HyperAI
Command Palette
Search for a command to run...
GLM-ASR-Nanoインテリジェント音声認識
1. チュートリアルの概要

GLM-ASR-Nano-2512は、ZhipuAIが2024年12月にリリースしたオープンソースの音声認識モデルで、パラメータスケールは15億(1.5B)です。複雑な現実世界のシナリオに対応するために特別に設計されており、フットプリントが小さいにもかかわらず、複数のベンチマークテストでOpenAI Whisper V3を上回る性能を発揮します。このモデルは標準的な中国語と英語をサポートし、方言認識やささやき声/低音のシナリオにおいて優れた堅牢性を示しています。エッジフレンドリーで高性能なモデルとして、高度なトレーニング戦略を採用し、極めて低音量の音声の詳細を正確に捉え、方言や複雑な音響環境における従来のASRモデルのギャップを埋めます。例えば、騒がしい会議の録音やプライバシーを保護したささやき声の会話において、GLM-ASR-Nanoは非常に正確な文字起こし結果を提供します。
このチュートリアルでは、Grado + Transformers を使用して、次のコンピューティング リソースを採用し、GLM-ASR-Nano-2512 をデモとしてデプロイします。 シングルRTX 5090 。
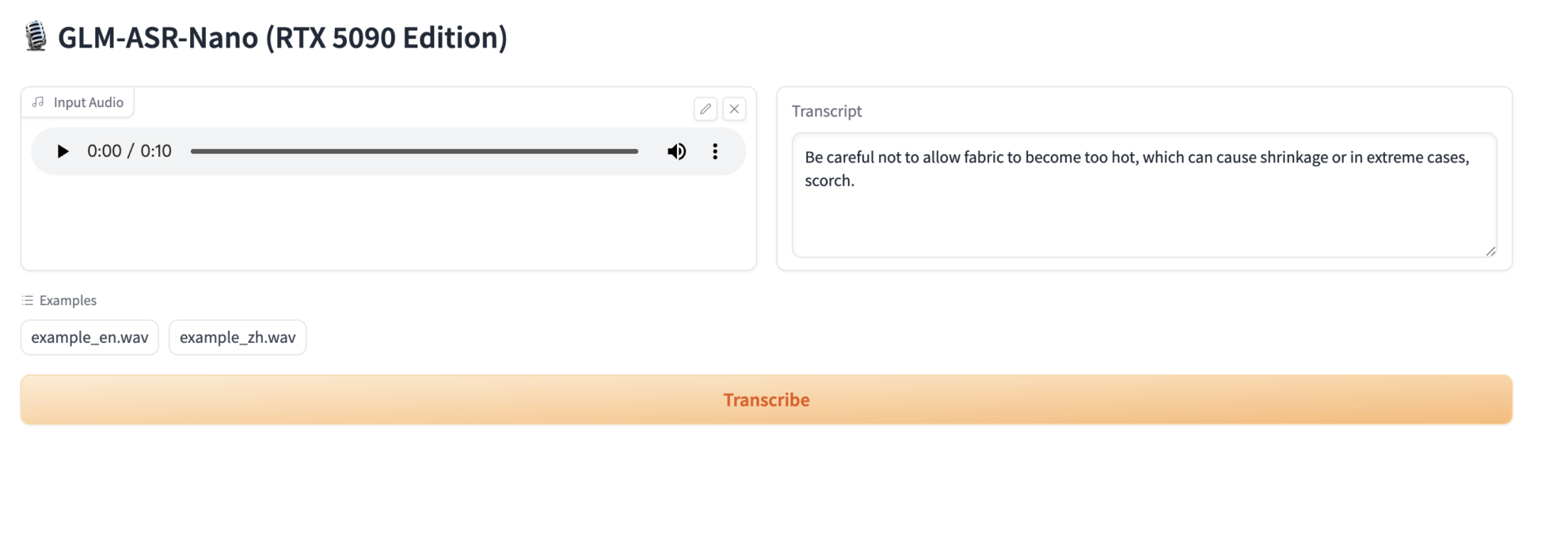
2. プロジェクト例
3. 操作手順
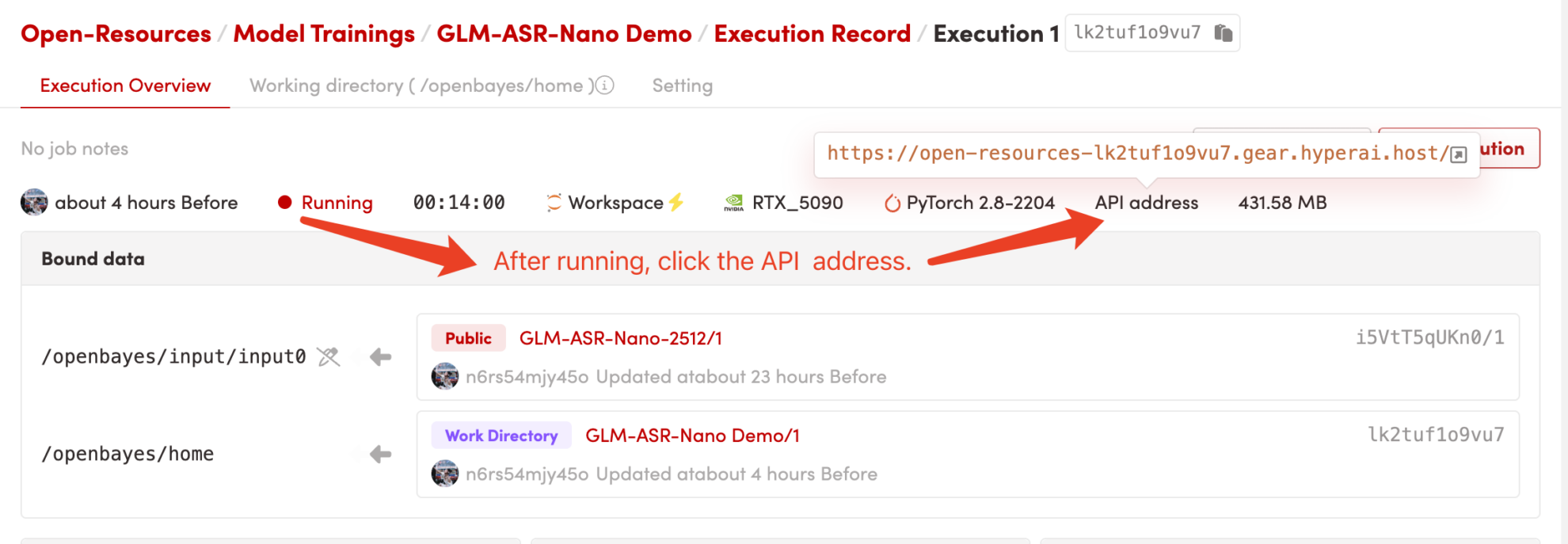
1. コンテナを起動した後、API アドレスをクリックして Web インターフェイスに入ります
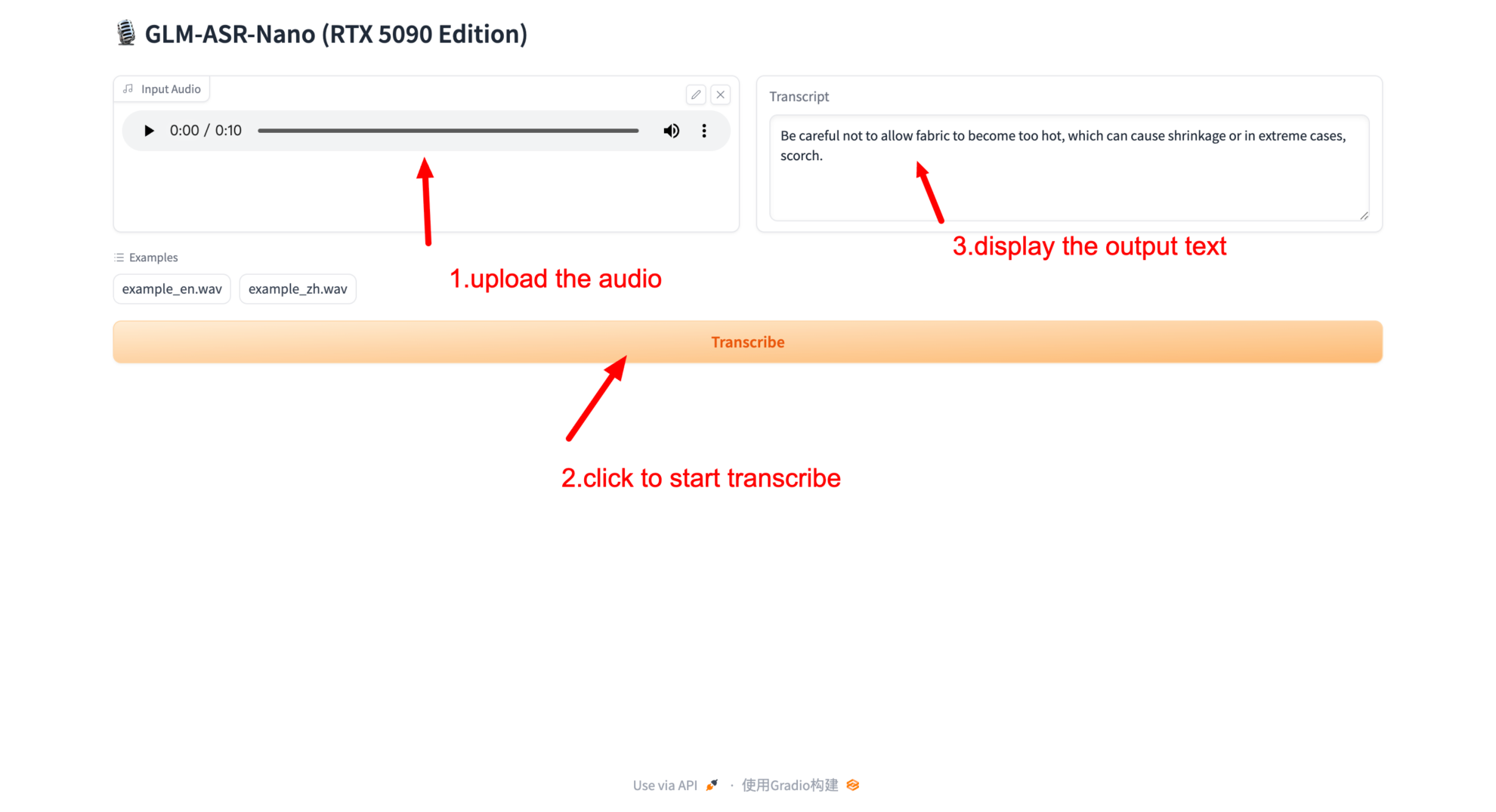
2. Webページにアクセスすると、認識用の音声または録音をアップロードできます。
表示されている場合 悪いゲートウェイ これはモデルの読み込み中を意味します。2~3分ほどお待ちいただいてからページを更新してください。
Safari ブラウザを使用する場合、オーディオは直接再生されない場合があり、再生する前にダウンロードする必要があります。
引用情報
@misc{glm-asr-nano-2512,
title={GLM-ASR-Nano: A Robust and Compact Speech Recognition Model},
author={ZhipuAI},
year={2024},
publisher={Hugging Face},
url={[https://huggingface.co/zai-org/GLM-ASR-Nano-2512](https://huggingface.co/zai-org/GLM-ASR-Nano-2512)}
}このノートブックはコミュニティユーザーによって提供されたものであり、教育および情報提供のみを目的としています。コンテンツに著作権侵害が含まれる場合は、[email protected]までご連絡ください。速やかに確認し、削除いたします。