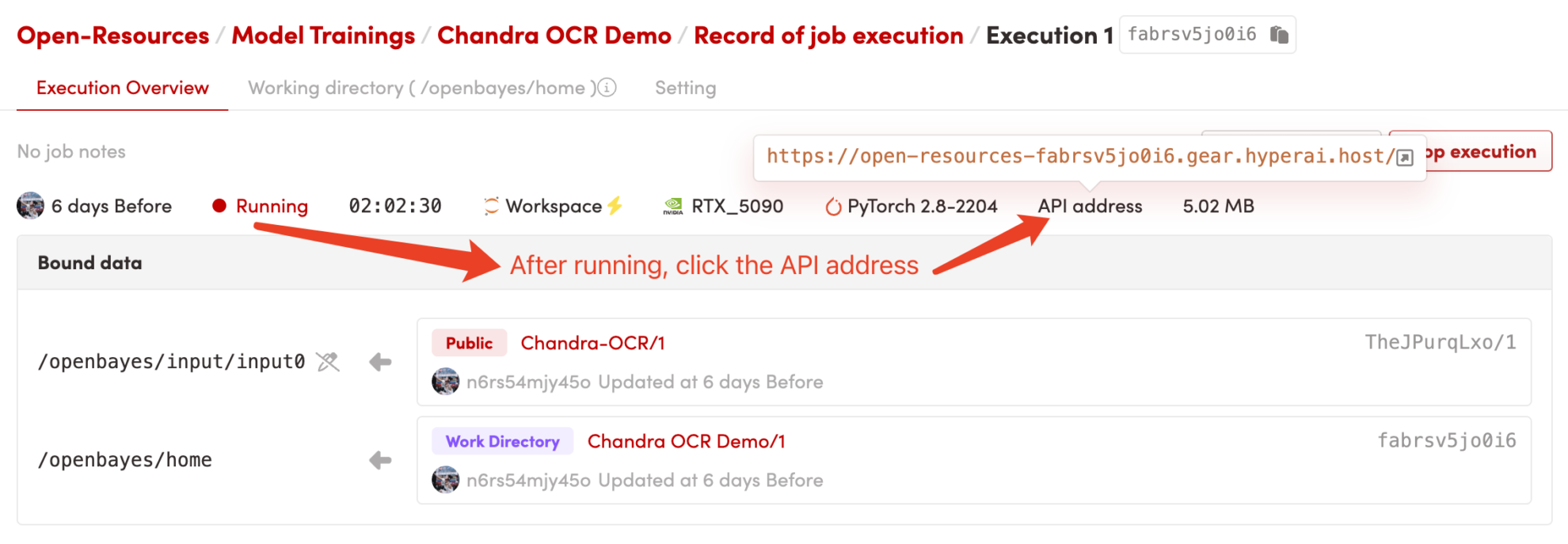
1. コンテナを起動するか、ローカルで実行します。
コンテナを起動したら、API アドレスをクリックして Web インターフェースにアクセスします。
2. ユーザーガイド
「Bad Gateway」と表示される場合は、モデルが初期化中であることを意味します。1~2分ほどお待ちいただき、ページを更新してください。
ヒントページに「load_model() を実行中」と表示された場合、モデルが初期化中であることを意味します。1~2分ほどお待ちいただいてからページを更新してください。


このノートブックはコミュニティユーザーによって提供されたものであり、教育および情報提供のみを目的としています。コンテンツに著作権侵害が含まれる場合は、[email protected]までご連絡ください。速やかに確認し、削除いたします。
Notebook の概要
レベル
入門
トピック
HyperAI Newsletters
最新情報を購読する
北京時間 毎週月曜日の午前9時 に、その週の最新情報をメールでお届けします
メール配信サービスは MailChimp によって提供されています