HyperAI
Command Palette
Search for a command to run...
Dia2-TTS: リアルタイム音声合成サービス
1. チュートリアルの概要

Dia2-TTSは、nari-labsチームが2025年11月にリリースしたDia2大規模音声生成モデル(Dia2-2B)をベースに構築されたリアルタイム音声合成サービスです。マルチターンの対話スクリプト入力、デュアルロール音声プロンプト(Prefix Voice)、マルチパラメータ制御可能なサンプリングをサポートし、Gradoを介して完全なWebベースのインタラクティブインターフェースを提供し、高品質な会話音声合成を実現します。Dia2-TTSは、連続したマルチターンの対話スクリプトを直接入力することで、自然で一貫性のある高品質な音声を生成することができ、バーチャルカスタマーサービス、音声アシスタント、AIダビング、ショートドラマ生成などの用途に適しています。
コア機能:
- マルチターン対話音声合成S1/S2 で 2 人のキャラクター間の連続したマルチターン ダイアログをサポートします。
- 声部接頭辞駆動による音色プレフィックスボイスによるキャラクターの声の一貫性の制御
- デュアルサンプリングシステムテキストとオーディオのサンプリング パラメータは個別に制御可能です。
- 制御可能なCFG生成全体的な生成強度の CFG スケール調整をサポートします。
- タイムスタンプ整列出力単語レベルのタイムスタンプにより、ポストプロダクションの字幕作成や編集が容易になります。
- WebベースのインタラクションGrado に基づくワンクリックのオンライン推論。
このチュートリアルでは、Gradoを用いてDia2-TTSリアルタイム音声合成サービスをデプロイします。使用するコンピューティングリソースは「RTX_5090」で、マルチターンの対話レベル音声生成タスクをスムーズに実行できます。現時点では、英語の対話のみを生成できます。
2. エフェクト表示
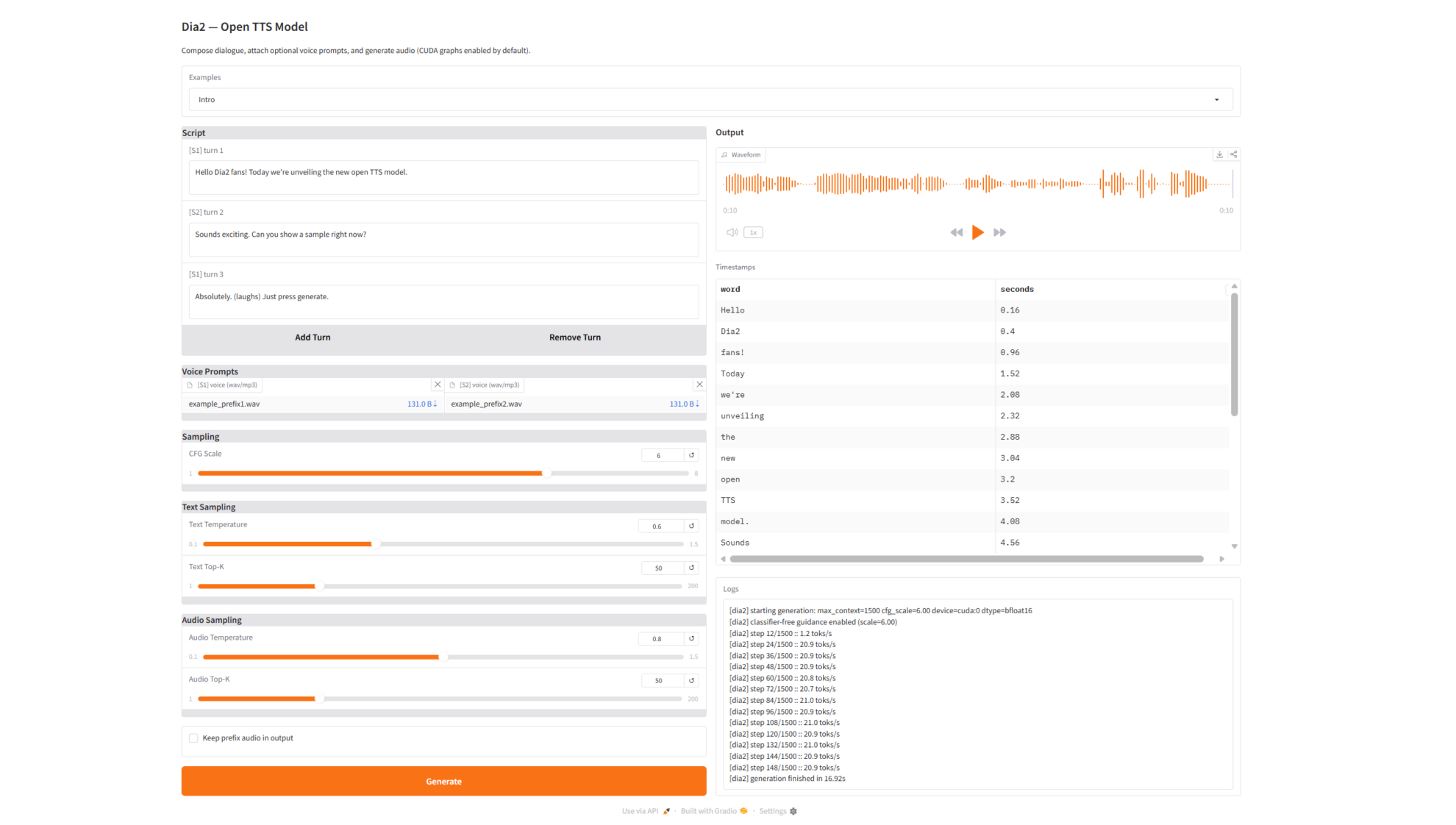
Dia2-TTS は実際のアプリケーションで次のことを実現できます。
- マルチターン対話音声合成連続した複数ターンの自然な対話の生成をサポートします。
- 非常に自然な音声出力滑らかな話し方、自然な間、安定した感情。
- キャラクターの声の保持声部接頭辞に基づいて一貫した声色を維持する
- 音声タイムスタンプ出力字幕生成、リップシンクアニメーション、二次編集などに使用できます。
- ログ可視化出力: 推論プロセスと生成状態を完全に実証する
3. 操作手順
1. コンテナを起動します
コンテナを起動した後、API アドレスをクリックして Web インターフェイスに入ります
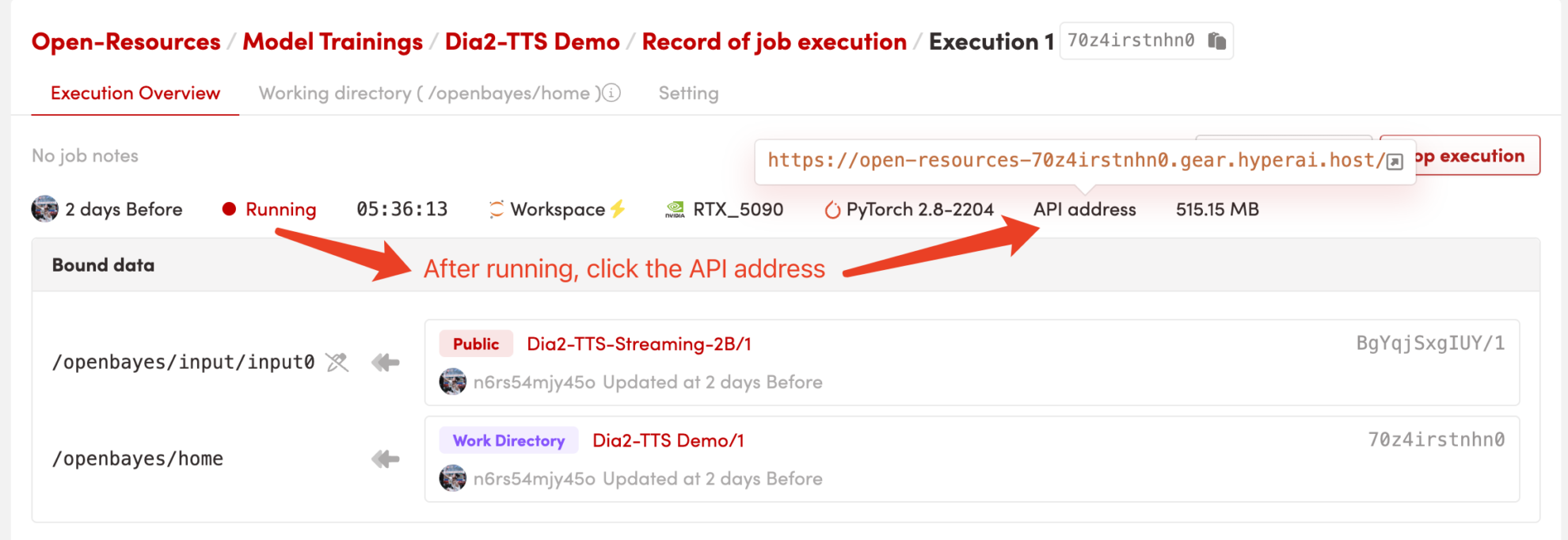
2. はじめに
「Bad Gateway」と表示される場合は、モデルが初期化中であることを意味します。1~2分ほどお待ちいただき、ページを更新してください。
Safari ブラウザを使用する場合、オーディオは直接再生されない場合があり、再生する前にダウンロードする必要があります。
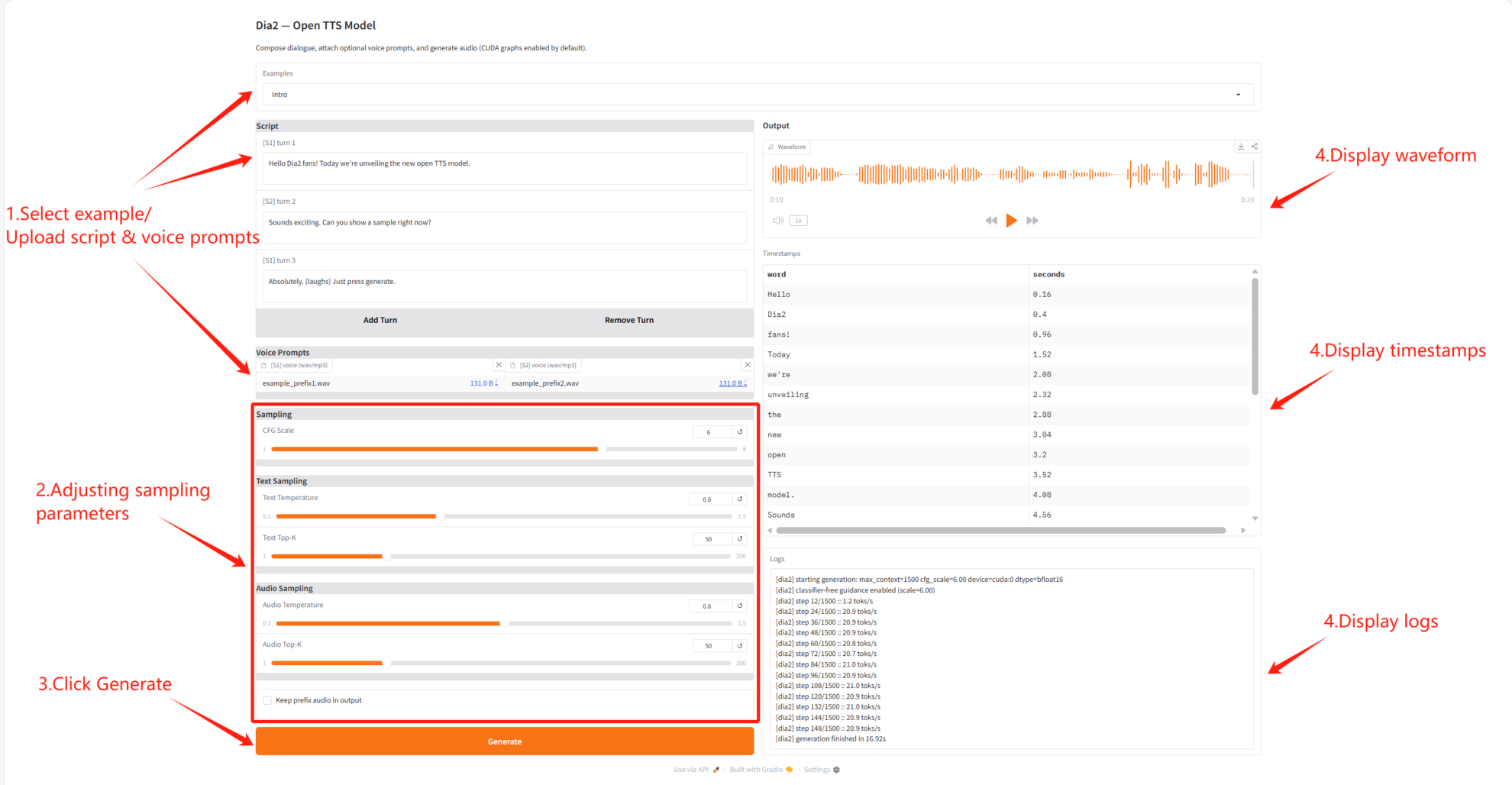
パラメータの説明
- 全体的な音声制御
- CFG スケール: テキストと音声生成の全体的なガイド強度を制御します。
- テキストサンプリング設定
- テキスト温度: テキスト生成のランダム性を制御します。
- テキストトップK: テキストサンプリング候補の範囲を制御する
- オーディオサンプリング設定
- オーディオ温度: オーディオ生成のランダム性を制御します。
- オーディオトップK: オーディオサンプルの候補範囲を制御します
- 音声プレフィックス制御
- プレフィックスを保持: 最終出力でプレフィックス付きの発音を保持するかどうか。
このノートブックはコミュニティユーザーによって提供されたものであり、教育および情報提供のみを目的としています。コンテンツに著作権侵害が含まれる場合は、[email protected]までご連絡ください。速やかに確認し、削除いたします。