Command Palette
Search for a command to run...
Depth-Anything-3: あらゆる視点から視覚空間を復元する
1. チュートリアルの概要

Depth-Anything-3 (DA3)は、ByteDance-Seedチームが2025年11月にリリースした画期的なビジュアルジオメトリモデルです。関連論文は次のとおりです。 深度何でも3:あらゆる視点から視覚空間を回復する 。
このモデルは、「ミニマリストモデリング」というコンセプトによって視覚幾何学タスクに革命をもたらします。バックボーンネットワークとして、単一の一般的なTransformer(例えば、バニラDINOエンコーダ)のみを使用し、複雑なマルチタスク学習を「深度光線表現」に置き換えることで、あらゆる視覚入力(既知および未知のカメラポーズの両方)から空間的に一貫性のある幾何学的構造を予測することを可能にします。その性能は、DA2(単眼深度推定)やVGGT(多視点深度/姿勢推定)といった従来のモデルを大幅に上回ります。すべてのモデルは、公開されている学術データセットを用いて学習され、精度と再現性のバランスが取れています。
コア機能:
- マルチタスク統合: 単一のモデルで、単眼深度推定、マルチビュー深度融合、カメラポーズ推定、3D ガウス生成などのタスクをサポートします。
- 高精度出力:HiRoom データセットで単眼深度精度 94.6% を達成。ETH3D 再構築精度は VGGT などのモデルを上回ります。
- マルチモデルの適応: Main (オールラウンダー)、Metric (深度測定)、Monocular (単眼のみ)、および Nested (ネストされた融合) シリーズ モデルを提供します。
- 柔軟なエクスポート: GLB、NPZ、PLY、3DGS ビデオなどの形式をサポートし、下流の 3D ツール (Blender など) とシームレスに統合します。
このチュートリアルでは、Grado を使用して、「RTX_5090」コンピューティング リソースを備えた DA3 コア モデルを展開します。これにより、ビデオ メモリやメモリのボトルネックなしで、3D ガウス生成 (高解像度) やマルチビュー 3D 再構築などの負荷の高いタスクを完全に実行できます。
2. エフェクト表示
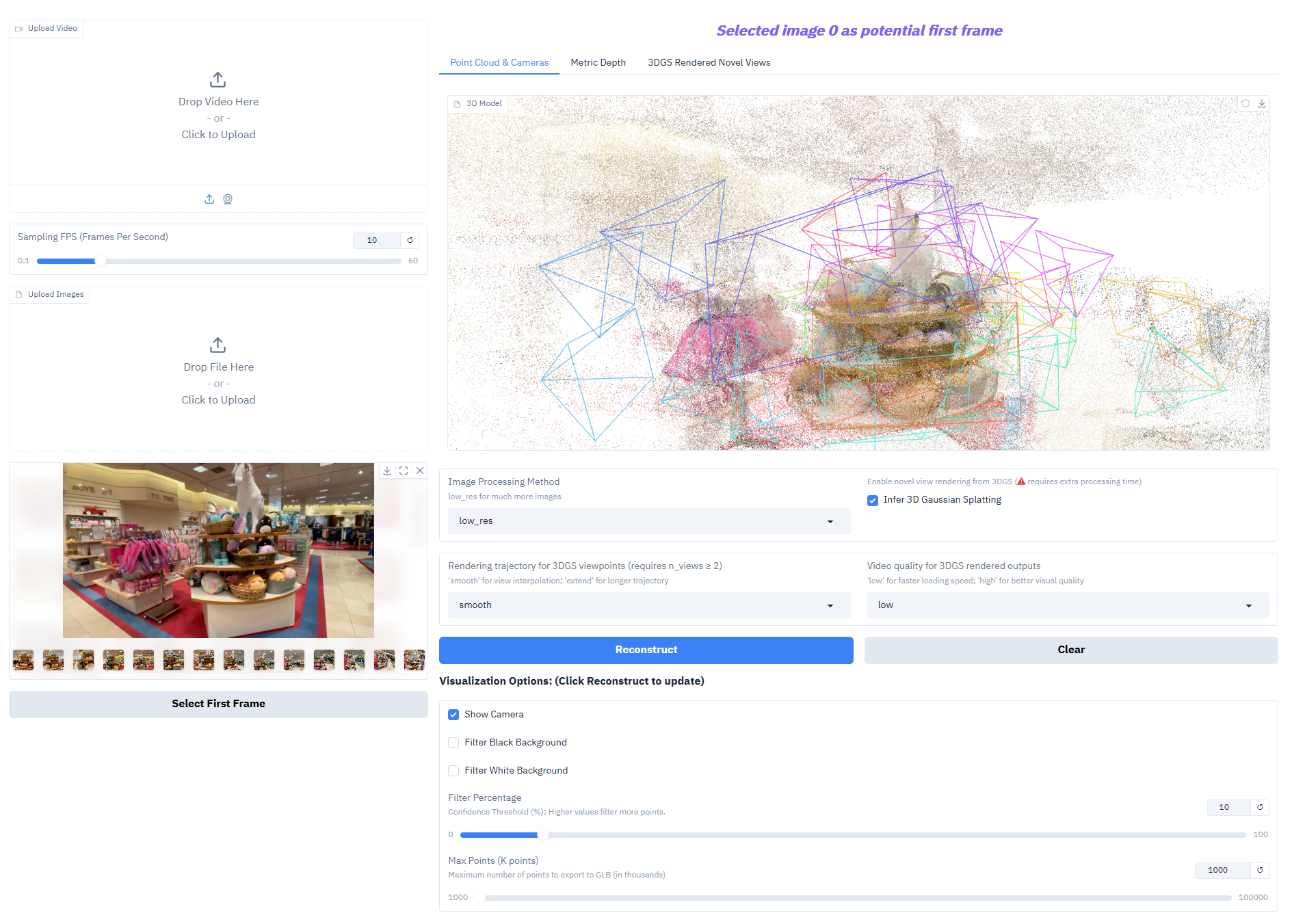
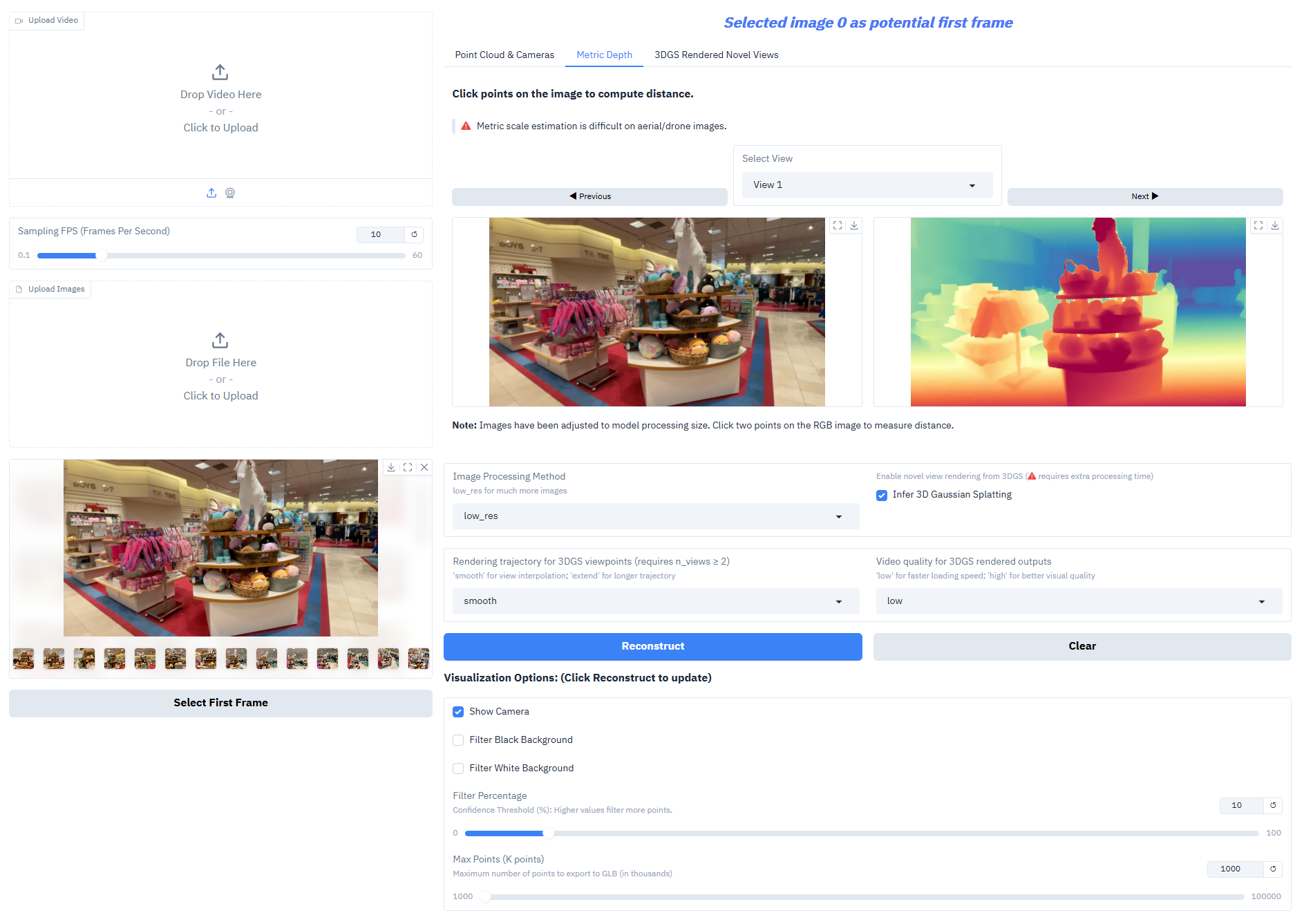
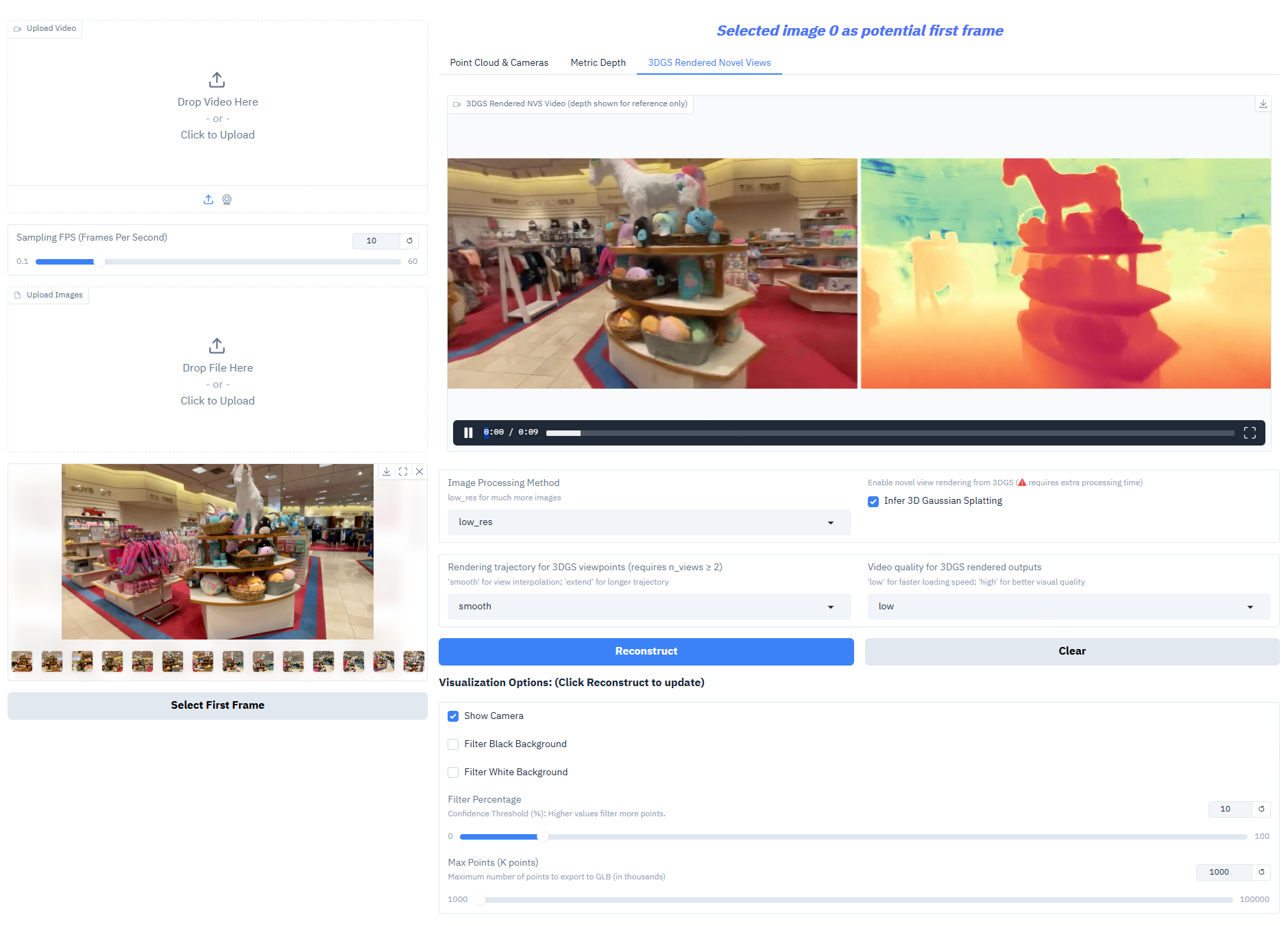
Depth-Anything-3 はコアタスクで非常に優れたパフォーマンスを発揮します。
- 単眼深度推定: 単一の RGB 画像から高精度の深度マップを生成し、シーンの空間階層を再構築します。
- マルチビュー深度融合: 同じシーンの複数の画像に基づいて一貫した深度フィールドを生成し、高品質の 3D 再構築をサポートします。
- カメラポーズ推定: カメラの固有パラメータと外部パラメータ (外部パラメータ [N,3,4]、固有パラメータ [N,3,3]) を正確に予測し、マルチビュー共同タスクに適応します。
- 3D ガウス生成: 新しいビュー構成 (フレーム レート ≥ 30 fps) をサポートする、高忠実度の 3D ガウス モデルを直接出力します。
- 深度測定出力: ネストされたシリーズ モデルは、測量、インテリア デザイン、その他のシナリオのニーズを満たす現実的なスケールの深度を生成できます。
3. 操作手順
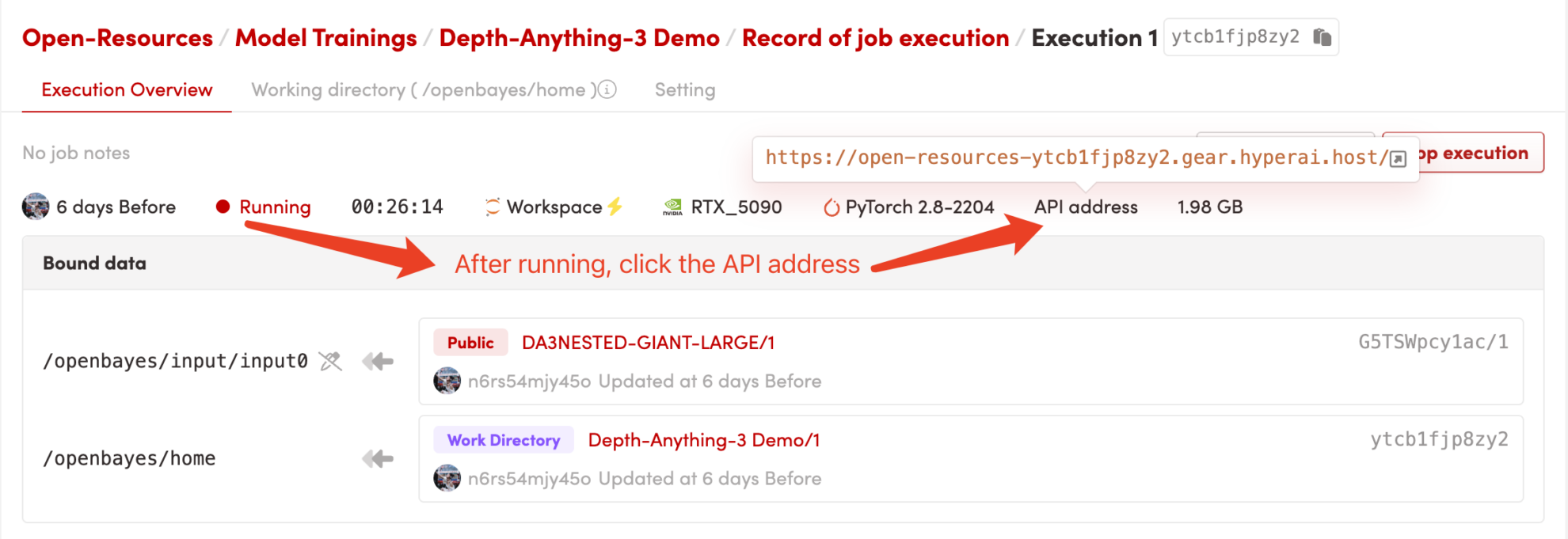
1. コンテナを起動します
コンテナを起動した後、API アドレスをクリックして Web インターフェイスに入ります
2. はじめに
「Bad Gateway」と表示される場合は、モデルが初期化中であることを意味します。モデルのサイズが大きいため、2~3分待ってからページを更新してください。
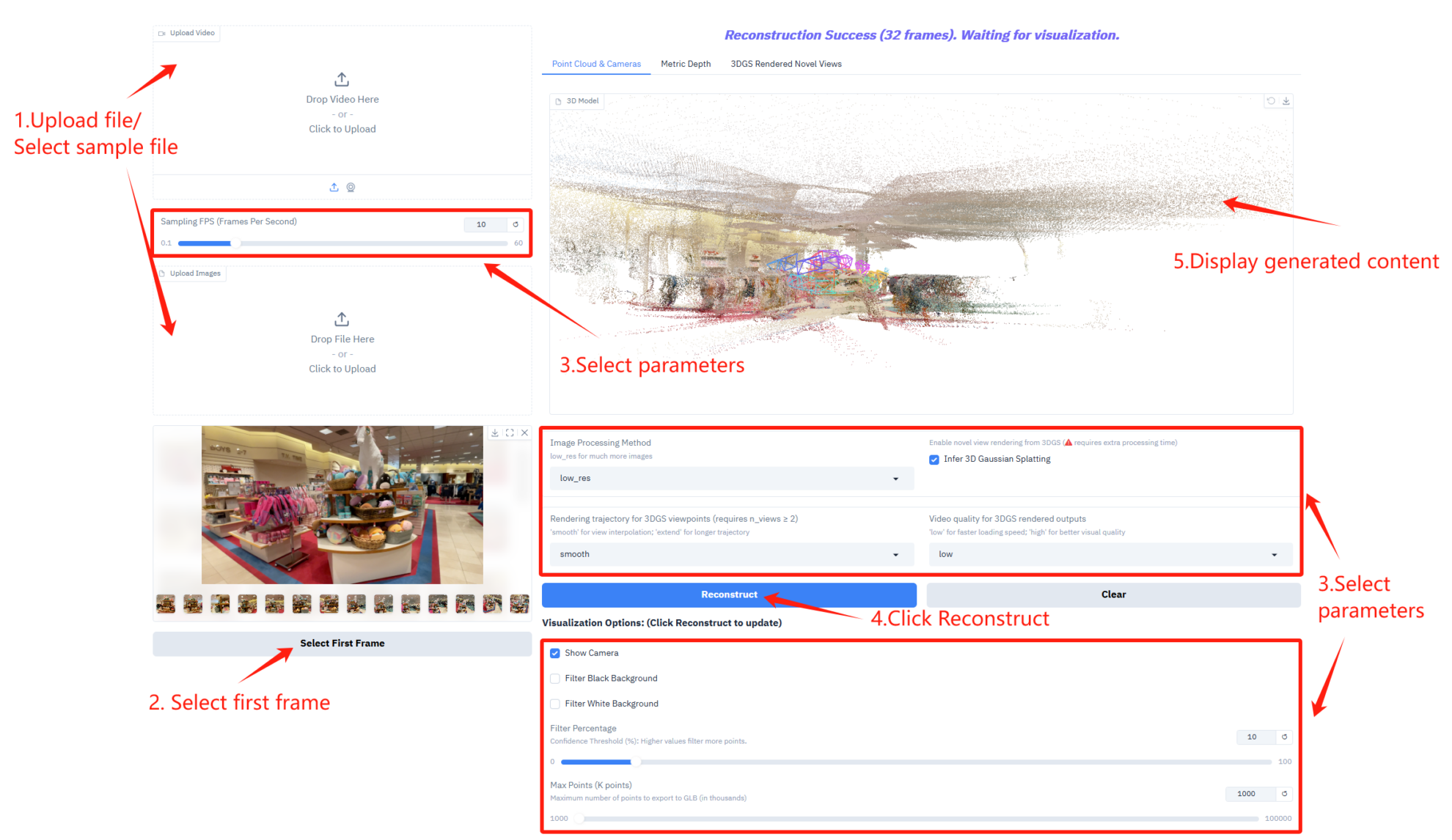
パラメータの説明
- サンプリングフレームレート設定
- サンプリング FPS (フレーム/秒): ビデオ サンプリングに使用される 1 秒あたりのフレーム数を制御します。
- 画像処理と3D推論のセットアップ
- 画像処理方法: 多数の画像に対応するために画像処理モードを選択します。
- 3D ガウス スプラッティングの推論: 3D ガウス スパッタリング推論を有効にするには、3D モデルを生成するために追加の処理時間が必要になります。
- レンダリング軌跡とビデオ品質の設定
- 3DGS ビューポイントのレンダリング トラジェクトリ: 3DGS ビューポイントのレンダリング トラジェクトリのタイプを選択します。
- 3DGS レンダリング出力のビデオ品質: 3DGS レンダリング出力のビデオ品質を制御します。
- 視覚化オプション
- カメラを表示: カメラの軌跡を 3D ビューで表示します。
- 黒い背景をフィルタリング: ポイント クラウド内の黒い背景領域をフィルタリングします。
- 白い背景をフィルタリング: ポイント クラウド内の白い背景領域をフィルタリングします。
- フィルター パーセンテージ: ポイント クラウドのフィルター強度を制御します。
- 最大ポイント (K ポイント): 3D モデルを GLB 形式でエクスポートするときの最大ポイント数を設定します。
引用情報
このプロジェクトの引用情報は次のとおりです。
@article{depthanything3,
title={Depth Anything 3: Recovering the visual space from any views},
author={Haotong Lin and Sili Chen and Jun Hao Liew and Donny Y. Chen and Zhenyu Li and Guang Shi and Jiashi Feng and Bingyi Kang},
journal={arXiv preprint arXiv:2511.10647},
year={2025}
}Notebook の概要
レベル
トピック