Command Palette
Search for a command to run...
Supertonic: ONNXに基づく高速TTS音声合成モデル
1. チュートリアルの概要

このチュートリアルは、公式の Supertone オープンソース プロジェクトに基づいています。スーパートニックオープンソース コミュニティへの貢献をいただいた Supertone チームに感謝します! ❤️
Supertonicは、Supertoneチームが2025年1月にリリースしたネイティブ音声合成(TTS)エンジンです。コア推論層は、低レイテンシかつ高並列処理のシナリオ向けに特別に設計されたONNXランタイムを使用して実装されています。従来の大規模TTSモデルとは異なり、Supertonicは高品質の音声合成を維持しながらハードウェア障壁を大幅に低減し、デスクトップ、サーバー、さらにはエッジデバイス上で完全にオフラインのリアルタイム推論をサポートします。特に、プライバシーとセキュリティが重視されるシナリオや、リアルタイムインタラクティブアプリケーション(デジタルヒューマンやゲームボイスチャットなど)への統合が必要なシナリオに適しています。
注意: このプロジェクトは現在、英語テキストの音声合成のみをサポートしています。
このチュートリアルでは、OpenBayes プラットフォーム上の単一の RTX 5090 GPU の計算能力を示し、onnxruntime-gpu ハードウェア アクセラレーションと Grado を使用して、ミリ秒レベルの英語音声合成を実現するビジュアル Web インターフェイスを構築します。
2. プロジェクト例
3. 操作手順
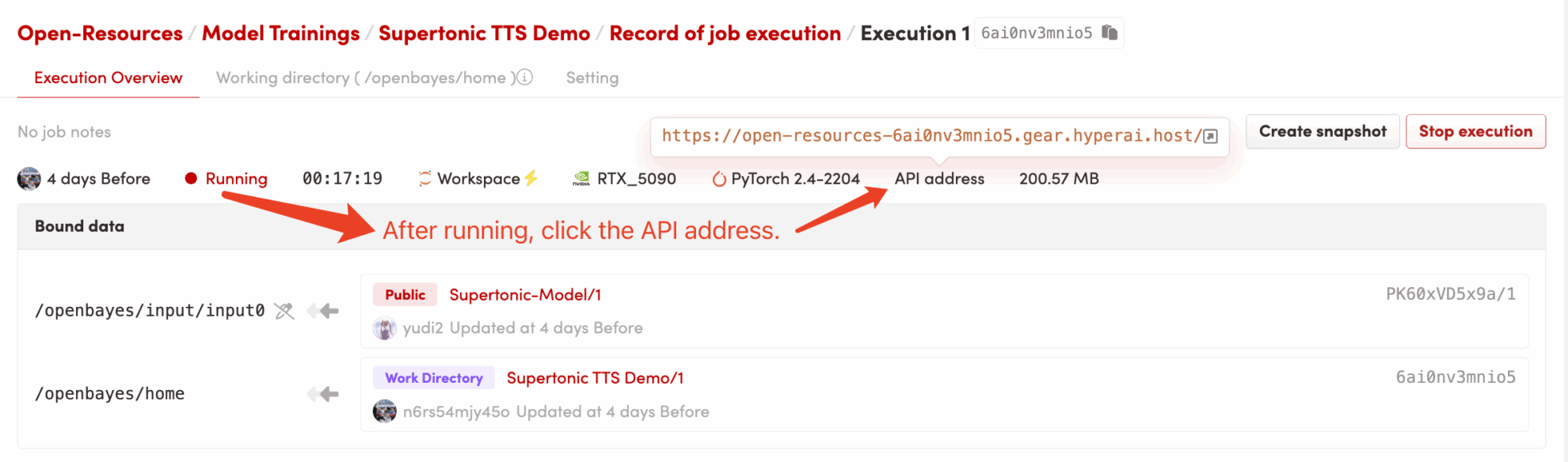
1. コンテナを起動した後、APIアドレスをクリックしてWebインターフェースに入ります。
- この公開チュートリアルを OpenBayes コンソールに複製します。
- コンテナを起動します。システムによって RTX 5090 リソースが自動的に割り当てられます。
- 開始待ち: コンテナが起動した後、バックグラウンドスクリプトが
dependencies.shCUDA環境が自動的に構成され、モデルがロードされます。コア依存関係は事前にインストールされているため、このプロセスは非常に高速で、通常は1~2分しかかかりません。 - アプリケーションへのアクセス: コンテナのステータスが「実行中」に変わったら、コンテナの詳細ページの右上隅にある「API アドレス」ボタンをクリックして、Grado Web インターフェースを開きます。
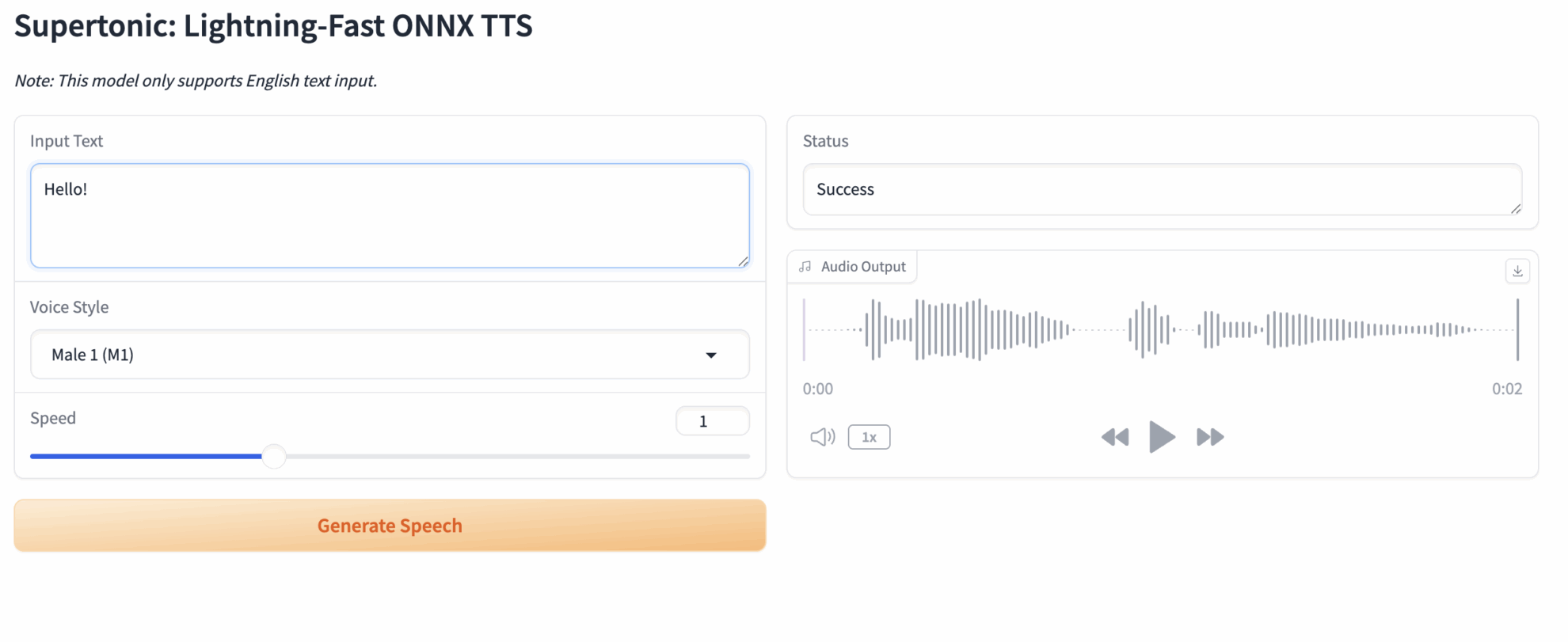
2. Webページにテキストを入力して音声を合成します。
「Bad Gateway」と表示される場合は、サービスが起動中であることを意味します。モデルの読み込みには時間がかかるため、1~2分ほどお待ちいただき、ページを更新してください。
Safari ブラウザを使用する場合、オーディオは直接再生されない場合があり、再生する前にダウンロードする必要があります。
ウェブページに入ると、完全に英語のインタラクティブなインターフェースが表示されます。
基本的な使用手順:
- 入力テキスト: 左側のテキストボックスに合成したい英語のテキストを入力します。例: Supertonic は超高速のテキスト読み上げモデルです。
- 音声スタイル: ドロップダウン メニューからプリセット スタイルを選択します (例: ...)。
Male 1男性の声またはFemale 1(女声) - 速度: スライダーをドラッグして読み上げ速度を調整します。デフォルト値は1.0です。
- 音声の生成: [生成] ボタンをクリックします。
- オーディオ出力:しばらくお待ちください。右側のプレーヤーが生成されたオーディオを自動的に再生します。右上のダウンロードボタンをクリックして保存することもできます。
.wav書類。

注: 初めて「生成」をクリックすると、ONNXランタイムがCUDAの初期化とグラフの最適化を実行するため、数秒かかる場合があります。その後の生成速度は非常に速くなります。

引用情報
@article{kim2025supertonic, title={SupertonicTTS: Towards Highly Efficient and Streamlined Text-to-Speech System}, author={Kim, Hyeongju and Yang, Jinhyeok and Yu, Yechan and Ji, Seunghun and Morton, Jacob and Bous, Malek and Lee, Sungjae}, journal={arXiv preprint arXiv:2503.23108}, year={2025}, url={[https://arxiv.org/abs/2503.23108](https://arxiv.org/abs/2503.23108)} } @article{kim2025larope,
title={Length-Aware Rotary Position Embedding for Text-Speech Alignment},
author={Kim, Hyeongju and Lee, Juheon and Yang, Jinhyeok and Morton, Jacob},
journal={arXiv preprint arXiv:2509.11084},
year={2025},
url={https://arxiv.org/abs/2509.11084}
}@article{kim2025spfm,
title={Training Flow Matching Models with Reliable Labels via Self-Purification},
author={Kim, Hyeongju and Yu, Yechan and Yi, June Young and Lee, Juheon},
journal={arXiv preprint arXiv:2509.19091},
year={2025},
url={https://arxiv.org/abs/2509.19091}
}