HyperAI
Command Palette
Search for a command to run...
Long-VITA: 数百万のトークンを使ったマルチモーダル理解デモ
1. チュートリアルの概要

Long-VITAは、テンセントYouTuラボ、南京大学、厦門大学が2025年2月に発表した、長コンテキスト・マルチモーダル大規模モデルの研究成果です。このモデルは、短いコンテキストでは最高の精度を維持しながら、コンテキスト長を100万トークンまで拡張し、テキストや画像などのマルチモーダル入力を効率的に処理できます。関連論文のタイトルは「…」です。Long-VITA: ショートコンテキストの精度をリードする100万トークンまでの大規模マルチモーダルモデルのスケーリング”。
このチュートリアルでは、単一の RTX 4090 グラフィック カードを使用し、Long-VITA-16K_HF モデルを展開します。
2. 効果例
テキスト会話
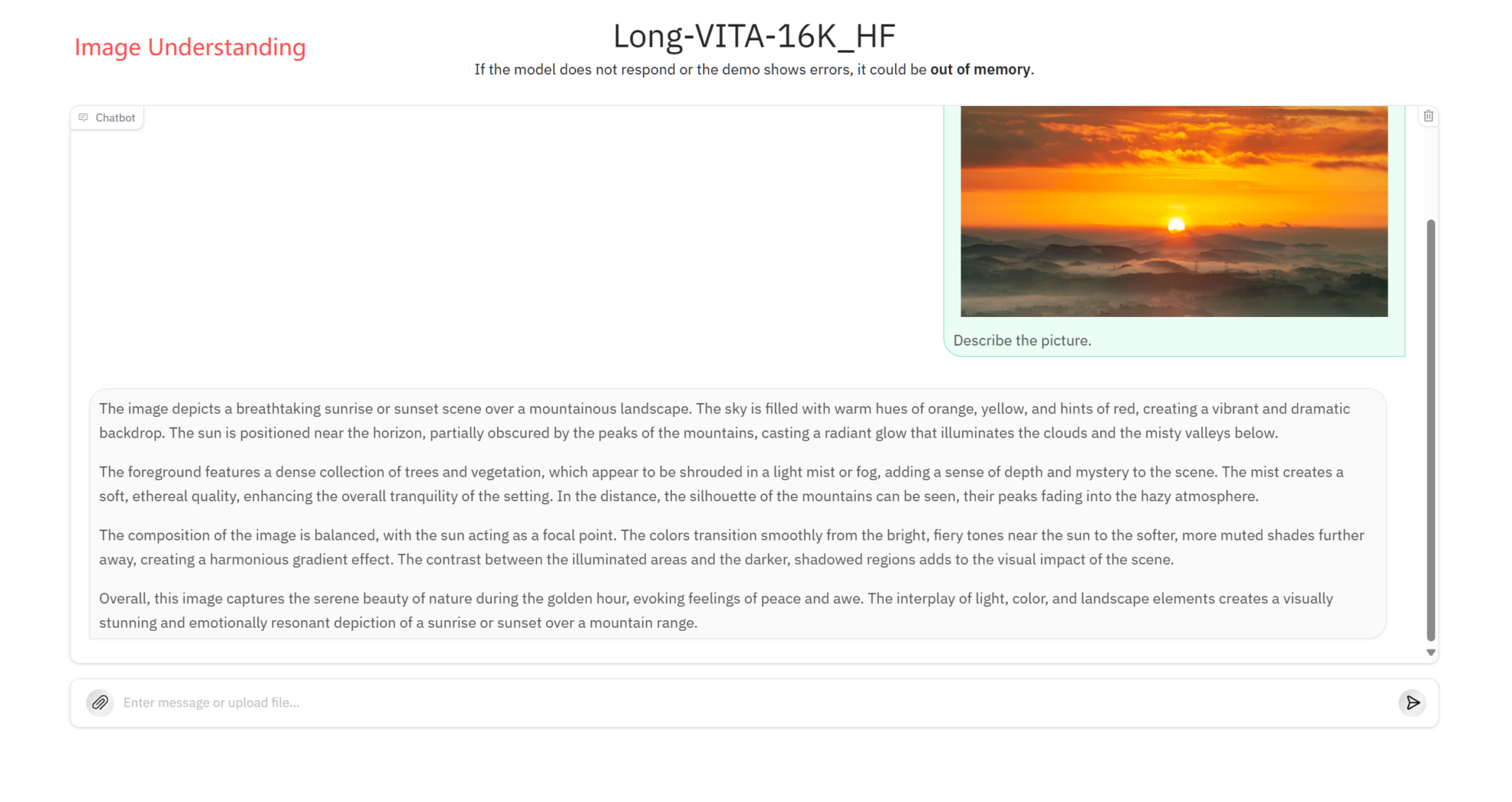
画像理解
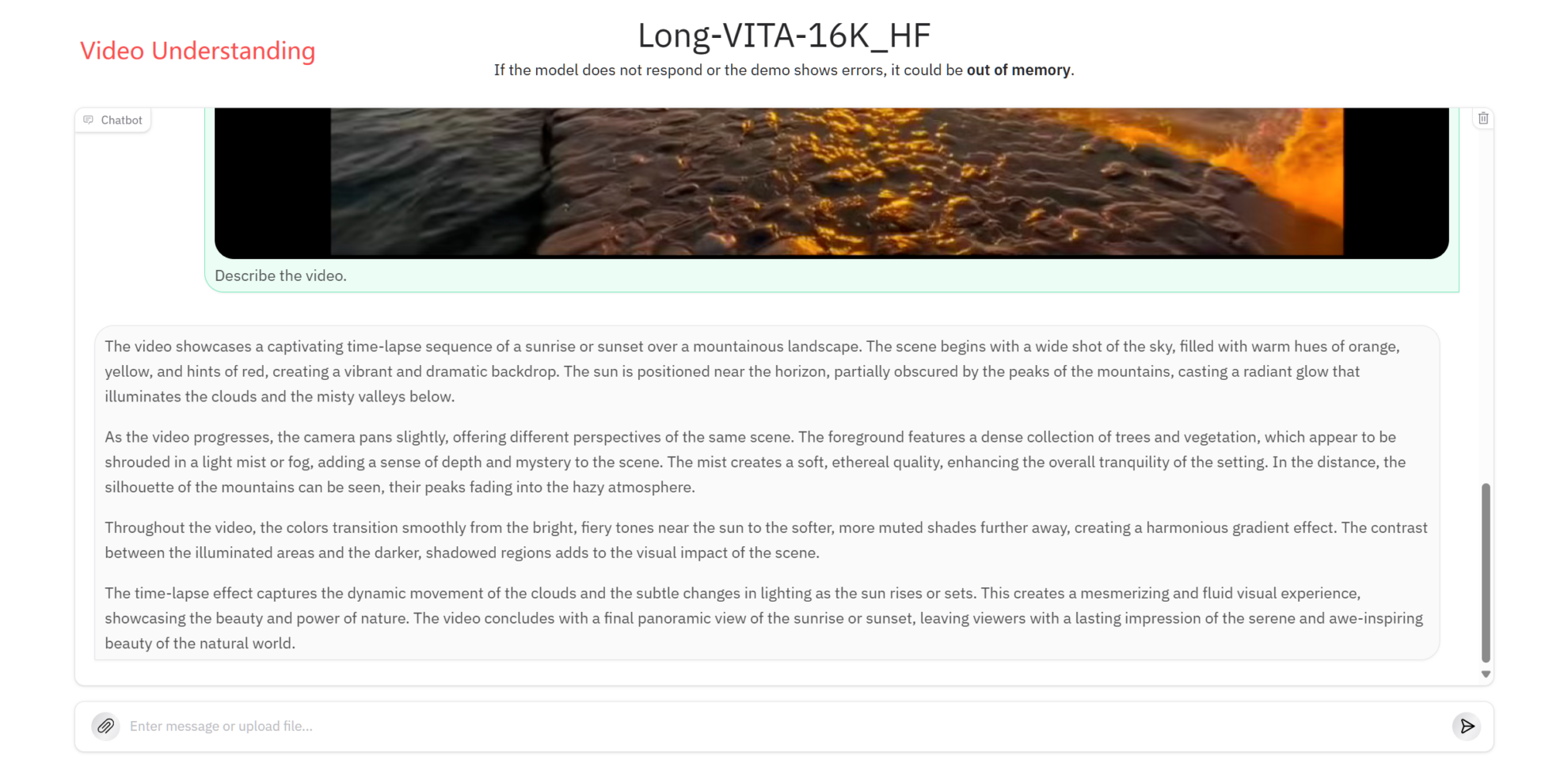
ビデオの理解
3. 操作手順
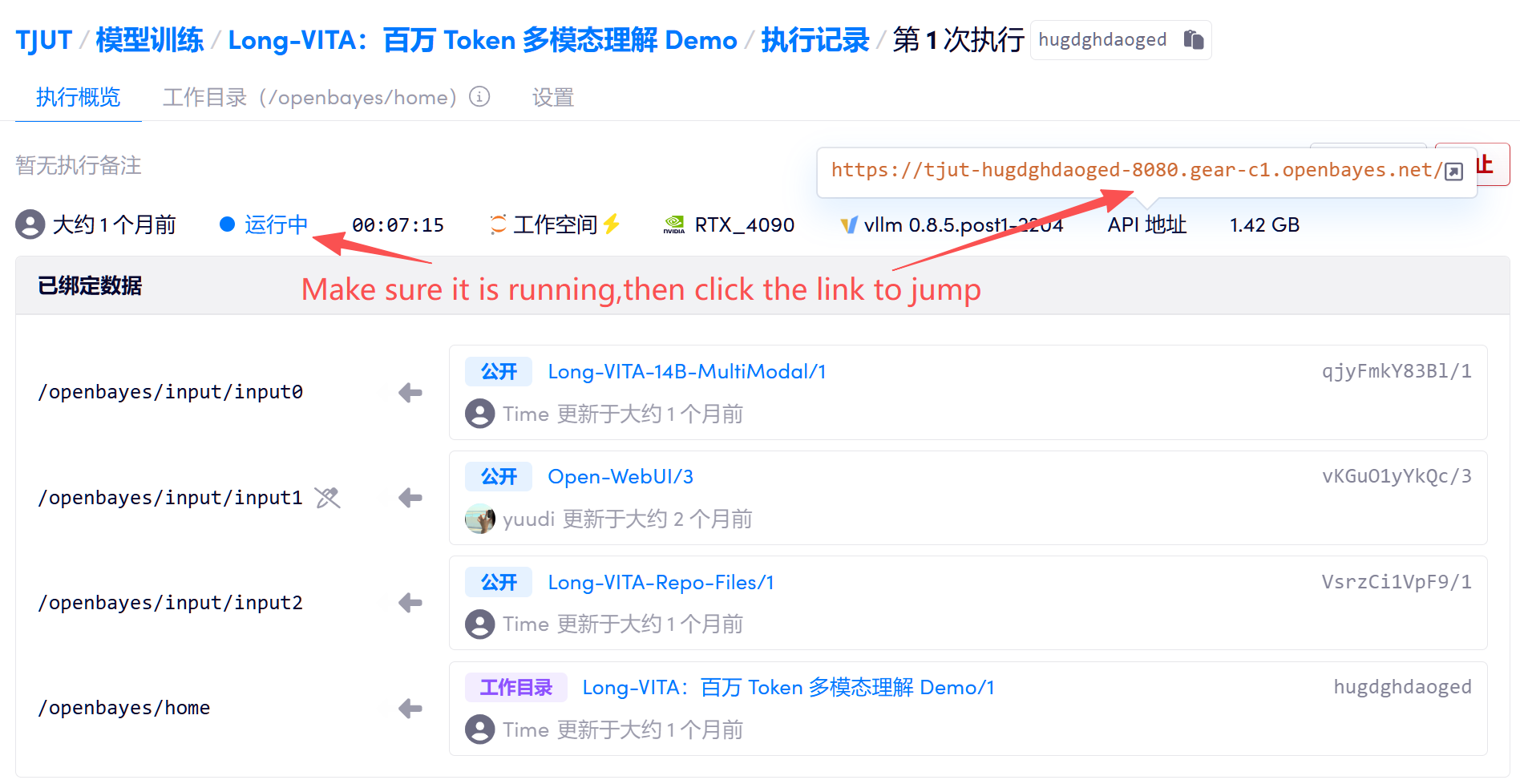
1. コンテナを起動した後、APIアドレスをクリックしてGradioインタラクティブインターフェースに入ります。
2. ウェブページに入ると、モデルを使用できます
「Bad Gateway」と表示される場合、モデルが初期化中であることを意味します。モデルが大きいため、2〜3分ほど待ってページを更新してください。
予防
- 長いコンテキスト入力の場合、十分なビデオ メモリを確保してください。非常に大きなテキストはバッチで読み込むことをお勧めします。
- 推論の遅延を減らすために、画像入力の辺の長さは 2048 ピクセル以下にすることをお勧めします。
- 推論が失敗した場合は、入力形式を確認するか、入力長を短くして再試行してください。
引用情報
このプロジェクトの引用情報は次のとおりです。
@misc{shen2025longvitascalinglargemultimodal,
title={Long-VITA: Scaling Large Multi-modal Models to 1 Million Tokens with Leading Short-Context Accuracy},
author={Yunhang Shen and Chaoyou Fu and Shaoqi Dong and Xiong Wang and Yi-Fan Zhang and Peixian Chen and Mengdan Zhang and Haoyu Cao and Ke Li and Xiawu Zheng and Yan Zhang and Yiyi Zhou and Ran He and Caifeng Shan and Rongrong Ji and Xing Sun},
year={2025},
eprint={2502.05177},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2502.05177},
}このノートブックはコミュニティユーザーによって提供されたものであり、教育および情報提供のみを目的としています。コンテンツに著作権侵害が含まれる場合は、[email protected]までご連絡ください。速やかに確認し、削除いたします。