Command Palette
Search for a command to run...
SoulX-Podcast: 複数の方言に対応したポッドキャスト品質の長文音声生成。
1. チュートリアルの概要

SoulX-Podcast は、ポッドキャスト スタイルのマルチターン、マルチスピーカーの会話音声生成用に設計されたモデルであり、従来のモノローグ TTS タスクでも優れたパフォーマンスを発揮します。
多ターン対話音声生成における高い自然さの要件を満たすため、SoulX-Podcastは一連の二次言語制御を統合し、北京語、英語、そして四川語、河南語、広東語を含む複数の中国語方言をサポートすることで、ポッドキャスト形式の音声生成をよりパーソナライズしたものにしています。関連する技術詳細は論文をご覧ください。 SoulX-Podcast: 複数話者、複数方言による長編ポッドキャスト音声生成。
このチュートリアルでは、デフォルトのリソースとして単一の RTX 5090 グラフィック カードを使用します。
2. プロジェクト例
次のスクリーンショットは、OpenBayes プラットフォーム上で実行されている SoulX-Podcast WebUI の実際のインターフェースを示しており、プロセス全体をすぐに理解するのに役立ちます。
方言デモンストレーションの例
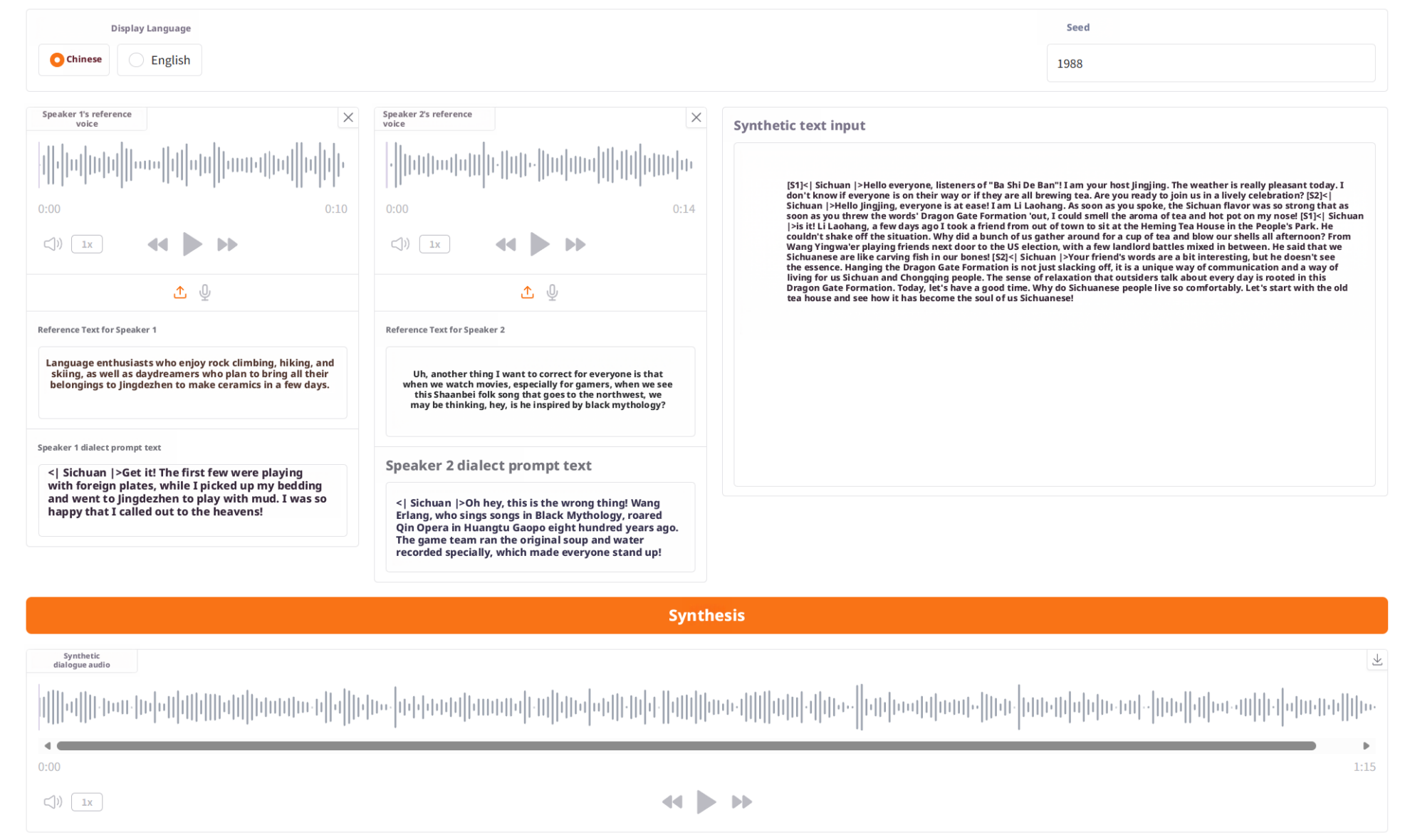
3. 操作手順
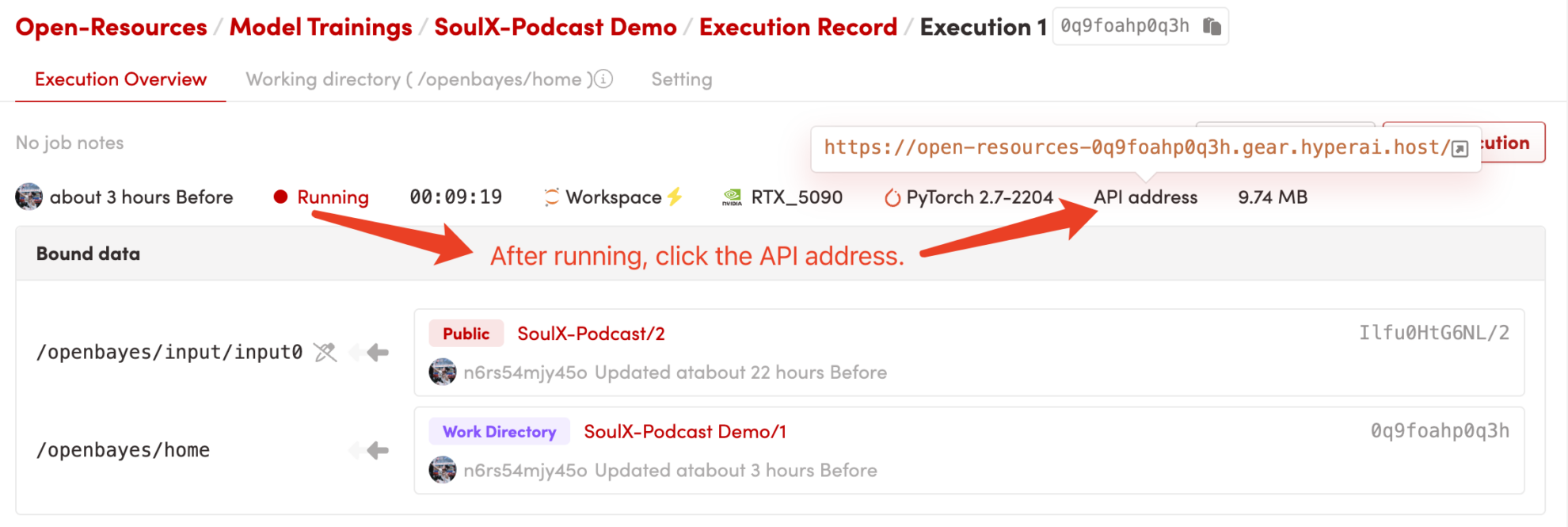
1. コンテナを起動した後、API アドレスをクリックして Web インターフェイスに入ります
2. 使用手順
WebUI に入ると、次のことが可能になります。
- 2人のスピーカーの参照音声をアップロードする
- 参照テキストを入力してください(方言のヒントはオプションです)
- ポッドキャストの完全な会話スクリプトを入力してください
- 「生成」ボタンをクリックします
- 最終的に生成されたポッドキャストのオーディオを表示および再生します。
操作例のスクリーンショットは次のとおりです。
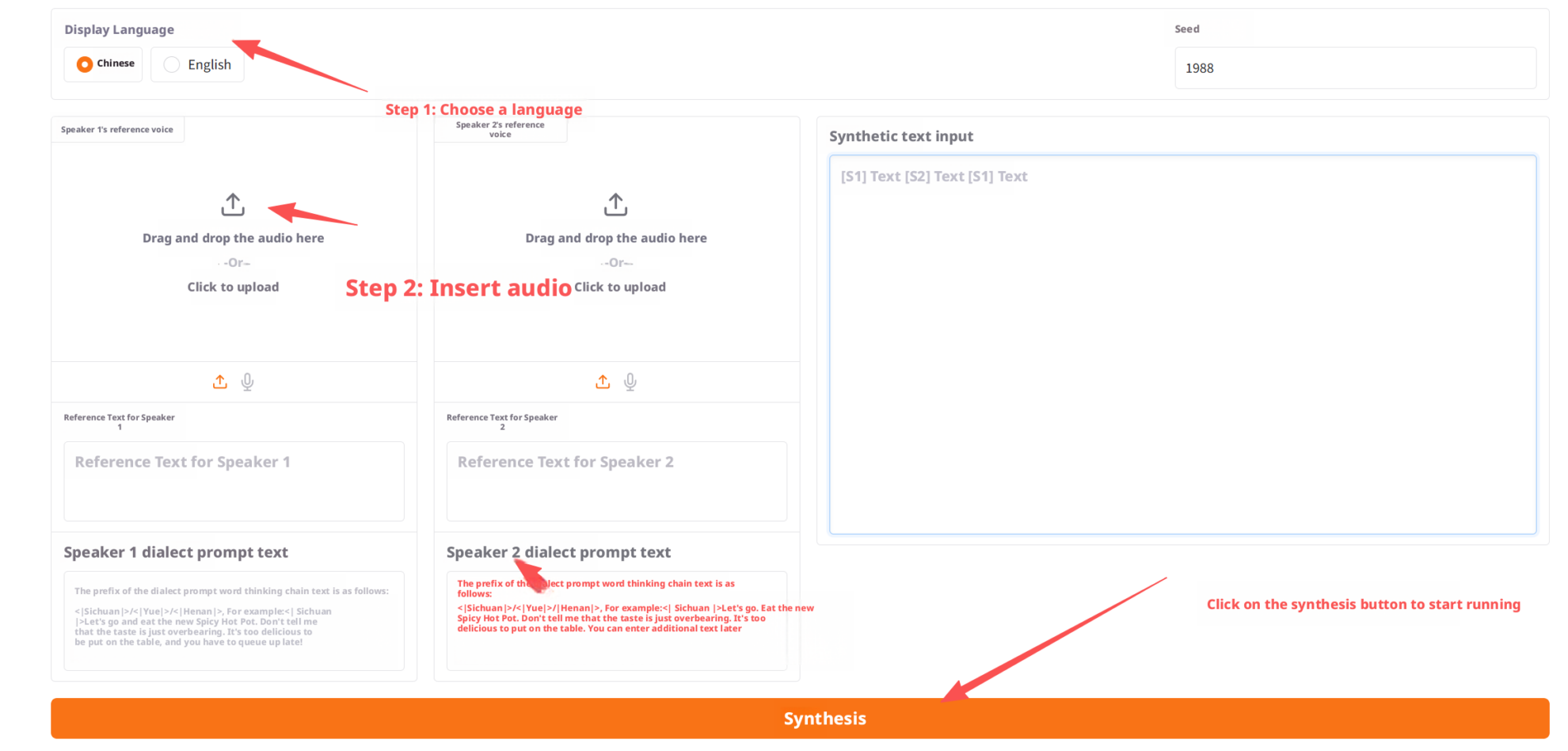
3. 方言プロンプトテキストを使用する手順
モデルに追加の方言の例文を提供することで、生成される音声の方言の自然さが大幅に向上します。
このプロセスは 4 つの簡単なステップで構成されており、簡単に使用できます。
ステップ1: 基本的なプロンプト入力を完了する
S1 と S2 の情報をそれぞれアップロードまたは入力します。
- 参考音声(プロンプトオーディオ)
- プロンプト テキスト ステップは、方言の強化を有効にする前に、話者の音色、トーン、役割の特性を決定するために使用されます。
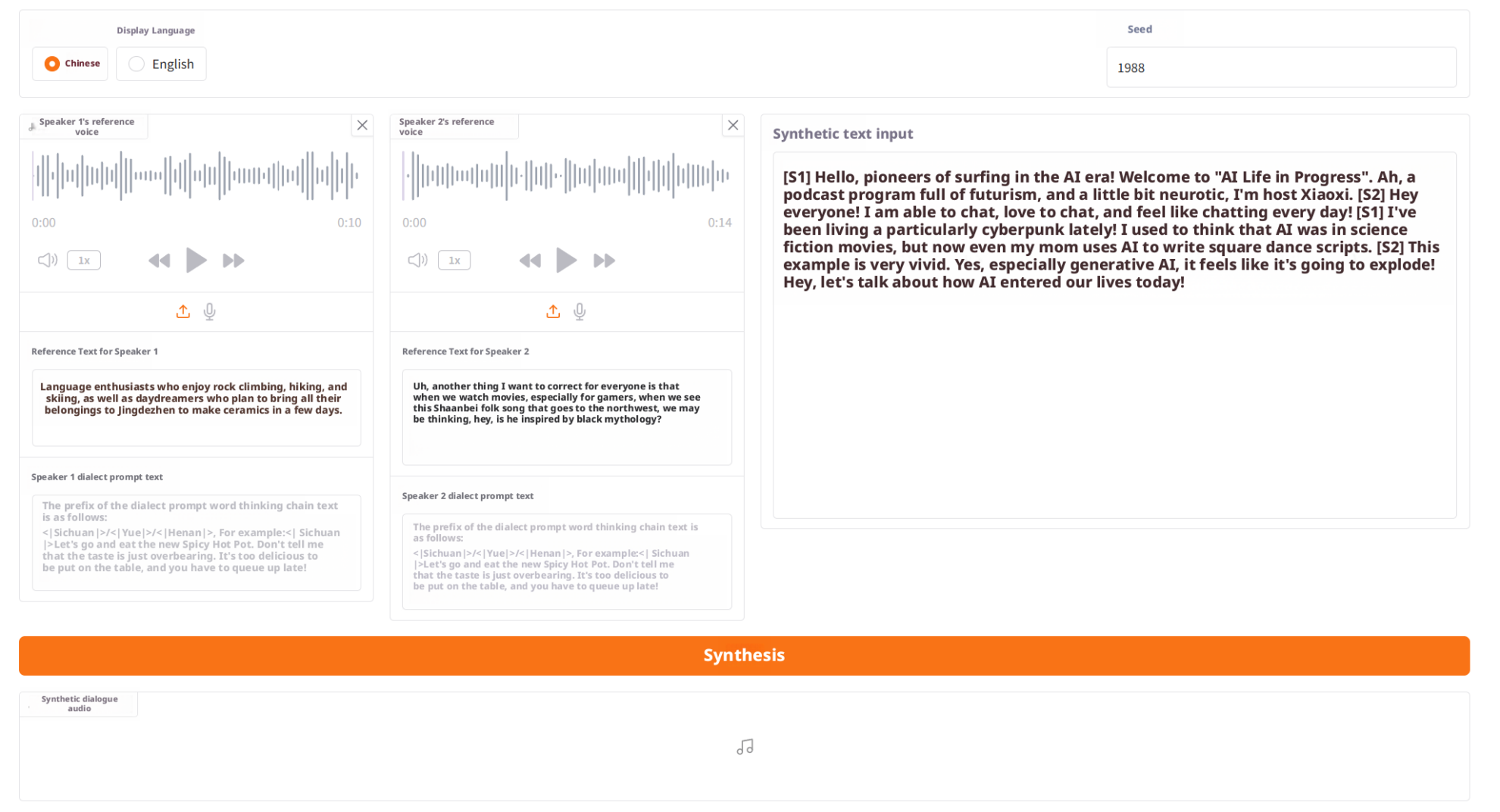
ステップ2: 方言を選択
方言プロンプト テキスト セレクターを展開し、拡張する方言の種類を選択します。
選択すると、システムはその方言の典型的な例文を自動的に読み込みます。

ステップ3: 方言の例を選択する
S1 と S2 それぞれに例文を 1 つ選択してください。
例文をクリックすると、対応する方言のプロンプトテキストが入力ボックスに自動的に入力されます。これらの例は方言風のプロンプトとして機能し、生成される音声をよりリアルで自然なものにします。
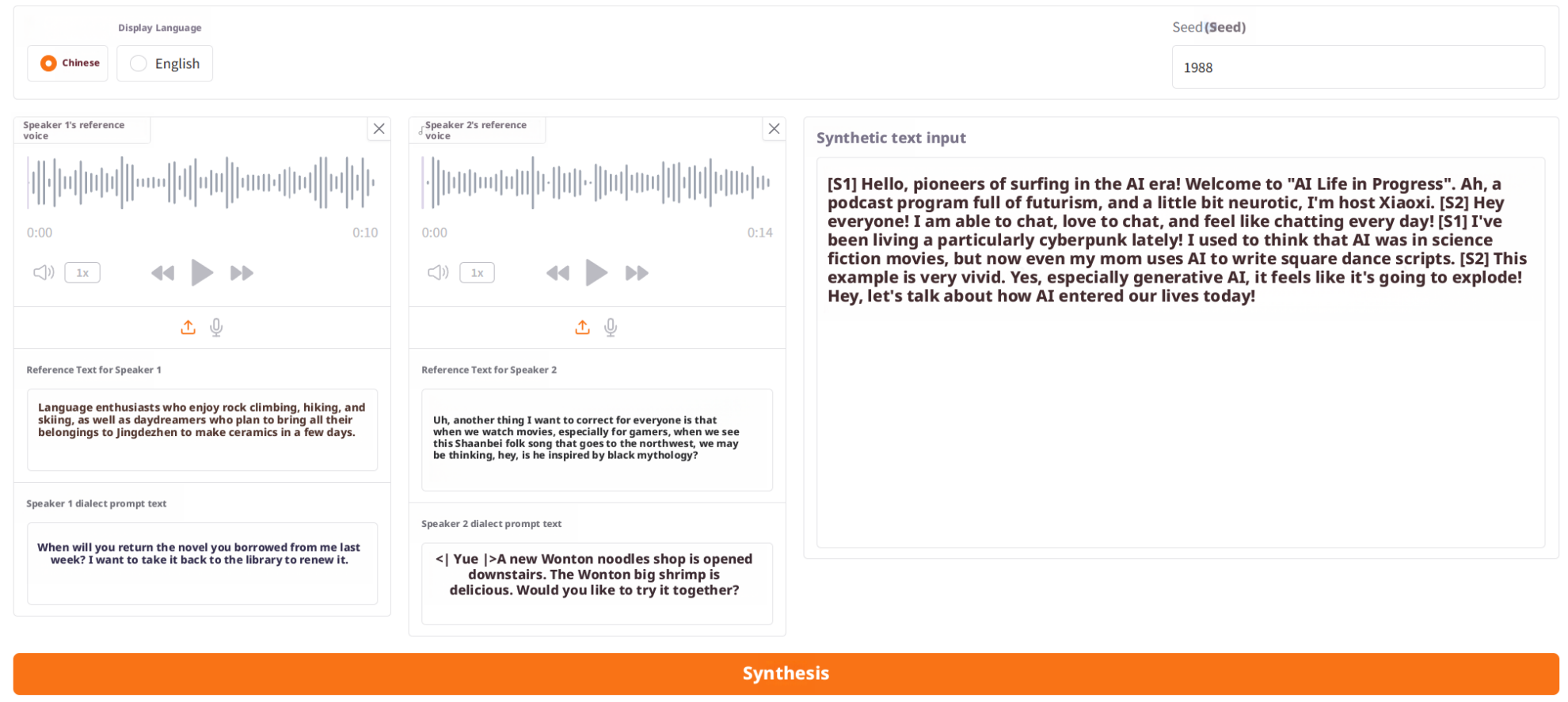
ステップ4: 合成テキストを入力して生成する
4. 議論
🖌️ 高品質のプロジェクトを見つけたら、メッセージを残してバックグラウンドで推奨してください。さらに、チュートリアル交換グループも設立しました。お友達はコードをスキャンして [SD チュートリアル] に参加し、さまざまな技術的な問題について話し合ったり、アプリケーションの効果を共有したりできます。

プロジェクトサポート
@misc{SoulXPodcast, title = {SoulX-Podcast: Towards Realistic Long-form Podcasts with Dialectal and Paralinguistic Diversity}, author = {Hanke Xie and Haopeng Lin and Wenxiao Cao and Dake Guo and Wenjie Tian and Jun Wu and Hanlin Wen and Ruixuan Shang and Hongmei Liu and Zhiqi Jiang and Yuepeng Jiang and Wenxi Chen and Ruiqi Yan and Jiale Qian and Yichao Yan and Shunshun Yin and Ming Tao and Xie Chen and Lei Xie and Xinsheng Wang}, year = {2025}, archivePrefix={arXiv}, url = {https://arxiv.org/abs/2510.23541}}